Scaling Data Quality Across a Modern Data Stack - Case Study with Group1001
Scaling Data Quality Across a Modern Data Stack - Case Study with Group1001
Scaling Data Quality Across a Modern Data Stack - Case Study with Group1001

Koen Van Duyse
Koen Van Duyse
Former Head of Customers and Partners at Soda
Former Head of Customers and Partners at Soda
Table of Contents

We wanted to provide high-quality datasets, delivered in near real-time, so that dashboards reflect live data as it comes in. And beyond just fixing technical issues, we wanted to transform the organization into a truly data-centric one — enabling decision-making rooted in accurate, timely data.
We wanted to provide high-quality datasets, delivered in near real-time, so that dashboards reflect live data as it comes in. And beyond just fixing technical issues, we wanted to transform the organization into a truly data-centric one — enabling decision-making rooted in accurate, timely data.

Gu Xie
Gu Xie
Head of Data Engineering
Head of Data Engineering
Head of Data Engineering
at
Group1001
Group1001
Group 1001 is a technology-driven financial services company that manages a diverse portfolio of insurance and investment products. The company's vision for data is pragmatic: every system should allow for faster, more accurate decisions while maintaining complete trust in the underlying information.
But as their data volumes grew and systems expanded, the data team faced increasing difficulties in maintaining accuracy, timeliness, and consistency across sources. Teams spent hours manually checking data integrity and reconciling inconsistencies between systems. This process was time-consuming, error-prone, and had limited scalability.
To overcome these challenges, back in 2022, Gu Xie, at the time the new Head of Data Engineering at Group 1001, set out to create a modern data stack: a modular, interoperable ecosystem of tools designed to automate, integrate, and scale data operations. Within this transformation, Soda emerged as the critical component that made data quality visible, automated, and accessible to everyone.
In less than a year, a five-person team at Group 1001 built a modern data stack that automated hundreds of quality checks and boosted productivity 10x, proving that enterprise-scale reliability doesn’t require enterprise-scale teams.
The challenge: from manual checks to a modern data stack
Before modernization, the data team's efforts were primarily focused on manual validation and reconciliation. Data engineers frequently began their mornings by scanning for broken pipelines and inconsistent tables, resolving issues before business users could start their day.
“I had to wake up at 6 a.m. every morning. And if anyone knows me, I’m not a morning person. But I had to run these checks to ensure that the data was actually present. Many times, you didn’t even know if the data was there. We were just checking for the basics so that we could actually run reports and inform the business when something was wrong.” — Gu Xie
This reactive approach resulted in bottlenecks that slowed analysis and reduced confidence in reports. Due to the lack of automated monitoring, issues were frequently discovered after they had reached downstream dashboards or business applications.
The company's infrastructure was also changing rapidly. New tools for ingestion, transformation, and orchestration were introduced, each with their own operational model. As a result, integrating and ensuring consistent data quality standards across this diverse stack became critical.
At the time, their small data team, consisting of only 5 people in charge of an ecosystem that supported multiple business functions, understood they needed tools that not only performed strongly in isolation but also integrated naturally into a cohesive ecosystem. To scale effectively, they required tools that reduced operational overhead, automated repetitive tasks, and provided transparency throughout the data lifecycle.
In sum, the team had clear priorities:
Automate quality validation to eliminate manual checks.
Integrate observability directly into pipelines and workflows.
Integrate seamlessly with existing technologies, without adding friction.
Enable self-service quality testing for analysts and business users.
The solution: designing for integration and efficiency
Group 1001’s guiding principle was clear: efficiency through interoperability. Instead of building a large, monolithic system, the team adopted a modular approach, combining tools that met their needs and also fit together with minimal friction.
The team began by modernizing ingestion and storage. Fivetran automated the transfer of data from operational systems to Snowflake, ensuring timeliness and consistency. Coalesce simplified transformation pipelines, whereas Dagster managed complex workflows with dependability and visibility.
The last piece was data quality. Group 1001 needed a solution that was lightweight, flexible, and easy to embed into existing pipelines. When evaluating data quality solutions, Group 1001 faced a common decision: build or buy?
Building from scratch would require:
Custom framework development and maintenance
Check template library creation
Failure tracking and alerting system
User interface for non-technical users
Ongoing engineering resources for updates
Having built data quality processes from scratch in previous roles, Gu understood the true cost of custom development.
“Initially, we were running daily queries manually. I thought, “Well, we could build a quick wrapper to run these automatically,” but for enterprise-scale operations, that’s not enough. You need standardized, templated checks for uniqueness, freshness, reference checks, statistical validations, and more. On top of that, you need a way to track failures, learn from them, and respond appropriately.
When I evaluated Soda, especially the cloud offering, I saw all these capabilities already built in: libraries of checks, customization, flexibility, and templates. Essentially, it meant I didn’t have to rebuild what was already there - it was ready to scale for the organization.” — Gu Xie
After considering several tools, Group 1001 chose Soda for its flexibility and built-in capabilities. But what stood out most to the data team was how effortlessly Soda integrated into their broader data ecosystem.
“Three days later, we rolled out Soda, using the open-source version, into production. Now it automatically runs all the checks we were doing manually and even stops report refreshes if something’s off, so the business never gets impacted. And because we have that check in place, I can now sleep and focus on other tasks. That’s value right there - pretty clear if you ask me.” — Gu Xie
At the beginning of this project, when migrating data from PostgreSQL to Snowflake, Soda checks were used to verify row counts and schema alignment, ensuring accurate reconciliation. This capability eliminated hours of manual comparison and significantly reduced risk during transitions.
