
Data cleansing is the most manually intensive activity in data management. A record fails a check. A pipeline stalls. Somewhere, a data steward opens a ticket, traces the lineage, finds the owner, and waits. The data gets fixed (or it doesn't) and the process starts again. Most organizations still run this cycle one record, one conversation, one remediation at a time.
On the other hand, data quality issue detection tools have gotten dramatically better over the past decade: ML-based anomaly detection, automated profiling, and real-time monitoring. But every alert still ends the same way. A steward exports the bad records, chases the source system owner for corrections, fixes the data in a spreadsheet, and reimports.
Organizations operationalized data issues detection but not remediation.
That's changing. Today, AI agents can now detect, diagnose, and route data quality issues without waiting for a human to open the queue. Agentic data cleansing uses specialized AI agents that detect failures, analyze the source to find what "correct" looks like and propose a targeted fix.
This doesn't replace the steward; it removes the parts that shouldn't require one: the repetitive lookups, the ownership guesswork, the manual record updates that pile up faster than any team can clear them.
The steward governs. The agent does the janitorial work.
Most guides treat data cleansing as a detection problem. Find the bad record, raise the alert, done. This guide starts where those leave off: why issue detection scaled but remediation didn't, how to assess whether your team has outgrown manual fixes, and the architecture that makes contract-driven remediation possible. If you're a data steward evaluating whether agentic cleansing belongs in your stack, this is where to start.
Key Takeaways |
|---|
|
What Is Data Cleansing (And What It Isn’t)?
Data cleansing is the process of detecting and correcting corrupt, inaccurate, incomplete, or inconsistent records in a dataset, then applying the necessary fixes at the source. It isn't the same as data transformation, data migration, or data enrichment, though it frequently overlaps with all three.
The scope of data cleansing includes deduplication, format standardization, null handling, referential integrity checks, entity resolution, and semantic drift correction. Each of these activities demands a different kind of expertise and tooling. Deduplication requires matching records that look similar but aren't identical. Format standardization requires domain-specific patterns. Entity resolution requires contextual understanding of what "the same thing" means across systems. The scope is broad, and that breadth is part of why data cleansing is so labor-intensive.
What data cleansing is not: it isn't ETL transformation, which restructures data for a target schema. It isn't data enrichment, which adds new fields from external sources. It isn't data migration, which moves data between systems. These activities are related but distinct. Conflating them leads to tooling decisions that solve the wrong problem.
The Remediation Gap
The data cleansing paradigm has been the same for decades: detect a problem, export the bad records, fix them manually or in a script, reimport. The tools changed. The workflow didn't.
The detection side leaped forward. ML-based anomaly detection, automated profiling, real-time monitoring, and data observability platforms all reached maturity. Teams can now detect issues at scale, across hundreds of datasets, in minutes.
The remediation side stayed manual. When the detection tool finishes its work, a human still has to fix the record. Stewards export to spreadsheets. Engineers write one-off SQL scripts. The fix goes back into the pipeline with no audit trail, no feedback loop, no learning.
Rule-based tools automated parts of detection and some correction. Address standardization, phone number formatting, and basic deduplication. But these tools require months of configuration and maintenance. They handle known, repeatable patterns. Novel failure types still require manual intervention.
