Data Observability vs Data Testing: What's the Difference?
Data Observability vs Data Testing: What's the Difference?
Data Observability vs Data Testing: What's the Difference?

Fabiana Ferraz
Fabiana Ferraz
Technical Writer at Soda
Technical Writer at Soda
Table of Contents
As data pipelines grow more complex, two concepts increasingly appear together in engineering conversations: data testing and data observability. They sound similar, but they solve different problems. Tests catch the failures you've written a rule for; observability catches the changes nobody thought to write a rule for.
Key Takeaways |
|---|
|
What is Data Testing?
Data testing is one of the mechanisms used to evaluate and maintain data quality. It involves validating datasets, pipelines, and transformations against predefined expectations.
These expectations are usually implemented as automated checks that run during data processing workflows. In modern data stacks, these checks live alongside transformation code in version-controlled repositories, the same way application code ships with unit tests.
As data engineering systems grow more complex, automated data testing becomes increasingly important because manual validation no longer scales. The goal is to prevent downstream breakage and keep transformations stable and reliable.
Data engineers build these tests into pipelines to detect problems before unreliable data reaches downstream systems. For example, a test might verify that order IDs remain unique, that revenue values are never negative, or that daily ingestion jobs complete within an expected time window.
Common Test Types
Modern data engineering teams use several categories of data validation tests to evaluate data quality throughout the pipeline. In practice, data testing usually checks:
Schema
Schema checks validate the structure of datasets. They ensure columns exist, data types remain consistent, and required fields are present. These tests are especially important when multiple systems move data across shared infrastructure.
Freshness
Freshness checks verify whether data is arriving on time. For example, a daily ingestion pipeline may fail if new records have not appeared within an expected window.
These checks are critical in real-time data environments where stale data can impact operational decisions.
Volume
Row count checks monitor unexpected changes in record counts. A sudden drop or spike in rows may indicate upstream integration failures, duplicate ingestion, or broken transformations.
Business Rule
Metric checks compare a computed value — an average, sum, count, or custom SQL result — against a threshold. For example, asserting that the average order value stays between $50 and $500, or that the count of failed transactions never exceeds 1% of total transactions.
Failed-rows checks flag specific rows that violate a rule. For example, no row should have a revenue value less than zero, no end_date should fall before its start_date, and account_status should always be one of an approved set of values.
Reconciliation
Reconciliation checks compare aggregate metrics across two related datasets. For example, ensuring the daily order total in a reporting table matches the sum in the source orders table, or that the customer count in the warehouse matches the count in the operational database.
These checks are often part of bigger data integrity testing practices, which help ensure data remains accurate, consistent, and reliable as it moves through pipelines and systems.
How Modern Teams Operationalize Tests: Data Contracts
Rather than scattering checks across pipeline scripts, modern data teams bundle them into a data contract — a single, version-controlled YAML spec that defines what "correct" looks like for a dataset. Engineers and the business users who consume the data co-author the contract; CI runs it on every change; the same contract is verified again in production.
A simple contract for a sales_transactions table looks like this:
dataset: warehouse/retail/public/sales_transactions checks: - schema: allow_extra_columns: false - freshness: column: order_date threshold: unit: hour must_be_less_than: 24 - row_count: threshold: must_be_greater_than: 1000 columns: - name: order_id data_type: varchar checks: - missing: - duplicate: - name: revenue data_type: numeric checks: - invalid: valid_min: 0
Each block under checks is one of the test types described above. The whole file is the contract and every change can be reviewed like code before it reaches production.
Read the blog “4 Templates You Can Use Today” for more data contracts examples.
Why Data Testing Alone Is Not Enough
Data testing is essential, but it is not sufficient on its own to understand or manage modern data systems. A team can implement hundreds of automated tests and still miss critical issues if they rely only on predefined validation rules.
That is because data testing is limited to what teams explicitly define in advance. It can confirm whether data matches expected conditions, but it does not explain how or why data behavior changes across the system.
For example, tests may confirm that a dataset still conforms to the schema and business rules while missing broader pipeline issues happening upstream. A pipeline may continue running successfully while ingesting incomplete or delayed records from a source system. A schema change might propagate downstream without immediately triggering a failing test. A dataset may technically pass all checks while still arriving too late to support operational reporting.
This is why data observability exists as a complement to data testing, not a replacement.
What is Data Observability?
Data observability focuses on understanding how data behaves as it moves through data infrastructure. Instead of only validating whether data meets predefined rules, data observability monitors whether the system that processes data is behaving normally and whether data integrity is being preserved across every stage of its lifecycle.
This includes tracking how data moves through pipelines, how it is transformed, and whether unexpected changes occur during data processing.
In modern data engineering roles, observability is becoming essential because data systems are no longer simple ETL pipelines. They are distributed networks of data integration across multiple platforms.
Let’s take this as an example: a pipeline might continue running successfully while quietly processing incomplete data from an upstream source. Without observability, this type of issue may not be detected until business intelligence dashboards or data analysis reports show incorrect results.