“We combined Snowflake with Airflow at the time, and leveraged Soda to handle a lot of the reconciliation during migration. That was key to ensuring data quality was maintained while ironing out the migration over a few weeks before going live.” - Gu Xie
The team began with Soda’s open-source framework to handle repetitive quality checks, monitoring record counts, completeness, and schema changes. As requirements grew, they adopted Soda Cloud (SaaS platform), unlocking more collaboration, governance, and alerting features.
Soda now connects with every major layer of Group 1001’s stack:
Dagster triggers Soda checks during pipeline runs, catching issues before data reaches end users.
Snowflake serves as the foundation, with Soda verifying data consistency across migrations and updates.
Coalesce integrates post-transformation tests, ensuring outputs meet defined quality thresholds.
Atlan surfaces Soda’s quality metrics within its catalog, linking observability to data lineage.
See all Soda integrations
This architecture enables end-to-end data quality coverage with minimal engineering effort.
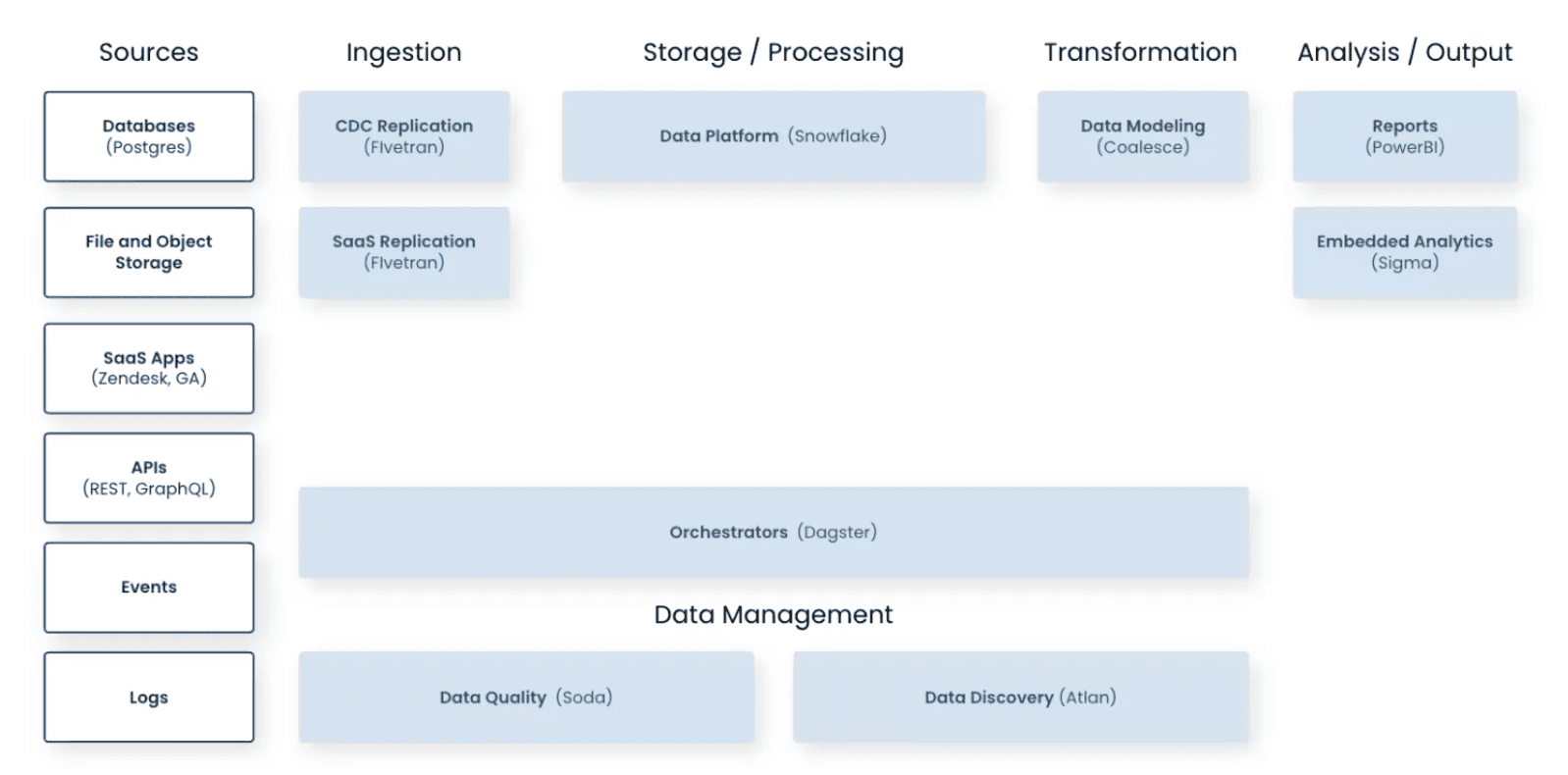
Image taken from Group 1001 increases productivity by 10x by Fivetran
“The real ROI has always been the productivity of our engineers, the productivity of our analysts - to not spend time troubleshooting and firefighting every day, to spend more time discovering new insights and delivering more value.” — Gu Xie
The impact: data quality as an enabler
Soda’s introduction shifted the data team’s mindset from reactive fixes to proactive monitoring. What used to require manual inspection now happens automatically across hundreds of datasets.
Each quality check runs as part of the pipeline execution, creating a continuous loop of validation.
Soda’s user-friendly YAML configuration also made it accessible to non-engineers. Data analysts could author their own tests, review results in Soda Cloud, and collaborate with engineers to refine thresholds, all without much coding experience.
The simplicity of YAML configuration meant that a QA team member without deep SQL expertise, could independently author and deploy checks for vendor data feeds. This self-service capability proved critical for scaling data reliability. Analysts who once relied on engineers for validation can now independently monitor their own datasets, reducing dependency and response time.
