



at
Appfire is a leading global software provider that enhances, extends, and connects the world's leading platforms, allowing teams to work in any way they want, from planning to product ideation, development, project delivery, and beyond. Appfire increases the value of platforms such as Atlassian, Microsoft, monday.com, and Salesforce, enabling teams to thrive and do their best work together.
By implementing Soda Core and Soda Cloud, Appfire reduced scan times from hours to seconds and gained real-time observability across its entire product portfolio. Since integrating Soda, Appfire has gained the necessary flexibility to continually refine processes and the observability required to effectively manage their product analytics initiatives at scale. Their data team now operates on an enterprise scale, detecting issues that would have gone unnoticed in manual processes.
The challenge: scaling data operations after rapid growth
A critical aspect of Appfire’s strategy involves making data-driven product design decisions. This relies heavily on the anonymous behavioral data continuously collected from their products. To ensure these decisions are sound, the company knows it needs strong data tracking and management.
Appfire needed assurance that the real-time data from their products was accurate and that any data issues could be quickly identified and addressed to maintain the integrity of their analytics and strategic planning.
In its early days, Appfire employed a manual QA process for product data analytics. This approach proved manageable when working with just a few products. However, as the company rapidly scaled, the manual system became increasingly strained.
With multiple applications simultaneously implementing product data analytics, the team was constantly stretched thin, unable to efficiently provide timely and effective feedback to all teams while juggling a large amount of information.
Another significant limitation was the lack of observability for products after they launched their analytics. There was no straightforward method for detecting data failures or unintentional regressions. Issues often only surfaced during later attempts at analysis, which could result in data loss.
Appfire has a portfolio of more than 100 diverse products, each with its unique set of analytics requirements. This portfolio structure includes numerous development teams employing various architectures. Consequently, establishing a consistent and scalable product analytics solution across a heterogeneous landscape presented a significant challenge. Key data quality issues originated from several factors:
First, data ownership was dispersed across numerous independent teams, leading to inconsistencies.
Second, there was a lack of unified visibility and control over the data, making it difficult to monitor and manage quality centrally.
Third, the existing governance capabilities within the current analytics tools were insufficient to meet the evolving needs of Appfire's complex data environment.
These challenges highlighted the growing need for more granular controls, centralized observability, and effective alerting mechanisms to properly manage the behavioral data, which is the critical product of their analytics efforts. It became clear that Appfire required a solution that could actively monitor data post-launch, allowing them to quickly identify and rectify any emerging issues. Given the scaling plans already in place for the next two years, a robust, adaptable solution was essential to address current and future data quality challenges.
The solution: centralized, scalable data quality framework
Once Appfire recognized the limitations of their existing toolset, they began exploring alternative solutions in the market. A key enabler for what came next was the completion of a project to stage their product data in a more flexible data warehouse solution. With this structure, they could evaluate a wider range of tools beyond those initially considered.
The team tested several tools with mature open-source packages and found that Soda Core stood out. Soda Core was notably straightforward to install and configure, making it the most accessible solution based on their initial testing.
