


This blog is based on a recent joint webinar where we walked through how Soda integrates with Databricks to implement, run, and monitor Data Contracts end-to-end. If you prefer a live walkthrough of the concepts and demos covered here, you can watch the full webinar recording here.
In this article, we’ll distill the key ideas, architectural patterns, and practical steps — from understanding the Databricks platform, to connecting Soda, defining Data Contracts, running them in pipelines, and analyzing results directly inside Databricks.
Introduction to Databricks
Over the last two to three years, Databricks platform has evolved from a data warehouse to a comprehensive data intelligence platform.
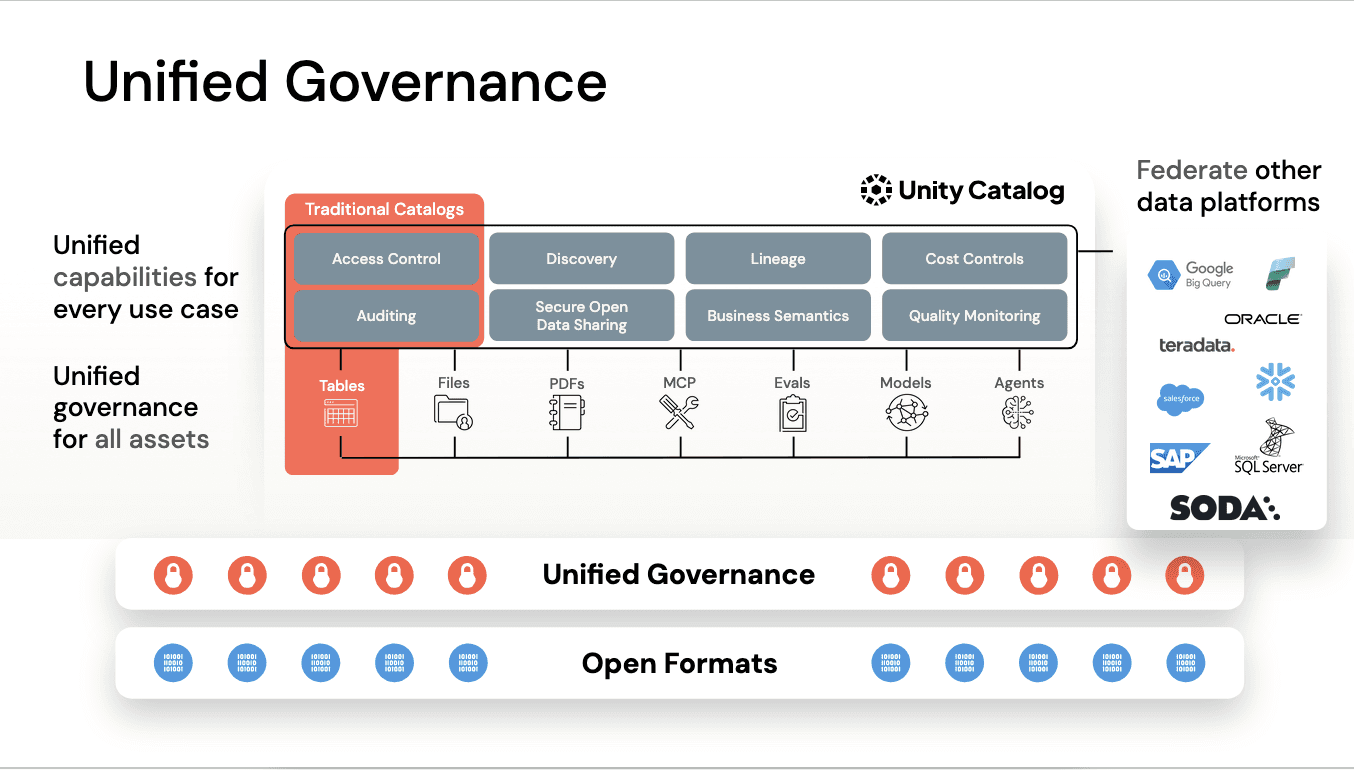
Databricks ensures governance across your data with Unity Catalog, which integrates with Soda.
From there, you can use Databricks for multiple workloads. Key examples include LakeFlow for ingestion, ETL, and streaming; dbSQL for SQL analytics; and LakeBase for applications with write-intensive workloads.
Underlying all of this is Agent Bricks, which helps optimize your environment and enables AI use cases.

Introduction to Soda
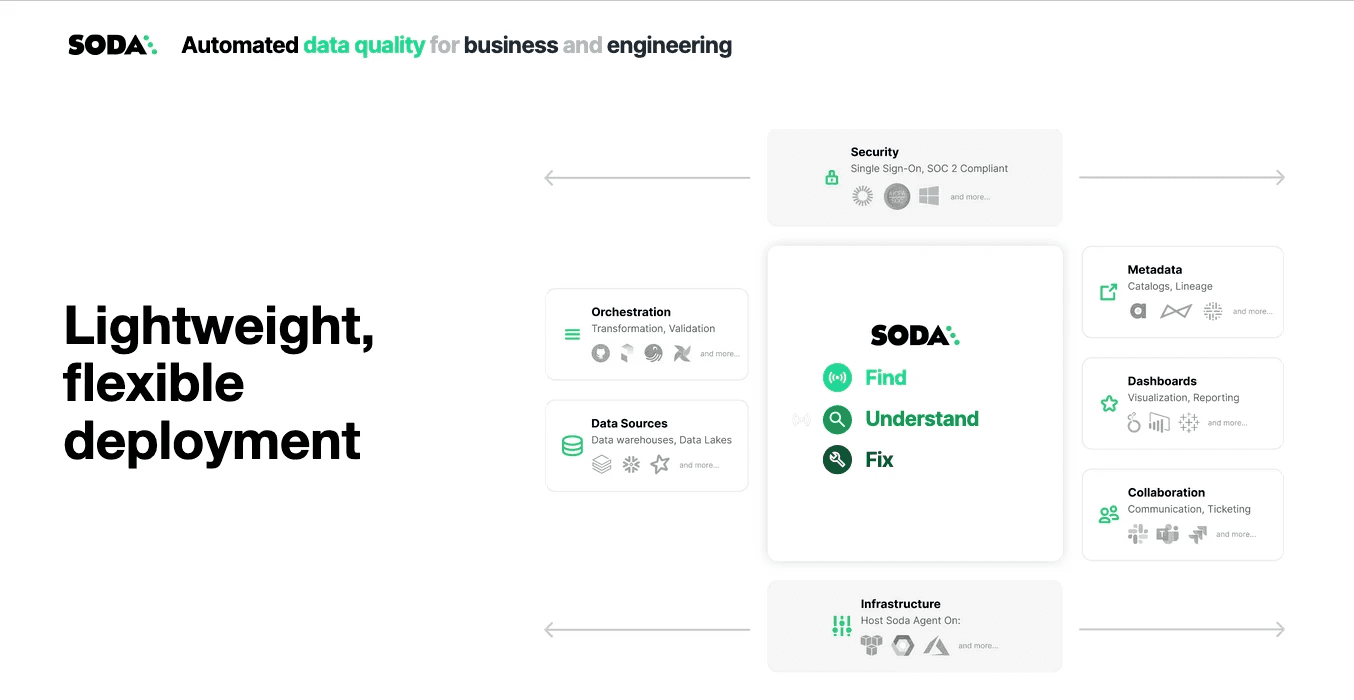
Soda is an end-to-end data quality platform designed to help you find data quality issues, understand them, prioritize them, and ultimately fix them — even at the record level. Soda is highly integrated, flexible, lightweight, and easy to deploy. It uses a hybrid deployment model: a cloud-based UI acting as the control plane and dashboard, while the core data quality engine runs within the customer’s private cloud.
