The Definitive Guide to Data Contracts
The Definitive Guide to Data Contracts
The Definitive Guide to Data Contracts

Fabiana Ferraz
Fabiana Ferraz
Technical Writer at Soda
Technical Writer at Soda
Table of Contents
Ask five data engineers what a data contract is, and you will likely get five different answers. Some will overlap. Others will subtly contradict each other.
That confusion comes from how the term is used today. Different tools describe data contracts through their own lens. Catalog tools focus on schemas and ownership. Data quality tools emphasize checks, SLAs, and freshness. Governance and access tools often fold in policies and permissions. All of them are partially right, but collectively incomplete.
This makes data contracts sound broader… and vaguer than they really are. Teams hear that contracts will fix data quality, governance, ownership, and speed, yet still struggle with basic questions: what exactly belongs in a contract, where it lives, how it is enforced, and who is accountable for it over time?
This article treats data contracts as a concrete, operational engineering pattern. Its goal is to establish a clear, end-to-end mental model for data contracts: what problem they solve, what they actually contain, and how they are implemented. Most importantly, it draws a clear line around how data contracts should be enforced in modern data platforms.
Key Takeaways |
|---|
|
Data Contracts 101
A data contract is an enforceable agreement between data producers and data consumers. It defines how data should be structured, validated, and governed as it moves through a pipeline. But the key aspect is that the rules in a data contract aren’t just documented; they must be continuously verified against incoming data.
In practice, data contracts act as checkpoints:
As data flows through pipelines, the contract automatically determines whether it can safely move to consumers. If the data meets the contract, it moves forward. If it doesn’t, it stops.
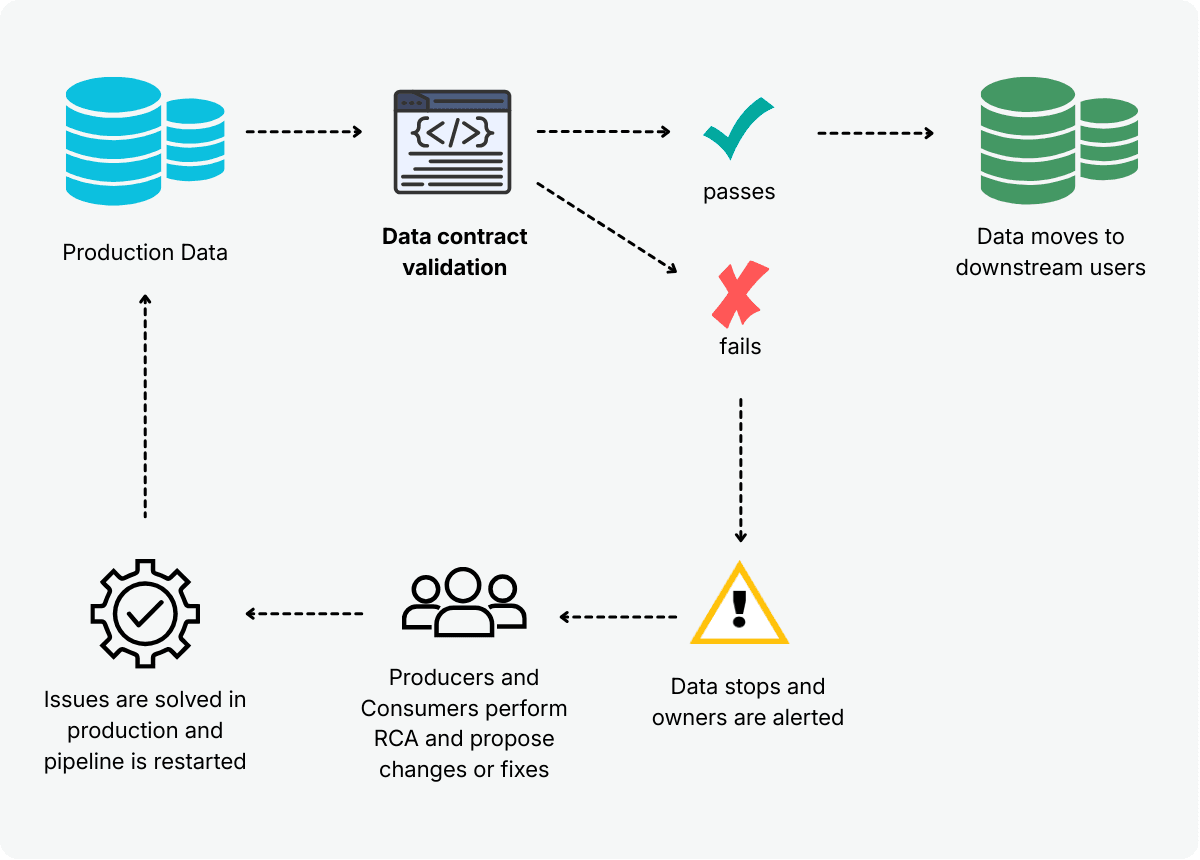
When a contract check fails, it produces a clear signal that something deviated from expectation. Integrated into CI/CD or orchestration workflows, these failures can notify responsible teams or block propagation until the issue is understood and resolved.
By making expectations explicit and enforceable, contracts remove ambiguity and eliminate undocumented assumptions about data behavior. The goal is to prevent downstream breakage and keep transformations stable and reliable.
Common Misconceptions
⛔️ Data Contracts are just documentation
Data contracts enforce expectations, not simply describe them.
Unlike traditional documentation, data contracts are typically expressed as code, most often in declarative formats such as YAML, stored in version control, and validated automatically during pipeline execution or deployment.
⛔️ Data Contracts over-constrain datasets
Data contracts define stability boundaries, not immutability.
Well-designed contracts specify what consumers can rely on, while allowing producers to evolve internal logic, add fields, or introduce new versions safely. Overly strict contracts are usually a design problem, not a limitation of the concept. The goal is safe change, not no change.
⛔️ Data Contracts are Data Products
A data contract is not a product by itself, but one component of a data product.
A data product is a cleaned, reusable, and secure data asset. It combines data with metadata, documentation, and quality standards to make it reliable and easy to consume. A single data product may expose multiple datasets, tables, or views, each serving different consumers and use cases. Each of those outputs can carry different expectations around schema, freshness, quality, or access, and therefore requires its own contract.
Contracts define the standards a data product should meet to be safely consumed.
Fundamental Elements of a Data Contract
A contract that cannot be enforced is not a contract, it is documentation with good intentions.
While data contracts can include technical and business descriptive context, such as ownership, documentation, or security requirements, the core value comes from what can be enforced automatically.
Enforceable Rules
Most organizations already have data standards. But they often live in static documents or catalog descriptions. These descriptions define what data should look like, but they do not translate into pipeline execution. This creates a gap between governance and reality.
Data contracts close that gap by encoding expectations in a form that can be executed.
With git-managed contracts, you can create, edit, and run contracts as code using YAML. This gives you full control over how your data is validated, and allows you to manage contracts just like any other code artifact: versioned, tested, and deployed via Git.
Every data contract begins with three essential elements that define its scope and purpose:
Dataset identification establishes what data you’re protecting. This includes:
which data source it comes from
its location in your data warehouse or lake (database and schema)
the dataset name
Think of this as the “address” of your data, without it, you can’t enforce any rules.
datasetDataset-level checks that verify the overall structure of your table.
Schema: Detects unexpected column additions, removals, or type changes
Freshness: Validates data meets your SLA (e.g., no more than 24 hours old based on a timestamp column)
Row count: Confirms the dataset actually contains data before consumption
With these, you ensure that any missing columns, unexpected data types, or reordered fields are detected early, that the data source has at least a minimum number of records and no unexpected gaps, and that there are no unexpected delays.
checks: - schema: allow_extra_columns: false allow_other_column_order: false - row_count: threshold: must_be_greater_than: 0
Column-level checks validate individual field quality and business logic.
Missing: Ensures critical identifiers like
idordateare never nullDuplicate: Ensures that values in a column or combination of columns are unique.
Invalid: Verifies values based on semantic type, a list of valid values, a regular expression, min/max value or character length.
Aggregate: Ensures that summary statistics (
avg,sum,min, etc.) over a column remain within acceptable ranges.
columns: - name: id data_type: varchar checks: - missing: - duplicate: - name: date data_type: timestamp checks: - missing: - name: column_1 data_type: varchar checks: - missing: - invalid: valid_min_length: 1 valid_max_length: 255 - name: column_2 data_type: varchar checks: - invalid: valid_values: ["C", "A", "D"] - name: column_3 data_type: integer checks: - aggregate: function: avg threshold: must_be_between: greater_than: 20 less_than: 50
Other customization options let you tailor contracts to your business context.
Thresholds: Define acceptable ranges or failure percentages
Filters: Apply checks to specific data subsets (e.g., high-value orders only)
Qualifiers: Create unique identities for multiple checks on the same column
Attributes: Organize checks by domain, priority, or sensitivity (PII classification)
Go to Soda Docs to learn more about how to create and edit git-managed data contracts. |
|---|
Once encoded in a contract, these expectations become executable specifications that can be validated consistently across environments: during development, deployment, and production runs. This allows expectations around schema, data types, constraints, and freshness to be continuously tested.
This rule enforcement doesn’t always mean hard blocking. Depending on the use case, it can involve alerting, quarantining data, or triggering controlled remediation workflows.
Central Source of Truth
In a typical data platform, quality checks are embedded wherever a team happens to notice a problem. A row-count assertion in an ingestion job. A schema test in a transformation model. A freshness check in a dashboard query.
Each check makes sense in isolation, but together they form a patchwork of partial guarantees. No single system has a complete view of what “good data” actually means.
Data contracts address this by extracting expectations from scattered code paths and turning them into a central, enforceable specification. They do not eliminate existing checks; they unify them.
Instead of ad-hoc validation logic that protects individual pipelines and late-stage debugging, contracts define shared guarantees that every system in the data lifecycle can verify with a consistent enforcement mechanism: a schema enforced in one transformation job protects that job; a schema defined as a contract protects every downstream consumer that relies on it.
Interface Between Producers and Consumers
A data contract is also an agreement between data producers and data consumers that defines the guarantees a dataset must satisfy as it moves through a pipeline.
This idea is borrowed directly from software engineering. APIs define strict interfaces between services so that teams can work independently without breaking each other. Data contracts apply the same discipline to data pipelines by establishing clear interfaces between data producers and consumers, separating internal implementation details from external expectations.
Consumers specify the guarantees they depend on to build reports, models, and applications.
Producers take responsibility for meeting those guarantees by delivering data that conforms to the agreed expectations.
Contract validation functions as a built-in control point. Every dataset update is evaluated against the published contract before it is released to consumers.
This workflow makes expectations explicit and shared. It allows teams to detect breaking changes early, identify incompatible updates quickly, and prevent silent failures from propagating through the platform.
Read more about this in “What Are Data Contracts And Why Do They Matter?” |
|---|
Why Do We Need Data Contracts?
Today, quality enforcement is usually implemented through checks within data pipelines that validate schema, nullability, and basic ranges. Engineers add these checks as data moves through ingestion and transformation steps. While useful, these validations operate locally: each pipeline enforces its own rules, based on local context and individual judgment. No single system has visibility into the full set of expectations placed on a dataset.
We need data contracts because modern data platforms cannot scale on implicit assumptions. Contracts replace informal expectations with explicit, machine-verifiable specifications that are validated before data is consumed.
In practice, this means replacing expectations around data with clear, testable guarantees, defined centrally and validated automatically. This helps surface failures before they reach dashboards, models, or business decisions.
Over the past decades, priorities in data management have shifted and expectations around data have risen to a whole new level. Most organizations today operate data architectures that are decentralized by necessity. Event-driven systems, domain-owned services, multiple ingestion paths, real-time and batch pipelines, and a growing dependency on analytics all coexist.
This complexity is the natural outcome of building data platforms that serve many use cases at speed. The cost of this breadth of scope, however, is that trust becomes harder to establish and easier to lose.
The pressure increases further with the rise of AI initiatives. As organizations adopt ML systems, autonomous workflows, and agentic decision engines, data can no longer be “mostly correct.” It must be predictably correct, consistently shaped, and delivered on time to be usable at scale.
Data contracts respond to this reality by making expectations explicit, shared, and enforceable across data products. Instead of discovering issues after data has already propagated downstream, teams can detect and block breaking changes at defined control points in the pipeline.
Read more about this in “Why Data Contracts: 5 Reasons Leaders Should Start Now” |
|---|
Technical Meets Business Stakeholder
Data contracts also matter because they address different risks for different stakeholders—and actually only work when both sides are aligned.
They provide a shared boundary where organizational ownership, technical enforcement, and operational accountability meet. Without that boundary, expectations remain implicit, enforcement is fragmented, and failures surface late, often in the hands of the wrong team.
Key Use Cases
The same data contract serves different purposes depending on whether you build data pipelines, consume analytical outputs, or rely on data for operational decisions.
For data producers (data engineers and architects)
Data contracts make delivery more predictable by turning expectations into machine-readable definitions that can be validated automatically.
In practice, this means:
Catching schema drift before it breaks downstream models
Blocking incomplete or late data before publication
Shipping changes faster because expectations are explicit and versioned
Contracts fit naturally into engineering workflows through Git, automation, and orchestration, replacing ad-hoc validation logic scattered across jobs with a single, reviewable specification.
For data consumers (analysts, data scientists, and ML teams)
Data contracts provide a reliable basis for consumption. This allows consumers to:
Verify structure, freshness, and basic quality constraints before building
Assess whether a dataset is suitable for reporting, experimentation, or production models
Detect breaking changes through contract violations rather than silent metric drift
As a result, downstream work becomes more predictable, and failures shift from late-stage analysis to early-stage validation.
For data governance and stewardship teams
Data contracts offer a practical way to operationalize governance. In practice, this enables governance teams to:
Define standards once and verify their application across data products
Tie expectations to owners and domains with clear accountability
Gain visibility into where contracts pass, fail, or drift over time
Instead of reviewing policies after incidents occur, governance teams gain continuous feedback on how standards operate in production.
The result is predictable change management: fewer downstream incidents, clearer ownership, and safer deployments without restricting system evolution.
Data Contracts Ecosystem
In the Gartner Hype Cycle for Data Management 2025, data contracts appear as an emerging mechanism for building trust, enforcing governance, and reducing the time it takes for data to deliver real value.
Gartner frames data contracts as a response to the realities of modern data platforms: AI workloads, decentralized ownership models such as data mesh, and the growing difficulty of keeping data quality and consistency under control as systems scale.
Rather than a short-lived trend, data contracts are treated as a structural component of mature data ecosystems, helping teams manage complexity and produce data that is reliable enough to be used safely by analytical and AI systems.
However, “data contracts” do not refer to a single type of tool or implementation. The ecosystem includes governance systems, descriptive standards, and execution engines — each operating at a different layer of the stack. Understanding these layers is essential to understanding what data contracts can (and cannot) actually enforce.
Governance Platforms and Data Contracts
Data contracts are no longer limited to engineering tools, they are becoming part of enterprise governance strategies.
Governance platforms such as Collibra and Atlan play an important role in the data contracts ecosystem by focusing on organization-wide visibility, discoverability, and lifecycle management of contract definitions.
In this model, a data contract can be created and stored alongside other governance metadata and integrated with permissions, stewardship workflows, and lifecycle processes already used to manage data products. It defines ownership, expected schema, and usage constraints in a way that is visible across the organization.
However, governance-layer contracts are typically descriptive: they capture expectations in catalogs and workflows, but they do not inherently enforce those expectations at runtime.
In practice, governance platforms serve as authoritative descriptions of what should be true, but they still rely on external execution engines to validate whether the data meets the agreed-upon conditions.
