Cessez de Réagir, Commencez à Prévenir : 3 Méthodes pour Détecter les Problèmes de Qualité des Données
Cessez de Réagir, Commencez à Prévenir : 3 Méthodes pour Détecter les Problèmes de Qualité des Données
Cessez de Réagir, Commencez à Prévenir : 3 Méthodes pour Détecter les Problèmes de Qualité des Données

Mathisse De Strooper
Mathisse De Strooper
Directeur de l'Ingénierie Client chez Soda
Directeur de l'Ingénierie Client chez Soda
Table des matières
Les problèmes de qualité des données peuvent surgir n'importe où, parfois, nous ne savons pas ce qu'ils sont, où ils se produisent, ni quand ils pourraient apparaître. Cela rend nos correctifs réactifs, nous réparons les problèmes uniquement après les plaintes.
Plutôt que de tracer constamment la lignée et d'appliquer des correctifs en aval, nous pourrions toujours faire un pas en arrière et nous concentrer sur la détection précoce. Après tout, comprendre le problème est la première étape pour le résoudre.
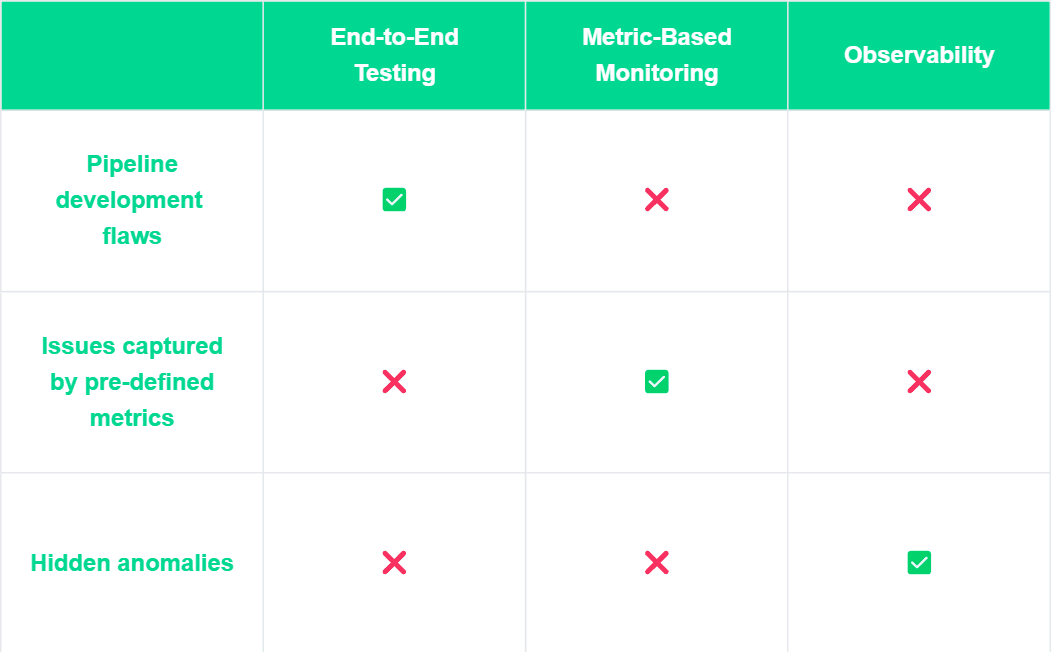
Bien que nous ne puissions pas prédire chaque problème de qualité des données possible, nous savons où chercher et comment enquêter. En général, les problèmes de qualité des données peuvent être découverts par trois méthodes :
Développement du Pipeline – Problèmes détectés lors des tests de pipeline.
Métriques Prédéfinies – Problèmes connus suivis par des contrôles de qualité spécifiques ou des seuils.
Anomalies Cachées – Problèmes inattendus que les mesures standard ne couvrent pas mais peuvent être trouvés par la détection d'anomalies.
Cependant, ces trois angles ne suggèrent pas qu'un soit meilleur que l'autre. En fait, ils sont tous importants car chacun se concentre sur un aspect différent de la qualité des données, nous aidant à détecter les problèmes aussi tôt et aussi complètement que possible.
Causes courantes des problèmes de qualité des données et leurs méthodes de détection.
Les tests de qualité des données de bout en bout pendant le développement aident à identifier les problèmes tôt, évitant les problèmes en aval. La surveillance basée sur les métriques assure la cohérence en détectant les problèmes selon les métriques prédéfinies, tandis que l'observabilité dévoile les anomalies cachées que la surveillance traditionnelle pourrait manquer.
Dans ce blog, nous explorerons comment détecter efficacement les problèmes de qualité des données dans ces domaines en utilisant Soda, avec des exemples pratiques montrant comment ces méthodes fonctionnent ensemble pour créer des solutions proactives pour une meilleure gouvernance des données.
Avant de plonger, passons en revue quelques préparations nécessaires.
Rédaction de Vérifications de la Qualité des Données que Tout le Monde Veut Lire
Nous ne pouvons pas nous attendre à ce que tout le monde dans l'équipe comprenne SQL, mais cela signifie-t-il que la qualité des données devrait être réservée uniquement à ceux qui le font? Absolument pas. Assurer une bonne qualité des données est un effort d'équipe, et il est crucial que tout le monde reste sur la même longueur d'onde.
C'est pourquoi nous avons besoin d'une approche simple pour définir les attentes en matière de données afin que tout le monde puisse les comprendre. Soda Check Language (SodaCL) convient parfaitement : il est assez simple pour que les membres de l'équipe moins techniques le comprennent, mais suffisamment puissant pour que les développeurs le personnalisent.
Voici un petit exemple de comment rédiger une vérification de qualité des données pour un ensemble de données dim_customer. Dans les sections suivantes, nous verrons comment ces vérifications entrent en jeu dans divers flux de travail.
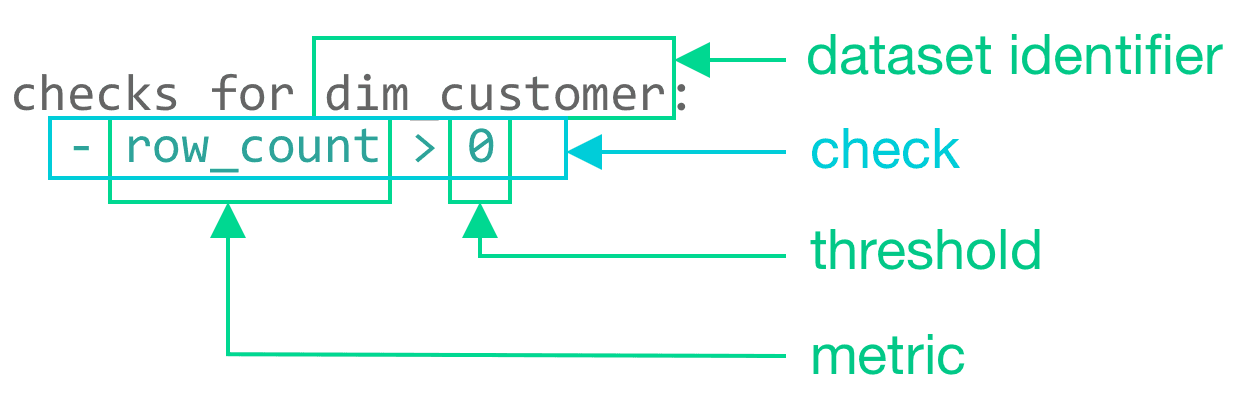
Structure d'une simple vérification SodaCL pour 'le nombre de lignes'
Test de la Qualité des Données de Bout en Bout avec Soda
Dans cette section, nous découvrirons comment valider et tester les données dans le pipeline de données avant qu'elles n'affectent la production avec les vérifications de qualité des données de Soda.
Les données circulent d'une étape à une autre dans un pipeline de données. Les tests de bout en bout (E2E) consistent à s'assurer que chaque étape du pipeline de données est fiable, du moment où les données arrivent dans l'entrepôt à celui où elles sont livrées à nos utilisateurs en aval.
Il est préférable de commencer les tests de qualité des données E2E aussi tôt que possible! Bien que nous puissions généralement gérer les problèmes de qualité des données à la source, ils peuvent être très difficiles à traiter s'ils surviennent plus tard.
Utiliser les vérifications de qualité des données de Soda avec SodaCL à chaque étape du pipeline de données aide à assurer la qualité des données et à maintenir le bon fonctionnement.
Ceci est particulièrement utile lorsque nous repérons des problèmes de qualité des données dans le pipeline en amont. Pour vous montrer comment cela fonctionne, j'ai créé un pipeline de données simple avec Airflow, où les données transitent de la base de données Snowflake, sont transformées avec DBT, et Soda exécute des vérifications de qualité des données entre chaque étape. Voici un aperçu rapide :
Pipeline de données Airflow DAG avec vérifications de qualité des données
Juste une petite remarque, cette section est un peu technique et longue, donc c'est super si vous savez déjà comment créer un pipeline de données, surtout avec le Airflow DAG. La démonstration se concentrera sur l'implémentation des scans de qualité des données Soda dans le pipeline de données Airflow, et elle commencera sous la condition que Snowflake soit connecté et configuré avec Airflow sur un système d'exploitation Windows.
Prérequis
Pour exécuter les vérifications de qualité des données Soda dans un pipeline de données, nous devons avoir la Soda Library installée, la configurer avec la source de données correspondante et spécifier quel type de vérifications nous voulons exécuter avec elle.
Installer Soda
Sous le répertoire projet actuel, dans notre cas 'Airflow_demo', créer un répertoire 'Soda' et créer un nouvel environnement virtuel.
Installer la bibliothèque Soda appropriée dans l'environnement virtuel en fonction de la source de données avec laquelle nous voulons travailler. Étant donné que j'utilise Snowflake, j'ai installé Soda avec
pip install -i https://pypi.cloud.soda.io soda-snowflake. Si vous utilisez un système d'exploitation différent ou devez configurer une autre source de données, veuillez vous référer à ce guide d'installation en conséquence.
La création de compte en libre-service pour Soda Cloud est temporairement suspendue tandis que nous préparons la disponibilité générale de plusieurs mises à jour majeures. Si vous souhaitez essayer Soda Cloud entre-temps, veuillez planifier un appel avec notre équipe d'experts, discuter de votre cas d'utilisation et commencer.
Configurer la Source de Données et Soda Cloud
Lorsque Soda doit exécuter des vérifications de qualité des données dans Airflow, il cherche un fichier configuration.yml pour trouver la source de données, ainsi qu'un autre fichier checks.yml contenant les vérifications de qualité des données que vous souhaitez effectuer. Assurez-vous que les deux fichiers sont préparés et enregistrés dans une structure similaire comme suit :
Dans le fichier configuration.yml, ajoutez les détails du compte Snowflake et les informations sur la source de données comme ceci, avec les détails du compte Soda Cloud à la fin :
data_source snowflake_db: type: snowflake connection: username: luca password: secret account: YOUR_SNOW_FLAKE_ACCOUNT database: ECOMMERCE_CUSTOMER_SATISFACTION warehouse: COMPUTE_WH role: ACCOUNTADMIN schema: CUSTOMER soda_cloud: host: cloud.soda.io api_key_id: secret api_key_secret
Spécifier les vérifications de qualité des données avec SodaCL
Dans le fichier checks.yml, nous écrirons les vérifications de qualité des données que Soda utilisera plus tard pour les exécuter sur notre ensemble de données. Écrire des vérifications est vraiment simple, comme ceci :
checks for CUSTOMER_SATISFACTION: - duplicate_count(ORDER_ID) = 0: name: No duplicate ORDER ID - missing_count(ORDER_ID) = 0: name: No missing ORDER ID - schema: warn: when schema changes: any name
J'ai inclus trois vérifications pour mon ensemble de données CUSTOMER_SATISFACTION : une vérification de duplication, un décompte des valeurs manquantes pour la colonne ORDER_ID, et une vérification du schéma qui nous alertera s'il y a des changements aux colonnes à l'avenir. Vous pouvez également découvrir plus de vérifications ou créer les vôtres en suivant les instructions dans cette documentation.
Enfin, dans la ligne de commande, tapons soda test-connection -d snowflake_db -c configuration.yml pour lancer un test et voir si Soda est connecté à ma source de données et fonctionne correctement.
Ayant tous les configurations en place, notre prochaine étape est d'intégrer Soda dans le pipeline Airflow.
Définir un Scan Soda dans DAG
Pour utiliser Soda avec notre pipeline de données Airflow, nous devons démarrer un workflow de Scan Soda dans un Airflow DAG. Dans un workflow de Scan Soda, Soda trouvera la source de données, obtiendra les identifiants d'accès (du configuration.yml), décidera quelles vérifications (du checks.yml) effectuer sur l'ensemble de données et fournira ensuite les résultats complets du scan.
Voici comment nous pouvons y parvenir avec deux étapes principales : d'abord, créer une fonction Python pour le workflow du Scan Soda, et ensuite, créer un nouveau fichier DAG et appeler cette fonction avec le décorateur @task.
