
Data engineering is the work of designing and maintaining systems. These systems move data from its source into a trusted, usable state.
That includes ingestion, transformation, validation, storage, and delivery into tools like dashboards, machine learning models, and applications. However, that definition doesn’t fully hold up anymore.
Most modern organizations don’t struggle with a lack of data. They struggle with making data reliable enough to act on.
Every interaction inside a digital system generates data. A user taps a button, a transaction goes through, a sensor sends a measurement, an API request finishes. In isolation, none of this is useful. But collectively, it forms the raw material of decision-making.
The problem is that raw data is not stable. Raw data is incomplete, delayed, duplicated, inconsistent, and constantly changing. Without structure, it quickly becomes just noise. This is where data engineering begins.
In modern organizations, data engineering is no longer just about pipelines. It is about building data systems that behave predictably under change. It is about ensuring that when something upstream breaks, the downstream impact is clear, limited, and recoverable.
Teams are no longer asking only “How do we move data?” They are asking:
“How do we ensure data is correct, fresh, and usable at every stage of its lifecycle?”
Answering that means looking at the role of the data engineer, the skills the job demands, the systems they build, and the architecture of the platforms that hold it all together.
Key Takeaways |
|---|
|
The Role of a Data Engineer
A data engineer is responsible for building the infrastructure that allows data to move reliably through an organization. In practice, this means designing systems that extract data from multiple sources, transform it into meaningful structures, and make it available for analysis or operational use.
But reducing the role to “pipeline building” misses the broader responsibility. A data engineer is ultimately accountable for data reliability as a system property.
That includes ensuring that data is not just present, but correct. Not just correct once, but consistently correct as upstream systems evolve. Not just available, but timely enough to support decisions.
In many organizations, data engineers sit between software engineering and analytics teams. They translate raw operational data into structured datasets that analysts and data scientists can rely on. This requires both technical depth and systems thinking.
A typical day of a data engineer might involve:
debugging a failing ingestion job,
optimizing a transformation query that is too slow at scale,
collaborating with analysts to refine a dataset definition, or
implementing data quality checks to prevent future issues.
What makes the role distinct is that data engineers operate on systems where failure is often silent. A pipeline may succeed while silently producing incorrect outputs. A schema may change without breaking ingestion. A dataset may update late without triggering an alert.
The data engineer’s responsibility extends beyond building systems that work. It extends to building systems that fail in visible and manageable ways.
Teams and Collaboration Models
Building systems that fail visibly isn't only a technical problem. It also depends on how data engineers are organized within the team, because ownership and accountability flow from team structure.
Data engineering does not operate in isolation. It is part of a broader ecosystem that includes analytics engineers, data analysts, and data scientists.
In centralized models, a single data team supports the entire organization. This allows for consistency but can become a bottleneck as the organization scales.
In embedded models, data engineers sit directly within product or domain teams. This improves alignment but can lead to fragmentation in tooling and standards.
Many mature organizations adopt a hybrid model, where a central platform team provides infrastructure and standards, while embedded engineers focus on domain-specific data needs.
Adjacent Roles in the Data Team
Within those structures, data engineers work alongside several adjacent roles, and understanding where each one ends is what prevents overlap, friction, and unowned data.
Data engineers focus on building and maintaining systems that move and structure data.
Data analysts focus on interpreting the data to generate insights.
Analytics engineers sit somewhere in between, often owning transformation logic and modeling within the warehouse.
Regardless of structure, ownership remains a critical factor. Without clear accountability for datasets and pipelines, systems tend to degrade over time.
Core Skills of a Data Engineer
While the team structure and tool set vary across organizations, the foundational skillset of a data engineer remains relatively consistent.
Strong SQL capability sits at the center of this skillset. SQL is not just a querying language; it is the primary interface through which most data transformation logic is expressed. Whether working in a warehouse or a lakehouse architecture, SQL remains the dominant language for shaping data. dbt has become the de facto framework for managing SQL-based transformations in modern stacks, adding version control, testing, documentation, and dependency management on top of SQL.
Alongside that, most data engineers rely heavily on Python or a similar general-purpose language. Python is typically used for orchestration logic, automation, and integrating systems that do not naturally communicate through SQL alone.
However, technical syntax alone is not enough. A strong data engineer understands how data should be modeled. This includes:
knowing when to normalize data for integrity versus when to denormalize it for performance in analytical systems
understanding dimensional modeling patterns, such as fact and dimension tables, and how these models influence downstream usability
Beyond modeling, distributed systems thinking becomes essential as data volumes grow. Modern data pipelines rarely run on a single machine. They are distributed across clusters, cloud services, and managed platforms. This introduces complexity around parallel processing, failure recovery, and resource allocation.
