A Practical Guide to Data Testing: Methods, Tools, and Best Practices
A Practical Guide to Data Testing: Methods, Tools, and Best Practices
A Practical Guide to Data Testing: Methods, Tools, and Best Practices

Kavita Rana
Kavita Rana
Technical Writer at Soda
Technical Writer at Soda
Table of Contents
You will not receive any warning sign for data quality issues. A value might be slightly off, a schema could change without notice, or a pipeline might run but produce stale results. By the time you notice, a report has already reached leadership or a model has been trained on incorrect data.
Data testing is the practice of verifying that your data meets defined quality standards before it reaches the people and systems that depend on it. Think of it as a continuous quality gate across your pipeline: catching issues at the source rather than discovering them after the fact.
The pressure is showing up at the top. A 2025 IBM Institute for Business Value report found that 43% of chief operations officers now identify data quality issues as their most significant data priority.
This guide covers everything you need to build a reliable data testing practice:
The core data testing methods and when to use them
How data validation works in practice
The data testing tools worth knowing
Best practices to help your team stay ahead of quality issues
Whether you're just starting to formalize your data quality process or looking to tighten up an existing one, you'll come away with a clear, practical framework you can start applying right away.
What is Data Testing?
Data testing is the process of validating data against defined criteria to confirm it behaves the way you expect. That means checking that values fall within acceptable ranges, that required fields aren't empty, that relationships between datasets hold up, and that the data arriving at the end of your pipeline matches what was intended at the start.
In practice, data testing spans the entire data lifecycle. You might run tests when data is ingested from a source system, after a transformation step, before a dashboard refreshes, or as part of a scheduled pipeline run. The goal is always the same: verify the data before it influences anything downstream.
Analytics reports are only as reliable as the data feeding them. Machine learning models trained on incomplete or inconsistent data produce flawed outputs, often in ways that are difficult to detect until real damage is done. And data-driven decisions, whether that's allocating budget, forecasting demand, or segmenting customers, depend on the assumption that the underlying data is accurate and complete. Data testing is what makes that assumption defensible.
Data validation is often used interchangeably with data testing, but they are not exactly the same. Validation is a subset of testing that focuses on checking whether data meets defined rules and formats at a specific point, such as confirming a field contains a valid date or falls within an accepted range. Data testing is the broader practice, covering validation as well as structural checks, transformation logic, pipeline integrity, and more. For a focused walkthrough of validation specifically, see our guide to data validation testing techniques.
Types of Data Testing
Data testing isn't one-size-fits-all. Different problems in a pipeline require different types of checks, and understanding the distinctions helps you build coverage that actually maps to how data moves and transforms in the real world.
Data Quality Checks
Data quality checks validate the content of your data against defined expectations. They answer the most fundamental question in data testing: is what's in this dataset actually correct?
This category covers:
Accuracy: Does the data reflect reality? A customer age of 400 or a negative order total points to a corruption or transformation error.
Completeness: Are required fields populated? Missing values in critical columns like
customer_idortransaction_datecan break downstream processes without any visible error.Consistency: Does the same metric report the same value across systems? Inconsistencies between a source database and a reporting table are a common and costly source of errors.
Uniqueness: Are there unexpected duplicates? A duplicate
order_idin a transactions table can distort revenue figures significantly.Validity: Does the data conform to defined formats and business rules? A date stored as plain text, a status field containing an unlisted value, or a price field returning a string are all validity failures — the data exists, but it isn't usable in its current form.
Timeliness: Is the data fresh enough to be useful? A pipeline that ran successfully but loaded data from six hours ago can be just as damaging as inaccurate data if your use case depends on current information.
These checks form the foundation of any data testing practice because they directly protect the outputs that business users depend on. For a deeper exploration of each, see our guide to the six data quality dimensions.
Structural Testing
Structural testing focuses on the physical structure of your datasets, including schemas, tables, columns, and data types, rather than the actual values. Even if the content is perfectly accurate, unexpected changes in structure can break downstream systems.
This includes:
Schema validation: Are all expected columns present, in the correct order, and with the correct data types?
Table-level checks: Do the expected tables exist? Have any been added, removed, or renamed?
Referential integrity: Do foreign keys resolve correctly across related tables?
Schema changes are one of the most frequent and least communicated causes of pipeline failures. Structural testing catches them before they propagate.
Functional Testing
Functional testing checks that your data processing logic works as intended. It focuses on how data changes as it moves through your pipeline, ensuring calculations are correct, business rules are applied properly, and CRUD operations (create, read, update, delete) produce the expected results.
Typical functional tests include:
Verifying that a revenue calculation produces the correct aggregated total after a transformation
Confirming that a deduplication step actually removes duplicate records rather than silently failing
Checking that filtering logic applied to a dataset excludes the right rows and retains the right ones
Functional testing is where your business logic gets validated. This layer ensures that your pipeline does more than just run and produces results that are correct according to the rules your organization has defined.
ETL and Migration Testing
ETL (extract, transform, load) testing and migration testing focus on what happens to data as it travels between systems. Whether you're running regular ETL jobs or executing a one-time migration to a new platform, these tests verify that data arrives at its destination intact and unchanged, where it should be unchanged.
Key checks in this category include:
Completeness: Did every record from the source arrive at the destination? Row counts before and after a load should match.
Transformation accuracy: Were the transformations applied correctly? A field that should be normalized, aggregated, or reformatted should reflect those changes accurately in the target system.
Data loss detection: Were any records silently dropped during extraction or load? Silent data loss is particularly dangerous because the pipeline appears to succeed while data is missing.
ETL and migration testing are especially critical during platform changes, cloud migrations, or any time data crosses a system boundary.
Data Testing Pyramid
The data testing pyramid is a practical mental model adapted from Mike Cohn's Testing Pyramid, a well-established concept in software engineering applied here to data pipelines.
The core principle holds: faster, cheaper tests should form the base of your suite, while broader, more expensive tests are used selectively.
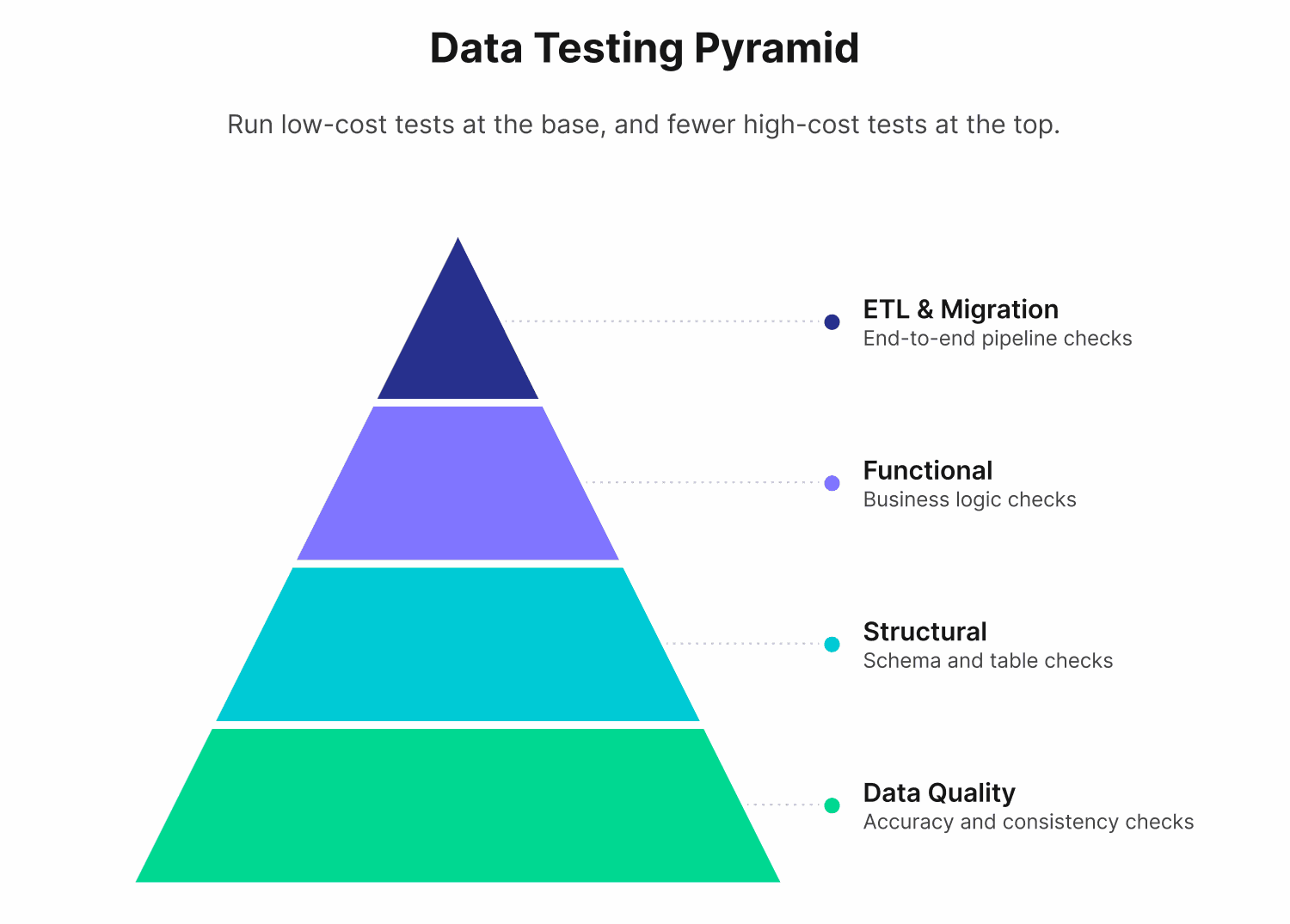
Data quality checks sit at the base because they run against individual fields and values. They are fast, targeted, and make up the largest share of a mature test suite. When one fails, you know exactly which column or metric to investigate.
