Driving Better Data Quality for Trusted Data Intelligence - Case Study with CarTrawler
Driving Better Data Quality for Trusted Data Intelligence - Case Study with CarTrawler
Driving Better Data Quality for Trusted Data Intelligence - Case Study with CarTrawler

Koen Van Duyse
Koen Van Duyse
Former Head of Customers and Partners at Soda
Former Head of Customers and Partners at Soda
Table of Contents

As an organization reliant on billions of data points, we need to be able to empower users across our business to trust the data they are using. Soda has integrated seamlessly into our technology stack and given us the confidence to find, analyze, implement, and resolve data issues through a simple self-serve capability.
As an organization reliant on billions of data points, we need to be able to empower users across our business to trust the data they are using. Soda has integrated seamlessly into our technology stack and given us the confidence to find, analyze, implement, and resolve data issues through a simple self-serve capability.

Sutaraj Dutta
Sutaraj Dutta
Data Eng Manager
Data Eng Manager
Data Eng Manager
at
CarTrawler
CarTrawler
As a car rental API provider, CarTrawler powers car hire functionality for major airlines, online travel agencies, and travel websites worldwide. When you book a flight on airlines like EasyJet, Eurowings, or United Airlines and see car rental options, that's likely CarTrawler working behind the scenes.
Founded in 2004 in Dublin, Ireland, CarTrawler employs over 400 people and prices over a billion different car hire products every day. This massive operation requires huge volumes of data, advanced algorithms, and critically, control over data quality. The company's success depends on delivering accurate, real-time data to feed recommendation engines that directly impact revenue.
As CarTrawler has acquired several major customers in the travel industry, the company urgently needed to scale its data operations. The CarTrawler and Soda story exists based on the shared vision to put data-driven innovation and human connection at the heart of operations.
Read on to learn about how Soda was the capstone in CarTrawler’s journey to create a unified data platform, ensuring end-to-end data quality. Find out how they bolstered their technology stack and vast amounts of data with a scalable data quality solution, enabling data engineers to test data quality as code, prevent data issues, and empower data consumers to self-serve and be accountable for their own data quality expectations.
The challenge: scaling trust and efficiency
CarTrawler prices over a billion different car hire products every day for airlines, travel agencies, and travel websites. Doing this effectively is something that requires huge volumes of data, advanced algorithms, and, critically, control over data quality.
The company’s data challenges stemmed from the sheer complexity and volume of its operations. The company manages approximately a thousand suppliers, each with their own data formats and quality standards. On the partner side, CarTrawler works with numerous travel businesses, each requiring customized integrations. Internal data sources add another layer, from Salesforce Marketing Cloud to proprietary applications, creating a vast web of data flowing from multiple directions.
As a consequence, with a data strategy influenced by individual departmental needs with separate data rules across disparate systems, the synchronization of data changes across teams had become a highly resource-intensive process.
CarTrawler had to deal with:
Raw data from many source systems
Many different types of workloads
Lack of common data understanding
Internal tagging engine, no consistency
Large volumes of data
CarTrawler urgently needed to identify ways to scale up its data operations and, at first, embarked upon a data transformation by building its own data quality tool. The company soon realized it was still unable to scale fast enough to onboard further new clients. In addition to the problem of scalability, CarTrawler also needed to overcome two major data quality challenges that its in-house tool couldn’t solve:
First, it lacked self-service functionality that would allow business users to take data quality into their own hands. Analysts and business users had to rely on engineering to implement quality checks, creating bottlenecks that slowed the entire organization.
Second, the tool couldn't automate the implementation of checks at the scale CarTrawler needed. With thousands of files, metrics, and KPIs requiring validation, manual check creation and maintenance was unsustainable.
The company needed a solution that could guarantee data quality at scale without proportionally increasing the engineering team. And one that could ensure thousands of metrics and KPIs were accurate, as well as provide confidence that automated models made decisions based on clean, reliable data.
The solution came through implementing Soda alongside their Snowflake data warehouse, creating a scalable, self-service data quality framework that transformed how the entire organization interacts with data.
The solution: implementing scalable, self-serve data quality
CarTrawler selected Soda to deliver a scalable data quality solution that would enable its data engineers to test data quality as code and prevent data issues, as well as empower its data consumers to self-serve and manage their own data quality expectations.
“The reason why we went with Soda was because it provided users with a nice interface. It provided an alerting and incident mechanism, and it put everything in a central place. We were even able to take the outcomes of our tests from dbt with Snowflake and bring that back into Soda.” — Stephen Carey, Head of Data Intelligence at CarTrawler
The team was immediately delighted by the speed and ease with which they could migrate to Soda, providing a single source of truth across the entire business. Today, Soda has been fully integrated with CarTrawler’s existing technology stack - including Airflow, dbt, Snowflake, and AWS, to store, ingest, and transform the data, Snowplow for customer data management, and Tableau and Thoughtspot for BI - which has been carefully curated to deliver self-serve capabilities.
Soda sits at the heart of this ecosystem, ensuring data quality at every stage. CarTrawler has established a low-code environment for data consumers across its organization to define data quality agreements and easily write data quality checks using SodaCL, Soda’s domain-specific language for data quality checks.
