AI for Data Quality: The Complete Guide for Data Teams
AI for Data Quality: The Complete Guide for Data Teams
AI for Data Quality: The Complete Guide for Data Teams

Fabiana Ferraz
Fabiana Ferraz
Technical Writer at Soda
Technical Writer at Soda
Table of Contents
AI for data quality shifts data management from manual rule-writing to automated systems that keep datasets accurate, complete, and fit for purpose.
For quite some time, AI has been helping write and review code across software engineering, but data quality is only catching up. To be fair, writing data tests requires heavy business context (e.g., "Is this $0 order a test record, a cancelled sale, or a broken integration?"), which made early AI and automation harder to apply compared to standard software logic.
But two things have been changing to make AI adoption for data quality management more imperative. First is scale: far more people touch data than ever, and far more of it moves through your pipelines every day. Second is a new kind of consumer: AI agents are now consuming your software and data too. Unlike a person, an agent won't pause at a value that looks off, so the quality of that data sets the ceiling on what it can safely do.
This guide breaks down the shift from manual data-quality checks to intelligent, automated systems. In this blog, we’ll cover:
Why data quality management needs to change.
What "AI for data quality" actually means.
The foundation needed to make AI-driven quality reliable and automated.
How modern data teams are using AI for data quality today.
By the end, you'll have a short self-check to see if your data is ready for AI, and a path to start without rebuilding everything.
Key Takeaways |
|---|
|
Why can't data quality stay manual?
Data quality can't stay manual because both sides of the equation outgrew hand-written checks: the way data is produced and the way it is consumed.
For a long time, data quality was a purely manual, highly reactive process. Data engineers and analysts would literally open documentation (if it existed), look at a new table, and manually write SQL assertions or configure rules one table at a time. That held up when a few analysts read a few dashboards. It doesn't hold up now.
More people, more data
The volume of data created and consumed worldwide keeps climbing, and access to it has been democratized at the same time.
Data engineering teams increasingly manage thousands of tables due to pipeline sprawl, AI context needs, and decentralized architectures. Some industries receive millions of records that update in real-time. On top of that, analysts, business users, and brand-new roles now work with tables they'd never have touched a few years ago.
Central, manual data quality simply can't cover that surface area. We've reached the point where keeping pace by hand no longer scales. AI, using anomaly detection to learn historical patterns and automatically flag unexpected changes, is what lets teams keep up with the velocity of modern data flow.
AI as your new consumer
Until recently, the only consumers of your data were people: analysts reading dashboards, teams building forecasts. They'd catch a wrong number and chase it down. Now, AI agents and models consume that data too, and they act on it directly, without pausing at a value that looks off. Feed them something outdated, duplicated, or contradictory, and they keep running and confidently generate wrong answers.
Today, data feeds real-time machine learning models, automated marketing triggers, and customer-facing products. And reversing automated actions executed on bad data is vastly more expensive and damaging than fixing a broken dashboard.
So AI-ready data is the new bar.
Poor data quality is now one of the biggest challenges standing between enterprise AI projects and production. Gartner predicts that through 2026, organizations will abandon 60% of AI projects due to a lack of AI-ready data.
The teams pulling ahead aren't working harder; they've handed the repetitive parts of quality management to AI and kept their people on judgment. AI does the heavy lifting, eliminating ad hoc validation scripts and manual checks so that teams can spend time analyzing instead of debugging.
Data quality for AI means making your data trustworthy enough for AI to consume. AI for data quality means using AI to run data quality workflows.
What is AI-driven data quality?
AI-driven data quality means using AI to do the data-quality work itself: proposing checks, watching for anomalies, and resolving issues, rather than having engineers hand-code every rule.
How much of that work you hand to the AI is what separates its two modes.
Assistive vs agentic AI for data quality
The difference between assistive and agentic AI for data quality comes down to how tasks are run and how much supervision is needed.
With assistive AI, you direct, and AI accelerates. Think of it as your co-pilot. You still define the strategy, but the AI eliminates the manual grind of writing syntax, tuning thresholds, and hunting for needles in the haystack. Day-to-day, assistive AI for data quality shows up in a few ways. For example:
Writing the checks: Instead of hard-coding SQL assertions or YAML files table by table, you interact in plain English. You tell the AI, "Ensure this transaction column never has negative values and updates daily," and it drafts the matching check for your data contract, which you review and approve before it runs.
Monitoring at scale: You stop writing manual threshold alerts (e.g., "Alert me if rows drop by 10%"). AI-driven anomaly detection automatically learns historical patterns by scanning rows to build a baseline of what "normal" looks like. It flags the anomalies humans miss and adapts as your data evolves.
Learning with feedback loops: The AI flags an issue or drafts the code. You review it, give it feedback ("Yes, this is an anomaly" or "No, this was a planned data drop"), and the algorithm gets smarter.