Structural checks operate at the dataset level — a schema check examines an entire table at once, not just a single column. Even though that scope is wide, these checks stay cheap and fast to run, which is why they sit just above the most granular checks rather than higher up the pyramid.
Functional checks occupy the middle layer. They validate transformation logic and business rules, which means they need to run against processed data rather than raw inputs. They take longer to set up and require more domain knowledge to write well.
ETL and migration checks sit at the top. They span multiple systems and validate the full movement of data from source to destination. These are the most resource-intensive checks and are typically run after a load completes or during a migration project rather than on every pipeline run.
The pyramid shape isn't a rule about which tests matter more. All four categories are necessary. It reflects the practical reality that lower-layer tests give you faster feedback, are less expensive to maintain, and catch the majority of issues before they need broader validation.
Key Tools for Data Testing
The data testing tool landscape has matured considerably. Here's a breakdown of the most widely used options, organized by how teams typically use them.
dbt Tests: Built-In Validation for Transformation Workflows
dbt includes four built-in checks: not_null, unique, accepted_values, and relationships, each defined in YAML and executed as SQL against your models. They integrate naturally into CI/CD pipelines and work best as a first line of defense during the transformation layer. They are not designed for broad pipeline monitoring or cross-system validation, but within their scope, they are reliable and low-overhead.
Python-Based Data Validation Frameworks
Open-source Python validation libraries let teams define expectations about their data and validate datasets against those expectations at critical points in a pipeline. They work well for ingestion-point validation and offer flexibility for custom logic. The tradeoff is setup complexity. These frameworks typically require more engineering effort to configure and maintain compared to declarative, YAML-based alternatives, and most lack native support for data contracts or cross-system observability.
Soda Collaborative Data Contracts
A data contract is broader than quality checks, but its value only materializes when expectations are executable. Soda focuses on that executable layer.
Collaborative Data Contracts are similar to unit tests for testing software, fully executable and enforceable. They support versioning, CI integration, and coordinated evolution across producers and consumers.
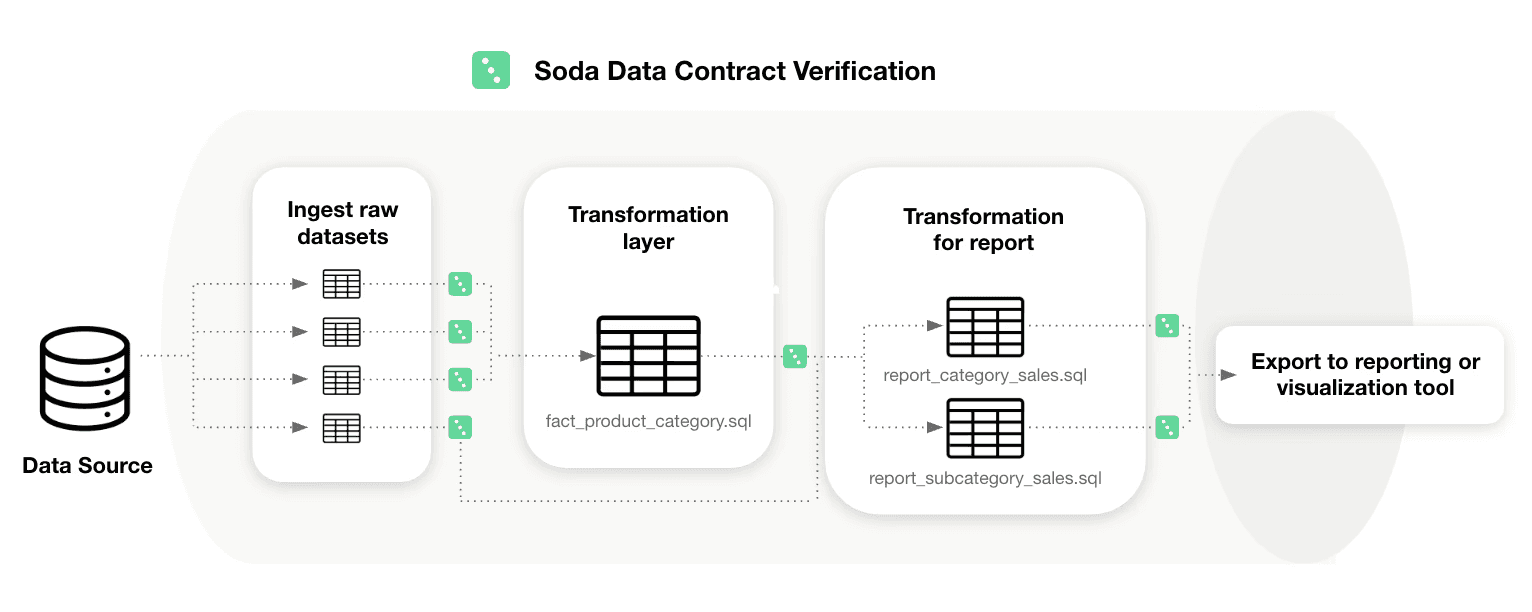
Also, in order to bridge the gap between technical and business users, Soda contracts can be authored, versioned, verified, and monitored in two complementary ways so they fit your team's workflow without friction:
Data Contracts as Code
Git-Managed Contracts offer a code-first way to define and enforce data quality expectations. Using Soda Core (Soda's open-source engine) and the Soda CLI, you can:
Define contracts in YAML using Soda contract language.
Perform contract verifications in CI/CD.
Push the contract and verification results into Soda Cloud for visibility.
Use Git as the source of truth for version control, collaboration, and review.