Unified Quality Management: Integration to Snowflake
It’s important to note that the integration between Soda and Snowflake provided capabilities beyond simple rule execution. It allowed CarTrawler to bring all rules into one place, report against those rules comprehensively, create data contracts defining quality expectations, and create additional rules through a single interface. The team can view the status of each rule instantly and manage and alert on them from one common location.
In the end, CarTrawler can validate that data flowing from diverse source systems into Snowflake maintains integrity and accuracy, creating trust that extends from raw ingestion through final consumption.
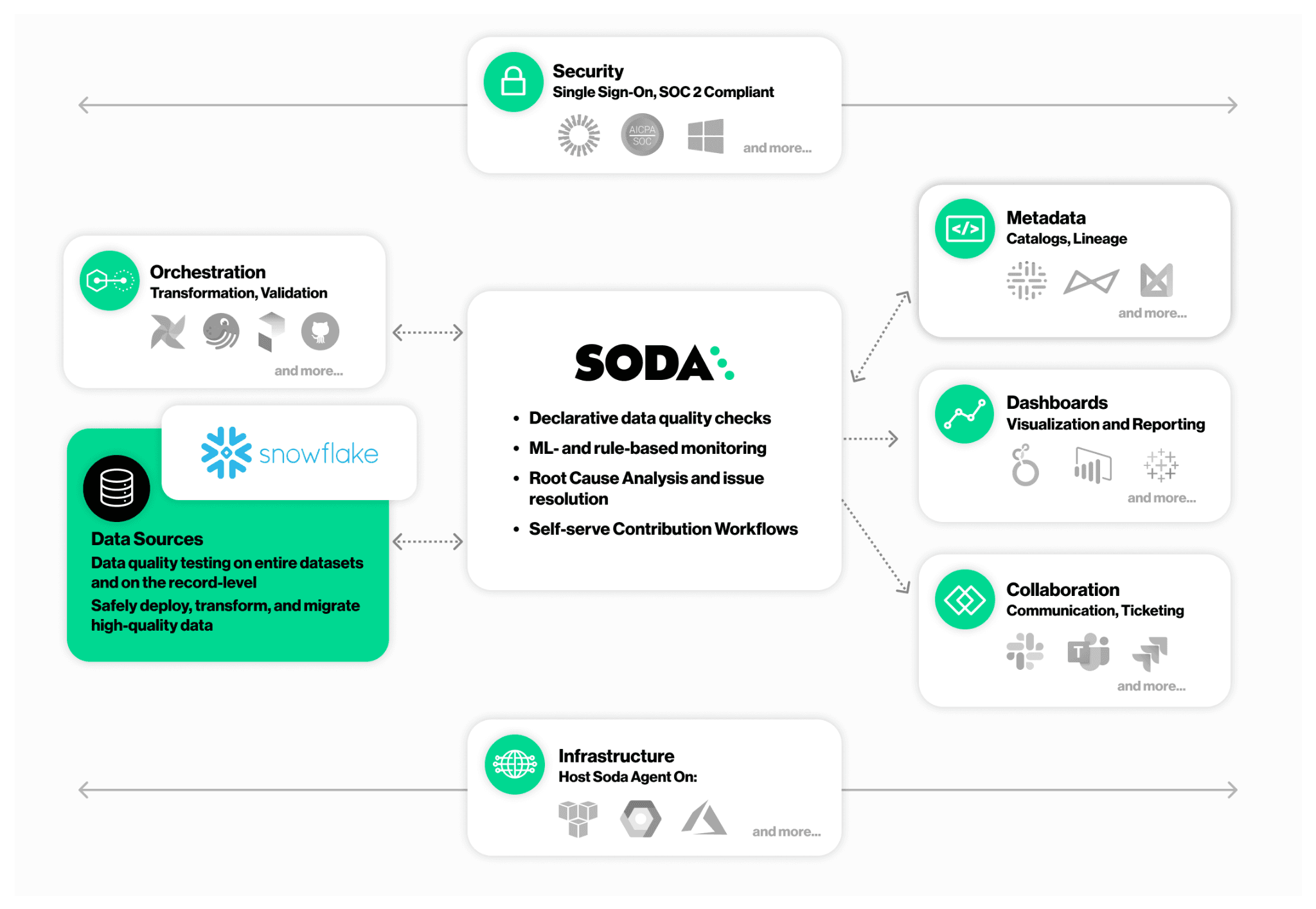
"Combining Snowflake and Soda has led to a wealth of benefits for us, meaning that not only have we been able to create a single source of truth for data analytics and data science, but we can trust the data contained in that platform thanks to being able to easily apply data quality rules, see feedback on those rules and implement fixes to achieve the best level of data reliability. The two platforms work in complementary ways, providing a combined solution which has taken our data operations to the next level." — Patrick Callinan, Director of Insights and Data Science.
Data Quality at Every Layer
The engineering team uses Soda primarily for day-to-day data pipeline validation, ensuring pipelines arrive on time, data is accurate and complete, and proper integrity is maintained. These checks run automatically as part of the orchestration workflow, catching issues before they propagate downstream.
Example Soda checks.yml
checks for dim_product: - avg(safety_stock_level) > 50 # Checks for schema changes - schema: name: Find forbidden, missing, or wrong type warn: when required column missing: [dealer_price, list_price] when forbidden column present: [credit_card] when wrong column type: standard_cost: money fail: when forbidden column present: [pii*] when wrong column index: model_name: 22 # Check for freshness - freshness (start_date) < 1d # Check for referential integrity checks for dim_department_group
Business teams apply Soda on top of the SQL transformation work they do in Snowflake. This self-service capability represents a fundamental shift in how CarTrawler operates. Previously, analysts would need to request engineering support to implement quality checks. Now, they can define their own quality expectations, write checks in SodaCL, and monitor results independently.
