
Most data teams discover data contracts the hard way: after a “small” schema tweak quietly breaks half a dashboard estate.
A producer renames a column. A nullability assumption stops being true. A new product line sneaks in values your models were never designed to handle. None of this looks dramatic in a pull request, but downstream the effects are real: failed pipelines, angry stakeholders, and hours of unplanned debugging.
If you work in a modern stack — Snowflake, Databricks, BigQuery, PostgreSQL, or a mix — you’ve probably felt this. As data volume and surface area grow, “be careful when you change the schema” is not a strategy.
Data contracts are the antidote: explicit, enforceable agreements between data producers and consumers about what a dataset must look like and how it should behave. They spell out structure, types, basic quality rules, ownership, and semantics before data ever hits production. Instead of “we assumed this table would never…”, you get “this table must… and Soda will enforce it.”
Soda’s take on data contracts adds a few important ingredients:
AI-powered contract generation so you are not staring at a blank YAML file.
A shared workflow where engineers work in Git and business users in the UI, on the same contracts.
Versioned proposals and diffs, so changes are reviewable and auditable.
Automated enforcement in pipelines and CI, so violations are caught before they spread.
This guide walks through what data contracts are in Soda, how they relate to testing and observability, and an implementation plan you can copy: from drafting and reviewing contracts, to wiring them into pipelines, scaling them across domains, and proving they work.
What Are Data Contracts in Soda?