No-Code Data Contracts
Cloud-Managed Contracts lets you set and manage data expectations directly in the Soda Cloud UI. This approach is ideal for data analysts, product owners, and stakeholders who prefer intuitive interfaces over code. Without any setup or code required, the interface lets you:
Propose or add quality rules with a no-code editor
Publish contracts with a click
Schedule or run on-demand contract verifications
Collaborate with your team and request edits
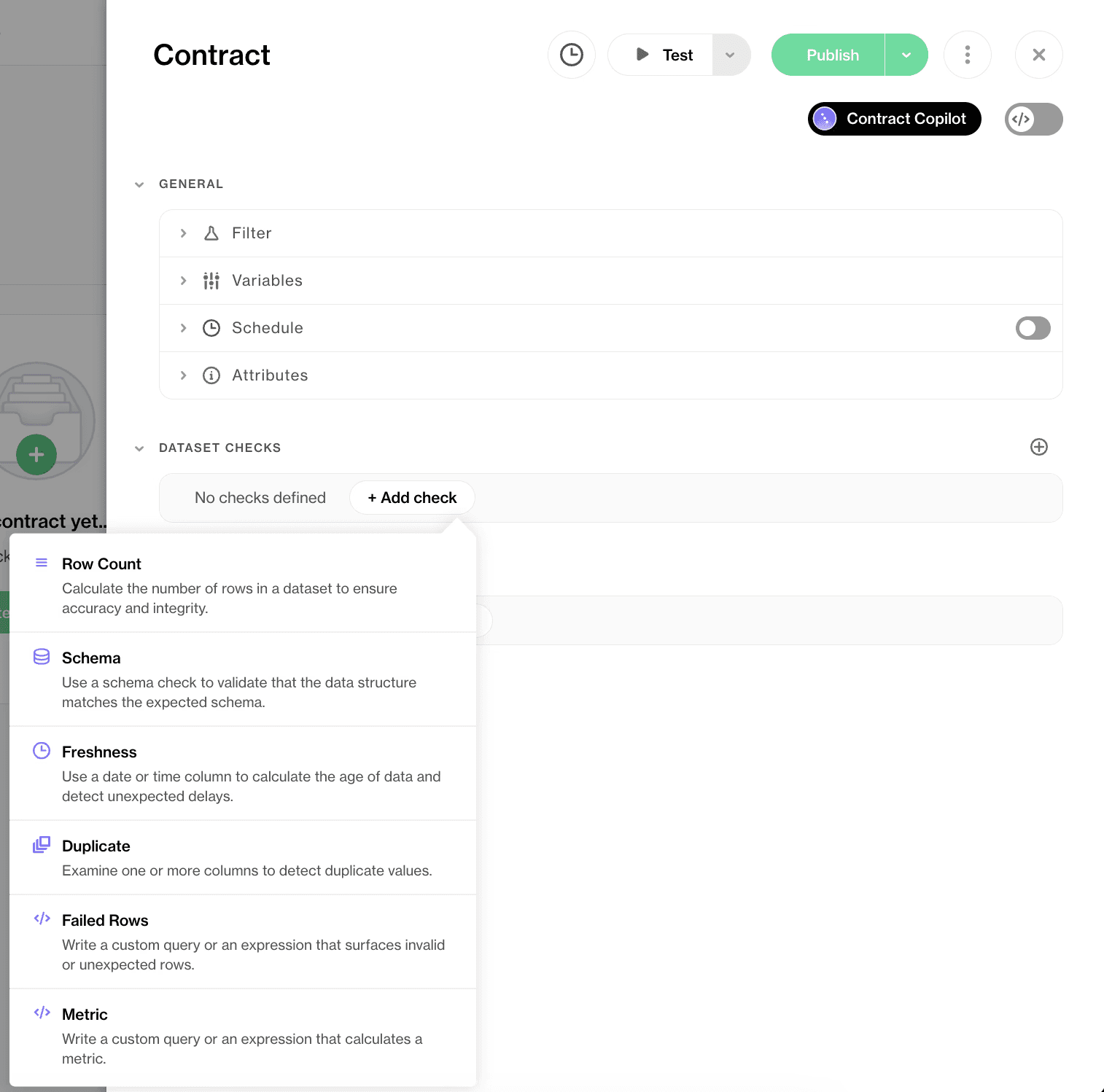
↗ Soda Cloud data contract UI with check builder for row count, schema, freshness, duplicate, failed rows, and metric checks.
All results from verifications will be stored and visualized in Soda Cloud. If a contract verification fails, notifications can be sent out, or new data can be stopped from being released to users.
Using YAML, or Soda UI, in just a few minutes, you can create checks that ensure:
Schema integrity
Data accuracy, completeness, and consistency
Freshness, availability, and latency
No Business Logic Violations
This hybrid approach allows collaboration across teams where business users bring domain expertise into the contract, while engineers ensure accuracy, consistency, and governance.
How to Automate Data Testing
Manual data testing doesn't scale. As pipelines grow, validating data by hand becomes inconsistent and slow. Traditional manual checks are time-consuming, vulnerable to human error, and unsuitable for modern, large-scale data processes.
Automation means your checks run on a defined schedule, after every pipeline run, or inside your CI/CD workflow, without manual intervention. You define the rules once, and the system enforces them every time data moves through your pipeline.
Soda's guide on implementing and enforcing data contracts walks through this end-to-end across the most common orchestration environments.
Integrating Soda Core Into Your Pipeline
Soda Core lets you embed checks at every pipeline stage to catch schema changes, volume changes, and quality issues after extraction, transformation, and before loading. Checks can be orchestrated natively in Airflow, Databricks, Prefect, and Dagster without data leaving your environment.
Running a scan is a single CLI command:
soda contract verify --data-source ds_config.yml --contract
Each check returns one of three states: pass, fail, or error, making results unambiguous.
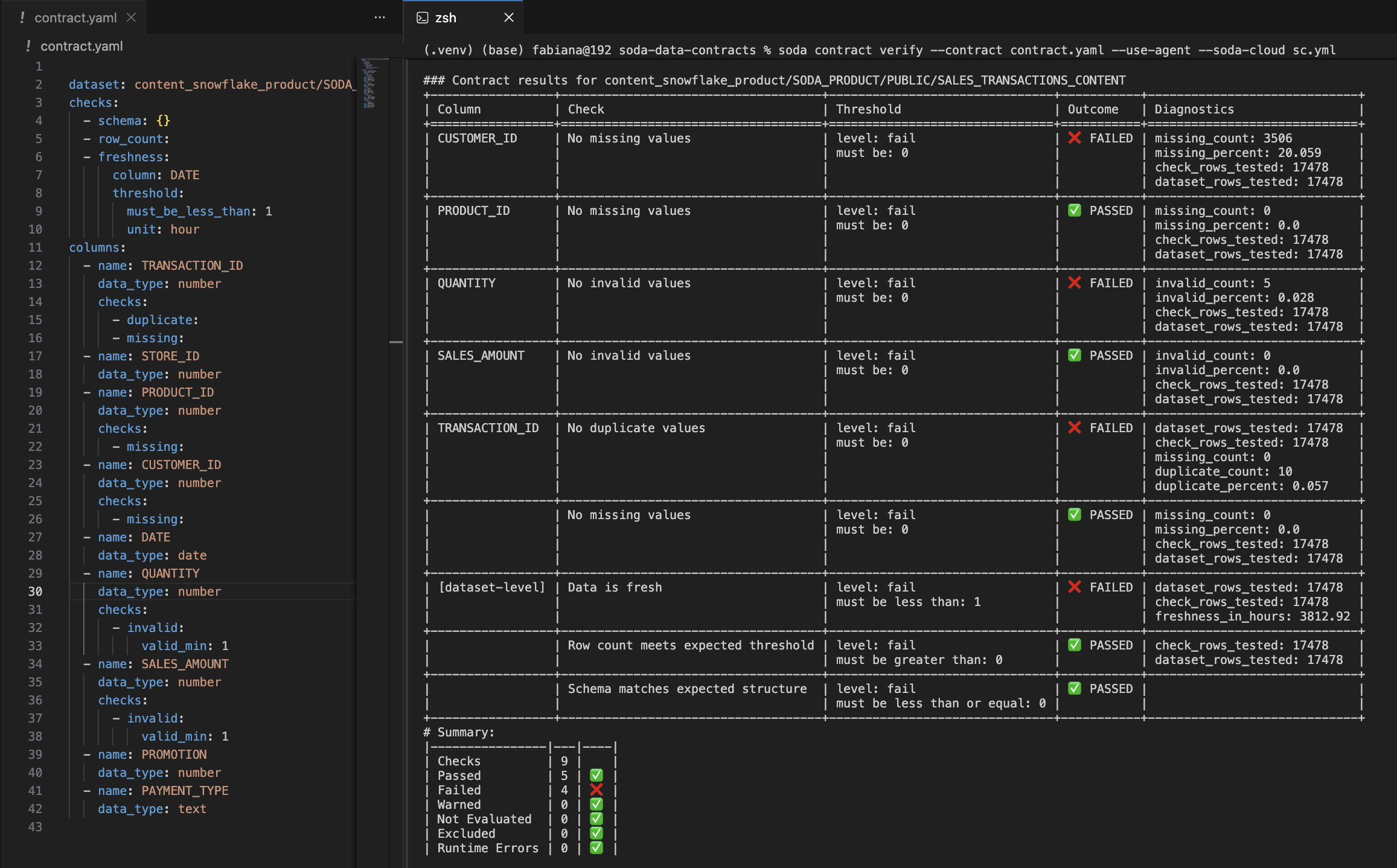
For Python-based pipelines, Soda Python API lets you embed testing directly in your pipeline code and halt execution if checks fail:
from soda_core.contracts import verify_contract_locally result = verify_contract_locally( data_source_file_path="ds_config.yml", contract_file_path="contract.yaml", publish=False, ) # Halt the pipeline if the contract did not pass if not result.is_ok: raise RuntimeError("Data contract verification failed")
Using Data Contracts as Automated Circuit Breakers
Soda lets you define explicit quality agreements between data producers and consumers and use them as circuit breakers, stopping pipelines when data fails to meet agreed specifications. Rather than letting bad data continue downstream, the pipeline stops at the point of failure, keeping issues contained and easier to resolve.