This distinction is architectural: governance systems operate at the policy and metadata layer, while execution systems operate inside pipelines and production environments.
By integrating governance definitions with systems that can execute and evaluate those expectations, teams close the gap between policy and practice. Read our article about how to Operationalize Data Governance with Collibra and Soda. |
|---|
Descriptive Data Contract Formats
The concept “data contract” is definitely gaining traction, but the industry is still working out what “doing it right” actually means. As adoption grows, the industry has started to converge on shared ways to describe data contracts.
A useful way to think about this ecosystem is to separate descriptive specifications from execution mechanisms. Below are two common descriptive contract formats. Let’s see what they contain and what they are missing.
Open Data Contract
The Open Data Contract (ODCS) defines a structured, YAML format for describing datasets and their expectations.
From a conceptual standpoint, ODCS focuses on the descriptive layer of data contracts. The purpose is to create a common language for describing data contracts in a way that tools, catalogs, and teams can understand consistently.
See the example YAML file below. It describes the schema and a cross-table reference:
schema: - id: users_tbl name: users properties: - id: user_id_pk name: id logicalType: integer relationships: - to: schema/accounts_tbl/properties/acct_user_id description: "Fully qualified reference using id fields"
However, the ODCS does not prescribe how often validation should occur, how failures should block pipelines, or how violations should be escalated. Those responsibilities belong to execution systems.
In other words, ODCS is designed to be a declarative specification, not an orchestration tool. It defines the “what” (the interface and expectations), while leaving the “how” and “when” (the implementation) to the systems that process the data.
dbt Model Contracts
dbt model contracts address a more specific problem: preventing accidental schema changes at the transformation boundary.
Defined in a model’s YAML configuration, dbt contracts tell dbt to validate that a model’s output matches an expected set of columns, data types, and basic constraints before materialization. If the contract is violated, the dbt run fails.
See the example dbt model schema below. The model will only materialize if the output table has the defined columns, data types, and constraints (in this case, order_id cannot be null):
models: - name: dim_orders config: materialized: table contract: enforced: true columns: - name: order_id data_type: int constraints: - type: not_null - name: order_type data_type
Because of this narrow scope, dbt contracts are best understood as schema contracts for transformations. They protect downstream models within a dbt DAG, providing valuable local safety. But they are not designed to function as full data contracts across the data lifecycle.
dbt enforces structural correctness at build time, but it does not monitor data freshness, distribution shifts, volume anomalies, or record-level integrity once data is in production.
Executable Data Contract Formats
Although governance platforms and descriptive contract formats have significantly improved how teams define and share expectations about data, what they do not solve on their own is continuous enforcement at runtime.
In today’s ecosystem, relatively few tools address this execution layer directly. Many solutions focus on documentation, metadata, or schema definitions, but stop short of continuous validation against live data.
Execution-focused data contracts address this gap by treating contracts as active control points in the data lifecycle. At this layer, a contract is not just stored, it is executed. Violations can block deployments, stop pipelines, trigger alerts, or initiate remediation workflows.
Teams need contracts that can be:
→ validated automatically in pipelines,
→ integrated into CI/CD workflows,
→ versioned and reviewed like code,
→ and enforced consistently across systems.
This shifts data contracts from static specifications to operational safeguards that influence whether data is allowed to move forward, trigger alerts, or require remediation.
Soda Data Contracts
Soda data contracts close the execution gap by focusing on the executable core of a data contract: the quality, freshness, and structural expectations that can be continuously validated against production data.
By embedding contract verification into pipelines, data contracts function as ongoing enforcement mechanisms.
Have a look at the structure of a Soda YAML data contract:
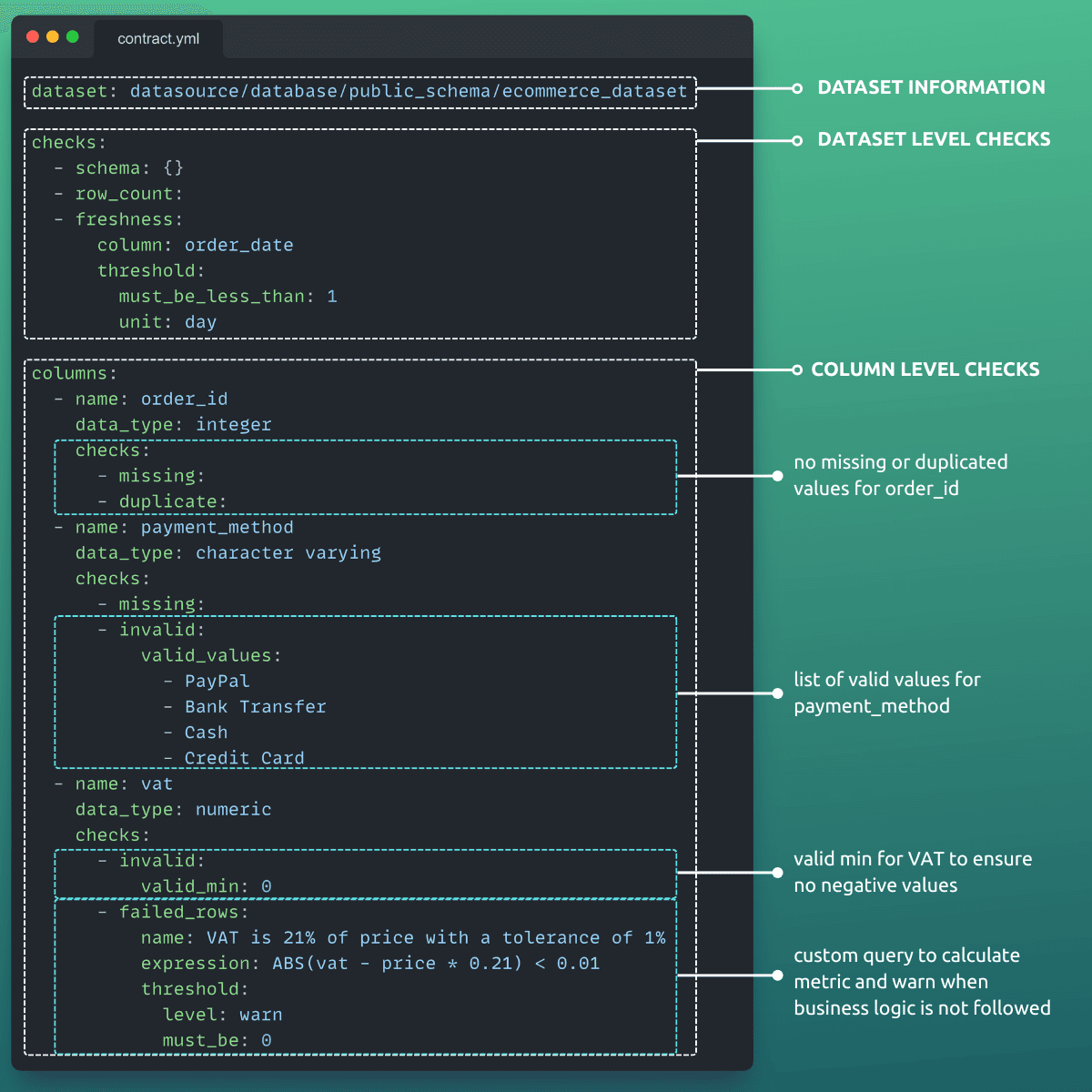
Execution engines such as Soda Core handle the mechanics of running dataset and column-level checks against real data within data pipelines and orchestration workflows.
Soda supports contract execution across a wide range of data sources, including PostgreSQL, Snowflake, BigQuery, Databricks, DuckDB, and others. Click to see all Soda Integrations. |
|---|
The Missing Layer: Contract Enforcement
As we could see, the missing layer in most data contracts is execution. Contracts exist, but enforcement is inconsistent, fragmented, or delayed, and violations are often only discovered downstream.
Execution usually fails not because expectations are unclear, but because enforcing them at scale introduces new challenges: keeping contracts up to date, aligning business and engineering inputs, and understanding why a contract failed.
Then, the question now is not what a data contract contains, but how those contracts must be implemented and enforced in real systems.