In Soda, a data contract is a formal specification for a dataset that:
Declares the expected schema (tables, columns, and data types).
Defines which fields are required vs optional (nullability and optionality).
Encodes quality rules that must always hold (e.g. uniqueness, valid ranges, allowed values).
Adds business semantics and governance metadata.
Think of it as the source of truth for “what good data looks like” for a single data product.
Typical components in a Soda data contract:
Dataset identity
→ Logical name and physical location (database, schema, table).
Columns and types
→ Expected column list and their data types.
→ Optional flags for nullable or optional fields.
Dataset-level checks
→ Row count expectations.
→ Duplicate rules (what fields must be unique together).
→ Freshness and delivery expectations where relevant.
Column-level checks
→ Valid value sets (countries, statuses, size codes).
→ Range checks (e.g. quantities must be ≥ 0).
→ Patterns and formats (emails, IDs, timestamps).
Once you publish a contract, Soda treats it as a living, enforceable agreement: it continuously validates new data against the contract and surfaces violations for investigation.
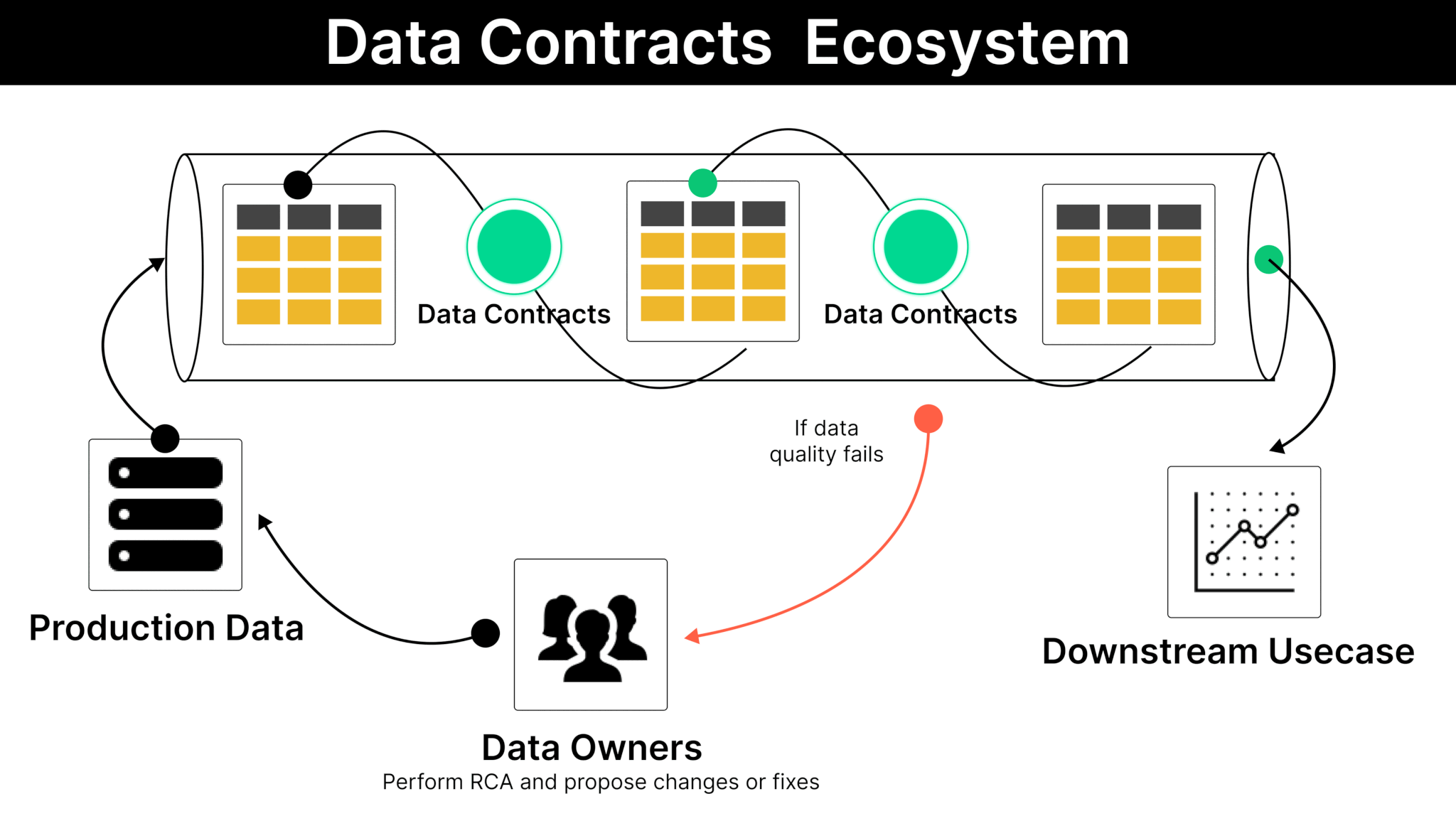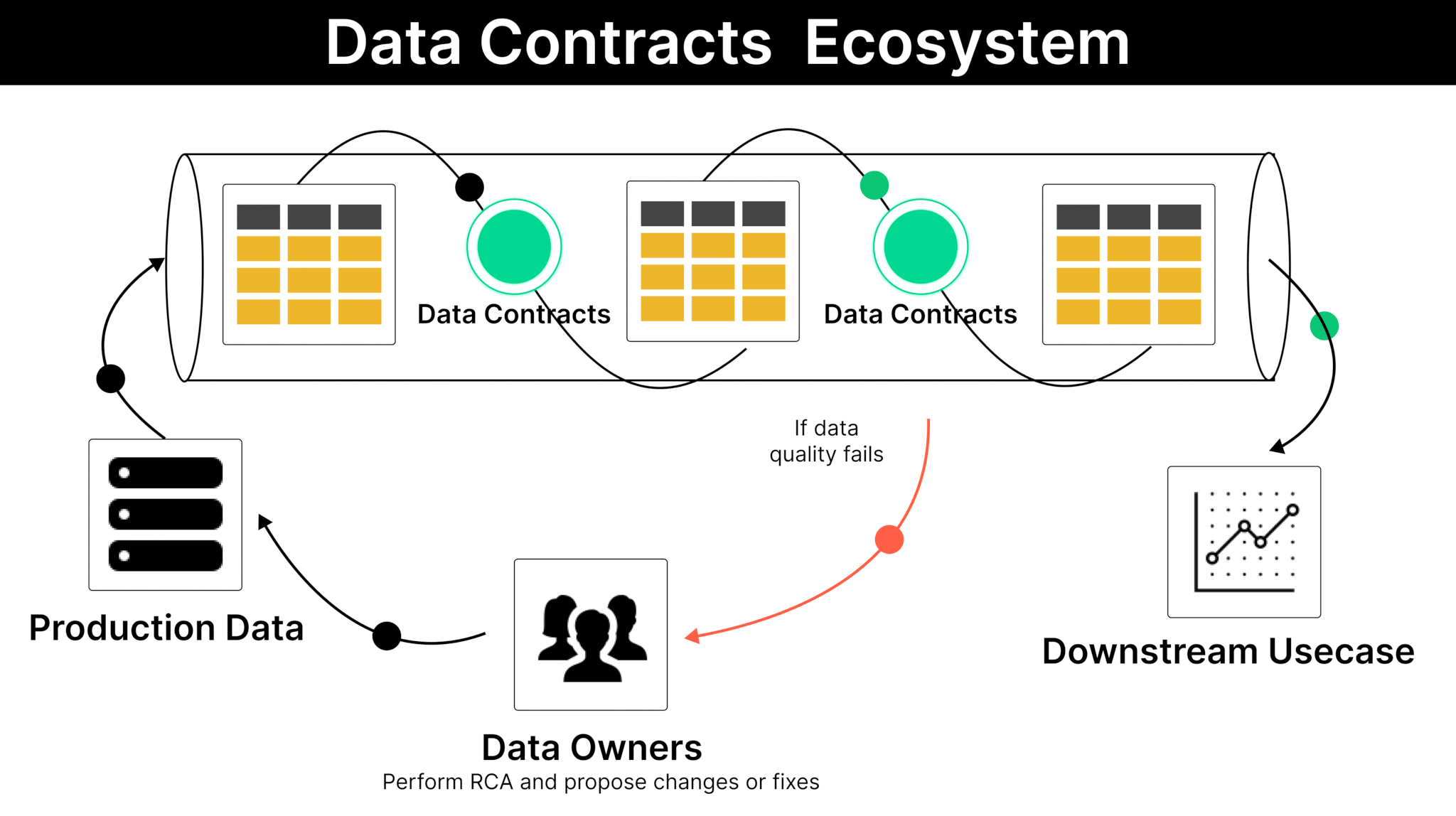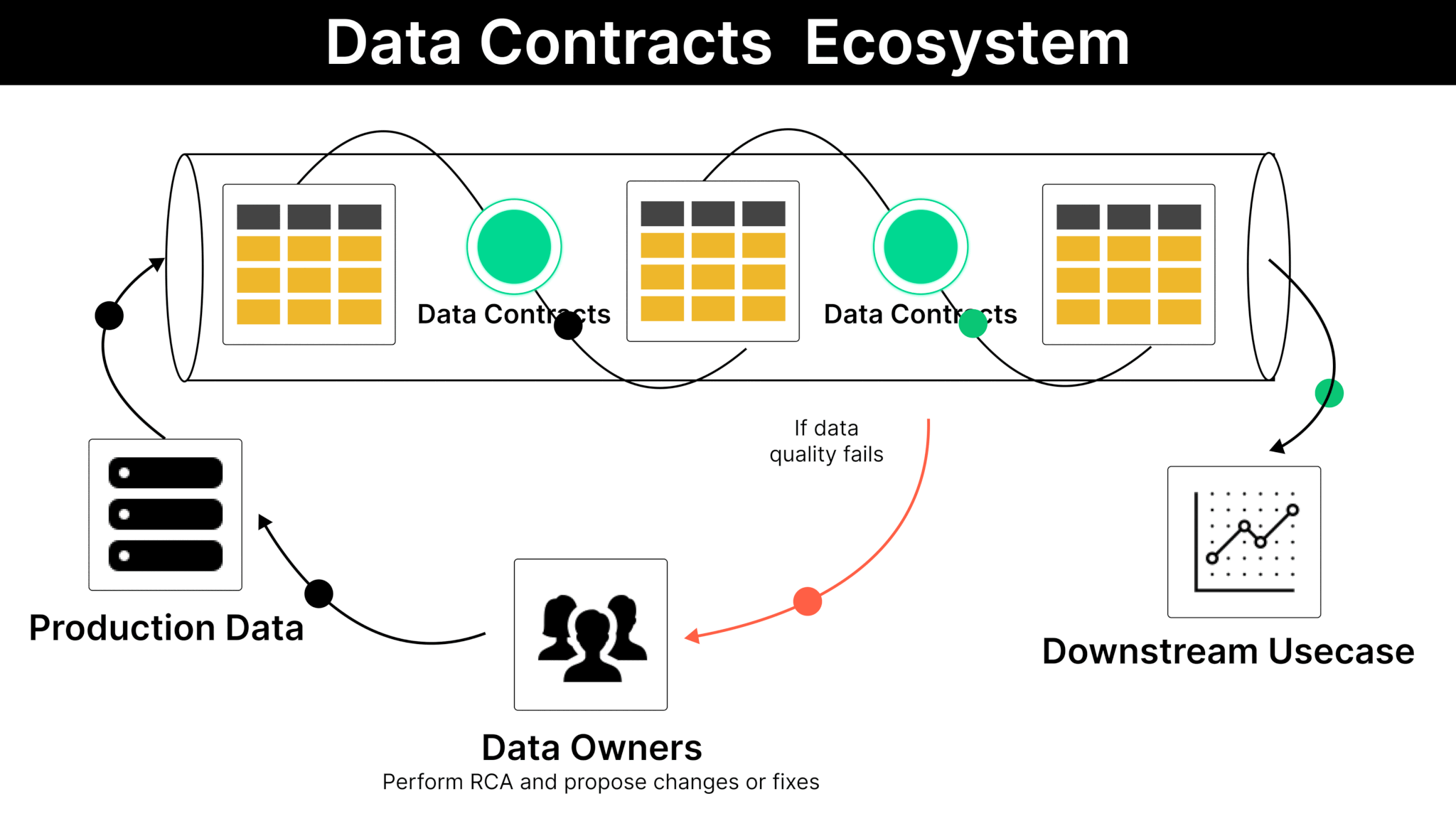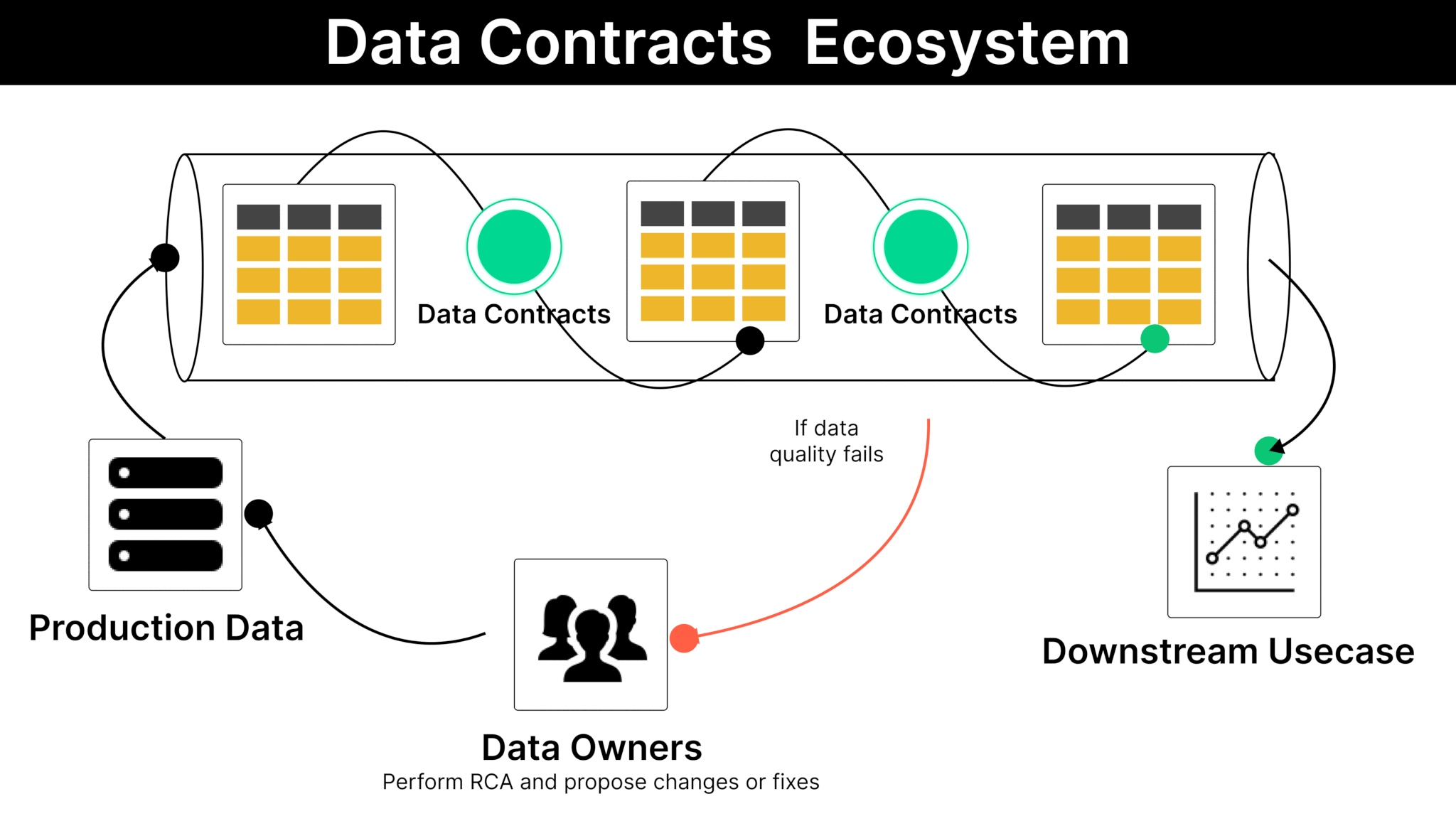
Data Contracts vs Quality Tests and Observability
Data contracts, tests, and observability all live in the same ecosystem, but they solve slightly different problems.
Contracts are about explicit promises at the boundary between producer and consumer.
Tests and observability are about detecting and diagnosing issues in runtime behavior.
If you only have tests, you are mostly reactive. If you only have contracts, you miss a lot of real-world anomalies. The sweet spot is using both — contracts to prevent structural and rule-based breaks, and observability to catch freshness, volume, and distribution drift.
Contracts: proactive guarantees
Contracts are strongest when they:
Sit close to the producer (shift-left), validating data as it is produced.
Cover non-negotiables: schema, types, key quality expectations, critical business rules.
Are reviewed and agreed by both sides (producer and consumer teams).
They answer: “What must always be true before you send this data downstream?”
Observability: runtime detection
Observability complements contracts by:
Measuring freshness (is this table updated on time?).
Tracking volume shifts (sudden spikes or drops).
Monitoring distribution changes (e.g. customer country mix, null patterns).
They answer: “Is the data behaving normally over time?”