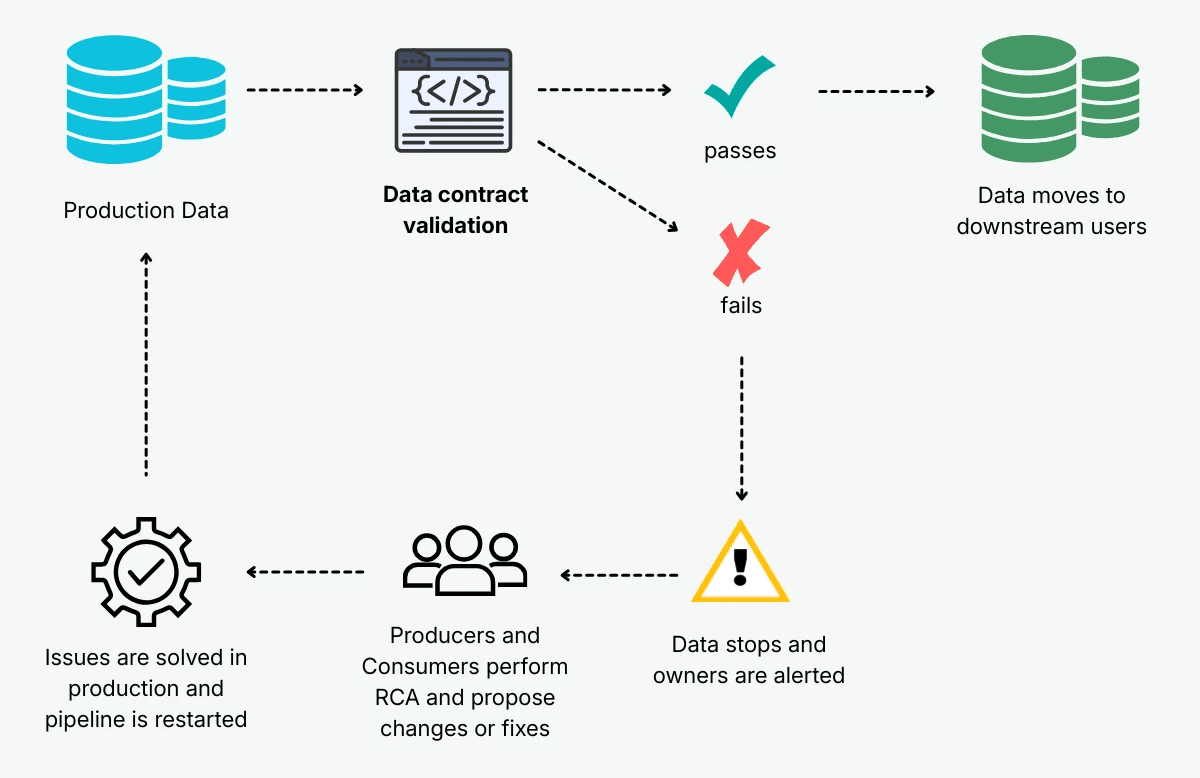
Best Practices in Data Testing
Strong data testing practices help teams detect issues early and maintain trust in data pipelines. The following approaches improve consistency, reliability, and long-term maintainability.
Start with your most critical data. Testing should focus on your most important data outcomes first. Start by defining what "good data" looks like for high-priority datasets, including expected row counts, required fields, valid value ranges, and acceptable freshness windows. A small set of well-maintained checks on critical data is more valuable than broad coverage that goes unmonitored.
Use reusable configuration files. A standard checklist ensures teams validate datasets consistently every time. Reusable YAML configuration files let you apply the same rules across multiple datasets and pipelines without duplicating effort. Typical checks include schema validation, null values, row counts, duplicates, and data freshness.
Make checks idempotent and re-run-safe. Pipelines retry, backfill, and replay. A test that passes on a fresh load but errors on a re-run — or one that flags late-arriving rows as missing before the next batch lands — trains teams to ignore alerts. Define freshness windows and row-count thresholds against expected arrival patterns, not against a single perfect run, so checks stay meaningful when data shows up late or a job runs twice.
Test early in the pipeline. Catching issues at ingestion or immediately after transformation is significantly less costly than finding them in a finished report. The further bad data travels before detection, the more systems and decisions it affects.
Collaborate across teams. Effective data testing requires input from both engineers and business stakeholders. Engineers understand pipelines and infrastructure; business users understand what the data should represent. Shared data contracts and governance workflows help ensure that testing reflects both technical requirements and business expectations.
Treat data contracts as living documents. As your data and business requirements evolve, so should your contracts. Review and update quality expectations regularly rather than setting them once and forgetting them.
When these practices are combined, data testing becomes more than a technical safeguard. It turns into a shared process for maintaining reliable, trustworthy data across the organization.
Measuring Success in Data Testing
Running tests is one thing. Knowing whether they're having a real impact on your data quality is another. Without a way to measure progress, it's difficult to justify investment in testing infrastructure or identify where your coverage needs to improve. These are the metrics worth tracking:
Test Pass Rate
This is the most direct signal of pipeline health. Track the percentage of checks that pass on each pipeline run and monitor how the number changes over time. A consistently high pass rate suggests stable and well-validated data. A declining rate often signals that something in the pipeline or an upstream source has changed. Tracking pass rate by dataset or pipeline stage, instead of as a single aggregate, also makes it easier to pinpoint where quality issues are concentrated.
Incident Rate
Measure the number of data quality incidents that reach downstream systems. These can include broken dashboards, incorrect reports, failed model inputs, or complaints from data consumers. This metric shows how much bad data is escaping your tests and creating real impact. As testing practices mature, the number should gradually decrease. If it does not, your tests may be missing key conditions or running at the wrong stages of the pipeline.
Mean Time to Detection (MTTD)
This metric measures how long it takes to detect a data quality issue after it occurs. A high MTTD means problems are moving far downstream before they are noticed, which increases the cost and effort required to resolve them. Automated testing at each pipeline stage significantly reduces detection time compared with manual or reactive approaches.
Schema Change Coverage
Track the percentage of datasets that have active schema checks in place. Schema changes are a common cause of silent data failures, yet they are also among the easiest issues to prevent with the right validation. Low coverage in this area is often a strong predictor of future incidents.
Compliance with Data Contracts
If your team uses data contracts to define expectations between data producers and consumers, track contract verification pass rates separately. A contract failure is more severe than a standard check failure. It signals that a formal agreement about data quality has been broken and that downstream consumers may already be affected.
Where to Go From Here
Data testing is not a one-time project. It's an ongoing practice that grows alongside your data infrastructure. The teams that get the most out of it are the ones that start small, build consistent habits, and expand coverage deliberately over time.
This guide maps the methods, tools, and practices of data testing; for the step-by-step framework of where each test runs inside an orchestrated pipeline, see a practical framework for testing data pipelines.
If you're ready to put this into practice, Soda's contract-based testing framework is a strong starting point. You can explore the documentation at docs.soda.io and find contract templates and examples at soda.io/templates. The first step is simply picking your most critical dataset, defining what good looks like, and running your first check.
Frequently Asked Questions
You will not receive any warning sign for data quality issues. A value might be slightly off, a schema could change without notice, or a pipeline might run but produce stale results. By the time you notice, a report has already reached leadership or a model has been trained on incorrect data.
Data testing is the practice of verifying that your data meets defined quality standards before it reaches the people and systems that depend on it. Think of it as a continuous quality gate across your pipeline: catching issues at the source rather than discovering them after the fact.
The pressure is showing up at the top. A 2025 IBM Institute for Business Value report found that 43% of chief operations officers now identify data quality issues as their most significant data priority.
This guide covers everything you need to build a reliable data testing practice:
The core data testing methods and when to use them
How data validation works in practice
The data testing tools worth knowing
Best practices to help your team stay ahead of quality issues
Whether you're just starting to formalize your data quality process or looking to tighten up an existing one, you'll come away with a clear, practical framework you can start applying right away.
What is Data Testing?
Data testing is the process of validating data against defined criteria to confirm it behaves the way you expect. That means checking that values fall within acceptable ranges, that required fields aren't empty, that relationships between datasets hold up, and that the data arriving at the end of your pipeline matches what was intended at the start.