Common Observability Signals
Modern observability platforms track several categories of signals across pipelines and datasets. Each one surfaces a different kind of unexpected change.
These signals are especially important in environments using cloud computing and real-time data pipelines, where changes can spread quickly across systems.
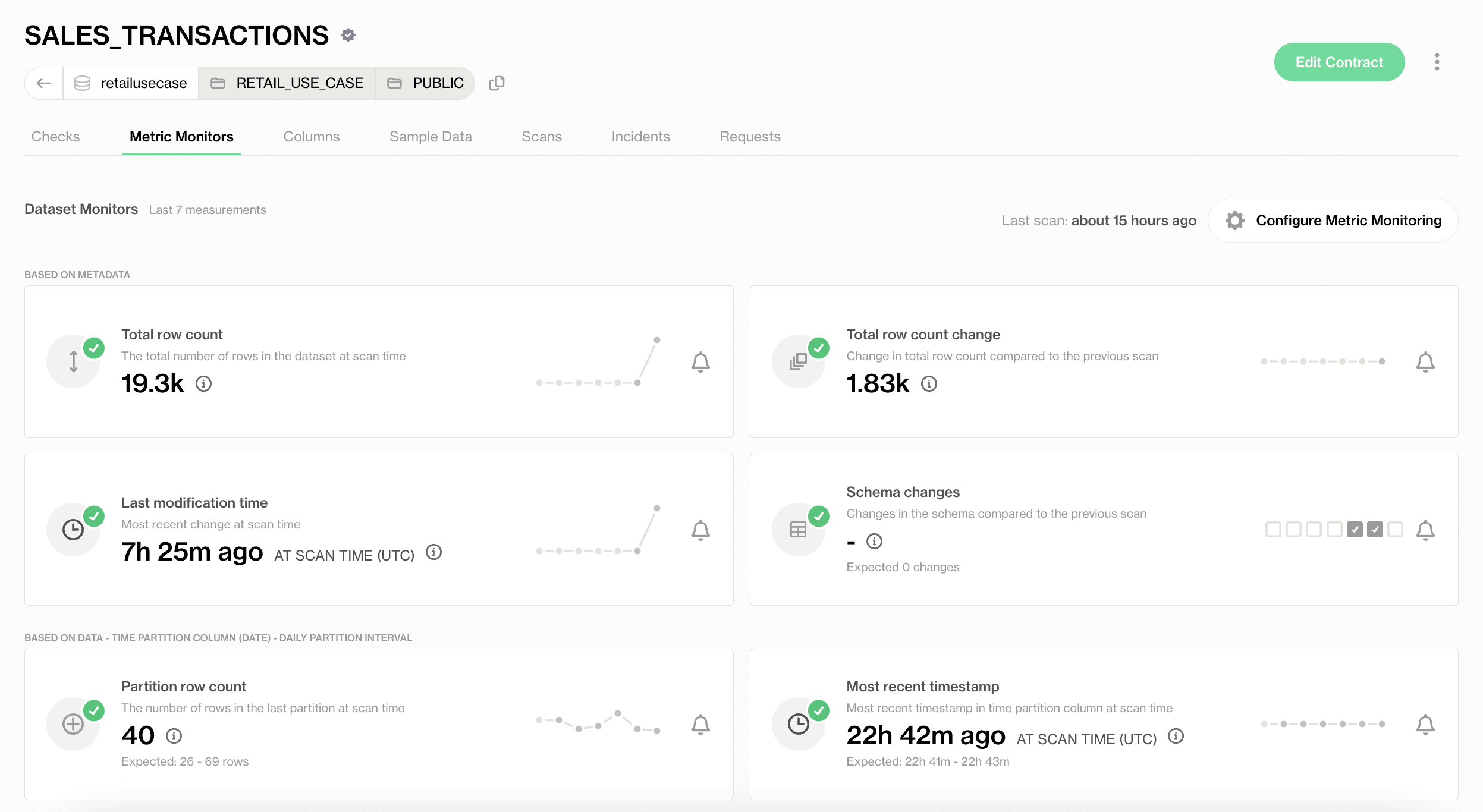
↗ Soda Metric Monitoring dashboard.
These are five of the most typical monitors:
Freshness
Freshness tracking watches whether data is arriving on the expected schedule. A dataset that should refresh hourly but hasn't updated in three hours is a freshness anomaly, even when the records themselves look correct.
Volume
Volume monitoring watches record counts over time. A sudden 80% drop in daily rows usually signals an upstream break long before any individual record-level test fails.