Cloud infrastructure knowledge is equally important. Most modern data systems operate within AWS, GCP, or Azure. Understanding storage systems, compute engines, and cost structures allows engineers to make informed trade-offs between performance and efficiency. Cost awareness is part of the job: a non-partitioned query that scans terabytes of data in Snowflake or BigQuery shows up on the monthly bill quickly, and engineers are expected to design with that in mind.
But, perhaps the most underappreciated skill in data engineering is not purely technical. It is the ability to reason about data quality. A pipeline that runs successfully is not necessarily a pipeline that produces trustworthy results. Engineers must be able to define what “correct data” means, detect when it deviates, and design systems that surface those deviations before they reach downstream consumers.
Finally, communication is a core part of the role. Data engineers constantly collaborate across teams, translating between business requirements and technical implementation. Without clarity in communication, even well-designed systems fail in practice because their purpose is misunderstood.
Want a take on what data engineering maturity looks like? Read our CTO Tom Baeyens’s article on The Four Levels of a Data Engineer.
The Modern Data Engineering Stack
A modern data stack is a set of cloud-based tools used to collect, store, transform, and analyze data, typically including data warehouses, ETL/ELT tools, orchestration platforms, and BI tools. It is best understood as a layered system.
Data ingestion is the entry point. Raw data enters the system from files, databases, applications, and event streams. The challenge here is not just connectivity but consistency: multiple sources emit data at different frequencies, formats, and reliability levels.
Storage sits next. In modern architectures, this is often a cloud data warehouse (Snowflake, BigQuery, Redshift) or a lakehouse (Databricks). The warehouse offers structured, query-optimized storage; the lakehouse adds flexibility for raw or semi-structured data and supports transformations directly on the lake.
Transformation is where raw data is cleaned, joined, aggregated, and reshaped into models that reflect business logic. A common organizing pattern is the medallion architecture: a Bronze layer for raw ingestion and history, Silver for filtered and cleaned data, and Gold for business-level aggregates ready for consumption.
Consumption is where the value is realized: dashboards, reports, machine learning models, and product features that rely on data to function.
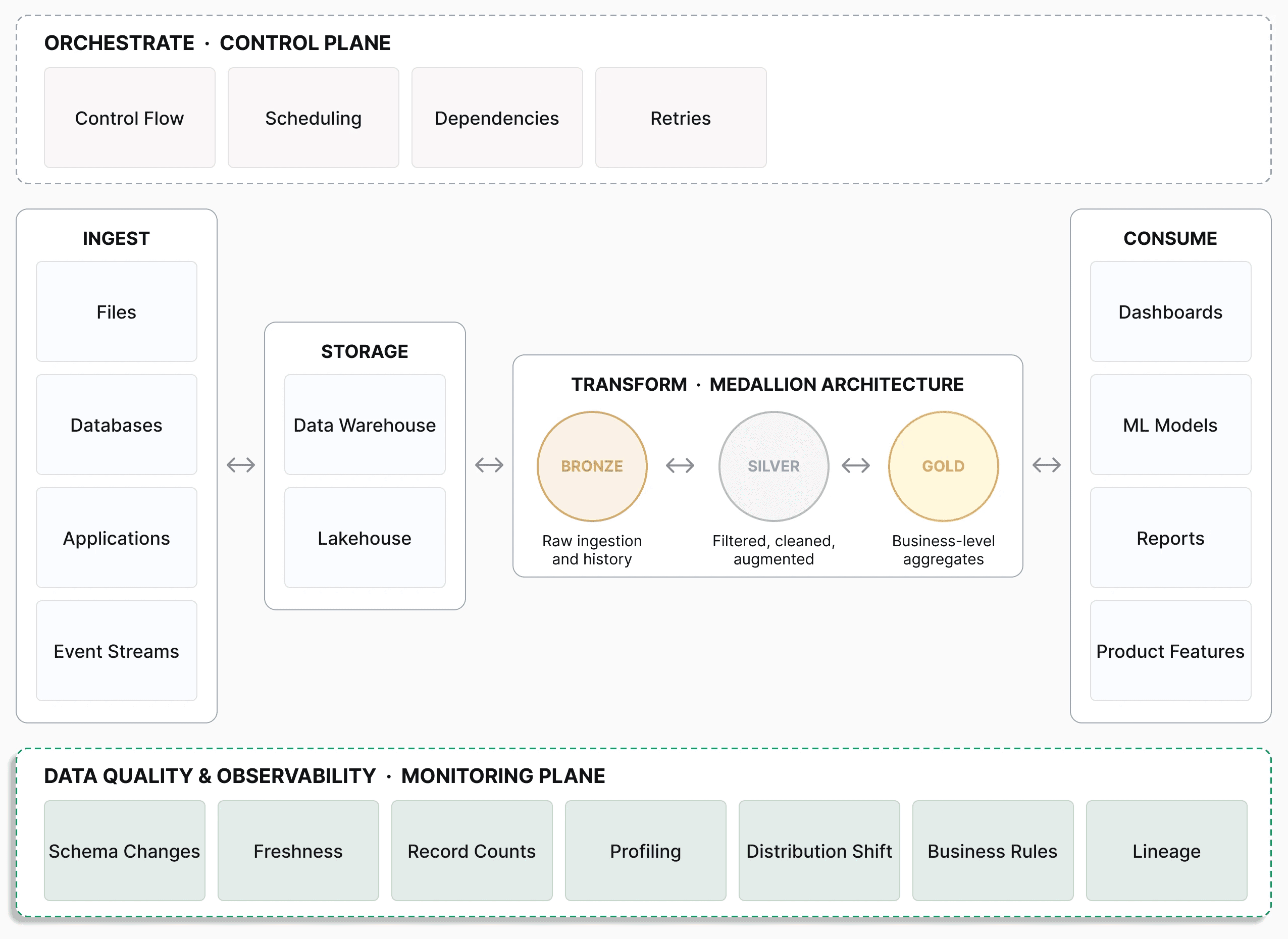
Two cross-cutting planes sit alongside this data flow.
Orchestration is the control plane. It coordinates how the layers run together, handling scheduling, dependencies, retries, and control flow. Without orchestration, even simple pipelines become difficult to manage at scale.
Data quality and observability is the monitoring plane. It doesn't move data; it watches it. It monitors schema changes, checks freshness, tracks anomalies, ensures business rules, tracks lineage. This is where systems like Soda fit in.