Soda connects to various data sources, including data warehouses, SQL databases, and data frames, enabling the monitoring of all structured data, including file- and API-based data. In Databricks, you can connect through SQL Warehouse or directly to Spark sessions within your Databricks notebooks jobs.
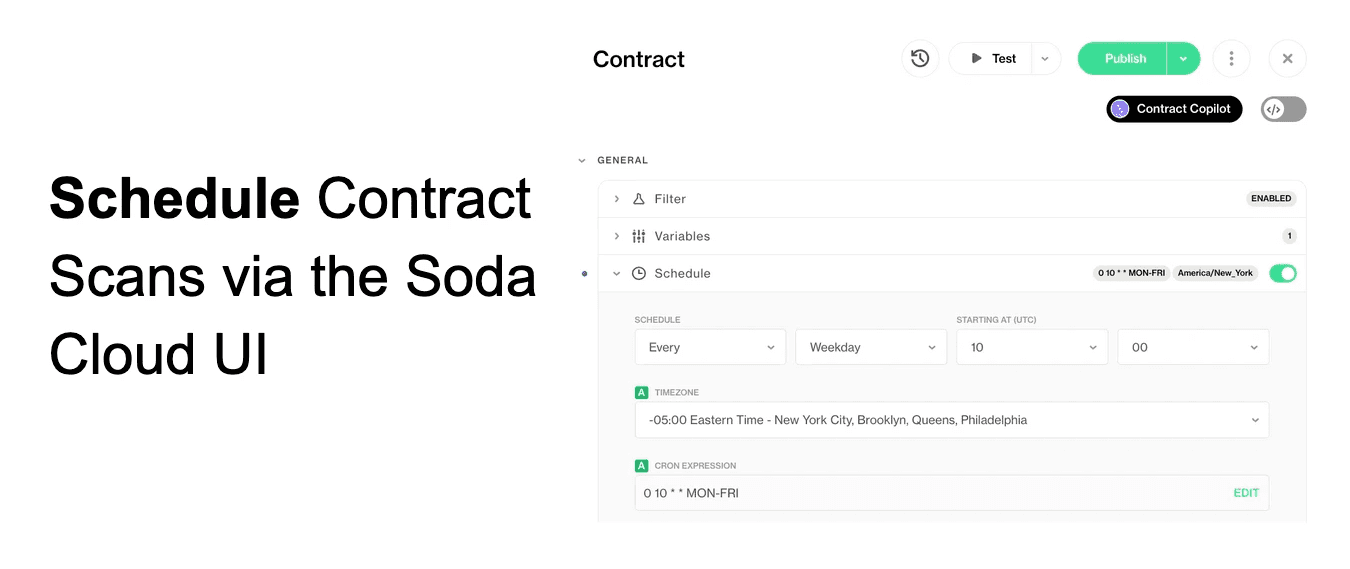
Scans can be easily orchestrated by setting a schedule in the Soda Cloud UI or by triggering scans from your existing pipelines and workflows using the Soda Python package.
From a security standpoint, Soda is SOC 2 Type 2 compliant, supports single sign-on, and role-based access control. It also integrates with metadata catalogs, BI tools, and communication or ticketing platforms like Slack, Jira, and ServiceNow.
Connect Soda to Databricks
One method is through SQL Warehouse, which can be configured entirely through the Soda Cloud UI.
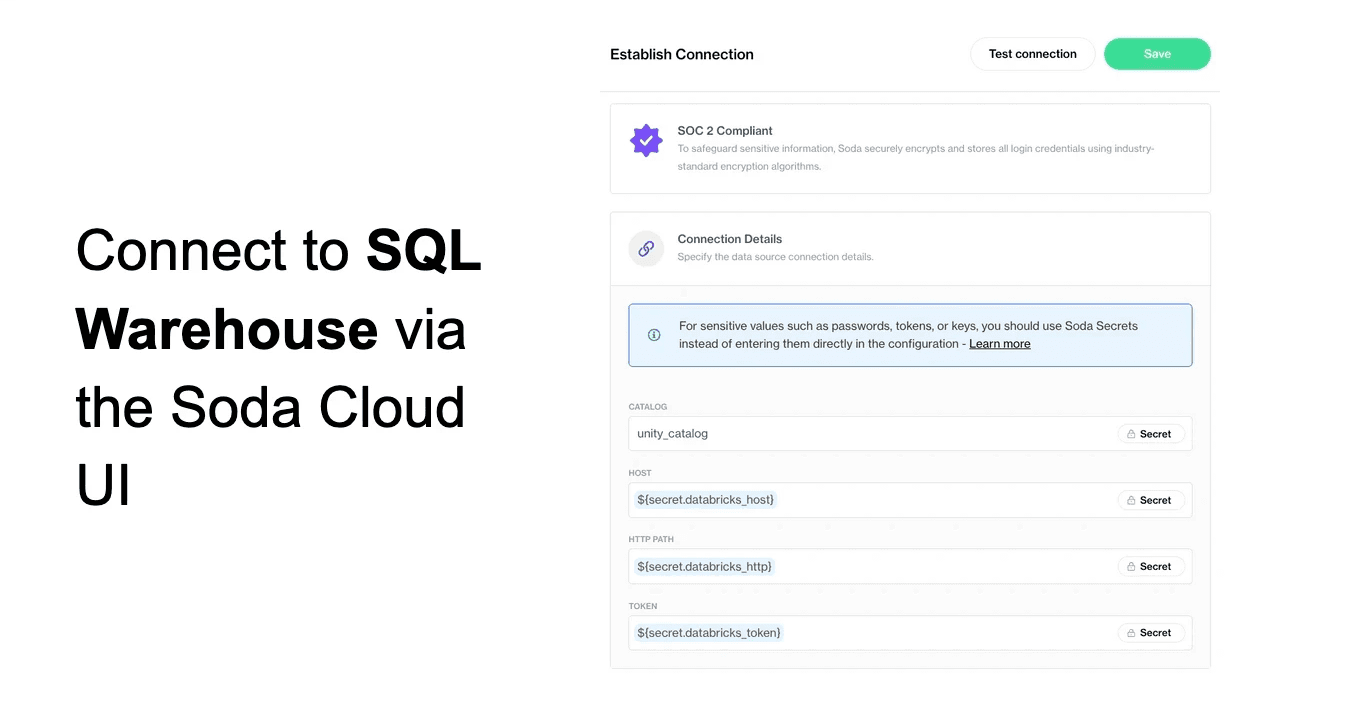
You select your Soda agent, provide connection details, and manage everything through the UI in a self-service manner.