With Agentic AI, you set the goal, and AI executes. Agentic data quality moves from passive suggestions to active execution. You establish the boundaries, and the agent actively works to keep your data within those lines. Some examples of how agentic AI for data quality shows up are:
Tracing root causes: While assistive AI alerts you that an anomaly occurred, an agentic workflow investigates why. If a pipeline breaks, the agent can autonomously trace the lineage to find the exact upstream schema change or bad data ingestion that caused the failure.
Drafting resolution: Instead of waiting for a data engineer to manually write a fix, the agent prepares the remediation logic. It might draft an updated check to handle a newly added column, suggest a quarantine rule for bad rows, or rewrite a broken test.
Operating on approval: The agent doesn’t push fixes to production blindly. It packages its findings and proposed code into a Pull Request or a UI prompt. The workflow is simple: the agent does the grunt work, and you approve the final action.
These are just examples. Because once you set the goal, an agent can run virtually any quality workflow you define — continuously and independently — and bring changes back for approval.
Whether you are using an assistant to translate business rules into code or an agent to trace and draft remediation steps, the goal isn't to remove human judgment; it's to remove the operational toil.
Assistive AI for data quality | Agentic AI for data quality | |
|---|---|---|
Who initiates | A person, step by step | You set a goal; the system plans |
Human role | In the driver's seat | In the loop, approving the work |
Best for | Targeted edits, explanations | Coverage and upkeep at scale |
Prerequisite | Data contracts to build on | Data contracts to act on |
Ultimately, the goal of both modes goes beyond just automating the daily grind. The bigger difference is where the safety check sits: with assistive AI, a person signs off on every change; in an agentic workflow, the data itself becomes the checkpoint, because the agent has to check its work against your definition of "good" before it acts.
That's what raises the bar for trust. And the durable value of both modes is the same: quality that both people and agents can act on with confidence.
Why data contracts make AI-driven data quality reliable
AI doesn't create quality; it scales whatever you already have. Point it at clear, well-defined data, and it's a force multiplier. Point it at a mess, and it produces confident, wrong answers faster.
So, if you want AI to automate your data quality, you have to give it a foundation in a language it understands: encoded and executable specs. This foundation is the data contract, and it's where most teams currently have a massive gap.
What a data contract actually is
A data contract is a version-controlled, executable spec of what a dataset must look like. It captures business expectations, ownership, and strict quality thresholds.
This embedded context is exactly what tells an agent when a dataset is trustworthy and when it needs to hold off and flag a human. Think of it as the .md file your data exposes to AI.
Without a contract, an AI agent is forced to fill the gaps and guess your business logic. Data contracts eliminate this risk. They keep data teams entirely in control of defining expectations, while the AI does the heavy work of enforcing them at scale.
That is the core architectural bet of modern data quality: one definition of "good" that serves humans and AI alike. The exact same contract that tells an analyst the data is safe to consume is the one an AI agent reads to decide whether to execute a task.
To understand the foundations of data contracts, read our definitive guide to data contracts.
Now, if data contracts are so useful, why doesn't every company already use them?
Because historically, writing a contract meant starting from a blank page. Expecting data engineers to manually write YAML files, define schemas, and hard-code quality thresholds for thousands of tables brings us right back to the manual bottleneck we started with.
This is where Soda AI comes in.
How teams use AI to get AI-ready data
The good news is that no one needs to start from a blank page anymore. And it isn't only engineers who contribute; the business people who know the data best can put their own context into a contract, in plain language, no ticket required.
Teams get reliable data for dashboards, ML models, and agents to consume by making quality machine-readable, then scaling it.
Soda AI to author and scale data contracts
Soda AI has a set of functionalities, allowing teams to generate data contracts from real data, refine them, and open them to agents. You reach much of it through a chat interface in Soda Cloud, in plain language, though you can also kick off Autopilot straight from your datasets. Either way, every action it proposes is shown and approved by a person before it runs.
Here is how the authoring process actually works in practice:
Chat interface
The conversational entry point to Soda AI. Ask what a check, monitor, or incident means, or tell it to make a change, and it reaches for the functionalities below (Autopilot, Copilot, and the agent-facing interfaces) to carry it out.

Contract Autopilot
The batch path from zero to coverage. Point Autopilot at your datasets and it generates fully populated data contracts, complete with recommended checks drawn from your data's own profile, so a team starting from nothing reaches real coverage in an afternoon instead of a multi-quarter program.