Contracts as a Shared Interface
Because data contracts sit at the boundary between producers and consumers, collaboration is unavoidable. Execution-focused approaches recognize this and design contracts as shared operational assets.
Producers and consumers create contracts to define both sides’ expectations, and the execution engine must ensure those expectations are evaluated automatically, at scale, and across environments.
This turns contracts into a bi-directional workflow: expectations flow from the business, enforcement flows through engineering, and feedback flows back through execution results. Accountability becomes explicit because failures are tied to concrete rules and owners rather than informal assumptions.
Turning Business Intent Into Executable Rules
One of the hardest parts of contract-driven workflows is translating business expectations into enforceable checks. This translation is often manual, slow, and error-prone.
Soda Cloud is a unified platform for centralized management of data contracts, including authoring, running, and collaborating across teams.
To lower the barrier to participation without weakening enforcement, technical teams can define and validate rules as code while non-technical stakeholders can propose or review expectations using the UI. Changes are tracked, versioned, and evaluated automatically once approved.
Example Soda Cloud data contract:
On top of that, Soda supports AI-assisted contract authoring, allowing teams to express expectations in plain language and convert them into executable data quality rules that engineers can review and deploy.
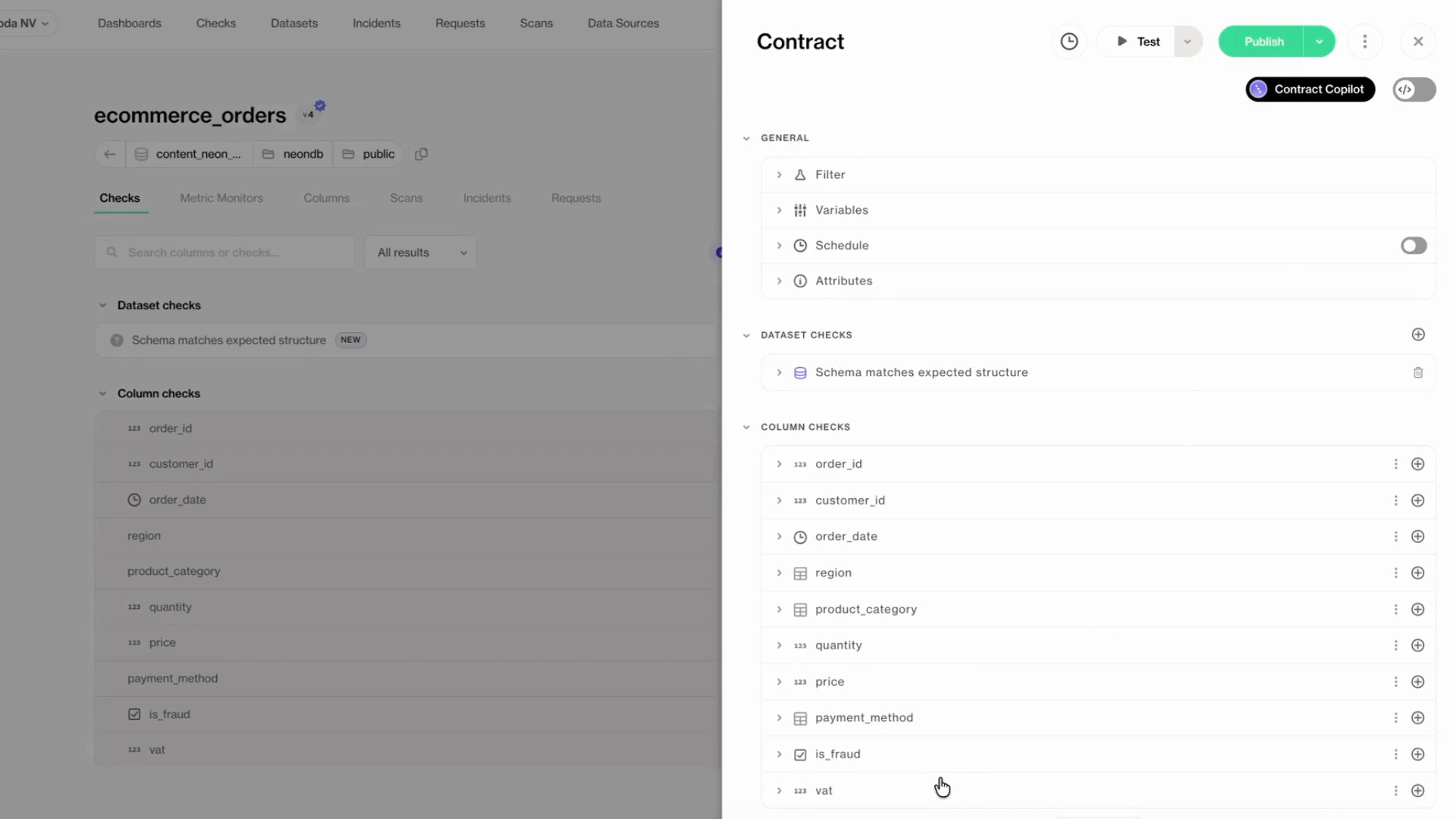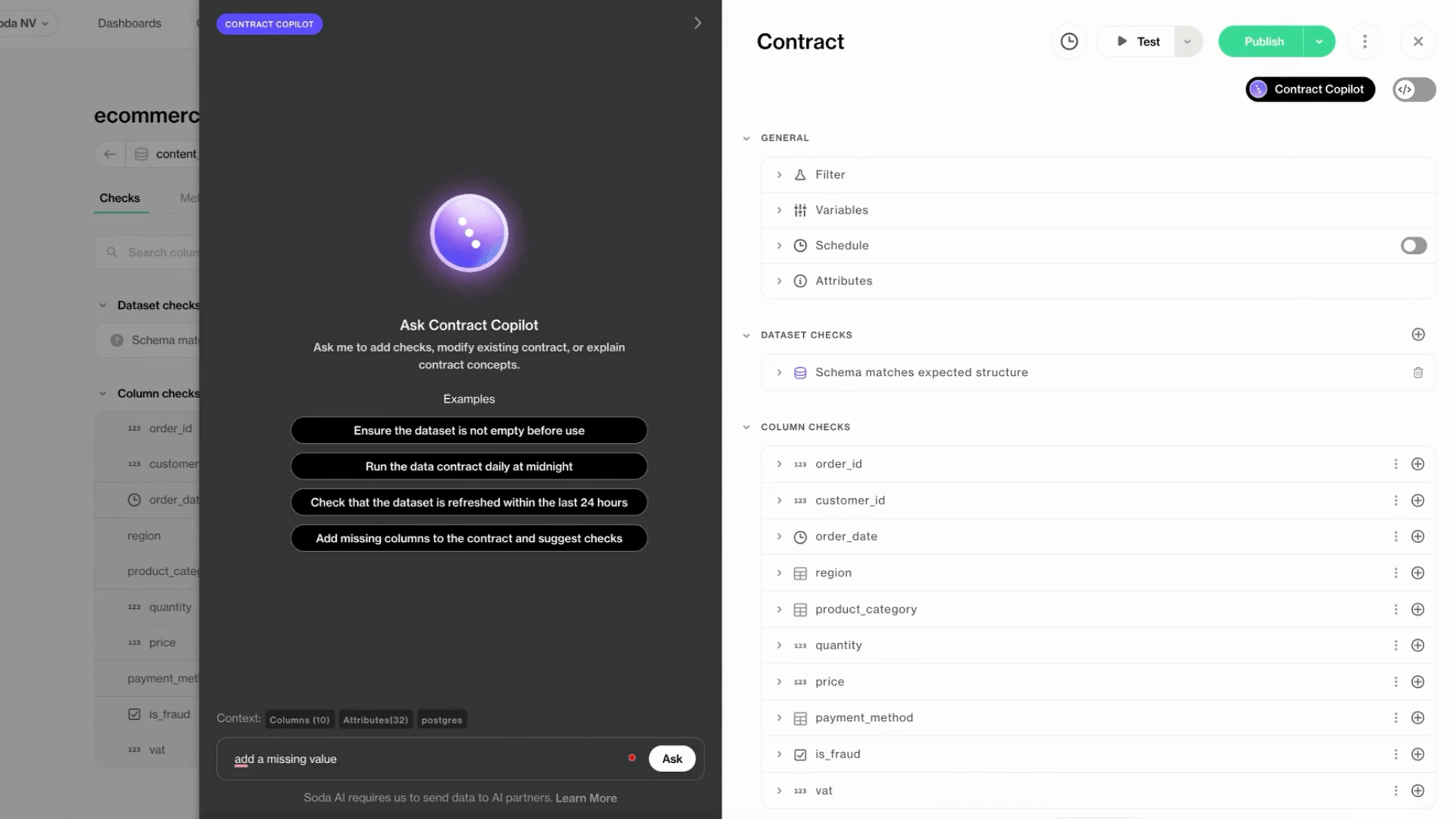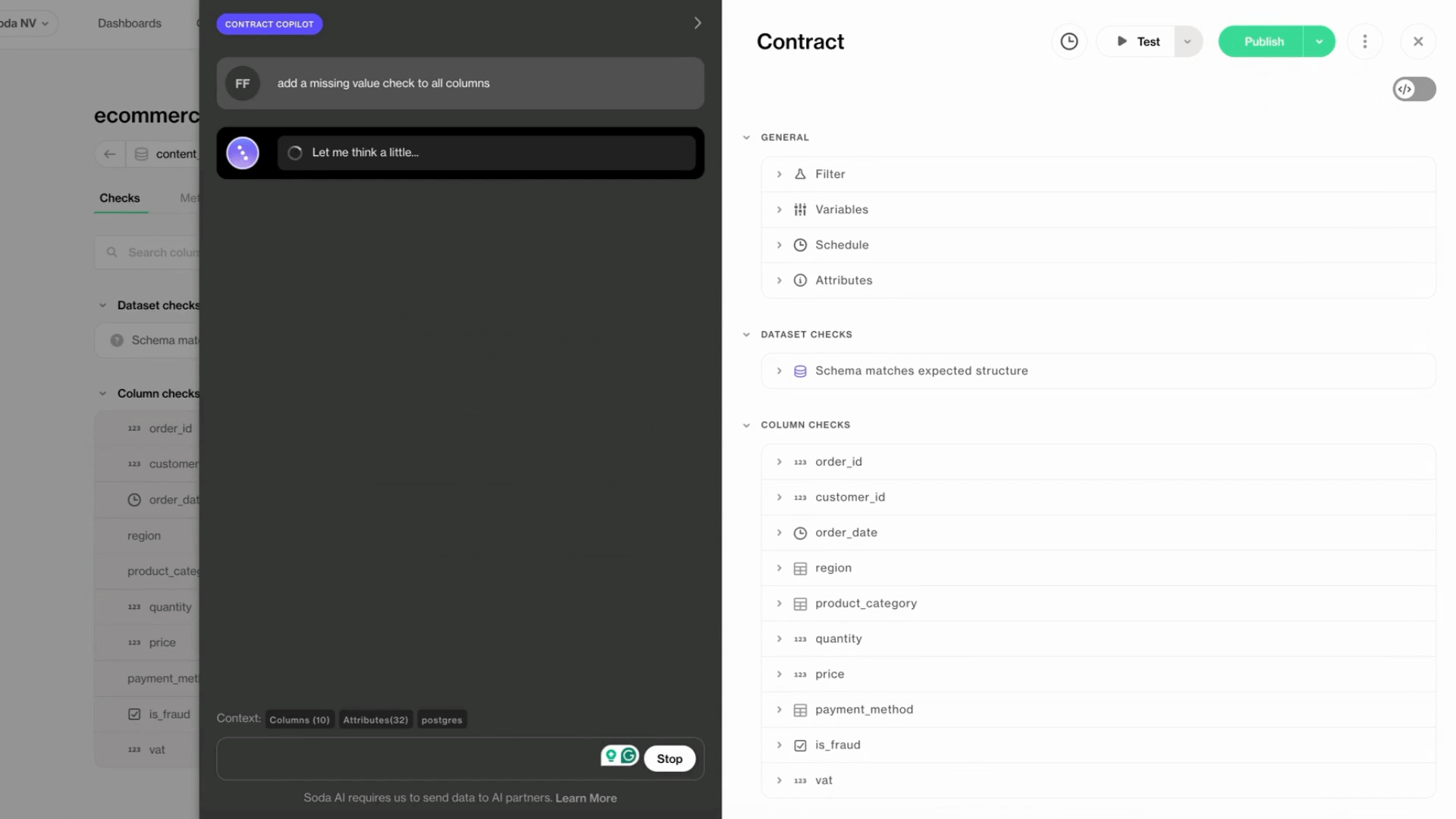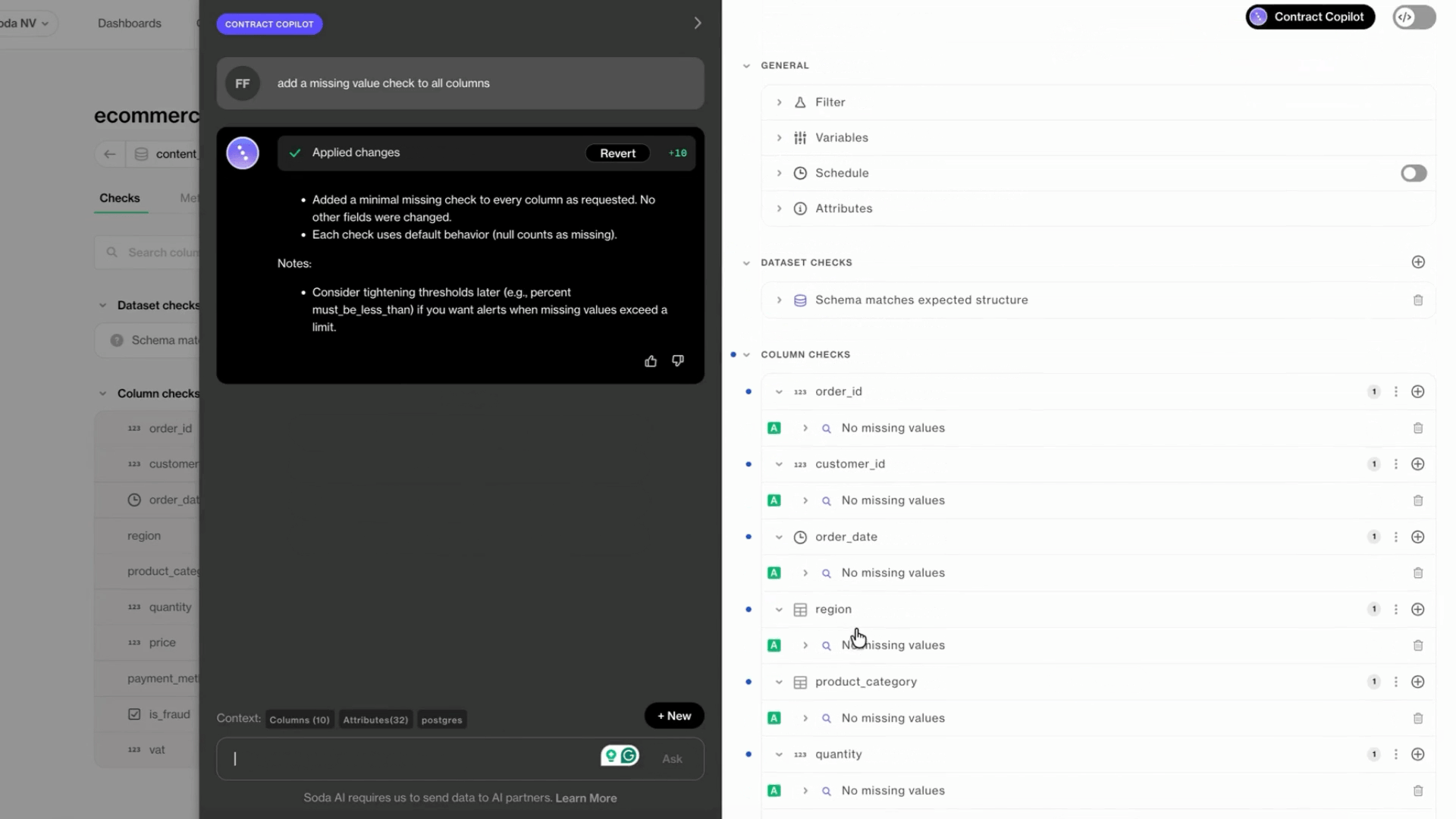
One Contract to Rule Them All
Another challenge with contract adoption is fragmentation. Schema checks live in transformations. Freshness checks live in monitoring tools. Business rules live in documentation. Each system enforces a partial view of “correctness.”
Execution-focused contracts consolidate those expectations into one machine-readable specification that can be evaluated consistently across environments and platforms as the single source of truth.
This means contracts become an active infrastructure that enforces expectations for schema, data quality, freshness, and other constraints as data flows through your architecture.
Scaling Contracts Beyond the First Dataset
Defining a data contract for a single dataset is rarely the hard part. The real challenge begins when contracts need to be applied at scale. At that point, speed and standardization start to pull in opposite directions.
Soda provides a range of built-in data quality checks and predefined contract templates covering common dimensions such as schema integrity, completeness, validity, freshness, and volume, as well as more advanced validation logic.
Soda contract templates help teams get started quickly without having to create contracts from scratch, while encouraging consistency across data products by encoding reusable expectations that scale across domains.
Continuous Contract Validation
Execution-focused contracts assume that every dataset update is a release event. Each run is evaluated against the same set of guarantees—schema, quality, freshness—before the data is exposed downstream.
This model treats data contracts much like software tests: they are versioned, reviewed, and executed automatically as part of normal delivery.
In practice, this shifts contract enforcement from occasional checks to continuous validation embedded directly into pipelines and orchestration workflows. This shifts data quality issues from silent failures to actionable signals with clear ownership.
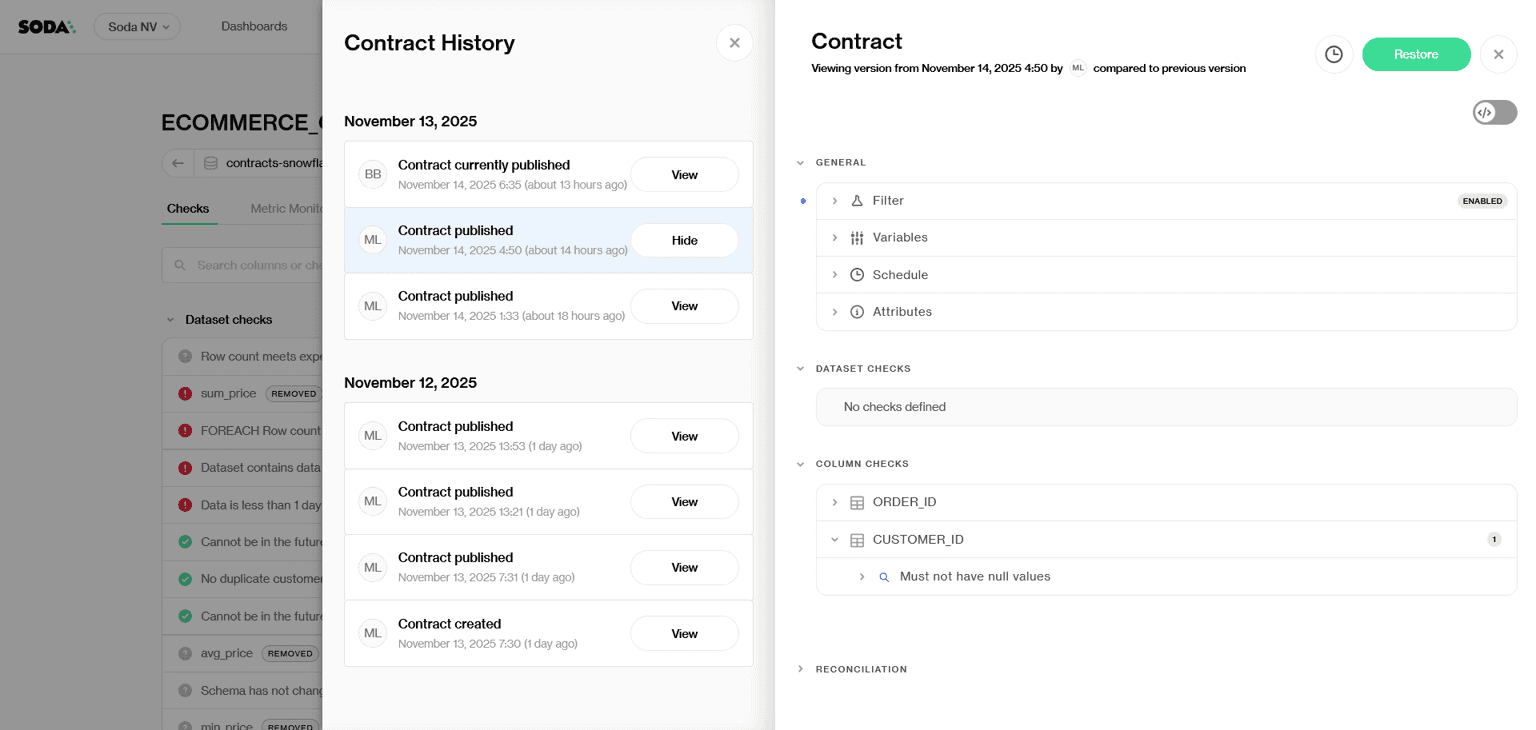
Making Contract Evolution Explicit and Safe
We must remember, though, that data contracts are not static. As data products evolve, expectations change — and unmanaged changes are a common source of breakage.
Soda treats contracts as versioned artifacts, preserving a complete history of changes, proposals, and approvals. This makes evolution explicit and reviewable, and allows teams to understand when, why, and how specifications were modified.
Diagnosing Failures, Not Just Flagging Them
Contract enforcement only creates value if failures are actionable and understandable. It’s not enough to signal that something broke; teams need to know what broke, where, and why in order to resolve it quickly.
Soda captures diagnostic context — including failed rows, check metadata, scan history, and dataset attributes — into a centralized diagnostics warehouse inside your own data warehouse. This means every contract violation is stored where your engineers already work, without moving data outside your environment.
How Different Data Contract Approaches Compare
To sum up, most implementations fall somewhere along a spectrum between policy definition and runtime execution.
Policy-oriented platforms, such as governance tools and descriptive standards, focus on declaring intent. They capture expectations around structure, ownership, and rules in a centralized, readable format. This is essential for alignment and accountability, but enforcement typically happens elsewhere.
Execution-oriented approaches focus on making those expectations enforceable. Contracts are evaluated automatically during pipeline runs, deployments, or scheduled checks. When expectations are violated, systems can fail fast, alert owners, or block propagation. Here, the contract actively shapes system behavior rather than documenting it.
Have a look at some differences below between ODCS and Soda contracts’ syntax.