Alternatively, you can use the Soda Core Python package to connect directly to Spark sessions, allowing programmatic data quality testing of spark dataframes in Databricks notebooks and workflows.
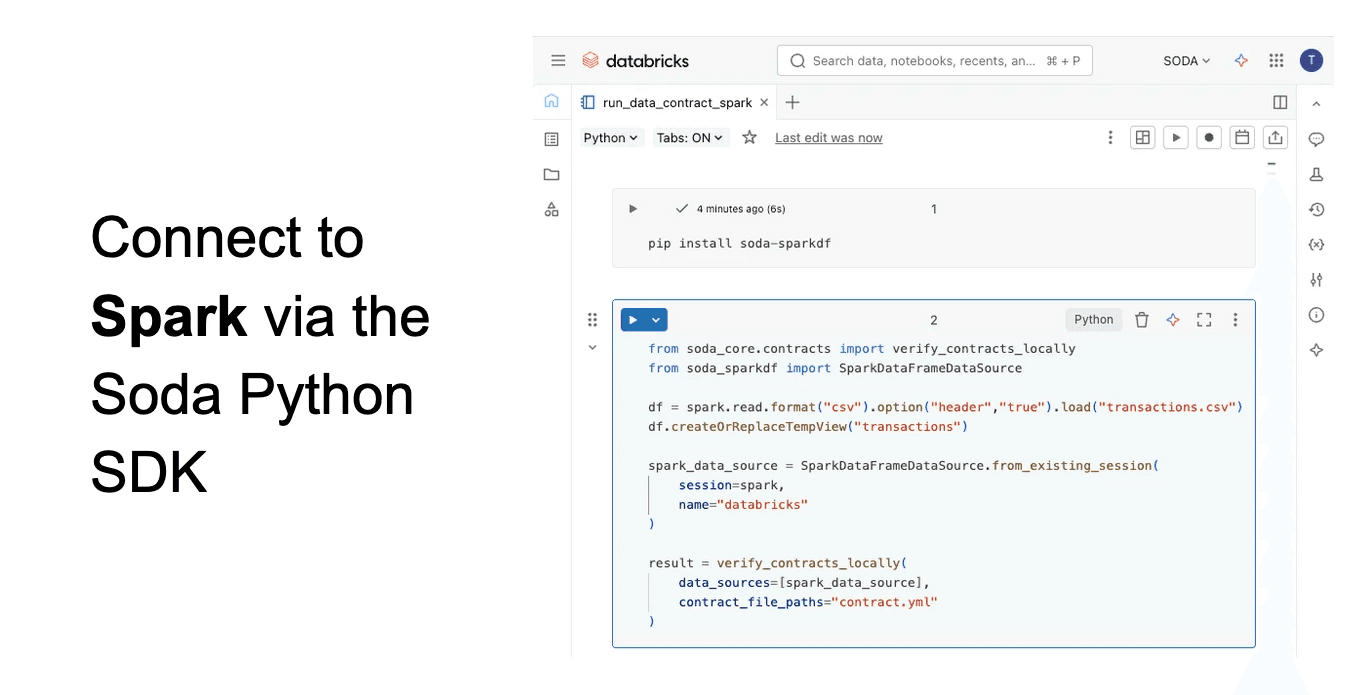
Define a Soda Data Contract
Next, let’s discuss defining and running a Soda Data Contract. For the full framework behind contracts, see The Definitive Guide to Data Contracts.
A Data Contract in Soda is a formal agreement between data producers and consumers describing what the data ought to be like. It’s not just documentation, it’s executable, meaning you can measure the extent to which your actual data satisfies the requirements defined in the contract.
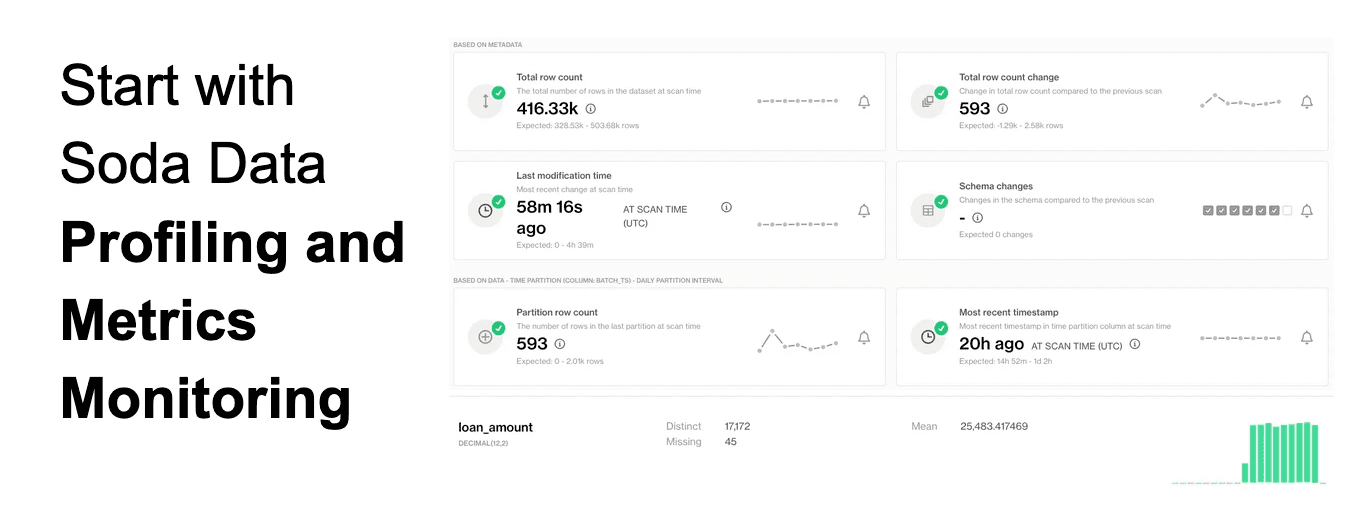
One way to get started is with our library of Data Contract templates tailored to different kinds of datasets from different industries. Another way to get started is with Soda’s automated Profiling and Metrics Monitoring systems. Before defining any rules, Soda profiles your data and detects anomalies in its variations over time, helping you derive data quality expectations. This helps you understand what your data actually looks like and how it is changing over time.

For example, profiling may reveal missing data, duplicates, or outliers. From there, you can define rules proactively. Metrics monitoring tracks trends over time and detects anomalies statistically.
