
Most data governance programs fail for a simple reason.
They stop at defining the policy.
You get a slide deck that defines principles, committees, a data dictionary, a glossary, and maybe a new business term approval workflow. But no one can show that the policy is adhered to in production data. There is no loop that connects policy to execution.
This guide is for teams that want a data governance framework that lives in everyday work. One that makes data more trustworthy, not just more documented.
We will cover:
What a data governance framework is and is not
The core components every practical framework needs
An 8-step implementation plan you can copy
How to operationalize governance with real checks and alerts
A simple maturity model and KPI starter set
How Soda puts this into practice
Key Takeaways |
|---|
|
What a data governance framework is (and is not)
A data governance framework is the operating model for how your company manages, secures, and uses data. It defines the roles, responsibilities, policies, and processes that keep data accurate, safe, and aligned with business goals.
Simply put:
A data governance framework is how you decide who owns which data, what “good” looks like, how you keep it that way, and how to improve it.
Governance is more than a catalog
A data catalog or data governance solution is important. It helps people find data and understand definitions. But a catalog without clear ownership, responsibilities, and checks in production is just a better organized library.
Your framework should answer questions like:
Who can approve a change to a key metric or field
Which policies apply to customer data in a specific domain
How issues are raised, triaged, and fixed
How you know if governance is working
Governance is not a one-time project
Many teams treat governance as a time-bound initiative focused on producing artifacts such as catalogs, policies, and documentation. The real risk is trying to “boil the ocean” — investing heavily in documenting everything rather than enabling the business to deliver critical data and AI initiatives successfully.
Effective governance behaves more like product management. You start small, prioritize what delivers immediate value, ship something that works, measure usage and impact, and iterate.
This is why you will see a maturity model and KPIs later in this guide. They keep you honest about progress.
Governance and data quality go together
Governance and data quality sit in a loop. Governance defines the rules and ownership. Data quality measures whether those rules hold in real data. Many of those who do data governance actually do it to improve data quality.
If you are still deciding which to start with, this article on data quality vs data governance explains why you usually need both in parallel.
Core components of a practical governance framework
Before you launch, create a components map of your data governance framework. Think of it as the blueprint that connects people, rules, and technology.
Here are the components to include.
1. Decision rights
Clarify who can approve which decisions about data. For example:
Who approves the creation of a new certified dataset
Who signs off on a data retention policy
Who can deprecate a widely used KPI
Keep it simple. Use a short list of decision types and assign them to roles, not individuals, so you can adapt as people change.
2. Roles: owners, stewards, engineers
Define a small set of roles that appear across domains:
Data owner
Accountable for business use of the data
Decides what “good enough” looks like
Escalation point for risk and exceptions
Data steward
Manages definitions, policies, and access within a domain
Coordinates with engineers on implementation
Technical owner
Usually an engineering or platform role
Implements controls, tests, and monitoring in tools and pipelines
These roles will show up again when we build the RACI matrix in the implementation steps.
3. Policies and standards
Policies and standards turn governance principles into rules. Start with three core families.
Metadata standards
Business terms, KPIs, and critical field definitions
Documentation describing how data is created and maintained, including systems of record and data lineage context
Access and retention
Who can access what and under which conditions
Retention rules based on data classification, regulatory requirements, and business value
Quality and certification
Minimum requirements for completeness, accuracy, timeliness, and other quality dimensions
Criteria that determine how data progresses across layers (for example, bronze, silver, and gold) and when data is considered trusted for business use
Keep policies short and specific. A good policy is easy to translate into automation.
4. Processes
Processes tell people what to do when something changes or breaks. At minimum, define:
Change management
How you propose, review, and approve schema or metric changes
Impact analysis before a breaking change ships
Issue management
How users raise data incidents
How you prioritise and assign them
Escalation paths
When an issue affects compliance or revenue, who gets the call
How you communicate with leadership
These processes can be light at first. The important part is that people know which path to follow.
5. Technology
Most teams already have some tools that do some data governance in place, such as a warehouse, a catalog, or a ticketing system. The framework connects them.
For a modern stack, you typically need:
A data catalog or governance solution to store definitions, ownership, and policies
Data lineage to understand how changes and issues flow across systems. If you want a primer, use this guide to data lineage for governance
Access controls at the warehouse and analytics layer
Quality enforcement tools that can express policies as checks and run them continuously, not only in ad hoc investigations
What’s really good? Governance teams can define policies in catalog tools, then execute them as automated checks in Soda, which turns documentation into actionable validation and alerts.
