


at
TL;DR
In under a year, 2K Games went from zero automated data quality checks to roughly 2,000 active checks across about 1,000 datasets, and it now sustains a 95% data quality SLA with alerts in minutes. The change wasn't a new tool. It was a new operating model: a named owner on every dataset, data contracts between producers and consumers, and per-studio scorecards.
2K Games is one of the world's leading publishers of interactive entertainment, the studio behind franchises like NBA 2K, WWE, and Borderlands under Take-Two Interactive. At that scale, telemetry runs to billions of records per second and swells to petabyte volumes during a launch. Keeping that data trustworthy across the entire footprint is the challenge.
A year ago, 2K had zero automated data quality checks in production. Today, it runs close to 2,000 across roughly 1,000 datasets, against a 95% data quality SLA. At the Data Innovation Summit 2026, Sid Srivastava, who leads data architecture and ML/AI platforms at 2K, explained how the team got there. The short version: the fix was organizational before it was technical. Here is his account.
The problem: we were reactive, and it showed
Twelve months ago, we had zero automated quality checks in production. We had bolted a few things together, but they produced a lot of false positives and false negatives.
Most issues surfaced the worst way possible: an analyst noticed something odd in a dashboard, or an executive asked about a number in a meeting. Our mean time to resolution was measured in days, not hours.
And every launch came with a war room. Shipping a title meant waiting to see what broke when the pipelines reached peak load for the first time. War rooms were just standard for us.
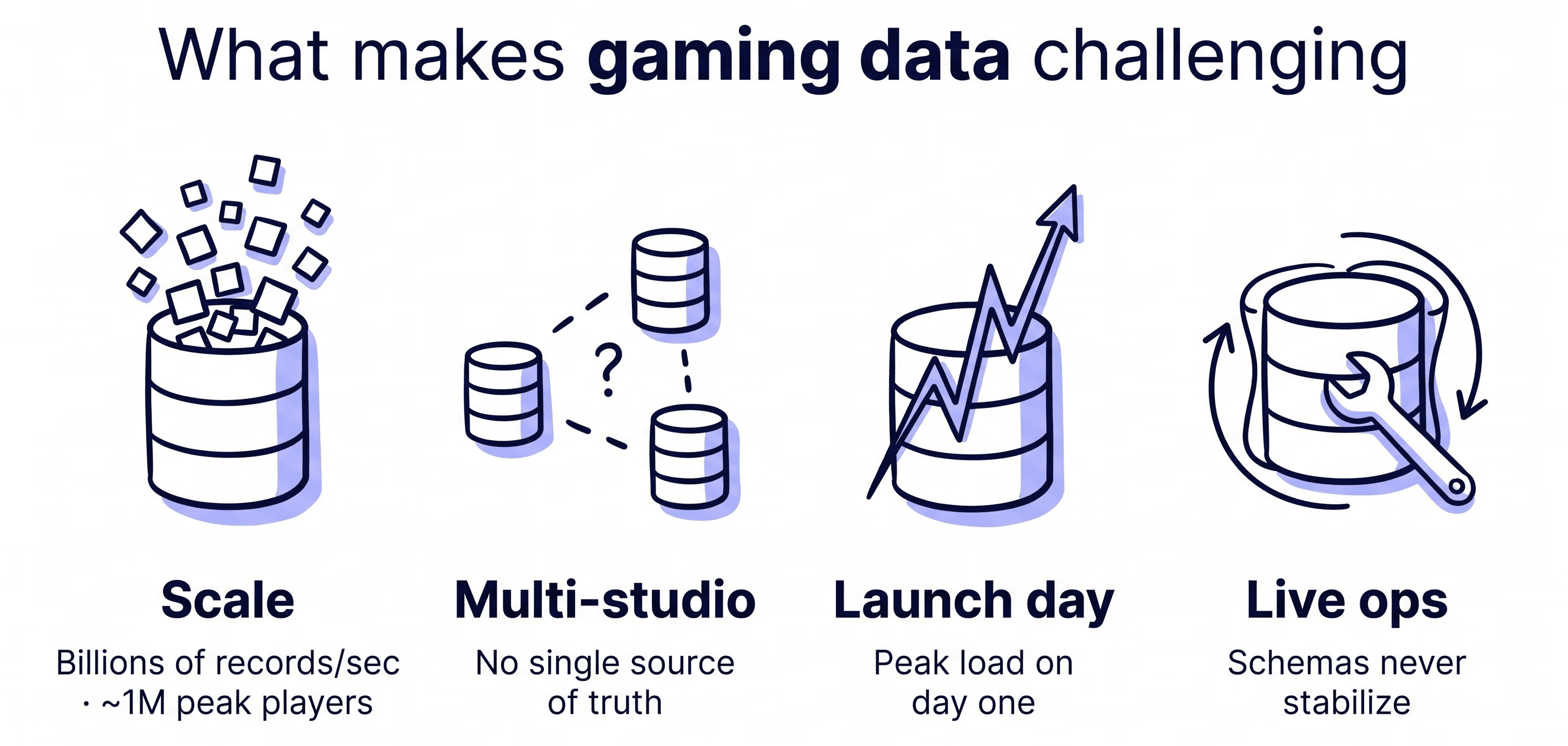
Why our data is different from a typical enterprise
Our data is different from a typical enterprise in four ways.