“With SodaCloud, we don’t need a highly technical user to author checks. A business analyst or data analyst can write and provision checks themselves through self-service. That was what I really liked about SodaCloud - it enabled a bigger vision for the organization.” — Gu Xie
Example Soda checks.yaml
dataset: dim_product owner: zaynabissa@company.com columns: - name: id data_type: VARCHAR checks: - type: duplicate_count - name: size data_type: VARCHAR checks: - type: invalid_count valid_values: ['S', 'M', 'L'] must_be_greater_than_or_equal: 10 - name: distance checks: - type: invalid_count valid_min: 0 valid_max: 1000 - name: created optional: true checks: - type
The results of Group 1001’s new data architecture were immediate:
Reduced Operational Overhead
Previously repetitive validation steps are now automated. Engineers spend less time troubleshooting, and issues are detected earlier, before reaching end users. This proactive approach has significantly decreased downtime and rework.
Scalable Quality Coverage
Every pipeline now includes automated checks. New datasets are onboarded with standardized rules, and issues are detected before they propagate. The team can easily expand monitoring as new sources or transformations are added.
Improved Collaboration and Trust
By integrating Soda with Atlan, Group 1001 brought quality visibility into its catalog, allowing data consumers to assess trust levels instantly. Business stakeholders now have greater confidence in the reports and insights they use for decision-making.
For Group 1001, the most important result of this modernization process was that their data became an asset they rely on, not a liability they work around.
Metric | Before Soda | After Soda |
|---|---|---|
Data Quality Checks | Manual, 6am daily | Automated, continuous |
Issue Detection | After business impact | Before propagation |
Analytics Delivery | Months | Few days days |
Migration Risk | High (manual validation) | Low (automated reconciliation) |
Team Capacity | Firefighting focused | Strategic work focused |
Business Confidence | Delayed, unreliable data | Near real-time, trusted data |
Quality Check Authors | Engineers only | Analysts + Engineers |
This transformation was achieved by a 5-person team in under 12 months, demonstrating that the right tooling choices can deliver enterprise-scale impact without enterprise-scale teams.
Building a Culture of Data Trust
Beyond technology, the adoption of Soda helped shift Group 1001’s data culture. Data quality is no longer the exclusive responsibility of engineers, it’s part of how every team works with data. Analysts and engineers alike contribute to defining quality expectations, writing checks, and reviewing results.
Transparency through Soda Cloud dashboards makes quality issues visible to everyone, fostering accountability and continuous improvement.
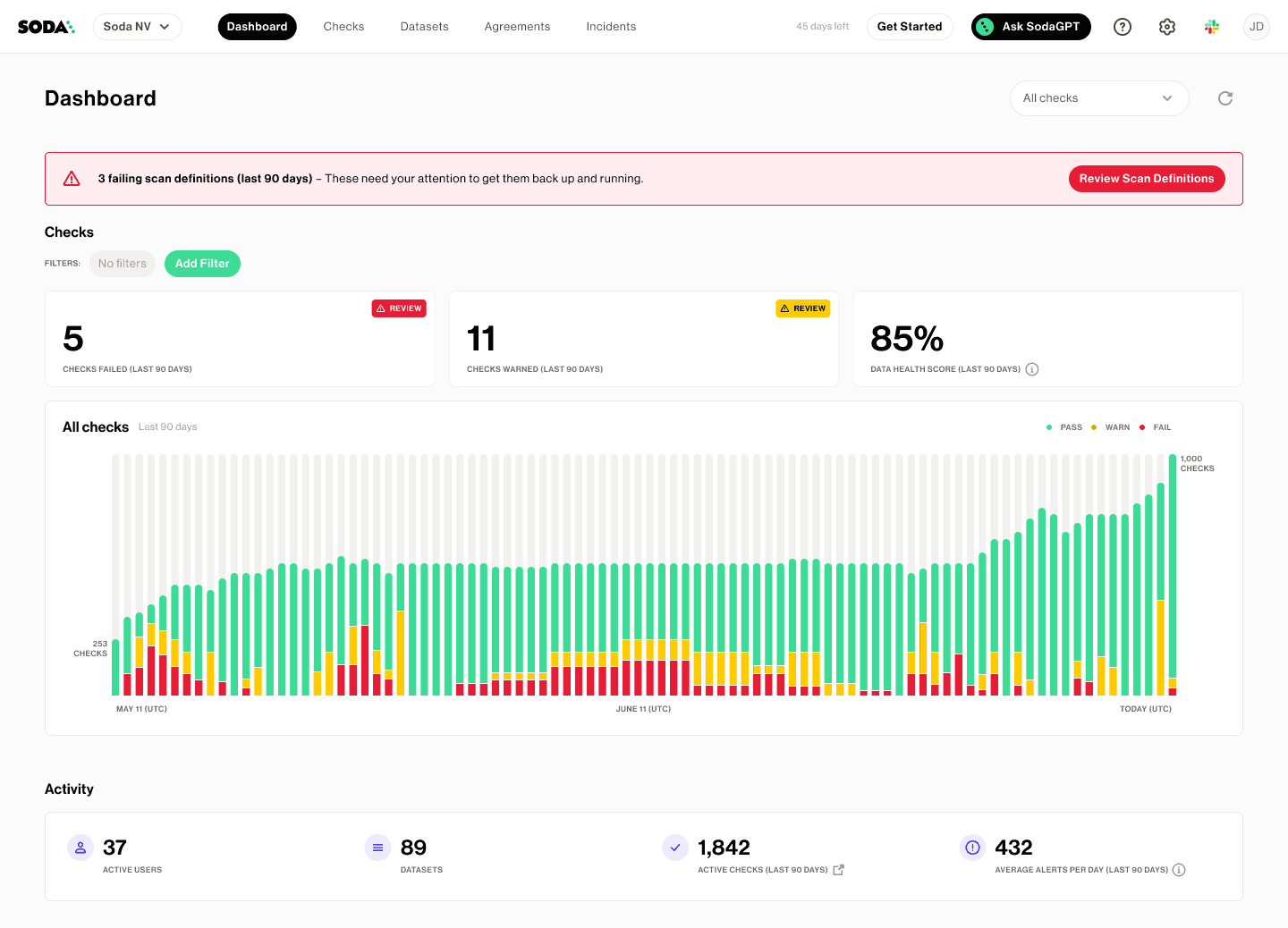
“Now we're proactive. We know there’s an issue, we inform the teams, we resolve it, and by resolving it, we can also apply another data quality rule to ensure it never happens again. That’s how we get a better handle on our datasets.” — Gu Xie
This collaborative approach has also influenced internal governance. The team now codifies lessons learned into reusable templates, ensuring that quality standards are consistently applied to new projects. Over time, this framework has become a foundation for data trust across the organization.