Étape 1 : Créez une fonction check() dans un nouveau fichier python check_function.py dans le dossier Soda pour configurer le workflow du Scan Soda :
# Invoke Soda library def check(scan_name, checks_subpath=None, data_source='snowflake_db', project_root='include'): from soda.scan import Scan # Soda needs both configuration & checks files to exectue the check config_file = f'{project_root}/soda/configuration.yml' checks_path = f'{project_root}/soda/checks.yml' if checks_subpath: checks_subpath += f'/{checks_subpath}' scan = Scan() scan.set_verbose() scan.add_configuration_yaml_file(config_file) scan.set_data_source_name(data_source) scan.add_sodacl_yaml_files(checks_path) scan.set_scan_definition_name(scan_name) result = scan.execute() print(scan.get_logs_text()) if result != 0: raise ValueError('Soda Scan failed'
Étape 2 : Créez un Airflow DAG qui appelle la fonction check() comme une tâche externe Python. Dans le fichier DAG, nous importons et invoquons la fonction check() comme ceci :
# DAG file: Import the check method from check_function.py def customer(): @task.external_python(python='/usr/local/airflow/soda_venv/bin/python') def check_customer(scan_name='check_customer', checks_subpath='tables', data_source='snowflake_db'): # check_function.py from the Soda folder from include.soda.check_function import check check(scan_name, checks_subpath, data_source) check_customer()
Votre dossier de travail devrait maintenant ressembler à ceci :
airflow_demo/ ├── dags/ │ ├── dag_soda.py #step 2 ├── Soda/ │ ├── check_function.py #step 1 │ ├── configuration.yml │ └── checks.yml
Arrêt de Pipeline 1 : Vérifications Pré-Transformation
Avec tout en place, nous pouvons déclencher le Airflow DAG avec le Scan Soda avant que les données n'atteignent l'étape de transformation. Dans ce processus, Soda scannera les données dans Snowflake et signalera tout ce qui ne répond pas aux règles de qualité que nous avons établies. Pensez à ceci comme notre première ligne de défense, attrapant tout problème évident avant qu'il n'affecte le reste du pipeline.
Vérifications de qualité des données avant la transformation de stade 2
Dès que le DAG a été déclenché, nous avons remarqué un avertissement d'échec dans le journal, nous informant que la vérification des valeurs manquantes pour la colonne ORDER_ID n'a pas réussi. Réfléchissez-y – si ces ID manquants passent inaperçus, les analyses en aval pourraient ne pas tenir compte de ces enregistrements, ce qui pourrait affecter notre rapport sur les volumes de commande ou la satisfaction client. Cela montre vraiment à quel point une bonne qualité des données est importante et constitue un argument solide en faveur des tests E2E. Après que la première vérification a été lancée, nous avons obtenu les avertissements suivants dans le terminal :
Oups! 1 échec. 0 avertissements. 0 erreurs. 2 réussites.
Le drapeau montre qu'il y a des valeurs manquantes dans la table sous la colonne ORDER_ID. Pour résoudre cela, nous pouvons accéder à l'interface utilisateur de Soda Cloud pour obtenir plus de détails sur les lignes de cette colonne particulière :
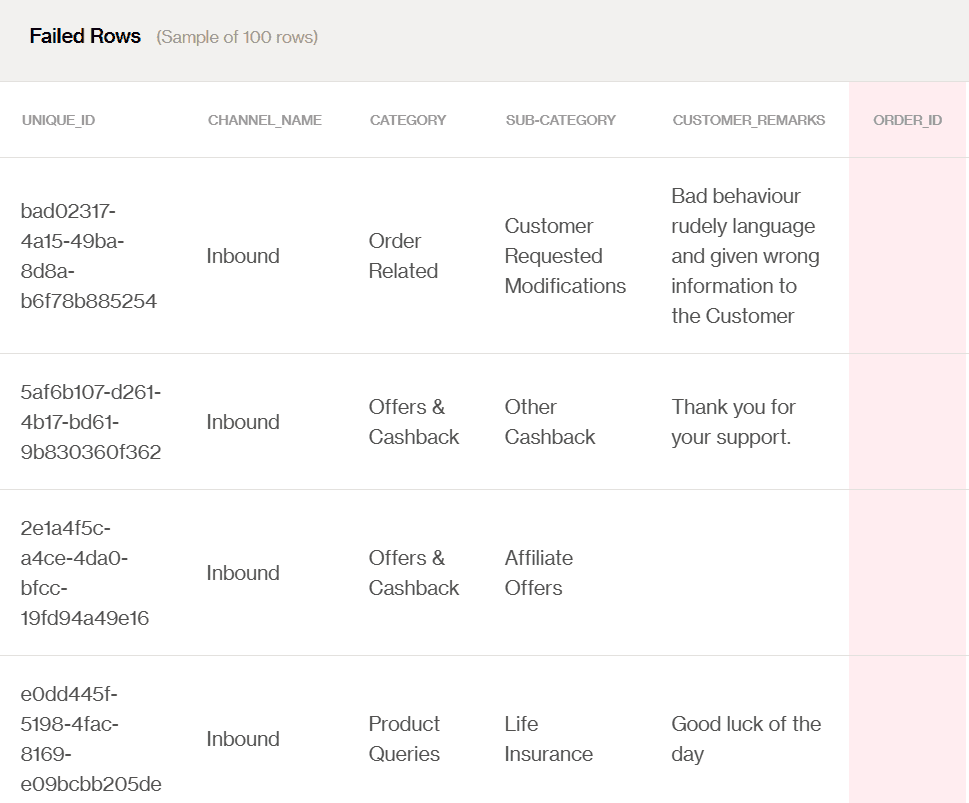
Analyse des lignes manquantes de l'interface utilisateur de Soda Cloud
Grâce aux informations de l'Analyse des Lignes Échouées, nous pouvons trouver tous les enregistrements qui n'ont pas réussi à passer la vérification des valeurs manquantes. Cette information arrive en temps voulu, nous permettant de résoudre le problème dès les premiers stades. En conséquence, comme nous voulons nous assurer que tous les retours d'ordre client soient examinés et analysés plus tard, cela nous aide également à éviter les problèmes lors du processus de transformation.
Pour une résolution rapide du problème, nous pouvons soit essayer de récupérer des enregistrements manquants de la source, supprimer ces entrées de la table, ou augmenter la tolérance pour les valeurs manquantes. À des fins de démonstration, je choisis d'augmenter les seuils de tolérance et de permettre des enregistrements supplémentaires de 5 % sans ORDER_ID dans le fichier checks.yml précédent, pour vous montrer comment cela fonctionnerait :
- missing_percentage(ORDER_ID) = 5%: name
Lancez à nouveau le DAG, et sans surprise, nous obtenons la notification suivante affichant dans le terminal :
Tout est bon. Pas de défaillance. Pas d'avertissement. Pas d'erreurs.
Arrêt de Pipeline 2 : Transformation dbt
Maintenant que nous avons les données brutes vérifiées et validées, il est temps de lancer une transformation dbt dans le DAG. À ce stade, dbt fait sa magie habituelle – comme joindre des tables et appliquer des règles métier – afin que nous puissions préparer les données pour l'analyse ou le machine learning.
Dans cet exemple, le travail de dbt est de créer un modèle de données qui génère une nouvelle table basée sur celle d'origine. Cette nouvelle table RESPONSIVE_RATE devrait inclure une colonne RESPONSE_TIME_SECONDS pour suivre combien de temps il faut à un service client pour répondre aux demandes, mesuré en secondes.
Je ne rentrerai pas dans tous les détails concernant la rédaction des modèles dbt et le déclenchement du DAG, car ce n'est pas le point central de cette démonstration.
Avec le DAG Airflow déclenché, le scan préalablement défini intervient à nouveau (n'oublions pas que le scan Soda sera toujours déclenché puisqu'il s'agit de la première partie du DAG). Sans alertes cette fois-ci, nous pouvons trouver notre nouvelle table agrégée dans Snowflake !
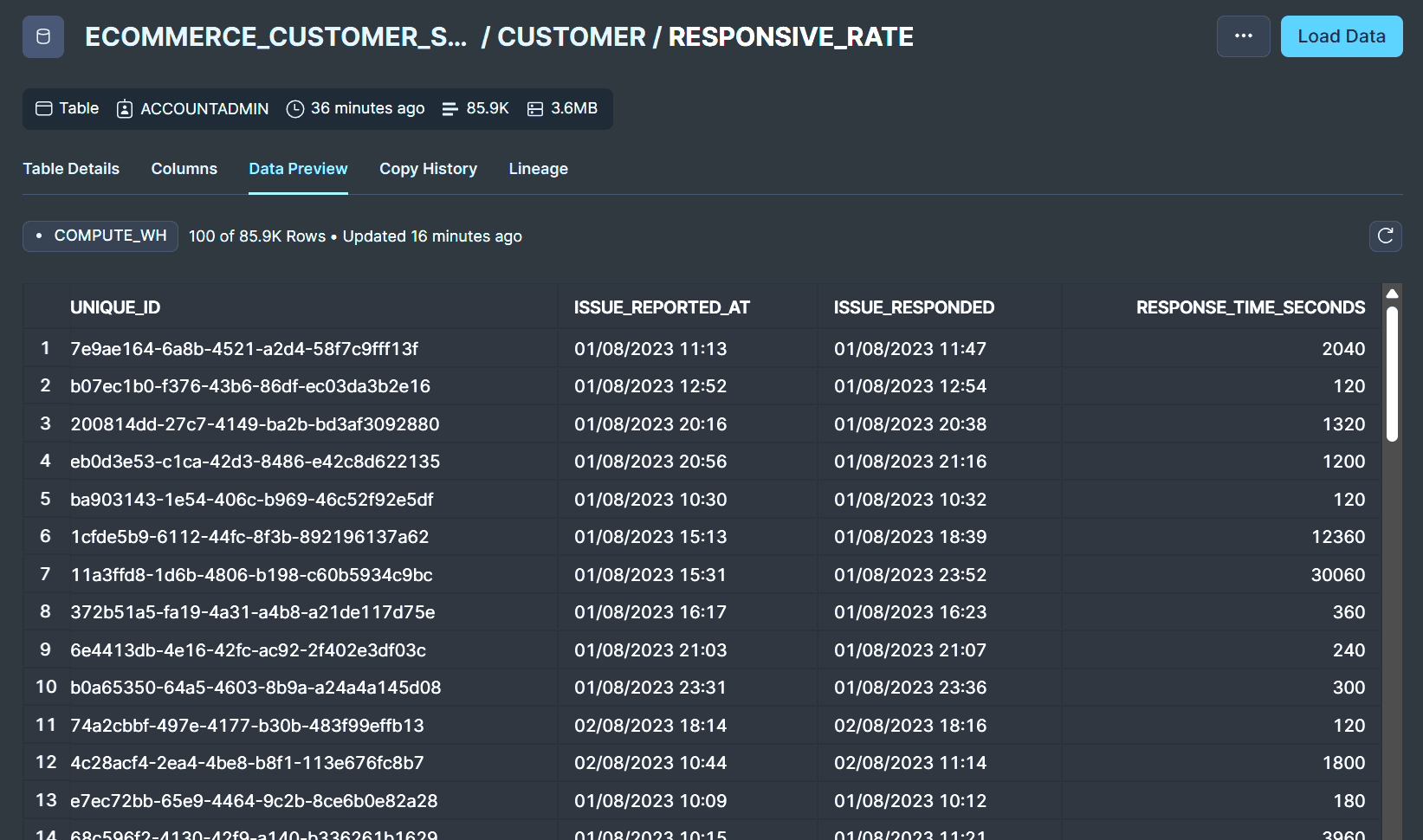
Nouvelle table Responsive_Rate générée par la transformation dbt
Arrêt de Pipeline 3 : Vérifications Post-Transformation
Notre nouvelle table semble géniale, mais nous avons encore du travail à faire. Alors que dbt fait un excellent travail, il ne garantit pas que nos données sont de hautes normes. Il y a toujours une chance que quelque chose d'inattendu se produise.
Par exemple, après la transformation, nous aboutissons à une nouvelle table comportant la métrique response_time_seconds. Mais que se passe-t-il si cela mène à de nouveaux problèmes de qualité des données, comme des horodatages manquants, entraînant des enregistrements nuls ou invalides ?
Pour détecter ces problèmes potentiels, ajoutons quelques vérifications supplémentaires sur la qualité des données. Dans le même dossier appelé 'Soda', nous pouvons créer un nouveau fichier check_transform.yml qui contiendra des vérifications de qualité des données spécifiques pour cette table transformée :
checks for RESPONSIVE_RATE: - missing_count(RESPONSE_TIME_SECONDS) = 0: name: No missing response time - schema: warn: when schema changes: any name
Sauf pour les vérifications régulières du schéma, j'ai également inclus une nouvelle vérification des valeurs manquantes pour la nouvelle colonne RESPONSE_TIME_SECONDS. Après cela, nous pouvons répéter le processus similaire (vérification de la qualité des données à l'arrêt 1) et ajouter cette nouvelle tâche au DAG.