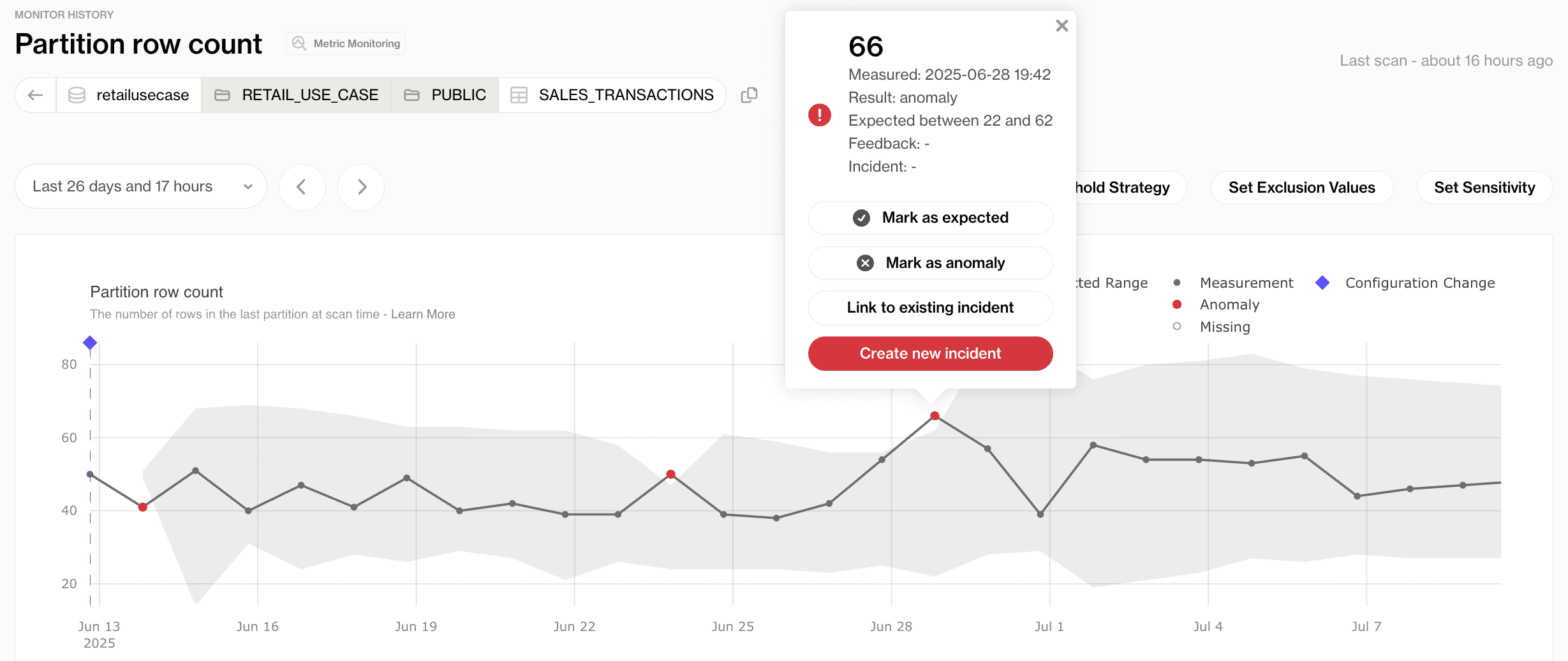
↗ Soda column monitor: the algorithm learned the baseline from history and surfaced the deviation for review.
Schema
Schema drift detection flags structural changes (new columns, dropped fields, type changes) as they propagate from source systems. Unlike schema tests, which assert a specific structure, drift detection surfaces unexpected changes for review.
Distribution
Distribution monitoring watches statistical properties of data over time. A field that suddenly contains 30% nulls, or where average values double overnight, indicates something changed upstream even if no explicit rule was violated.
Lineage
Lineage maps how datasets connect across pipelines. When something breaks, lineage tells teams exactly which dashboards, models, or applications are affected, turning incident triage from a hunt into a query.
Learn more in the article “What Is Data Observability? 5 Pillars + How to Implement It”.
Data Observability vs Data Testing: The Core Difference
Data testing and data observability are both used to improve data reliability, but they approach problems differently.
Data testing validates data against predefined expectations.
→ Teams define rules based on schema, business logic, freshness requirements, or data modeling assumptions, then run automated checks to verify that data continues to conform to those expectations.
Data observability continuously monitors how data behaves across pipelines, transformations, and systems.
→ It helps teams detect unexpected changes, anomalies, and operational issues that may not have been explicitly anticipated in advance.
In practice, data testing answers questions like:
Did this dataset violate a known rule?
Did a required field become null?
Did row counts drop below a threshold?
Data observability focuses on questions like:
What changed in the pipeline?
Why did this dataset suddenly drift?
Which downstream systems are affected?
In other words, data testing is designed to validate expected conditions. Data observability is designed to surface unexpected behavior across the broader data system.
Data Observability | Data Testing | |
|---|---|---|
Approach | Reactive and adaptive | Proactive and preventative |
When it runs | In production, runtime monitoring | Pre-production, during development or CI/CD |
What it does | Monitors data behavior and changes over time; detects anomalies, schema changes, and unexpected issues | Validates known rules and enforces contracts |
What it catches | Unknown unknowns — deviations no one thought to write a rule for | Known knowns — failures you've defined a rule for |
Configuration | Adaptive — baselines learned from historical data | Explicit, per-check (you write the rule) |
Output when it fires | Signal (something looks unusual; investigate) | Certainty (rule failed) |
Example | Row count dropped 40% overnight without anyone configuring a 40% threshold |
|
Modern data teams increasingly rely on both. Testing provides precise validation for known requirements, while observability improves visibility into complex, distributed data infrastructure where not every failure mode can be predicted ahead of time.