“The way I see Soda and how it actually helps us transform and the value we get is the fact that we can sleep at night knowing that our processes are running, that we can trust that if everything's finished and the cycle's complete and we can see the data now in our dashboard refreshed, we can trust it.” — Gu Xie
Looking ahead: metadata-driven observability
Group 1001’s next phase focuses on deepening the connection between metadata and quality observability. By linking Soda’s validation metrics with Atlan’s lineage data, the company aims to create an intelligent feedback loop that automatically prioritizes quality improvements based on data usage and business impact.
For Gu Xie, the strategy remains clear: keep the stack modular, interoperable, and focused on enabling people to do more with data.
“Because we're using this catalog to house all data assets, we can now share it across departments, teams, and even different companies. Now we can truly democratize data within the organization.” — Gu Xie
Key Takeaways
Group 1001's journey offers actionable lessons for organizations facing similar challenges:
If you're waking up to check data manually: Start with automation. Don't wait for perfect infrastructure; solve the immediate pain point.
If you have a small team supporting large needs: Best-of-breed tools are your force multiplier.
If you're planning a platform migration: Make data quality your safety net. Automated validation is cheaper than migration failure.
If your organization doesn't trust the data: Start measuring what matters. Not the number of checks, but the reduction in recurring issues.
If you're choosing between build vs. buy: Consider opportunity cost. The weeks spent building data quality infrastructure are weeks not spent delivering business insights. Soda gave Group 1001 enterprise-grade capabilities in days, not months.
Disclaimer: This material was created in 2023. Please note that figures and statistics may have changed, and there might be minor code syntax or UI path differences since its publication. |
|---|
Watch the Interview
Hear more from Gu Xie, Head of Data Engineering at Group 1001, in the Fizz podcast interview: Building a Modern Data Stack
Get in touch
Schedule a demo with the Soda team or request a free account to find out how much you could optimize your data quality strategy across your entire data ecosystem.
Group 1001 is a technology-driven financial services company that manages a diverse portfolio of insurance and investment products. The company's vision for data is pragmatic: every system should allow for faster, more accurate decisions while maintaining complete trust in the underlying information.
But as their data volumes grew and systems expanded, the data team faced increasing difficulties in maintaining accuracy, timeliness, and consistency across sources. Teams spent hours manually checking data integrity and reconciling inconsistencies between systems. This process was time-consuming, error-prone, and had limited scalability.
To overcome these challenges, back in 2022, Gu Xie, at the time the new Head of Data Engineering at Group 1001, set out to create a modern data stack: a modular, interoperable ecosystem of tools designed to automate, integrate, and scale data operations. Within this transformation, Soda emerged as the critical component that made data quality visible, automated, and accessible to everyone.
In less than a year, a five-person team at Group 1001 built a modern data stack that automated hundreds of quality checks and boosted productivity 10x, proving that enterprise-scale reliability doesn’t require enterprise-scale teams.
The challenge: from manual checks to a modern data stack
Before modernization, the data team's efforts were primarily focused on manual validation and reconciliation. Data engineers frequently began their mornings by scanning for broken pipelines and inconsistent tables, resolving issues before business users could start their day.
“I had to wake up at 6 a.m. every morning. And if anyone knows me, I’m not a morning person. But I had to run these checks to ensure that the data was actually present. Many times, you didn’t even know if the data was there. We were just checking for the basics so that we could actually run reports and inform the business when something was wrong.” — Gu Xie
This reactive approach resulted in bottlenecks that slowed analysis and reduced confidence in reports. Due to the lack of automated monitoring, issues were frequently discovered after they had reached downstream dashboards or business applications.
The company's infrastructure was also changing rapidly. New tools for ingestion, transformation, and orchestration were introduced, each with their own operational model. As a result, integrating and ensuring consistent data quality standards across this diverse stack became critical.
At the time, their small data team, consisting of only 5 people in charge of an ecosystem that supported multiple business functions, understood they needed tools that not only performed strongly in isolation but also integrated naturally into a cohesive ecosystem. To scale effectively, they required tools that reduced operational overhead, automated repetitive tasks, and provided transparency throughout the data lifecycle.
In sum, the team had clear priorities:
Automate quality validation to eliminate manual checks.
Integrate observability directly into pipelines and workflows.
Integrate seamlessly with existing technologies, without adding friction.
Enable self-service quality testing for analysts and business users.
The solution: designing for integration and efficiency
Group 1001’s guiding principle was clear: efficiency through interoperability. Instead of building a large, monolithic system, the team adopted a modular approach, combining tools that met their needs and also fit together with minimal friction.
The team began by modernizing ingestion and storage. Fivetran automated the transfer of data from operational systems to Snowflake, ensuring timeliness and consistency. Coalesce simplified transformation pipelines, whereas Dagster managed complex workflows with dependability and visibility.
The last piece was data quality. Group 1001 needed a solution that was lightweight, flexible, and easy to embed into existing pipelines. When evaluating data quality solutions, Group 1001 faced a common decision: build or buy?