Data science teams use Soda for their feature store—a repository of features used to train machine learning models for pricing, sorting engines, and recommendation algorithms. By applying Soda to the feature store, data scientists can focus solely on building models rather than spending excessive time on data validation.
“Self-serve analytics is important at CarTrawler because you need to be able to democratize and get people to work with data and base their decisions on facts. But on top of that, with Soda, we’re also able to give them the ability to put data quality on top of what they’re producing themselves. So, in terms of self-service, comes responsibility.” — Stephen Carey, Head of Data Intelligence at CarTrawler
Better and cleaner data, managed at a greater scale, allows CarTrawler to build better models, which leads to better optimizations, higher-quality machine learning, improved sort results, better recommendations, and ultimately better conversion and financial return.
The impact: building trust and driving business performance
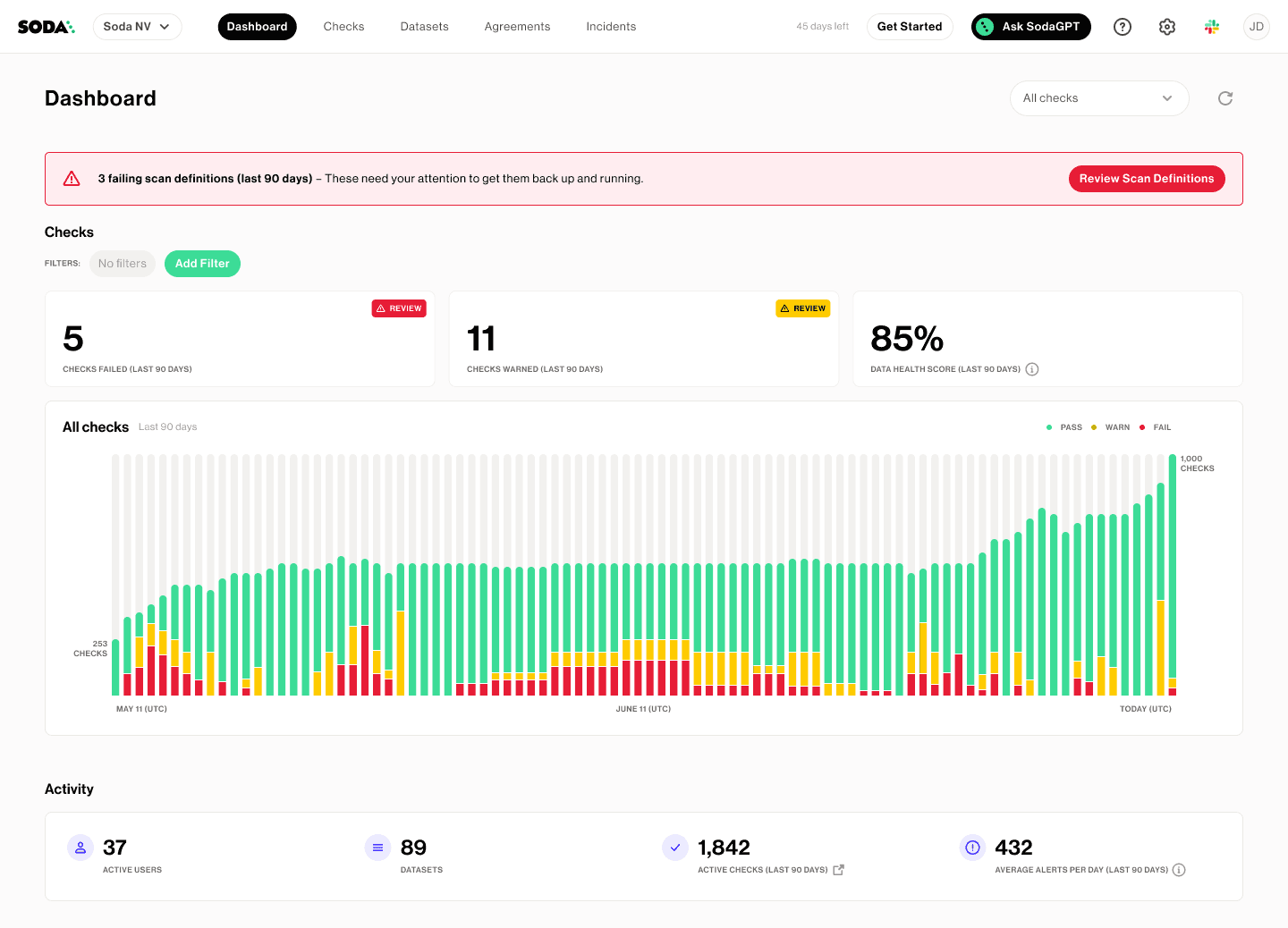
Soda has become an integral part of CarTrawler’s daily data operations, and the most fundamental impact has been building trust in data across the organization.
With the capabilities provided by Soda, CarTrawler has generated total trust in the huge volumes of data it is ingesting and providing to its users.