Building a Practical Data Reliability Strategy
A reliable data system pairs two layers: tests that enforce known rules, and observability that catches what those rules miss.
In practice, the most useful pattern is to pair each test with a matching observability signal, so the system catches both known failures and unknown drift:
Schema test in CI + schema drift detection in production. The test blocks a breaking model from merging; the signal catches structural changes that propagate from upstream sources you don't control.
Row-count check at load time + volume anomaly monitoring over time. The check fails if a daily load returns zero rows; the monitor flags a 40% drop that's still technically above zero.
Freshness check on a critical table + freshness anomaly tracking across the warehouse. The check enforces the SLA you care about; the tracker surfaces tables you haven’t put under SLA yet.
Failed-rows check on a business rule + distribution monitoring. The rule catches values you know are invalid (negative revenue, blank customer IDs); the monitor catches a sudden shift in the population — a column that used to be 5% null suddenly running 30%.
The data contract is what makes this work in practice. Rather than maintaining tests in pipeline code and observability rules in a separate tool, the contract is the single, version-controlled spec — co-authored by engineers and the business users who consume the data — that the whole system runs against. When the dataset changes, the contract changes, and the rules update with it.
Try it on your pipeline. Fork Soda Core, write a contract in YAML and run
soda contract verifyagainst a dataset locally.
Frequently Asked Questions
As data pipelines grow more complex, two concepts increasingly appear together in engineering conversations: data testing and data observability. They sound similar, but they solve different problems. Tests catch the failures you've written a rule for; observability catches the changes nobody thought to write a rule for.
Key Takeaways |
|---|
|
What is Data Testing?
Data testing is one of the mechanisms used to evaluate and maintain data quality. It involves validating datasets, pipelines, and transformations against predefined expectations.
These expectations are usually implemented as automated checks that run during data processing workflows. In modern data stacks, these checks live alongside transformation code in version-controlled repositories, the same way application code ships with unit tests.
As data engineering systems grow more complex, automated data testing becomes increasingly important because manual validation no longer scales. The goal is to prevent downstream breakage and keep transformations stable and reliable.
Data engineers build these tests into pipelines to detect problems before unreliable data reaches downstream systems. For example, a test might verify that order IDs remain unique, that revenue values are never negative, or that daily ingestion jobs complete within an expected time window.
Common Test Types
Modern data engineering teams use several categories of data validation tests to evaluate data quality throughout the pipeline. In practice, data testing usually checks:
Schema
Schema checks validate the structure of datasets. They ensure columns exist, data types remain consistent, and required fields are present. These tests are especially important when multiple systems move data across shared infrastructure.
Freshness
Freshness checks verify whether data is arriving on time. For example, a daily ingestion pipeline may fail if new records have not appeared within an expected window.
These checks are critical in real-time data environments where stale data can impact operational decisions.
Volume
Row count checks monitor unexpected changes in record counts. A sudden drop or spike in rows may indicate upstream integration failures, duplicate ingestion, or broken transformations.
Business Rule
Metric checks compare a computed value — an average, sum, count, or custom SQL result — against a threshold. For example, asserting that the average order value stays between $50 and $500, or that the count of failed transactions never exceeds 1% of total transactions.
Failed-rows checks flag specific rows that violate a rule. For example, no row should have a revenue value less than zero, no end_date should fall before its start_date, and account_status should always be one of an approved set of values.
Reconciliation
Reconciliation checks compare aggregate metrics across two related datasets. For example, ensuring the daily order total in a reporting table matches the sum in the source orders table, or that the customer count in the warehouse matches the count in the operational database.
These checks are often part of bigger data integrity testing practices, which help ensure data remains accurate, consistent, and reliable as it moves through pipelines and systems.
How Modern Teams Operationalize Tests: Data Contracts
Rather than scattering checks across pipeline scripts, modern data teams bundle them into a data contract — a single, version-controlled YAML spec that defines what "correct" looks like for a dataset. Engineers and the business users who consume the data co-author the contract; CI runs it on every change; the same contract is verified again in production.
A simple contract for a sales_transactions table looks like this:
dataset: warehouse/retail/public/sales_transactions checks: - schema: allow_extra_columns: false - freshness: column: order_date threshold: unit: hour must_be_less_than: 24 - row_count: threshold: must_be_greater_than: 1000 columns: - name: order_id data_type: varchar checks: - missing: - duplicate: - name: revenue data_type: numeric checks: - invalid: valid_min: 0
Each block under checks is one of the test types described above. The whole file is the contract and every change can be reviewed like code before it reaches production.
Read the blog “4 Templates You Can Use Today” for more data contracts examples.
Why Data Testing Alone Is Not Enough
Data testing is essential, but it is not sufficient on its own to understand or manage modern data systems. A team can implement hundreds of automated tests and still miss critical issues if they rely only on predefined validation rules.
