
After reading data trend reports, analyst notes, and industry predictions for 2026, one pattern kept emerging. The conversation is still centered on AI / ML / GenAI. But not in the same way it was a year or two ago. The focus has shifted from experimentation to execution, from proof-of-concept to proof-of-value.
For many organizations, the competitive edge in 2026 won’t come from deploying more AI models, but from operating AI systems that are reliable, explainable, and supported by trusted data foundations.
According to BARC's Data, BI, and Analytics Trend Monitor 2026, data quality management has reclaimed the top priority for organizations worldwide, outranking AI initiatives. Even as interest in generative and agentic AI grows, leading companies will continue to differentiate themselves by balancing strong foundations and innovation.
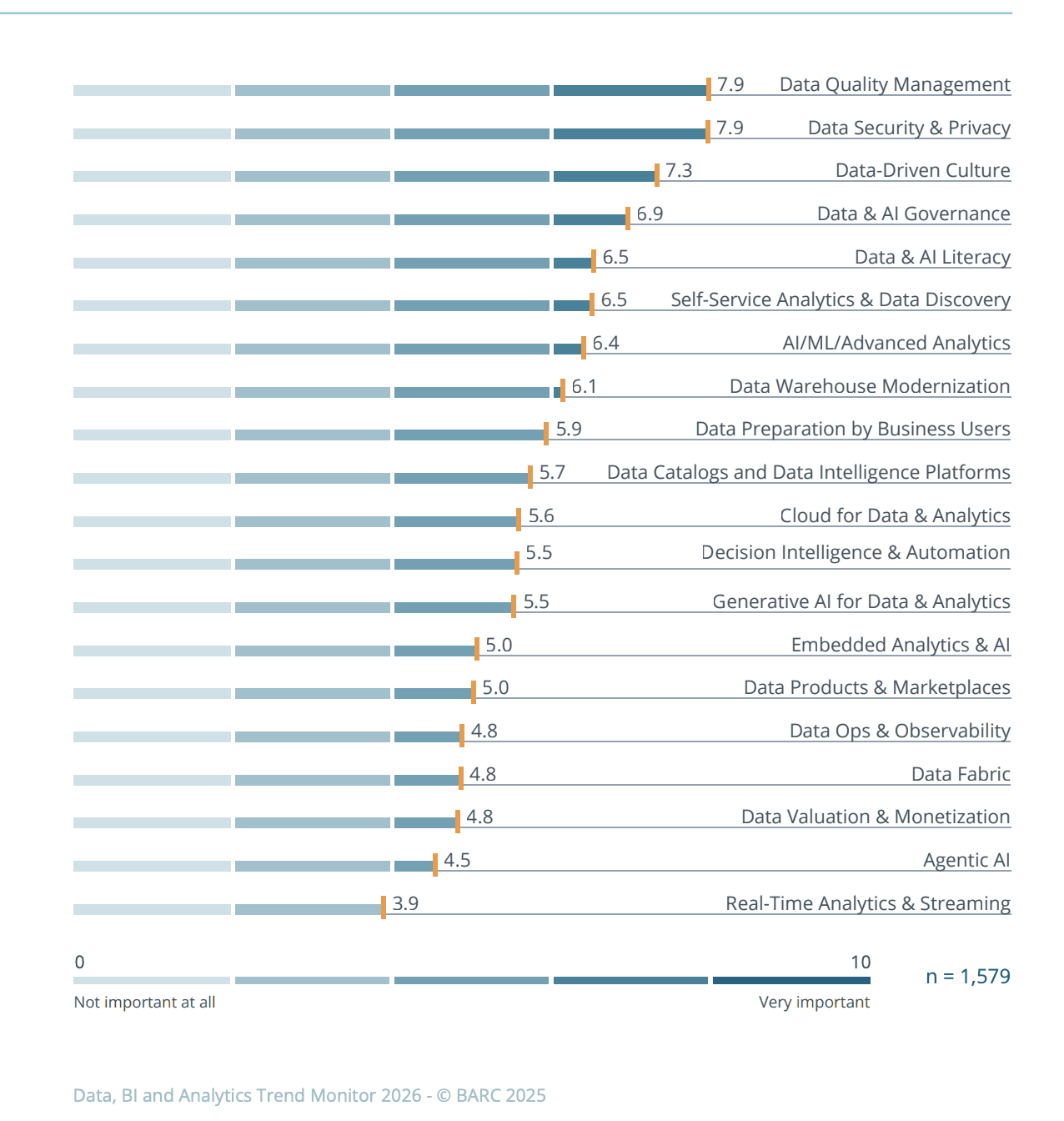
This balance becomes even more critical as AI systems grow more autonomous. Agentic models and AI-driven workflows increase both the speed and the impact of decisions, leaving little room for unreliable inputs. In Coalesce's Top Data Trends for 2026, one topic is recurrent: agentic models significantly raise the bar for data quality management. When systems are trusted to act and decide on their own, the data behind those decisions must meet a higher standard than ever before.