“Working with Soda has improved the productivity of my team because previously we would have had to do a lot of back-and-forth Q&A - like, is this file up to date? is it working? are you sure? - Whereas now, we can guarantee the quality; that it has been checked, that it is compliant, that it passes all of the quality rules.” — Patrick Callinan, Director of Insights and Data Science
The enhanced trust in data feeding CarTrawler's real-time recommendation engines delivered a measurable business outcome: a 5% improvement in revenue per visitor. This seemingly small percentage translates to a significant financial impact at CarTrawler's scale.
In addition, Patrick Callinan, Director of Insights and Data Science, estimates that without Soda, his team would need another two to three headcounts to achieve the same level of data quality coverage.
Top Soda Features for CarTrawler
1. User-Friendly Interface:
provides visibility for both technical and non-technical users
enables self-service without deep coding knowledge
creates transparency into data quality status
centralizes alerting and incident management
2. Soda Agent for Engineers
easy to maintain
integrates smoothly with orchestration workflows
provides flexibility in deployment
scales effortlessly with data volume
3. Rich Documentation and Community
Soda's documentation provides clear examples and makes integration straightforward.
The Soda community also plays a supporting role: when questions arise, posting in the Slack channel typically yields quick responses from experts around the world.
Looking ahead: sustainable scaling
Data quality isn't an isolated concern; it's integrated into every layer of the architecture specifically to enable better business outcomes. Soda has enabled CarTrawler to scale its data operations in ways that weren't previously possible.
"Soda blended very well with the data stack at CarTrawler. The future looks very bright. With the Soda platform, we can now onboard more and more datasets, helping different teams at CarTrawler achieve their goals." — Sutaraj Dutta, Head of Data Engineering at CarTrawler
This competitive advantage wasn't achieved through massive engineering investment or building everything in-house. It came from recognizing that data quality at scale requires purpose-built tools, embracing self-service as a principle rather than just a feature, and making quality everyone's responsibility through democratized access and accountability.
Disclaimer: This material was created in 2023. Please note that figures and statistics may have changed, and there might be minor code syntax or UI path differences since its publication. |
|---|
Driving Better Data Quality for Trusted Data Intelligence
CarTrawler selected Soda to deliver a scalable data quality solution that would enable its data engineers to test data quality as code and prevent data issues, and empower its data consumers to self-serve and manage their own data quality expectations.
In this video, Patrick Callinan, Director of Insights and Data Science; Stephen Carey, Head of Data Intelligence; and Sutaraj Dutta, Head of Data Engineering, share CarTrawler’s transformation journey and how Soda has been fully integrated into CarTrawler’s technology stack - including Airflow, dbt, Snowflake, and AWS, to store, ingest, and transform the data, Snowplow for customer data management, and Tableau and Thoughtspot for BI - which has been carefully curated to deliver self-serve capabilities across the entire business.
Get in touch
Schedule a demo with the Soda team or request a free account to find out how much you could optimize your data quality strategy across your entire data ecosystem.
As a car rental API provider, CarTrawler powers car hire functionality for major airlines, online travel agencies, and travel websites worldwide. When you book a flight on airlines like EasyJet, Eurowings, or United Airlines and see car rental options, that's likely CarTrawler working behind the scenes.
Founded in 2004 in Dublin, Ireland, CarTrawler employs over 400 people and prices over a billion different car hire products every day. This massive operation requires huge volumes of data, advanced algorithms, and critically, control over data quality. The company's success depends on delivering accurate, real-time data to feed recommendation engines that directly impact revenue.
As CarTrawler has acquired several major customers in the travel industry, the company urgently needed to scale its data operations. The CarTrawler and Soda story exists based on the shared vision to put data-driven innovation and human connection at the heart of operations.
Read on to learn about how Soda was the capstone in CarTrawler’s journey to create a unified data platform, ensuring end-to-end data quality. Find out how they bolstered their technology stack and vast amounts of data with a scalable data quality solution, enabling data engineers to test data quality as code, prevent data issues, and empower data consumers to self-serve and be accountable for their own data quality expectations.
The challenge: scaling trust and efficiency
CarTrawler prices over a billion different car hire products every day for airlines, travel agencies, and travel websites. Doing this effectively is something that requires huge volumes of data, advanced algorithms, and, critically, control over data quality.
The company’s data challenges stemmed from the sheer complexity and volume of its operations. The company manages approximately a thousand suppliers, each with their own data formats and quality standards. On the partner side, CarTrawler works with numerous travel businesses, each requiring customized integrations. Internal data sources add another layer, from Salesforce Marketing Cloud to proprietary applications, creating a vast web of data flowing from multiple directions.
As a consequence, with a data strategy influenced by individual departmental needs with separate data rules across disparate systems, the synchronization of data changes across teams had become a highly resource-intensive process.
CarTrawler had to deal with:
Raw data from many source systems
Many different types of workloads
Lack of common data understanding
Internal tagging engine, no consistency
Large volumes of data
CarTrawler urgently needed to identify ways to scale up its data operations and, at first, embarked upon a data transformation by building its own data quality tool. The company soon realized it was still unable to scale fast enough to onboard further new clients. In addition to the problem of scalability, CarTrawler also needed to overcome two major data quality challenges that its in-house tool couldn’t solve:
First, it lacked self-service functionality that would allow business users to take data quality into their own hands. Analysts and business users had to rely on engineering to implement quality checks, creating bottlenecks that slowed the entire organization.