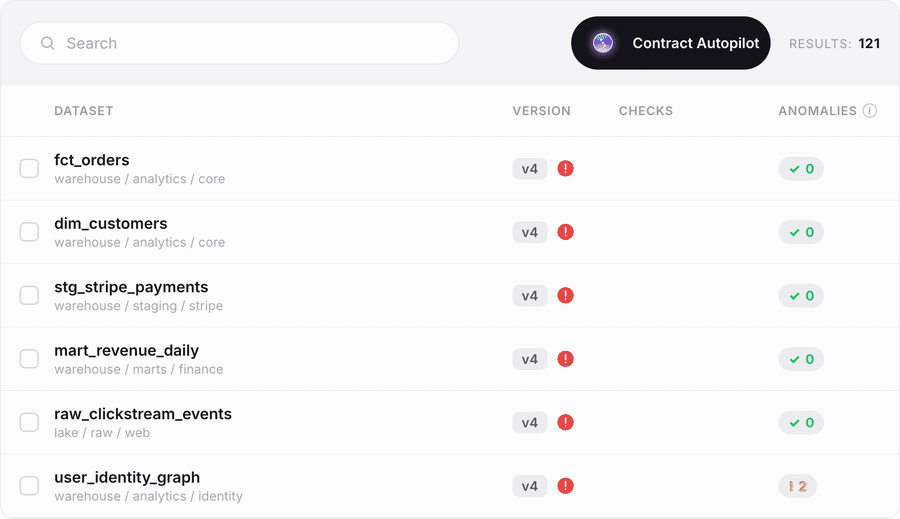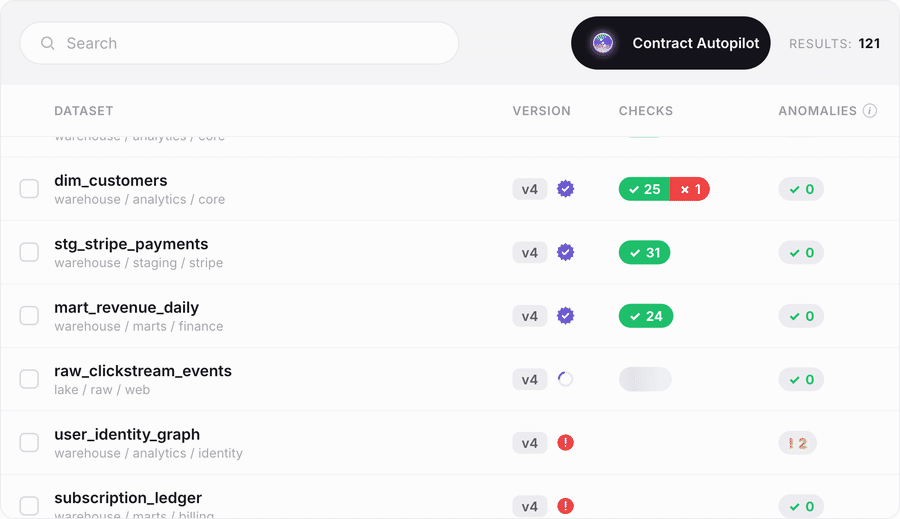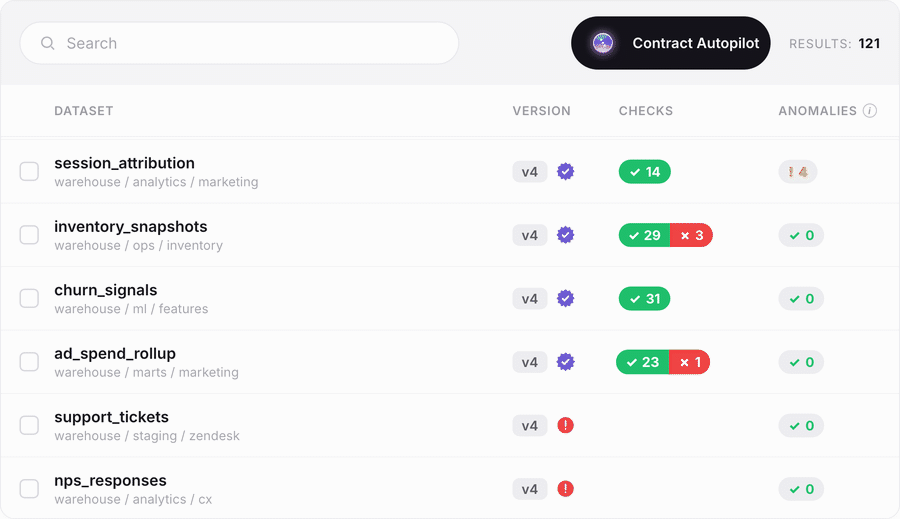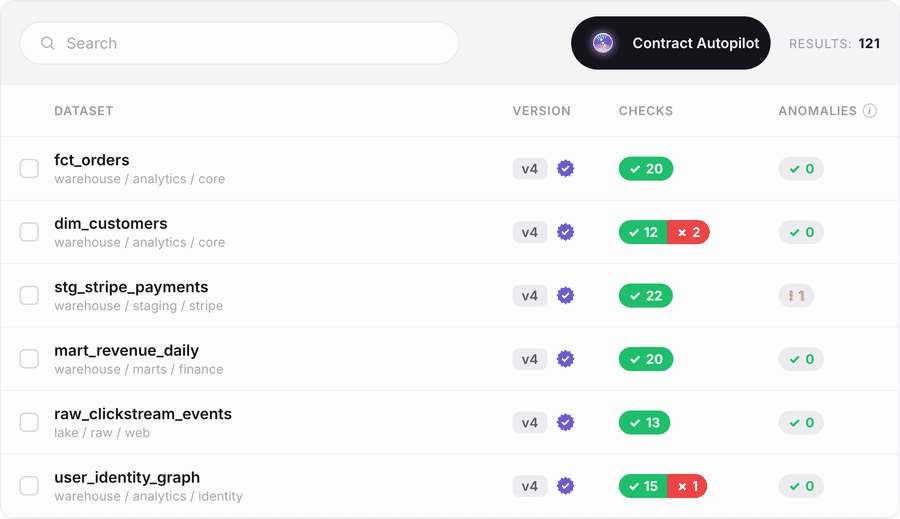
Contract Copilot
The plain-language way to refine a single contract, with you in the driver's seat. Ask Copilot to add a freshness check, tighten a rule, or handle a nested field. It updates the contract from schema and metadata (never your raw rows) and shows you exactly what changed.