Building from scratch would require:
Custom framework development and maintenance
Check template library creation
Failure tracking and alerting system
User interface for non-technical users
Ongoing engineering resources for updates
Having built data quality processes from scratch in previous roles, Gu understood the true cost of custom development.
“Initially, we were running daily queries manually. I thought, “Well, we could build a quick wrapper to run these automatically,” but for enterprise-scale operations, that’s not enough. You need standardized, templated checks for uniqueness, freshness, reference checks, statistical validations, and more. On top of that, you need a way to track failures, learn from them, and respond appropriately.
When I evaluated Soda, especially the cloud offering, I saw all these capabilities already built in: libraries of checks, customization, flexibility, and templates. Essentially, it meant I didn’t have to rebuild what was already there - it was ready to scale for the organization.” — Gu Xie
After considering several tools, Group 1001 chose Soda for its flexibility and built-in capabilities. But what stood out most to the data team was how effortlessly Soda integrated into their broader data ecosystem.
“Three days later, we rolled out Soda, using the open-source version, into production. Now it automatically runs all the checks we were doing manually and even stops report refreshes if something’s off, so the business never gets impacted. And because we have that check in place, I can now sleep and focus on other tasks. That’s value right there - pretty clear if you ask me.” — Gu Xie
At the beginning of this project, when migrating data from PostgreSQL to Snowflake, Soda checks were used to verify row counts and schema alignment, ensuring accurate reconciliation. This capability eliminated hours of manual comparison and significantly reduced risk during transitions.
“We combined Snowflake with Airflow at the time, and leveraged Soda to handle a lot of the reconciliation during migration. That was key to ensuring data quality was maintained while ironing out the migration over a few weeks before going live.” - Gu Xie
The team began with Soda’s open-source framework to handle repetitive quality checks, monitoring record counts, completeness, and schema changes. As requirements grew, they adopted Soda Cloud (SaaS platform), unlocking more collaboration, governance, and alerting features.
Soda now connects with every major layer of Group 1001’s stack:
Dagster triggers Soda checks during pipeline runs, catching issues before data reaches end users.
Snowflake serves as the foundation, with Soda verifying data consistency across migrations and updates.
Coalesce integrates post-transformation tests, ensuring outputs meet defined quality thresholds.
Atlan surfaces Soda’s quality metrics within its catalog, linking observability to data lineage.
See all Soda integrations
This architecture enables end-to-end data quality coverage with minimal engineering effort.
Image taken from Group 1001 increases productivity by 10x by Fivetran
“The real ROI has always been the productivity of our engineers, the productivity of our analysts - to not spend time troubleshooting and firefighting every day, to spend more time discovering new insights and delivering more value.” — Gu Xie
The impact: data quality as an enabler
Soda’s introduction shifted the data team’s mindset from reactive fixes to proactive monitoring. What used to require manual inspection now happens automatically across hundreds of datasets.
Each quality check runs as part of the pipeline execution, creating a continuous loop of validation.
Soda’s user-friendly YAML configuration also made it accessible to non-engineers. Data analysts could author their own tests, review results in Soda Cloud, and collaborate with engineers to refine thresholds, all without much coding experience.
The simplicity of YAML configuration meant that a QA team member without deep SQL expertise, could independently author and deploy checks for vendor data feeds. This self-service capability proved critical for scaling data reliability. Analysts who once relied on engineers for validation can now independently monitor their own datasets, reducing dependency and response time.
“With SodaCloud, we don’t need a highly technical user to author checks. A business analyst or data analyst can write and provision checks themselves through self-service. That was what I really liked about SodaCloud - it enabled a bigger vision for the organization.” — Gu Xie
Example Soda checks.yaml
dataset: dim_product owner: zaynabissa@company.com columns: - name: id data_type: VARCHAR checks: - type: duplicate_count - name: size data_type: VARCHAR checks: - type: invalid_count valid_values: ['S', 'M', 'L'] must_be_greater_than_or_equal: 10 - name: distance checks: - type: invalid_count valid_min: 0 valid_max: 1000 - name: created optional: true checks: - type
The results of Group 1001’s new data architecture were immediate:
Reduced Operational Overhead
Previously repetitive validation steps are now automated. Engineers spend less time troubleshooting, and issues are detected earlier, before reaching end users. This proactive approach has significantly decreased downtime and rework.
Scalable Quality Coverage
Every pipeline now includes automated checks. New datasets are onboarded with standardized rules, and issues are detected before they propagate. The team can easily expand monitoring as new sources or transformations are added.
Improved Collaboration and Trust
By integrating Soda with Atlan, Group 1001 brought quality visibility into its catalog, allowing data consumers to assess trust levels instantly. Business stakeholders now have greater confidence in the reports and insights they use for decision-making.
For Group 1001, the most important result of this modernization process was that their data became an asset they rely on, not a liability they work around.
Metric | Before Soda | After Soda |
|---|---|---|
Data Quality Checks | Manual, 6am daily | Automated, continuous |
Issue Detection | After business impact | Before propagation |
Analytics Delivery | Months | Few days days |
Migration Risk | High (manual validation) | Low (automated reconciliation) |
Team Capacity | Firefighting focused | Strategic work focused |
Business Confidence | Delayed, unreliable data | Near real-time, trusted data |
Quality Check Authors | Engineers only | Analysts + Engineers |
This transformation was achieved by a 5-person team in under 12 months, demonstrating that the right tooling choices can deliver enterprise-scale impact without enterprise-scale teams.
Building a Culture of Data Trust
Beyond technology, the adoption of Soda helped shift Group 1001’s data culture. Data quality is no longer the exclusive responsibility of engineers, it’s part of how every team works with data. Analysts and engineers alike contribute to defining quality expectations, writing checks, and reviewing results.