Maintenant, le fichier DAG aura un workflow complet comme suit :
Scan Soda → Transformation dbt → Scan Soda
# This is our dag workflow @dag( start_date=datetime(2024, 3, 1), schedule='@daily', catchup=False, tags=["customer pipeline"], ) # The DAG workflow def customer(): # Pre-transformation Soda Scan @task.external_python(python='/usr/local/airflow/soda_venv/bin/python') def check_customer(scan_name='check_customer', checks_subpath='tables', data_source='snowflake_db'): from include.soda.check_function import check check(scan_name, checks_subpath, data_source) # dbt Transformation transform = DbtTaskGroup( group_id='transform', project_config=DBT_PROJECT_CONFIG, profile_config=DBT_CONFIG, render_config=RenderConfig( load_method=LoadMode.DBT_LS, select=['path:models/transform'] ) ) # Post-transformation Soda Scan @task.external_python(python='/usr/local/airflow/soda_venv/bin/python') def check_transform(scan_name='response_rate_check', checks_subpath='tables', data_source='snowflake_db'): from include.soda.check_function import check check(scan_name, checks_subpath, data_source)
Enfin, le DAG est à nouveau déclenché, et ce que nous aurons est ce joli graphique DAG dans Airflow montrant que tout a été exécuté avec succès! 🎉
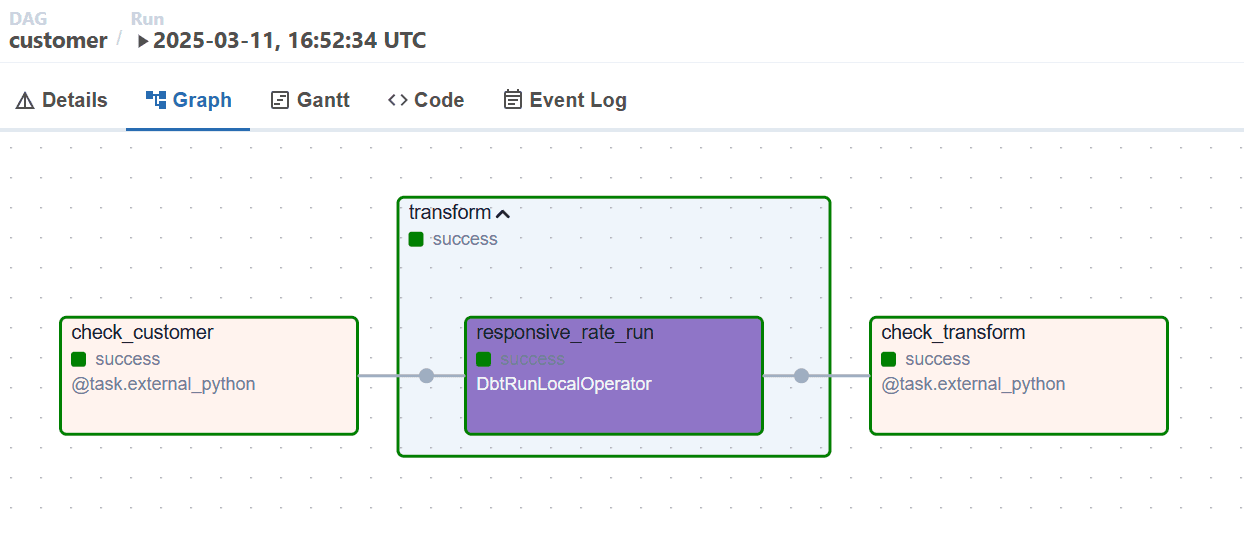
Workflow d'exécution du DAG
De plus, nous pouvons explorer les résultats du scan de la nouvelle table dans l'interface Soda Cloud d'une manière holistique, où nos collègues peuvent également avoir accès. Je n'expliquerai pas les détails ici, car c'est le sujet de la prochaine section :)
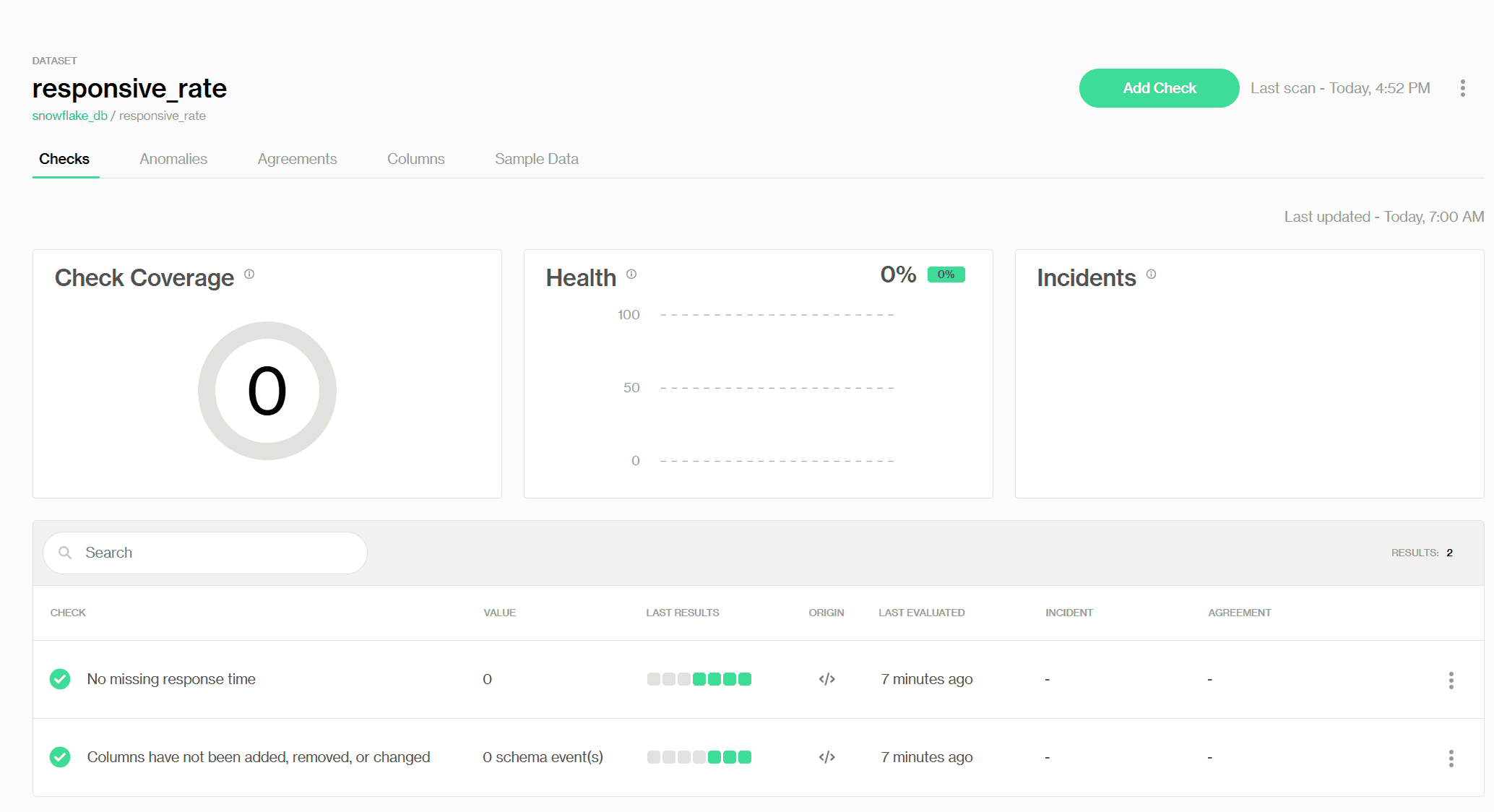
Résultats du scan Soda pour le nouvel ensemble de données dans l'interface Soda Cloud
Une fois que tout est vérifié, les données sont prêtes à être utilisées, que ce soit pour un tableau de bord dans un outil BI ou pour entraîner un modèle de machine learning. Lorsque elles arrivent à ces systèmes, nous avons effectué plusieurs contrôles, réduisant considérablement les surprises et les problèmes de dernière minute.
Surveillance de la Qualité des Données en Action
Bien que les tests E2E soient excellents pour s'assurer que notre pipeline de données reste robuste pendant le développement et les changements, des problèmes de qualité des données peuvent encore surgir à tout moment. Il est important de détecter ces problèmes rapidement et de les résoudre avant qu'ils ne causent des problèmes en aval.
Après tout, la qualité des données nécessite une assurance à long terme.
Soda surveille la qualité des données avec des règles, des seuils, et des tableaux de bord—comme ceux que nous allons explorer dans l'interface Soda Cloud UI—pour mesurer la santé de la qualité des données. Si une métrique dépasse un seuil prédéfini (par exemple, si le nombre de lignes traitées chute en dessous d'une référence connue) ou un changement de schéma simple, nous recevrons une alerte immédiatement.
Métriques, Seuils, et Stratégie d'Alertes
Rappelez-vous le nouvel ensemble de données responsive_rate que nous avons généré avec le DAG auparavant ? Il fournit de nouvelles informations sur le temps qu'il faut habituellement à un représentant du service client pour répondre à et résoudre les problèmes des clients.
D'un point de vue analytique, il serait bénéfique de s'assurer qu'aucun temps de réponse d'un représentant client ne soit négatif. C'est une nouvelle métrique de qualité des données que nous avons l'intention d'ajouter maintenant, mais qui n'était pas incluse lors de nos tests de bout en bout.
De plus, nous aimerions recevoir une alerte lorsque le nombre total de ces enregistrements invalides dépasse 2 %. Voyons comment nous pouvons y parvenir dans le tableau de bord de Soda!
Dans l'interface Soda Cloud UI, si nous trouvons le tableau de bord de l'ensemble de données, nous pourrons y trouver plusieurs vérifications prédéfinies de Soda, ainsi que des vérifications SQL personnalisables.