In practice, data testing spans the entire data lifecycle. You might run tests when data is ingested from a source system, after a transformation step, before a dashboard refreshes, or as part of a scheduled pipeline run. The goal is always the same: verify the data before it influences anything downstream.
Analytics reports are only as reliable as the data feeding them. Machine learning models trained on incomplete or inconsistent data produce flawed outputs, often in ways that are difficult to detect until real damage is done. And data-driven decisions, whether that's allocating budget, forecasting demand, or segmenting customers, depend on the assumption that the underlying data is accurate and complete. Data testing is what makes that assumption defensible.
Data validation is often used interchangeably with data testing, but they are not exactly the same. Validation is a subset of testing that focuses on checking whether data meets defined rules and formats at a specific point, such as confirming a field contains a valid date or falls within an accepted range. Data testing is the broader practice, covering validation as well as structural checks, transformation logic, pipeline integrity, and more. For a focused walkthrough of validation specifically, see our guide to data validation testing techniques.
Types of Data Testing
Data testing isn't one-size-fits-all. Different problems in a pipeline require different types of checks, and understanding the distinctions helps you build coverage that actually maps to how data moves and transforms in the real world.
Data Quality Checks
Data quality checks validate the content of your data against defined expectations. They answer the most fundamental question in data testing: is what's in this dataset actually correct?
This category covers:
Accuracy: Does the data reflect reality? A customer age of 400 or a negative order total points to a corruption or transformation error.
Completeness: Are required fields populated? Missing values in critical columns like
customer_idortransaction_datecan break downstream processes without any visible error.Consistency: Does the same metric report the same value across systems? Inconsistencies between a source database and a reporting table are a common and costly source of errors.
Uniqueness: Are there unexpected duplicates? A duplicate
order_idin a transactions table can distort revenue figures significantly.Validity: Does the data conform to defined formats and business rules? A date stored as plain text, a status field containing an unlisted value, or a price field returning a string are all validity failures — the data exists, but it isn't usable in its current form.
Timeliness: Is the data fresh enough to be useful? A pipeline that ran successfully but loaded data from six hours ago can be just as damaging as inaccurate data if your use case depends on current information.
These checks form the foundation of any data testing practice because they directly protect the outputs that business users depend on. For a deeper exploration of each, see our guide to the six data quality dimensions.
Structural Testing
Structural testing focuses on the physical structure of your datasets, including schemas, tables, columns, and data types, rather than the actual values. Even if the content is perfectly accurate, unexpected changes in structure can break downstream systems.
This includes:
Schema validation: Are all expected columns present, in the correct order, and with the correct data types?
Table-level checks: Do the expected tables exist? Have any been added, removed, or renamed?
Referential integrity: Do foreign keys resolve correctly across related tables?
Schema changes are one of the most frequent and least communicated causes of pipeline failures. Structural testing catches them before they propagate.
Functional Testing
Functional testing checks that your data processing logic works as intended. It focuses on how data changes as it moves through your pipeline, ensuring calculations are correct, business rules are applied properly, and CRUD operations (create, read, update, delete) produce the expected results.
Typical functional tests include:
Verifying that a revenue calculation produces the correct aggregated total after a transformation
Confirming that a deduplication step actually removes duplicate records rather than silently failing
Checking that filtering logic applied to a dataset excludes the right rows and retains the right ones
Functional testing is where your business logic gets validated. This layer ensures that your pipeline does more than just run and produces results that are correct according to the rules your organization has defined.
ETL and Migration Testing
ETL (extract, transform, load) testing and migration testing focus on what happens to data as it travels between systems. Whether you're running regular ETL jobs or executing a one-time migration to a new platform, these tests verify that data arrives at its destination intact and unchanged, where it should be unchanged.
Key checks in this category include:
Completeness: Did every record from the source arrive at the destination? Row counts before and after a load should match.
Transformation accuracy: Were the transformations applied correctly? A field that should be normalized, aggregated, or reformatted should reflect those changes accurately in the target system.
Data loss detection: Were any records silently dropped during extraction or load? Silent data loss is particularly dangerous because the pipeline appears to succeed while data is missing.
ETL and migration testing are especially critical during platform changes, cloud migrations, or any time data crosses a system boundary.
Data Testing Pyramid
The data testing pyramid is a practical mental model adapted from Mike Cohn's Testing Pyramid, a well-established concept in software engineering applied here to data pipelines.
The core principle holds: faster, cheaper tests should form the base of your suite, while broader, more expensive tests are used selectively.
Data quality checks sit at the base because they run against individual fields and values. They are fast, targeted, and make up the largest share of a mature test suite. When one fails, you know exactly which column or metric to investigate.
Structural checks operate at the dataset level — a schema check examines an entire table at once, not just a single column. Even though that scope is wide, these checks stay cheap and fast to run, which is why they sit just above the most granular checks rather than higher up the pyramid.
Functional checks occupy the middle layer. They validate transformation logic and business rules, which means they need to run against processed data rather than raw inputs. They take longer to set up and require more domain knowledge to write well.
ETL and migration checks sit at the top. They span multiple systems and validate the full movement of data from source to destination. These are the most resource-intensive checks and are typically run after a load completes or during a migration project rather than on every pipeline run.
The pyramid shape isn't a rule about which tests matter more. All four categories are necessary. It reflects the practical reality that lower-layer tests give you faster feedback, are less expensive to maintain, and catch the majority of issues before they need broader validation.
Key Tools for Data Testing
The data testing tool landscape has matured considerably. Here's a breakdown of the most widely used options, organized by how teams typically use them.
dbt Tests: Built-In Validation for Transformation Workflows
dbt includes four built-in checks: not_null, unique, accepted_values, and relationships, each defined in YAML and executed as SQL against your models. They integrate naturally into CI/CD pipelines and work best as a first line of defense during the transformation layer. They are not designed for broad pipeline monitoring or cross-system validation, but within their scope, they are reliable and low-overhead.
Python-Based Data Validation Frameworks
Open-source Python validation libraries let teams define expectations about their data and validate datasets against those expectations at critical points in a pipeline. They work well for ingestion-point validation and offer flexibility for custom logic. The tradeoff is setup complexity. These frameworks typically require more engineering effort to configure and maintain compared to declarative, YAML-based alternatives, and most lack native support for data contracts or cross-system observability.
Soda Collaborative Data Contracts
A data contract is broader than quality checks, but its value only materializes when expectations are executable. Soda focuses on that executable layer.
Collaborative Data Contracts are similar to unit tests for testing software, fully executable and enforceable. They support versioning, CI integration, and coordinated evolution across producers and consumers.
Also, in order to bridge the gap between technical and business users, Soda contracts can be authored, versioned, verified, and monitored in two complementary ways so they fit your team's workflow without friction:
Data Contracts as Code
Git-Managed Contracts offer a code-first way to define and enforce data quality expectations. Using Soda Core (Soda's open-source engine) and the Soda CLI, you can:
Define contracts in YAML using Soda contract language.
Perform contract verifications in CI/CD.
Push the contract and verification results into Soda Cloud for visibility.
Use Git as the source of truth for version control, collaboration, and review.
No-Code Data Contracts
Cloud-Managed Contracts lets you set and manage data expectations directly in the Soda Cloud UI. This approach is ideal for data analysts, product owners, and stakeholders who prefer intuitive interfaces over code. Without any setup or code required, the interface lets you:
Propose or add quality rules with a no-code editor
Publish contracts with a click
Schedule or run on-demand contract verifications
Collaborate with your team and request edits
↗ Soda Cloud data contract UI with check builder for row count, schema, freshness, duplicate, failed rows, and metric checks.
All results from verifications will be stored and visualized in Soda Cloud. If a contract verification fails, notifications can be sent out, or new data can be stopped from being released to users.
Using YAML, or Soda UI, in just a few minutes, you can create checks that ensure:
Schema integrity
Data accuracy, completeness, and consistency
Freshness, availability, and latency
No Business Logic Violations
This hybrid approach allows collaboration across teams where business users bring domain expertise into the contract, while engineers ensure accuracy, consistency, and governance.
How to Automate Data Testing
Manual data testing doesn't scale. As pipelines grow, validating data by hand becomes inconsistent and slow. Traditional manual checks are time-consuming, vulnerable to human error, and unsuitable for modern, large-scale data processes.