That is because data testing is limited to what teams explicitly define in advance. It can confirm whether data matches expected conditions, but it does not explain how or why data behavior changes across the system.
For example, tests may confirm that a dataset still conforms to the schema and business rules while missing broader pipeline issues happening upstream. A pipeline may continue running successfully while ingesting incomplete or delayed records from a source system. A schema change might propagate downstream without immediately triggering a failing test. A dataset may technically pass all checks while still arriving too late to support operational reporting.
This is why data observability exists as a complement to data testing, not a replacement.
What is Data Observability?
Data observability focuses on understanding how data behaves as it moves through data infrastructure. Instead of only validating whether data meets predefined rules, data observability monitors whether the system that processes data is behaving normally and whether data integrity is being preserved across every stage of its lifecycle.
This includes tracking how data moves through pipelines, how it is transformed, and whether unexpected changes occur during data processing.
In modern data engineering roles, observability is becoming essential because data systems are no longer simple ETL pipelines. They are distributed networks of data integration across multiple platforms.
Let’s take this as an example: a pipeline might continue running successfully while quietly processing incomplete data from an upstream source. Without observability, this type of issue may not be detected until business intelligence dashboards or data analysis reports show incorrect results.
Common Observability Signals
Modern observability platforms track several categories of signals across pipelines and datasets. Each one surfaces a different kind of unexpected change.
These signals are especially important in environments using cloud computing and real-time data pipelines, where changes can spread quickly across systems.
↗ Soda Metric Monitoring dashboard.
These are five of the most typical monitors:
Freshness
Freshness tracking watches whether data is arriving on the expected schedule. A dataset that should refresh hourly but hasn't updated in three hours is a freshness anomaly, even when the records themselves look correct.
Volume
Volume monitoring watches record counts over time. A sudden 80% drop in daily rows usually signals an upstream break long before any individual record-level test fails.
↗ Soda column monitor: the algorithm learned the baseline from history and surfaced the deviation for review.
Schema
Schema drift detection flags structural changes (new columns, dropped fields, type changes) as they propagate from source systems. Unlike schema tests, which assert a specific structure, drift detection surfaces unexpected changes for review.
Distribution
Distribution monitoring watches statistical properties of data over time. A field that suddenly contains 30% nulls, or where average values double overnight, indicates something changed upstream even if no explicit rule was violated.
Lineage
Lineage maps how datasets connect across pipelines. When something breaks, lineage tells teams exactly which dashboards, models, or applications are affected, turning incident triage from a hunt into a query.
Learn more in the article “What Is Data Observability? 5 Pillars + How to Implement It”.
Data Observability vs Data Testing: The Core Difference
Data testing and data observability are both used to improve data reliability, but they approach problems differently.
Data testing validates data against predefined expectations.
→ Teams define rules based on schema, business logic, freshness requirements, or data modeling assumptions, then run automated checks to verify that data continues to conform to those expectations.
Data observability continuously monitors how data behaves across pipelines, transformations, and systems.
→ It helps teams detect unexpected changes, anomalies, and operational issues that may not have been explicitly anticipated in advance.
In practice, data testing answers questions like:
Did this dataset violate a known rule?
Did a required field become null?
Did row counts drop below a threshold?
Data observability focuses on questions like:
What changed in the pipeline?
Why did this dataset suddenly drift?
Which downstream systems are affected?
In other words, data testing is designed to validate expected conditions. Data observability is designed to surface unexpected behavior across the broader data system.
Data Observability | Data Testing | |
|---|---|---|
Approach | Reactive and adaptive | Proactive and preventative |
When it runs | In production, runtime monitoring | Pre-production, during development or CI/CD |
What it does | Monitors data behavior and changes over time; detects anomalies, schema changes, and unexpected issues | Validates known rules and enforces contracts |
What it catches | Unknown unknowns — deviations no one thought to write a rule for | Known knowns — failures you've defined a rule for |
Configuration | Adaptive — baselines learned from historical data | Explicit, per-check (you write the rule) |
Output when it fires | Signal (something looks unusual; investigate) | Certainty (rule failed) |
Example | Row count dropped 40% overnight without anyone configuring a 40% threshold |
|
Modern data teams increasingly rely on both. Testing provides precise validation for known requirements, while observability improves visibility into complex, distributed data infrastructure where not every failure mode can be predicted ahead of time.
Building a Practical Data Reliability Strategy
A reliable data system pairs two layers: tests that enforce known rules, and observability that catches what those rules miss.
In practice, the most useful pattern is to pair each test with a matching observability signal, so the system catches both known failures and unknown drift:
Schema test in CI + schema drift detection in production. The test blocks a breaking model from merging; the signal catches structural changes that propagate from upstream sources you don't control.
Row-count check at load time + volume anomaly monitoring over time. The check fails if a daily load returns zero rows; the monitor flags a 40% drop that's still technically above zero.
Freshness check on a critical table + freshness anomaly tracking across the warehouse. The check enforces the SLA you care about; the tracker surfaces tables you haven’t put under SLA yet.