Agent-facing interfaces: MCP, CLI, and API
Where your agents and pipelines reach trusted data. MCP, the CLI, and the API put your contracts and data-quality status in front of the tools your team and your agents already use: Soda MCP connects your own agents to trusted data, the CLI runs data quality checks programmatically inside your existing pipelines, and the API integrates Soda with your own systems.
Check out the video below. In this demo, Santiago uses the new Soda MCP with Claude to find out which of his datasets are “AI-ready”.
What it looks like by role
People stay central. AI handles enforcement at scale; the domain knowledge and judgment stay with your team. Here's what changes day to day, following the data from the teams that build it to the leaders who answer for it:
Data engineers wire checks into their pipelines with the CLI, build Soda into their own tooling through the API, and hand the larger, repetitive jobs to agents over MCP.
Governance teams and stewards turn the rules they already know into running checks with Copilot, widen coverage, and trace a failed record to its root cause. Every failed row is captured in the Diagnostics Warehouse, inside your own environment, for an audit trail without exporting data.
Business and analytics users can ask, in plain language, whether the data behind a dashboard is trustworthy, and propose a quality rule without filing a ticket.
Architects and CTOs get a clear record of what an agent did versus what a person did. By default, Soda AI works from metadata rather than raw data, and bring-your-own-key (BYOK) keeps sensitive data on your terms.
Soda's AI is purpose-built and independently validated:
~70% fewer false-positive alerts, so teams spend their time on real issues, not noise.
~1 billion rows scanned in 64 seconds, so coverage scales without runaway compute cost.
Peer-reviewed research (NeurIPS, JAIR, and ACML) behind the anomaly-detection models.
Where to start
AI for data quality isn't one-size-fits-all; where you begin depends on how much coverage you already have.
Smaller and mid-market teams: start from zero. The fastest path to coverage is to generate it. Point Autopilot at your datasets and it drafts fully populated contracts in a batch, so a lean team goes from nothing to a real baseline in an afternoon, then refines from there.
Scaling teams: refine and right-size. Once you have a baseline, the work shifts from creating checks to managing them. AI suggests checks where coverage is thin, simulates what a check will cost before you add it, and prunes the redundant ones, so coverage deepens without compute costs running away. The trap to avoid: adding checks everywhere, because coverage without cost-awareness gets expensive fast.
Enterprises: manage the whole estate. At estate scale, AI helps run the program itself: scanning everything for over-checking, prioritizing the fixes that matter most, and giving leaders one view of data-estate health. Because Soda runs each contract as the most optimized SQL it can, that cost stays manageable even across a large estate.
Team profile | Where to start | What AI does | Soda AI surface |
|---|---|---|---|
Smaller / mid-market | From zero | Batch-generate contracts for coverage | Contract Autopilot |
Scaling | Refining coverage | Suggest checks, simulate cost, prune | Soda AI (agentic) + MCP |
Enterprise | Whole-estate view | Monitor health, prioritize fixes | Soda AI + MCP |
In this demo, Hakim shows how a governance lead asks Soda AI for quality coverage across every data source, gets an instant read on the whole estate, and reassigns dataset ownership, all in plain language.
Quick readiness check
The fastest way to begin is to find out where you stand. Do this quick self-check.
Is your data ready for AI?
If an AI agent read your production data today, could it tell which tables are trustworthy — and could a new analyst?
Can you state, for each critical dataset, what "good" looks like in a form a machine can check?
Are quality expectations shared between the people who produce data and the people who consume it?
When something breaks, can you trace it to its likely root cause?
Do you know what your current checks cost to run?
The more "no"s, the wider your AI-readiness gap: the distance between your data today and quality that's defined, executable, and shared, so people and agents can both trust it. It's where most teams start, and closing it is faster than it used to be. Closing that gap is as much a governance shift as a tooling one; for the governance side, read AI governance and data quality essentials.
From here, three steps:
Make quality machine-readable. Generate your first contracts with Autopilot instead of writing them by hand.
Refine and scale. Iterate with Copilot, wire checks into pipelines with the CLI, and open quality to agents with MCP.
Keep a human in the loop. Review what the AI proposes and approve what's right. The provenance stays visible the whole way.
The bottom line
AI for data quality isn't a smarter alarm on your dashboards. It's making quality defined, shared, and legible to AI, with humans approving the work.