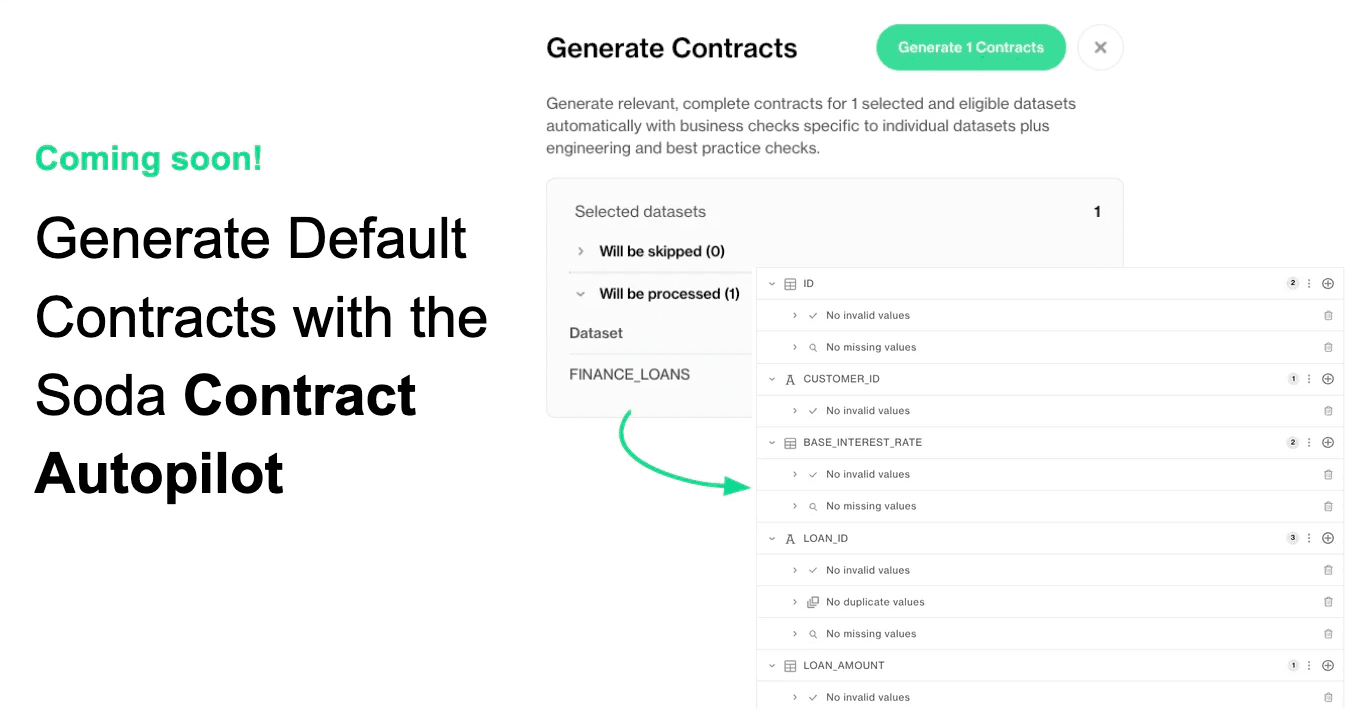
Soda’s Contract Autopilot leverages data profiling information to generate initial contracts for your datasets.
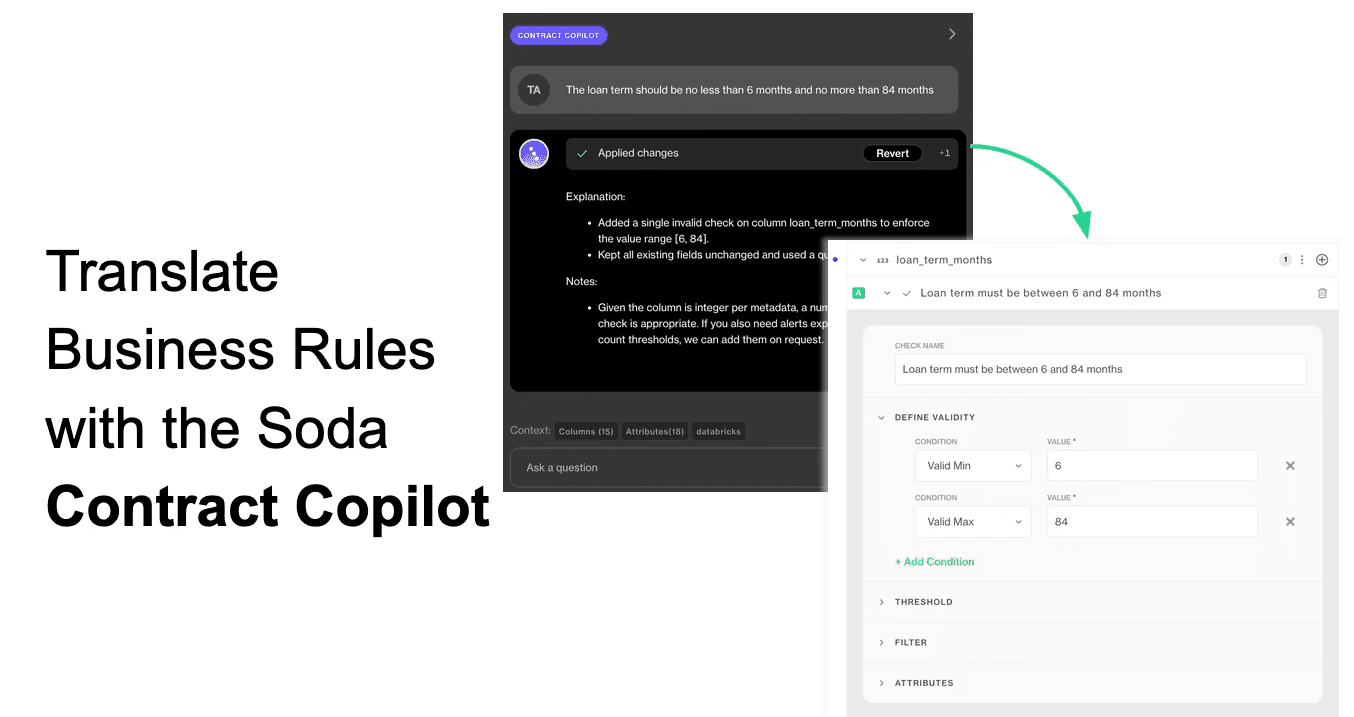
Soda also provides a Contract Copilot which can be used to continually refine and update your Data Contracts through a conversational interface, which automatically converts your data quality requirements documentation into executable data quality tests.
Under the hood, Data Contracts are represented as YAML files, allowing customization and programmatic workflows. The UI also provides detailed configuration options for thresholds, filters, metadata attributes, and scheduling.