Second, the tool couldn't automate the implementation of checks at the scale CarTrawler needed. With thousands of files, metrics, and KPIs requiring validation, manual check creation and maintenance was unsustainable.
The company needed a solution that could guarantee data quality at scale without proportionally increasing the engineering team. And one that could ensure thousands of metrics and KPIs were accurate, as well as provide confidence that automated models made decisions based on clean, reliable data.
The solution came through implementing Soda alongside their Snowflake data warehouse, creating a scalable, self-service data quality framework that transformed how the entire organization interacts with data.
The solution: implementing scalable, self-serve data quality
CarTrawler selected Soda to deliver a scalable data quality solution that would enable its data engineers to test data quality as code and prevent data issues, as well as empower its data consumers to self-serve and manage their own data quality expectations.
“The reason why we went with Soda was because it provided users with a nice interface. It provided an alerting and incident mechanism, and it put everything in a central place. We were even able to take the outcomes of our tests from dbt with Snowflake and bring that back into Soda.” — Stephen Carey, Head of Data Intelligence at CarTrawler
The team was immediately delighted by the speed and ease with which they could migrate to Soda, providing a single source of truth across the entire business. Today, Soda has been fully integrated with CarTrawler’s existing technology stack - including Airflow, dbt, Snowflake, and AWS, to store, ingest, and transform the data, Snowplow for customer data management, and Tableau and Thoughtspot for BI - which has been carefully curated to deliver self-serve capabilities.
Soda sits at the heart of this ecosystem, ensuring data quality at every stage. CarTrawler has established a low-code environment for data consumers across its organization to define data quality agreements and easily write data quality checks using SodaCL, Soda’s domain-specific language for data quality checks.
Unified Quality Management: Integration to Snowflake
It’s important to note that the integration between Soda and Snowflake provided capabilities beyond simple rule execution. It allowed CarTrawler to bring all rules into one place, report against those rules comprehensively, create data contracts defining quality expectations, and create additional rules through a single interface. The team can view the status of each rule instantly and manage and alert on them from one common location.
In the end, CarTrawler can validate that data flowing from diverse source systems into Snowflake maintains integrity and accuracy, creating trust that extends from raw ingestion through final consumption.
"Combining Snowflake and Soda has led to a wealth of benefits for us, meaning that not only have we been able to create a single source of truth for data analytics and data science, but we can trust the data contained in that platform thanks to being able to easily apply data quality rules, see feedback on those rules and implement fixes to achieve the best level of data reliability. The two platforms work in complementary ways, providing a combined solution which has taken our data operations to the next level." — Patrick Callinan, Director of Insights and Data Science.
Data Quality at Every Layer
The engineering team uses Soda primarily for day-to-day data pipeline validation, ensuring pipelines arrive on time, data is accurate and complete, and proper integrity is maintained. These checks run automatically as part of the orchestration workflow, catching issues before they propagate downstream.
Example Soda checks.yml
checks for dim_product: - avg(safety_stock_level) > 50 # Checks for schema changes - schema: name: Find forbidden, missing, or wrong type warn: when required column missing: [dealer_price, list_price] when forbidden column present: [credit_card] when wrong column type: standard_cost: money fail: when forbidden column present: [pii*] when wrong column index: model_name: 22 # Check for freshness - freshness (start_date) < 1d # Check for referential integrity checks for dim_department_group
Business teams apply Soda on top of the SQL transformation work they do in Snowflake. This self-service capability represents a fundamental shift in how CarTrawler operates. Previously, analysts would need to request engineering support to implement quality checks. Now, they can define their own quality expectations, write checks in SodaCL, and monitor results independently.
Data science teams use Soda for their feature store—a repository of features used to train machine learning models for pricing, sorting engines, and recommendation algorithms. By applying Soda to the feature store, data scientists can focus solely on building models rather than spending excessive time on data validation.
“Self-serve analytics is important at CarTrawler because you need to be able to democratize and get people to work with data and base their decisions on facts. But on top of that, with Soda, we’re also able to give them the ability to put data quality on top of what they’re producing themselves. So, in terms of self-service, comes responsibility.” — Stephen Carey, Head of Data Intelligence at CarTrawler
Better and cleaner data, managed at a greater scale, allows CarTrawler to build better models, which leads to better optimizations, higher-quality machine learning, improved sort results, better recommendations, and ultimately better conversion and financial return.
The impact: building trust and driving business performance
Soda has become an integral part of CarTrawler’s daily data operations, and the most fundamental impact has been building trust in data across the organization.
With the capabilities provided by Soda, CarTrawler has generated total trust in the huge volumes of data it is ingesting and providing to its users.
“Working with Soda has improved the productivity of my team because previously we would have had to do a lot of back-and-forth Q&A - like, is this file up to date? is it working? are you sure? - Whereas now, we can guarantee the quality; that it has been checked, that it is compliant, that it passes all of the quality rules.” — Patrick Callinan, Director of Insights and Data Science
The enhanced trust in data feeding CarTrawler's real-time recommendation engines delivered a measurable business outcome: a 5% improvement in revenue per visitor. This seemingly small percentage translates to a significant financial impact at CarTrawler's scale.
In addition, Patrick Callinan, Director of Insights and Data Science, estimates that without Soda, his team would need another two to three headcounts to achieve the same level of data quality coverage.
