
Soda Agreements evolved and now we have Soda Data Contracts. Read more about it here: Soda Releases OSS Data Contract Engine
Just before the European summer break, we introduced the next milestone for Soda in preview mode. We released a new set of features and capabilities that we think will bring Soda Cloud - and data quality management - to the next level. And today, we’re making those features and capabilities generally available.
Data Quality Isn’t Easy
At Soda we recognize that there is a critical business need to unite data producers and data consumers in the quest for high-quality, reliable data. We have always said that “data quality is a team sport” and we’ve been working on ensuring that Soda Cloud can enable data domain teams to work together, with the right accountability and responsibility to produce, share, and use data.
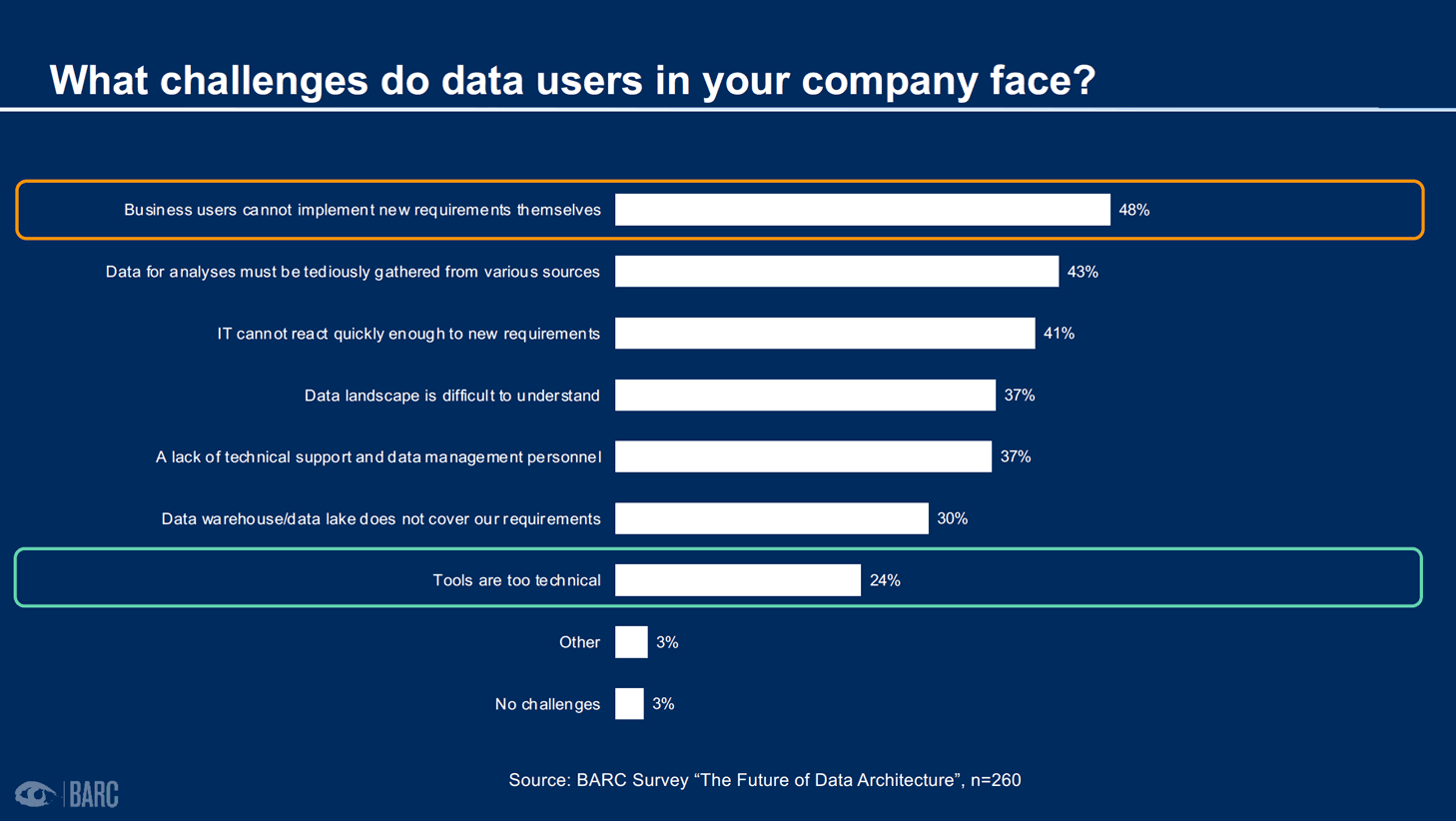
However, the common challenges faced by data consumers today, as noted in the BARC Survey, “The Future of Data Architecture”, are that tools are too technical, business users cannot implement new requirements themselves, and IT (or engineering) cannot react quickly enough to new requirements.