Automation means your checks run on a defined schedule, after every pipeline run, or inside your CI/CD workflow, without manual intervention. You define the rules once, and the system enforces them every time data moves through your pipeline.
Soda's guide on implementing and enforcing data contracts walks through this end-to-end across the most common orchestration environments.
Integrating Soda Core Into Your Pipeline
Soda Core lets you embed checks at every pipeline stage to catch schema changes, volume changes, and quality issues after extraction, transformation, and before loading. Checks can be orchestrated natively in Airflow, Databricks, Prefect, and Dagster without data leaving your environment.
Running a scan is a single CLI command:
soda contract verify --data-source ds_config.yml --contract
Each check returns one of three states: pass, fail, or error, making results unambiguous.
For Python-based pipelines, Soda Python API lets you embed testing directly in your pipeline code and halt execution if checks fail:
from soda_core.contracts import verify_contract_locally result = verify_contract_locally( data_source_file_path="ds_config.yml", contract_file_path="contract.yaml", publish=False, ) # Halt the pipeline if the contract did not pass if not result.is_ok: raise RuntimeError("Data contract verification failed")
Using Data Contracts as Automated Circuit Breakers
Soda lets you define explicit quality agreements between data producers and consumers and use them as circuit breakers, stopping pipelines when data fails to meet agreed specifications. Rather than letting bad data continue downstream, the pipeline stops at the point of failure, keeping issues contained and easier to resolve.
Best Practices in Data Testing
Strong data testing practices help teams detect issues early and maintain trust in data pipelines. The following approaches improve consistency, reliability, and long-term maintainability.
Start with your most critical data. Testing should focus on your most important data outcomes first. Start by defining what "good data" looks like for high-priority datasets, including expected row counts, required fields, valid value ranges, and acceptable freshness windows. A small set of well-maintained checks on critical data is more valuable than broad coverage that goes unmonitored.
Use reusable configuration files. A standard checklist ensures teams validate datasets consistently every time. Reusable YAML configuration files let you apply the same rules across multiple datasets and pipelines without duplicating effort. Typical checks include schema validation, null values, row counts, duplicates, and data freshness.
Make checks idempotent and re-run-safe. Pipelines retry, backfill, and replay. A test that passes on a fresh load but errors on a re-run — or one that flags late-arriving rows as missing before the next batch lands — trains teams to ignore alerts. Define freshness windows and row-count thresholds against expected arrival patterns, not against a single perfect run, so checks stay meaningful when data shows up late or a job runs twice.
Test early in the pipeline. Catching issues at ingestion or immediately after transformation is significantly less costly than finding them in a finished report. The further bad data travels before detection, the more systems and decisions it affects.
Collaborate across teams. Effective data testing requires input from both engineers and business stakeholders. Engineers understand pipelines and infrastructure; business users understand what the data should represent. Shared data contracts and governance workflows help ensure that testing reflects both technical requirements and business expectations.
Treat data contracts as living documents. As your data and business requirements evolve, so should your contracts. Review and update quality expectations regularly rather than setting them once and forgetting them.
When these practices are combined, data testing becomes more than a technical safeguard. It turns into a shared process for maintaining reliable, trustworthy data across the organization.
Measuring Success in Data Testing
Running tests is one thing. Knowing whether they're having a real impact on your data quality is another. Without a way to measure progress, it's difficult to justify investment in testing infrastructure or identify where your coverage needs to improve. These are the metrics worth tracking:
Test Pass Rate
This is the most direct signal of pipeline health. Track the percentage of checks that pass on each pipeline run and monitor how the number changes over time. A consistently high pass rate suggests stable and well-validated data. A declining rate often signals that something in the pipeline or an upstream source has changed. Tracking pass rate by dataset or pipeline stage, instead of as a single aggregate, also makes it easier to pinpoint where quality issues are concentrated.
Incident Rate
Measure the number of data quality incidents that reach downstream systems. These can include broken dashboards, incorrect reports, failed model inputs, or complaints from data consumers. This metric shows how much bad data is escaping your tests and creating real impact. As testing practices mature, the number should gradually decrease. If it does not, your tests may be missing key conditions or running at the wrong stages of the pipeline.
Mean Time to Detection (MTTD)
This metric measures how long it takes to detect a data quality issue after it occurs. A high MTTD means problems are moving far downstream before they are noticed, which increases the cost and effort required to resolve them. Automated testing at each pipeline stage significantly reduces detection time compared with manual or reactive approaches.
Schema Change Coverage
Track the percentage of datasets that have active schema checks in place. Schema changes are a common cause of silent data failures, yet they are also among the easiest issues to prevent with the right validation. Low coverage in this area is often a strong predictor of future incidents.
Compliance with Data Contracts
If your team uses data contracts to define expectations between data producers and consumers, track contract verification pass rates separately. A contract failure is more severe than a standard check failure. It signals that a formal agreement about data quality has been broken and that downstream consumers may already be affected.
Where to Go From Here
Data testing is not a one-time project. It's an ongoing practice that grows alongside your data infrastructure. The teams that get the most out of it are the ones that start small, build consistent habits, and expand coverage deliberately over time.
This guide maps the methods, tools, and practices of data testing; for the step-by-step framework of where each test runs inside an orchestrated pipeline, see a practical framework for testing data pipelines.
If you're ready to put this into practice, Soda's contract-based testing framework is a strong starting point. You can explore the documentation at docs.soda.io and find contract templates and examples at soda.io/templates. The first step is simply picking your most critical dataset, defining what good looks like, and running your first check.
Frequently Asked Questions
You will not receive any warning sign for data quality issues. A value might be slightly off, a schema could change without notice, or a pipeline might run but produce stale results. By the time you notice, a report has already reached leadership or a model has been trained on incorrect data.
Data testing is the practice of verifying that your data meets defined quality standards before it reaches the people and systems that depend on it. Think of it as a continuous quality gate across your pipeline: catching issues at the source rather than discovering them after the fact.
The pressure is showing up at the top. A 2025 IBM Institute for Business Value report found that 43% of chief operations officers now identify data quality issues as their most significant data priority.
This guide covers everything you need to build a reliable data testing practice:
The core data testing methods and when to use them
How data validation works in practice
The data testing tools worth knowing
Best practices to help your team stay ahead of quality issues
Whether you're just starting to formalize your data quality process or looking to tighten up an existing one, you'll come away with a clear, practical framework you can start applying right away.
What is Data Testing?
Data testing is the process of validating data against defined criteria to confirm it behaves the way you expect. That means checking that values fall within acceptable ranges, that required fields aren't empty, that relationships between datasets hold up, and that the data arriving at the end of your pipeline matches what was intended at the start.
In practice, data testing spans the entire data lifecycle. You might run tests when data is ingested from a source system, after a transformation step, before a dashboard refreshes, or as part of a scheduled pipeline run. The goal is always the same: verify the data before it influences anything downstream.
Analytics reports are only as reliable as the data feeding them. Machine learning models trained on incomplete or inconsistent data produce flawed outputs, often in ways that are difficult to detect until real damage is done. And data-driven decisions, whether that's allocating budget, forecasting demand, or segmenting customers, depend on the assumption that the underlying data is accurate and complete. Data testing is what makes that assumption defensible.
Data validation is often used interchangeably with data testing, but they are not exactly the same. Validation is a subset of testing that focuses on checking whether data meets defined rules and formats at a specific point, such as confirming a field contains a valid date or falls within an accepted range. Data testing is the broader practice, covering validation as well as structural checks, transformation logic, pipeline integrity, and more. For a focused walkthrough of validation specifically, see our guide to data validation testing techniques.
Types of Data Testing
Data testing isn't one-size-fits-all. Different problems in a pipeline require different types of checks, and understanding the distinctions helps you build coverage that actually maps to how data moves and transforms in the real world.
Data Quality Checks
Data quality checks validate the content of your data against defined expectations. They answer the most fundamental question in data testing: is what's in this dataset actually correct?
This category covers:
Accuracy: Does the data reflect reality? A customer age of 400 or a negative order total points to a corruption or transformation error.
Completeness: Are required fields populated? Missing values in critical columns like
customer_idortransaction_datecan break downstream processes without any visible error.Consistency: Does the same metric report the same value across systems? Inconsistencies between a source database and a reporting table are a common and costly source of errors.
Uniqueness: Are there unexpected duplicates? A duplicate
order_idin a transactions table can distort revenue figures significantly.Validity: Does the data conform to defined formats and business rules? A date stored as plain text, a status field containing an unlisted value, or a price field returning a string are all validity failures — the data exists, but it isn't usable in its current form.