The message is straightforward: innovation is built on solid foundations, and those foundations still need to be strengthened. Siloed systems, undocumented data usage, and missing metadata make it difficult to assess whether data is fit for AI-driven use cases, let alone scale them safely. As a result, organizations are being forced to rethink how data is collected, managed, and validated as part of their AI strategy.
The trends that follow reflect how leading organizations are responding to that reality by investing in fundamentals that allow AI to perform reliably, responsibly, and at scale.
Trend 1 – AI-Ready Data Becomes a Leadership Priority
In 2026, CDOs will be held more accountable for justifying AI spending, explaining why pilots fail to scale, and demonstrating tangible business impact.
AI-ready data goes beyond traditional data quality metrics like accuracy and completeness; it includes context, lineage, governance, and fitness for autonomous and generative AI use cases. Hallucinations, biased predictions, and inconsistent recommendations rarely originate in the algorithms themselves. They are usually symptoms of noisy, incomplete, or poorly governed data.
Without measurable data standards in place, organizations risk scaling AI systems that are difficult to trust, govern, or defend at the executive level. And, when AI results are unreliable, the risk goes beyond wasted investment. Decision integrity suffers, regulatory exposure rises, and leadership confidence in data-driven initiatives declines.
As a result, organizations are beginning to treat data quality metrics as leading indicators of AI ROI. In practice, fewer AI initiatives will be approved unless there is clear evidence that the underlying data supports them.
As organizations move from experimentation into production, the gap between traditional data quality practices and what AI systems actually require has become impossible to ignore. AI success is no longer determined by algorithmic sophistication, but by the quality, governance, and contextual integrity of the data that feeds it.

Once AI-ready data becomes a leadership requirement, organizations need operational systems that can continuously validate and protect that readiness in production.
Trend 2 – Automated Observability and Anomaly Detection
Writing rules by hand, reviewing alerts one by one, and individually investigating every anomaly simply doesn’t keep pace with modern data environments. This year, the companies pulling ahead are not the ones claiming perfect data. They are the ones who plan for failure, learn quickly from production issues, and create systems that identify problems early and transparently.
Instead of treating data quality as a post-processing activity, organizations are incorporating data observability directly into their pipelines. Freshness, volume, distribution, and schema behavior are all continuously monitored, with clear quality metrics linked to service-level objectives.
Instead of relying solely on predefined thresholds, cutting-edge data management systems learn what "normal" looks like across datasets, detect anomalies automatically, and adapt as data evolves. When something deviates from the norm, anomalies emerge quickly, frequently before downstream dashboards, models, or applications are impacted.
In more mature setups, autonomous agents will go a step further by correlating signals across pipelines, predicting potential failures, and triggering remediation workflows with minimal human intervention. This reduces the operational toil that has traditionally consumed data teams, freeing them to focus on architecture, enablement, and strategy.
