Platform Automation
Platform Automation
Data Contract Template
Data Contract Template
Ensure data from platform automation metadata is fresh, complete, and reliable before it is used for ingestion governance, pipeline orchestration, destination routing, and platform-level operational oversight.

Minseo (Len) Park
Former Growth at Soda
Data contract description
This data contract is designed for MatHem, where declarative data contracts are used to automate how source systems are connected to the company’s unified data platform and how those assets are routed into medallion-style BigQuery layers for downstream use. In this use case, platform_automation serves as governed metadata for the automation layer by describing the owning squad, the origin service repository, the source pattern (cdc, event, file, api_pull, or db_query), the ingest mode, and the target bq_project_layer, bq_dataset, and bq_table, helping MatHem standardize how ingestion and transformation workflows are defined, reviewed, and executed across its platform.
platform_automation_data_contract.yaml
datasetvariables: CONTRACT_NAME: default: "datahem_platform_automation" DOMAIN_SQUAD: default: "Data Engineering Team" ORIGIN_SERVICE_REPO: default: "https://github.com/mathem/origin-service" BUSINESS_DESCRIPTION: default: "Handles data lifecycle automation and transformation for real-time data ingestion and processing." SCHEMA_VERSION: default: "1.0" checks: - schema: allow_extra_columns: false allow_other_column_order: false - row_count: threshold: must_be_greater_than: 0 - freshness: column: processed_at threshold: unit: hour must_be_less_than: 12
columns: - name: contract_name data_type: string checks: - missing: - duplicate: - invalid: name: "Contract Name length guardrail" valid_min_length: 1 valid_max_length: 128 - name: domain_squad data_type: string checks: - missing: - invalid: name: "Domain Squad name guardrail" valid_min_length: 1 valid_max_length: 64 - name: origin_service_repo data_type: string checks: - missing: - invalid: name: "Origin Service Repo URL" valid_min_length: 5 valid_max_length: 255 - name: business_description data_type: string checks: - missing: - invalid: name: "Business Description length guardrail" valid_min_length: 10 valid_max_length: 255 - name: schema_version data_type: string checks: - missing: - invalid: name: "Schema Version format" valid_format: name: Version pattern regex: '^[0-9]+\.[0-9]+$' - name: source_type data_type: string checks: - missing: - invalid: name: "Valid Source Type" valid_values: - cdc - event - file - api_pull - db_query - name: source_ref data_type: string checks: - missing: - invalid: name: "Source Reference length guardrail" valid_min_length: 1 valid_max_length: 128 - name: ingest_mode data_type: string checks: - missing: - invalid: name: "Valid Ingest Mode" valid_values: - streaming - microbatch - name: bq_project_layer data_type: string checks: - missing: - invalid: name: "Valid BQ Project Layer" valid_values: - bronze - silver - gold - experimental - name: bq_dataset data_type: string checks: - missing: - invalid: name: "BQ Dataset name guardrail" valid_min_length: 1 valid_max_length: 64 - name: bq_table data_type: string checks: - missing: - invalid: name: "BQ Table name guardrail" valid_min_length: 1 valid_max_length: 128
Data contract description
This data contract is designed for MatHem, where declarative data contracts are used to automate how source systems are connected to the company’s unified data platform and how those assets are routed into medallion-style BigQuery layers for downstream use. In this use case, platform_automation serves as governed metadata for the automation layer by describing the owning squad, the origin service repository, the source pattern (cdc, event, file, api_pull, or db_query), the ingest mode, and the target bq_project_layer, bq_dataset, and bq_table, helping MatHem standardize how ingestion and transformation workflows are defined, reviewed, and executed across its platform.