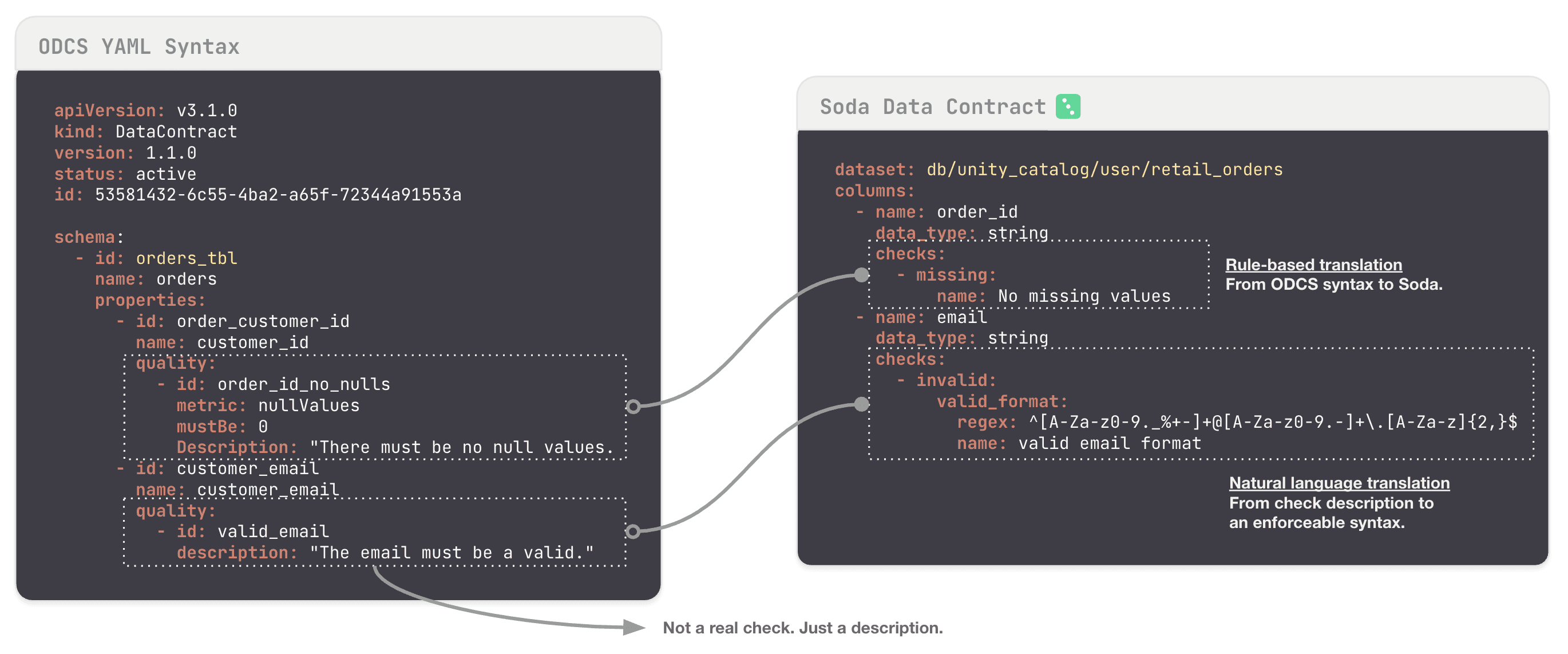
We are soon going to launch a tool to translate descriptive ODCS into executable Soda data contracts. Stay tuned!
Data Contract Layers at a Glance
The table below summarizes how common approaches fit into the broader data contracts ecosystem.
These approaches are not mutually exclusive. Mature data platforms often combine governance-layer definitions, standardized specifications, and runtime enforcement mechanisms.
Dimension | Governance Platforms | ODCS | dbt Contracts | Soda Data Contracts |
|---|---|---|---|---|
Primary Layer of Operation | Governance & metadata | Specification standard | Transformation boundary | Runtime enforcement |
Primary Goal | Define ownership, policy, lifecycle | Standardize contract structure | Prevent schema drift in models | Enforce data quality & behavior across lifecycle |
Nature of the Contract | Policy & metadata artifact | Descriptive YAML specification | Declarative model constraint | Executable contract evaluated against live data |
Scope of Enforcement | Ownership, policy visibility | Schema & relationships | Schema + basic constraints | Schema, quality rules, freshness, volume, anomalies |
Compile-Time Enforcement | No | No | Yes (during dbt run) | Yes |
Continuous Runtime Validation | No | No | No | Yes |
Pre-Ingestion / In-Motion Enforcement | No | No | No | Yes |
Pipeline Blocking Capability | No | No | dbt-only scope | Across systems |
Data Quality Coverage | Descriptive only | Descriptive only | Limited (structural) | Broad (dataset, column, record-level) |
CI/CD Integration | Indirect via workflows | No | Native in dbt | Native across CI & orchestration |
Handling Breaking Changes | Documented & workflowed | Documented | Caught in model execution | Blocked before downstream propagation |
Typical User | Governance teams, data owners | Architects, standards bodies | Analytics engineers | Data engineers, data stewards |
Best Fit | Enterprise governance & accountability | Interoperability & tooling alignment | dbt-centric stacks | Production-grade, operational data platforms |
The Future of Data Contracts
As systems grow more complex and expectations around data reliability rise, teams need a way to make trust explicit without slowing down delivery. What started as a way to clarify expectations is becoming a core building block for reliable, scalable data systems.
What’s driving this shift:
➡️ Stronger governance pressure: Regulatory requirements, auditability, and data reliability expectations are increasing. Data contracts offer a structured way to define and share expectations without turning governance into a bottleneck.
➡️ Earlier validation (“shift left”): Teams are validating contracts during development and CI/CD instead of tackling breaking changes in production. This is moving failures closer to where changes happen, reducing incident impact, and aligning data workflows with DevOps and DataOps practices.
➡️ AI-assisted contract authoring: AI is lowering the barrier to defining contracts. Business and governance teams can express expectations in plain language, while tools translate those expectations into executable rules. This will reduce back-and-forth and speed up adoption.
➡️ Decentralized data architectures: Data mesh, domain ownership, and hybrid platforms require shared, machine-readable expectations. Data contracts provide a common interface that is allowing teams to evolve independently while still working within consistent enterprise-wide rules.
Taken together, these trends point to data contracts becoming the default way to manage expectations at scale, combining clarity, automation, and enforcement.
What it Means at Soda
Looking ahead, Soda’s direction for data contracts is a natural extension of treating contracts as executable control points, not just quality checks.
Today, contracts define and enforce quality and structure. The longer-term goal is to broaden their scope to cover additional controls such as access policies, retention rules, and lifecycle constraints, using the same contract-as-code approach.
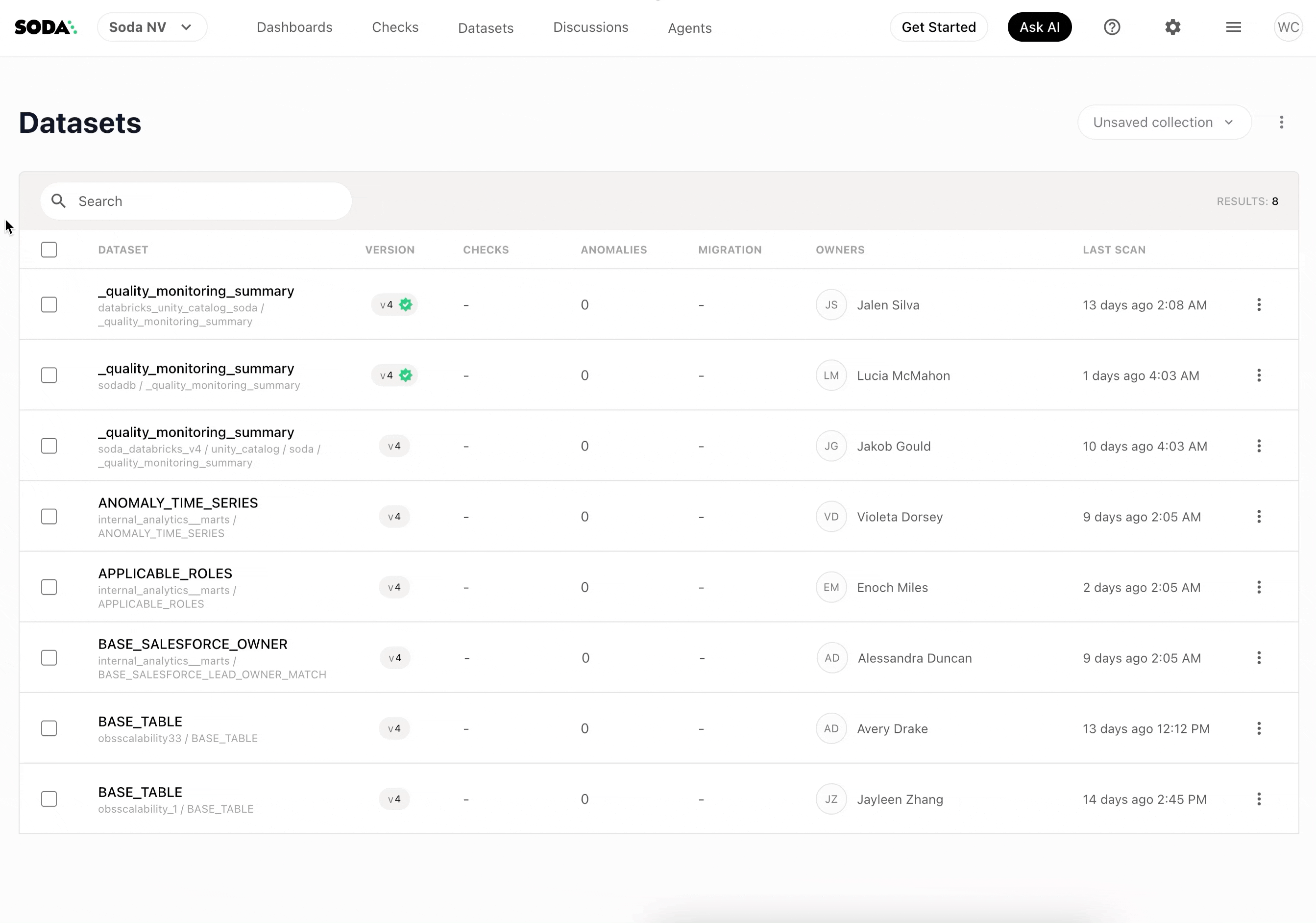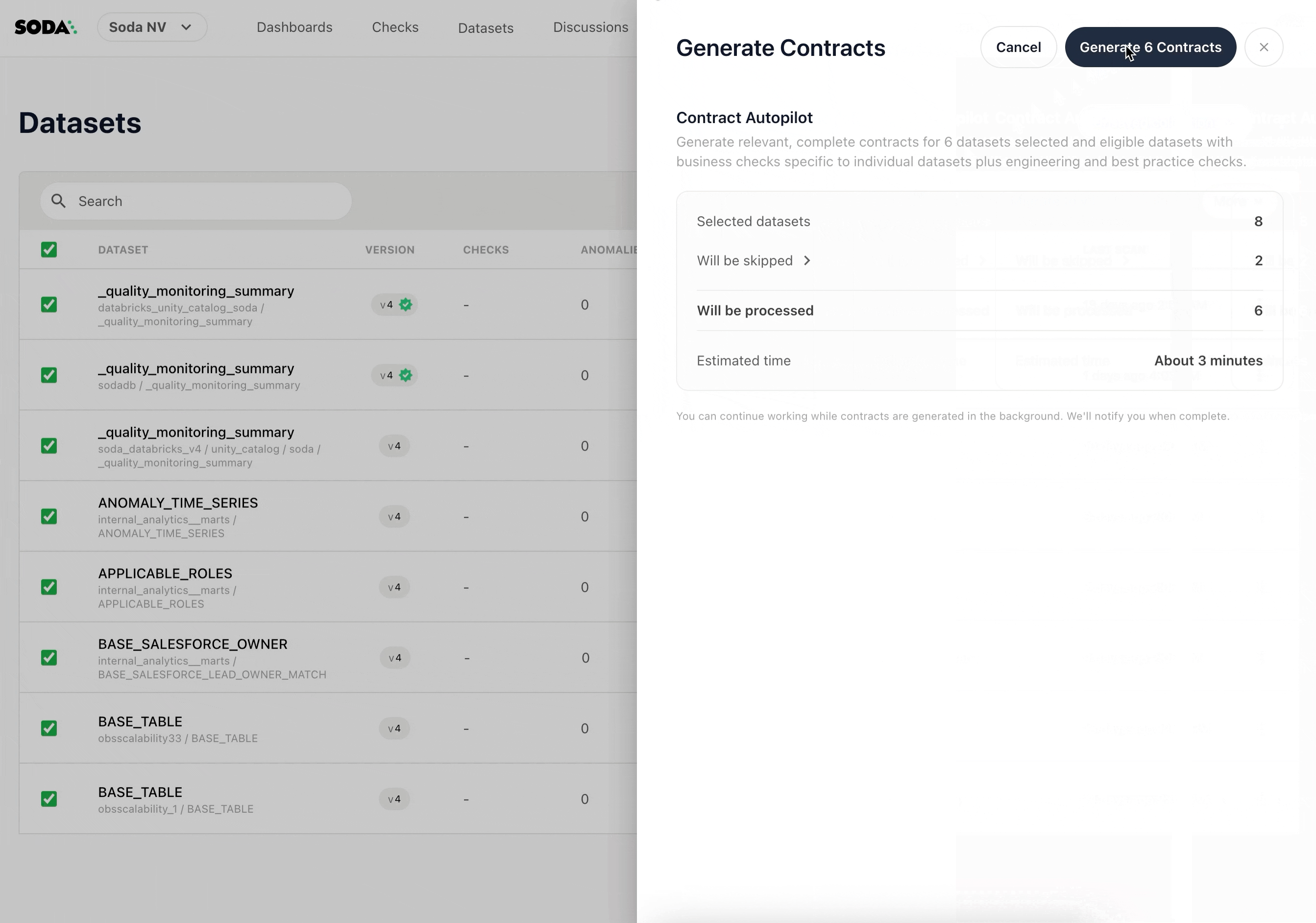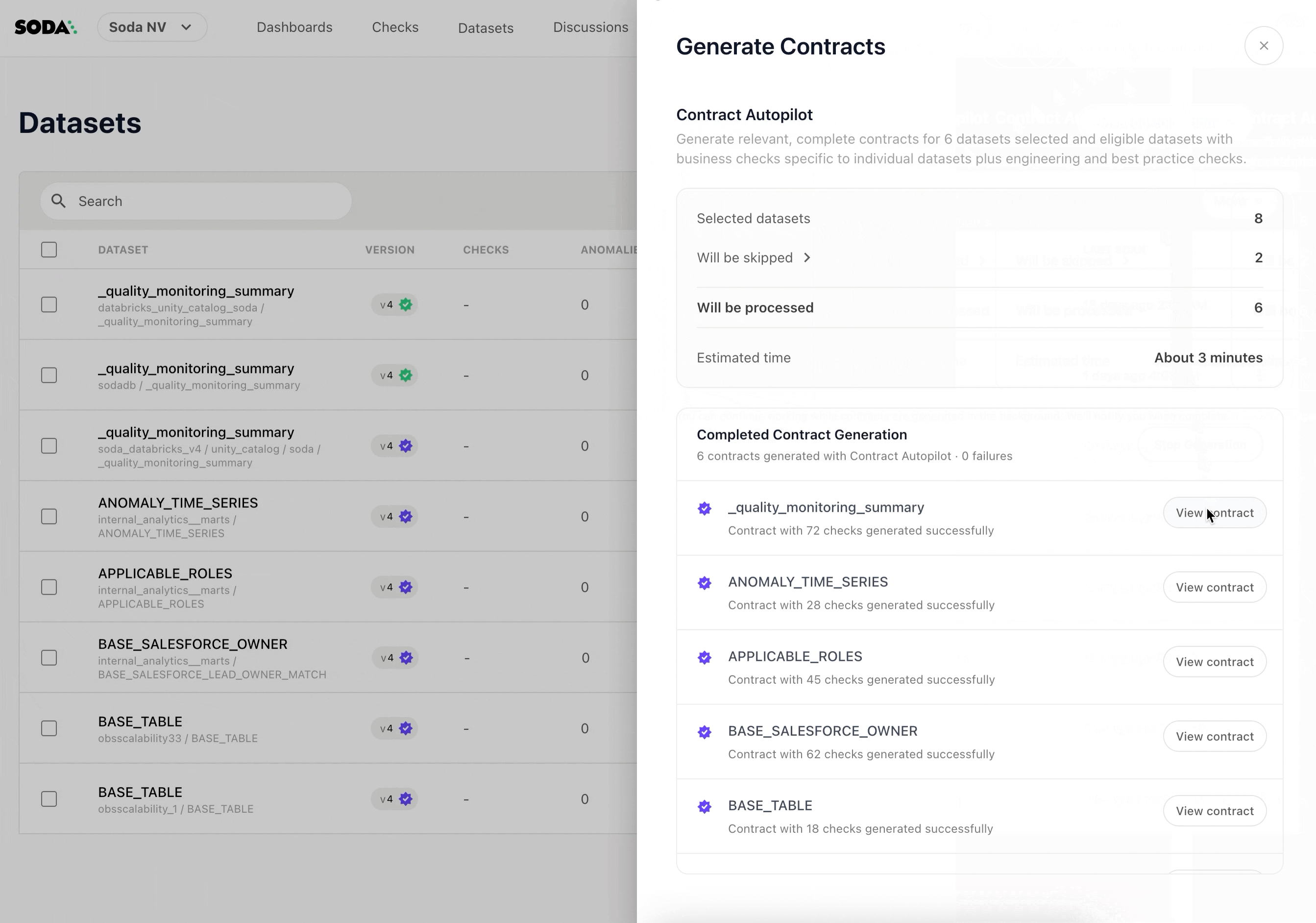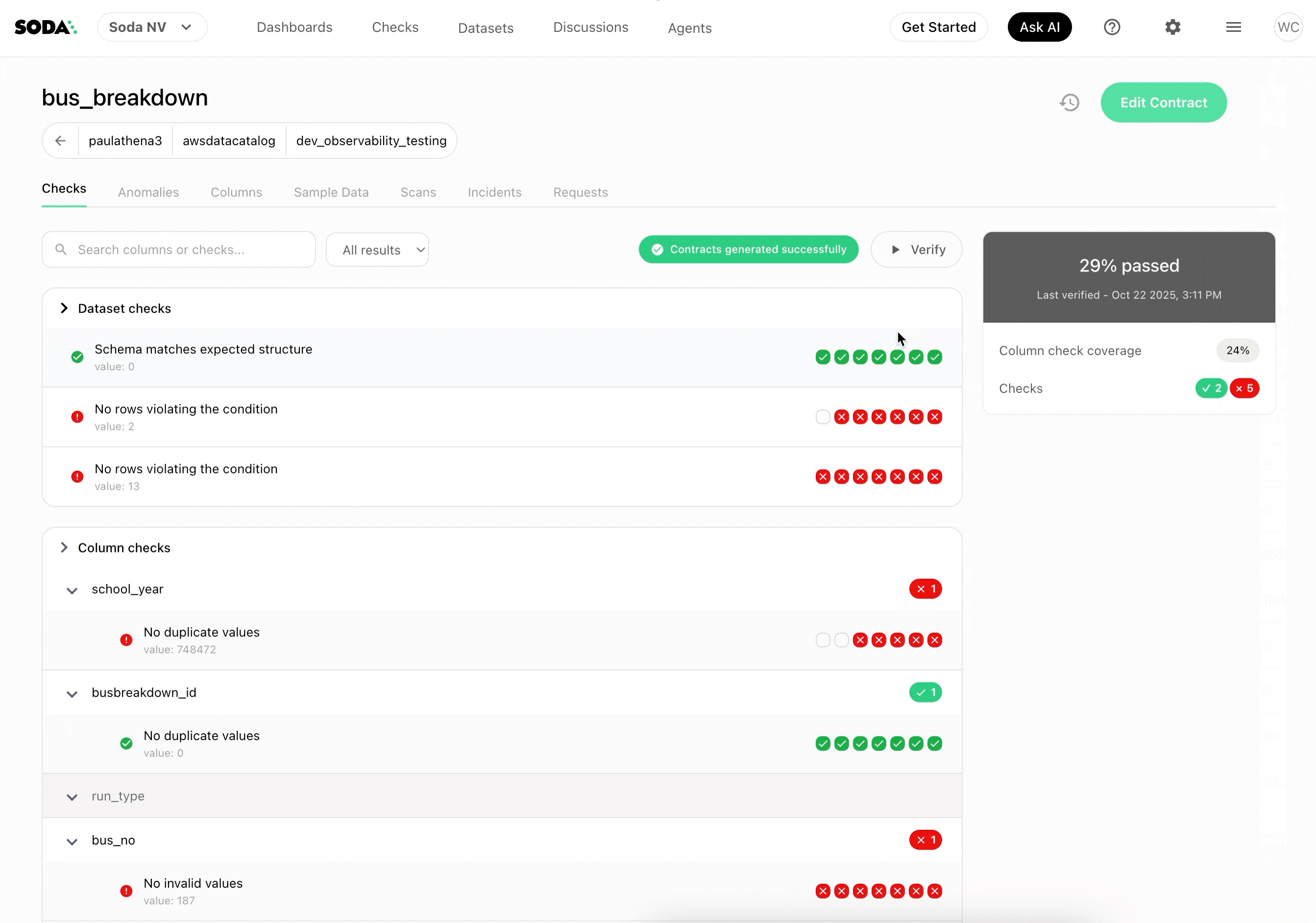
Another area of focus is increasing automation in how contracts are created and maintained. With Contract Autopilot (now in private preview), Soda is experimenting with deriving contract recommendations directly from existing data. By analyzing schema, metadata, and observed data patterns, this AI-assisted contract generator can propose baseline contracts across many tables at once. These recommendations are meant to serve as a starting point, helping teams establish initial guarantees more quickly and then refine them over time as ownership and requirements become clearer.
Final Thoughts
Data contracts did not emerge because the industry suddenly fell in love with governance. They emerged because modern data platforms can no longer scale on implicit assumptions and scattered validations.
At their core, contracts are not descriptions of data. They are instructions for validation. They make expectations explicit and enforceable, defining clear compatibility boundaries for schema, volume, freshness, and validity. Instead of discovering problems at the point of consumption, pipelines can detect breaking changes at controlled checkpoints before data is published.
This shift matters. The rise of data contracts is less about adopting a new best practice and more about a change in maturity. As platforms grow more decentralized and interconnected, teams need shared guarantees that travel across systems and organizational boundaries.
Data contracts do not make data “good” by themselves. What they do is create the conditions under which quality, governance, and reliability can be enforced consistently at scale.
Schedule a talk with our team of experts or request a free account to discover how Soda integrates with your existing stack to address current challenges.
Frequently Asked Questions
Ask five data engineers what a data contract is, and you will likely get five different answers. Some will overlap. Others will subtly contradict each other.
That confusion comes from how the term is used today. Different tools describe data contracts through their own lens. Catalog tools focus on schemas and ownership. Data quality tools emphasize checks, SLAs, and freshness. Governance and access tools often fold in policies and permissions. All of them are partially right, but collectively incomplete.
This makes data contracts sound broader… and vaguer than they really are. Teams hear that contracts will fix data quality, governance, ownership, and speed, yet still struggle with basic questions: what exactly belongs in a contract, where it lives, how it is enforced, and who is accountable for it over time?
This article treats data contracts as a concrete, operational engineering pattern. Its goal is to establish a clear, end-to-end mental model for data contracts: what problem they solve, what they actually contain, and how they are implemented. Most importantly, it draws a clear line around how data contracts should be enforced in modern data platforms.
Key Takeaways |
|---|
|
Data Contracts 101
A data contract is an enforceable agreement between data producers and data consumers. It defines how data should be structured, validated, and governed as it moves through a pipeline. But the key aspect is that the rules in a data contract aren’t just documented; they must be continuously verified against incoming data.
In practice, data contracts act as checkpoints:
As data flows through pipelines, the contract automatically determines whether it can safely move to consumers. If the data meets the contract, it moves forward. If it doesn’t, it stops.
When a contract check fails, it produces a clear signal that something deviated from expectation. Integrated into CI/CD or orchestration workflows, these failures can notify responsible teams or block propagation until the issue is understood and resolved.
By making expectations explicit and enforceable, contracts remove ambiguity and eliminate undocumented assumptions about data behavior. The goal is to prevent downstream breakage and keep transformations stable and reliable.
Common Misconceptions
⛔️ Data Contracts are just documentation
Data contracts enforce expectations, not simply describe them.
Unlike traditional documentation, data contracts are typically expressed as code, most often in declarative formats such as YAML, stored in version control, and validated automatically during pipeline execution or deployment.
⛔️ Data Contracts over-constrain datasets
Data contracts define stability boundaries, not immutability.