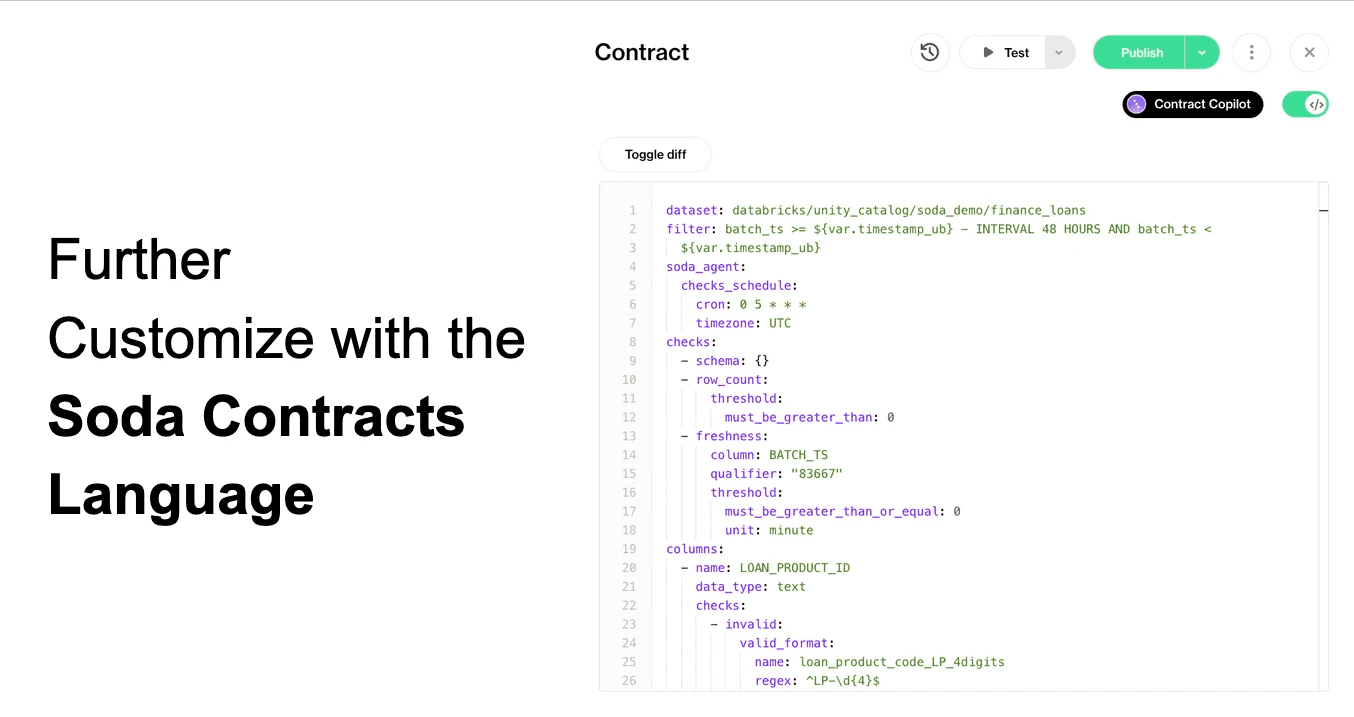
Run a Soda Data Contract
To run a contract, you can schedule it directly within Soda or trigger execution via Python SDK or REST API from external workflows such as ETL pipelines. A common pattern is testing data at multiple stages — after extraction, loading, and transformation — to ensure quality before proceeding downstream.
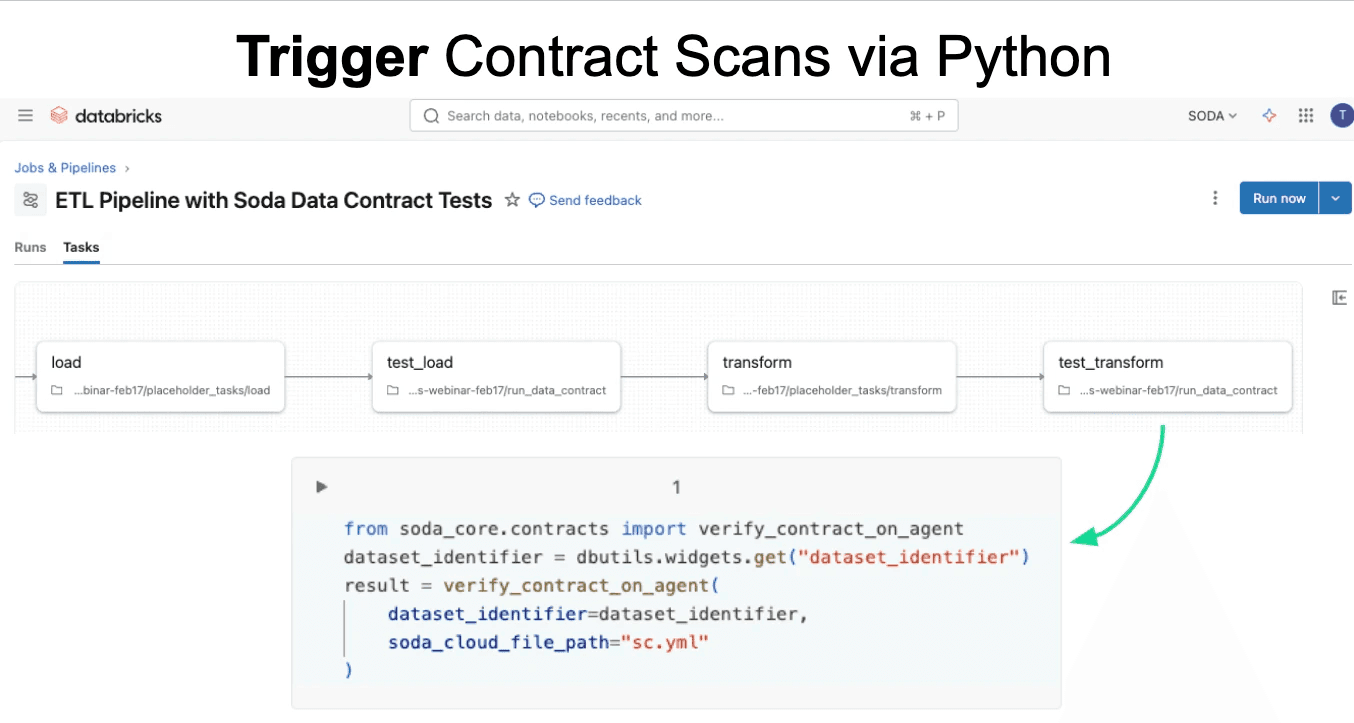
View Data Quality Results in Databricks
Next, let’s look at viewing data quality results in Databricks.