Everything you know about data quality still holds. The difference now is reach: you can cover more of your data, and keep that coverage current, without scaling the team. Start with one dataset, make quality enforceable, and build from there.
If you already run contracts across your estate, the frontier is agentic data quality at scale: workflows where AI keeps coverage current, simulates the cost of changes before they land, and prunes checks that no longer earn their keep.
The direction is a platform where quality rules are derived automatically, enforced continuously, and refined together. With Soda AI: Autopilot gets you covered, Copilot helps you get it right, and enforcement keeps it that way. None of it removes the human. It works because contracts make the AI's work reviewable.
Want to see what AI-driven data quality looks like in practice? Explore Soda AI.
Frequently asked questions
AI for data quality shifts data management from manual rule-writing to automated systems that keep datasets accurate, complete, and fit for purpose.
For quite some time, AI has been helping write and review code across software engineering, but data quality is only catching up. To be fair, writing data tests requires heavy business context (e.g., "Is this $0 order a test record, a cancelled sale, or a broken integration?"), which made early AI and automation harder to apply compared to standard software logic.
But two things have been changing to make AI adoption for data quality management more imperative. First is scale: far more people touch data than ever, and far more of it moves through your pipelines every day. Second is a new kind of consumer: AI agents are now consuming your software and data too. Unlike a person, an agent won't pause at a value that looks off, so the quality of that data sets the ceiling on what it can safely do.
This guide breaks down the shift from manual data-quality checks to intelligent, automated systems. In this blog, we’ll cover:
Why data quality management needs to change.
What "AI for data quality" actually means.
The foundation needed to make AI-driven quality reliable and automated.
How modern data teams are using AI for data quality today.
By the end, you'll have a short self-check to see if your data is ready for AI, and a path to start without rebuilding everything.
Key Takeaways |
|---|
|
Why can't data quality stay manual?
Data quality can't stay manual because both sides of the equation outgrew hand-written checks: the way data is produced and the way it is consumed.
For a long time, data quality was a purely manual, highly reactive process. Data engineers and analysts would literally open documentation (if it existed), look at a new table, and manually write SQL assertions or configure rules one table at a time. That held up when a few analysts read a few dashboards. It doesn't hold up now.
More people, more data
The volume of data created and consumed worldwide keeps climbing, and access to it has been democratized at the same time.
Data engineering teams increasingly manage thousands of tables due to pipeline sprawl, AI context needs, and decentralized architectures. Some industries receive millions of records that update in real-time. On top of that, analysts, business users, and brand-new roles now work with tables they'd never have touched a few years ago.
Central, manual data quality simply can't cover that surface area. We've reached the point where keeping pace by hand no longer scales. AI, using anomaly detection to learn historical patterns and automatically flag unexpected changes, is what lets teams keep up with the velocity of modern data flow.
AI as your new consumer
Until recently, the only consumers of your data were people: analysts reading dashboards, teams building forecasts. They'd catch a wrong number and chase it down. Now, AI agents and models consume that data too, and they act on it directly, without pausing at a value that looks off. Feed them something outdated, duplicated, or contradictory, and they keep running and confidently generate wrong answers.
Today, data feeds real-time machine learning models, automated marketing triggers, and customer-facing products. And reversing automated actions executed on bad data is vastly more expensive and damaging than fixing a broken dashboard.
So AI-ready data is the new bar.
Poor data quality is now one of the biggest challenges standing between enterprise AI projects and production. Gartner predicts that through 2026, organizations will abandon 60% of AI projects due to a lack of AI-ready data.
The teams pulling ahead aren't working harder; they've handed the repetitive parts of quality management to AI and kept their people on judgment. AI does the heavy lifting, eliminating ad hoc validation scripts and manual checks so that teams can spend time analyzing instead of debugging.
Data quality for AI means making your data trustworthy enough for AI to consume. AI for data quality means using AI to run data quality workflows.
What is AI-driven data quality?
AI-driven data quality means using AI to do the data-quality work itself: proposing checks, watching for anomalies, and resolving issues, rather than having engineers hand-code every rule.
How much of that work you hand to the AI is what separates its two modes.
Assistive vs agentic AI for data quality
The difference between assistive and agentic AI for data quality comes down to how tasks are run and how much supervision is needed.
With assistive AI, you direct, and AI accelerates. Think of it as your co-pilot. You still define the strategy, but the AI eliminates the manual grind of writing syntax, tuning thresholds, and hunting for needles in the haystack. Day-to-day, assistive AI for data quality shows up in a few ways. For example:
Writing the checks: Instead of hard-coding SQL assertions or YAML files table by table, you interact in plain English. You tell the AI, "Ensure this transaction column never has negative values and updates daily," and it drafts the matching check for your data contract, which you review and approve before it runs.
Monitoring at scale: You stop writing manual threshold alerts (e.g., "Alert me if rows drop by 10%"). AI-driven anomaly detection automatically learns historical patterns by scanning rows to build a baseline of what "normal" looks like. It flags the anomalies humans miss and adapts as your data evolves.
Learning with feedback loops: The AI flags an issue or drafts the code. You review it, give it feedback ("Yes, this is an anomaly" or "No, this was a planned data drop"), and the algorithm gets smarter.