Well-designed contracts specify what consumers can rely on, while allowing producers to evolve internal logic, add fields, or introduce new versions safely. Overly strict contracts are usually a design problem, not a limitation of the concept. The goal is safe change, not no change.
⛔️ Data Contracts are Data Products
A data contract is not a product by itself, but one component of a data product.
A data product is a cleaned, reusable, and secure data asset. It combines data with metadata, documentation, and quality standards to make it reliable and easy to consume. A single data product may expose multiple datasets, tables, or views, each serving different consumers and use cases. Each of those outputs can carry different expectations around schema, freshness, quality, or access, and therefore requires its own contract.
Contracts define the standards a data product should meet to be safely consumed.
Fundamental Elements of a Data Contract
A contract that cannot be enforced is not a contract, it is documentation with good intentions.
While data contracts can include technical and business descriptive context, such as ownership, documentation, or security requirements, the core value comes from what can be enforced automatically.
Enforceable Rules
Most organizations already have data standards. But they often live in static documents or catalog descriptions. These descriptions define what data should look like, but they do not translate into pipeline execution. This creates a gap between governance and reality.
Data contracts close that gap by encoding expectations in a form that can be executed.
With git-managed contracts, you can create, edit, and run contracts as code using YAML. This gives you full control over how your data is validated, and allows you to manage contracts just like any other code artifact: versioned, tested, and deployed via Git.
Every data contract begins with three essential elements that define its scope and purpose:
Dataset identification establishes what data you’re protecting. This includes:
which data source it comes from
its location in your data warehouse or lake (database and schema)
the dataset name
Think of this as the “address” of your data, without it, you can’t enforce any rules.
datasetDataset-level checks that verify the overall structure of your table.
Schema: Detects unexpected column additions, removals, or type changes
Freshness: Validates data meets your SLA (e.g., no more than 24 hours old based on a timestamp column)
Row count: Confirms the dataset actually contains data before consumption
With these, you ensure that any missing columns, unexpected data types, or reordered fields are detected early, that the data source has at least a minimum number of records and no unexpected gaps, and that there are no unexpected delays.
checks: - schema: allow_extra_columns: false allow_other_column_order: false - row_count: threshold: must_be_greater_than: 0
Column-level checks validate individual field quality and business logic.
Missing: Ensures critical identifiers like
idordateare never nullDuplicate: Ensures that values in a column or combination of columns are unique.
Invalid: Verifies values based on semantic type, a list of valid values, a regular expression, min/max value or character length.
Aggregate: Ensures that summary statistics (
avg,sum,min, etc.) over a column remain within acceptable ranges.
columns: - name: id data_type: varchar checks: - missing: - duplicate: - name: date data_type: timestamp checks: - missing: - name: column_1 data_type: varchar checks: - missing: - invalid: valid_min_length: 1 valid_max_length: 255 - name: column_2 data_type: varchar checks: - invalid: valid_values: ["C", "A", "D"] - name: column_3 data_type: integer checks: - aggregate: function: avg threshold: must_be_between: greater_than: 20 less_than: 50
Other customization options let you tailor contracts to your business context.
Thresholds: Define acceptable ranges or failure percentages
Filters: Apply checks to specific data subsets (e.g., high-value orders only)
Qualifiers: Create unique identities for multiple checks on the same column
Attributes: Organize checks by domain, priority, or sensitivity (PII classification)
Go to Soda Docs to learn more about how to create and edit git-managed data contracts. |
|---|
Once encoded in a contract, these expectations become executable specifications that can be validated consistently across environments: during development, deployment, and production runs. This allows expectations around schema, data types, constraints, and freshness to be continuously tested.
This rule enforcement doesn’t always mean hard blocking. Depending on the use case, it can involve alerting, quarantining data, or triggering controlled remediation workflows.
Central Source of Truth
In a typical data platform, quality checks are embedded wherever a team happens to notice a problem. A row-count assertion in an ingestion job. A schema test in a transformation model. A freshness check in a dashboard query.
Each check makes sense in isolation, but together they form a patchwork of partial guarantees. No single system has a complete view of what “good data” actually means.
Data contracts address this by extracting expectations from scattered code paths and turning them into a central, enforceable specification. They do not eliminate existing checks; they unify them.
Instead of ad-hoc validation logic that protects individual pipelines and late-stage debugging, contracts define shared guarantees that every system in the data lifecycle can verify with a consistent enforcement mechanism: a schema enforced in one transformation job protects that job; a schema defined as a contract protects every downstream consumer that relies on it.
Interface Between Producers and Consumers
A data contract is also an agreement between data producers and data consumers that defines the guarantees a dataset must satisfy as it moves through a pipeline.
This idea is borrowed directly from software engineering. APIs define strict interfaces between services so that teams can work independently without breaking each other. Data contracts apply the same discipline to data pipelines by establishing clear interfaces between data producers and consumers, separating internal implementation details from external expectations.
Consumers specify the guarantees they depend on to build reports, models, and applications.
Producers take responsibility for meeting those guarantees by delivering data that conforms to the agreed expectations.
Contract validation functions as a built-in control point. Every dataset update is evaluated against the published contract before it is released to consumers.
This workflow makes expectations explicit and shared. It allows teams to detect breaking changes early, identify incompatible updates quickly, and prevent silent failures from propagating through the platform.
Read more about this in “What Are Data Contracts And Why Do They Matter?” |
|---|
Why Do We Need Data Contracts?
Today, quality enforcement is usually implemented through checks within data pipelines that validate schema, nullability, and basic ranges. Engineers add these checks as data moves through ingestion and transformation steps. While useful, these validations operate locally: each pipeline enforces its own rules, based on local context and individual judgment. No single system has visibility into the full set of expectations placed on a dataset.
We need data contracts because modern data platforms cannot scale on implicit assumptions. Contracts replace informal expectations with explicit, machine-verifiable specifications that are validated before data is consumed.
In practice, this means replacing expectations around data with clear, testable guarantees, defined centrally and validated automatically. This helps surface failures before they reach dashboards, models, or business decisions.
Over the past decades, priorities in data management have shifted and expectations around data have risen to a whole new level. Most organizations today operate data architectures that are decentralized by necessity. Event-driven systems, domain-owned services, multiple ingestion paths, real-time and batch pipelines, and a growing dependency on analytics all coexist.
This complexity is the natural outcome of building data platforms that serve many use cases at speed. The cost of this breadth of scope, however, is that trust becomes harder to establish and easier to lose.
The pressure increases further with the rise of AI initiatives. As organizations adopt ML systems, autonomous workflows, and agentic decision engines, data can no longer be “mostly correct.” It must be predictably correct, consistently shaped, and delivered on time to be usable at scale.