Transparency through Soda Cloud dashboards makes quality issues visible to everyone, fostering accountability and continuous improvement.
“Now we're proactive. We know there’s an issue, we inform the teams, we resolve it, and by resolving it, we can also apply another data quality rule to ensure it never happens again. That’s how we get a better handle on our datasets.” — Gu Xie
This collaborative approach has also influenced internal governance. The team now codifies lessons learned into reusable templates, ensuring that quality standards are consistently applied to new projects. Over time, this framework has become a foundation for data trust across the organization.
“The way I see Soda and how it actually helps us transform and the value we get is the fact that we can sleep at night knowing that our processes are running, that we can trust that if everything's finished and the cycle's complete and we can see the data now in our dashboard refreshed, we can trust it.” — Gu Xie
Looking ahead: metadata-driven observability
Group 1001’s next phase focuses on deepening the connection between metadata and quality observability. By linking Soda’s validation metrics with Atlan’s lineage data, the company aims to create an intelligent feedback loop that automatically prioritizes quality improvements based on data usage and business impact.
For Gu Xie, the strategy remains clear: keep the stack modular, interoperable, and focused on enabling people to do more with data.
“Because we're using this catalog to house all data assets, we can now share it across departments, teams, and even different companies. Now we can truly democratize data within the organization.” — Gu Xie
Key Takeaways
Group 1001's journey offers actionable lessons for organizations facing similar challenges:
If you're waking up to check data manually: Start with automation. Don't wait for perfect infrastructure; solve the immediate pain point.
If you have a small team supporting large needs: Best-of-breed tools are your force multiplier.
If you're planning a platform migration: Make data quality your safety net. Automated validation is cheaper than migration failure.
If your organization doesn't trust the data: Start measuring what matters. Not the number of checks, but the reduction in recurring issues.
If you're choosing between build vs. buy: Consider opportunity cost. The weeks spent building data quality infrastructure are weeks not spent delivering business insights. Soda gave Group 1001 enterprise-grade capabilities in days, not months.
Disclaimer: This material was created in 2023. Please note that figures and statistics may have changed, and there might be minor code syntax or UI path differences since its publication. |
|---|
Watch the Interview
Hear more from Gu Xie, Head of Data Engineering at Group 1001, in the Fizz podcast interview: Building a Modern Data Stack
Get in touch
Schedule a demo with the Soda team or request a free account to find out how much you could optimize your data quality strategy across your entire data ecosystem.
Group 1001 is a technology-driven financial services company that manages a diverse portfolio of insurance and investment products. The company's vision for data is pragmatic: every system should allow for faster, more accurate decisions while maintaining complete trust in the underlying information.
But as their data volumes grew and systems expanded, the data team faced increasing difficulties in maintaining accuracy, timeliness, and consistency across sources. Teams spent hours manually checking data integrity and reconciling inconsistencies between systems. This process was time-consuming, error-prone, and had limited scalability.
To overcome these challenges, back in 2022, Gu Xie, at the time the new Head of Data Engineering at Group 1001, set out to create a modern data stack: a modular, interoperable ecosystem of tools designed to automate, integrate, and scale data operations. Within this transformation, Soda emerged as the critical component that made data quality visible, automated, and accessible to everyone.
In less than a year, a five-person team at Group 1001 built a modern data stack that automated hundreds of quality checks and boosted productivity 10x, proving that enterprise-scale reliability doesn’t require enterprise-scale teams.
The challenge: from manual checks to a modern data stack
Before modernization, the data team's efforts were primarily focused on manual validation and reconciliation. Data engineers frequently began their mornings by scanning for broken pipelines and inconsistent tables, resolving issues before business users could start their day.
“I had to wake up at 6 a.m. every morning. And if anyone knows me, I’m not a morning person. But I had to run these checks to ensure that the data was actually present. Many times, you didn’t even know if the data was there. We were just checking for the basics so that we could actually run reports and inform the business when something was wrong.” — Gu Xie
This reactive approach resulted in bottlenecks that slowed analysis and reduced confidence in reports. Due to the lack of automated monitoring, issues were frequently discovered after they had reached downstream dashboards or business applications.
The company's infrastructure was also changing rapidly. New tools for ingestion, transformation, and orchestration were introduced, each with their own operational model. As a result, integrating and ensuring consistent data quality standards across this diverse stack became critical.
At the time, their small data team, consisting of only 5 people in charge of an ecosystem that supported multiple business functions, understood they needed tools that not only performed strongly in isolation but also integrated naturally into a cohesive ecosystem. To scale effectively, they required tools that reduced operational overhead, automated repetitive tasks, and provided transparency throughout the data lifecycle.
In sum, the team had clear priorities:
Automate quality validation to eliminate manual checks.
Integrate observability directly into pipelines and workflows.
Integrate seamlessly with existing technologies, without adding friction.
Enable self-service quality testing for analysts and business users.
The solution: designing for integration and efficiency
Group 1001’s guiding principle was clear: efficiency through interoperability. Instead of building a large, monolithic system, the team adopted a modular approach, combining tools that met their needs and also fit together with minimal friction.
The team began by modernizing ingestion and storage. Fivetran automated the transfer of data from operational systems to Snowflake, ensuring timeliness and consistency. Coalesce simplified transformation pipelines, whereas Dagster managed complex workflows with dependability and visibility.
The last piece was data quality. Group 1001 needed a solution that was lightweight, flexible, and easy to embed into existing pipelines. When evaluating data quality solutions, Group 1001 faced a common decision: build or buy?
Building from scratch would require:
Custom framework development and maintenance
Check template library creation
Failure tracking and alerting system
User interface for non-technical users
Ongoing engineering resources for updates
Having built data quality processes from scratch in previous roles, Gu understood the true cost of custom development.