Comparison table
Here’s how the two approaches line up:
Aspect | Data Contracts | Observability |
|---|---|---|
Primary goal | Prevent incompatible or low-quality data at the boundary | Detect and understand issues in live data |
Focus | Schema, types, constraints, semantics, ownership | Freshness, volume, distribution, performance |
When they run | Before or at ingestion / interface points | Continuously in production, often across many datasets |
Who owns them | Shared between producers and consumers, often product / domain | Data platform, reliability, and analytics engineering teams |
Ideal usage | Tier 1 data products; critical producer–consumer interfaces | Broad coverage across warehouses, lakes, and BI layers |
In Soda | Contracts defined in YAML/UI, enforced by Soda in pipelines | Monitors, and alerts defined in Soda and run continuously |
Use contracts as your guardrails, and observability as your radar. If you want a deeper dive on how the two reinforce each other in practice, see our article on “contracts + testing together.”
The Building Blocks of a Good Data Contract
Before you roll out contracts widely, it helps to standardize what “good” looks like for your organization.
For each contracted dataset, aim to capture at least:
Schema and shape
The canonical list of columns, their data types, and primary keys.
Any composite keys that must be unique together.
Optionality and defaults
Which fields are mandatory (no nulls allowed).
Which fields may be missing for some records, and under what conditions.
Quality rules
Valid value sets (e.g. order_status ∈ {PENDING, SHIPPED, CANCELLED}).
Ranges and thresholds (e.g. price ≥ 0, discount between 0 and 1).
Format checks (e.g. ISO date, email format).
Deduplication rules and collision policies.
Soda’s AI and UI-based workflows help you fill in many of these pieces from existing tables and checks, so you are not designing everything from scratch.
How to Implement Data Contracts with Soda (Step-by-Step)
Think of this as your operating model for contracts. You can start with a single domain and a handful of Tier 1 data products, then expand. If you want a video guide besides the steps we will outline below, just click the link.
Step 1. Choose where contracts matter first
Start where a break really hurts:
Regulatory or financial reporting tables.
Core domain objects such as customers, orders, accounts.
High-traffic interfaces between teams (e.g. product events flowing into analytics).
Make a short list of Tier 1 datasets. For each one, identify:
Producer team and point person.
Key consumer teams (and their main use cases).
Any known pain from schema changes or quality drift.
These are your pilot contracts.
Step 2. Generate your first contract draft in Soda
Next, get a first version out of your head and into Soda.
Connect Soda to the data source that holds your chosen table.
Use Soda’s contract capabilities (UI and YAML) to pull in the current schema as a starting point.
Let Soda’s AI helpers suggest checks and constraints based on sample data and patterns — for example, inferring which columns look like IDs, emails, or enums.
You should now have a minimal, but concrete, draft that covers:
Dataset identity.
Column list with types.
A handful of obvious checks (non-null keys, basic ranges, uniqueness).
Resist the urge to over-specify everything on day one. You can tighten rules iteratively as you learn.
Step 3. Tighten the contract with producers and consumers
A contract only works if both sides can live with it.
Run a short, focused session with:
The producer team (often data or platform engineers).
Key consumers (analytics, ML, finance, product analysts).
A governance or steward role if you have one.
Walk through the draft and agree on:
Which fields are truly required and which can be optional.
Critical business rules that must be encoded (e.g. “every order must have a customer_id that exists in the customer table”).
Tolerance levels: e.g. is 0.1% invalid values acceptable, or must it be 0?
How strict to be in the first phase (warn vs block).
Soda’s collaborative model — engineers editing YAML in Git, business users adjusting rules in the UI — keeps everyone in a shared workflow, with proposals and diffs visible on both sides.
By the end of this step, your contract is something people recognize as “the way this dataset is supposed to behave”, not just an engineering artifact.
Step 4. Wire contracts into your pipelines
A contract that never runs is just a document.
Connect contracts to the places where data actually moves:
Batch pipelines
Use Soda Core and the contracts capabilities to execute contract checks as part of ingestion or transformation jobs.
Run them right after data is produced, before it flows downstream.