Data contracts respond to this reality by making expectations explicit, shared, and enforceable across data products. Instead of discovering issues after data has already propagated downstream, teams can detect and block breaking changes at defined control points in the pipeline.
Read more about this in “Why Data Contracts: 5 Reasons Leaders Should Start Now” |
|---|
Technical Meets Business Stakeholder
Data contracts also matter because they address different risks for different stakeholders—and actually only work when both sides are aligned.
They provide a shared boundary where organizational ownership, technical enforcement, and operational accountability meet. Without that boundary, expectations remain implicit, enforcement is fragmented, and failures surface late, often in the hands of the wrong team.
Key Use Cases
The same data contract serves different purposes depending on whether you build data pipelines, consume analytical outputs, or rely on data for operational decisions.
For data producers (data engineers and architects)
Data contracts make delivery more predictable by turning expectations into machine-readable definitions that can be validated automatically.
In practice, this means:
Catching schema drift before it breaks downstream models
Blocking incomplete or late data before publication
Shipping changes faster because expectations are explicit and versioned
Contracts fit naturally into engineering workflows through Git, automation, and orchestration, replacing ad-hoc validation logic scattered across jobs with a single, reviewable specification.
For data consumers (analysts, data scientists, and ML teams)
Data contracts provide a reliable basis for consumption. This allows consumers to:
Verify structure, freshness, and basic quality constraints before building
Assess whether a dataset is suitable for reporting, experimentation, or production models
Detect breaking changes through contract violations rather than silent metric drift
As a result, downstream work becomes more predictable, and failures shift from late-stage analysis to early-stage validation.
For data governance and stewardship teams
Data contracts offer a practical way to operationalize governance. In practice, this enables governance teams to:
Define standards once and verify their application across data products
Tie expectations to owners and domains with clear accountability
Gain visibility into where contracts pass, fail, or drift over time
Instead of reviewing policies after incidents occur, governance teams gain continuous feedback on how standards operate in production.
The result is predictable change management: fewer downstream incidents, clearer ownership, and safer deployments without restricting system evolution.
Data Contracts Ecosystem
In the Gartner Hype Cycle for Data Management 2025, data contracts appear as an emerging mechanism for building trust, enforcing governance, and reducing the time it takes for data to deliver real value.
Gartner frames data contracts as a response to the realities of modern data platforms: AI workloads, decentralized ownership models such as data mesh, and the growing difficulty of keeping data quality and consistency under control as systems scale.
Rather than a short-lived trend, data contracts are treated as a structural component of mature data ecosystems, helping teams manage complexity and produce data that is reliable enough to be used safely by analytical and AI systems.
However, “data contracts” do not refer to a single type of tool or implementation. The ecosystem includes governance systems, descriptive standards, and execution engines — each operating at a different layer of the stack. Understanding these layers is essential to understanding what data contracts can (and cannot) actually enforce.
Governance Platforms and Data Contracts
Data contracts are no longer limited to engineering tools, they are becoming part of enterprise governance strategies.
Governance platforms such as Collibra and Atlan play an important role in the data contracts ecosystem by focusing on organization-wide visibility, discoverability, and lifecycle management of contract definitions.
In this model, a data contract can be created and stored alongside other governance metadata and integrated with permissions, stewardship workflows, and lifecycle processes already used to manage data products. It defines ownership, expected schema, and usage constraints in a way that is visible across the organization.
However, governance-layer contracts are typically descriptive: they capture expectations in catalogs and workflows, but they do not inherently enforce those expectations at runtime.
In practice, governance platforms serve as authoritative descriptions of what should be true, but they still rely on external execution engines to validate whether the data meets the agreed-upon conditions.
This distinction is architectural: governance systems operate at the policy and metadata layer, while execution systems operate inside pipelines and production environments.
By integrating governance definitions with systems that can execute and evaluate those expectations, teams close the gap between policy and practice. Read our article about how to Operationalize Data Governance with Collibra and Soda. |
|---|
Descriptive Data Contract Formats
The concept “data contract” is definitely gaining traction, but the industry is still working out what “doing it right” actually means. As adoption grows, the industry has started to converge on shared ways to describe data contracts.
A useful way to think about this ecosystem is to separate descriptive specifications from execution mechanisms. Below are two common descriptive contract formats. Let’s see what they contain and what they are missing.
Open Data Contract
The Open Data Contract (ODCS) defines a structured, YAML format for describing datasets and their expectations.
From a conceptual standpoint, ODCS focuses on the descriptive layer of data contracts. The purpose is to create a common language for describing data contracts in a way that tools, catalogs, and teams can understand consistently.
See the example YAML file below. It describes the schema and a cross-table reference:
schema: - id: users_tbl name: users properties: - id: user_id_pk name: id logicalType: integer relationships: - to: schema/accounts_tbl/properties/acct_user_id description: "Fully qualified reference using id fields"
However, the ODCS does not prescribe how often validation should occur, how failures should block pipelines, or how violations should be escalated. Those responsibilities belong to execution systems.
In other words, ODCS is designed to be a declarative specification, not an orchestration tool. It defines the “what” (the interface and expectations), while leaving the “how” and “when” (the implementation) to the systems that process the data.
dbt Model Contracts
dbt model contracts address a more specific problem: preventing accidental schema changes at the transformation boundary.
Defined in a model’s YAML configuration, dbt contracts tell dbt to validate that a model’s output matches an expected set of columns, data types, and basic constraints before materialization. If the contract is violated, the dbt run fails.
See the example dbt model schema below. The model will only materialize if the output table has the defined columns, data types, and constraints (in this case, order_id cannot be null):
models: - name: dim_orders config: materialized: table contract: enforced: true columns: - name: order_id data_type: int constraints: - type: not_null - name: order_type data_type
Because of this narrow scope, dbt contracts are best understood as schema contracts for transformations. They protect downstream models within a dbt DAG, providing valuable local safety. But they are not designed to function as full data contracts across the data lifecycle.
dbt enforces structural correctness at build time, but it does not monitor data freshness, distribution shifts, volume anomalies, or record-level integrity once data is in production.
Executable Data Contract Formats
Although governance platforms and descriptive contract formats have significantly improved how teams define and share expectations about data, what they do not solve on their own is continuous enforcement at runtime.
In today’s ecosystem, relatively few tools address this execution layer directly. Many solutions focus on documentation, metadata, or schema definitions, but stop short of continuous validation against live data.
Execution-focused data contracts address this gap by treating contracts as active control points in the data lifecycle. At this layer, a contract is not just stored, it is executed. Violations can block deployments, stop pipelines, trigger alerts, or initiate remediation workflows.
Teams need contracts that can be:
→ validated automatically in pipelines,
→ integrated into CI/CD workflows,
→ versioned and reviewed like code,
→ and enforced consistently across systems.
This shifts data contracts from static specifications to operational safeguards that influence whether data is allowed to move forward, trigger alerts, or require remediation.
Soda Data Contracts
Soda data contracts close the execution gap by focusing on the executable core of a data contract: the quality, freshness, and structural expectations that can be continuously validated against production data.
By embedding contract verification into pipelines, data contracts function as ongoing enforcement mechanisms.
Have a look at the structure of a Soda YAML data contract:
Execution engines such as Soda Core handle the mechanics of running dataset and column-level checks against real data within data pipelines and orchestration workflows.
Soda supports contract execution across a wide range of data sources, including PostgreSQL, Snowflake, BigQuery, Databricks, DuckDB, and others. Click to see all Soda Integrations. |
|---|
The Missing Layer: Contract Enforcement
As we could see, the missing layer in most data contracts is execution. Contracts exist, but enforcement is inconsistent, fragmented, or delayed, and violations are often only discovered downstream.
Execution usually fails not because expectations are unclear, but because enforcing them at scale introduces new challenges: keeping contracts up to date, aligning business and engineering inputs, and understanding why a contract failed.
Then, the question now is not what a data contract contains, but how those contracts must be implemented and enforced in real systems.
Contracts as a Shared Interface
Because data contracts sit at the boundary between producers and consumers, collaboration is unavoidable. Execution-focused approaches recognize this and design contracts as shared operational assets.
Producers and consumers create contracts to define both sides’ expectations, and the execution engine must ensure those expectations are evaluated automatically, at scale, and across environments.
This turns contracts into a bi-directional workflow: expectations flow from the business, enforcement flows through engineering, and feedback flows back through execution results. Accountability becomes explicit because failures are tied to concrete rules and owners rather than informal assumptions.
Turning Business Intent Into Executable Rules
One of the hardest parts of contract-driven workflows is translating business expectations into enforceable checks. This translation is often manual, slow, and error-prone.
Soda Cloud is a unified platform for centralized management of data contracts, including authoring, running, and collaborating across teams.
To lower the barrier to participation without weakening enforcement, technical teams can define and validate rules as code while non-technical stakeholders can propose or review expectations using the UI. Changes are tracked, versioned, and evaluated automatically once approved.
Example Soda Cloud data contract:
On top of that, Soda supports AI-assisted contract authoring, allowing teams to express expectations in plain language and convert them into executable data quality rules that engineers can review and deploy.
One Contract to Rule Them All
Another challenge with contract adoption is fragmentation. Schema checks live in transformations. Freshness checks live in monitoring tools. Business rules live in documentation. Each system enforces a partial view of “correctness.”
Execution-focused contracts consolidate those expectations into one machine-readable specification that can be evaluated consistently across environments and platforms as the single source of truth.
This means contracts become an active infrastructure that enforces expectations for schema, data quality, freshness, and other constraints as data flows through your architecture.
Scaling Contracts Beyond the First Dataset
Defining a data contract for a single dataset is rarely the hard part. The real challenge begins when contracts need to be applied at scale. At that point, speed and standardization start to pull in opposite directions.
Soda provides a range of built-in data quality checks and predefined contract templates covering common dimensions such as schema integrity, completeness, validity, freshness, and volume, as well as more advanced validation logic.
Soda contract templates help teams get started quickly without having to create contracts from scratch, while encouraging consistency across data products by encoding reusable expectations that scale across domains.
Continuous Contract Validation
Execution-focused contracts assume that every dataset update is a release event. Each run is evaluated against the same set of guarantees—schema, quality, freshness—before the data is exposed downstream.
This model treats data contracts much like software tests: they are versioned, reviewed, and executed automatically as part of normal delivery.
In practice, this shifts contract enforcement from occasional checks to continuous validation embedded directly into pipelines and orchestration workflows. This shifts data quality issues from silent failures to actionable signals with clear ownership.
Making Contract Evolution Explicit and Safe
We must remember, though, that data contracts are not static. As data products evolve, expectations change — and unmanaged changes are a common source of breakage.
Soda treats contracts as versioned artifacts, preserving a complete history of changes, proposals, and approvals. This makes evolution explicit and reviewable, and allows teams to understand when, why, and how specifications were modified.
Diagnosing Failures, Not Just Flagging Them
Contract enforcement only creates value if failures are actionable and understandable. It’s not enough to signal that something broke; teams need to know what broke, where, and why in order to resolve it quickly.
Soda captures diagnostic context — including failed rows, check metadata, scan history, and dataset attributes — into a centralized diagnostics warehouse inside your own data warehouse. This means every contract violation is stored where your engineers already work, without moving data outside your environment.
How Different Data Contract Approaches Compare
To sum up, most implementations fall somewhere along a spectrum between policy definition and runtime execution.
Policy-oriented platforms, such as governance tools and descriptive standards, focus on declaring intent. They capture expectations around structure, ownership, and rules in a centralized, readable format. This is essential for alignment and accountability, but enforcement typically happens elsewhere.
Execution-oriented approaches focus on making those expectations enforceable. Contracts are evaluated automatically during pipeline runs, deployments, or scheduled checks. When expectations are violated, systems can fail fast, alert owners, or block propagation. Here, the contract actively shapes system behavior rather than documenting it.
Have a look at some differences below between ODCS and Soda contracts’ syntax.
We are soon going to launch a tool to translate descriptive ODCS into executable Soda data contracts. Stay tuned!
Data Contract Layers at a Glance
The table below summarizes how common approaches fit into the broader data contracts ecosystem.
These approaches are not mutually exclusive. Mature data platforms often combine governance-layer definitions, standardized specifications, and runtime enforcement mechanisms.
Dimension | Governance Platforms | ODCS | dbt Contracts | Soda Data Contracts |
|---|---|---|---|---|
Primary Layer of Operation | Governance & metadata | Specification standard | Transformation boundary | Runtime enforcement |
Primary Goal | Define ownership, policy, lifecycle | Standardize contract structure | Prevent schema drift in models | Enforce data quality & behavior across lifecycle |
Nature of the Contract | Policy & metadata artifact | Descriptive YAML specification | Declarative model constraint | Executable contract evaluated against live data |
Scope of Enforcement | Ownership, policy visibility | Schema & relationships | Schema + basic constraints | Schema, quality rules, freshness, volume, anomalies |
Compile-Time Enforcement | No | No | Yes (during dbt run) | Yes |
Continuous Runtime Validation | No | No | No | Yes |
Pre-Ingestion / In-Motion Enforcement | No | No | No | Yes |
Pipeline Blocking Capability | No | No | dbt-only scope | Across systems |
Data Quality Coverage | Descriptive only | Descriptive only | Limited (structural) | Broad (dataset, column, record-level) |
CI/CD Integration | Indirect via workflows | No | Native in dbt | Native across CI & orchestration |
Handling Breaking Changes | Documented & workflowed | Documented | Caught in model execution | Blocked before downstream propagation |
Typical User | Governance teams, data owners | Architects, standards bodies | Analytics engineers | Data engineers, data stewards |
Best Fit | Enterprise governance & accountability | Interoperability & tooling alignment | dbt-centric stacks | Production-grade, operational data platforms |
The Future of Data Contracts
As systems grow more complex and expectations around data reliability rise, teams need a way to make trust explicit without slowing down delivery. What started as a way to clarify expectations is becoming a core building block for reliable, scalable data systems.
What’s driving this shift:
➡️ Stronger governance pressure: Regulatory requirements, auditability, and data reliability expectations are increasing. Data contracts offer a structured way to define and share expectations without turning governance into a bottleneck.
➡️ Earlier validation (“shift left”): Teams are validating contracts during development and CI/CD instead of tackling breaking changes in production. This is moving failures closer to where changes happen, reducing incident impact, and aligning data workflows with DevOps and DataOps practices.
➡️ AI-assisted contract authoring: AI is lowering the barrier to defining contracts. Business and governance teams can express expectations in plain language, while tools translate those expectations into executable rules. This will reduce back-and-forth and speed up adoption.
➡️ Decentralized data architectures: Data mesh, domain ownership, and hybrid platforms require shared, machine-readable expectations. Data contracts provide a common interface that is allowing teams to evolve independently while still working within consistent enterprise-wide rules.
Taken together, these trends point to data contracts becoming the default way to manage expectations at scale, combining clarity, automation, and enforcement.
What it Means at Soda
Looking ahead, Soda’s direction for data contracts is a natural extension of treating contracts as executable control points, not just quality checks.
Today, contracts define and enforce quality and structure. The longer-term goal is to broaden their scope to cover additional controls such as access policies, retention rules, and lifecycle constraints, using the same contract-as-code approach.
Another area of focus is increasing automation in how contracts are created and maintained. With Contract Autopilot (now in private preview), Soda is experimenting with deriving contract recommendations directly from existing data. By analyzing schema, metadata, and observed data patterns, this AI-assisted contract generator can propose baseline contracts across many tables at once. These recommendations are meant to serve as a starting point, helping teams establish initial guarantees more quickly and then refine them over time as ownership and requirements become clearer.