Failed-rows check on a business rule + distribution monitoring. The rule catches values you know are invalid (negative revenue, blank customer IDs); the monitor catches a sudden shift in the population — a column that used to be 5% null suddenly running 30%.
The data contract is what makes this work in practice. Rather than maintaining tests in pipeline code and observability rules in a separate tool, the contract is the single, version-controlled spec — co-authored by engineers and the business users who consume the data — that the whole system runs against. When the dataset changes, the contract changes, and the rules update with it.
Try it on your pipeline. Fork Soda Core, write a contract in YAML and run
soda contract verifyagainst a dataset locally.
Frequently Asked Questions
As data pipelines grow more complex, two concepts increasingly appear together in engineering conversations: data testing and data observability. They sound similar, but they solve different problems. Tests catch the failures you've written a rule for; observability catches the changes nobody thought to write a rule for.
Key Takeaways |
|---|
|
What is Data Testing?
Data testing is one of the mechanisms used to evaluate and maintain data quality. It involves validating datasets, pipelines, and transformations against predefined expectations.
These expectations are usually implemented as automated checks that run during data processing workflows. In modern data stacks, these checks live alongside transformation code in version-controlled repositories, the same way application code ships with unit tests.
As data engineering systems grow more complex, automated data testing becomes increasingly important because manual validation no longer scales. The goal is to prevent downstream breakage and keep transformations stable and reliable.
Data engineers build these tests into pipelines to detect problems before unreliable data reaches downstream systems. For example, a test might verify that order IDs remain unique, that revenue values are never negative, or that daily ingestion jobs complete within an expected time window.
Common Test Types
Modern data engineering teams use several categories of data validation tests to evaluate data quality throughout the pipeline. In practice, data testing usually checks:
Schema
Schema checks validate the structure of datasets. They ensure columns exist, data types remain consistent, and required fields are present. These tests are especially important when multiple systems move data across shared infrastructure.
Freshness
Freshness checks verify whether data is arriving on time. For example, a daily ingestion pipeline may fail if new records have not appeared within an expected window.
These checks are critical in real-time data environments where stale data can impact operational decisions.
Volume
Row count checks monitor unexpected changes in record counts. A sudden drop or spike in rows may indicate upstream integration failures, duplicate ingestion, or broken transformations.
Business Rule
Metric checks compare a computed value — an average, sum, count, or custom SQL result — against a threshold. For example, asserting that the average order value stays between $50 and $500, or that the count of failed transactions never exceeds 1% of total transactions.
Failed-rows checks flag specific rows that violate a rule. For example, no row should have a revenue value less than zero, no end_date should fall before its start_date, and account_status should always be one of an approved set of values.
Reconciliation
Reconciliation checks compare aggregate metrics across two related datasets. For example, ensuring the daily order total in a reporting table matches the sum in the source orders table, or that the customer count in the warehouse matches the count in the operational database.
These checks are often part of bigger data integrity testing practices, which help ensure data remains accurate, consistent, and reliable as it moves through pipelines and systems.
How Modern Teams Operationalize Tests: Data Contracts
Rather than scattering checks across pipeline scripts, modern data teams bundle them into a data contract — a single, version-controlled YAML spec that defines what "correct" looks like for a dataset. Engineers and the business users who consume the data co-author the contract; CI runs it on every change; the same contract is verified again in production.
A simple contract for a sales_transactions table looks like this:
dataset: warehouse/retail/public/sales_transactions checks: - schema: allow_extra_columns: false - freshness: column: order_date threshold: unit: hour must_be_less_than: 24 - row_count: threshold: must_be_greater_than: 1000 columns: - name: order_id data_type: varchar checks: - missing: - duplicate: - name: revenue data_type: numeric checks: - invalid: valid_min: 0
Each block under checks is one of the test types described above. The whole file is the contract and every change can be reviewed like code before it reaches production.
Read the blog “4 Templates You Can Use Today” for more data contracts examples.
Why Data Testing Alone Is Not Enough
Data testing is essential, but it is not sufficient on its own to understand or manage modern data systems. A team can implement hundreds of automated tests and still miss critical issues if they rely only on predefined validation rules.
That is because data testing is limited to what teams explicitly define in advance. It can confirm whether data matches expected conditions, but it does not explain how or why data behavior changes across the system.
For example, tests may confirm that a dataset still conforms to the schema and business rules while missing broader pipeline issues happening upstream. A pipeline may continue running successfully while ingesting incomplete or delayed records from a source system. A schema change might propagate downstream without immediately triggering a failing test. A dataset may technically pass all checks while still arriving too late to support operational reporting.
This is why data observability exists as a complement to data testing, not a replacement.
What is Data Observability?
Data observability focuses on understanding how data behaves as it moves through data infrastructure. Instead of only validating whether data meets predefined rules, data observability monitors whether the system that processes data is behaving normally and whether data integrity is being preserved across every stage of its lifecycle.