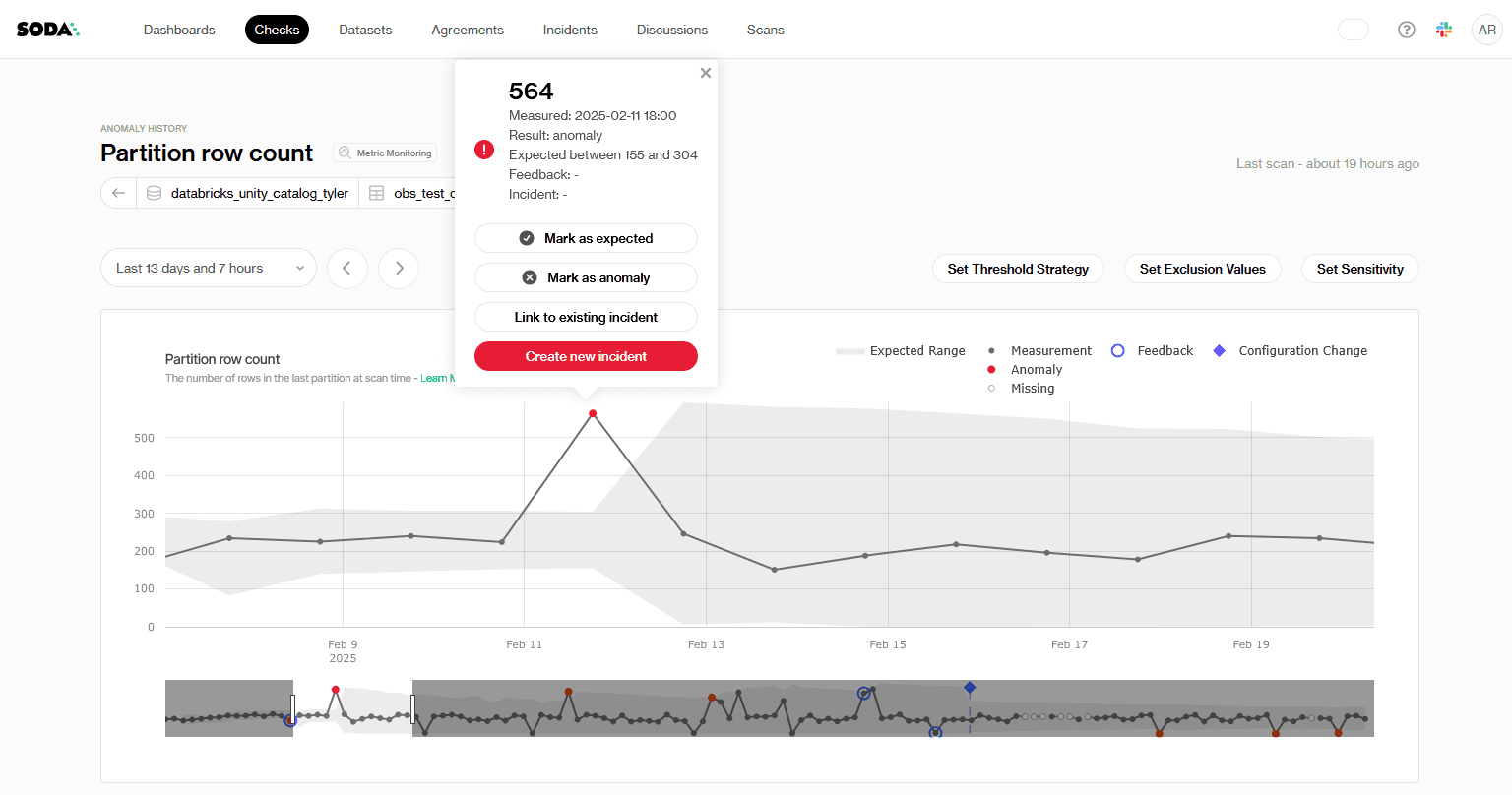
As monitoring becomes more automated, the next challenge is making quality signals understandable and actionable beyond the data team.
Trend 3 - NLP-Driven Platforms
Alongside deeper automation, 2026 also marks data quality work as no longer the domain of technical teams alone. Rather than expecting only data engineers or analysts to write tests, interpret errors, and monitor pipelines, a new layer of AI-assisted interaction is making data quality management much more accessible to business stakeholders and non-technical users.
Natural language interfaces enable non-technical users to interact with data quality in plain terms. Instead of searching through metrics or writing code, teams will be able to ask simple questions about pipeline health, recent anomalies, or changes in data behavior and then get contextual responses.
These interfaces are increasingly paired with AI assistants that help draft, explain, or refine quality checks using natural language. A user can describe an expectation in business terms, and the system translates it into executable logic.
By making quality easier to question, explain, and discuss, NLP-driven platforms help organizations respond faster and make collaboration smoother by aligning business intent with technical implementation earlier in the process.
However, human expertise will remain crucial. For data engineers and analysts, this means that instead of acting as translators between systems and stakeholders, they can focus on validating logic, refining rules, and improving upstream design. Data quality management will increasingly rely on machine assistance to extend human capacity, not to replace it.