platform_automation_data_contract.yaml
datasetvariables: CONTRACT_NAME: default: "datahem_platform_automation" DOMAIN_SQUAD: default: "Data Engineering Team" ORIGIN_SERVICE_REPO: default: "https://github.com/mathem/origin-service" BUSINESS_DESCRIPTION: default: "Handles data lifecycle automation and transformation for real-time data ingestion and processing." SCHEMA_VERSION: default: "1.0" checks: - schema: allow_extra_columns: false allow_other_column_order: false - row_count: threshold: must_be_greater_than: 0 - freshness: column: processed_at threshold: unit: hour must_be_less_than: 12
columns: - name: contract_name data_type: string checks: - missing: - duplicate: - invalid: name: "Contract Name length guardrail" valid_min_length: 1 valid_max_length: 128 - name: domain_squad data_type: string checks: - missing: - invalid: name: "Domain Squad name guardrail" valid_min_length: 1 valid_max_length: 64 - name: origin_service_repo data_type: string checks: - missing: - invalid: name: "Origin Service Repo URL" valid_min_length: 5 valid_max_length: 255 - name: business_description data_type: string checks: - missing: - invalid: name: "Business Description length guardrail" valid_min_length: 10 valid_max_length: 255 - name: schema_version data_type: string checks: - missing: - invalid: name: "Schema Version format" valid_format: name: Version pattern regex: '^[0-9]+\.[0-9]+$' - name: source_type data_type: string checks: - missing: - invalid: name: "Valid Source Type" valid_values: - cdc - event - file - api_pull - db_query - name: source_ref data_type: string checks: - missing: - invalid: name: "Source Reference length guardrail" valid_min_length: 1 valid_max_length: 128 - name: ingest_mode data_type: string checks: - missing: - invalid: name: "Valid Ingest Mode" valid_values: - streaming - microbatch - name: bq_project_layer data_type: string checks: - missing: - invalid: name: "Valid BQ Project Layer" valid_values: - bronze - silver - gold - experimental - name: bq_dataset data_type: string checks: - missing: - invalid: name: "BQ Dataset name guardrail" valid_min_length: 1 valid_max_length: 64 - name: bq_table data_type: string checks: - missing: - invalid: name: "BQ Table name guardrail" valid_min_length: 1 valid_max_length: 128
Data contract description
This data contract is designed for MatHem, where declarative data contracts are used to automate how source systems are connected to the company’s unified data platform and how those assets are routed into medallion-style BigQuery layers for downstream use. In this use case, platform_automation serves as governed metadata for the automation layer by describing the owning squad, the origin service repository, the source pattern (cdc, event, file, api_pull, or db_query), the ingest mode, and the target bq_project_layer, bq_dataset, and bq_table, helping MatHem standardize how ingestion and transformation workflows are defined, reviewed, and executed across its platform.
platform_automation_data_contract.yaml
datasetvariables: CONTRACT_NAME: default: "datahem_platform_automation" DOMAIN_SQUAD: default: "Data Engineering Team" ORIGIN_SERVICE_REPO: default: "https://github.com/mathem/origin-service" BUSINESS_DESCRIPTION: default: "Handles data lifecycle automation and transformation for real-time data ingestion and processing." SCHEMA_VERSION: default: "1.0" checks: - schema: allow_extra_columns: false allow_other_column_order: false - row_count: threshold: must_be_greater_than: 0 - freshness: column: processed_at threshold: unit: hour must_be_less_than: 12
columns: - name: contract_name data_type: string checks: - missing: - duplicate: - invalid: name: "Contract Name length guardrail" valid_min_length: 1 valid_max_length: 128 - name: domain_squad data_type: string checks: - missing: - invalid: name: "Domain Squad name guardrail" valid_min_length: 1 valid_max_length: 64 - name: origin_service_repo data_type: string checks: - missing: - invalid: name: "Origin Service Repo URL" valid_min_length: 5 valid_max_length: 255 - name: business_description data_type: string checks: - missing: - invalid: name: "Business Description length guardrail" valid_min_length: 10 valid_max_length: 255 - name: schema_version data_type: string checks: - missing: - invalid: name: "Schema Version format" valid_format: name: Version pattern regex: '^[0-9]+\.[0-9]+$' - name: source_type data_type: string checks: - missing: - invalid: name: "Valid Source Type" valid_values: - cdc - event - file - api_pull - db_query - name: source_ref data_type: string checks: - missing: - invalid: name: "Source Reference length guardrail" valid_min_length: 1 valid_max_length: 128 - name: ingest_mode data_type: string checks: - missing: - invalid: name: "Valid Ingest Mode" valid_values: - streaming - microbatch - name: bq_project_layer data_type: string checks: - missing: - invalid: name: "Valid BQ Project Layer" valid_values: - bronze - silver - gold - experimental - name: bq_dataset data_type: string checks: - missing: - invalid: name: "BQ Dataset name guardrail" valid_min_length: 1 valid_max_length: 64 - name: bq_table data_type: string checks: - missing: - invalid: name: "BQ Table name guardrail" valid_min_length: 1 valid_max_length: 128
How to Enforce Data Contracts with Soda
Embed data quality through data contracts at any point in your pipeline.
Embed data quality through data contracts at any point in your pipeline.