6. Metrics
Finally, decide how you will measure governance itself. A framework is only working if you can show improvements in:
Adoption of governed data
Trust in key datasets
Speed and safety of changes
We will cover specific KPIs later. For now, just note that metrics belong in the framework from day one, not as an afterthought.
The 8-step implementation plan
You do not need a huge team to get started. You do need a clear sequence.
Here is an 8-step plan you can copy and adapt.
Step 1. Define outcomes
Start with three to five outcomes that matter to leadership. Examples:
Reduce regulatory or privacy risk
Increase trust in metrics for board-level reporting
Shorten the time it takes to onboard new analysts or data products
Write each outcome in a one-line format:
Because we govern data better, we will achieve X for Y audience, measured by Z.
These outcomes will shape your policies, KPIs, and roadmap.
Step 2. Scope domains and Tier 1 data products
Do not try to govern everything. Pick domains and Tier 1 data products.
A domain is a business area, such as Sales, Finance, Risk, or Product Analytics.
A Tier 1 data product is any dataset or report that, if wrong, hurts customers, revenue, or compliance.
Select one or two domains and a short list of Tier 1 products inside them. Everything in this guide can be piloted there first.
Step 3. Establish governance bodies
You now need a lightweight structure of committees or forums. Typical examples:
Enterprise Data Council
Meets monthly
Sets overall priorities and approves cross-domain policies
Includes a C-level sponsor, domain owners, and platform leadership
Domain governance groups
Meet weekly or every two weeks
Review issues and proposed changes within a domain
Own the backlog of governance work
Keep meetings short and focused on decisions, not status updates. Use written proposals for policy or ownership changes so decisions are traceable.
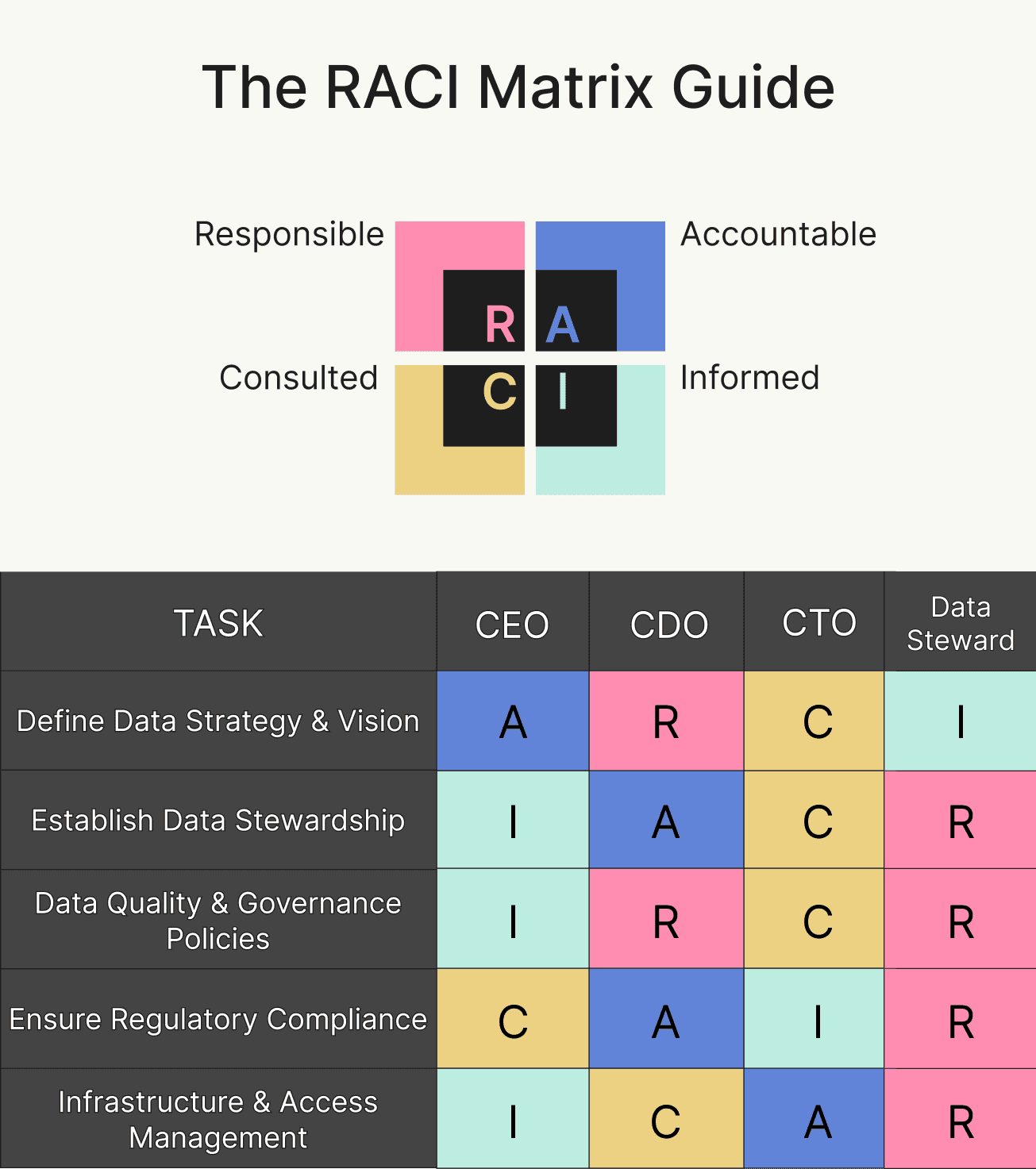
Step 4. Assign roles and RACI
For each Tier 1 data product, assign clear roles. Then document them in a simple RACI matrix.