Final Thoughts
Data contracts did not emerge because the industry suddenly fell in love with governance. They emerged because modern data platforms can no longer scale on implicit assumptions and scattered validations.
At their core, contracts are not descriptions of data. They are instructions for validation. They make expectations explicit and enforceable, defining clear compatibility boundaries for schema, volume, freshness, and validity. Instead of discovering problems at the point of consumption, pipelines can detect breaking changes at controlled checkpoints before data is published.
This shift matters. The rise of data contracts is less about adopting a new best practice and more about a change in maturity. As platforms grow more decentralized and interconnected, teams need shared guarantees that travel across systems and organizational boundaries.
Data contracts do not make data “good” by themselves. What they do is create the conditions under which quality, governance, and reliability can be enforced consistently at scale.
Schedule a talk with our team of experts or request a free account to discover how Soda integrates with your existing stack to address current challenges.
Frequently Asked Questions
Ask five data engineers what a data contract is, and you will likely get five different answers. Some will overlap. Others will subtly contradict each other.
That confusion comes from how the term is used today. Different tools describe data contracts through their own lens. Catalog tools focus on schemas and ownership. Data quality tools emphasize checks, SLAs, and freshness. Governance and access tools often fold in policies and permissions. All of them are partially right, but collectively incomplete.
This makes data contracts sound broader… and vaguer than they really are. Teams hear that contracts will fix data quality, governance, ownership, and speed, yet still struggle with basic questions: what exactly belongs in a contract, where it lives, how it is enforced, and who is accountable for it over time?
This article treats data contracts as a concrete, operational engineering pattern. Its goal is to establish a clear, end-to-end mental model for data contracts: what problem they solve, what they actually contain, and how they are implemented. Most importantly, it draws a clear line around how data contracts should be enforced in modern data platforms.
Key Takeaways |
|---|
|
Data Contracts 101
A data contract is an enforceable agreement between data producers and data consumers. It defines how data should be structured, validated, and governed as it moves through a pipeline. But the key aspect is that the rules in a data contract aren’t just documented; they must be continuously verified against incoming data.
In practice, data contracts act as checkpoints:
As data flows through pipelines, the contract automatically determines whether it can safely move to consumers. If the data meets the contract, it moves forward. If it doesn’t, it stops.
When a contract check fails, it produces a clear signal that something deviated from expectation. Integrated into CI/CD or orchestration workflows, these failures can notify responsible teams or block propagation until the issue is understood and resolved.
By making expectations explicit and enforceable, contracts remove ambiguity and eliminate undocumented assumptions about data behavior. The goal is to prevent downstream breakage and keep transformations stable and reliable.
Common Misconceptions
⛔️ Data Contracts are just documentation
Data contracts enforce expectations, not simply describe them.
Unlike traditional documentation, data contracts are typically expressed as code, most often in declarative formats such as YAML, stored in version control, and validated automatically during pipeline execution or deployment.
⛔️ Data Contracts over-constrain datasets
Data contracts define stability boundaries, not immutability.
Well-designed contracts specify what consumers can rely on, while allowing producers to evolve internal logic, add fields, or introduce new versions safely. Overly strict contracts are usually a design problem, not a limitation of the concept. The goal is safe change, not no change.
⛔️ Data Contracts are Data Products
A data contract is not a product by itself, but one component of a data product.
A data product is a cleaned, reusable, and secure data asset. It combines data with metadata, documentation, and quality standards to make it reliable and easy to consume. A single data product may expose multiple datasets, tables, or views, each serving different consumers and use cases. Each of those outputs can carry different expectations around schema, freshness, quality, or access, and therefore requires its own contract.
Contracts define the standards a data product should meet to be safely consumed.
Fundamental Elements of a Data Contract
A contract that cannot be enforced is not a contract, it is documentation with good intentions.
While data contracts can include technical and business descriptive context, such as ownership, documentation, or security requirements, the core value comes from what can be enforced automatically.
Enforceable Rules
Most organizations already have data standards. But they often live in static documents or catalog descriptions. These descriptions define what data should look like, but they do not translate into pipeline execution. This creates a gap between governance and reality.
Data contracts close that gap by encoding expectations in a form that can be executed.
With git-managed contracts, you can create, edit, and run contracts as code using YAML. This gives you full control over how your data is validated, and allows you to manage contracts just like any other code artifact: versioned, tested, and deployed via Git.
Every data contract begins with three essential elements that define its scope and purpose:
Dataset identification establishes what data you’re protecting. This includes:
which data source it comes from
its location in your data warehouse or lake (database and schema)
the dataset name
Think of this as the “address” of your data, without it, you can’t enforce any rules.
datasetDataset-level checks that verify the overall structure of your table.
Schema: Detects unexpected column additions, removals, or type changes
Freshness: Validates data meets your SLA (e.g., no more than 24 hours old based on a timestamp column)
Row count: Confirms the dataset actually contains data before consumption
With these, you ensure that any missing columns, unexpected data types, or reordered fields are detected early, that the data source has at least a minimum number of records and no unexpected gaps, and that there are no unexpected delays.
checks: - schema: allow_extra_columns: false allow_other_column_order: false - row_count: threshold: must_be_greater_than: 0
Column-level checks validate individual field quality and business logic.
Missing: Ensures critical identifiers like
idordateare never nullDuplicate: Ensures that values in a column or combination of columns are unique.
Invalid: Verifies values based on semantic type, a list of valid values, a regular expression, min/max value or character length.
Aggregate: Ensures that summary statistics (
avg,sum,min, etc.) over a column remain within acceptable ranges.
columns: - name: id data_type: varchar checks: - missing: - duplicate: - name: date data_type: timestamp checks: - missing: - name: column_1 data_type: varchar checks: - missing: - invalid: valid_min_length: 1 valid_max_length: 255 - name: column_2 data_type: varchar checks: - invalid: valid_values: ["C", "A", "D"] - name: column_3 data_type: integer checks: - aggregate: function: avg threshold: must_be_between: greater_than: 20 less_than: 50
Other customization options let you tailor contracts to your business context.
Thresholds: Define acceptable ranges or failure percentages
Filters: Apply checks to specific data subsets (e.g., high-value orders only)
Qualifiers: Create unique identities for multiple checks on the same column
Attributes: Organize checks by domain, priority, or sensitivity (PII classification)
Go to Soda Docs to learn more about how to create and edit git-managed data contracts. |
|---|
Once encoded in a contract, these expectations become executable specifications that can be validated consistently across environments: during development, deployment, and production runs. This allows expectations around schema, data types, constraints, and freshness to be continuously tested.
This rule enforcement doesn’t always mean hard blocking. Depending on the use case, it can involve alerting, quarantining data, or triggering controlled remediation workflows.
Central Source of Truth
In a typical data platform, quality checks are embedded wherever a team happens to notice a problem. A row-count assertion in an ingestion job. A schema test in a transformation model. A freshness check in a dashboard query.
Each check makes sense in isolation, but together they form a patchwork of partial guarantees. No single system has a complete view of what “good data” actually means.
Data contracts address this by extracting expectations from scattered code paths and turning them into a central, enforceable specification. They do not eliminate existing checks; they unify them.
Instead of ad-hoc validation logic that protects individual pipelines and late-stage debugging, contracts define shared guarantees that every system in the data lifecycle can verify with a consistent enforcement mechanism: a schema enforced in one transformation job protects that job; a schema defined as a contract protects every downstream consumer that relies on it.
Interface Between Producers and Consumers
A data contract is also an agreement between data producers and data consumers that defines the guarantees a dataset must satisfy as it moves through a pipeline.
This idea is borrowed directly from software engineering. APIs define strict interfaces between services so that teams can work independently without breaking each other. Data contracts apply the same discipline to data pipelines by establishing clear interfaces between data producers and consumers, separating internal implementation details from external expectations.
Consumers specify the guarantees they depend on to build reports, models, and applications.
Producers take responsibility for meeting those guarantees by delivering data that conforms to the agreed expectations.
Contract validation functions as a built-in control point. Every dataset update is evaluated against the published contract before it is released to consumers.
This workflow makes expectations explicit and shared. It allows teams to detect breaking changes early, identify incompatible updates quickly, and prevent silent failures from propagating through the platform.
Read more about this in “What Are Data Contracts And Why Do They Matter?” |
|---|
Why Do We Need Data Contracts?
Today, quality enforcement is usually implemented through checks within data pipelines that validate schema, nullability, and basic ranges. Engineers add these checks as data moves through ingestion and transformation steps. While useful, these validations operate locally: each pipeline enforces its own rules, based on local context and individual judgment. No single system has visibility into the full set of expectations placed on a dataset.
We need data contracts because modern data platforms cannot scale on implicit assumptions. Contracts replace informal expectations with explicit, machine-verifiable specifications that are validated before data is consumed.
In practice, this means replacing expectations around data with clear, testable guarantees, defined centrally and validated automatically. This helps surface failures before they reach dashboards, models, or business decisions.
Over the past decades, priorities in data management have shifted and expectations around data have risen to a whole new level. Most organizations today operate data architectures that are decentralized by necessity. Event-driven systems, domain-owned services, multiple ingestion paths, real-time and batch pipelines, and a growing dependency on analytics all coexist.
This complexity is the natural outcome of building data platforms that serve many use cases at speed. The cost of this breadth of scope, however, is that trust becomes harder to establish and easier to lose.
The pressure increases further with the rise of AI initiatives. As organizations adopt ML systems, autonomous workflows, and agentic decision engines, data can no longer be “mostly correct.” It must be predictably correct, consistently shaped, and delivered on time to be usable at scale.
Data contracts respond to this reality by making expectations explicit, shared, and enforceable across data products. Instead of discovering issues after data has already propagated downstream, teams can detect and block breaking changes at defined control points in the pipeline.
Read more about this in “Why Data Contracts: 5 Reasons Leaders Should Start Now” |
|---|
Technical Meets Business Stakeholder
Data contracts also matter because they address different risks for different stakeholders—and actually only work when both sides are aligned.
They provide a shared boundary where organizational ownership, technical enforcement, and operational accountability meet. Without that boundary, expectations remain implicit, enforcement is fragmented, and failures surface late, often in the hands of the wrong team.
Key Use Cases
The same data contract serves different purposes depending on whether you build data pipelines, consume analytical outputs, or rely on data for operational decisions.
For data producers (data engineers and architects)
Data contracts make delivery more predictable by turning expectations into machine-readable definitions that can be validated automatically.
In practice, this means:
Catching schema drift before it breaks downstream models
Blocking incomplete or late data before publication
Shipping changes faster because expectations are explicit and versioned
Contracts fit naturally into engineering workflows through Git, automation, and orchestration, replacing ad-hoc validation logic scattered across jobs with a single, reviewable specification.
For data consumers (analysts, data scientists, and ML teams)
Data contracts provide a reliable basis for consumption. This allows consumers to:
Verify structure, freshness, and basic quality constraints before building
Assess whether a dataset is suitable for reporting, experimentation, or production models
Detect breaking changes through contract violations rather than silent metric drift
As a result, downstream work becomes more predictable, and failures shift from late-stage analysis to early-stage validation.
For data governance and stewardship teams
Data contracts offer a practical way to operationalize governance. In practice, this enables governance teams to:
Define standards once and verify their application across data products
Tie expectations to owners and domains with clear accountability
Gain visibility into where contracts pass, fail, or drift over time
Instead of reviewing policies after incidents occur, governance teams gain continuous feedback on how standards operate in production.
The result is predictable change management: fewer downstream incidents, clearer ownership, and safer deployments without restricting system evolution.
Data Contracts Ecosystem
In the Gartner Hype Cycle for Data Management 2025, data contracts appear as an emerging mechanism for building trust, enforcing governance, and reducing the time it takes for data to deliver real value.
Gartner frames data contracts as a response to the realities of modern data platforms: AI workloads, decentralized ownership models such as data mesh, and the growing difficulty of keeping data quality and consistency under control as systems scale.
Rather than a short-lived trend, data contracts are treated as a structural component of mature data ecosystems, helping teams manage complexity and produce data that is reliable enough to be used safely by analytical and AI systems.
However, “data contracts” do not refer to a single type of tool or implementation. The ecosystem includes governance systems, descriptive standards, and execution engines — each operating at a different layer of the stack. Understanding these layers is essential to understanding what data contracts can (and cannot) actually enforce.
Governance Platforms and Data Contracts
Data contracts are no longer limited to engineering tools, they are becoming part of enterprise governance strategies.
Governance platforms such as Collibra and Atlan play an important role in the data contracts ecosystem by focusing on organization-wide visibility, discoverability, and lifecycle management of contract definitions.
In this model, a data contract can be created and stored alongside other governance metadata and integrated with permissions, stewardship workflows, and lifecycle processes already used to manage data products. It defines ownership, expected schema, and usage constraints in a way that is visible across the organization.
However, governance-layer contracts are typically descriptive: they capture expectations in catalogs and workflows, but they do not inherently enforce those expectations at runtime.
In practice, governance platforms serve as authoritative descriptions of what should be true, but they still rely on external execution engines to validate whether the data meets the agreed-upon conditions.
This distinction is architectural: governance systems operate at the policy and metadata layer, while execution systems operate inside pipelines and production environments.
By integrating governance definitions with systems that can execute and evaluate those expectations, teams close the gap between policy and practice. Read our article about how to Operationalize Data Governance with Collibra and Soda. |
|---|
Descriptive Data Contract Formats
The concept “data contract” is definitely gaining traction, but the industry is still working out what “doing it right” actually means. As adoption grows, the industry has started to converge on shared ways to describe data contracts.
A useful way to think about this ecosystem is to separate descriptive specifications from execution mechanisms. Below are two common descriptive contract formats. Let’s see what they contain and what they are missing.
Open Data Contract
The Open Data Contract (ODCS) defines a structured, YAML format for describing datasets and their expectations.
From a conceptual standpoint, ODCS focuses on the descriptive layer of data contracts. The purpose is to create a common language for describing data contracts in a way that tools, catalogs, and teams can understand consistently.
See the example YAML file below. It describes the schema and a cross-table reference:
schema: - id: users_tbl name: users properties: - id: user_id_pk name: id logicalType: integer relationships: - to: schema/accounts_tbl/properties/acct_user_id description: "Fully qualified reference using id fields"
However, the ODCS does not prescribe how often validation should occur, how failures should block pipelines, or how violations should be escalated. Those responsibilities belong to execution systems.
In other words, ODCS is designed to be a declarative specification, not an orchestration tool. It defines the “what” (the interface and expectations), while leaving the “how” and “when” (the implementation) to the systems that process the data.
dbt Model Contracts
dbt model contracts address a more specific problem: preventing accidental schema changes at the transformation boundary.
Defined in a model’s YAML configuration, dbt contracts tell dbt to validate that a model’s output matches an expected set of columns, data types, and basic constraints before materialization. If the contract is violated, the dbt run fails.
See the example dbt model schema below. The model will only materialize if the output table has the defined columns, data types, and constraints (in this case, order_id cannot be null):
models: - name: dim_orders config: materialized: table contract: enforced: true columns: - name: order_id data_type: int constraints: - type: not_null - name: order_type data_type
Because of this narrow scope, dbt contracts are best understood as schema contracts for transformations. They protect downstream models within a dbt DAG, providing valuable local safety. But they are not designed to function as full data contracts across the data lifecycle.
dbt enforces structural correctness at build time, but it does not monitor data freshness, distribution shifts, volume anomalies, or record-level integrity once data is in production.
Executable Data Contract Formats
Although governance platforms and descriptive contract formats have significantly improved how teams define and share expectations about data, what they do not solve on their own is continuous enforcement at runtime.