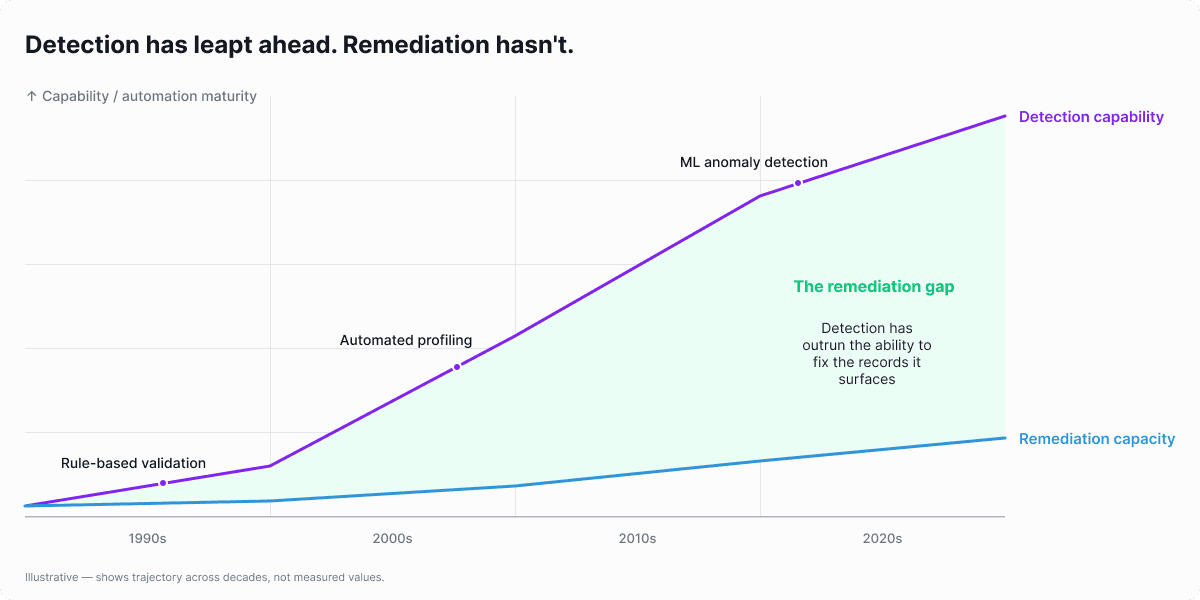
In short, automated detection tools added volume to the data cleansing backlog by finding more issues. But without proportional remediation capacity, the backlog of known data issues that haven't been fixed grew faster than stewards could work on, generating a remediation debt.
The organizational consequence is clear: stewards were hired to govern data, but they spend their time as human ETL, fixing records one by one.
Why did this persist? Data remediation requires understanding context: what "correct" looks like for this dataset, this business rule, this domain. Context is hard to encode in static rules. That's the technical barrier that kept remediation mostly manual until now.
Three Generations of Data Cleansing
Data cleansing has evolved through three distinct generations, each defined by how corrections are identified and applied. Most organizations are still operating in Gen 1 or early Gen 2.
Gen 1: Manual Cleansing (SQL Scripts, Spreadsheets, ETL Logic)
The original approach. The majority of data teams still operate here.
Export bad records, fix in Excel or a SQL script, reimport.
It's human-driven, one-off, produces no learning, and leaves no audit trail.
It works for small datasets, ad-hoc corrections, and one-time migrations.
It breaks at scale, with recurring issues, and under compliance requirements.
Gen 2: Rule-Based Automation (Enterprise DQ Platforms)
Predefined rules automate detection and some correction.
Powerful but slow to configure, requiring DQ specialists, static rules that don't adapt.
Strengths: handles known, repeatable patterns at scale, like address standardization and phone format normalization.
Limitations: months of deployment, enterprise pricing, rules that don't learn from feedback, and no context awareness.
Gen 2 tools detect well but remediate narrowly. Novel failure types still require manual intervention.
Gen 3: Agentic Cleansing (AI Agents + Data Contracts)
Specialized AI agents that understand context, learn from feedback, and fix at source.
Contract-driven: a data contract defines what "correct" looks like. When a record violates a contract, a specialized agent analyzes the failure and generates a targeted fix.
Human-in-the-loop: stewards approve, reject, or modify every suggested fix. No black-box remediation.
The unlock: agents need a specification of "correct." That specification is the data contract. Without it, agents guess. With it, they have a target. One specification, two jobs: validation and remediation from the same artifact.
Most organizations won't skip Gen 2. But the gap between Gen 2 and Gen 3 is closing faster than the gap between Gen 1 and Gen 2 ever did.
What Makes Agentic Cleansing Different?
Agentic data cleansing is not a faster version of rule-based cleaning. It is architecturally different:
Specialized agents per failure type
Entity normalization, address formatting, semantic drift, deduplication. Each failure type gets a purpose-built agent, not a general-purpose LLM. A deduplication agent understands fuzzy matching and merge logic. A format standardization agent understands domain-specific patterns. Specialization produces better fixes than a single model trying to do everything.
Governed approval with a complete audit trail
Stewards approve, reject, or modify every proposed fix. Every decision is recorded: timestamp, contract rule that triggered the failure, proposed fix, approver, outcome. When an auditor asks "who changed this record and why?", the answer is in the trail. This is what separates agentic cleansing from a prototype built on a general-purpose LLM — governance is structural, not bolted on.
A learning system
Every steward decision trains the model. A rejection teaches the agent where its understanding of the contract falls short. An approval reinforces the pattern. Over time, fix confidence scores increase and the volume of records requiring manual review decreases. Organizations that invest early see compounding returns: every decision makes the next one better.