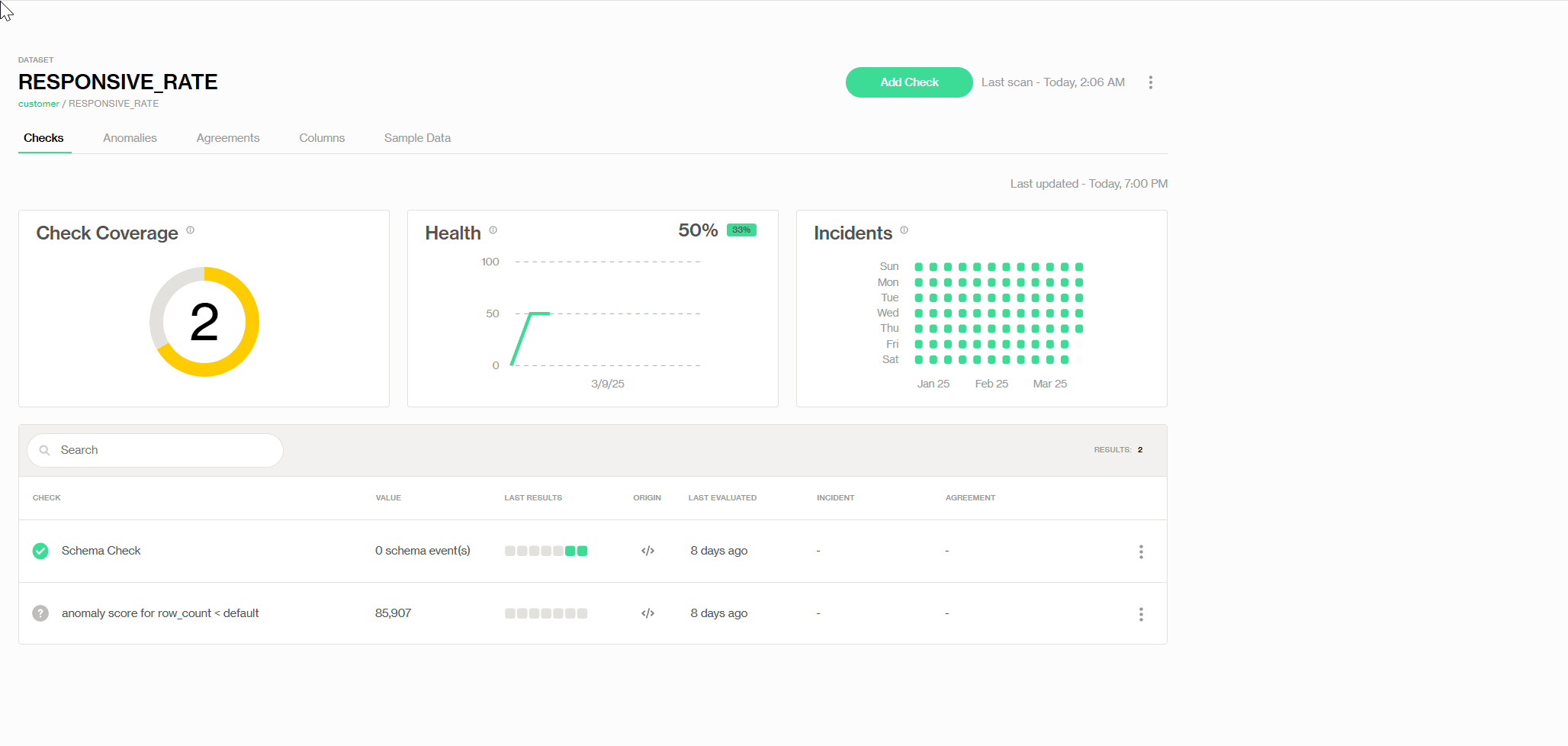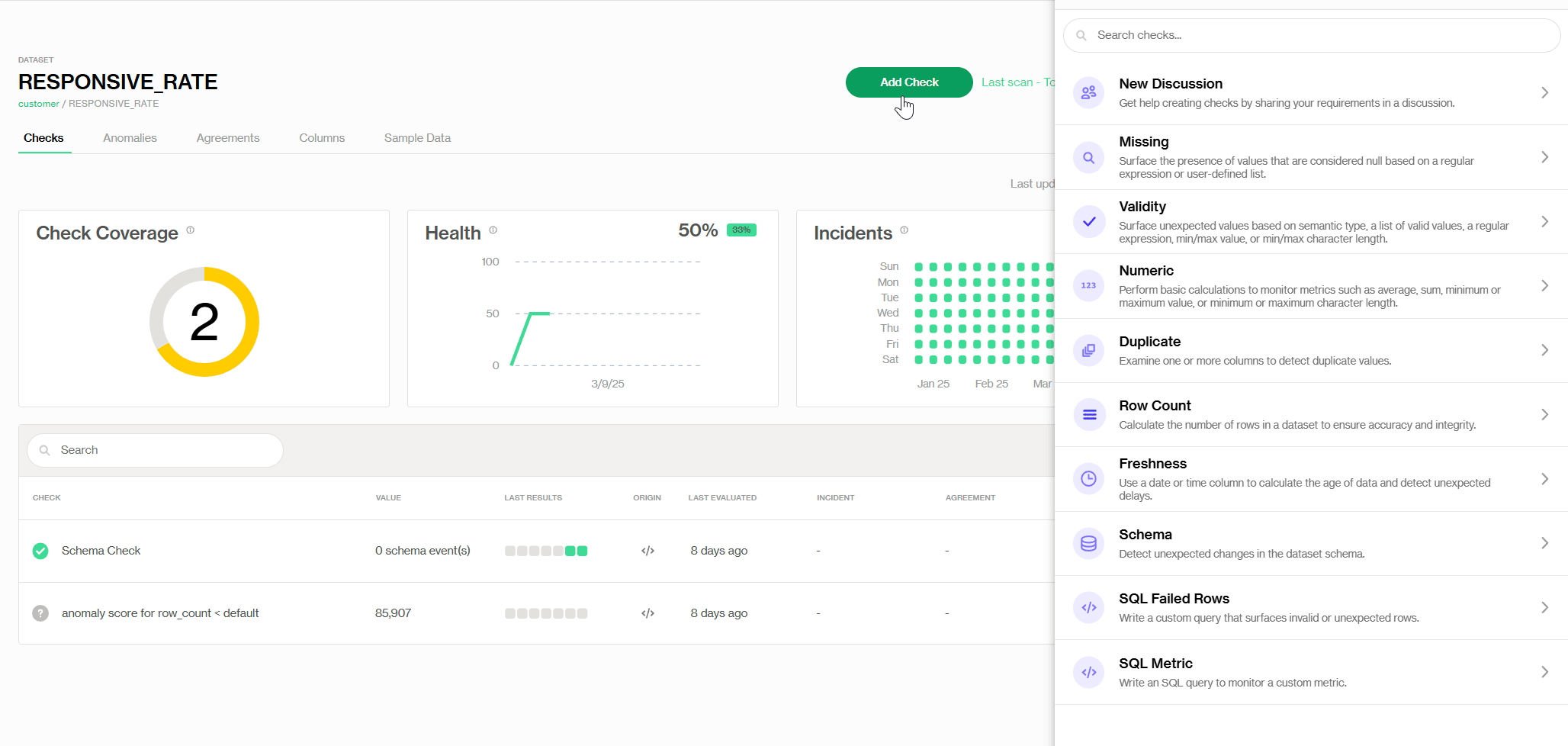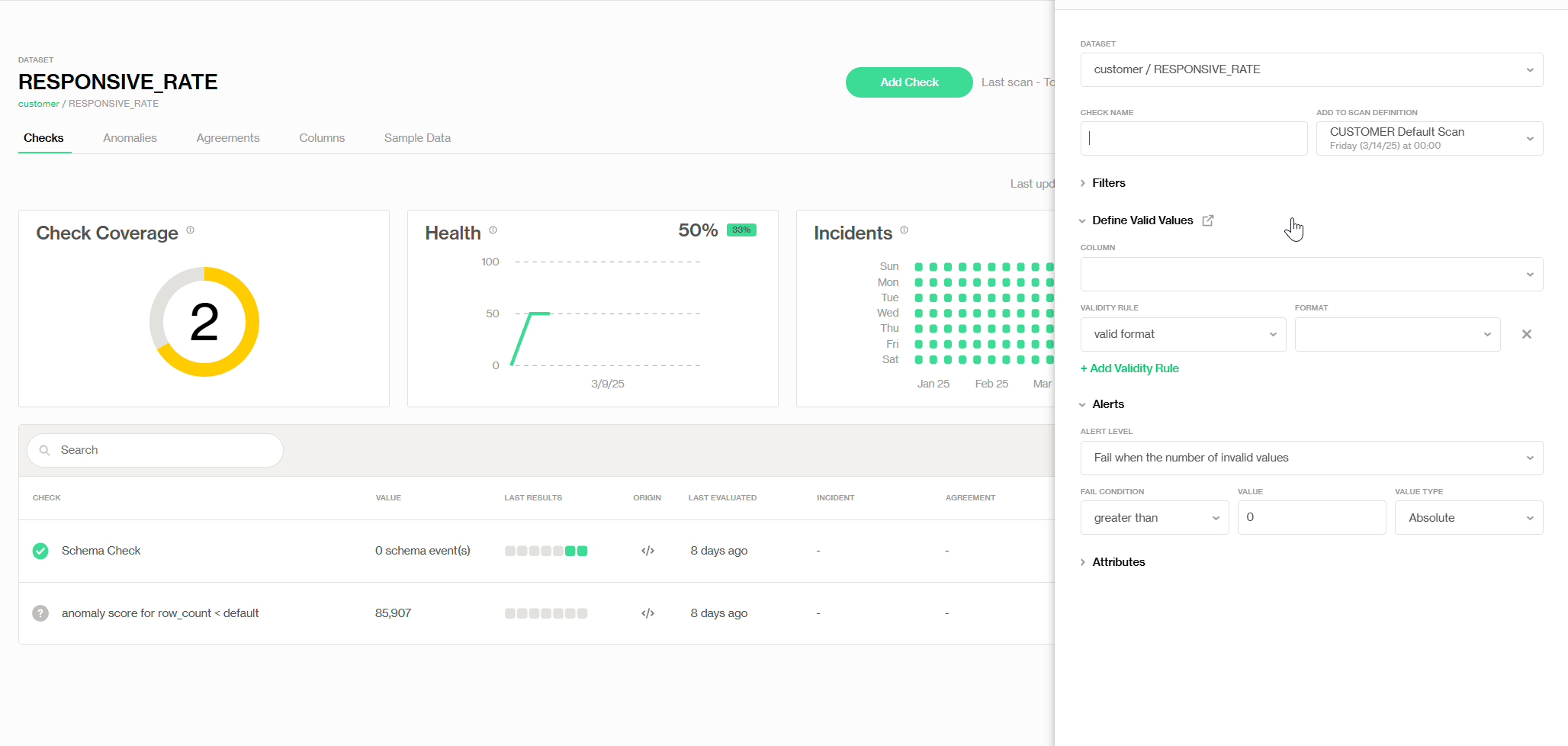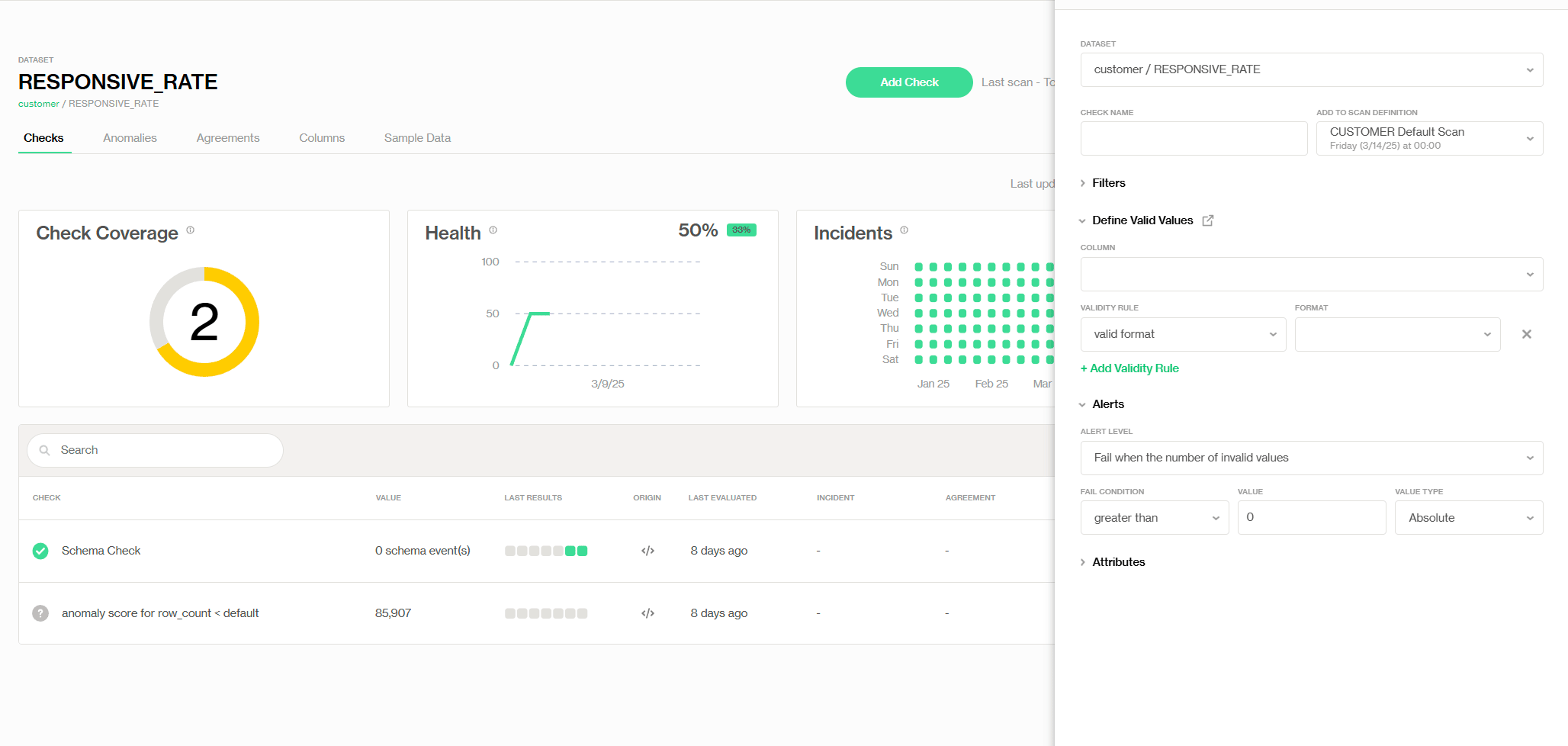
Ajout de la vérification de Validité prédéfinie
Pratiquement, nous pouvons définir une règle de validité (montrée comme suit) avec la vérification prédéfinie appelée 'Validité', où nous fixons la valeur de validité min à 0—donc tout ce qui est négatif est flaggé comme étant une valeur invalide. De plus, nous modifions notre niveau de tolérance aux valeurs invalides et recevons une alerte lorsque le nombre total de valeurs invalides atteint 2 % du total des enregistrements. Ainsi, le propriétaire des données peut corriger les erreurs à temps pour éviter d'autres problèmes en aval.