In today’s ecosystem, relatively few tools address this execution layer directly. Many solutions focus on documentation, metadata, or schema definitions, but stop short of continuous validation against live data.
Execution-focused data contracts address this gap by treating contracts as active control points in the data lifecycle. At this layer, a contract is not just stored, it is executed. Violations can block deployments, stop pipelines, trigger alerts, or initiate remediation workflows.
Teams need contracts that can be:
→ validated automatically in pipelines,
→ integrated into CI/CD workflows,
→ versioned and reviewed like code,
→ and enforced consistently across systems.
This shifts data contracts from static specifications to operational safeguards that influence whether data is allowed to move forward, trigger alerts, or require remediation.
Soda Data Contracts
Soda data contracts close the execution gap by focusing on the executable core of a data contract: the quality, freshness, and structural expectations that can be continuously validated against production data.
By embedding contract verification into pipelines, data contracts function as ongoing enforcement mechanisms.
Have a look at the structure of a Soda YAML data contract:
Execution engines such as Soda Core handle the mechanics of running dataset and column-level checks against real data within data pipelines and orchestration workflows.
Soda supports contract execution across a wide range of data sources, including PostgreSQL, Snowflake, BigQuery, Databricks, DuckDB, and others. Click to see all Soda Integrations. |
|---|
The Missing Layer: Contract Enforcement
As we could see, the missing layer in most data contracts is execution. Contracts exist, but enforcement is inconsistent, fragmented, or delayed, and violations are often only discovered downstream.
Execution usually fails not because expectations are unclear, but because enforcing them at scale introduces new challenges: keeping contracts up to date, aligning business and engineering inputs, and understanding why a contract failed.
Then, the question now is not what a data contract contains, but how those contracts must be implemented and enforced in real systems.
Contracts as a Shared Interface
Because data contracts sit at the boundary between producers and consumers, collaboration is unavoidable. Execution-focused approaches recognize this and design contracts as shared operational assets.
Producers and consumers create contracts to define both sides’ expectations, and the execution engine must ensure those expectations are evaluated automatically, at scale, and across environments.
This turns contracts into a bi-directional workflow: expectations flow from the business, enforcement flows through engineering, and feedback flows back through execution results. Accountability becomes explicit because failures are tied to concrete rules and owners rather than informal assumptions.
Turning Business Intent Into Executable Rules
One of the hardest parts of contract-driven workflows is translating business expectations into enforceable checks. This translation is often manual, slow, and error-prone.
Soda Cloud is a unified platform for centralized management of data contracts, including authoring, running, and collaborating across teams.
To lower the barrier to participation without weakening enforcement, technical teams can define and validate rules as code while non-technical stakeholders can propose or review expectations using the UI. Changes are tracked, versioned, and evaluated automatically once approved.
Example Soda Cloud data contract:
On top of that, Soda supports AI-assisted contract authoring, allowing teams to express expectations in plain language and convert them into executable data quality rules that engineers can review and deploy.
One Contract to Rule Them All
Another challenge with contract adoption is fragmentation. Schema checks live in transformations. Freshness checks live in monitoring tools. Business rules live in documentation. Each system enforces a partial view of “correctness.”
Execution-focused contracts consolidate those expectations into one machine-readable specification that can be evaluated consistently across environments and platforms as the single source of truth.
This means contracts become an active infrastructure that enforces expectations for schema, data quality, freshness, and other constraints as data flows through your architecture.
Scaling Contracts Beyond the First Dataset
Defining a data contract for a single dataset is rarely the hard part. The real challenge begins when contracts need to be applied at scale. At that point, speed and standardization start to pull in opposite directions.
Soda provides a range of built-in data quality checks and predefined contract templates covering common dimensions such as schema integrity, completeness, validity, freshness, and volume, as well as more advanced validation logic.
Soda contract templates help teams get started quickly without having to create contracts from scratch, while encouraging consistency across data products by encoding reusable expectations that scale across domains.
Continuous Contract Validation
Execution-focused contracts assume that every dataset update is a release event. Each run is evaluated against the same set of guarantees—schema, quality, freshness—before the data is exposed downstream.
This model treats data contracts much like software tests: they are versioned, reviewed, and executed automatically as part of normal delivery.
In practice, this shifts contract enforcement from occasional checks to continuous validation embedded directly into pipelines and orchestration workflows. This shifts data quality issues from silent failures to actionable signals with clear ownership.
Making Contract Evolution Explicit and Safe
We must remember, though, that data contracts are not static. As data products evolve, expectations change — and unmanaged changes are a common source of breakage.
Soda treats contracts as versioned artifacts, preserving a complete history of changes, proposals, and approvals. This makes evolution explicit and reviewable, and allows teams to understand when, why, and how specifications were modified.
Diagnosing Failures, Not Just Flagging Them
Contract enforcement only creates value if failures are actionable and understandable. It’s not enough to signal that something broke; teams need to know what broke, where, and why in order to resolve it quickly.
Soda captures diagnostic context — including failed rows, check metadata, scan history, and dataset attributes — into a centralized diagnostics warehouse inside your own data warehouse. This means every contract violation is stored where your engineers already work, without moving data outside your environment.
How Different Data Contract Approaches Compare
To sum up, most implementations fall somewhere along a spectrum between policy definition and runtime execution.
Policy-oriented platforms, such as governance tools and descriptive standards, focus on declaring intent. They capture expectations around structure, ownership, and rules in a centralized, readable format. This is essential for alignment and accountability, but enforcement typically happens elsewhere.
Execution-oriented approaches focus on making those expectations enforceable. Contracts are evaluated automatically during pipeline runs, deployments, or scheduled checks. When expectations are violated, systems can fail fast, alert owners, or block propagation. Here, the contract actively shapes system behavior rather than documenting it.
Have a look at some differences below between ODCS and Soda contracts’ syntax.
We are soon going to launch a tool to translate descriptive ODCS into executable Soda data contracts. Stay tuned!
Data Contract Layers at a Glance
The table below summarizes how common approaches fit into the broader data contracts ecosystem.
These approaches are not mutually exclusive. Mature data platforms often combine governance-layer definitions, standardized specifications, and runtime enforcement mechanisms.
Dimension | Governance Platforms | ODCS | dbt Contracts | Soda Data Contracts |
|---|---|---|---|---|
Primary Layer of Operation | Governance & metadata | Specification standard | Transformation boundary | Runtime enforcement |
Primary Goal | Define ownership, policy, lifecycle | Standardize contract structure | Prevent schema drift in models | Enforce data quality & behavior across lifecycle |
Nature of the Contract | Policy & metadata artifact | Descriptive YAML specification | Declarative model constraint | Executable contract evaluated against live data |
Scope of Enforcement | Ownership, policy visibility | Schema & relationships | Schema + basic constraints | Schema, quality rules, freshness, volume, anomalies |
Compile-Time Enforcement | No | No | Yes (during dbt run) | Yes |
Continuous Runtime Validation | No | No | No | Yes |
Pre-Ingestion / In-Motion Enforcement | No | No | No | Yes |
Pipeline Blocking Capability | No | No | dbt-only scope | Across systems |
Data Quality Coverage | Descriptive only | Descriptive only | Limited (structural) | Broad (dataset, column, record-level) |
CI/CD Integration | Indirect via workflows | No | Native in dbt | Native across CI & orchestration |
Handling Breaking Changes | Documented & workflowed | Documented | Caught in model execution | Blocked before downstream propagation |
Typical User | Governance teams, data owners | Architects, standards bodies | Analytics engineers | Data engineers, data stewards |
Best Fit | Enterprise governance & accountability | Interoperability & tooling alignment | dbt-centric stacks | Production-grade, operational data platforms |
The Future of Data Contracts
As systems grow more complex and expectations around data reliability rise, teams need a way to make trust explicit without slowing down delivery. What started as a way to clarify expectations is becoming a core building block for reliable, scalable data systems.
What’s driving this shift:
➡️ Stronger governance pressure: Regulatory requirements, auditability, and data reliability expectations are increasing. Data contracts offer a structured way to define and share expectations without turning governance into a bottleneck.
➡️ Earlier validation (“shift left”): Teams are validating contracts during development and CI/CD instead of tackling breaking changes in production. This is moving failures closer to where changes happen, reducing incident impact, and aligning data workflows with DevOps and DataOps practices.
➡️ AI-assisted contract authoring: AI is lowering the barrier to defining contracts. Business and governance teams can express expectations in plain language, while tools translate those expectations into executable rules. This will reduce back-and-forth and speed up adoption.
➡️ Decentralized data architectures: Data mesh, domain ownership, and hybrid platforms require shared, machine-readable expectations. Data contracts provide a common interface that is allowing teams to evolve independently while still working within consistent enterprise-wide rules.
Taken together, these trends point to data contracts becoming the default way to manage expectations at scale, combining clarity, automation, and enforcement.
What it Means at Soda
Looking ahead, Soda’s direction for data contracts is a natural extension of treating contracts as executable control points, not just quality checks.
Today, contracts define and enforce quality and structure. The longer-term goal is to broaden their scope to cover additional controls such as access policies, retention rules, and lifecycle constraints, using the same contract-as-code approach.
Another area of focus is increasing automation in how contracts are created and maintained. With Contract Autopilot (now in private preview), Soda is experimenting with deriving contract recommendations directly from existing data. By analyzing schema, metadata, and observed data patterns, this AI-assisted contract generator can propose baseline contracts across many tables at once. These recommendations are meant to serve as a starting point, helping teams establish initial guarantees more quickly and then refine them over time as ownership and requirements become clearer.
Final Thoughts
Data contracts did not emerge because the industry suddenly fell in love with governance. They emerged because modern data platforms can no longer scale on implicit assumptions and scattered validations.
At their core, contracts are not descriptions of data. They are instructions for validation. They make expectations explicit and enforceable, defining clear compatibility boundaries for schema, volume, freshness, and validity. Instead of discovering problems at the point of consumption, pipelines can detect breaking changes at controlled checkpoints before data is published.
This shift matters. The rise of data contracts is less about adopting a new best practice and more about a change in maturity. As platforms grow more decentralized and interconnected, teams need shared guarantees that travel across systems and organizational boundaries.
Data contracts do not make data “good” by themselves. What they do is create the conditions under which quality, governance, and reliability can be enforced consistently at scale.
Schedule a talk with our team of experts or request a free account to discover how Soda integrates with your existing stack to address current challenges.
Frequently Asked Questions
Do Soda Data Contracts support ODCS (Open Data Contract)?
Partially, we support OCDS-specific fields in a Soda Contract. We see ODCS as a documentation layer and Soda as the execution layer, which requires execution specific properties. Users can start off with an OCDS contract and Soda will make it executable by translating it into the Soda Contract Language. That’s how we make specifications enforceable in your data pipelines.
Are Soda Data Contracts limited to schema enforcement?
No. Schema validation is only one part of a data contract. Soda contracts can enforce data quality rules such as completeness, validity, freshness, volume, and cross-column logic. This allows teams to encode not just structure, but what “fit for use” means in practice. See more details here on the data quality rules Soda contracts can enforce.
Do I need Soda Cloud to use data contracts?
No. Soda Core is open source and can execute data contracts independently. Soda Cloud adds centralized management, collaboration, diagnostics, and anomaly detection, but contract execution works in pipelines without it.
How are data contracts different from “just adding more tests”?
A test is part of a contract, but there’s more to it. Data contracts define system-wide guarantees that apply to datasets across ingestion, transformation, and consumption. Each dataset has its own contract, which contains not only quality test configurations but also optional attributes and custom metadata (such as owner, domain, product, team, description, etc.).
What happens when data does not meet the contract?
Contract violations are detected automatically at defined control points in the pipeline. When data fails validation, teams can trigger alerts, fail builds, block downstream propagation, or capture failed rows for investigation.
How do teams avoid different interpretations of the same contract?
Contracts work because they are machine-readable and executable. Instead of relying on human interpretation, expectations are validated directly against data. Collaborative review, examples, and version-controlled changes help align intent, but execution removes ambiguity.
Are data contracts useful outside large-scale or data mesh architectures?
Yes. Data contracts are valuable even in small or early-stage systems. They prevent implicit assumptions from accumulating and provide a clean foundation for growth. Many teams adopt contracts to avoid future refactorings.
Trusted by the world’s leading enterprises
Real stories from companies using Soda to keep their data reliable, accurate, and ready for action.
At the end of the day, we don’t want to be in there managing the checks, updating the checks, adding the checks. We just want to go and observe what’s happening, and that’s what Soda is enabling right now.

Sid Srivastava
Director of Data Governance, Quality and MLOps
Investing in data quality is key for cross-functional teams to make accurate, complete decisions with fewer risks and greater returns, using initiatives such as product thinking, data governance, and self-service platforms.

Mario Konschake
Director of Product-Data Platform
Soda has integrated seamlessly into our technology stack and given us the confidence to find, analyze, implement, and resolve data issues through a simple self-serve capability.

Sutaraj Dutta
Data Engineering Manager
Our goal was to deliver high-quality datasets in near real-time, ensuring dashboards reflect live data as it flows in. But beyond solving technical challenges, we wanted to spark a cultural shift - empowering the entire organization to make decisions grounded in accurate, timely data.

Gu Xie
Head of Data Engineering
4.4 of 5
Your data has problems.
Now they fix themselves.
Automated data quality, remediation, and management.
One platform, agents that do the work, you approve.
Trusted by








Trusted by the world’s leading enterprises
Real stories from companies using Soda to keep their data reliable, accurate, and ready for action.
At the end of the day, we don’t want to be in there managing the checks, updating the checks, adding the checks. We just want to go and observe what’s happening, and that’s what Soda is enabling right now.
Sid Srivastava
Director of Data Governance, Quality and MLOps
Investing in data quality is key for cross-functional teams to make accurate, complete decisions with fewer risks and greater returns, using initiatives such as product thinking, data governance, and self-service platforms.
Mario Konschake
Director of Product-Data Platform
Soda has integrated seamlessly into our technology stack and given us the confidence to find, analyze, implement, and resolve data issues through a simple self-serve capability.
Sutaraj Dutta
Data Engineering Manager
Our goal was to deliver high-quality datasets in near real-time, ensuring dashboards reflect live data as it flows in. But beyond solving technical challenges, we wanted to spark a cultural shift - empowering the entire organization to make decisions grounded in accurate, timely data.
Gu Xie
Head of Data Engineering
4.4 of 5
Your data has problems.
Now they fix themselves.
Automated data quality, remediation, and management.
One platform, agents that do the work, you approve.
Trusted by
Solutions
Trusted by the world’s leading enterprises
Real stories from companies using Soda to keep their data reliable, accurate, and ready for action.
At the end of the day, we don’t want to be in there managing the checks, updating the checks, adding the checks. We just want to go and observe what’s happening, and that’s what Soda is enabling right now.
Sid Srivastava
Director of Data Governance, Quality and MLOps
Investing in data quality is key for cross-functional teams to make accurate, complete decisions with fewer risks and greater returns, using initiatives such as product thinking, data governance, and self-service platforms.
Mario Konschake
Director of Product-Data Platform
Soda has integrated seamlessly into our technology stack and given us the confidence to find, analyze, implement, and resolve data issues through a simple self-serve capability.
Sutaraj Dutta
Data Engineering Manager
Our goal was to deliver high-quality datasets in near real-time, ensuring dashboards reflect live data as it flows in. But beyond solving technical challenges, we wanted to spark a cultural shift - empowering the entire organization to make decisions grounded in accurate, timely data.
Gu Xie
Head of Data Engineering
4.4 of 5
Your data has problems.
Now they fix themselves.
Automated data quality, remediation, and management.
One platform, agents that do the work, you approve.
Trusted by
Solutions