Top Soda Features for CarTrawler
1. User-Friendly Interface:
provides visibility for both technical and non-technical users
enables self-service without deep coding knowledge
creates transparency into data quality status
centralizes alerting and incident management
2. Soda Agent for Engineers
easy to maintain
integrates smoothly with orchestration workflows
provides flexibility in deployment
scales effortlessly with data volume
3. Rich Documentation and Community
Soda's documentation provides clear examples and makes integration straightforward.
The Soda community also plays a supporting role: when questions arise, posting in the Slack channel typically yields quick responses from experts around the world.
Looking ahead: sustainable scaling
Data quality isn't an isolated concern; it's integrated into every layer of the architecture specifically to enable better business outcomes. Soda has enabled CarTrawler to scale its data operations in ways that weren't previously possible.
"Soda blended very well with the data stack at CarTrawler. The future looks very bright. With the Soda platform, we can now onboard more and more datasets, helping different teams at CarTrawler achieve their goals." — Sutaraj Dutta, Head of Data Engineering at CarTrawler
This competitive advantage wasn't achieved through massive engineering investment or building everything in-house. It came from recognizing that data quality at scale requires purpose-built tools, embracing self-service as a principle rather than just a feature, and making quality everyone's responsibility through democratized access and accountability.
Disclaimer: This material was created in 2023. Please note that figures and statistics may have changed, and there might be minor code syntax or UI path differences since its publication. |
|---|
Driving Better Data Quality for Trusted Data Intelligence
CarTrawler selected Soda to deliver a scalable data quality solution that would enable its data engineers to test data quality as code and prevent data issues, and empower its data consumers to self-serve and manage their own data quality expectations.
In this video, Patrick Callinan, Director of Insights and Data Science; Stephen Carey, Head of Data Intelligence; and Sutaraj Dutta, Head of Data Engineering, share CarTrawler’s transformation journey and how Soda has been fully integrated into CarTrawler’s technology stack - including Airflow, dbt, Snowflake, and AWS, to store, ingest, and transform the data, Snowplow for customer data management, and Tableau and Thoughtspot for BI - which has been carefully curated to deliver self-serve capabilities across the entire business.
Get in touch
Schedule a demo with the Soda team or request a free account to find out how much you could optimize your data quality strategy across your entire data ecosystem.
As a car rental API provider, CarTrawler powers car hire functionality for major airlines, online travel agencies, and travel websites worldwide. When you book a flight on airlines like EasyJet, Eurowings, or United Airlines and see car rental options, that's likely CarTrawler working behind the scenes.
Founded in 2004 in Dublin, Ireland, CarTrawler employs over 400 people and prices over a billion different car hire products every day. This massive operation requires huge volumes of data, advanced algorithms, and critically, control over data quality. The company's success depends on delivering accurate, real-time data to feed recommendation engines that directly impact revenue.
As CarTrawler has acquired several major customers in the travel industry, the company urgently needed to scale its data operations. The CarTrawler and Soda story exists based on the shared vision to put data-driven innovation and human connection at the heart of operations.
Read on to learn about how Soda was the capstone in CarTrawler’s journey to create a unified data platform, ensuring end-to-end data quality. Find out how they bolstered their technology stack and vast amounts of data with a scalable data quality solution, enabling data engineers to test data quality as code, prevent data issues, and empower data consumers to self-serve and be accountable for their own data quality expectations.
The challenge: scaling trust and efficiency
CarTrawler prices over a billion different car hire products every day for airlines, travel agencies, and travel websites. Doing this effectively is something that requires huge volumes of data, advanced algorithms, and, critically, control over data quality.
The company’s data challenges stemmed from the sheer complexity and volume of its operations. The company manages approximately a thousand suppliers, each with their own data formats and quality standards. On the partner side, CarTrawler works with numerous travel businesses, each requiring customized integrations. Internal data sources add another layer, from Salesforce Marketing Cloud to proprietary applications, creating a vast web of data flowing from multiple directions.
As a consequence, with a data strategy influenced by individual departmental needs with separate data rules across disparate systems, the synchronization of data changes across teams had become a highly resource-intensive process.
CarTrawler had to deal with:
Raw data from many source systems
Many different types of workloads
Lack of common data understanding
Internal tagging engine, no consistency
Large volumes of data
CarTrawler urgently needed to identify ways to scale up its data operations and, at first, embarked upon a data transformation by building its own data quality tool. The company soon realized it was still unable to scale fast enough to onboard further new clients. In addition to the problem of scalability, CarTrawler also needed to overcome two major data quality challenges that its in-house tool couldn’t solve:
First, it lacked self-service functionality that would allow business users to take data quality into their own hands. Analysts and business users had to rely on engineering to implement quality checks, creating bottlenecks that slowed the entire organization.
Second, the tool couldn't automate the implementation of checks at the scale CarTrawler needed. With thousands of files, metrics, and KPIs requiring validation, manual check creation and maintenance was unsustainable.
The company needed a solution that could guarantee data quality at scale without proportionally increasing the engineering team. And one that could ensure thousands of metrics and KPIs were accurate, as well as provide confidence that automated models made decisions based on clean, reliable data.
The solution came through implementing Soda alongside their Snowflake data warehouse, creating a scalable, self-service data quality framework that transformed how the entire organization interacts with data.