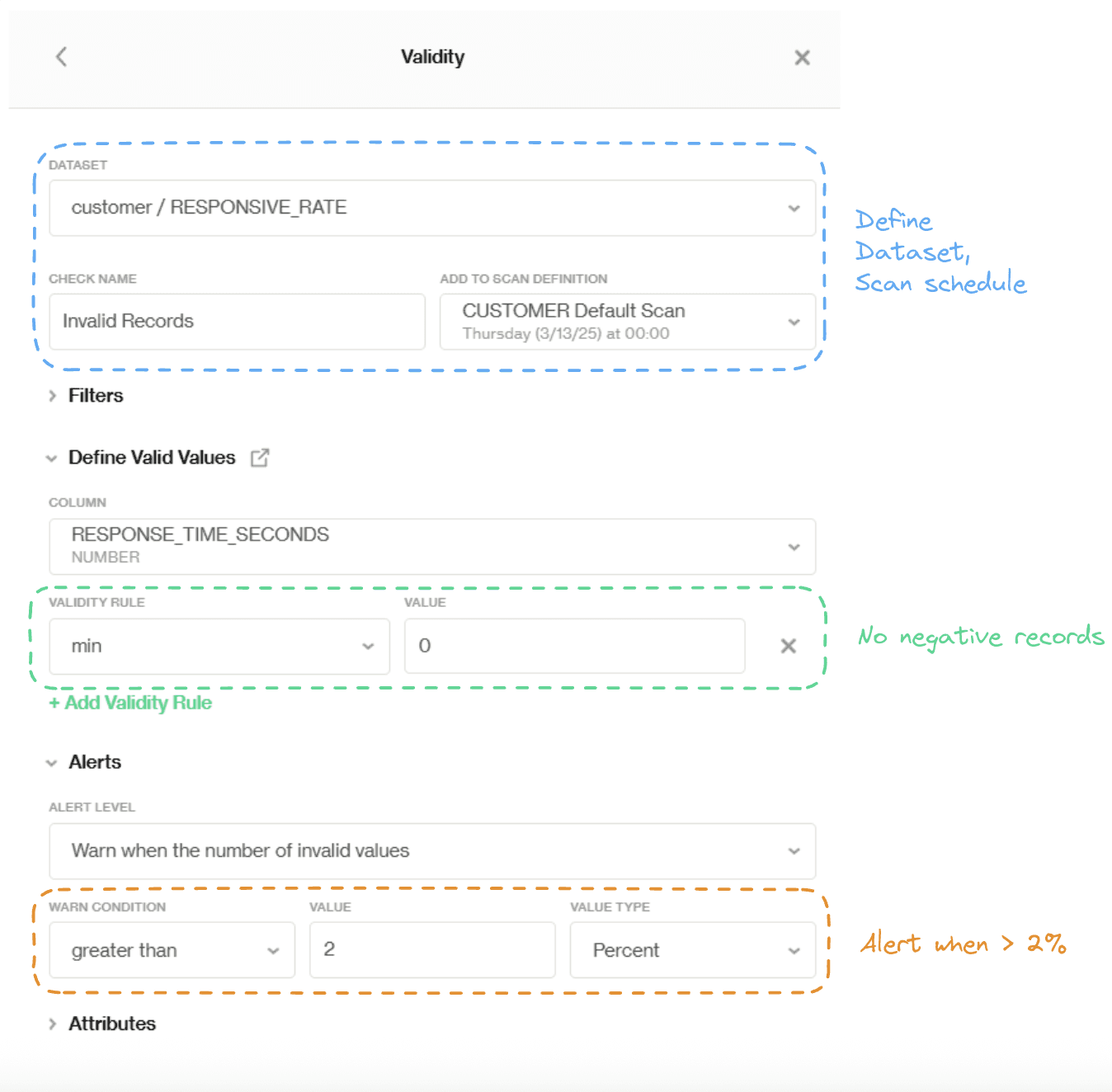
Ajout de la vérification de Validité prédéfinie
Une fois que nous avons configuré toutes les vérifications, avec les seuils et les alertes prêts à fonctionner, nous pouvons surveiller la santé de la qualité des données sur tous les ensembles de données avec des tableaux de bord, où nous verrons des journaux, des alertes, et des tendances tout au même endroit, sans avoir à deviner.
La plateforme Soda Cloud UI offre trois tableaux de bord avec trois niveaux de granularité :
Tableau de Bord Principal surveille l'état général de la source de données
Tableau de Bord de l'Ensemble de Données surveille un ensemble de données spécifique
Tableau de Bord des Métriques pour chaque vérification de la qualité des données.
Découvrons ensemble ces tableaux de bord, un par un.
Tableau de Bord Principal
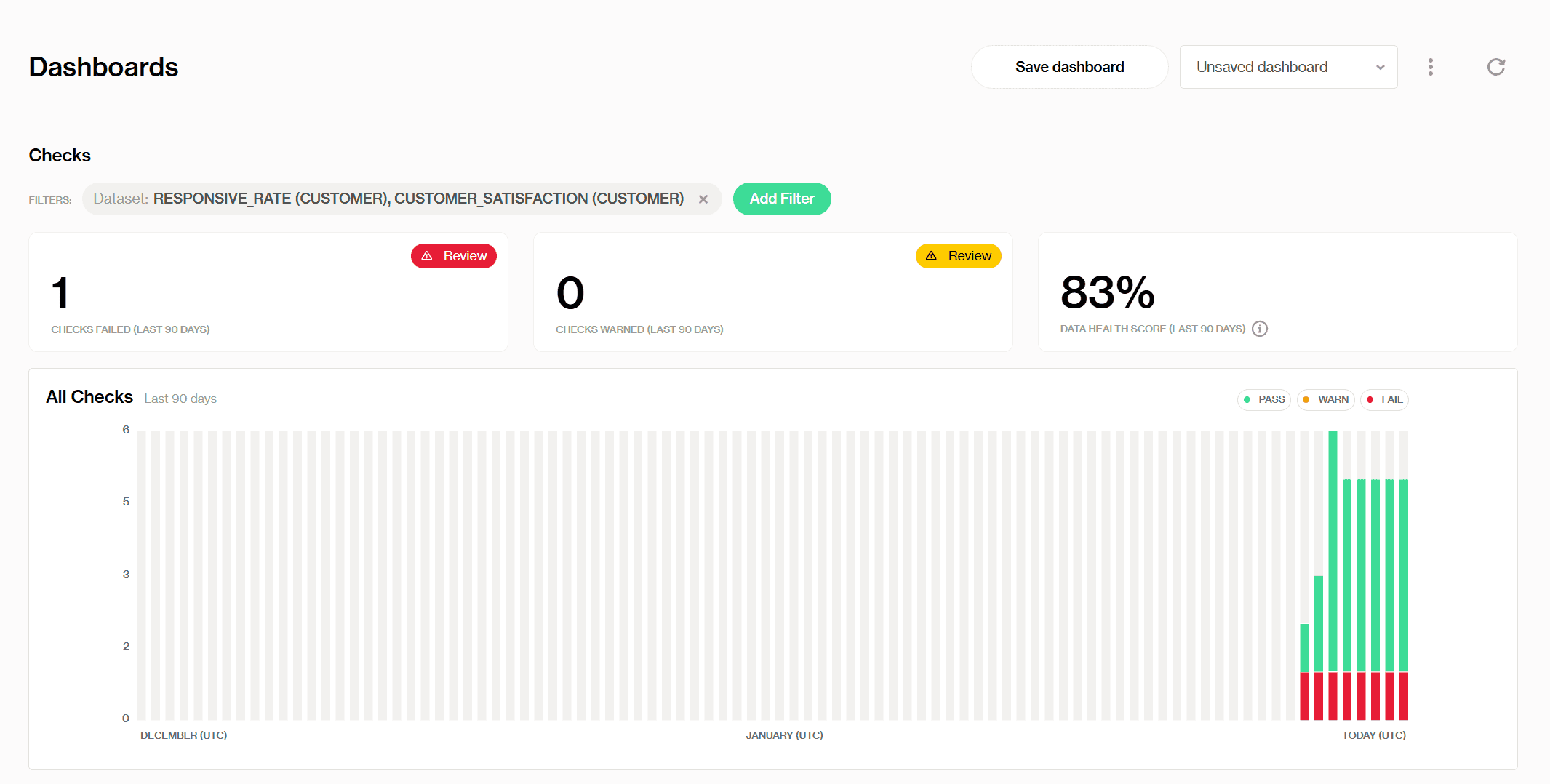
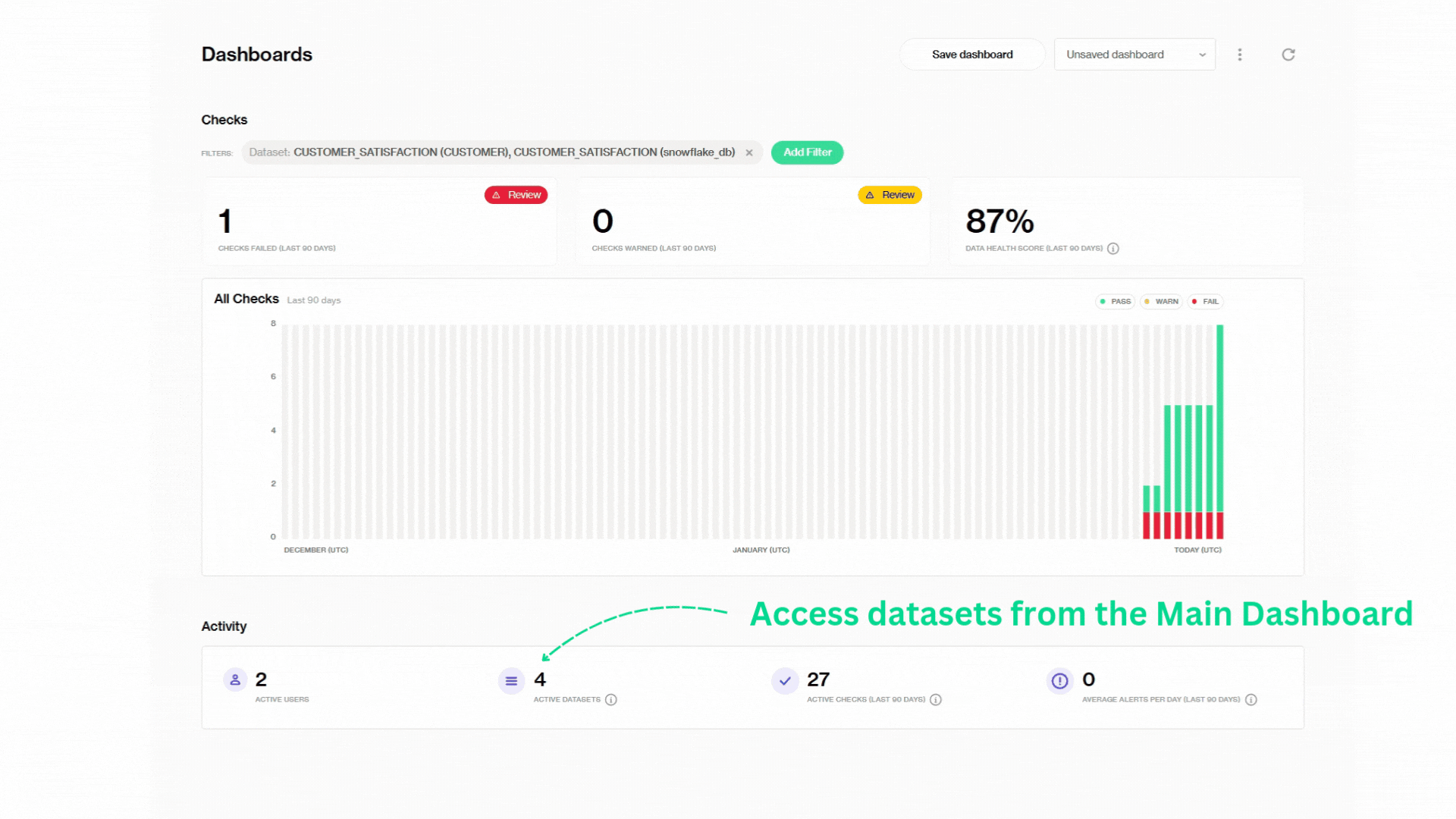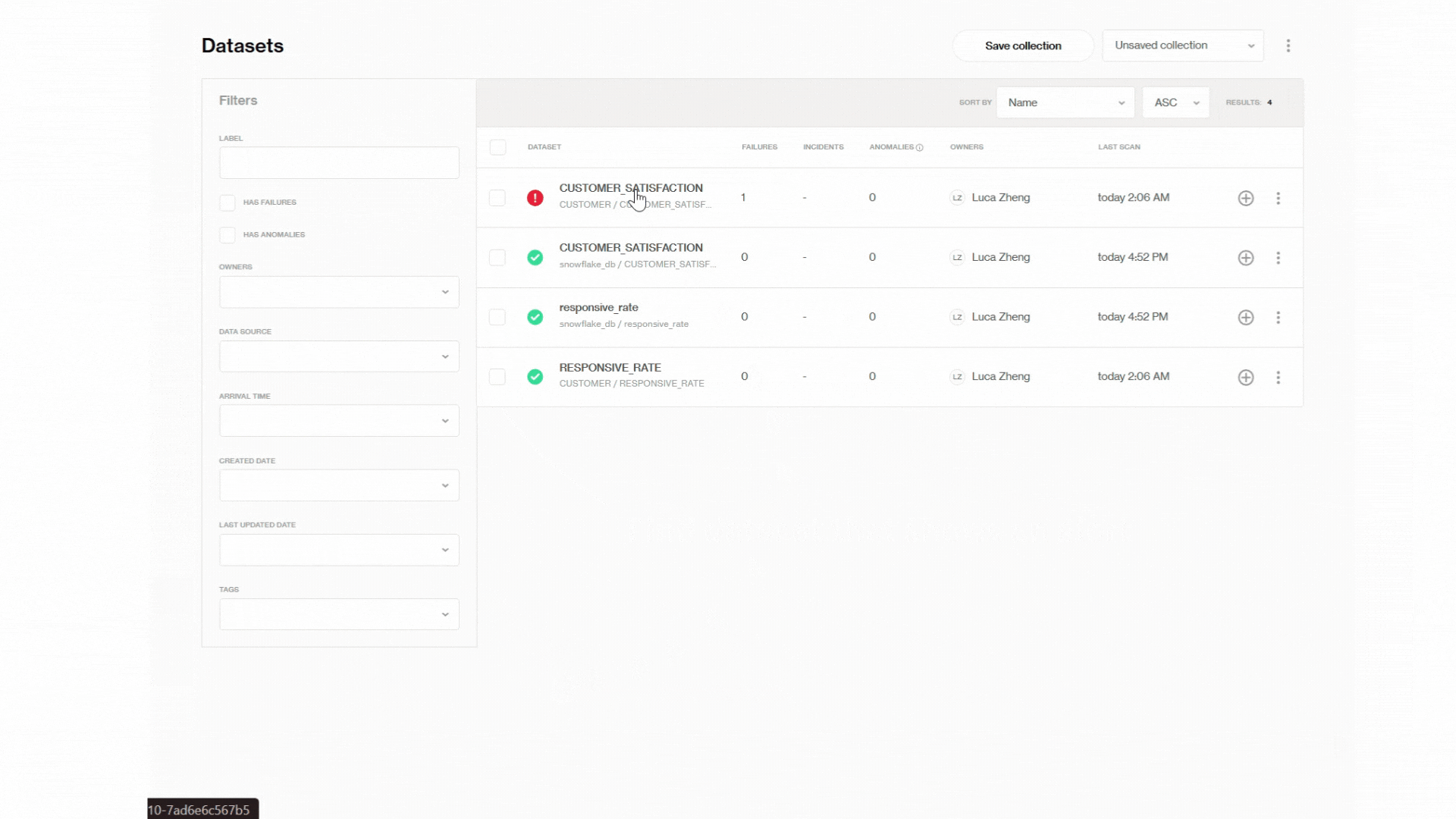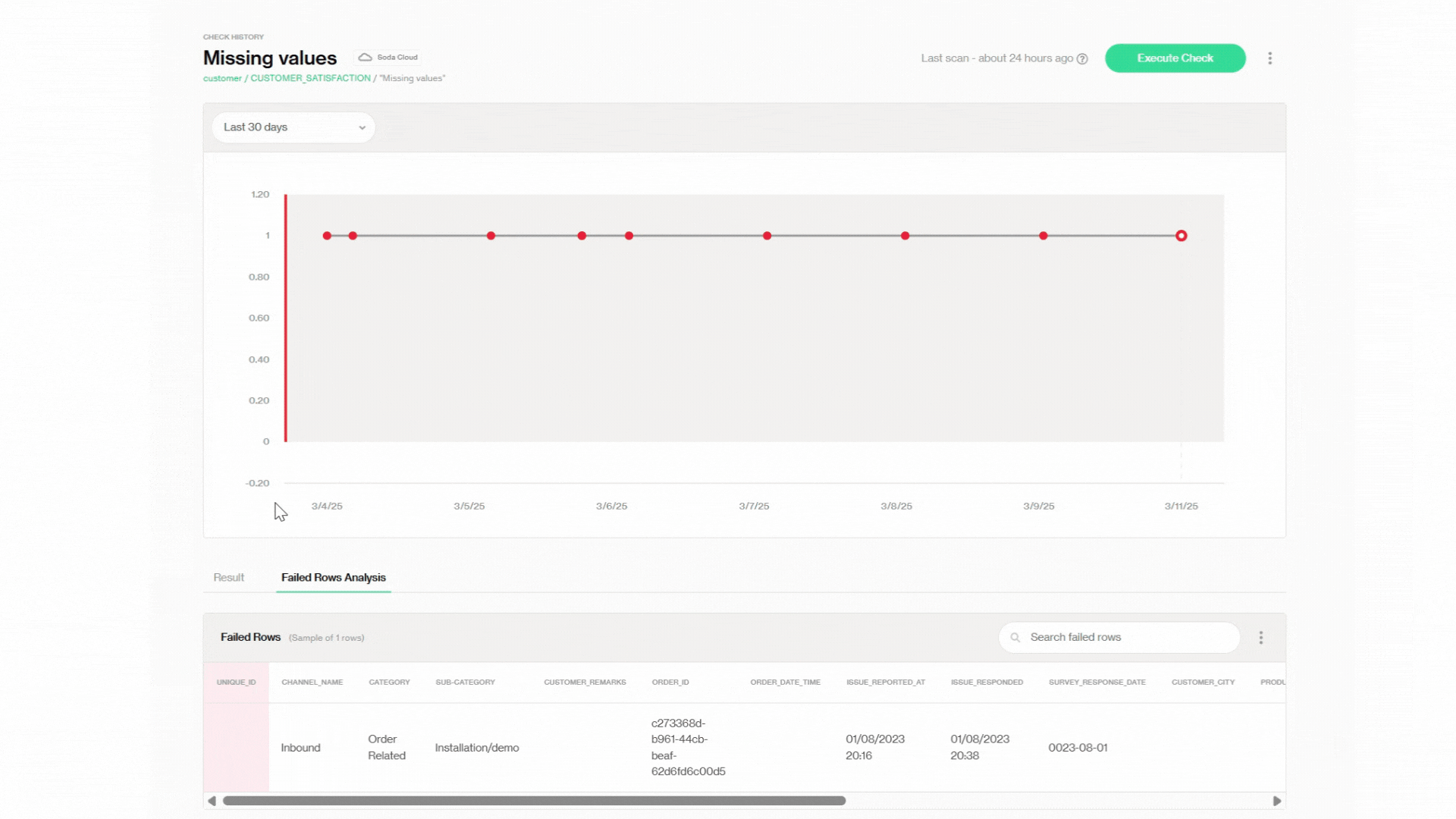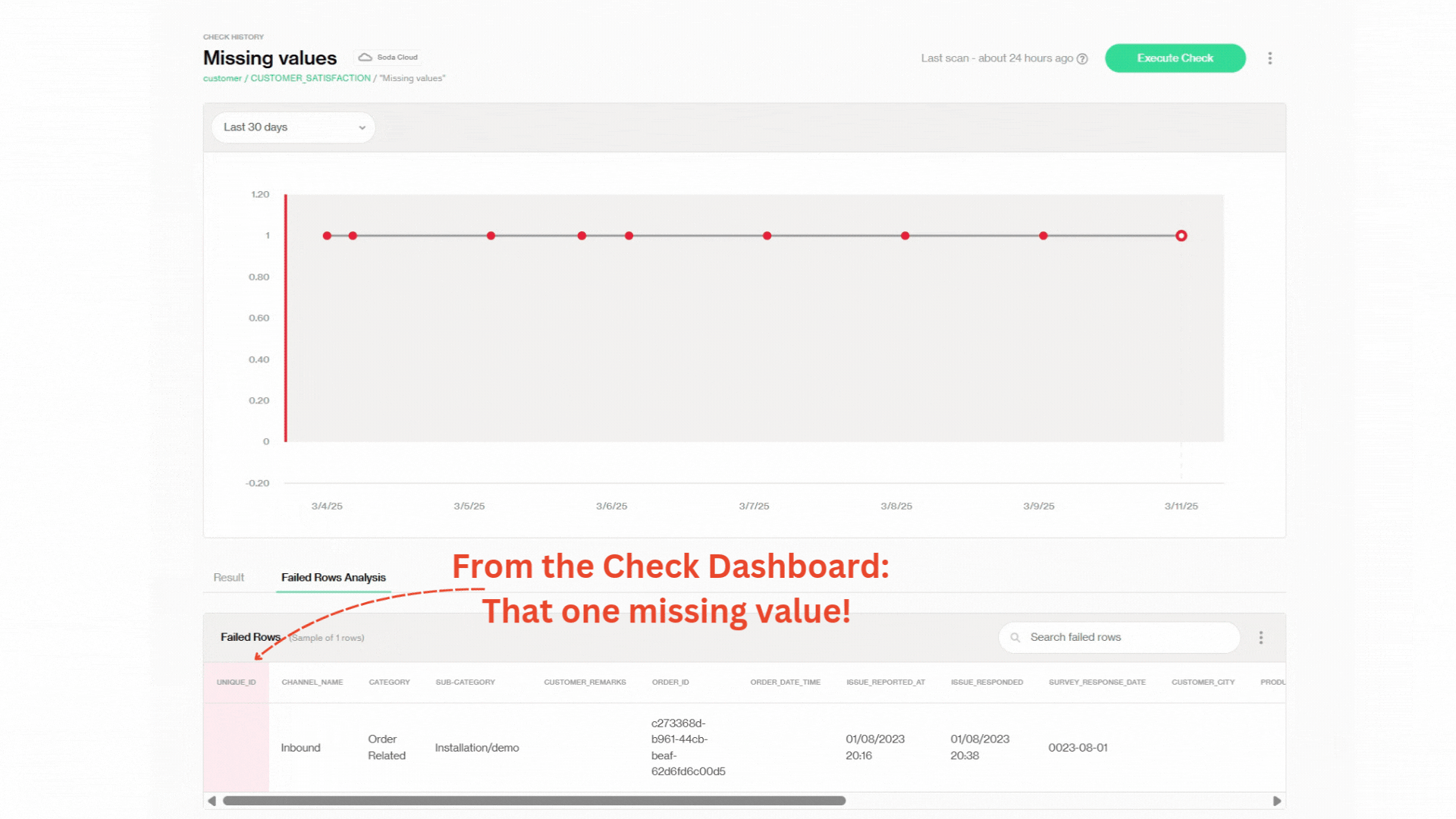
Ce tableau de bord est notre vue d'ensemble des toutes les vérifications à travers un ou plusieurs ensembles de données. D'un coup d'œil, nous pouvons voir que nous avons 1 vérification qui a échoué au cours des 90 derniers jours, 0 vérification qui nécessite de l'attention et un score global de santé des données de 83 % de santé des données.
Ajout de la vérification de Validité prédéfinie
Remarquez comment chaque barre verticale représente une exécution de vérification à un moment donné :
vert pour réussi, rouge pour échoué, et jaune pour avertissements. Si vous passez votre souris sur les barres, vous pouvez voir combien de vérifications passent, nécessitent de l'attention ou échouent et doivent être résolues immédiatement. Comme celle-ci :

Aussi, l'option filtres nous aide à regrouper des ensembles de données spécifiques et nous permet de suivre toutes les vérifications qui ont été exécutées sur ceux-ci. Ici, le tableau de bord principal montre toutes les métriques en combinant les deux ensembles de données que nous avons mentionnés auparavant, l'ensemble de données original CUSTOMER_SATISFACTION, et RESPONSIVE_RATE.
Tableau de Bord de l'Ensemble de Données
Cette vue de tableau de bord offre un résumé en un coup d'œil de la santé de l'ensemble de données. S'il y a un signal d'alarme, tel que des valeurs manquantes, nous pouvons approfondir pour voir exactement quelles lignes ou colonnes ont déclenché l'échec, nous faisant gagner des heures de conjectures.