You Can Code With Us
For so long, data quality has been a mandate addressed by a group of people with a niche set of skills; as such, many existing tools have been built for a niche technical audience. Writing SQL queries and baking them into data pipelines or other ETL tools or systems, has meant that it has been impossible to scale data quality across the organization with only a few teams bearing the burden of maintaining data quality and often struggling without the time, knowledge, or understanding of the data, or proper tools that they need.
These barriers to access - not knowing SQL, not knowing how to write code, not having access to data sources or data pipelines, not having the right tools - just stagnated any effort or motivation to establish and maintain trust in the data that teams were working on. The barriers also created bottlenecks that are crippling for a business and that’s why we knew it made sense to build for the data producers and consumers, and change how they get access to data.
We were very thoughtful about how to do that and took a complete departure from the old ways. In June of this year, we released Soda Core, our open-source tool for data engineers, with SodaCL (Soda Checks Language) a new Domain-Specific Language for writing data quality checks.

SodaCL is a human-readable, low-code, YAML-based Domain-Specific Language for writing data quality checks. It was a huge - and important - leap forward towards democratizing data quality management for the right people: making it accessible, easy to work with, irrespective of technical know-how, and being confident to use the data to make business decisions.
And that leap brings us to the present day, with our next milestone as we make the newest set of features generally available. It’s the Self-Serve Release.
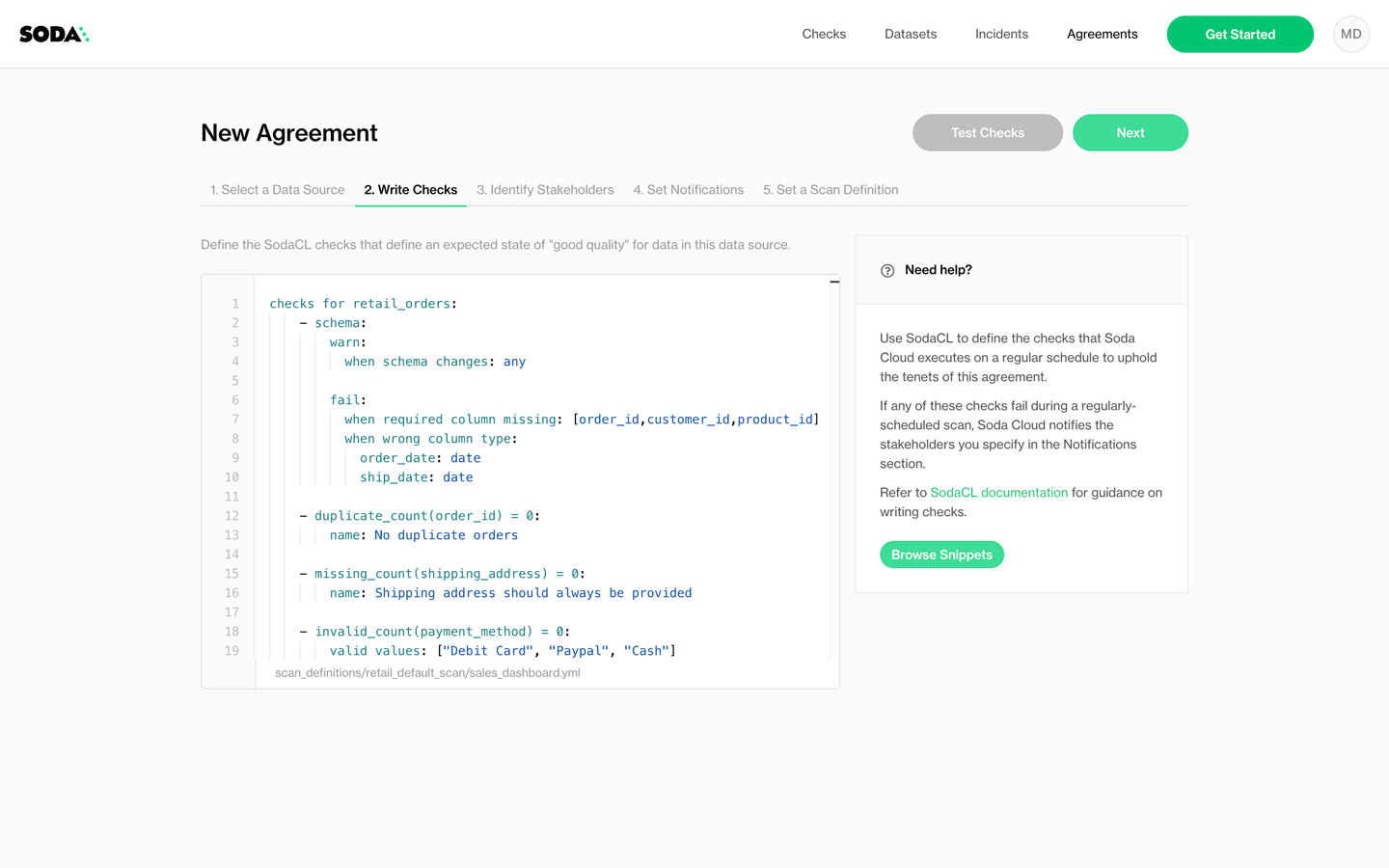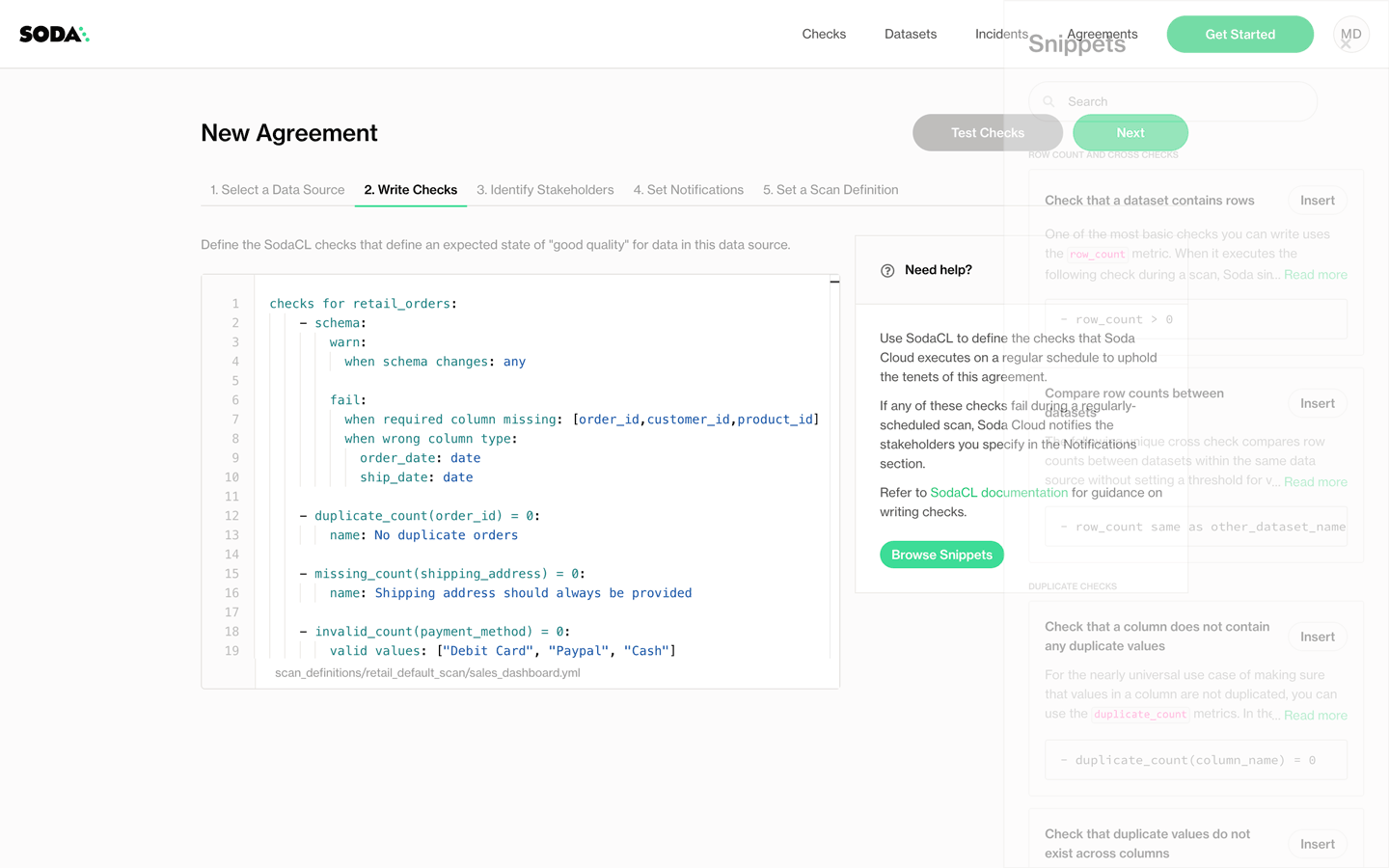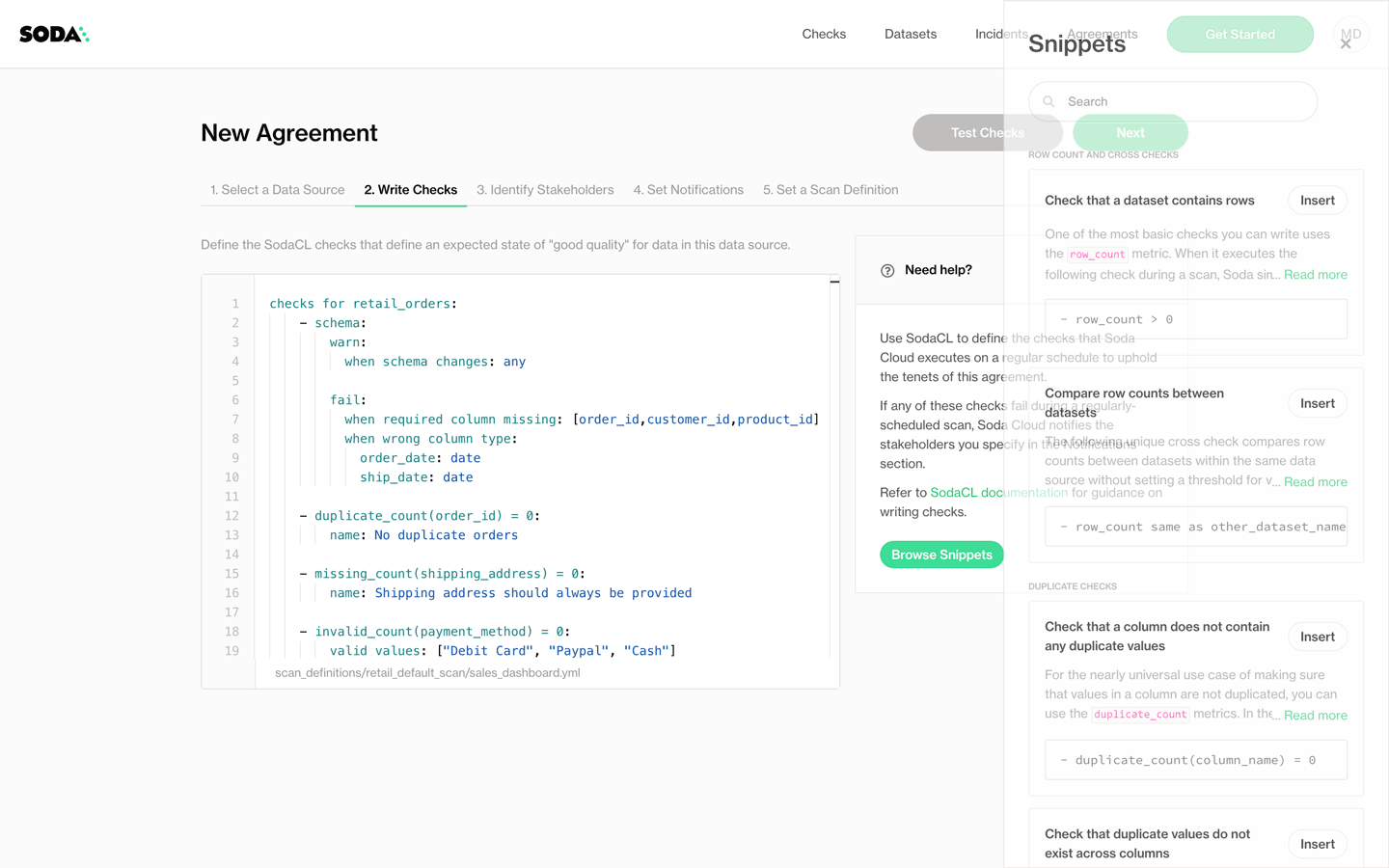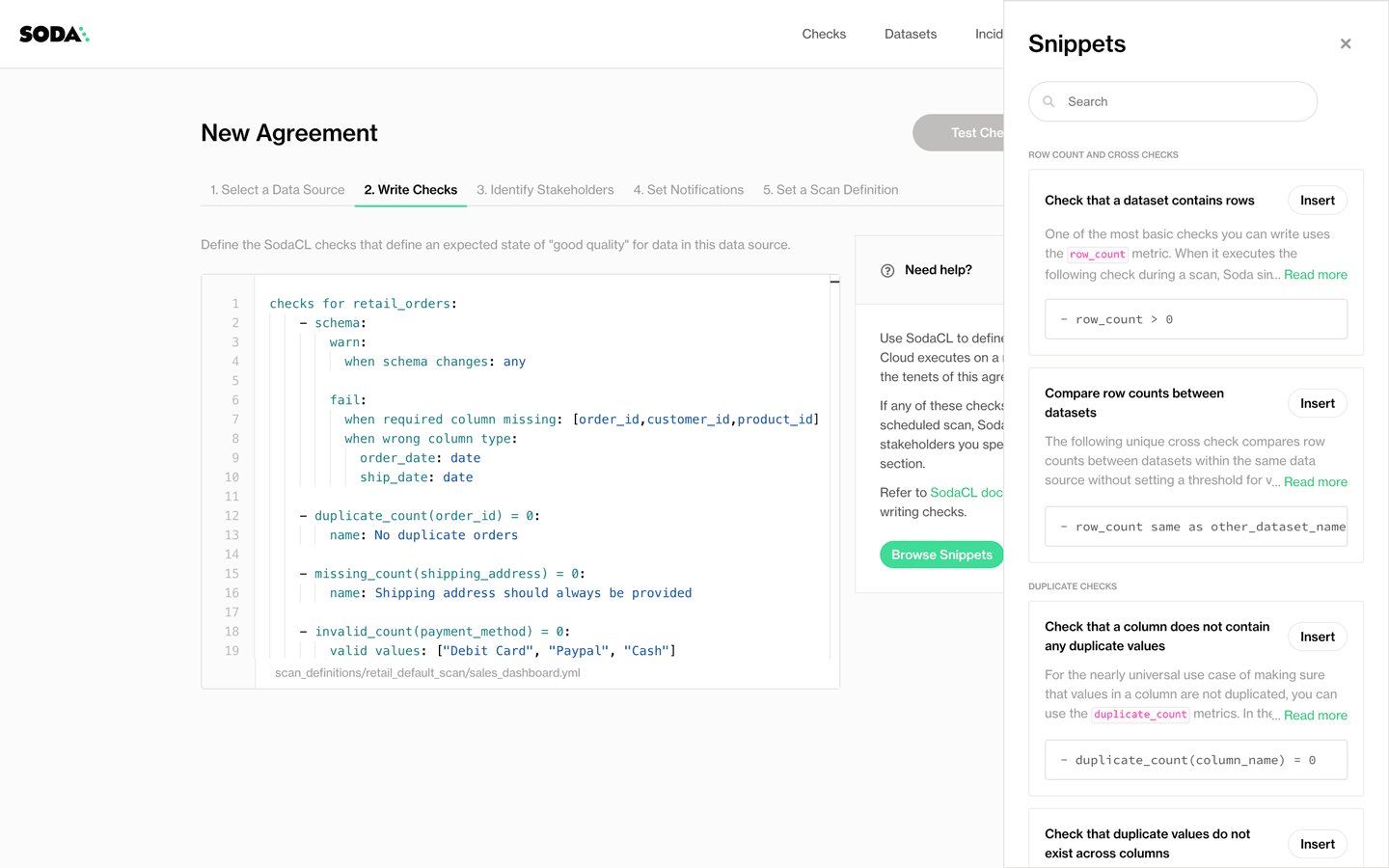
With these data quality agreements, data consumers become first-class citizens in the necessarily decentralized task of data quality management.
