What Breaks When AI Agents Can't See Data Quality
What Breaks When AI Agents Can't See Data Quality
What Breaks When AI Agents Can't See Data Quality

Maarten Masschelein
Maarten Masschelein
CEO and Founder at Soda
CEO and Founder at Soda
Table of Contents
AI agents don't fail the way software usually fails. There's no stack trace, no error code, no red alert in the monitoring dashboard. When an AI agent consumes bad data, it does something far worse than crash — it keeps running. It produces a forecast, a recommendation, an automated action, with exactly the same confidence as if the data were perfect.
That's the problem we don't talk about enough.
In McKinsey's State of AI 2025 survey, nearly a third of all respondents report negative consequences stemming specifically from AI inaccuracy. And in LangChain's State of Agent Engineering 2025 survey, 32.9% of the respondents cite quality of outputs as their top barrier to putting agents in production. These aren't theoretical risks. They're what's already happening in production at enterprise scale.
What "Confident but Wrong" Actually Looks Like
Let me describe three scenarios I hear about constantly in conversations with data leaders.
Stale data, live decisions. An AI agent pulls from a table that hasn't been refreshed in 18 hours. It doesn't check. It doesn't know the data is stale. It produces a demand forecast based on yesterday's reality and routes it to an automated procurement workflow. Nobody catches it until the PO is already placed.
Schema drift, silent breakage. A column gets renamed upstream — revenue_usd becomes total_revenue. The agent still runs. It's now operating on the wrong field, producing outputs that look structurally plausible but are mathematically wrong. The dashboard that consumed the output looked fine. The decision it informed wasn't.
Anomalous data, no guardrail. A spike in null values after a failed ETL job. A sudden distribution shift in transaction data. A duplicate load that doubled the volume. All invisible to the AI agent. All things a human analyst might catch by glancing at a chart and thinking "that doesn't look right." AI agents don't glance. They act.
This is the everyday reality of production data pipelines. The critical difference is this: when a human encounters suspect data, they hesitate. They investigate. An AI agent encounters the same data and accelerates through it.
Why Data Observability Belongs Inside the Context Layer
There's a growing consensus — and Atlan has been articulating this clearly — that AI agents need an enterprise context layer to function responsibly. Not just access to data, but access to context about data: lineage, governance policies, business definitions, and quality signals.
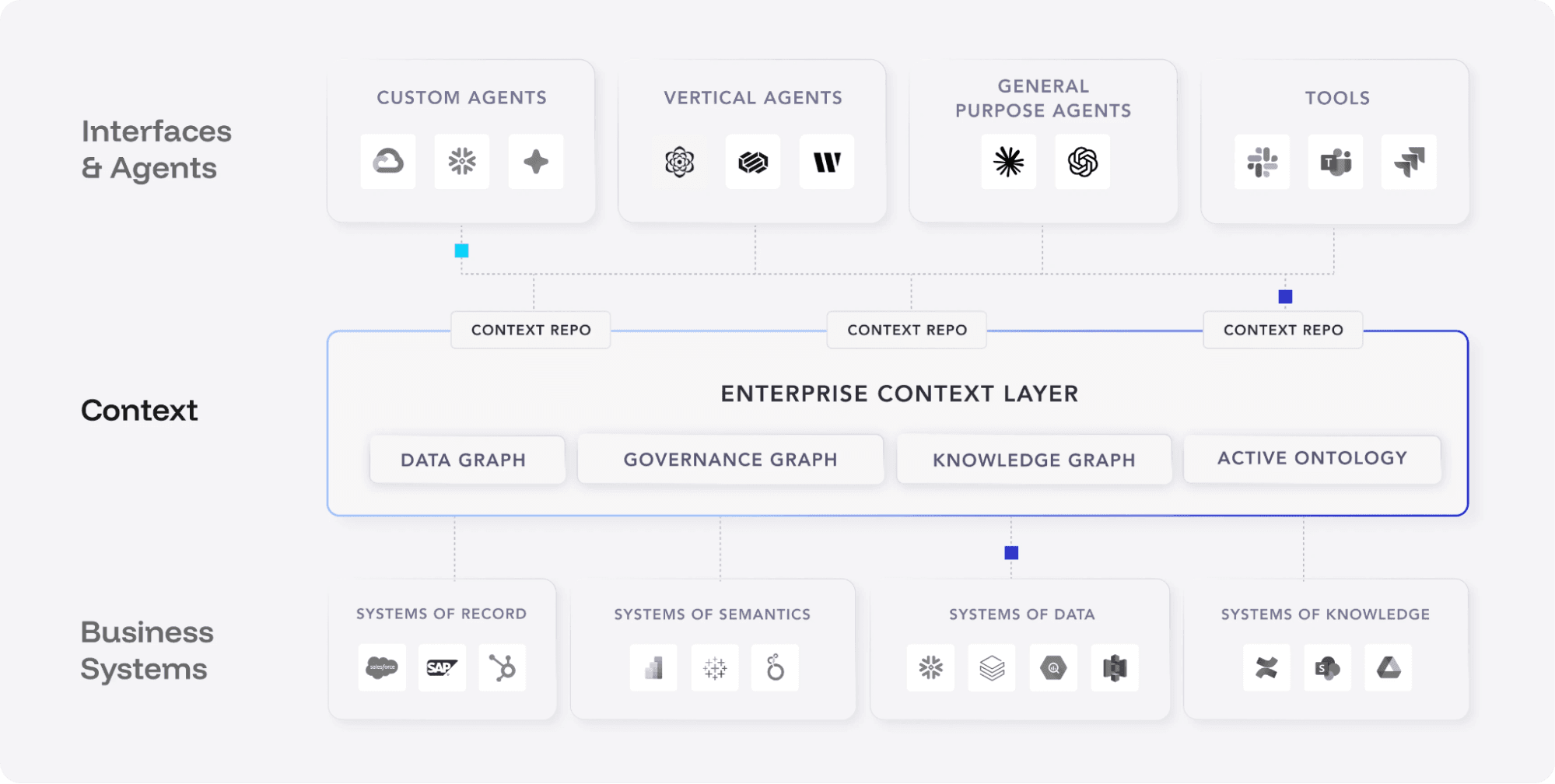
↗ Atlan's Enterprise Context Layer architecture: AI agents and tools at the top consume context from the Data Graph, Governance Graph, Knowledge Graph, and Active Ontology, which in turn draw from business systems below.
Here's the thing: without data quality signals flowing into that context layer, an agent can know where data came from, who governs it, and what it's called — but not whether it's fit for use right now. Lineage tells you the path. Governance tells you the policy. Data observability tells you the truth about the data's current state: Is it fresh? Is the schema intact? Are the values within expected ranges? Has the volume changed unexpectedly?
These are continuous, real-time signals. Not a one-time profile run. AI-native anomaly detection that adapts to each dataset's baseline and flags deviations the moment they appear — before an agent acts on them. At Soda, this is what our data observability platform delivers: quality signals at the speed AI workloads demand, with 70% fewer false positives than threshold-based approaches.
The Question Every AI Leader Should Be Asking
Before your next AI agent goes live — or the next time one of your current agents makes an automated decision — ask this: Does it know whether the data it's consuming is trustworthy right now?
If the answer is no, the agent is operating blind. And the organization is accepting risk it can't see.
The companies that will get enterprise AI right over the next two years won't be the ones with the most sophisticated models. They'll be the ones that built the infrastructure to tell their models when not to act — or when to flag uncertainty rather than produce a confident answer. Data observability is that signal layer — the piece that tells the context layer when data is and isn't fit for use.
If you're interested in how this infrastructure is being built across the industry, Atlan Activate is bringing together data leaders from 80+ other enterprises to explore exactly this: what the enterprise context layer looks like in practice, and what's required to make AI agents production-ready.
The most dangerous AI output isn't the one that's obviously wrong. It's the one that looks exactly right.