How Soda Cleanse Implements It
Soda built agentic data cleansing on top of the same platform that powers validation and observability. Every failed record is automatically linked to the contract rule it violated, the anomaly that flagged it, and its history across scans. Agents don't work from the contract alone. They trace issues to their root cause with full context: what the rule expects, how the data has behaved before, and what changed.
Contract-native remediation
Fix strategies live inside the same data contract as the check that catches the problem. The rule and the remedy are declared together, version-controlled together, deployed together. Detection and remediation never drift apart because they share the same artifact.
The right tool for each fix
Each check declares its own remediation strategy. A constant default when one will do. A SQL lookup when the answer lives in a reference table. AI when the correction needs context or reasoning. Deduplication uses deterministic fuzzy matching and weighted merge logic, no AI involved. The contract author picks the cheapest, most predictable tool per check, and AI only steps in where it's actually needed.
Write-back on your terms
Approved fixes can write directly to the source table through an audited path, route to a managed fixes table for downstream workflows, or stay in Cleanse as a record of intent. No team has to grant write access on day one. For regulated environments, that flexibility is the difference between a pilot that gets approved and one that stalls in security review.
Steward feedback deepens how the contract is applied
Approvals and rejections teach the system what the contract means in practice. Edge cases that the contract text alone doesn't cover get resolved through human judgment, and that judgment feeds back into the model.
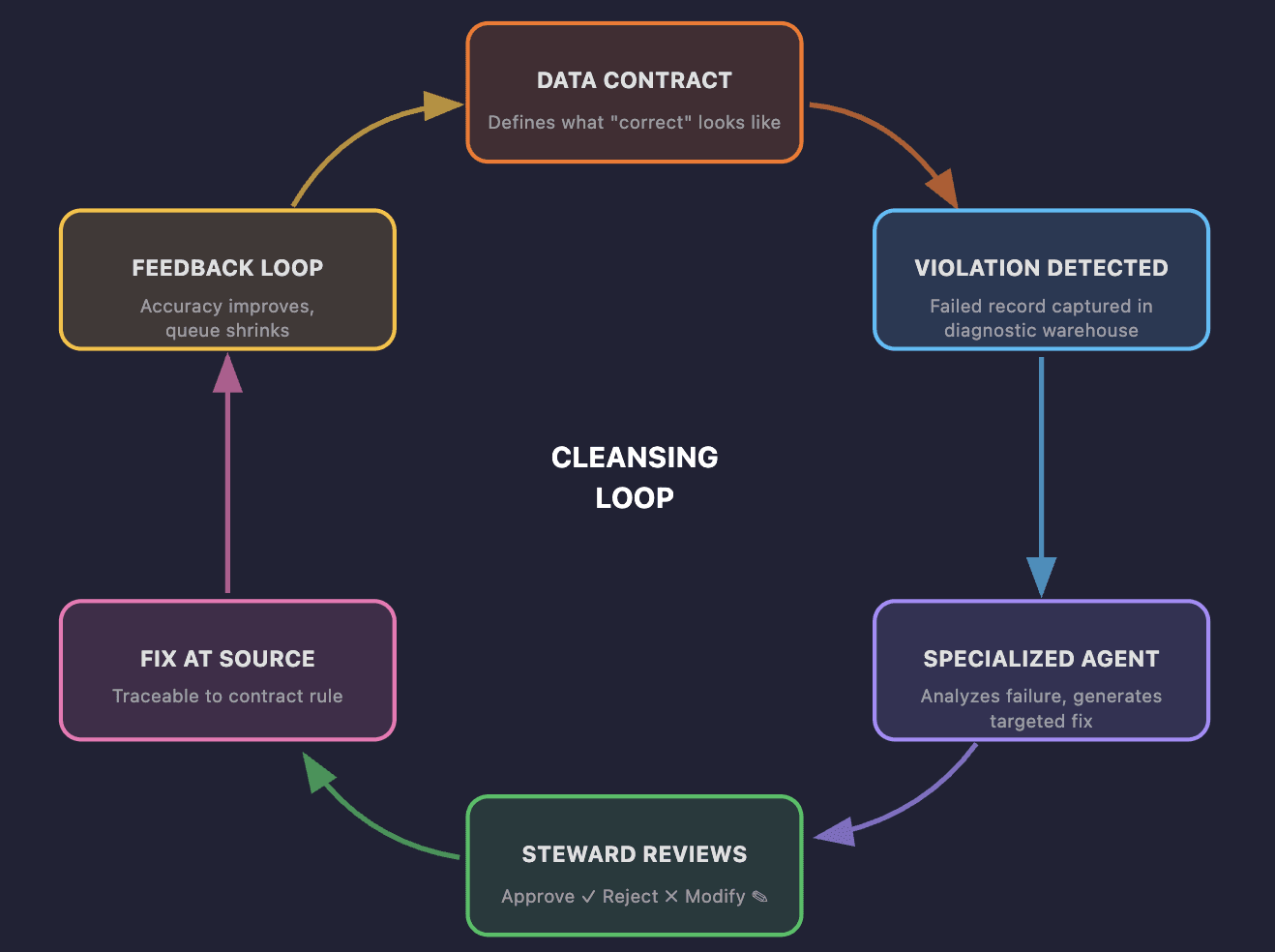
The Cleansing Loop
The full cycle works like this:
A data contract defines the schema, value constraints, and business rules for a dataset
When a record violates a contract, the failure type and contract context are passed to a specialized agent
The contract's declared strategy generates a fix: a constant, a SQL lookup, or an AI-proposed correction, depending on what the problem requires
The steward reviews
The fix is applied at the source
The steward's decision feeds back into the model
The loop is continuous. Every steward interaction improves the next cycle.
Ready to evaluate? Book a demo to see how Soda Cleanse makes data stewards day-to-day much easier.
How Does the Data Cleansing Market Look in 2026?
The data quality tools market reached $3.27 billion in 2026 and is forecast to reach $7.39 billion by 2031, growing at 17.7% per year (Mordor Intelligence, 2025). Within that market, three distinct approaches to data cleansing tools compete for adoption, each with different strengths and gaps.
Observability-First Tools (Detect, Don't Fix)