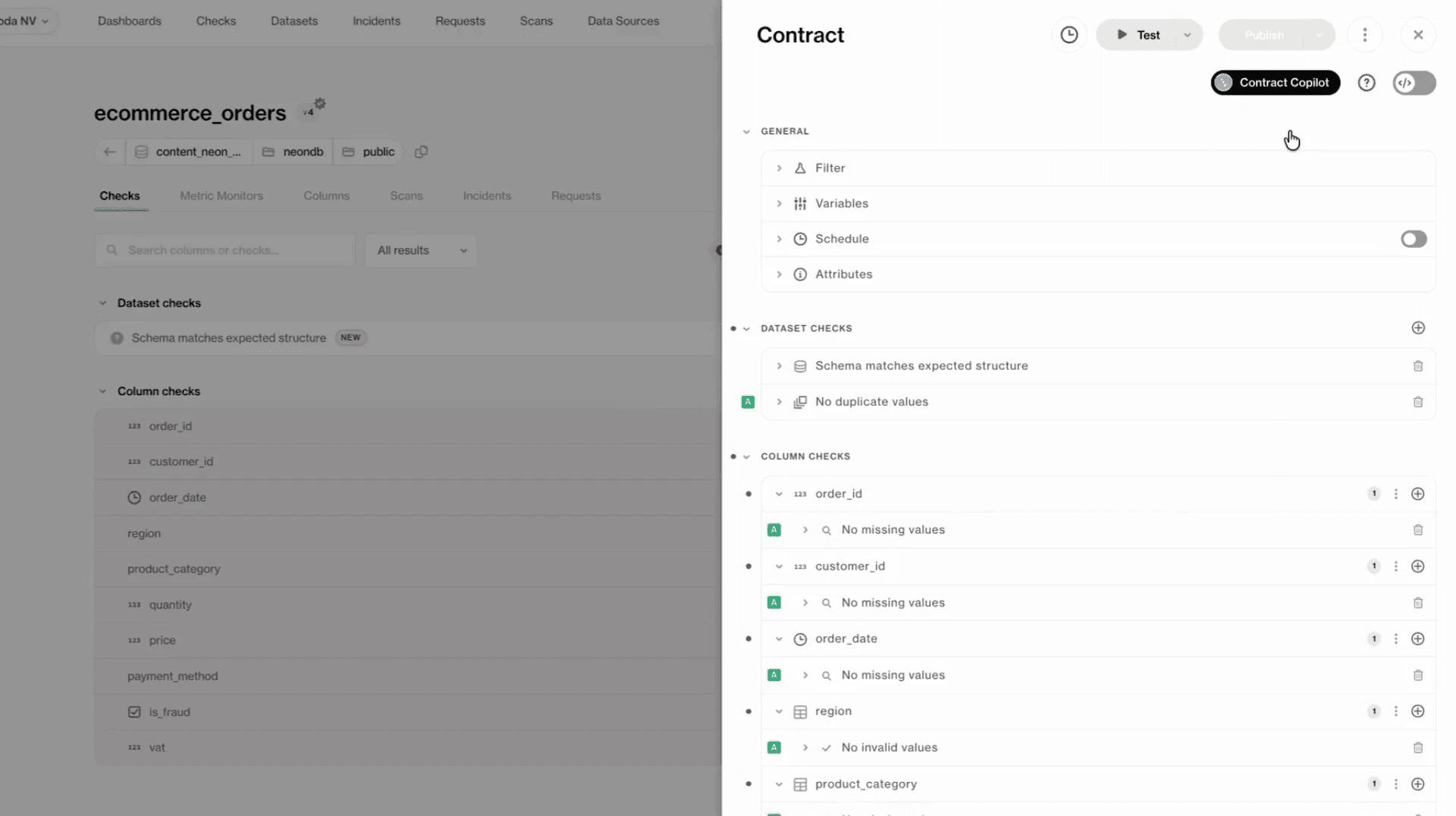
Now, as more stakeholders engage with data quality, organizations need clear agreements that define ownership, expectations, and accountability across teams.
Trend 4 – Data Contracts & Adaptive Data Governance
Another clear trend is that organizations making real progress are those that treat data quality and governance as shared responsibilities rather than an IT function. This requires a cultural shift where teams know what “good” actually means in measurable terms.
Teams need explicit, measurable expectations for data, communicated consistently, and enforced where data is produced as well as where it is consumed.
Data contracts are emerging as a practical mechanism to support this shift. At their core, data contracts define clear agreements between data producers and consumers, such as schema, quality expectations, validation rules, and ownership.