These users are at last empowered to connect to the data sources, to discover their data and think about what constitutes “good quality”. They are empowered to take action themselves, take the initiative to make sure that the data they care about the most, the data they use to make decisions and feed reports and populate dashboards meets their own standards for reliability, and bakes their trust into the data.
Soda Agreements as a tool, however, is far from being a stand-alone feature. To empower people to participate in data quality management, we have to also give them access to the data. This requirement opened the door into a whole host of supporting features, without which writing agreements wouldn’t be possible.
Soda Cloud users needed a way to connect to new data sources, such as Snowflake or MS SQL Server, from within the UI, so we built a step-by-step guided workflow to establish these connections. It’s baseline accessibility.
To securely access these new data sources from within the Soda Cloud UI, we needed to empower users to deploy a Soda Agent in their own cloud services provider, such as AWS. It is via the agent that any Soda Cloud user (with permission) can get access to the data they want to check.
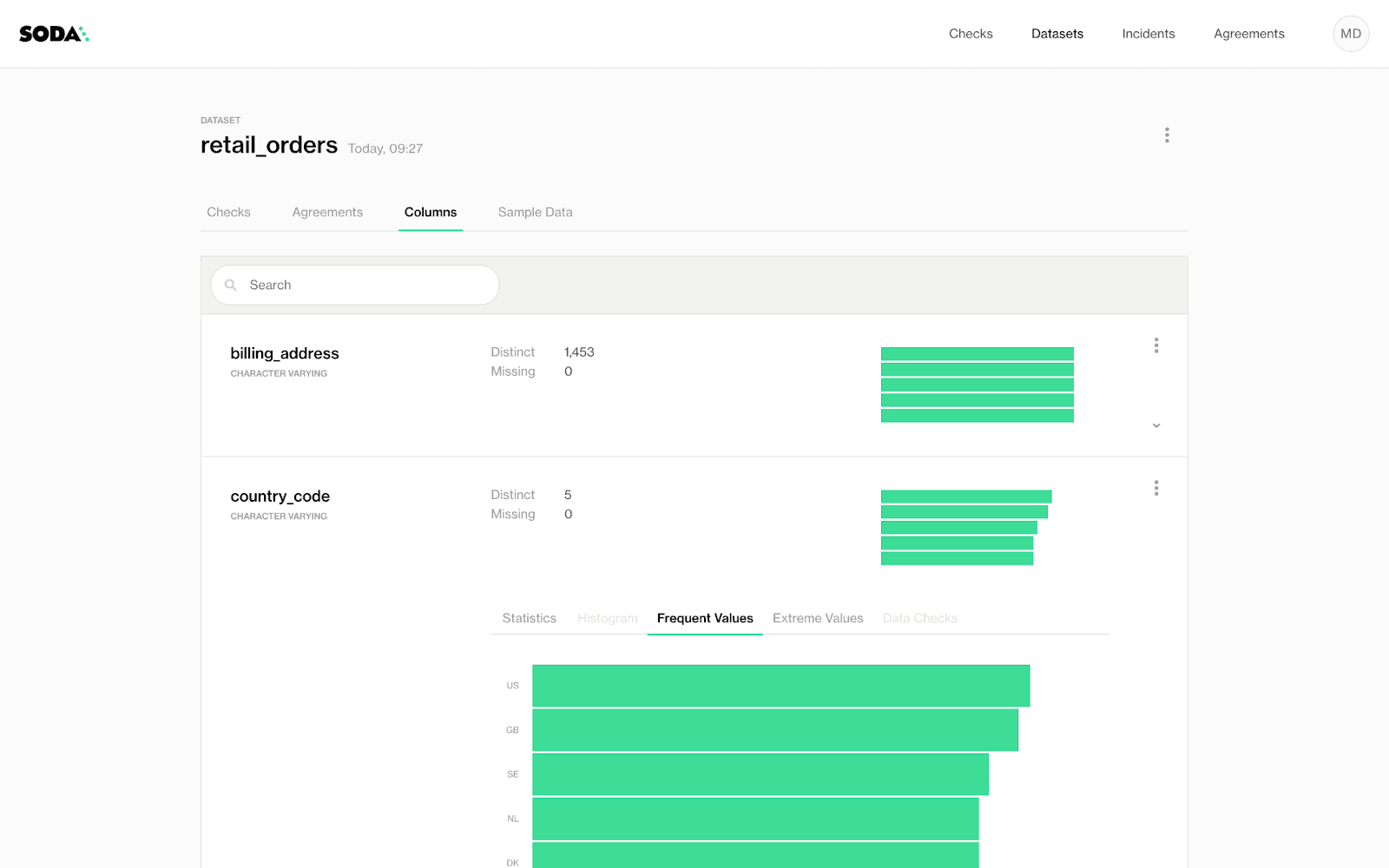
Establishing connections to access data is, of course, crucial, but equally as crucial is the ability to see what is in there. Which datasets are we working with? What data do they contain, what are the column names? How does one know what to check for if the data is in a black box
Automated dataset discovery, column profiling, and data sampling give all users the ability to get close enough to their data to start writing rules about its quality. (To comply with any internal security rules, you can arrange to store failed row samples in your own environment.)
Once proposed and approved by stakeholders, Soda Cloud has to actually run scans on data sources to execute the data quality checks that form agreements. Thus, we introduced scan definitions, a way of defining when and where Soda Cloud runs its scans.
Finally, as a first helpful step towards establishing good data quality, users can choose to automatically set up and start running automated monitoring checks for data anomalies and schema changes. Before writing an agreement, before even knowing what kind of data is rattling around inside a data source, a user can begin capturing data quality metadata right out of the box, no insider knowledge required.