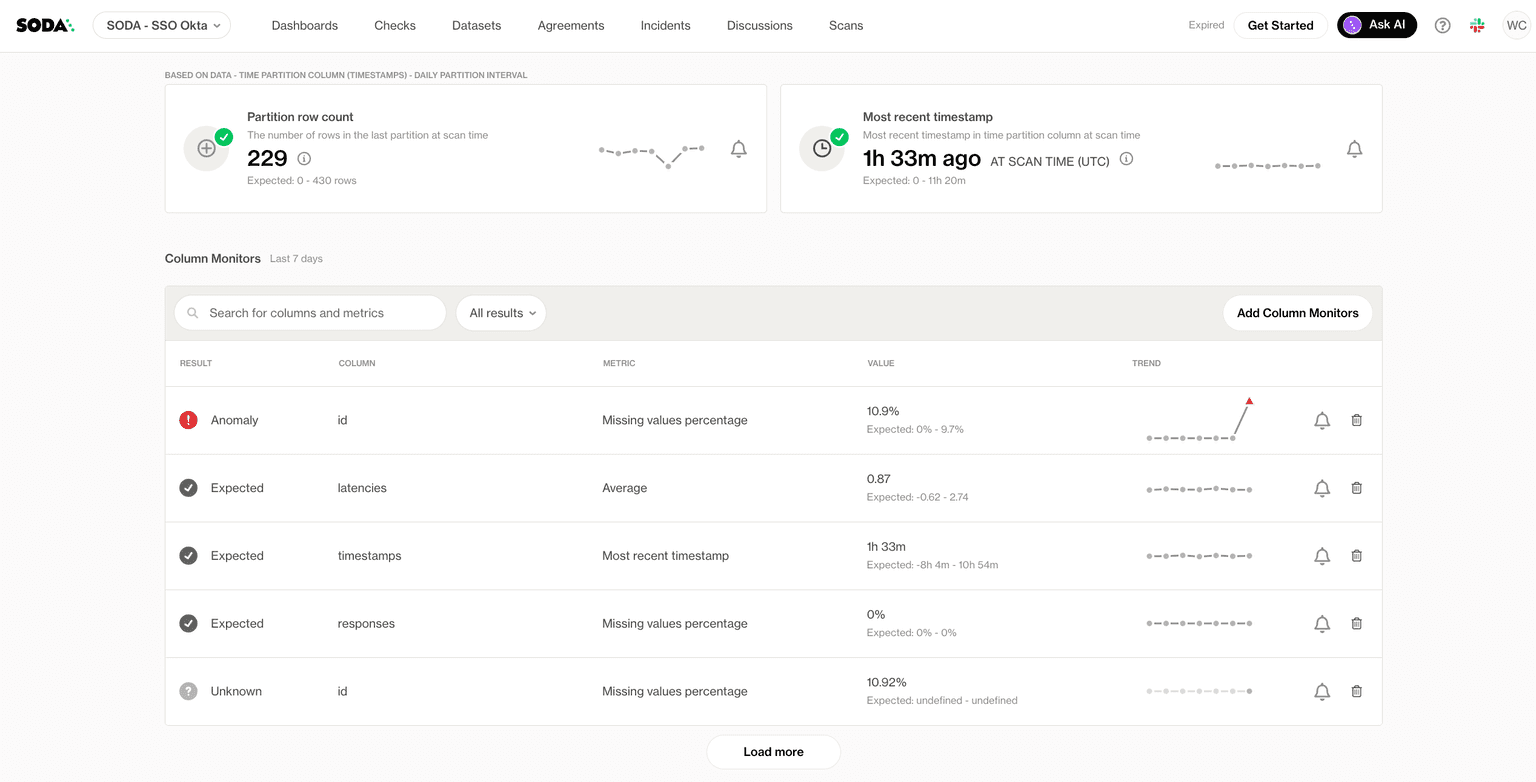
They developed a programmatic approach to pull new data from their platforms, and the Soda scans delivered results in seconds. This enabled them to check a much broader range of data than was feasible with manual methods. Moreover, the open-source version allowed for the codification of data quality standards; as the volume of implemented checks grew, managing them manually became impractical, making Soda's programmatic approach invaluable.
While Soda Core addressed many initial needs, the company also recognized the need to automate issue tracking and notifications. This led them to explore Soda Cloud (SaaS platform). They found that Soda Cloud’s retention features, the ease of viewing scan results, and the notification options aligned well with their workflow.

↗ Soda issue tracking - Create Incident
As a result, after running a Proof of Concept (POC) project for a few months with Soda, they decided to adopt Soda Cloud, further enhancing their data management capabilities.
The impact: visibility, consistency, and confidence
With the implementation of Soda Cloud, Appfire gained the ability to operate at scale with a powerful data quality tool. Working in collaboration with their Data Warehouse team, all critical data was organized into an easily accessible format, paired with robust data quality checks powered by Soda.
Appfire shifted their QA approach, placing greater emphasis on codifying organizational taxonomy rules into precise definitions executable by Soda. This shift refined their internal guidelines, reducing ambiguity across the organization. By quantifying outcomes and making them transparent, the team became more objective and rigorous in their analysis and process development.
This comprehensive change equipped Appfire's small-scale data team with the tools necessary to scale their work and meet increasing demands while consistently improving overall data quality. The team automated as much of the process as possible, focusing on creating and managing objective rules and expectations within their taxonomy.
The expanding Soda implementation ensured that these rules were always factored into their quality management practices for every product. With this new data quality framework, Appfire achieved:
A single, centralized view of data health across multiple systems
Standardized governance policies that scale with acquisitions
More reliable, trusted data for business and engineering teams
A foundation for proactive quality management, reducing operational overhead
Looking ahead: scaling trust in data, one product at a time
Appfire’s shift from manual QA to a scalable, automated data quality framework has been a practical response to the growing complexity of its product portfolio. With over 100 products in motion, the need for a reliable and consistent approach to data governance was critical.
Soda helped the team move away from ad-hoc fixes toward a structured process that identifies issues early, improves data reliability, and supports better decision-making.
As Appfire continues to expand and evolve its product portfolio, the role of data observability remains more critical than ever.
With continued innovation in anomaly detection and observability, Soda is not just a technology vendor, but a strategic partner in Appfire’s broader data management strategy. Together, they are setting a new standard for how data reliability and trust are built into the core of digital product development.
For any modern organization managing complex data pipelines, observability is no longer a nice-to-have—it’s essential. Soda provides the tools needed to keep data quality under control without adding unnecessary complexity or overhead.
Disclaimer: This material was created in 2025. Please note that figures and statistics may have changed, and there might be minor code syntax or UI path differences since its publication. |
|---|
Get in touch
Schedule a demo with the Soda team or request a free account to find out how much you could optimize your data quality strategy across your entire data ecosystem.