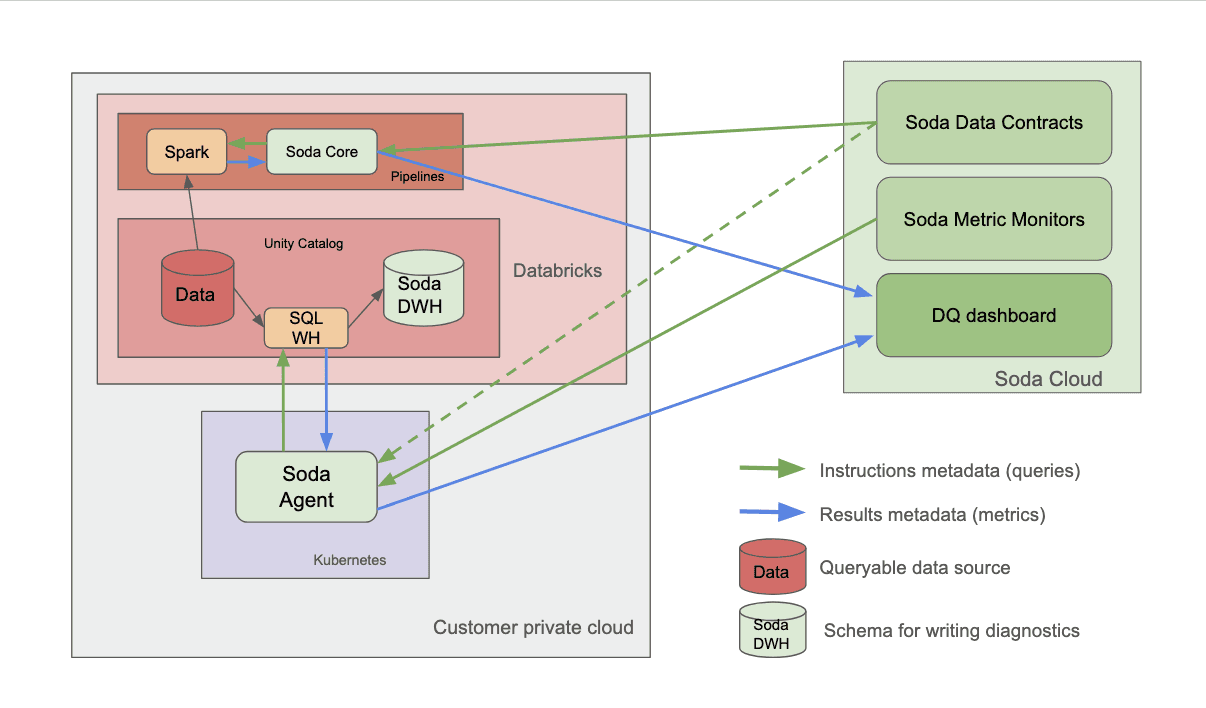
Soda uses a diagnostics warehouse — a dedicated schema where scan results are stored. This includes scan logs, rule results, and failed rows for record-level checks. Importantly, failed rows remain in the customer’s environment rather than being sent to Soda’s cloud.
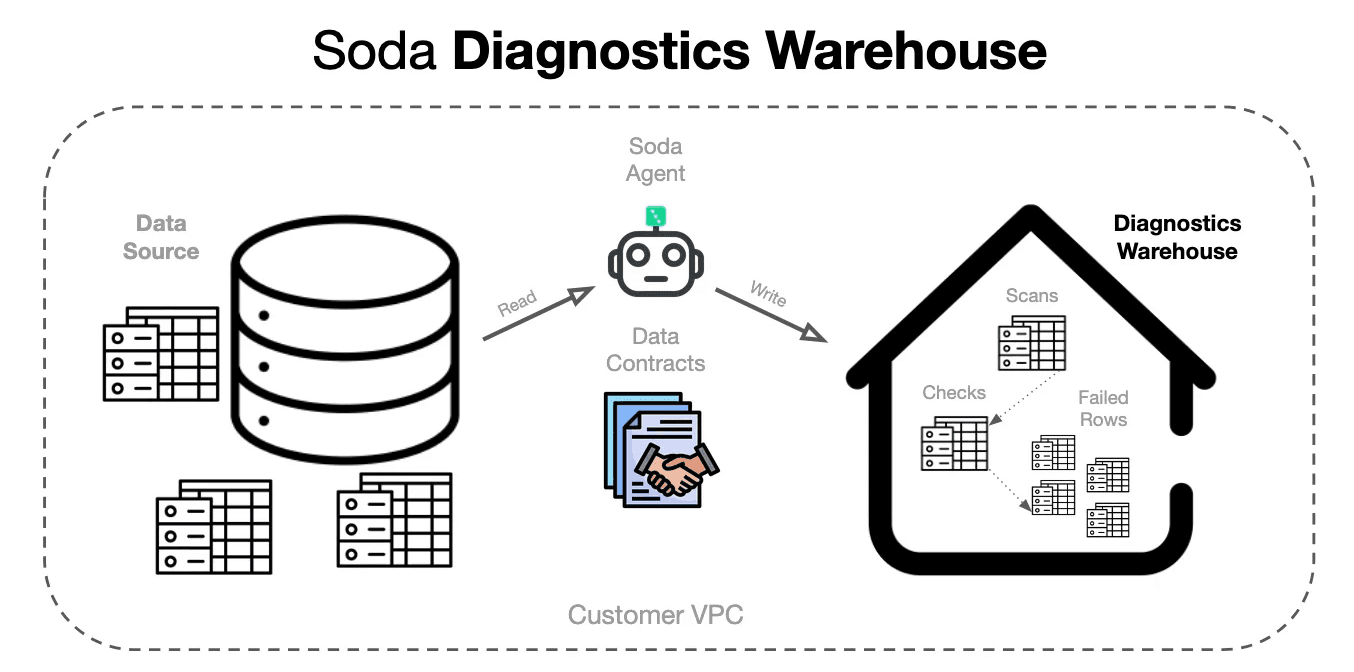
This enables workflows such as investigating failed rows directly in Databricks.