Strength: excellent at detection, anomaly investigation, root cause analysis. Modern observability platforms surface issues across hundreds of datasets in real time.
The gap: when the investigation ends, a human still fixes the record. They tell you what broke. They don't fix it.
Enterprise Platforms (Fix, but Slowly)
Strength: deep cleansing capabilities, analyst recognition, mature feature sets.
The gap: months of deployment, enterprise pricing, rule-based, not learning, and a separate rule engine from detection. Same remediation outcome. Months to deploy. Enterprise pricing.
Agentic Cleansing (Detect + Fix + Learn)
The emerging category. AI agents detect failures, generate fixes, and learn from steward feedback.
The differentiator: contract-driven specification, not a separate rule engine. Continuous improvement. Governed and traceable. Detection to resolution in one platform.
Dimension | Manual Scripts | Observability Tools | Enterprise Platforms | Agentic Cleansing |
|---|---|---|---|---|
Detection depth | Low | High | High | High |
Remediation capability | Manual | None | Rule-based | Agent-driven |
Time to value | Immediate | Days | Months | Days to weeks |
Learning / improvement | None | None | None | Continuous |
Governance / traceability | None | Partial | Partial | Complete |
40% of enterprise applications will feature task-specific AI agents by end of 2026, up from less than 5% in 2025 (Gartner, 2025). Data cleansing is one of the first domains where agentic approaches deliver measurable value, because they can quickly trace issues to their root cause with full context from data contracts, anomalies, and historical runs.
Does Your Team Need Agentic Cleansing?
Not every team needs agentic cleansing. But if your stewards spend more than 10 hours per week on manual record corrections, your remediation backlog grows faster than your team can work it. If the same failure types recur across datasets, you've outgrown manual and rule-based approaches.
Here are five signals that indicate your team has outgrown manual remediation:
Signal 1: Steward time on manual fixes
If data stewards spend more than 50% of their time correcting records rather than defining standards, remediation has become the bottleneck. They were hired to govern, but they're working as human ETL.
Signal 2: Growing remediation backlog
If the number of known-but-unfixed data issues increases month over month, your capacity doesn't match detection output. You're adding to the problem faster than you're solving it.
Signal 3: Recurring failure types
If the same kinds of errors, format mismatches, entity duplicates, and null patterns appear across datasets, a learning system will outperform one-off scripts. Scripts don't learn. Agents do.
Signal 4: Compliance pressure
If auditors ask "who changed this record and why?" and you can't answer with confidence, you need traceable, governed remediation with a complete audit trail.