Ajout de la vérification de Validité prédéfinie
Nous pouvons également surveiller d'autres métriques :
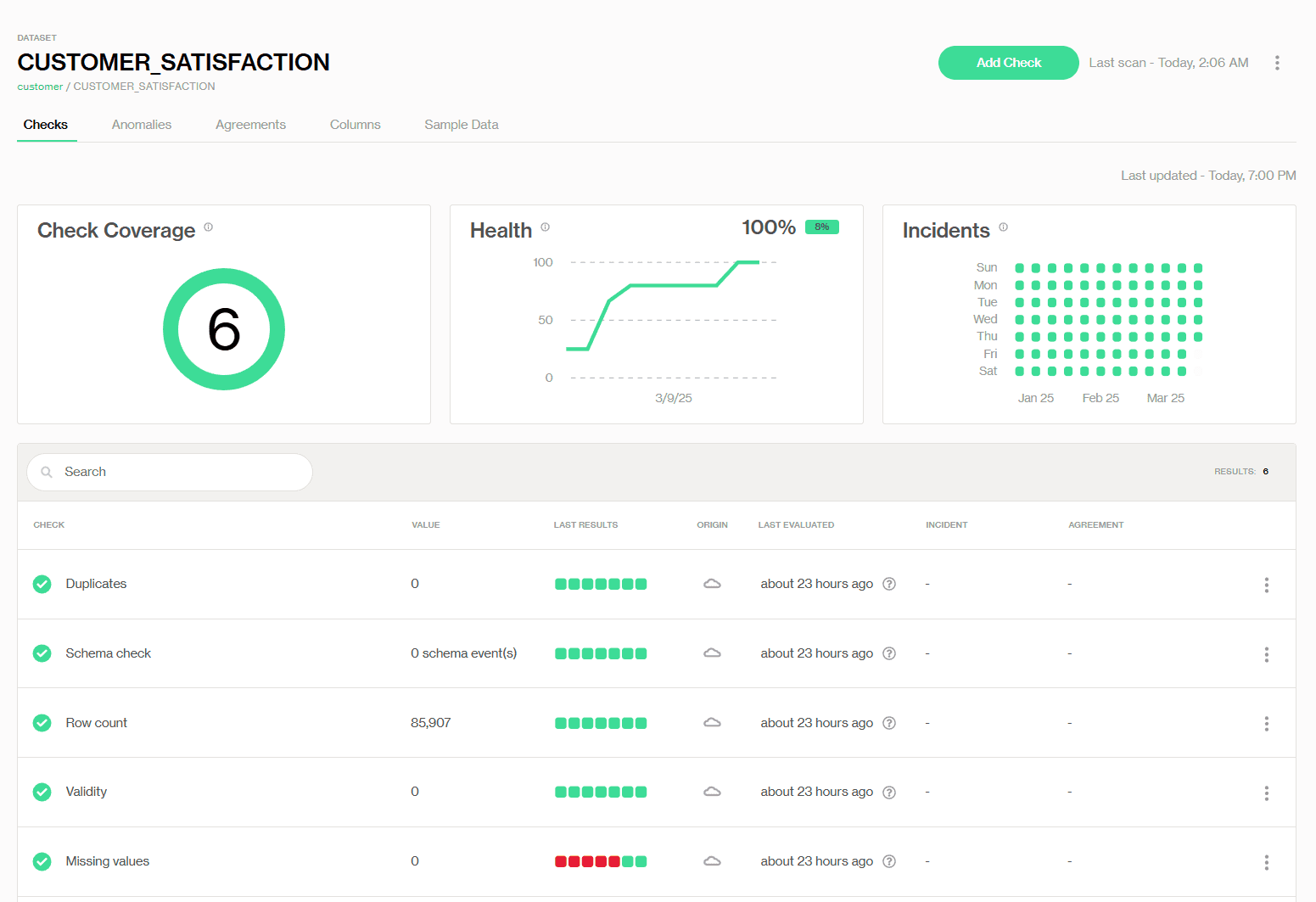
Couverture des Vérifications (6) – Le nombre total de vérifications de qualité des données configurées pour cet ensemble de données.
Santé (100 %) – Un score visuel rapide indiquant le taux de réussite/échec global des vérifications récentes.
Incidents – Une grille de type calendrier affichant les jours où les vérifications ont échoué, réussi ou ont généré des avertissements.
En dessous, il y a une liste détaillée de chaque vérification. Dans cet exemple :
Doublons : Zéro doublons, donc cette vérification est verte et réussie.
Valeurs manquantes : Nous avons détecté des valeurs manquantes il y a plusieurs jours, ce qui explique pourquoi cette vérification a des indicateurs d'état d'échec rouge.
De plus, en utilisant l'option 'Colonne' depuis le panneau supérieur, nous pouvons examiner de plus près les détails de niveau de colonne. Ici, nous pouvons explorer chaque colonne pour rassembler des informations plus détaillées, fournissant des informations telles que des statistiques de base et identifiant des valeurs fréquentes et extrêmes.

Informations sur le niveau des colonnes de l'ensemble de données: customer_satisfaction
Tableau de Bord des Métriques
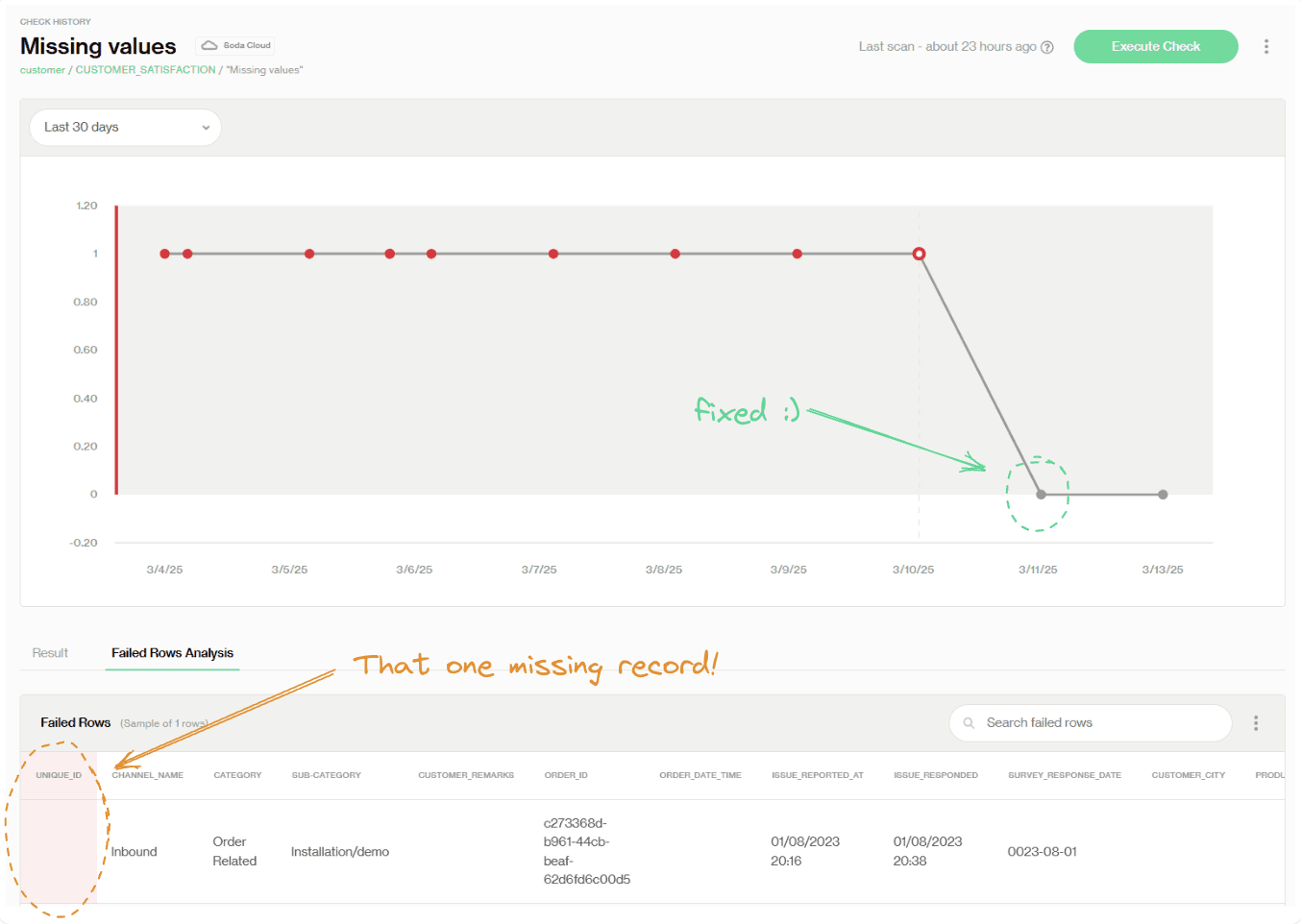
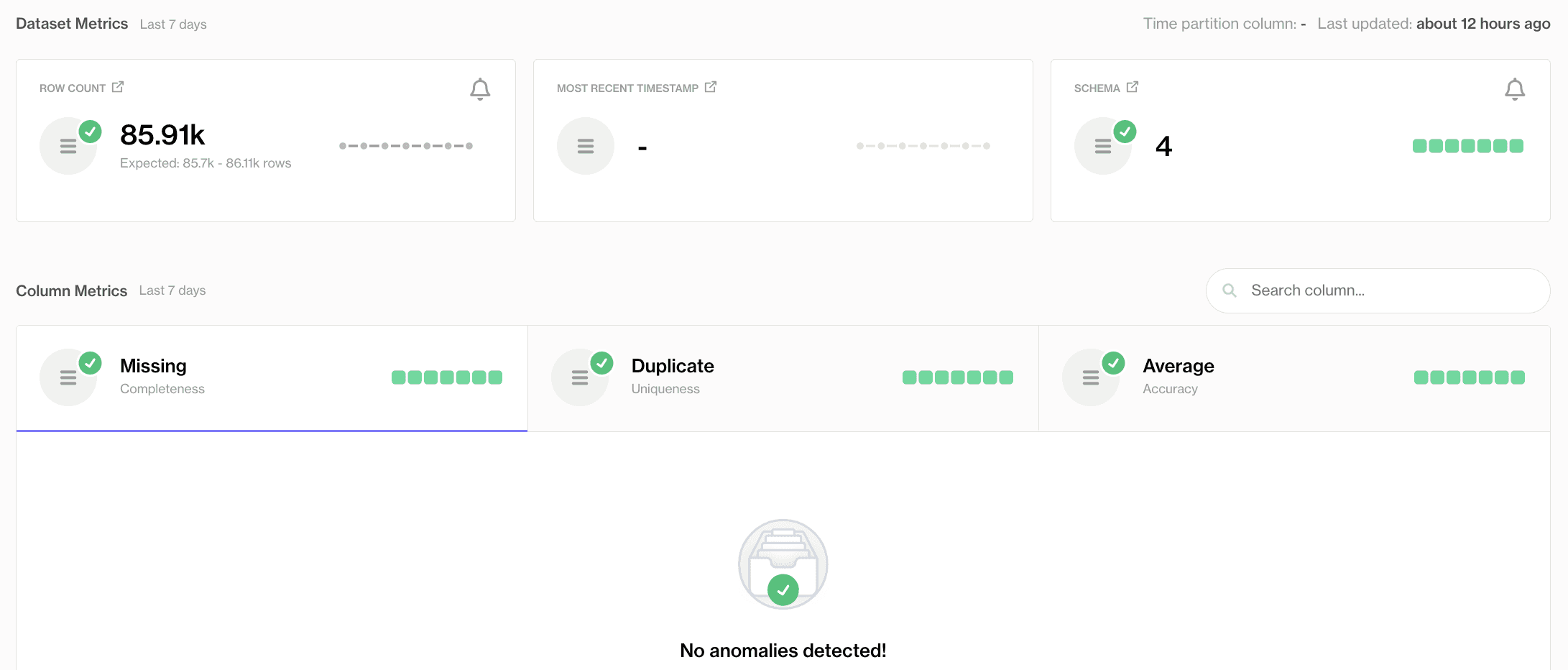
Chaque vérification a son propre tableau de bord ! Par exemple, nous pouvons zoomer sur une vérification spécifique, 'Valeurs Manquantes' du Tableau de Bord de l'Ensemble de Données précédent CUSTOMER_SATISFACTION. Ici, nous pouvons voir qu'il y avait une valeur manquante chaque jour pendant les quelques jours passés, mais elle a été résolue le 3/11/2025.
Le tableau de bord des métriques des valeurs manquantes
Les points rouges dans le graphique en ligne indiquent des échecs à chaque scan, facilitant la visualisation de la manière dont ce problème a été constant et n'a pas amélioré au fil du temps.
En dessous du graphique, dans l'onglet Analyse des Lignes Échouées, nous pouvons trouver des détails au niveau des lignes sur les enregistrements en échec. Si vous vous souvenez de la section précédente, c'est là que nous identifions les problèmes de valeurs manquantes après le premier échec de scan.
Hiérarchie des Tableaux de Bord de Surveillance Soda
Ceci devrait vous montrer comment zoomer sur des enregistrements de niveau de ligne spécifique à partir de la vue d'ensemble afin que vous puissiez avoir une meilleure compréhension de la hiérarchie des tableaux de bord de données Soda et de ce à quoi vous attendre pour votre cas d'utilisation spécifique. Commençons par le tableau de bord principal et voyons si nous pouvons trouver cette valeur manquante avec juste quelques clics! 😎
Observabilité des Anomalies
Il existe des problèmes de qualité de données qui ne peuvent être définis ou surveillés uniquement par des tests et une surveillance. Imaginez changer manuellement les seuils pour les 'comptes de lignes' appropriés chaque jour ou essayer de surveiller les changements de schéma légèrement différents à travers 100 tables.
Après tout, nous ne pouvons pas nous permettre de s'appuyer sur des seuils statiques et finir par être surpris par des anomalies inattendues.