This includes tracking how data moves through pipelines, how it is transformed, and whether unexpected changes occur during data processing.
In modern data engineering roles, observability is becoming essential because data systems are no longer simple ETL pipelines. They are distributed networks of data integration across multiple platforms.
Let’s take this as an example: a pipeline might continue running successfully while quietly processing incomplete data from an upstream source. Without observability, this type of issue may not be detected until business intelligence dashboards or data analysis reports show incorrect results.
Common Observability Signals
Modern observability platforms track several categories of signals across pipelines and datasets. Each one surfaces a different kind of unexpected change.
These signals are especially important in environments using cloud computing and real-time data pipelines, where changes can spread quickly across systems.
↗ Soda Metric Monitoring dashboard.
These are five of the most typical monitors:
Freshness
Freshness tracking watches whether data is arriving on the expected schedule. A dataset that should refresh hourly but hasn't updated in three hours is a freshness anomaly, even when the records themselves look correct.
Volume
Volume monitoring watches record counts over time. A sudden 80% drop in daily rows usually signals an upstream break long before any individual record-level test fails.
↗ Soda column monitor: the algorithm learned the baseline from history and surfaced the deviation for review.
Schema
Schema drift detection flags structural changes (new columns, dropped fields, type changes) as they propagate from source systems. Unlike schema tests, which assert a specific structure, drift detection surfaces unexpected changes for review.
Distribution
Distribution monitoring watches statistical properties of data over time. A field that suddenly contains 30% nulls, or where average values double overnight, indicates something changed upstream even if no explicit rule was violated.
Lineage
Lineage maps how datasets connect across pipelines. When something breaks, lineage tells teams exactly which dashboards, models, or applications are affected, turning incident triage from a hunt into a query.
Learn more in the article “What Is Data Observability? 5 Pillars + How to Implement It”.
Data Observability vs Data Testing: The Core Difference
Data testing and data observability are both used to improve data reliability, but they approach problems differently.
Data testing validates data against predefined expectations.
→ Teams define rules based on schema, business logic, freshness requirements, or data modeling assumptions, then run automated checks to verify that data continues to conform to those expectations.
Data observability continuously monitors how data behaves across pipelines, transformations, and systems.
→ It helps teams detect unexpected changes, anomalies, and operational issues that may not have been explicitly anticipated in advance.
In practice, data testing answers questions like:
Did this dataset violate a known rule?
Did a required field become null?
Did row counts drop below a threshold?
Data observability focuses on questions like:
What changed in the pipeline?
Why did this dataset suddenly drift?
Which downstream systems are affected?
In other words, data testing is designed to validate expected conditions. Data observability is designed to surface unexpected behavior across the broader data system.
Data Observability | Data Testing | |
|---|---|---|
Approach | Reactive and adaptive | Proactive and preventative |
When it runs | In production, runtime monitoring | Pre-production, during development or CI/CD |
What it does | Monitors data behavior and changes over time; detects anomalies, schema changes, and unexpected issues | Validates known rules and enforces contracts |
What it catches | Unknown unknowns — deviations no one thought to write a rule for | Known knowns — failures you've defined a rule for |
Configuration | Adaptive — baselines learned from historical data | Explicit, per-check (you write the rule) |
Output when it fires | Signal (something looks unusual; investigate) | Certainty (rule failed) |
Example | Row count dropped 40% overnight without anyone configuring a 40% threshold |
|
Modern data teams increasingly rely on both. Testing provides precise validation for known requirements, while observability improves visibility into complex, distributed data infrastructure where not every failure mode can be predicted ahead of time.
Building a Practical Data Reliability Strategy
A reliable data system pairs two layers: tests that enforce known rules, and observability that catches what those rules miss.
In practice, the most useful pattern is to pair each test with a matching observability signal, so the system catches both known failures and unknown drift:
Schema test in CI + schema drift detection in production. The test blocks a breaking model from merging; the signal catches structural changes that propagate from upstream sources you don't control.
Row-count check at load time + volume anomaly monitoring over time. The check fails if a daily load returns zero rows; the monitor flags a 40% drop that's still technically above zero.
Freshness check on a critical table + freshness anomaly tracking across the warehouse. The check enforces the SLA you care about; the tracker surfaces tables you haven’t put under SLA yet.
Failed-rows check on a business rule + distribution monitoring. The rule catches values you know are invalid (negative revenue, blank customer IDs); the monitor catches a sudden shift in the population — a column that used to be 5% null suddenly running 30%.
The data contract is what makes this work in practice. Rather than maintaining tests in pipeline code and observability rules in a separate tool, the contract is the single, version-controlled spec — co-authored by engineers and the business users who consume the data — that the whole system runs against. When the dataset changes, the contract changes, and the rules update with it.
Try it on your pipeline. Fork Soda Core, write a contract in YAML and run
soda contract verifyagainst a dataset locally.
Frequently Asked Questions
What is the difference between data observability and data testing?
Data testing validates data against predefined expectations such as schema rules, freshness thresholds, or business logic. Data observability continuously monitors how data behaves across systems to detect unexpected changes, anomalies, and operational issues that may not have been explicitly defined in advance.