First is the scale. We process billions of records per second in telemetry, the kind of volume that breaks standard tooling. NBA 2K alone can reach around a million concurrent players at peak, and every one of them generates events we have to land, validate, and trust in near real time.
Second is the multi-studio reality. Each studio runs its own schemas and platforms, so there is no single source of truth to validate against.
Third is launch day. When a title goes live, our pipelines take peak load for the first time ever. There is no catching it next sprint. It is all the data, all at once.
Fourth is live ops. Patches and season updates constantly reshape the data, so our schemas never really stabilize. They keep evolving.
What changed: we made data quality a team sport
The biggest unlock was a mindset shift.
Data quality is not each team's job. Across the board, it's the whole org's job.
We run six teams in one ecosystem: telemetry, data engineering, ML ops, data science, BI and reporting, and data governance and quality. Telemetry has to send clean events. Data engineering has to land them faithfully. Governance defines the rules.
Once every team owned its part, quality stopped being something a central team chased after the fact.
We made that real with three things.
First, shared ownership with no anonymous queues. Every dataset has a named owner, and that name shows up on every alert. Nothing disappears into a nameless backlog.
Second, data contracts: formal agreements between the teams that produce data and the teams that consume it. With lineage, we can see exactly who is affected when something changes, so a schema change is no longer a surprise.
Third, per-studio scorecards. We measure data quality per studio, because what gets measured is what gets fixed. Those scorecards are still rolling out, and the goal is to turn trust into a number a studio head can own.
How we scaled to nearly 2,000 DQ checks
Picking a tool was never the hard part. The hard part was understanding what every team around us does, then making quality everyone's job. Once the ownership was in place, the tooling could scale it.
We put data quality upstream in the architecture instead of bolting it on at the end. Our managed layer follows a medallion pattern: raw telemetry first, then a curated managed layer with notebooks, self-serve data marts, and near real-time feeds, then the business dashboards on top.
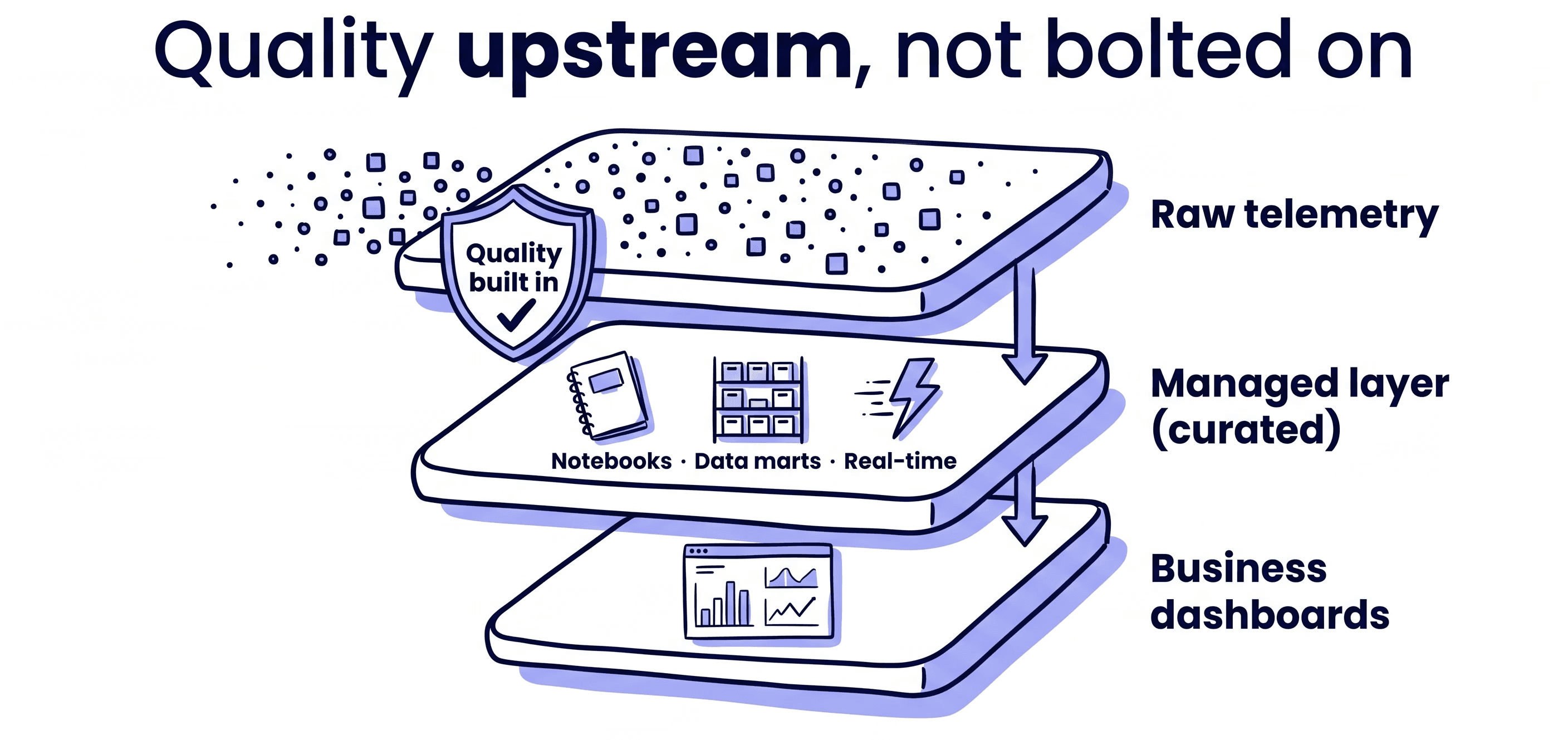
Because quality sits upstream, we catch issues before they reach anyone who depends on them.