AI agents don't fail the way software usually fails. There's no stack trace, no error code, no red alert in the monitoring dashboard. When an AI agent consumes bad data, it does something far worse than crash — it keeps running. It produces a forecast, a recommendation, an automated action, with exactly the same confidence as if the data were perfect.
That's the problem we don't talk about enough.
In McKinsey's State of AI 2025 survey, nearly a third of all respondents report negative consequences stemming specifically from AI inaccuracy. And in LangChain's State of Agent Engineering 2025 survey, 32.9% of the respondents cite quality of outputs as their top barrier to putting agents in production. These aren't theoretical risks. They're what's already happening in production at enterprise scale.
What "Confident but Wrong" Actually Looks Like
Let me describe three scenarios I hear about constantly in conversations with data leaders.
Stale data, live decisions. An AI agent pulls from a table that hasn't been refreshed in 18 hours. It doesn't check. It doesn't know the data is stale. It produces a demand forecast based on yesterday's reality and routes it to an automated procurement workflow. Nobody catches it until the PO is already placed.
Schema drift, silent breakage. A column gets renamed upstream — revenue_usd becomes total_revenue. The agent still runs. It's now operating on the wrong field, producing outputs that look structurally plausible but are mathematically wrong. The dashboard that consumed the output looked fine. The decision it informed wasn't.
Anomalous data, no guardrail. A spike in null values after a failed ETL job. A sudden distribution shift in transaction data. A duplicate load that doubled the volume. All invisible to the AI agent. All things a human analyst might catch by glancing at a chart and thinking "that doesn't look right." AI agents don't glance. They act.
This is the everyday reality of production data pipelines. The critical difference is this: when a human encounters suspect data, they hesitate. They investigate. An AI agent encounters the same data and accelerates through it.
Why Data Observability Belongs Inside the Context Layer
There's a growing consensus — and Atlan has been articulating this clearly — that AI agents need an enterprise context layer to function responsibly. Not just access to data, but access to context about data: lineage, governance policies, business definitions, and quality signals.
↗ Atlan's Enterprise Context Layer architecture: AI agents and tools at the top consume context from the Data Graph, Governance Graph, Knowledge Graph, and Active Ontology, which in turn draw from business systems below.
Here's the thing: without data quality signals flowing into that context layer, an agent can know where data came from, who governs it, and what it's called — but not whether it's fit for use right now. Lineage tells you the path. Governance tells you the policy. Data observability tells you the truth about the data's current state: Is it fresh? Is the schema intact? Are the values within expected ranges? Has the volume changed unexpectedly?
These are continuous, real-time signals. Not a one-time profile run. AI-native anomaly detection that adapts to each dataset's baseline and flags deviations the moment they appear — before an agent acts on them. At Soda, this is what our data observability platform delivers: quality signals at the speed AI workloads demand, with 70% fewer false positives than threshold-based approaches.
The Question Every AI Leader Should Be Asking
Before your next AI agent goes live — or the next time one of your current agents makes an automated decision — ask this: Does it know whether the data it's consuming is trustworthy right now?
If the answer is no, the agent is operating blind. And the organization is accepting risk it can't see.
The companies that will get enterprise AI right over the next two years won't be the ones with the most sophisticated models. They'll be the ones that built the infrastructure to tell their models when not to act — or when to flag uncertainty rather than produce a confident answer. Data observability is that signal layer — the piece that tells the context layer when data is and isn't fit for use.
If you're interested in how this infrastructure is being built across the industry, Atlan Activate is bringing together data leaders from 80+ other enterprises to explore exactly this: what the enterprise context layer looks like in practice, and what's required to make AI agents production-ready.
The most dangerous AI output isn't the one that's obviously wrong. It's the one that looks exactly right.
Trusted by the world’s leading enterprises
Real stories from companies using Soda to keep their data reliable, accurate, and ready for action.
At the end of the day, we don’t want to be in there managing the checks, updating the checks, adding the checks. We just want to go and observe what’s happening, and that’s what Soda is enabling right now.