Each piece depends on the others. A failure in ingestion propagates into transformation. A mistake in transformation affects analytics. A lack of observability allows issues to persist undetected.
This interdependence is what makes data engineering fundamentally a systems discipline rather than a collection of tools.
Systems Thinking in Data Engineering
One of the most important mental shifts in data engineering is moving from thinking in pipelines to thinking in systems.
A pipeline is a linear process: data enters, is transformed, and exits.
A system is a network of interdependent pipelines, each with its own constraints, failure modes, and downstream effects.
In a system, a small change in one place can have disproportionate effects elsewhere. A renamed column in a source database might break multiple dashboards. If a data ingestion job is delayed, it can cause outdated metrics across the organization.
Understanding these relationships is essential because most data failures are not isolated, they are systemic.
This is why trade-offs become central to data engineering decisions. Increasing data freshness often increases cost. Improving accuracy can slow things down. Simplifying a pipeline may reduce flexibility.
Common Trade-Offs
Within this layered system, two long-standing trade-offs shape how data teams build transformations and processing.
ETL and ELT represent common paradigms of data processing. ETL transforms data before loading it into storage, while ELT loads raw data first and performs transformations inside the warehouse.
The transformation layer has been increasingly happening inside the warehouse itself using ELT patterns rather than traditional ETL, with dbt as the de facto framework for managing these transformations as code.
Batch and streaming systems also represent a fundamental trade-off between simplicity and speed. Batch processing is easier to manage but introduces latency. Streaming systems reduce latency but increase complexity significantly.
Each of these trade-offs has cost, performance, and operational implications that ripple across the rest of the system.
There is rarely a perfect solution. Instead, engineers must make those trade-offs explicit and design systems that behave predictably under their constraints.
Common Challenges in Data Engineering
Whatever trade-offs a team makes, certain failure modes show up again and again. Even well-designed systems encounter recurring challenges.
Silent failures are among the most dangerous, where pipelines succeed but produce incorrect outputs without triggering errors.
Schema drift introduces similar risks when upstream systems change unexpectedly.
Another challenge is the lack of observability. Without visibility into data behavior, teams often discover issues only after they impact dashboards or users.
Tool sprawl can also create fragmentation, where multiple overlapping systems exist without clear ownership or integration.
Unowned datasets tend to degrade over time, as no one is responsible for maintaining their quality or relevance.