“Initially, we were running daily queries manually. I thought, “Well, we could build a quick wrapper to run these automatically,” but for enterprise-scale operations, that’s not enough. You need standardized, templated checks for uniqueness, freshness, reference checks, statistical validations, and more. On top of that, you need a way to track failures, learn from them, and respond appropriately.
When I evaluated Soda, especially the cloud offering, I saw all these capabilities already built in: libraries of checks, customization, flexibility, and templates. Essentially, it meant I didn’t have to rebuild what was already there - it was ready to scale for the organization.” — Gu Xie
After considering several tools, Group 1001 chose Soda for its flexibility and built-in capabilities. But what stood out most to the data team was how effortlessly Soda integrated into their broader data ecosystem.
“Three days later, we rolled out Soda, using the open-source version, into production. Now it automatically runs all the checks we were doing manually and even stops report refreshes if something’s off, so the business never gets impacted. And because we have that check in place, I can now sleep and focus on other tasks. That’s value right there - pretty clear if you ask me.” — Gu Xie
At the beginning of this project, when migrating data from PostgreSQL to Snowflake, Soda checks were used to verify row counts and schema alignment, ensuring accurate reconciliation. This capability eliminated hours of manual comparison and significantly reduced risk during transitions.
“We combined Snowflake with Airflow at the time, and leveraged Soda to handle a lot of the reconciliation during migration. That was key to ensuring data quality was maintained while ironing out the migration over a few weeks before going live.” - Gu Xie
The team began with Soda’s open-source framework to handle repetitive quality checks, monitoring record counts, completeness, and schema changes. As requirements grew, they adopted Soda Cloud (SaaS platform), unlocking more collaboration, governance, and alerting features.
Soda now connects with every major layer of Group 1001’s stack:
Dagster triggers Soda checks during pipeline runs, catching issues before data reaches end users.
Snowflake serves as the foundation, with Soda verifying data consistency across migrations and updates.
Coalesce integrates post-transformation tests, ensuring outputs meet defined quality thresholds.
Atlan surfaces Soda’s quality metrics within its catalog, linking observability to data lineage.
See all Soda integrations
This architecture enables end-to-end data quality coverage with minimal engineering effort.
Image taken from Group 1001 increases productivity by 10x by Fivetran
“The real ROI has always been the productivity of our engineers, the productivity of our analysts - to not spend time troubleshooting and firefighting every day, to spend more time discovering new insights and delivering more value.” — Gu Xie
The impact: data quality as an enabler
Soda’s introduction shifted the data team’s mindset from reactive fixes to proactive monitoring. What used to require manual inspection now happens automatically across hundreds of datasets.
Each quality check runs as part of the pipeline execution, creating a continuous loop of validation.
Soda’s user-friendly YAML configuration also made it accessible to non-engineers. Data analysts could author their own tests, review results in Soda Cloud, and collaborate with engineers to refine thresholds, all without much coding experience.
The simplicity of YAML configuration meant that a QA team member without deep SQL expertise, could independently author and deploy checks for vendor data feeds. This self-service capability proved critical for scaling data reliability. Analysts who once relied on engineers for validation can now independently monitor their own datasets, reducing dependency and response time.
“With SodaCloud, we don’t need a highly technical user to author checks. A business analyst or data analyst can write and provision checks themselves through self-service. That was what I really liked about SodaCloud - it enabled a bigger vision for the organization.” — Gu Xie
Example Soda checks.yaml
dataset: dim_product owner: zaynabissa@company.com columns: - name: id data_type: VARCHAR checks: - type: duplicate_count - name: size data_type: VARCHAR checks: - type: invalid_count valid_values: ['S', 'M', 'L'] must_be_greater_than_or_equal: 10 - name: distance checks: - type: invalid_count valid_min: 0 valid_max: 1000 - name: created optional: true checks: - type
The results of Group 1001’s new data architecture were immediate:
Reduced Operational Overhead
Previously repetitive validation steps are now automated. Engineers spend less time troubleshooting, and issues are detected earlier, before reaching end users. This proactive approach has significantly decreased downtime and rework.
Scalable Quality Coverage
Every pipeline now includes automated checks. New datasets are onboarded with standardized rules, and issues are detected before they propagate. The team can easily expand monitoring as new sources or transformations are added.
Improved Collaboration and Trust
By integrating Soda with Atlan, Group 1001 brought quality visibility into its catalog, allowing data consumers to assess trust levels instantly. Business stakeholders now have greater confidence in the reports and insights they use for decision-making.
For Group 1001, the most important result of this modernization process was that their data became an asset they rely on, not a liability they work around.
Metric | Before Soda | After Soda |
|---|---|---|
Data Quality Checks | Manual, 6am daily | Automated, continuous |
Issue Detection | After business impact | Before propagation |
Analytics Delivery | Months | Few days days |
Migration Risk | High (manual validation) | Low (automated reconciliation) |
Team Capacity | Firefighting focused | Strategic work focused |
Business Confidence | Delayed, unreliable data | Near real-time, trusted data |
Quality Check Authors | Engineers only | Analysts + Engineers |
This transformation was achieved by a 5-person team in under 12 months, demonstrating that the right tooling choices can deliver enterprise-scale impact without enterprise-scale teams.
Building a Culture of Data Trust
Beyond technology, the adoption of Soda helped shift Group 1001’s data culture. Data quality is no longer the exclusive responsibility of engineers, it’s part of how every team works with data. Analysts and engineers alike contribute to defining quality expectations, writing checks, and reviewing results.
Transparency through Soda Cloud dashboards makes quality issues visible to everyone, fostering accountability and continuous improvement.