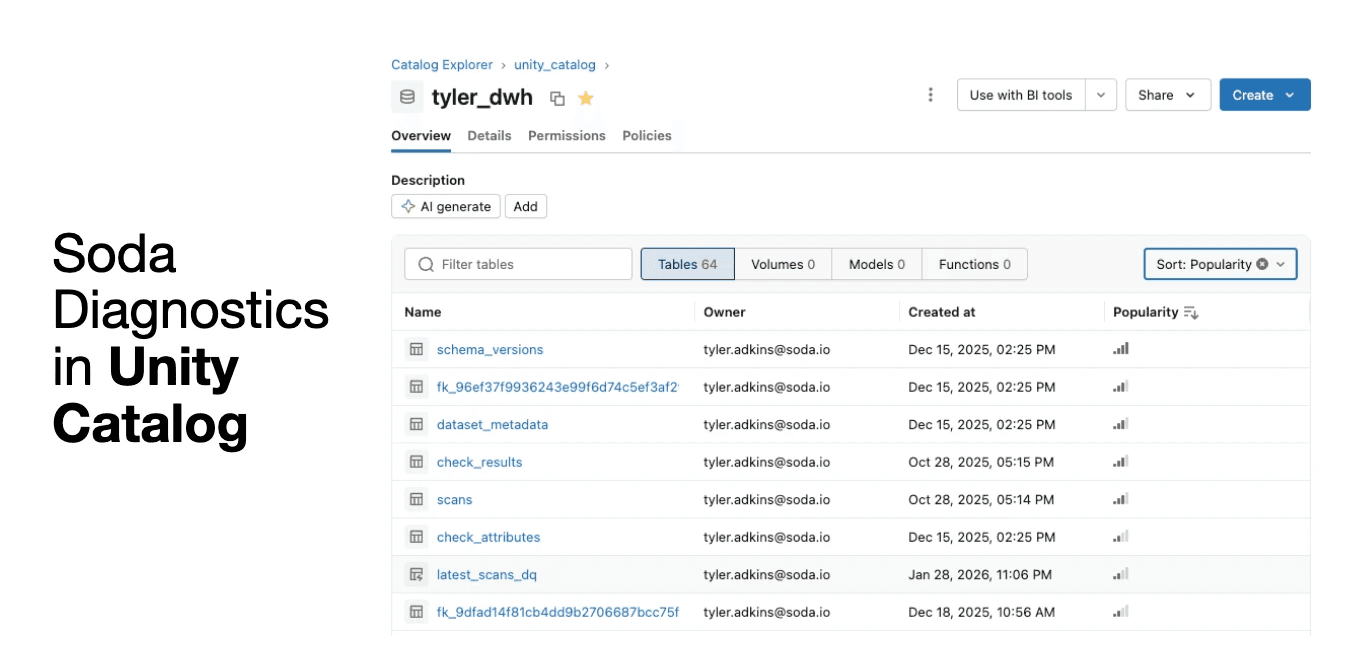
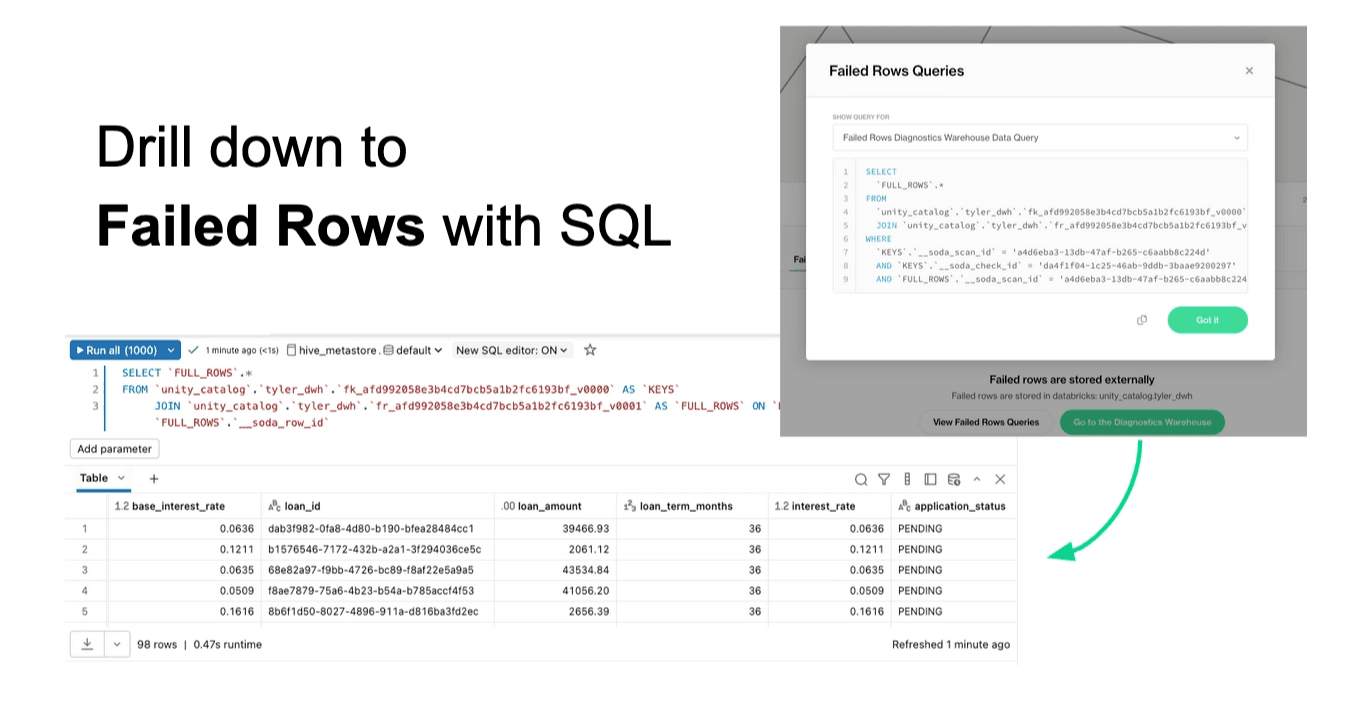
Soda generates queries to retrieve those rows, including both live queries against source tables and frozen snapshots for auditing.
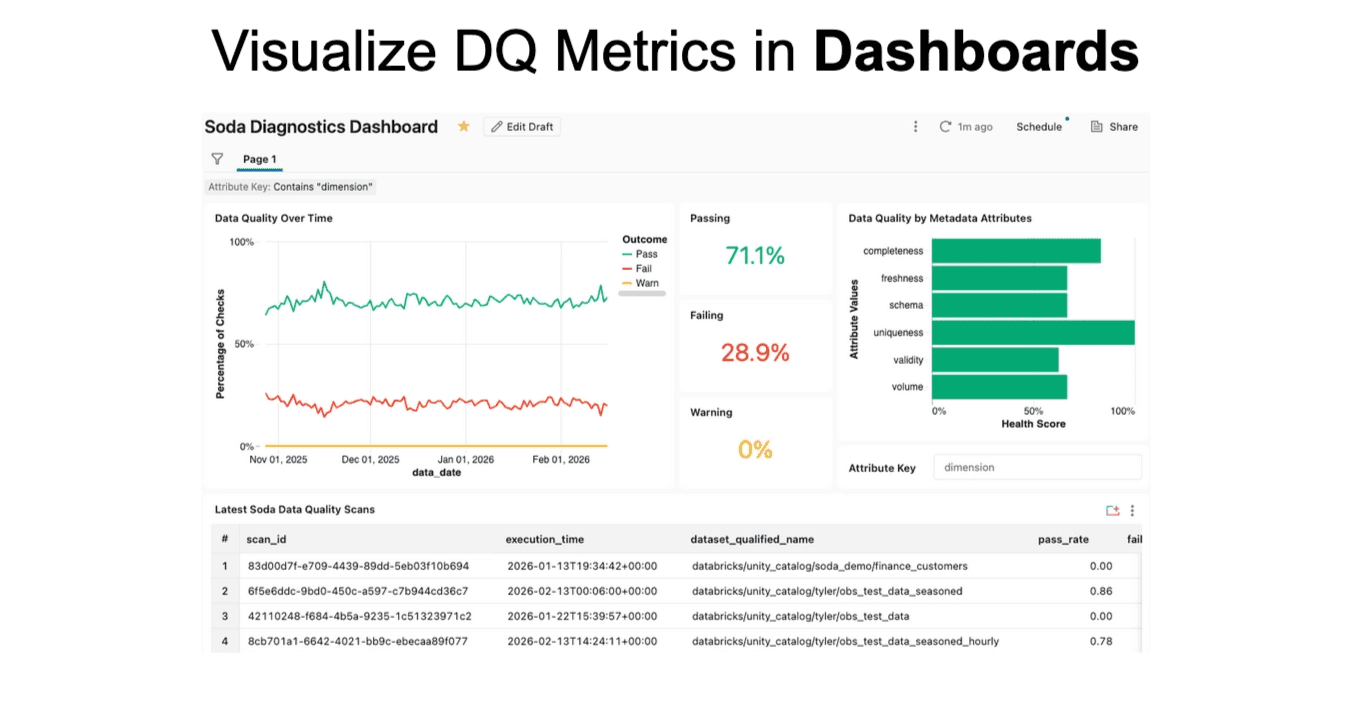
You can also build dashboards using these diagnostics tables to visualize data quality trends or embed trust indicators into existing dashboards.