# pip install soda-{data source} for other data sources
# pip install soda-{data source} for other data sources
pip install soda-postgres
pip install soda-postgres
# verify the contract locally against a data source
# verify the contract locally against a data source
soda contract verify -c contract.yml -ds ds_config.yml
soda contract verify -c contract.yml -ds ds_config.yml
# publish and schedule the contract with Soda Cloud
# publish and schedule the contract with Soda Cloud
soda contract publish -c contract.yml -sc sc_config.yml
soda contract publish -c contract.yml -sc sc_config.yml
Check out the CLI documentation to learn more.
Check out the CLI documentation to learn more.
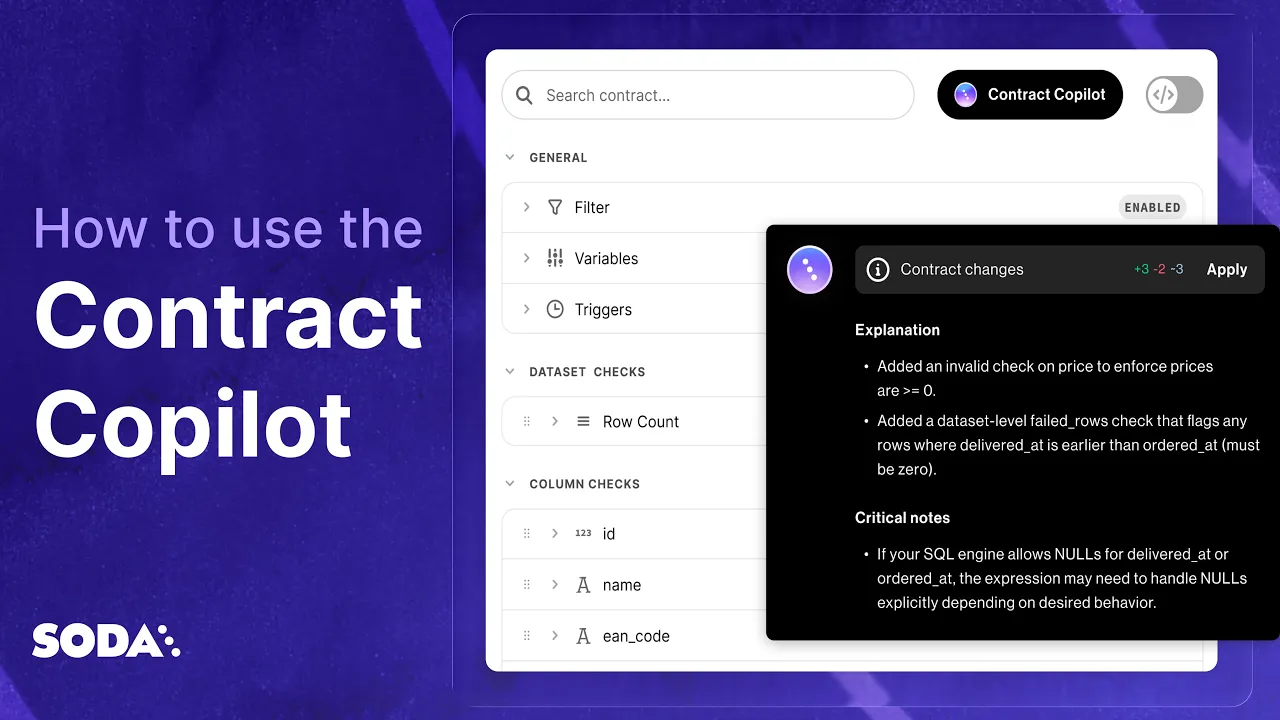
How to Automatically Create Data Contracts.
In one Click.
Automatically write and publish data contracts using Soda's AI-powered data contract copilot.
Make data contracts work in production
Business knows what good data looks like. Engineering knows how to deliver it at scale. Soda unites both, turning governance expectations into executable contracts.
Explore more data contract templates
One new data contract template every day, across industries and use cases










4.4 of 5
Your data has problems.
Now they fix themselves.
Automated data quality, remediation, and management.
One platform, agents that do the work, you approve.
Trusted by








4.4 of 5
Your data has problems.
Now they fix themselves.
Automated data quality, remediation, and management.
One platform, agents that do the work, you approve.
Trusted by
Solutions
4.4 of 5
Your data has problems.
Now they fix themselves.
Automated data quality, remediation, and management.
One platform, agents that do the work, you approve.
Trusted by
Solutions