By making these expectations explicit and executable, contracts reduce ambiguity and help prevent downstream surprises.
Adaptive data governance builds on this foundation. Rather than static, top-down rules, governance is evolving alongside data usage, risk, and regulatory requirements. As AI systems become more prevalent, governance must also support transparency, traceability, and responsible use, without becoming a bottleneck to innovation and decision-making.
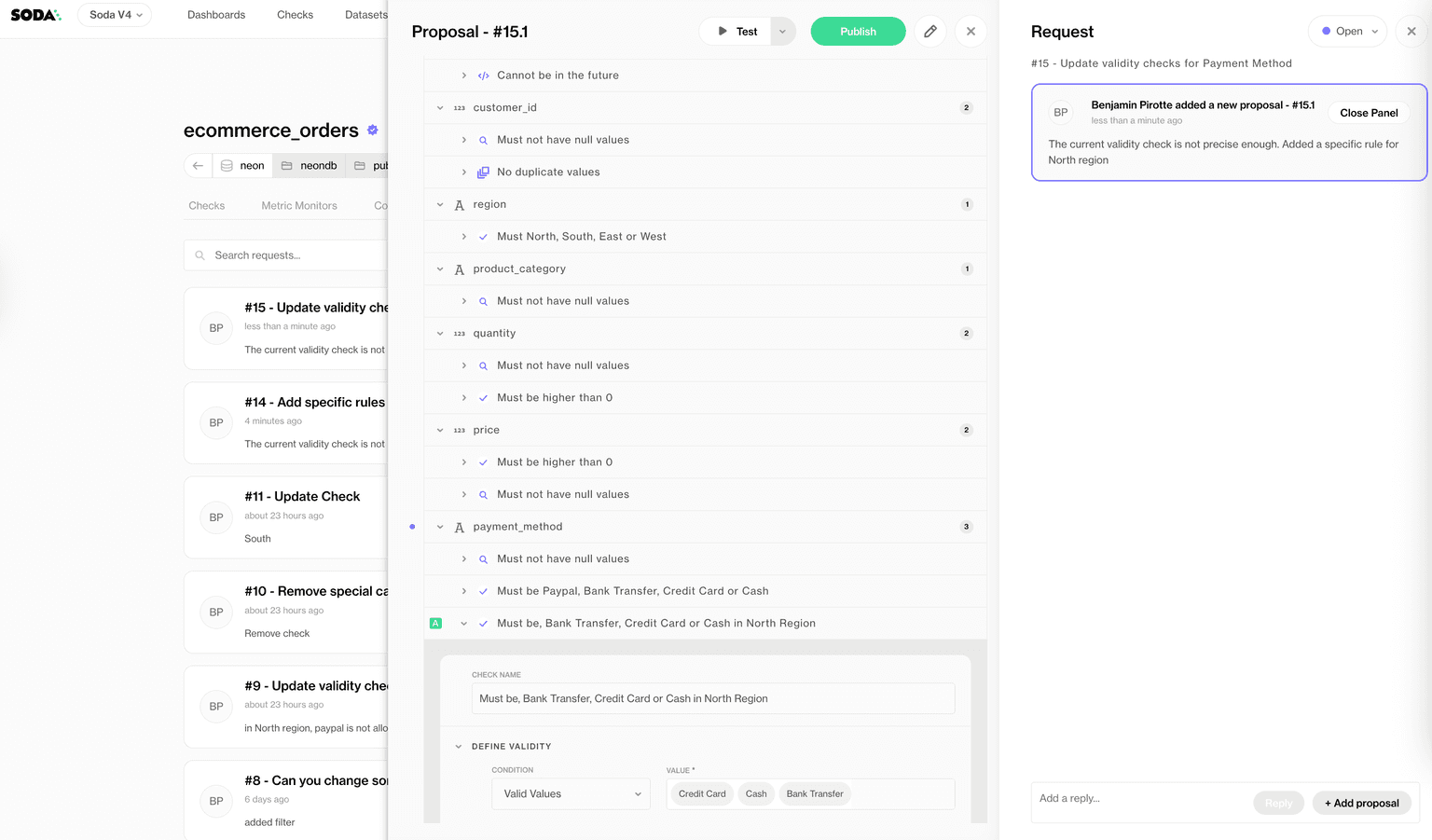
Soda Collaborative Data Contracts ⤴️
Having said all that, defining expectations is only effective if organizations can prove how data flows, changes, and is used across systems.