Timeliness: Is the data fresh enough to be useful? A pipeline that ran successfully but loaded data from six hours ago can be just as damaging as inaccurate data if your use case depends on current information.
These checks form the foundation of any data testing practice because they directly protect the outputs that business users depend on. For a deeper exploration of each, see our guide to the six data quality dimensions.
Structural Testing
Structural testing focuses on the physical structure of your datasets, including schemas, tables, columns, and data types, rather than the actual values. Even if the content is perfectly accurate, unexpected changes in structure can break downstream systems.
This includes:
Schema validation: Are all expected columns present, in the correct order, and with the correct data types?
Table-level checks: Do the expected tables exist? Have any been added, removed, or renamed?
Referential integrity: Do foreign keys resolve correctly across related tables?
Schema changes are one of the most frequent and least communicated causes of pipeline failures. Structural testing catches them before they propagate.
Functional Testing
Functional testing checks that your data processing logic works as intended. It focuses on how data changes as it moves through your pipeline, ensuring calculations are correct, business rules are applied properly, and CRUD operations (create, read, update, delete) produce the expected results.
Typical functional tests include:
Verifying that a revenue calculation produces the correct aggregated total after a transformation
Confirming that a deduplication step actually removes duplicate records rather than silently failing
Checking that filtering logic applied to a dataset excludes the right rows and retains the right ones
Functional testing is where your business logic gets validated. This layer ensures that your pipeline does more than just run and produces results that are correct according to the rules your organization has defined.
ETL and Migration Testing
ETL (extract, transform, load) testing and migration testing focus on what happens to data as it travels between systems. Whether you're running regular ETL jobs or executing a one-time migration to a new platform, these tests verify that data arrives at its destination intact and unchanged, where it should be unchanged.
Key checks in this category include:
Completeness: Did every record from the source arrive at the destination? Row counts before and after a load should match.
Transformation accuracy: Were the transformations applied correctly? A field that should be normalized, aggregated, or reformatted should reflect those changes accurately in the target system.
Data loss detection: Were any records silently dropped during extraction or load? Silent data loss is particularly dangerous because the pipeline appears to succeed while data is missing.
ETL and migration testing are especially critical during platform changes, cloud migrations, or any time data crosses a system boundary.
Data Testing Pyramid
The data testing pyramid is a practical mental model adapted from Mike Cohn's Testing Pyramid, a well-established concept in software engineering applied here to data pipelines.
The core principle holds: faster, cheaper tests should form the base of your suite, while broader, more expensive tests are used selectively.
Data quality checks sit at the base because they run against individual fields and values. They are fast, targeted, and make up the largest share of a mature test suite. When one fails, you know exactly which column or metric to investigate.
Structural checks operate at the dataset level — a schema check examines an entire table at once, not just a single column. Even though that scope is wide, these checks stay cheap and fast to run, which is why they sit just above the most granular checks rather than higher up the pyramid.
Functional checks occupy the middle layer. They validate transformation logic and business rules, which means they need to run against processed data rather than raw inputs. They take longer to set up and require more domain knowledge to write well.
ETL and migration checks sit at the top. They span multiple systems and validate the full movement of data from source to destination. These are the most resource-intensive checks and are typically run after a load completes or during a migration project rather than on every pipeline run.
The pyramid shape isn't a rule about which tests matter more. All four categories are necessary. It reflects the practical reality that lower-layer tests give you faster feedback, are less expensive to maintain, and catch the majority of issues before they need broader validation.
Key Tools for Data Testing
The data testing tool landscape has matured considerably. Here's a breakdown of the most widely used options, organized by how teams typically use them.
dbt Tests: Built-In Validation for Transformation Workflows
dbt includes four built-in checks: not_null, unique, accepted_values, and relationships, each defined in YAML and executed as SQL against your models. They integrate naturally into CI/CD pipelines and work best as a first line of defense during the transformation layer. They are not designed for broad pipeline monitoring or cross-system validation, but within their scope, they are reliable and low-overhead.
Python-Based Data Validation Frameworks
Open-source Python validation libraries let teams define expectations about their data and validate datasets against those expectations at critical points in a pipeline. They work well for ingestion-point validation and offer flexibility for custom logic. The tradeoff is setup complexity. These frameworks typically require more engineering effort to configure and maintain compared to declarative, YAML-based alternatives, and most lack native support for data contracts or cross-system observability.
Soda Collaborative Data Contracts
A data contract is broader than quality checks, but its value only materializes when expectations are executable. Soda focuses on that executable layer.
Collaborative Data Contracts are similar to unit tests for testing software, fully executable and enforceable. They support versioning, CI integration, and coordinated evolution across producers and consumers.
Also, in order to bridge the gap between technical and business users, Soda contracts can be authored, versioned, verified, and monitored in two complementary ways so they fit your team's workflow without friction:
Data Contracts as Code
Git-Managed Contracts offer a code-first way to define and enforce data quality expectations. Using Soda Core (Soda's open-source engine) and the Soda CLI, you can:
Define contracts in YAML using Soda contract language.
Perform contract verifications in CI/CD.
Push the contract and verification results into Soda Cloud for visibility.
Use Git as the source of truth for version control, collaboration, and review.
No-Code Data Contracts
Cloud-Managed Contracts lets you set and manage data expectations directly in the Soda Cloud UI. This approach is ideal for data analysts, product owners, and stakeholders who prefer intuitive interfaces over code. Without any setup or code required, the interface lets you:
Propose or add quality rules with a no-code editor
Publish contracts with a click
Schedule or run on-demand contract verifications
Collaborate with your team and request edits
↗ Soda Cloud data contract UI with check builder for row count, schema, freshness, duplicate, failed rows, and metric checks.
All results from verifications will be stored and visualized in Soda Cloud. If a contract verification fails, notifications can be sent out, or new data can be stopped from being released to users.
Using YAML, or Soda UI, in just a few minutes, you can create checks that ensure:
Schema integrity
Data accuracy, completeness, and consistency
Freshness, availability, and latency
No Business Logic Violations
This hybrid approach allows collaboration across teams where business users bring domain expertise into the contract, while engineers ensure accuracy, consistency, and governance.
How to Automate Data Testing
Manual data testing doesn't scale. As pipelines grow, validating data by hand becomes inconsistent and slow. Traditional manual checks are time-consuming, vulnerable to human error, and unsuitable for modern, large-scale data processes.
Automation means your checks run on a defined schedule, after every pipeline run, or inside your CI/CD workflow, without manual intervention. You define the rules once, and the system enforces them every time data moves through your pipeline.
Soda's guide on implementing and enforcing data contracts walks through this end-to-end across the most common orchestration environments.
Integrating Soda Core Into Your Pipeline
Soda Core lets you embed checks at every pipeline stage to catch schema changes, volume changes, and quality issues after extraction, transformation, and before loading. Checks can be orchestrated natively in Airflow, Databricks, Prefect, and Dagster without data leaving your environment.
Running a scan is a single CLI command:
soda contract verify --data-source ds_config.yml --contract
Each check returns one of three states: pass, fail, or error, making results unambiguous.
For Python-based pipelines, Soda Python API lets you embed testing directly in your pipeline code and halt execution if checks fail:
from soda_core.contracts import verify_contract_locally result = verify_contract_locally( data_source_file_path="ds_config.yml", contract_file_path="contract.yaml", publish=False, ) # Halt the pipeline if the contract did not pass if not result.is_ok: raise RuntimeError("Data contract verification failed")
Using Data Contracts as Automated Circuit Breakers
Soda lets you define explicit quality agreements between data producers and consumers and use them as circuit breakers, stopping pipelines when data fails to meet agreed specifications. Rather than letting bad data continue downstream, the pipeline stops at the point of failure, keeping issues contained and easier to resolve.
Best Practices in Data Testing
Strong data testing practices help teams detect issues early and maintain trust in data pipelines. The following approaches improve consistency, reliability, and long-term maintainability.
Start with your most critical data. Testing should focus on your most important data outcomes first. Start by defining what "good data" looks like for high-priority datasets, including expected row counts, required fields, valid value ranges, and acceptable freshness windows. A small set of well-maintained checks on critical data is more valuable than broad coverage that goes unmonitored.
Use reusable configuration files. A standard checklist ensures teams validate datasets consistently every time. Reusable YAML configuration files let you apply the same rules across multiple datasets and pipelines without duplicating effort. Typical checks include schema validation, null values, row counts, duplicates, and data freshness.