Development and CI/CD
Integrate Soda checks into your GitHub workflows or other CI tools, so contract violations block or flag pull requests that would introduce a breaking change.
Decide how strict you want to be:
In dev, you might start with warnings and visible comments on pull requests.
In production, you might quarantine data or stop downstream jobs if Tier 1 contracts fail.
The key principle: new data must prove it respects the contract before everyone else treats it as trustworthy.
Rollout Checklist (per data product)
Use this as a quick check every time you add a new contract:
Tier 1 dataset identified with a clear producer and main consumers.
Data owner and technical owner assigned and discoverable.
Contract reviewed and agreed by producer + consumer reps.
Contract hooked into at least one pipeline stage (ingestion or transformation).
Alerts mapped to the right Slack channel / incident system.
Behavior on failure defined (warn, block, quarantine).
Contract and its status visible in your catalog or governance portal.
If you can’t tick most of these, the contract is not really “live” yet.
Step 5. Turn on automated enforcement and routing
Now you can close the loop between policy and reality.
In Soda:
➡ Configure how each contract failure should behave for a given dataset:
Warn only (log and alert) for less critical datasets.
Hard fail (stop downstream processing) for Tier 1 datasets.
➡ Set up alert routing based on ownership metadata in the contract, so incidents automatically go to the right team or on-call rotation.
➡ Standardize incident labels and severities (P1 for regulatory data, P2 for product analytics, etc.).
From this point on, producers see the effect of contract violations immediately — in their pipelines, in their CI checks, or in their incident channels — instead of days later via a broken report.
Step 6. Reuse and scale: contract templates and patterns
Once a few contracts are working, you want consistency instead of bespoke designs everywhere.
Look for patterns and create templates, for example:
“Customer master” contract pattern used by multiple regions.
“Event stream” contract pattern for product telemetry tables.
“Financial fact” contract pattern for revenue and cost tables.
Each template can define a standard set of:
Required columns (e.g. id, created_at, updated_at).
Standard checks (non-null keys, no duplicates, freshness).
Recommended governance fields (owner, domain, Tier level).
As you roll these patterns to more teams and domains, you’ll quickly run into questions of scale: hundreds of contracts, automated rollout, centralized visibility. That’s where a dedicated approach to scaling contract enforcement becomes useful, covering promotion workflows, bulk updates, and cross-domain reporting.
Step 7. Make contracts visible to consumers
Contracts shouldn’t be something only engineers know about.
Make them easy to find for consumers by:
Surfacing contract status (last run, last failure) in your catalog or governance portal.
Linking from dashboards back to the underlying contract for the source table.
Letting business users subscribe to alerts for the datasets they care about most.
For many consumers, the practical question is simple: “Can I rely on this dataset today?” Contracts, combined with Soda’s run history and incident timelines, let you answer that with evidence instead of hope.
Step 8. Measure, review, and iterate
Finally, treat contracts as a product, not a project.
Track a small governance-style scorecard:
Contract coverage across Tier 1 datasets.
Number of contract violations per month (and per dataset).
Breaking change rate before vs after contracts.
Mean time to detect and resolve contract-related incidents.
Review this regularly in your data council or platform forum. As you add new domains or data products, use the same metrics so you can compare progress.
Collaborating on Data Contracts: Business + Engineering
Soda is designed for a world where:
Engineers are happiest editing versioned files in Git.
Business and governance users are happiest in a UI.
Everyone still needs to talk about the same contracts.
In practice that looks like:
Single contract, multiple views
Engineers see a YAML or declarative representation they can review, lint, and test.
Business users see an interface where they can propose changes, adjust thresholds, or comment on rules.
Versioned proposals and diffs
Any change to a contract is a proposal with a diff.
Approvals are explicit; audits can see who changed what, when, and why.
Commenting and discussion in context
Questions about a specific check live with that check, not in random chat threads.
Decisions about relaxing or tightening a rule are captured next to the contract, not lost in email.
