
Organizations are building and operationalizing more and more data products to drive business outcomes. As data and analytics engineers prepare data products, they have two critical requirements:
to monitor the quality of the data being fed into the data products
to deliver reliable transformations and output
Stop Firefighting Data Quality Issues
The schema of a dataset can change over time and these changes can create silent data issues. The data issues are silent because, at best, they result in failed data transformations; at worst, data products keep on working, but on bad data.
So the use case is straightforward: alert me when there is a column change in my dataset.
Many data teams lack the systems or processes to automatically detect changes, anomalies, or problems within the data, and as a result, silent data issues can have a serious downstream impact. As an engineer, it’s unlikely that you will be aware of a column being removed, until the data consumer realizes that the data is missing or wrong and the downstream impact is missed revenue opportunities, for example. The consequence is time and money wasted in firefighting and cleaning up data issues.
This blog was created with previous versions of Soda Cloud, so there might be minor UI path differences. If you have any questions, refer to https://docs.soda.io/ |
|---|
Automated Monitoring: Schema Evolution Monitor
As part of Soda’s automated monitoring features, the Schema Evolution Monitor serves data and analytics engineers whose role it is to test data to ensure its quality.
The Schema Evolution Monitor is an automated, out-of-the-box feature that requires no configuration. When a new dataset is onboarded, Soda Cloud automatically adds a schema monitor with default configuration for the following alert levels:
Column added: Warning
Column type changed: Critical
Column removed: Critical
...and notifications:
Recipient: Dataset Owner
Method: email and default Slack channel, if defined on organization level
The monitor immediately begins detecting schema changes and sending notifications when changes occur.
When columns in a dataset have been added, removed, or changed, Soda Cloud sends notifications which enable you to investigate and get ahead of any silent issues before the data quality has a downstream impact.
Let’s look at an example.
A dataset, ‘CLIENTS’, contains customer data that is monitored for consistency in Soda.
⚠️ In the GIF below, in order to showcase the monitor in action, we’re demonstrating the manual creation of a schema evolution monitor where the user defines the threshold levels for the alerts, and identifies who should be notified and how. Remember that Soda Cloud automatically adds the schema evolution monitor to all of your datasets when they are onboarded.
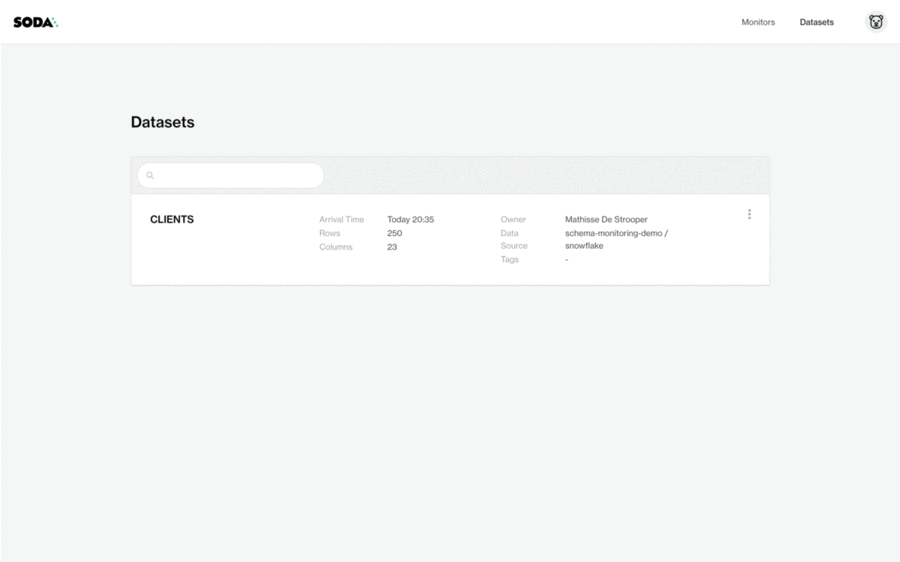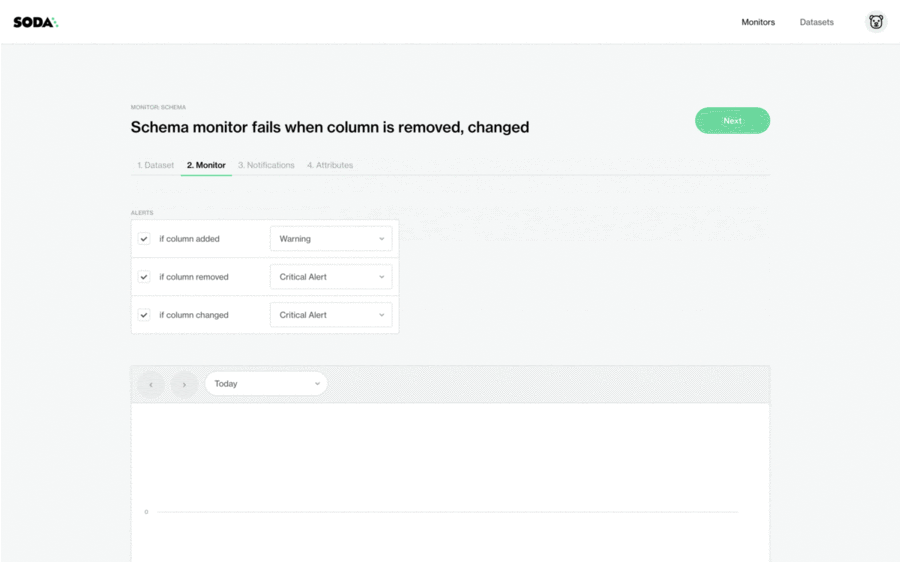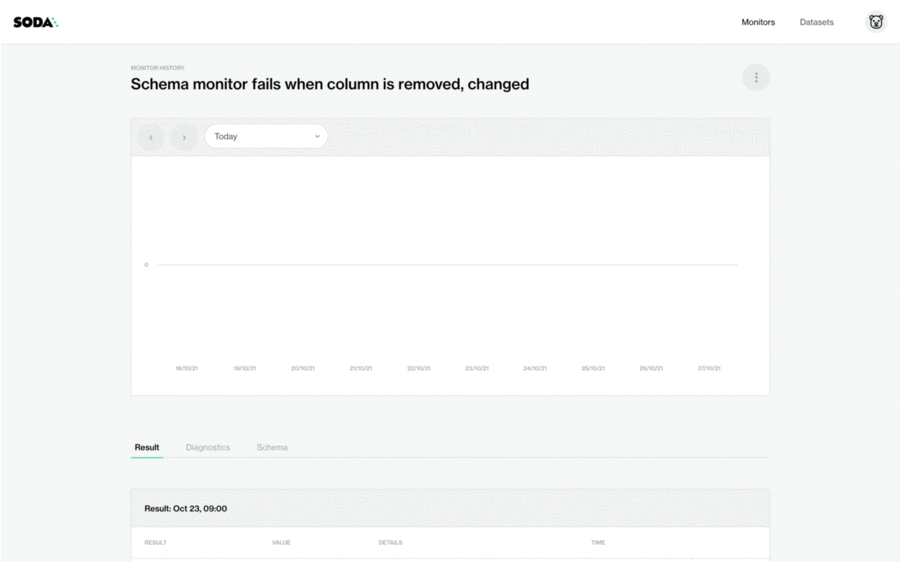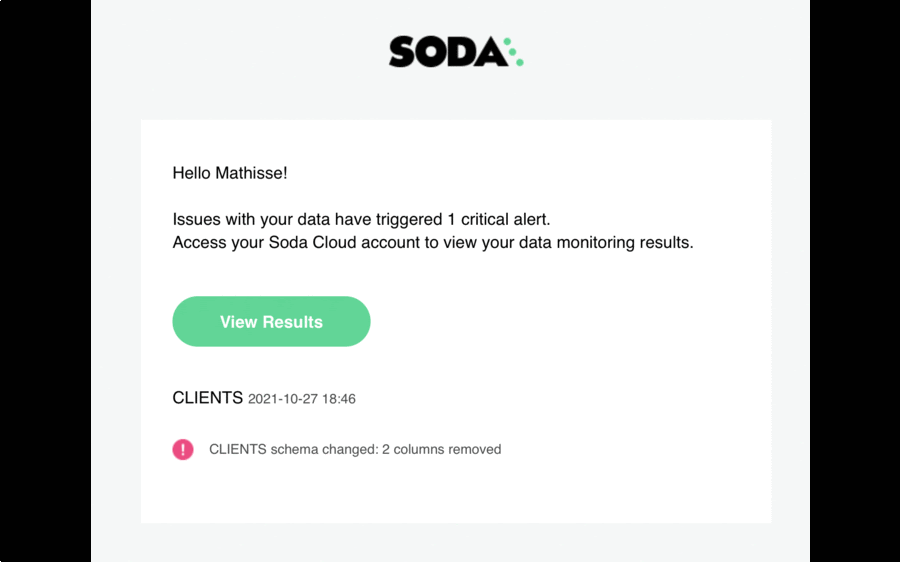
Follow the GIF along and you’ll see that schema changes were detected by the monitor when two columns - ‘FULLNAME’ and ‘REGION’ - were added, and then again, a few days later, when two columns - ‘COUNTRY’ and ‘COUNTRY_CODE’ - were deleted.
Soda Cloud automatically sends an email alert to the right people to notify them that a critical issue has been detected. This ensures that anyone that relies on that dataset is alerted at the right time and can take action to analyze and resolve the issue before there is a downstream impact, such as an impact on reports or Machine Learning models.