With Agentic AI, you set the goal, and AI executes. Agentic data quality moves from passive suggestions to active execution. You establish the boundaries, and the agent actively works to keep your data within those lines. Some examples of how agentic AI for data quality shows up are:
Tracing root causes: While assistive AI alerts you that an anomaly occurred, an agentic workflow investigates why. If a pipeline breaks, the agent can autonomously trace the lineage to find the exact upstream schema change or bad data ingestion that caused the failure.
Drafting resolution: Instead of waiting for a data engineer to manually write a fix, the agent prepares the remediation logic. It might draft an updated check to handle a newly added column, suggest a quarantine rule for bad rows, or rewrite a broken test.
Operating on approval: The agent doesn’t push fixes to production blindly. It packages its findings and proposed code into a Pull Request or a UI prompt. The workflow is simple: the agent does the grunt work, and you approve the final action.
These are just examples. Because once you set the goal, an agent can run virtually any quality workflow you define — continuously and independently — and bring changes back for approval.
Whether you are using an assistant to translate business rules into code or an agent to trace and draft remediation steps, the goal isn't to remove human judgment; it's to remove the operational toil.
Assistive AI for data quality | Agentic AI for data quality | |
|---|---|---|
Who initiates | A person, step by step | You set a goal; the system plans |
Human role | In the driver's seat | In the loop, approving the work |
Best for | Targeted edits, explanations | Coverage and upkeep at scale |
Prerequisite | Data contracts to build on | Data contracts to act on |
Ultimately, the goal of both modes goes beyond just automating the daily grind. The bigger difference is where the safety check sits: with assistive AI, a person signs off on every change; in an agentic workflow, the data itself becomes the checkpoint, because the agent has to check its work against your definition of "good" before it acts.
That's what raises the bar for trust. And the durable value of both modes is the same: quality that both people and agents can act on with confidence.
Why data contracts make AI-driven data quality reliable
AI doesn't create quality; it scales whatever you already have. Point it at clear, well-defined data, and it's a force multiplier. Point it at a mess, and it produces confident, wrong answers faster.
So, if you want AI to automate your data quality, you have to give it a foundation in a language it understands: encoded and executable specs. This foundation is the data contract, and it's where most teams currently have a massive gap.
What a data contract actually is
A data contract is a version-controlled, executable spec of what a dataset must look like. It captures business expectations, ownership, and strict quality thresholds.
This embedded context is exactly what tells an agent when a dataset is trustworthy and when it needs to hold off and flag a human. Think of it as the .md file your data exposes to AI.
Without a contract, an AI agent is forced to fill the gaps and guess your business logic. Data contracts eliminate this risk. They keep data teams entirely in control of defining expectations, while the AI does the heavy work of enforcing them at scale.
That is the core architectural bet of modern data quality: one definition of "good" that serves humans and AI alike. The exact same contract that tells an analyst the data is safe to consume is the one an AI agent reads to decide whether to execute a task.
To understand the foundations of data contracts, read our definitive guide to data contracts.
Now, if data contracts are so useful, why doesn't every company already use them?
Because historically, writing a contract meant starting from a blank page. Expecting data engineers to manually write YAML files, define schemas, and hard-code quality thresholds for thousands of tables brings us right back to the manual bottleneck we started with.
This is where Soda AI comes in.
How teams use AI to get AI-ready data
The good news is that no one needs to start from a blank page anymore. And it isn't only engineers who contribute; the business people who know the data best can put their own context into a contract, in plain language, no ticket required.
Teams get reliable data for dashboards, ML models, and agents to consume by making quality machine-readable, then scaling it.
Soda AI to author and scale data contracts
Soda AI has a set of functionalities, allowing teams to generate data contracts from real data, refine them, and open them to agents. You reach much of it through a chat interface in Soda Cloud, in plain language, though you can also kick off Autopilot straight from your datasets. Either way, every action it proposes is shown and approved by a person before it runs.
Here is how the authoring process actually works in practice:
Chat interface
The conversational entry point to Soda AI. Ask what a check, monitor, or incident means, or tell it to make a change, and it reaches for the functionalities below (Autopilot, Copilot, and the agent-facing interfaces) to carry it out.
Contract Autopilot
The batch path from zero to coverage. Point Autopilot at your datasets and it generates fully populated data contracts, complete with recommended checks drawn from your data's own profile, so a team starting from nothing reaches real coverage in an afternoon instead of a multi-quarter program.
Contract Copilot
The plain-language way to refine a single contract, with you in the driver's seat. Ask Copilot to add a freshness check, tighten a rule, or handle a nested field. It updates the contract from schema and metadata (never your raw rows) and shows you exactly what changed.
Agent-facing interfaces: MCP, CLI, and API
Where your agents and pipelines reach trusted data. MCP, the CLI, and the API put your contracts and data-quality status in front of the tools your team and your agents already use: Soda MCP connects your own agents to trusted data, the CLI runs data quality checks programmatically inside your existing pipelines, and the API integrates Soda with your own systems.