“Now we're proactive. We know there’s an issue, we inform the teams, we resolve it, and by resolving it, we can also apply another data quality rule to ensure it never happens again. That’s how we get a better handle on our datasets.” — Gu Xie
This collaborative approach has also influenced internal governance. The team now codifies lessons learned into reusable templates, ensuring that quality standards are consistently applied to new projects. Over time, this framework has become a foundation for data trust across the organization.
“The way I see Soda and how it actually helps us transform and the value we get is the fact that we can sleep at night knowing that our processes are running, that we can trust that if everything's finished and the cycle's complete and we can see the data now in our dashboard refreshed, we can trust it.” — Gu Xie
Looking ahead: metadata-driven observability
Group 1001’s next phase focuses on deepening the connection between metadata and quality observability. By linking Soda’s validation metrics with Atlan’s lineage data, the company aims to create an intelligent feedback loop that automatically prioritizes quality improvements based on data usage and business impact.
For Gu Xie, the strategy remains clear: keep the stack modular, interoperable, and focused on enabling people to do more with data.
“Because we're using this catalog to house all data assets, we can now share it across departments, teams, and even different companies. Now we can truly democratize data within the organization.” — Gu Xie
Key Takeaways
Group 1001's journey offers actionable lessons for organizations facing similar challenges:
If you're waking up to check data manually: Start with automation. Don't wait for perfect infrastructure; solve the immediate pain point.
If you have a small team supporting large needs: Best-of-breed tools are your force multiplier.
If you're planning a platform migration: Make data quality your safety net. Automated validation is cheaper than migration failure.
If your organization doesn't trust the data: Start measuring what matters. Not the number of checks, but the reduction in recurring issues.
If you're choosing between build vs. buy: Consider opportunity cost. The weeks spent building data quality infrastructure are weeks not spent delivering business insights. Soda gave Group 1001 enterprise-grade capabilities in days, not months.
Disclaimer: This material was created in 2023. Please note that figures and statistics may have changed, and there might be minor code syntax or UI path differences since its publication. |
|---|
Watch the Interview
Hear more from Gu Xie, Head of Data Engineering at Group 1001, in the Fizz podcast interview: Building a Modern Data Stack
Get in touch
Schedule a demo with the Soda team or request a free account to find out how much you could optimize your data quality strategy across your entire data ecosystem.
Trusted by the world’s leading enterprises
Real stories from companies using Soda to keep their data reliable, accurate, and ready for action.
At the end of the day, we don’t want to be in there managing the checks, updating the checks, adding the checks. We just want to go and observe what’s happening, and that’s what Soda is enabling right now.

Sid Srivastava
Director of Data Governance, Quality and MLOps
Investing in data quality is key for cross-functional teams to make accurate, complete decisions with fewer risks and greater returns, using initiatives such as product thinking, data governance, and self-service platforms.

Mario Konschake
Director of Product-Data Platform
Soda has integrated seamlessly into our technology stack and given us the confidence to find, analyze, implement, and resolve data issues through a simple self-serve capability.

Sutaraj Dutta
Data Engineering Manager
Our goal was to deliver high-quality datasets in near real-time, ensuring dashboards reflect live data as it flows in. But beyond solving technical challenges, we wanted to spark a cultural shift - empowering the entire organization to make decisions grounded in accurate, timely data.

Gu Xie
Head of Data Engineering
4.4 of 5
Your data has problems.
Now they fix themselves.
Automated data quality, remediation, and management.
One platform, agents that do the work, you approve.
Trusted by








Trusted by the world’s leading enterprises
Real stories from companies using Soda to keep their data reliable, accurate, and ready for action.
At the end of the day, we don’t want to be in there managing the checks, updating the checks, adding the checks. We just want to go and observe what’s happening, and that’s what Soda is enabling right now.
Sid Srivastava
Director of Data Governance, Quality and MLOps
Investing in data quality is key for cross-functional teams to make accurate, complete decisions with fewer risks and greater returns, using initiatives such as product thinking, data governance, and self-service platforms.
Mario Konschake
Director of Product-Data Platform
Soda has integrated seamlessly into our technology stack and given us the confidence to find, analyze, implement, and resolve data issues through a simple self-serve capability.
Sutaraj Dutta
Data Engineering Manager
Our goal was to deliver high-quality datasets in near real-time, ensuring dashboards reflect live data as it flows in. But beyond solving technical challenges, we wanted to spark a cultural shift - empowering the entire organization to make decisions grounded in accurate, timely data.
Gu Xie
Head of Data Engineering
4.4 of 5
Your data has problems.
Now they fix themselves.
Automated data quality, remediation, and management.
One platform, agents that do the work, you approve.
Trusted by
Solutions
Trusted by the world’s leading enterprises
Real stories from companies using Soda to keep their data reliable, accurate, and ready for action.
At the end of the day, we don’t want to be in there managing the checks, updating the checks, adding the checks. We just want to go and observe what’s happening, and that’s what Soda is enabling right now.
Sid Srivastava
Director of Data Governance, Quality and MLOps
Investing in data quality is key for cross-functional teams to make accurate, complete decisions with fewer risks and greater returns, using initiatives such as product thinking, data governance, and self-service platforms.
Mario Konschake
Director of Product-Data Platform
Soda has integrated seamlessly into our technology stack and given us the confidence to find, analyze, implement, and resolve data issues through a simple self-serve capability.
Sutaraj Dutta
Data Engineering Manager
Our goal was to deliver high-quality datasets in near real-time, ensuring dashboards reflect live data as it flows in. But beyond solving technical challenges, we wanted to spark a cultural shift - empowering the entire organization to make decisions grounded in accurate, timely data.
Gu Xie
Head of Data Engineering
4.4 of 5
Your data has problems.
Now they fix themselves.
Automated data quality, remediation, and management.
One platform, agents that do the work, you approve.
Trusted by
Solutions