Responsible
Usually data engineers or analytics engineers
Build and maintain the pipelines or models
Accountable
Data owner for the domain
Final sign-off on business meaning and quality thresholds
Consulted
Stewards, security, risk, or compliance stakeholders
Informed
Downstream data consumers
You can design RACI matrices at the activity level, not only by dataset. For example, “approve new access”, “accept a schema change”, or “define retention period”. That approach keeps responsibilities very concrete.
Step 5. Define policies and standards
Now pick an initial set of policies. Resist the urge to write a full playbook. Start with three policy families and a handful of specific statements in each.
Definitions
Example: “There is one certified definition of active customer, owned by the Sales data owner. Any change to this definition requires sign-off from Finance and Product owners.”
Access
Example: “Only customer success and support roles can see full customer contact details. All others see masked values in analytics datasets.”
Quality
Example: “For the Tier 1 Revenue Reporting dataset, daily completeness must be at least 99.5 percent, and any deviation triggers a P1 incident.”
Keep policies in the same place as your metadata, ideally in your catalog or governance solution, not in a separate document repository.
Step 6. Implement metadata and lineage
To govern anything, you need to see it. That visibility starts with metadata and lineage.
Focus on:
Ownership and documentation in the catalog
Every Tier 1 dataset should have an owner, steward, purpose, and contact channel.
Technical lineage
Connect tables, pipelines, and BI dashboards so you can answer “What breaks if we change this field” in minutes.
Business lineage
Link data to processes, regulations, and reports. For example, “This table is the source for our regulatory capital calculation.”
If you are new to lineage, share a simple primer like data lineage for governance with teams so you have a shared language.
Step 7. Operationalize policy enforcement
This is the step many teams skip. They define policies but never translate them into checks that run against real data.
You need a repeatable loop:
Policy
Example: “Customer records for EU residents must not include unencrypted national identifiers.”
Contract or rule
Express this as a data contract or quality rule in your catalog or governance solution.
Check
Implement the rule as an automated test in a tool such as Soda. For instance, “no values in column X may match pattern Y”.
Alert
Configure alerts to route incidents to the right channel, mapped to the RACI assignments.
Remediation
Define playbooks for common failures. Some can be automated, others may require a human decision.
This is also a good moment to explore dedicated data governance tools and data governance solutions that make policy execution easier. Many teams integrate catalog platforms like Collibra with Soda so governance rules flow directly into executable checks and monitoring. You can see an example of this in how teams operationalize governance with enforcement.
Step 8. Measure and iterate
Finally, build a small governance scorecard. Track it every month and review it with your data council.
You can use the KPI starter set below, grouped into:
Adoption
Trust
Change and risk
Use the scorecard to drive decisions on staffing, new data governance tools, and policy changes. When you add a new domain, use the same scorecard so results stay comparable.
How to operationalize governance in real stacks
Most governance programs stall between steps 5 and 7. Policies exist, but they sit in documents. Engineers and analysts keep working in their own tools, and data issues are still discovered by angry dashboard users.
To avoid that gap, treat enforcement as a shared workflow between governance and engineering.
A simple example loop:
Governance team defines a quality rule in the catalog.
The rule is synced to Soda as a check in a Data Contract for a given table or column.
Soda runs checks as part of pipelines or continuous monitoring.
If a check fails, Soda raises an alert in the team’s incident channel.
The owner and responsible engineer triage, fix, and document the outcome in the catalog.
Over time, this loop gives you something that policy documents never can: evidence. You can show which policies are enforced, where they fail, and how quickly you respond. That is the difference between “we have a policy” and “we run a governed data platform”.