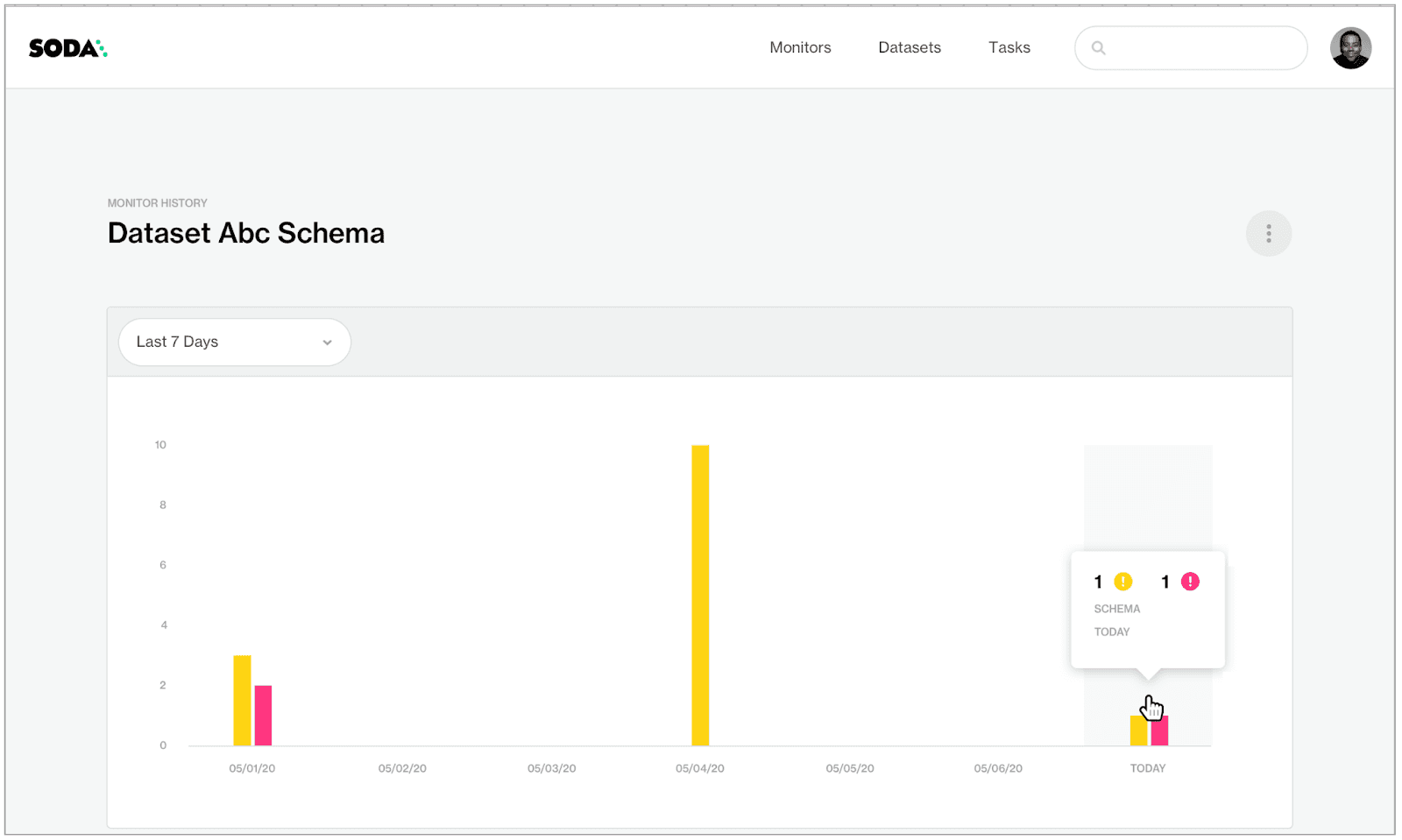
The bar chart stores the historical warnings and critical alerts detected by the Schema Evolution Monitor. By default, Soda Cloud issues warnings when columns are added or changed, and critical alerts when columns are removed.
The schema change history provides an overview of all the types of changes that have occurred over time, allowing you to better understand the data and the requirements of the data consumers. This schema monitor helps achieve decent coverage to check the consistency of the dataset which, ultimately, increases trust in the data products.
What’s Next?
The limitation of monitoring (or what we often refer to as data observability) is that you cannot quarantine bad data. As part of the next release of Soda’s Data Reliability Tools, we’re launching our own language (*really cool name to be announced), which will provide data and analytics engineers with the capability to easily test schemas.
🚀 Yes, you heard it here first. Soda’s “really-cool-to-be-named” language will give users of our open source tools the ability to test schemas at ingestion, or before and after transformations. The language is being built to be included in a data pipeline, so you can stop pipelines and quarantine bad data when you need to. Here comes data reliability.
There’s a Cool New Language Coming to Data Quality
Here’s a sneak peek, because we’re that excited, too! The example below shows the “really-cool-to-be-named” language being applied directly on a dataframe using Soda Spark, or on tables using Soda SQL. Next to required columns, you can specify the order, case sensitivity, and the required data type for each column.

Intrigued? We can’t wait to deliver this game changing capability!
We’d love to hear how the Schema Evolution Monitor works for you and we’re available for any questions or feedback.
Join our Soda Community on Slack to stay up-to-date with the latest Soda releases and let us know what you think!