Signal 5: Script sprawl
If engineers maintain a growing library of one-off SQL fix scripts with no reuse, no feedback loop, and no documentation, the maintenance burden will eventually exceed the remediation benefit.
Self-Assessment
How many times have you said yes to the conditions above? Score yourself:
0-1 yes: Manual or rule-based cleansing is sufficient for now.
2-3 yes: Evaluate agentic cleansing. Start with a pilot on your highest-volume failure type.
4-5 yes: Agentic cleansing should be a priority initiative.
Getting Started with Agentic Data Cleansing
Start with one dataset and one failure type. You don't need to cleanse everything at once. Here are the core data cleansing process steps for teams adopting an agentic approach.
Step 1: Identify your highest-volume recurring failure type
Start by scanning your monitoring dashboards for the failure types that appear most frequently across datasets. Duplicates, format mismatches, and null patterns are the most common candidates.
Duplicates make the best pilot because the success metric is unambiguous: record count drops, and downstream consumers notice immediately. Format mismatches are a strong second choice because the fix is deterministic — a phone number either matches the pattern or it doesn't. Null patterns are trickier because the "correct" value often requires business context that only a domain expert can provide, which makes them a better candidate for a second phase when the steward feedback loop is already running.
Pick one. Resist the temptation to cleanse three datasets in parallel during a pilot. A single failure type on a single dataset gives your team a clean signal on whether the approach works.
Step 2: Define a data contract for that dataset
The contract specifies what "correct" looks like: schema, value constraints, freshness requirements, and business rules. It scopes the agent's work and makes every fix auditable from day one.
If you're new to contracts, start minimal. Schema validation and null checks are enough to activate agentic cleansing and begin generating feedback. A contract that covers three rules you enforce consistently is more valuable than one that covers thirty rules nobody reviews. Explore contract templates for ready-to-use starting points, or review the Soda documentation for a step-by-step setup guide.
Step 3: Deploy an agentic cleansing tool on that contract
Connect the contract to an agentic cleansing tool and review the first round of proposed fixes with your steward team. The feedback you provide in week one shapes the accuracy you get in week four. Every approval teaches the agent what "correct" looks like in practice. Every rejection sharpens where its understanding falls short.
What to avoid in a pilot
Three patterns stall early adoption.
First, skipping steward review to "move faster". This starves the feedback loop and the agent never improves beyond its baseline.
Second, writing overly complex contracts before the system has learned from simple ones. Start with rules your team already enforces manually, not aspirational rules nobody checks today.
Third, measuring success too early. The compounding effect of steward feedback needs time to show meaningful accuracy gains. Give the pilot enough cycles for the learning loop to kick in before you judge it.
Prove value on one contract, one dataset, one failure type. Then expand.
What Comes Next: Continuous, Governed Cleansing
Data cleansing is shifting from a manual, project-based activity to a continuous, contract-governed, agent-driven process. The remediation gap, where detection scaled but fixing didn't, is closing.
The direction is clear. Cleansing runs continuously. It's embedded in the pipeline, triggered at ingest and transformation rather than applied after the fact. Contract checks trigger agent remediation in real time, not in batch.
The data contract is the single source of truth. As business rules change, the contract updates. Cleansing agents adapt automatically. There's no separate "remediation configuration" to maintain. Every change to the contract cascades to the agents that enforce it.
Accuracy compounds over time through feedback loops. Stewards shift from fixing to governing.
Book a demo to see how Soda Cleanse turns your data contracts into governed, continuously improving remediation.
Frequently Asked Questions
What is the difference between data cleansing and data cleaning?
The terms are often used interchangeably. In practice, "data cleaning" typically refers to fixing individual errors, a tactical activity. "Data cleansing" implies a broader scope including enrichment, governance, and root-cause prevention.
What is agentic data cleansing?
Agentic data cleansing uses specialized AI agents to detect failed records, generate targeted fixes, and apply them at source, with human steward approval at every step. Unlike rule-based tools, agents learn from steward feedback and improve over time.
How do data contracts relate to data cleansing?
A data contract defines what "correct" looks like for a dataset. When a record violates a contract, the cleansing agent uses the contract as its specification for generating a fix. One artifact powers both validation and remediation. Organizations already using contracts can activate agentic cleansing immediately.
Can AI fully automate data cleansing?
Not without governance. Agentic cleansing keeps humans in the loop: stewards approve, reject, or modify every proposed fix. The AI handles the repetitive work. Stewards govern the outcome.