Trend 5 – Data Lineage, Transparency & Compliance
In 2026, organizations will continue to be under growing pressure to explain where data comes from, how it is transformed, and how it is ultimately used by models, dashboards, and automated systems. Without this visibility, confidence in analytics and AI quickly erodes.
As data volumes grow and architectures become more distributed, data lineage provides that visibility. It allows teams to trace data from source to consumption, showing how inputs were transformed along the way.
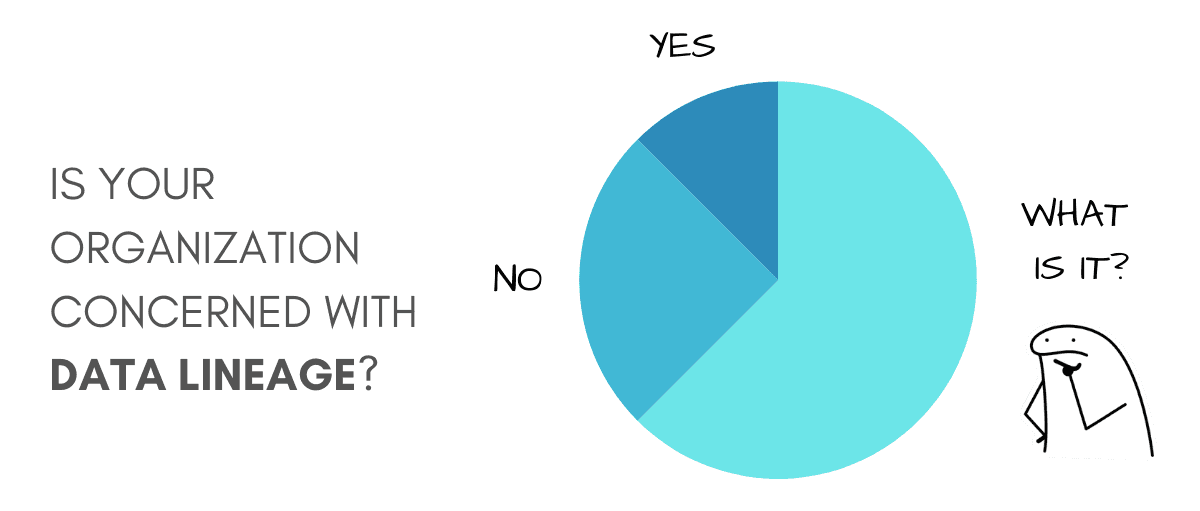
When results look wrong or decisions are questioned, lineage makes it possible to investigate quickly, enabling teams to assess the impact of data changes before they propagate downstream.
Regulatory pressure — such as compliance with GDPR and protection of sensitive information — is accelerating this need for a trust infrastructure. New rules around data usage, privacy, and AI transparency are increasing the cost of not knowing how data is handled. As organizations operate across regions, data must comply with different storage, access, and usage requirements, or they might face financial penalties and legal exposure. In this environment, being able to demonstrate transparency and control is as important as achieving performance gains.
Rather than slowing innovation, by investing in observability, testing, contracts and lineage, organizations will be able to move forward knowing they can stand behind the data they rely on, explain decisions and scale AI more confidently.
A Practical Playbook for CDOs in 2026
Taken together, these five trends point to a significant shift in how organizations approach data and AI in 2026. The question is no longer whether to invest in AI, but rather whether the underlying data foundations are robust enough to support real-world business outcomes.
The best-in-class organizations aren’t choosing between innovation and fundamentals. As research consistently shows, they invest in both, but in the right order.
For CDOs and data leaders, this translates into a practical set of priorities:
Implement automated data quality checks that run continuously.
Use anomaly detection and smart alerting to direct attention to issues that are truly important.
Adopt data contracts with executable quality rules to align producers and consumers.
Centralize quality results and lineage, allowing for traceability from source systems to dashboards and models.
Monitor operational quality metrics like quality SLAs, incident frequency, and time-to-resolution as indicators of AI readiness and ROI.
By grounding AI initiatives in reliable data practices, organizations can move faster with less risk, clearer accountability, and greater trust in the outcomes they deliver.
Here’s to 2026 being a year of meaningful progress, built on strong data foundations, designed for scale, and ready for whatever comes next.