When should teams use data testing?
Data testing is most useful when teams need to validate explicit expectations inside data pipelines. This includes schema validation, null checks, freshness monitoring, duplicate detection, and business-rule enforcement during ETL extract transform load workflows.
When does data observability become necessary?
Data observability becomes increasingly important as data infrastructure grows more complex. In distributed cloud computing environments with multiple pipelines, integrations, and real-time data systems, observability helps teams detect unexpected issues that traditional tests may not catch immediately.
What types of issues can data observability detect?
Data observability can detect issues such as unexpected volume drops, schema drift, delayed data freshness, distribution changes, pipeline anomalies, and downstream impact across connected systems.
Can data observability replace data testing?
No. Data observability and data testing solve different problems. Data testing is effective for validating known conditions and enforcing specific requirements. Data observability provides broader visibility into pipeline behavior, data movement, and system health. Most modern data teams use both together.
Do modern data engineering teams need both observability and testing?
Yes. Data testing helps validate expected conditions, while data observability improves visibility into broader system behavior. Together, they help data engineers build more reliable data infrastructure and reduce the risk of silent pipeline failures.
How do data contracts fit with testing and observability?
Data contracts are the spec that bundles your tests in one place — a single, version-controlled YAML file co-authored by engineers and the business users who consume the data. Tests live inside the contract; observability complements it by catching changes the contract's rules don't cover.
Trusted by the world’s leading enterprises
Real stories from companies using Soda to keep their data reliable, accurate, and ready for action.
At the end of the day, we don’t want to be in there managing the checks, updating the checks, adding the checks. We just want to go and observe what’s happening, and that’s what Soda is enabling right now.

Sid Srivastava
Director of Data Governance, Quality and MLOps
Investing in data quality is key for cross-functional teams to make accurate, complete decisions with fewer risks and greater returns, using initiatives such as product thinking, data governance, and self-service platforms.

Mario Konschake
Director of Product-Data Platform
Soda has integrated seamlessly into our technology stack and given us the confidence to find, analyze, implement, and resolve data issues through a simple self-serve capability.

Sutaraj Dutta
Data Engineering Manager
Our goal was to deliver high-quality datasets in near real-time, ensuring dashboards reflect live data as it flows in. But beyond solving technical challenges, we wanted to spark a cultural shift - empowering the entire organization to make decisions grounded in accurate, timely data.

Gu Xie
Head of Data Engineering
4.4 of 5
Your data has problems.
Now they fix themselves.
Automated data quality, remediation, and management.
One platform, agents that do the work, you approve.
Trusted by








Trusted by the world’s leading enterprises
Real stories from companies using Soda to keep their data reliable, accurate, and ready for action.
At the end of the day, we don’t want to be in there managing the checks, updating the checks, adding the checks. We just want to go and observe what’s happening, and that’s what Soda is enabling right now.
Sid Srivastava
Director of Data Governance, Quality and MLOps
Investing in data quality is key for cross-functional teams to make accurate, complete decisions with fewer risks and greater returns, using initiatives such as product thinking, data governance, and self-service platforms.
Mario Konschake
Director of Product-Data Platform
Soda has integrated seamlessly into our technology stack and given us the confidence to find, analyze, implement, and resolve data issues through a simple self-serve capability.
Sutaraj Dutta
Data Engineering Manager
Our goal was to deliver high-quality datasets in near real-time, ensuring dashboards reflect live data as it flows in. But beyond solving technical challenges, we wanted to spark a cultural shift - empowering the entire organization to make decisions grounded in accurate, timely data.
Gu Xie
Head of Data Engineering
4.4 of 5
Your data has problems.
Now they fix themselves.
Automated data quality, remediation, and management.
One platform, agents that do the work, you approve.
Trusted by
Solutions
Trusted by the world’s leading enterprises
Real stories from companies using Soda to keep their data reliable, accurate, and ready for action.
At the end of the day, we don’t want to be in there managing the checks, updating the checks, adding the checks. We just want to go and observe what’s happening, and that’s what Soda is enabling right now.
Sid Srivastava
Director of Data Governance, Quality and MLOps
Investing in data quality is key for cross-functional teams to make accurate, complete decisions with fewer risks and greater returns, using initiatives such as product thinking, data governance, and self-service platforms.
Mario Konschake
Director of Product-Data Platform
Soda has integrated seamlessly into our technology stack and given us the confidence to find, analyze, implement, and resolve data issues through a simple self-serve capability.
Sutaraj Dutta
Data Engineering Manager
Our goal was to deliver high-quality datasets in near real-time, ensuring dashboards reflect live data as it flows in. But beyond solving technical challenges, we wanted to spark a cultural shift - empowering the entire organization to make decisions grounded in accurate, timely data.
Gu Xie
Head of Data Engineering
4.4 of 5
Your data has problems.
Now they fix themselves.
Automated data quality, remediation, and management.
One platform, agents that do the work, you approve.
Trusted by
Solutions