Check out the video below. In this demo, Santiago uses the new Soda MCP with Claude to find out which of his datasets are “AI-ready”.
What it looks like by role
People stay central. AI handles enforcement at scale; the domain knowledge and judgment stay with your team. Here's what changes day to day, following the data from the teams that build it to the leaders who answer for it:
Data engineers wire checks into their pipelines with the CLI, build Soda into their own tooling through the API, and hand the larger, repetitive jobs to agents over MCP.
Governance teams and stewards turn the rules they already know into running checks with Copilot, widen coverage, and trace a failed record to its root cause. Every failed row is captured in the Diagnostics Warehouse, inside your own environment, for an audit trail without exporting data.
Business and analytics users can ask, in plain language, whether the data behind a dashboard is trustworthy, and propose a quality rule without filing a ticket.
Architects and CTOs get a clear record of what an agent did versus what a person did. By default, Soda AI works from metadata rather than raw data, and bring-your-own-key (BYOK) keeps sensitive data on your terms.
Soda's AI is purpose-built and independently validated:
~70% fewer false-positive alerts, so teams spend their time on real issues, not noise.
~1 billion rows scanned in 64 seconds, so coverage scales without runaway compute cost.
Peer-reviewed research (NeurIPS, JAIR, and ACML) behind the anomaly-detection models.
Where to start
AI for data quality isn't one-size-fits-all; where you begin depends on how much coverage you already have.
Smaller and mid-market teams: start from zero. The fastest path to coverage is to generate it. Point Autopilot at your datasets and it drafts fully populated contracts in a batch, so a lean team goes from nothing to a real baseline in an afternoon, then refines from there.
Scaling teams: refine and right-size. Once you have a baseline, the work shifts from creating checks to managing them. AI suggests checks where coverage is thin, simulates what a check will cost before you add it, and prunes the redundant ones, so coverage deepens without compute costs running away. The trap to avoid: adding checks everywhere, because coverage without cost-awareness gets expensive fast.
Enterprises: manage the whole estate. At estate scale, AI helps run the program itself: scanning everything for over-checking, prioritizing the fixes that matter most, and giving leaders one view of data-estate health. Because Soda runs each contract as the most optimized SQL it can, that cost stays manageable even across a large estate.
Team profile | Where to start | What AI does | Soda AI surface |
|---|---|---|---|
Smaller / mid-market | From zero | Batch-generate contracts for coverage | Contract Autopilot |
Scaling | Refining coverage | Suggest checks, simulate cost, prune | Soda AI (agentic) + MCP |
Enterprise | Whole-estate view | Monitor health, prioritize fixes | Soda AI + MCP |
In this demo, Hakim shows how a governance lead asks Soda AI for quality coverage across every data source, gets an instant read on the whole estate, and reassigns dataset ownership, all in plain language.
Quick readiness check
The fastest way to begin is to find out where you stand. Do this quick self-check.
Is your data ready for AI?
If an AI agent read your production data today, could it tell which tables are trustworthy — and could a new analyst?
Can you state, for each critical dataset, what "good" looks like in a form a machine can check?
Are quality expectations shared between the people who produce data and the people who consume it?
When something breaks, can you trace it to its likely root cause?
Do you know what your current checks cost to run?
The more "no"s, the wider your AI-readiness gap: the distance between your data today and quality that's defined, executable, and shared, so people and agents can both trust it. It's where most teams start, and closing it is faster than it used to be. Closing that gap is as much a governance shift as a tooling one; for the governance side, read AI governance and data quality essentials.
From here, three steps:
Make quality machine-readable. Generate your first contracts with Autopilot instead of writing them by hand.
Refine and scale. Iterate with Copilot, wire checks into pipelines with the CLI, and open quality to agents with MCP.
Keep a human in the loop. Review what the AI proposes and approve what's right. The provenance stays visible the whole way.
The bottom line
AI for data quality isn't a smarter alarm on your dashboards. It's making quality defined, shared, and legible to AI, with humans approving the work.
Everything you know about data quality still holds. The difference now is reach: you can cover more of your data, and keep that coverage current, without scaling the team. Start with one dataset, make quality enforceable, and build from there.
If you already run contracts across your estate, the frontier is agentic data quality at scale: workflows where AI keeps coverage current, simulates the cost of changes before they land, and prunes checks that no longer earn their keep.
The direction is a platform where quality rules are derived automatically, enforced continuously, and refined together. With Soda AI: Autopilot gets you covered, Copilot helps you get it right, and enforcement keeps it that way. None of it removes the human. It works because contracts make the AI's work reviewable.
Want to see what AI-driven data quality looks like in practice? Explore Soda AI.
Frequently asked questions
What is AI for data quality?
AI for data quality is the use of AI to define, monitor, and resolve data quality at a scale that hand-written rules can't match. It works in two modes: assistive data quality, where you direct the AI step by step, and agentic data quality, where you set a goal and approve the work the system does.
What's the difference between assistive and agentic AI for data quality?