Make checks idempotent and re-run-safe. Pipelines retry, backfill, and replay. A test that passes on a fresh load but errors on a re-run — or one that flags late-arriving rows as missing before the next batch lands — trains teams to ignore alerts. Define freshness windows and row-count thresholds against expected arrival patterns, not against a single perfect run, so checks stay meaningful when data shows up late or a job runs twice.
Test early in the pipeline. Catching issues at ingestion or immediately after transformation is significantly less costly than finding them in a finished report. The further bad data travels before detection, the more systems and decisions it affects.
Collaborate across teams. Effective data testing requires input from both engineers and business stakeholders. Engineers understand pipelines and infrastructure; business users understand what the data should represent. Shared data contracts and governance workflows help ensure that testing reflects both technical requirements and business expectations.
Treat data contracts as living documents. As your data and business requirements evolve, so should your contracts. Review and update quality expectations regularly rather than setting them once and forgetting them.
When these practices are combined, data testing becomes more than a technical safeguard. It turns into a shared process for maintaining reliable, trustworthy data across the organization.
Measuring Success in Data Testing
Running tests is one thing. Knowing whether they're having a real impact on your data quality is another. Without a way to measure progress, it's difficult to justify investment in testing infrastructure or identify where your coverage needs to improve. These are the metrics worth tracking:
Test Pass Rate
This is the most direct signal of pipeline health. Track the percentage of checks that pass on each pipeline run and monitor how the number changes over time. A consistently high pass rate suggests stable and well-validated data. A declining rate often signals that something in the pipeline or an upstream source has changed. Tracking pass rate by dataset or pipeline stage, instead of as a single aggregate, also makes it easier to pinpoint where quality issues are concentrated.
Incident Rate
Measure the number of data quality incidents that reach downstream systems. These can include broken dashboards, incorrect reports, failed model inputs, or complaints from data consumers. This metric shows how much bad data is escaping your tests and creating real impact. As testing practices mature, the number should gradually decrease. If it does not, your tests may be missing key conditions or running at the wrong stages of the pipeline.
Mean Time to Detection (MTTD)
This metric measures how long it takes to detect a data quality issue after it occurs. A high MTTD means problems are moving far downstream before they are noticed, which increases the cost and effort required to resolve them. Automated testing at each pipeline stage significantly reduces detection time compared with manual or reactive approaches.
Schema Change Coverage
Track the percentage of datasets that have active schema checks in place. Schema changes are a common cause of silent data failures, yet they are also among the easiest issues to prevent with the right validation. Low coverage in this area is often a strong predictor of future incidents.
Compliance with Data Contracts
If your team uses data contracts to define expectations between data producers and consumers, track contract verification pass rates separately. A contract failure is more severe than a standard check failure. It signals that a formal agreement about data quality has been broken and that downstream consumers may already be affected.
Where to Go From Here
Data testing is not a one-time project. It's an ongoing practice that grows alongside your data infrastructure. The teams that get the most out of it are the ones that start small, build consistent habits, and expand coverage deliberately over time.
This guide maps the methods, tools, and practices of data testing; for the step-by-step framework of where each test runs inside an orchestrated pipeline, see a practical framework for testing data pipelines.
If you're ready to put this into practice, Soda's contract-based testing framework is a strong starting point. You can explore the documentation at docs.soda.io and find contract templates and examples at soda.io/templates. The first step is simply picking your most critical dataset, defining what good looks like, and running your first check.
Frequently Asked Questions
What are the key challenges in data testing?
The main challenges are scale, visibility, and ownership. Growing pipelines make manual checks impractical, while upstream schema changes often break downstream processes silently. Unclear ownership allows issues to persist. Technical problems are largely solvable with the right tools; organizational challenges require defined ownership and shared standards between data producers and consumers.
Can data testing be fully automated?
Most routine checks like row counts, null values, duplicates, schema validation and freshness, can run automatically without human intervention. However, human judgment is still needed to define thresholds, write business rules, and decide which failures should halt a pipeline versus trigger an alert. The goal is freeing your team to focus on exceptions that matter.
How do I get started with data testing in a large organization?
Start with your most critical datasets: those powering executive dashboards, financial reports, or ML models. Define what good data looks like; row counts, required fields, valid ranges, freshness windows, then automate those checks. Avoid building a full framework immediately. A small set of well-maintained checks on high-priority data beats broad, unmonitored coverage every time.
What's the difference between data testing and data observability?
Data testing validates data against predefined rules at specific points in a pipeline. Data observability continuously monitors pipeline health; tracking anomalies, lineage, and trends without requiring explicit rules upfront. They're complementary: testing enforces known expectations, observability surfaces unknown issues. Mature data teams typically use both together rather than choosing one over the other.
How often should data tests be updated?
Tests should be reviewed whenever business logic changes, a source system is updated, or a new use case depends on the data. At minimum, revisit your test suite quarterly. Stale checks, ones that no longer reflect current requirements, can pass while masking real problems, which is often worse than having no test at all.
Trusted by the world’s leading enterprises
Real stories from companies using Soda to keep their data reliable, accurate, and ready for action.
At the end of the day, we don’t want to be in there managing the checks, updating the checks, adding the checks. We just want to go and observe what’s happening, and that’s what Soda is enabling right now.

Sid Srivastava
Director of Data Governance, Quality and MLOps
Investing in data quality is key for cross-functional teams to make accurate, complete decisions with fewer risks and greater returns, using initiatives such as product thinking, data governance, and self-service platforms.

Mario Konschake
Director of Product-Data Platform
Soda has integrated seamlessly into our technology stack and given us the confidence to find, analyze, implement, and resolve data issues through a simple self-serve capability.

Sutaraj Dutta
Data Engineering Manager
Our goal was to deliver high-quality datasets in near real-time, ensuring dashboards reflect live data as it flows in. But beyond solving technical challenges, we wanted to spark a cultural shift - empowering the entire organization to make decisions grounded in accurate, timely data.

Gu Xie
Head of Data Engineering
4.4 of 5
Your data has problems.
Now they fix themselves.
Automated data quality, remediation, and management.
One platform, agents that do the work, you approve.
Trusted by








Trusted by the world’s leading enterprises
Real stories from companies using Soda to keep their data reliable, accurate, and ready for action.
At the end of the day, we don’t want to be in there managing the checks, updating the checks, adding the checks. We just want to go and observe what’s happening, and that’s what Soda is enabling right now.
Sid Srivastava
Director of Data Governance, Quality and MLOps
Investing in data quality is key for cross-functional teams to make accurate, complete decisions with fewer risks and greater returns, using initiatives such as product thinking, data governance, and self-service platforms.
Mario Konschake
Director of Product-Data Platform
Soda has integrated seamlessly into our technology stack and given us the confidence to find, analyze, implement, and resolve data issues through a simple self-serve capability.
Sutaraj Dutta
Data Engineering Manager
Our goal was to deliver high-quality datasets in near real-time, ensuring dashboards reflect live data as it flows in. But beyond solving technical challenges, we wanted to spark a cultural shift - empowering the entire organization to make decisions grounded in accurate, timely data.
Gu Xie
Head of Data Engineering
4.4 of 5
Your data has problems.
Now they fix themselves.
Automated data quality, remediation, and management.
One platform, agents that do the work, you approve.
Trusted by
Solutions
Trusted by the world’s leading enterprises
Real stories from companies using Soda to keep their data reliable, accurate, and ready for action.
At the end of the day, we don’t want to be in there managing the checks, updating the checks, adding the checks. We just want to go and observe what’s happening, and that’s what Soda is enabling right now.
Sid Srivastava
Director of Data Governance, Quality and MLOps
Investing in data quality is key for cross-functional teams to make accurate, complete decisions with fewer risks and greater returns, using initiatives such as product thinking, data governance, and self-service platforms.
Mario Konschake
Director of Product-Data Platform
Soda has integrated seamlessly into our technology stack and given us the confidence to find, analyze, implement, and resolve data issues through a simple self-serve capability.
Sutaraj Dutta
Data Engineering Manager
Our goal was to deliver high-quality datasets in near real-time, ensuring dashboards reflect live data as it flows in. But beyond solving technical challenges, we wanted to spark a cultural shift - empowering the entire organization to make decisions grounded in accurate, timely data.
Gu Xie
Head of Data Engineering
4.4 of 5
Your data has problems.
Now they fix themselves.
Automated data quality, remediation, and management.
One platform, agents that do the work, you approve.
Trusted by
Solutions