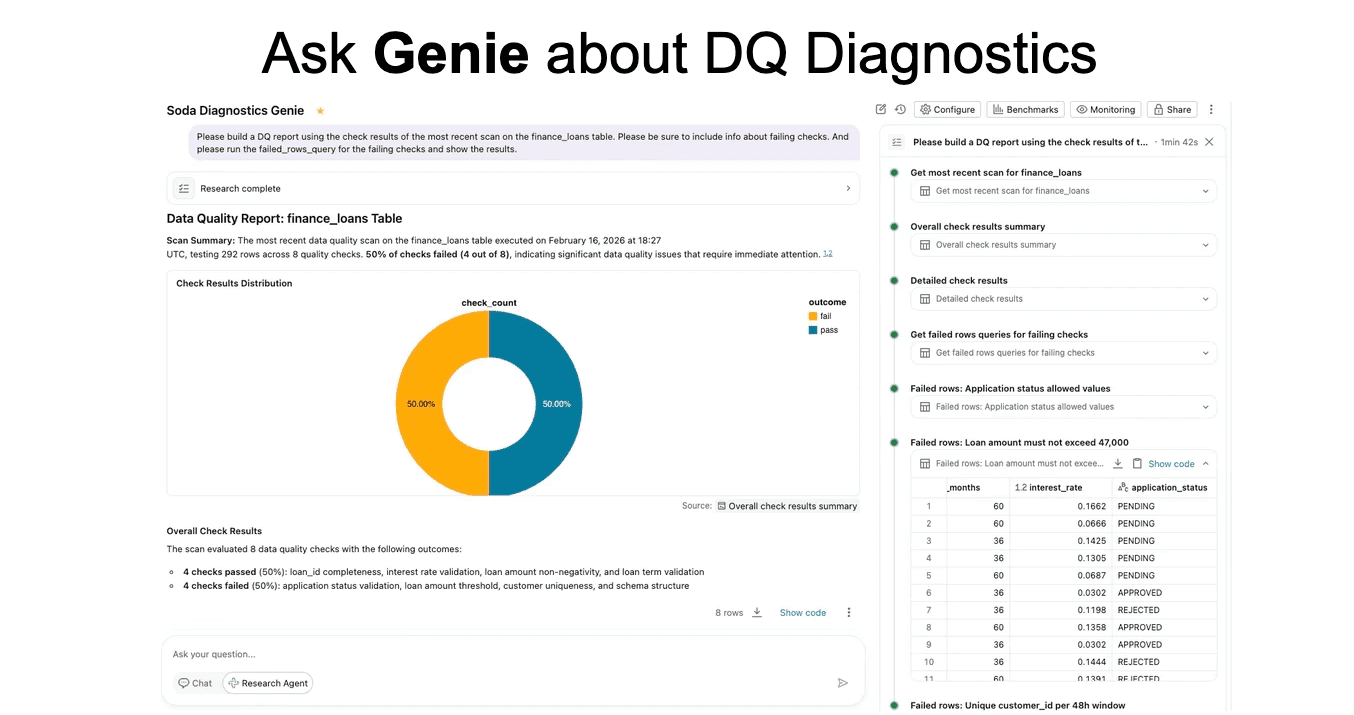
Additionally, Databricks Genie can be used to query diagnostics tables conversationally to generate reports.
Wrap Up
In this blog, we covered the foundations of the Databricks platform and how Soda integrates with it. You saw how to connect Soda to Databricks, define executable Data Contracts, and run them within your pipelines.
We also explored how profiling, monitoring, and AI-assisted features help you create meaningful rules faster. Finally, we looked at how to investigate results directly in Databricks using diagnostics tables and dashboards.
At this point, you should have a clear picture of how to implement, execute, and operationalize Data Contracts in a Databricks environment. If you would like to learn more about this topic, feel free to reach out to Soda team. Schedule a talk with our team of experts or request a free account to discover how Soda integrates with your existing stack to address current challenges.
Frequently Asked Questions
Does Soda cover data lineage?
No. Soda does not provide native data lineage capabilities. Instead, it integrates with partner tools that manage lineage and can use lineage information to help organize rules, alerts, or recommendations.
How does Soda handle data quality for semi-structured and unstructured data?
Semi-structured data: Supported. For example, nested structures (like struct types in Databricks) can be validated by referencing subfields using expressions in the contracts language. Unstructured data: Not directly supported (e.g., PDFs or Word documents). However, text fields within structured datasets can be validated.
Can business users define rules in Databricks using Soda?
Yes. Business users can: Use the Contract Copilot to describe rules in natural language and have them converted into executable checks. Create rules manually through the UI. Typically, governance workflows include review and approval before rules are published.
Is there an option to import data contracts in ODCS format?
Not currently as a built-in feature, but: A translation tool to convert ODCS contracts into Soda’s contract language is being developed. As a workaround, users can try pasting ODCS contracts into Copilot for translation.
Can multiple datasets be joined to apply a custom DQ rule?
Yes. Several approaches are available: Custom SQL checks that join multiple tables. Reference data validation against another dataset. Reconciliation checks comparing source and target tables (even across different systems).
Does Contract Copilot suggest automatic rule recommendations for a dataset?
Partially. Copilot can suggest basic rules based on metadata and existing contracts. A new feature (“Contract Autopilot”) is being developed to automatically recommend rules based on profiling data and metrics.
Is it possible to get a table-level DQ score when multiple checks are applied?
Yes. Soda provides aggregated results such as: Overall pass rate for the dataset. Number of passing/failing checks. Coverage metrics. These can be viewed in the Soda UI, diagnostics tables, or dashboards.
How does Contract Copilot work? Can customers bring their own models/API keys?
Contract Copilot works by using: Dataset schema and metadata. Contract context. User input prompts. Internal system prompts. Currently, it uses OpenAI models on the backend. Bring-your-own-model/API-key support is planned but not yet available.
How can DQ rules be bound to a specific project/use case and run in series or parallel?
Rules can be tagged with metadata attributes (e.g., project, domain, use case, team). These attributes can: Control alerts and notifications. Organize dashboards and reporting. Execution can be orchestrated through schedules or triggered via pipelines (e.g., Python SDK), allowing sequential or parallel workflows.
Can data quality rules be reused?
Yes. Rules can currently be copied between contracts. Upcoming functionality will allow organization-level standards where rules are defined once and applied across multiple datasets automatically.