It’s Getting Better All The Time
Trust me when I say, these new features are game-changers - and we’re hearing that from our community. Our eager cohort of early adopters with preview access to Soda Agreements and everything that comes with it, have resoundingly validated everything that we felt certain would be true about self-serve democratizing and decentralizing data quality.
“...we think that it will help us democratize the solution to other teams that have interest in implementing data quality checks but don't have the knowledge to use solutions for scheduling jobs, orchestration workflow, etc.
…this feature [...] looks to be quite accessible for our business analyst users…
Definitely excited about the Agreements feature – we would want to see closer collaboration between engineers and analysts via that capability…”
It’s Time to Unite!
Our customers, partners, and community members registered with a Soda Cloud account now have access to the Self-Serve release and the new features and capabilities.
This video offers a great introduction and overview of the new features, how to access them, how to get your colleagues on board and convince them to become stakeholders in data quality agreements.
You can check out the Quick start guide for Soda Cloud, which includes guidance on how to set up and start working with the newest self-serve features.
Our docs have detailed instructions and how-to’s for setting up and using the Soda Agent, adding new data sources, creating agreements, and of course, tips and best practices for writing data quality checks with SodaCL.
I’ll be hosting a webinar on Tuesday 8 November at 11am Eastern / 5pm Central Europe, walking through the new Self-Serve release. You can watch it here.
Coming soon, we’re expanding Soda Core, our open-source tool, to support Kafka Streaming and we’ll also be expanding Soda Core’s YAML files to become data contracts. Two capabilities that will help propel a lot of organizations further on their journey to good data quality.
The entire team and I are excited by the possibilities that self-serve offers, and the upcoming developments. Stay connected and keep in touch with what we’re working on. Join our Soda Community on Slack.