The difference is who drives. With assistive AI, a person directs each step, like asking a copilot to add a check. With agentic AI, you set a goal and a boundary, and the system plans and runs the work, then brings changes back for approval. Both modes need machine-readable specs to work.
Why is data quality important for AI?
AI acts on data literally, so flawed inputs produce flawed outputs. An agent can't apply the human judgment that catches an odd number in a report, so the quality of what you feed it sets the ceiling on what it can reliably do.
How does AI improve data quality?
AI improves data quality by taking on work that used to be manual: profiling tables, suggesting and drafting checks, learning each dataset's normal behavior to flag anomalies, and helping remediate issues once they surface. Used well, it lets a small team cover far more data, and keep that coverage current than hand-written rules ever could.
How do data contracts help AI for data quality?
Data contracts make quality executable. A contract states what a dataset should look like, so an agent can read it and know when data is trustworthy and when to hold off. Without that signal, AI acts confidently on data it can't verify.
What does Soda AI do?
Soda AI is the umbrella for Soda's AI features: a chat interface, Contract Autopilot, Contract Copilot, and agent-facing interfaces (MCP, the CLI, and the API). Together, they author and scale data contracts, connect your agents and pipelines to trusted data, and keep a human in the loop to review and approve the work.
Does AI replace data engineers and stewards?
No. AI for data quality removes the repetitive work that never needed human judgment, like drafting a first contract for every table. The engineer and the steward stay in the loop, owning the decisions and the domain knowledge, while the AI handles scale and speed.
Trusted by the world’s leading enterprises
Real stories from companies using Soda to keep their data reliable, accurate, and ready for action.
At the end of the day, we don’t want to be in there managing the checks, updating the checks, adding the checks. We just want to go and observe what’s happening, and that’s what Soda is enabling right now.

Sid Srivastava
Director of Data Governance, Quality and MLOps
Investing in data quality is key for cross-functional teams to make accurate, complete decisions with fewer risks and greater returns, using initiatives such as product thinking, data governance, and self-service platforms.

Mario Konschake
Director of Product-Data Platform
Soda has integrated seamlessly into our technology stack and given us the confidence to find, analyze, implement, and resolve data issues through a simple self-serve capability.

Sutaraj Dutta
Data Engineering Manager
Our goal was to deliver high-quality datasets in near real-time, ensuring dashboards reflect live data as it flows in. But beyond solving technical challenges, we wanted to spark a cultural shift - empowering the entire organization to make decisions grounded in accurate, timely data.

Gu Xie
Head of Data Engineering
4.4 of 5
Your data has problems.
Now they fix themselves.
Automated data quality, remediation, and management.
One platform, agents that do the work, you approve.
Trusted by








Trusted by the world’s leading enterprises
Real stories from companies using Soda to keep their data reliable, accurate, and ready for action.
At the end of the day, we don’t want to be in there managing the checks, updating the checks, adding the checks. We just want to go and observe what’s happening, and that’s what Soda is enabling right now.
Sid Srivastava
Director of Data Governance, Quality and MLOps
Investing in data quality is key for cross-functional teams to make accurate, complete decisions with fewer risks and greater returns, using initiatives such as product thinking, data governance, and self-service platforms.
Mario Konschake
Director of Product-Data Platform
Soda has integrated seamlessly into our technology stack and given us the confidence to find, analyze, implement, and resolve data issues through a simple self-serve capability.
Sutaraj Dutta
Data Engineering Manager
Our goal was to deliver high-quality datasets in near real-time, ensuring dashboards reflect live data as it flows in. But beyond solving technical challenges, we wanted to spark a cultural shift - empowering the entire organization to make decisions grounded in accurate, timely data.
Gu Xie
Head of Data Engineering
4.4 of 5
Your data has problems.
Now they fix themselves.
Automated data quality, remediation, and management.
One platform, agents that do the work, you approve.
Trusted by
Solutions
Trusted by the world’s leading enterprises
Real stories from companies using Soda to keep their data reliable, accurate, and ready for action.
At the end of the day, we don’t want to be in there managing the checks, updating the checks, adding the checks. We just want to go and observe what’s happening, and that’s what Soda is enabling right now.
Sid Srivastava
Director of Data Governance, Quality and MLOps
Investing in data quality is key for cross-functional teams to make accurate, complete decisions with fewer risks and greater returns, using initiatives such as product thinking, data governance, and self-service platforms.
Mario Konschake
Director of Product-Data Platform
Soda has integrated seamlessly into our technology stack and given us the confidence to find, analyze, implement, and resolve data issues through a simple self-serve capability.
Sutaraj Dutta
Data Engineering Manager
Our goal was to deliver high-quality datasets in near real-time, ensuring dashboards reflect live data as it flows in. But beyond solving technical challenges, we wanted to spark a cultural shift - empowering the entire organization to make decisions grounded in accurate, timely data.
Gu Xie
Head of Data Engineering
4.4 of 5
Your data has problems.
Now they fix themselves.
Automated data quality, remediation, and management.
One platform, agents that do the work, you approve.
Trusted by
Solutions