A simple data governance maturity model
Use this lightweight maturity model to explain progress to non-technical leaders.
Level | Name | What it looks like |
|---|---|---|
0 | Ad hoc | Data issues handled case by case. No shared definitions, ownership, or processes. |
1 | Policy aware | Some policies and a catalog exist, but enforcement is manual and inconsistent. |
2 | Connected | Domains, owners, and councils are in place. Key datasets have checks and alerts. |
3 | Operational and automated | Policies, lineage, quality checks, and access controls are integrated in tools. |
Most organisations move from level 0 to level 2 in their first one to two years. Level 3 is an ongoing journey, not a project milestone.
KPIs to prove governance is working
You cannot manage what you never measure. Here is a starter set of governance KPIs you can track from day one.
Adoption KPIs
Catalog usage: Number of monthly active users in the catalog or governance portal
Certified dataset coverage: Percentage of key reports that are built on certified datasets
Owner coverage: Percentage of Tier 1 datasets with an assigned owner and steward
Trust KPIs
Data incident rate: Number of high-impact data incidents per month or quarter
Mean time to resolve (MTTR): Average time from detection to resolution for data incidents
Policy compliance rate: Percentage of automated checks that pass for Tier 1 datasets
Change and risk KPIs
Breaking change rate: Percentage of schema or metric changes that cause downstream issues
Change lead time: Average time to move a governed change from proposal to production
Contract compliance: Percentage of data contracts with all required checks implemented
Start small. Pick two adoption metrics, two trust metrics, and one change metric. Put them on a simple dashboard. Use that dashboard in every governance council meeting.
How Soda does it
Soda sits in the middle of this framework. It connects the world of policies and ownership with the world of pipelines, tables, and dashboards. Here is how Soda supports each part of the model.
Turning policies into executable checks
Governance teams define rules for quality, access, and critical fields. Soda turns those rules into:
Human-readable checks that describe what “good” data looks like
Automated tests that run inside data pipelines or on a schedule
This means a policy such as “no personal email addresses in this dataset” becomes a concrete rule that runs against every new batch or every new row, not just a note in a wiki.
Continuous monitoring for Tier 1 data products
Soda lets you mark certain datasets as more important and then monitor them more closely. For your Tier 1 data products, you can:
Attach stricter checks and thresholds
Run validations more frequently
Route alerts to dedicated channels or on call rotations
This matches the idea of Tier 1 data products in the framework and keeps the focus on where issues hurt most.
Integration with catalogs and governance tools
Most organisations already invest in a catalog or governance platform. Soda connects to those tools, so you do not create yet another silo. For example:
Policies defined in a catalog can be translated into Soda checks
Ownership information can drive alert routing, so incidents go straight to the accountable team
Lineage information can help you understand the blast radius of a failed check
The post on how teams operationalize governance with enforcement shows this in more detail with Collibra.
Evidence for councils and auditors
Every check Soda runs leaves a trace. Over time, you build a rich history of:
Passed and failed checks
Frequency and severity of incidents
Time to detection and resolution
This history turns into concrete evidence for your governance council, for risk and compliance teams, and for auditors. Instead of saying “we believe our data quality is high”, you can show trends and concrete numbers.
Helping teams collaborate on data quality
Soda isn’t only for engineers. Business users, data stewards, and data owners can:
See the status of key datasets at a glance
Subscribe to alerts for the data they care about
Comment on incidents and document decisions
That shared view is what makes governance part of everyday work—not something that shows up once a year in a policy review.
And it’s collaborative: engineers and business users can define and evolve the rules together. Engineers run checks as code, while business teams participate in the UI—so data contracts stay both enforceable and understandable.
Frequently Asked Questions
Do we need a Chief Data Officer before we start governance?
No. You can start with an executive sponsor who feels the pain from bad data, plus a small cross-functional group that can give governance some focused time. A future CDO can then build on this foundation.
What is the minimum team size?
For a pilot, you usually need one data or product leader who acts as data owner for a domain, one steward who cares about process, definitions, and policies, and one engineer who can implement pipelines and quality checks that enable visibility into lineage. All of them can do this part-time if the scope is narrow.
How long before we see value?
If you focus on one domain and a short list of Tier 1 datasets, you should see value within one quarter in the form of fewer incidents, faster resolution, and more confidence in key reports.
How do ISO or NIST style frameworks relate to this approach?
ISO and NIST provide high-level principles and control families. The eight-step plan in this guide is a practical way to apply them. You can later map each step to specific clauses so your operating model doubles as compliance evidence.