Sid Srivastava
Director of Data Governance, Quality and MLOps
Investing in data quality is key for cross-functional teams to make accurate, complete decisions with fewer risks and greater returns, using initiatives such as product thinking, data governance, and self-service platforms.

Mario Konschake
Director of Product-Data Platform
Soda has integrated seamlessly into our technology stack and given us the confidence to find, analyze, implement, and resolve data issues through a simple self-serve capability.

Sutaraj Dutta
Data Engineering Manager
Our goal was to deliver high-quality datasets in near real-time, ensuring dashboards reflect live data as it flows in. But beyond solving technical challenges, we wanted to spark a cultural shift - empowering the entire organization to make decisions grounded in accurate, timely data.

Gu Xie
Head of Data Engineering
4.4 of 5
Your data has problems.
Now they fix themselves.
Automated data quality, remediation, and management.
One platform, agents that do the work, you approve.
Trusted by








Trusted by the world’s leading enterprises
Real stories from companies using Soda to keep their data reliable, accurate, and ready for action.
At the end of the day, we don’t want to be in there managing the checks, updating the checks, adding the checks. We just want to go and observe what’s happening, and that’s what Soda is enabling right now.
Sid Srivastava
Director of Data Governance, Quality and MLOps
Investing in data quality is key for cross-functional teams to make accurate, complete decisions with fewer risks and greater returns, using initiatives such as product thinking, data governance, and self-service platforms.
Mario Konschake
Director of Product-Data Platform
Soda has integrated seamlessly into our technology stack and given us the confidence to find, analyze, implement, and resolve data issues through a simple self-serve capability.
Sutaraj Dutta
Data Engineering Manager
Our goal was to deliver high-quality datasets in near real-time, ensuring dashboards reflect live data as it flows in. But beyond solving technical challenges, we wanted to spark a cultural shift - empowering the entire organization to make decisions grounded in accurate, timely data.
Gu Xie
Head of Data Engineering
4.4 of 5
Your data has problems.
Now they fix themselves.
Automated data quality, remediation, and management.
One platform, agents that do the work, you approve.
Trusted by
Solutions
Trusted by the world’s leading enterprises
Real stories from companies using Soda to keep their data reliable, accurate, and ready for action.
At the end of the day, we don’t want to be in there managing the checks, updating the checks, adding the checks. We just want to go and observe what’s happening, and that’s what Soda is enabling right now.
Sid Srivastava
Director of Data Governance, Quality and MLOps
Investing in data quality is key for cross-functional teams to make accurate, complete decisions with fewer risks and greater returns, using initiatives such as product thinking, data governance, and self-service platforms.
Mario Konschake
Director of Product-Data Platform
Soda has integrated seamlessly into our technology stack and given us the confidence to find, analyze, implement, and resolve data issues through a simple self-serve capability.
Sutaraj Dutta
Data Engineering Manager
Our goal was to deliver high-quality datasets in near real-time, ensuring dashboards reflect live data as it flows in. But beyond solving technical challenges, we wanted to spark a cultural shift - empowering the entire organization to make decisions grounded in accurate, timely data.
Gu Xie
Head of Data Engineering
4.4 of 5
Your data has problems.
Now they fix themselves.
Automated data quality, remediation, and management.
One platform, agents that do the work, you approve.
Trusted by
Solutions