The common thread tying these challenges together is the absence of data quality discipline. Data contracts catch schema drift before it propagates. Data observability surfaces silent failures and ownership gaps. Together, they convert reactive firefighting into a system property: reliable data, built into the pipeline rather than checked after the fact.
Best Practices in Data Engineering
Avoiding those failure modes comes down to a small set of consistent practices; less about specific tools and more about how systems are designed and maintained.
☑️ One of the most important principles is treating data as a product. Each dataset should have clear ownership, a defined purpose, and documented behavior. Without this, datasets accumulate ambiguity over time, making them harder to trust and harder to use.
☑️ Another foundational practice is version control. Data pipelines, transformation logic, and data contracts should all live in versioned repositories. This ensures that changes are traceable and reversible, and that schema evolution is intentional rather than accidental.
☑️ Automation is equally critical. Data validation should not depend on manual inspection. Instead, it should be integrated directly into CI/CD pipelines so that issues are detected as part of the development process, not after deployment.
☑️ Test the transformations themselves, not just the output data. A pipeline that produces clean data today won't necessarily produce clean data after the next refactor. Frameworks like dbt tests (or Python-based data testing libraries) let engineers assert expectations about transformation logic, including unique keys, expected row counts, and valid value ranges, and catch regressions before they reach production.
☑️ A related principle is shifting quality checks left in the pipeline. The earlier an issue is detected, the cheaper it is to fix. Catching a schema mismatch in a pull request is significantly easier than discovering it in production dashboards.
☑️ Finally, systems should be designed with failure in mind. This includes mechanisms such as quarantining bad data, retrying failed jobs, and alerting clearly when something deviates from expected behavior.
The Future of Data Engineering
These practices aren't static. Data engineering is evolving toward greater automation, observability, and governance — and the gap between teams that adopt them and teams that don't is widening.
As data becomes more central to decision-making, the cost of unreliable data increases. This makes system design, observability, and data quality not optional enhancements, but foundational requirements.
Data contracts are becoming more common as a way to formally define expectations between data producers and consumers.
Observability is shifting from optional monitoring to a core system requirement.
Real-time data processing is expanding in operational use cases like fraud detection and recommendation systems, though analytics workloads remain predominantly batch.
At the same time, governance is increasingly being encoded directly into systems rather than documented separately. This reduces ambiguity and improves enforcement.
The most effective data teams do not simply move data. They design systems that ensure data remains trustworthy as it flows through the organization.
That reliability does not come from complexity. It comes from consistency: consistent modeling, consistent validation, and consistent ownership.
Because in data engineering, trust is not just assumed. It is engineered.
For more on what reliable data engineering looks like in practice, see Soda's library of pieces written for data engineers, or book a demo with our team of experts.
Frequently Asked Questions
How is data engineering different from data science?
Data engineering focuses on building and maintaining the infrastructure and pipelines that make data accessible, while data science focuses on analyzing and modeling that data to generate insights.
What is the difference between a data engineer and an analytics engineer?
Data engineers build the infrastructure that moves and stores data — ingestion, pipelines, warehouses, observability. Analytics engineers work one layer up: they own transformation logic inside the warehouse, model business-ready datasets, and bridge the gap between raw data and analyst-ready data.
What skills are required for data engineering?
Key skills include SQL, Python, data modeling, distributed systems thinking, cloud infrastructure (including cost awareness), and data quality practices. In modern stacks, juniors should also learn dbt for SQL transformations, version control with Git, and how to test transformations, not just data quality.
What is data quality in data engineering?
Data quality refers to the accuracy, completeness, consistency, and reliability of data throughout its lifecycle, ensuring it is fit for use in analytics and decision-making.
Why is data observability important?
Data observability ensures that teams can detect issues in pipelines, monitor freshness and quality, and maintain trust in data systems used for decision-making.
What is data modeling in data engineering?
Data modeling is the process of structuring data in a way that makes it easier to store, access, and analyze efficiently, often using schemas and relationships between datasets. The most common pattern in analytics is dimensional modeling, with fact tables (events and metrics) connected to dimension tables (descriptive context like customers, products, or time).
What are common tools used in data engineering?
Common tools include cloud platforms like AWS, GCP, and Azure; data warehouses like Snowflake, BigQuery, or Redshift; lakehouse platforms like Databricks; transformation frameworks like dbt; orchestration tools like Airflow or Dagster; and processing engines like Spark for large-scale workloads.