This shared workflow is what turns contracts from “yet another engineering file” into an everyday tool for product managers, analysts, and governance teams.
Implementing Contracts in Modern Stacks
The patterns stay the same even as underlying platforms differ.
Snowflake, BigQuery, PostgreSQL
Run Soda contract checks as part of ingestion or transformation jobs targeting these warehouses.
Attach contracts to dbt models or similar transformations so each model has a clear, enforced contract at its output boundary.
Use CI (e.g. GitHub Actions) to run checks when models change, not just nightly.
Databricks and Spark
Integrate contracts at the notebook, job, or Delta Live Table layer, where data is produced and transformed.
Use Soda’s Spark support to validate contracts close to compute, and rely on lineage to understand downstream impact when something fails.
For a deeper walkthrough of this pattern, including observability and runtime monitoring, see our guide on “contracts in modern stacks” for Databricks.
Orchestration and CI/CD
Treat contract checks as first-class tasks in Airflow, Dagster, or your orchestrator of choice.
Combine runtime checks with Git-based validation in CI so both code changes and data changes are policed consistently.
As you exceed a handful of data products, you’ll need to think explicitly about scaling contract enforcement: common templates, bulk changes, rollout strategy, and central reporting across hundreds of contracts. That’s where platform-level patterns and tooling make the difference between a neat pilot and a sustainable practice.
How to Tell If Your Contracts Are Working
You know your contract program is doing its job when:
Contract coverage is high for Tier 1 datasets, and growing for Tier 2.
Incident volume from schema and rule violations goes down quarter over quarter.
When incidents do happen, they are caught at the producer boundary, not by end users.
Breaking change rate — incidents caused by schema or semantic changes — is visibly lower than before contracts.
Producers start asking for contracts proactively because they see them as protection, not red tape.
A simple monthly dashboard that tracks:
Number of active contracts.
Violations per contract per period.
Time from violation to acknowledgement and fix.
Number of blocked vs warning-only contract failures.
…is usually enough to steer improvements and justify further investment.
Schedule a talk with our team of experts or request a free account to discover how Soda integrates with your existing stack to address current challenges.
Frequently Asked Questions
Do we need data contracts for every dataset?
No. Start with Tier 1 data products — the tables and streams where a break has real business or regulatory impact. As your patterns and tooling mature, you can extend contracts to Tier 2 datasets where they add clear value.
Are contracts only for batch data, or do they work for streaming too?
The principle is the same for both: data must prove it respects the contract before consumers rely on it. For batch, that usually means checks at the end of a job. For streaming, it often means near-real-time checks at the interface between producer and storage, or before aggregations.
What happens when a producer needs to change the schema?
In a contract-first setup, schema change is a change to the contract. The producer proposes a new version (for example, adding a column or relaxing a constraint), consumers review and approve it, and Soda enforces the new version once agreed. CI checks catch incompatible changes before they land in production.
How are contracts different from just adding more tests?
Tests are isolated checks. A contract is a coherent bundle of schema, rules, semantics, and ownership that defines the boundary between teams. You can have lots of tests without a clear agreement on what a dataset represents or who is responsible; a contract fixes that.
Can Soda data contracts work without Soda Cloud?
Soda’s contract engine is built to run programmatically in pipelines using Soda Core, and can integrate with your existing CI/CD and orchestration. Soda Cloud then adds collaborative UI Contract Copilot feature to write them or edit them with AI, history, and governance views on top. You can start programmatically and add Cloud when collaboration becomes the bottleneck.
How hard is it to get started with data contracts?
For a pilot, you typically need one producer team, one or two key consumers, and a single Tier 1 dataset. With Soda’s AI-powered suggestions and shared UI+Git workflow, writing a first contract and wiring it into a pipeline is usually measured in days, not months — and the first time a contract blocks a breaking change, the value becomes obvious.