The solution: implementing scalable, self-serve data quality
CarTrawler selected Soda to deliver a scalable data quality solution that would enable its data engineers to test data quality as code and prevent data issues, as well as empower its data consumers to self-serve and manage their own data quality expectations.
“The reason why we went with Soda was because it provided users with a nice interface. It provided an alerting and incident mechanism, and it put everything in a central place. We were even able to take the outcomes of our tests from dbt with Snowflake and bring that back into Soda.” — Stephen Carey, Head of Data Intelligence at CarTrawler
The team was immediately delighted by the speed and ease with which they could migrate to Soda, providing a single source of truth across the entire business. Today, Soda has been fully integrated with CarTrawler’s existing technology stack - including Airflow, dbt, Snowflake, and AWS, to store, ingest, and transform the data, Snowplow for customer data management, and Tableau and Thoughtspot for BI - which has been carefully curated to deliver self-serve capabilities.
Soda sits at the heart of this ecosystem, ensuring data quality at every stage. CarTrawler has established a low-code environment for data consumers across its organization to define data quality agreements and easily write data quality checks using SodaCL, Soda’s domain-specific language for data quality checks.
Unified Quality Management: Integration to Snowflake
It’s important to note that the integration between Soda and Snowflake provided capabilities beyond simple rule execution. It allowed CarTrawler to bring all rules into one place, report against those rules comprehensively, create data contracts defining quality expectations, and create additional rules through a single interface. The team can view the status of each rule instantly and manage and alert on them from one common location.
In the end, CarTrawler can validate that data flowing from diverse source systems into Snowflake maintains integrity and accuracy, creating trust that extends from raw ingestion through final consumption.
"Combining Snowflake and Soda has led to a wealth of benefits for us, meaning that not only have we been able to create a single source of truth for data analytics and data science, but we can trust the data contained in that platform thanks to being able to easily apply data quality rules, see feedback on those rules and implement fixes to achieve the best level of data reliability. The two platforms work in complementary ways, providing a combined solution which has taken our data operations to the next level." — Patrick Callinan, Director of Insights and Data Science.
Data Quality at Every Layer
The engineering team uses Soda primarily for day-to-day data pipeline validation, ensuring pipelines arrive on time, data is accurate and complete, and proper integrity is maintained. These checks run automatically as part of the orchestration workflow, catching issues before they propagate downstream.
Example Soda checks.yml
checks for dim_product: - avg(safety_stock_level) > 50 # Checks for schema changes - schema: name: Find forbidden, missing, or wrong type warn: when required column missing: [dealer_price, list_price] when forbidden column present: [credit_card] when wrong column type: standard_cost: money fail: when forbidden column present: [pii*] when wrong column index: model_name: 22 # Check for freshness - freshness (start_date) < 1d # Check for referential integrity checks for dim_department_group
Business teams apply Soda on top of the SQL transformation work they do in Snowflake. This self-service capability represents a fundamental shift in how CarTrawler operates. Previously, analysts would need to request engineering support to implement quality checks. Now, they can define their own quality expectations, write checks in SodaCL, and monitor results independently.
Data science teams use Soda for their feature store—a repository of features used to train machine learning models for pricing, sorting engines, and recommendation algorithms. By applying Soda to the feature store, data scientists can focus solely on building models rather than spending excessive time on data validation.
“Self-serve analytics is important at CarTrawler because you need to be able to democratize and get people to work with data and base their decisions on facts. But on top of that, with Soda, we’re also able to give them the ability to put data quality on top of what they’re producing themselves. So, in terms of self-service, comes responsibility.” — Stephen Carey, Head of Data Intelligence at CarTrawler
Better and cleaner data, managed at a greater scale, allows CarTrawler to build better models, which leads to better optimizations, higher-quality machine learning, improved sort results, better recommendations, and ultimately better conversion and financial return.
The impact: building trust and driving business performance
Soda has become an integral part of CarTrawler’s daily data operations, and the most fundamental impact has been building trust in data across the organization.
With the capabilities provided by Soda, CarTrawler has generated total trust in the huge volumes of data it is ingesting and providing to its users.
“Working with Soda has improved the productivity of my team because previously we would have had to do a lot of back-and-forth Q&A - like, is this file up to date? is it working? are you sure? - Whereas now, we can guarantee the quality; that it has been checked, that it is compliant, that it passes all of the quality rules.” — Patrick Callinan, Director of Insights and Data Science
The enhanced trust in data feeding CarTrawler's real-time recommendation engines delivered a measurable business outcome: a 5% improvement in revenue per visitor. This seemingly small percentage translates to a significant financial impact at CarTrawler's scale.
In addition, Patrick Callinan, Director of Insights and Data Science, estimates that without Soda, his team would need another two to three headcounts to achieve the same level of data quality coverage.
Top Soda Features for CarTrawler
1. User-Friendly Interface:
provides visibility for both technical and non-technical users
enables self-service without deep coding knowledge
creates transparency into data quality status
centralizes alerting and incident management
2. Soda Agent for Engineers
easy to maintain
integrates smoothly with orchestration workflows
provides flexibility in deployment
scales effortlessly with data volume
3. Rich Documentation and Community
Soda's documentation provides clear examples and makes integration straightforward.
The Soda community also plays a supporting role: when questions arise, posting in the Slack channel typically yields quick responses from experts around the world.