Automation did the scaling. Schema breaks are caught in CI/CD, inside GitHub, before a merge lands. Analysts set up their own checks on custom datasets through self-service, so they never have to queue behind us.
Three use cases run on that foundation:
launch quality, where we are the first line of defense when a title ships;
CI/CD integration, with checks running in our pipelines on both Snowflake and Databricks;
and self-serve monitoring.
The checks cover freshness, volume, schema, and row counts, with alerts in Slack and email.
Soda is the engine underneath all three. It runs the same checks across Snowflake and Databricks, gates schema changes in CI/CD, and continuously monitors freshness and volume on the managed layer.
To be clear about scope, this catches structural failures, not a confusing revenue drop or broken dashboard logic. But it gave us the shift that mattered most: from detection to prevention.
The results
At the end of the day, we have the same teams, same studios, but a different operating model. Today, we run close to 2,000 active checks across about 1,000 datasets, against a 95% data quality SLA, and we are hitting it. Schema breaks are caught in CI/CD before they merge. Alerts land in Slack in minutes, not days.
From reactive to proactive: a 12-month transformation.
Then (~12 months ago) | Now |
|---|---|
0 automated data quality checks in production | 1,945 active checks running across the platform |
Issues surfaced by analysts in dashboards, or worse, by execs in meetings | 984 datasets under continuous monitoring |
MTTR for data incidents measured in days | 95% data quality SLA, and hitting it |
No formal SLAs on freshness, accuracy, or completeness | Slack alerts in minutes, not days |
Launch-day "war rooms" were standard operating procedure | Schema breaks caught in CI/CD before merge |
Studios couldn't confidently answer, "is this data trustworthy?" | Per-studio DQ scorecards rolling out |
The result that compounds is cultural. Quality is visible and owned, and with per-studio scorecards rolling out, trust is becoming a number a studio head can point to instead of argue about.
What 2K's story means for your team
Buying a tool first is backwards; a tool amplifies an operating model, it doesn't create one. 2K's results came from a cultural shift:
Give every critical dataset a named owner, and put that name on every alert.
Turn producer-consumer dependencies into data contracts before automating.
Move checks left, gating schema changes in CI/CD before they merge.
Commit to an SLA and publish a per-team scorecard.
Turn on self-service so domain teams extend coverage without a central bottleneck.
Soda is built to make each step automatic at scale: data contracts your engineers write in code, observability on your managed layer, and anomaly detection tuned for around 70% fewer false positives.
Book a demo to see how Soda turns a data quality operating model into automated checks.
Frequently asked questions
Who is responsible for data quality?
Everyone who touches the data, with a named owner per dataset. The key practice is removing anonymous queues, so every dataset has an owner whose name appears in every alert.
How do you scale data quality across many teams without a central bottleneck?
Through data contracts and self-service. Contracts make each producer-consumer dependency explicit, so changes can't silently break downstream teams, and self-service checks let analysts add their own coverage without waiting on a central team.
What is a data quality SLA, and is 95% realistic?
A data quality SLA is a committed target for how reliably your data meets its quality checks. 2K committed to and sustained a 95% SLA across roughly 1,000 datasets, so it's achievable at real scale, but only once ownership and automated checks are in place to make the number meaningful. The honest follow-up every leader should ask is: 95% of what? An SLA is only as meaningful as its denominator, whether that's checks passing, datasets meeting threshold, or records within tolerance over a defined window. Pick the unit that maps to how the business actually consumes the data, and the number becomes a commitment you can defend.
How do data contracts prevent bad data instead of just detecting it?
A data contract defines the schema, freshness, and volume that consumers expect, then enforces it in CI/CD. When a change would violate the contract, the pipeline halts before the merge lands, so the bad change never reaches production data. That's the shift from detection to prevention.