Looking ahead: sustainable scaling
Data quality isn't an isolated concern; it's integrated into every layer of the architecture specifically to enable better business outcomes. Soda has enabled CarTrawler to scale its data operations in ways that weren't previously possible.
"Soda blended very well with the data stack at CarTrawler. The future looks very bright. With the Soda platform, we can now onboard more and more datasets, helping different teams at CarTrawler achieve their goals." — Sutaraj Dutta, Head of Data Engineering at CarTrawler
This competitive advantage wasn't achieved through massive engineering investment or building everything in-house. It came from recognizing that data quality at scale requires purpose-built tools, embracing self-service as a principle rather than just a feature, and making quality everyone's responsibility through democratized access and accountability.
Disclaimer: This material was created in 2023. Please note that figures and statistics may have changed, and there might be minor code syntax or UI path differences since its publication. |
|---|
Driving Better Data Quality for Trusted Data Intelligence
CarTrawler selected Soda to deliver a scalable data quality solution that would enable its data engineers to test data quality as code and prevent data issues, and empower its data consumers to self-serve and manage their own data quality expectations.
In this video, Patrick Callinan, Director of Insights and Data Science; Stephen Carey, Head of Data Intelligence; and Sutaraj Dutta, Head of Data Engineering, share CarTrawler’s transformation journey and how Soda has been fully integrated into CarTrawler’s technology stack - including Airflow, dbt, Snowflake, and AWS, to store, ingest, and transform the data, Snowplow for customer data management, and Tableau and Thoughtspot for BI - which has been carefully curated to deliver self-serve capabilities across the entire business.
Get in touch
Schedule a demo with the Soda team or request a free account to find out how much you could optimize your data quality strategy across your entire data ecosystem.
Trusted by the world’s leading enterprises
Real stories from companies using Soda to keep their data reliable, accurate, and ready for action.
At the end of the day, we don’t want to be in there managing the checks, updating the checks, adding the checks. We just want to go and observe what’s happening, and that’s what Soda is enabling right now.

Sid Srivastava
Director of Data Governance, Quality and MLOps
Investing in data quality is key for cross-functional teams to make accurate, complete decisions with fewer risks and greater returns, using initiatives such as product thinking, data governance, and self-service platforms.

Mario Konschake
Director of Product-Data Platform
Soda has integrated seamlessly into our technology stack and given us the confidence to find, analyze, implement, and resolve data issues through a simple self-serve capability.

Sutaraj Dutta
Data Engineering Manager
Our goal was to deliver high-quality datasets in near real-time, ensuring dashboards reflect live data as it flows in. But beyond solving technical challenges, we wanted to spark a cultural shift - empowering the entire organization to make decisions grounded in accurate, timely data.

Gu Xie
Head of Data Engineering
4.4 of 5
Your data has problems.
Now they fix themselves.
Automated data quality, remediation, and management.
One platform, agents that do the work, you approve.
Trusted by








Trusted by the world’s leading enterprises
Real stories from companies using Soda to keep their data reliable, accurate, and ready for action.
At the end of the day, we don’t want to be in there managing the checks, updating the checks, adding the checks. We just want to go and observe what’s happening, and that’s what Soda is enabling right now.
Sid Srivastava
Director of Data Governance, Quality and MLOps
Investing in data quality is key for cross-functional teams to make accurate, complete decisions with fewer risks and greater returns, using initiatives such as product thinking, data governance, and self-service platforms.
Mario Konschake
Director of Product-Data Platform
Soda has integrated seamlessly into our technology stack and given us the confidence to find, analyze, implement, and resolve data issues through a simple self-serve capability.
Sutaraj Dutta
Data Engineering Manager
Our goal was to deliver high-quality datasets in near real-time, ensuring dashboards reflect live data as it flows in. But beyond solving technical challenges, we wanted to spark a cultural shift - empowering the entire organization to make decisions grounded in accurate, timely data.
Gu Xie
Head of Data Engineering
4.4 of 5
Your data has problems.
Now they fix themselves.
Automated data quality, remediation, and management.
One platform, agents that do the work, you approve.
Trusted by
Solutions
Trusted by the world’s leading enterprises
Real stories from companies using Soda to keep their data reliable, accurate, and ready for action.
At the end of the day, we don’t want to be in there managing the checks, updating the checks, adding the checks. We just want to go and observe what’s happening, and that’s what Soda is enabling right now.
Sid Srivastava
Director of Data Governance, Quality and MLOps
Investing in data quality is key for cross-functional teams to make accurate, complete decisions with fewer risks and greater returns, using initiatives such as product thinking, data governance, and self-service platforms.
Mario Konschake
Director of Product-Data Platform
Soda has integrated seamlessly into our technology stack and given us the confidence to find, analyze, implement, and resolve data issues through a simple self-serve capability.
Sutaraj Dutta
Data Engineering Manager
Our goal was to deliver high-quality datasets in near real-time, ensuring dashboards reflect live data as it flows in. But beyond solving technical challenges, we wanted to spark a cultural shift - empowering the entire organization to make decisions grounded in accurate, timely data.
Gu Xie
Head of Data Engineering
4.4 of 5
Your data has problems.
Now they fix themselves.
Automated data quality, remediation, and management.
One platform, agents that do the work, you approve.
Trusted by
Solutions