Cela signifie que nous devons passer de la surveillance des tables une par une à leur observation toutes à la fois. Tous les nouveaux modèles qui émergent contre ce qui est 'normal', nous devons être prêts pour eux, et être préparés dès que possible.
C'est ce qu'on appelle l'Observabilité. Cela fonctionne indépendamment, en recherchant des anomalies qui pourraient être en dehors de notre vue immédiate. Soda y parvient en utilisant le machine learning pour observer les anomalies des données régulières et publie les résultats de détection sur le 'Tableau de Bord des Anomalies'.
Voici une liste de choses que le tableau de bord des anomalies nous aide à découvrir, à titre d'exemple :
Repérer les changements silencieux – Une diminution progressive du nombre de lignes ou des changements mineurs dans les colonnes numériques qui ne déclencheraient pas d'alertes de seuil basiques.
Découvrir des problèmes de données invisibles – Un nouveau flux de données a introduit des doublons subtils qui sont passés inaperçus.
Offrir un contexte plus approfondi – Le tableau de bord fournit une répartition des anomalies de niveau de colonne sur la semaine dernière afin que vous puissiez voir exactement quelles colonnes ou lignes nécessitent votre attention.
Le Tableau de Bord des Anomalies : Une Vue Approfondie
Le tableau de bord des anomalies détecte les anomalies de manière autonome et partitionnera les données et commencera des scans quotidiens. Une fois activé, il créera automatiquement des contrôles de détection des anomalies sur votre ensemble de données pour surveiller les changements inhabituels.
Le tableau de bord des métriques des valeurs manquantes
Du départ, Soda configure trois vérifications principales au niveau de l'ensemble de données :
Changements de Volume de Lignes – Surveille les pics ou baisses inattendus dans le nombre de lignes.
Fraisure des Données – Nous alerte si de nouveaux enregistrements cessent soudainement d'arriver quand ils arriveraient normalement.
Évolution du Schéma – Flague les colonnes qui ont été ajoutées, supprimées, ou significativement modifiées.
En même temps, au niveau de la colonne, Soda garde un œil sur :
Valeurs Manquantes – Repère des augmentations anormales des entrées nulles.
Valeurs dupliquées – Détecte toute augmentation des lignes en double.
Valeurs Moyennes dans les Colonnes Numériques – Recherche des changements inattendus dans les moyennes.
Après une courte période d'entraînement, généralement autour de cinq jours, le moteur de machine learning de Soda aura une idée de ce à quoi ressemblent les données 'normales'. Ensuite, chaque fois qu'il détecte quelque chose d'inhabituel, il met en évidence le problème sur le tableau de bord des anomalies.
Nous pouvons configurer des notifications (via Slack, MS Teams, etc.) pour nous alerter en temps réel afin que nous puissions intervenir sur toute anomalie avant qu'elle ne cause de plus gros maux de tête en aval.
La Synergie de l'Observabilité, des Tests, et de la Surveillance
À première vue, l'Observabilité, les Tests E2E, et la Surveillance peuvent sembler séparés. Mais une fois que nous les unissons, nous débloquerons une synergie puissante qui mène à une gouvernance de données beaucoup plus efficace.
Une résolution idéale des problèmes de qualité des données :
C'est une matinée normale pour votre équipe de données lorsqu'une alerte Slack apparaît - une anomalie signalée par le moteur d'observabilité de Soda. Le système a remarqué un petit changement dans le volume des lignes qui n'a pas déclenché une alerte standard, et personne n'avait spécifiquement testé cela dans une vérification E2E.
Jenny, l'analyste des données et propriétaire du dataset, vérifie rapidement le Tableau de Bord des Anomalies pour voir quelles colonnes sont affectées.
Pendant ce temps, Dave, l'ingénieur des données, ouvre le tableau de bord de surveillance pour obtenir plus de détails des statistiques de niveau de colonne. Il a remarqué que la colonne contenait maintenant une nouvelle forme de duplication, avec le même texte répété plusieurs fois dans la même ligne - une anomalie au-delà de ce que les vérifications de tests et surveillance actuelles pourraient détecter.
Dave résout le problème à la source et ajuste le processus de transformation pour correspondre au nouveau changement, tandis que Jenny met à jour les vérifications de qualité des données existantes.
Après cela, Dave met à jour les nouvelles métriques de qualité des données pour le pipeline et effectue un nouveau test E2E. Avec la confirmation de Soda Scan de la correction, les tableaux de bord de surveillance et des anomalies restent verts pour le reste des mois. Au final, pas de surcommunication, du temps a été économisé pour tout le monde, et l'anomalie n'a pas affecté le pipeline en aval, la crise évitée.
Un rapide récapitulatif
La qualité des données n'est pas quelque chose que nous pouvons nous permettre de gérer de manière réactive. Les problèmes ne disparaîtront pas d'eux-mêmes, maintenant ou à l'avenir. Pour éviter les dette de données, nous devons repérer les problèmes rapidement, communiquer efficacement, et les résoudre en collaboration.
Imaginez un monde sans ingénieurs de données stressés ou plaintes constantes de la part des parties prenantes de l'entreprise. Tout le monde aurait plus de temps et d'énergie pour se concentrer sur ce qui compte vraiment. Au final, tout le monde gagne.
Les problèmes de qualité des données peuvent surgir n'importe où, parfois, nous ne savons pas ce qu'ils sont, où ils se produisent, ni quand ils pourraient apparaître. Cela rend nos correctifs réactifs, nous réparons les problèmes uniquement après les plaintes.
Plutôt que de tracer constamment la lignée et d'appliquer des correctifs en aval, nous pourrions toujours faire un pas en arrière et nous concentrer sur la détection précoce. Après tout, comprendre le problème est la première étape pour le résoudre.
Bien que nous ne puissions pas prédire chaque problème de qualité des données possible, nous savons où chercher et comment enquêter. En général, les problèmes de qualité des données peuvent être découverts par trois méthodes :
Développement du Pipeline – Problèmes détectés lors des tests de pipeline.
Métriques Prédéfinies – Problèmes connus suivis par des contrôles de qualité spécifiques ou des seuils.
Anomalies Cachées – Problèmes inattendus que les mesures standard ne couvrent pas mais peuvent être trouvés par la détection d'anomalies.
Cependant, ces trois angles ne suggèrent pas qu'un soit meilleur que l'autre. En fait, ils sont tous importants car chacun se concentre sur un aspect différent de la qualité des données, nous aidant à détecter les problèmes aussi tôt et aussi complètement que possible.
Causes courantes des problèmes de qualité des données et leurs méthodes de détection.
Les tests de qualité des données de bout en bout pendant le développement aident à identifier les problèmes tôt, évitant les problèmes en aval. La surveillance basée sur les métriques assure la cohérence en détectant les problèmes selon les métriques prédéfinies, tandis que l'observabilité dévoile les anomalies cachées que la surveillance traditionnelle pourrait manquer.
Dans ce blog, nous explorerons comment détecter efficacement les problèmes de qualité des données dans ces domaines en utilisant Soda, avec des exemples pratiques montrant comment ces méthodes fonctionnent ensemble pour créer des solutions proactives pour une meilleure gouvernance des données.
Avant de plonger, passons en revue quelques préparations nécessaires.
Rédaction de Vérifications de la Qualité des Données que Tout le Monde Veut Lire
Nous ne pouvons pas nous attendre à ce que tout le monde dans l'équipe comprenne SQL, mais cela signifie-t-il que la qualité des données devrait être réservée uniquement à ceux qui le font? Absolument pas. Assurer une bonne qualité des données est un effort d'équipe, et il est crucial que tout le monde reste sur la même longueur d'onde.
C'est pourquoi nous avons besoin d'une approche simple pour définir les attentes en matière de données afin que tout le monde puisse les comprendre. Soda Check Language (SodaCL) convient parfaitement : il est assez simple pour que les membres de l'équipe moins techniques le comprennent, mais suffisamment puissant pour que les développeurs le personnalisent.
Voici un petit exemple de comment rédiger une vérification de qualité des données pour un ensemble de données dim_customer. Dans les sections suivantes, nous verrons comment ces vérifications entrent en jeu dans divers flux de travail.
Structure d'une simple vérification SodaCL pour 'le nombre de lignes'
Test de la Qualité des Données de Bout en Bout avec Soda
Dans cette section, nous découvrirons comment valider et tester les données dans le pipeline de données avant qu'elles n'affectent la production avec les vérifications de qualité des données de Soda.
Les données circulent d'une étape à une autre dans un pipeline de données. Les tests de bout en bout (E2E) consistent à s'assurer que chaque étape du pipeline de données est fiable, du moment où les données arrivent dans l'entrepôt à celui où elles sont livrées à nos utilisateurs en aval.
Il est préférable de commencer les tests de qualité des données E2E aussi tôt que possible! Bien que nous puissions généralement gérer les problèmes de qualité des données à la source, ils peuvent être très difficiles à traiter s'ils surviennent plus tard.
Utiliser les vérifications de qualité des données de Soda avec SodaCL à chaque étape du pipeline de données aide à assurer la qualité des données et à maintenir le bon fonctionnement.
Ceci est particulièrement utile lorsque nous repérons des problèmes de qualité des données dans le pipeline en amont. Pour vous montrer comment cela fonctionne, j'ai créé un pipeline de données simple avec Airflow, où les données transitent de la base de données Snowflake, sont transformées avec DBT, et Soda exécute des vérifications de qualité des données entre chaque étape. Voici un aperçu rapide :
Pipeline de données Airflow DAG avec vérifications de qualité des données
Juste une petite remarque, cette section est un peu technique et longue, donc c'est super si vous savez déjà comment créer un pipeline de données, surtout avec le Airflow DAG. La démonstration se concentrera sur l'implémentation des scans de qualité des données Soda dans le pipeline de données Airflow, et elle commencera sous la condition que Snowflake soit connecté et configuré avec Airflow sur un système d'exploitation Windows.
Prérequis
Pour exécuter les vérifications de qualité des données Soda dans un pipeline de données, nous devons avoir la Soda Library installée, la configurer avec la source de données correspondante et spécifier quel type de vérifications nous voulons exécuter avec elle.
Installer Soda
Sous le répertoire projet actuel, dans notre cas 'Airflow_demo', créer un répertoire 'Soda' et créer un nouvel environnement virtuel.
Installer la bibliothèque Soda appropriée dans l'environnement virtuel en fonction de la source de données avec laquelle nous voulons travailler. Étant donné que j'utilise Snowflake, j'ai installé Soda avec
pip install -i https://pypi.cloud.soda.io soda-snowflake. Si vous utilisez un système d'exploitation différent ou devez configurer une autre source de données, veuillez vous référer à ce guide d'installation en conséquence.
La création de compte en libre-service pour Soda Cloud est temporairement suspendue tandis que nous préparons la disponibilité générale de plusieurs mises à jour majeures. Si vous souhaitez essayer Soda Cloud entre-temps, veuillez planifier un appel avec notre équipe d'experts, discuter de votre cas d'utilisation et commencer.
Configurer la Source de Données et Soda Cloud
Lorsque Soda doit exécuter des vérifications de qualité des données dans Airflow, il cherche un fichier configuration.yml pour trouver la source de données, ainsi qu'un autre fichier checks.yml contenant les vérifications de qualité des données que vous souhaitez effectuer. Assurez-vous que les deux fichiers sont préparés et enregistrés dans une structure similaire comme suit :
Dans le fichier configuration.yml, ajoutez les détails du compte Snowflake et les informations sur la source de données comme ceci, avec les détails du compte Soda Cloud à la fin :
data_source snowflake_db: type: snowflake connection: username: luca password: secret account: YOUR_SNOW_FLAKE_ACCOUNT database: ECOMMERCE_CUSTOMER_SATISFACTION warehouse: COMPUTE_WH role: ACCOUNTADMIN schema: CUSTOMER soda_cloud: host: cloud.soda.io api_key_id: secret api_key_secret
Spécifier les vérifications de qualité des données avec SodaCL
Dans le fichier checks.yml, nous écrirons les vérifications de qualité des données que Soda utilisera plus tard pour les exécuter sur notre ensemble de données. Écrire des vérifications est vraiment simple, comme ceci :
checks for CUSTOMER_SATISFACTION: - duplicate_count(ORDER_ID) = 0: name: No duplicate ORDER ID - missing_count(ORDER_ID) = 0: name: No missing ORDER ID - schema: warn: when schema changes: any name
J'ai inclus trois vérifications pour mon ensemble de données CUSTOMER_SATISFACTION : une vérification de duplication, un décompte des valeurs manquantes pour la colonne ORDER_ID, et une vérification du schéma qui nous alertera s'il y a des changements aux colonnes à l'avenir. Vous pouvez également découvrir plus de vérifications ou créer les vôtres en suivant les instructions dans cette documentation.
Enfin, dans la ligne de commande, tapons soda test-connection -d snowflake_db -c configuration.yml pour lancer un test et voir si Soda est connecté à ma source de données et fonctionne correctement.
Ayant tous les configurations en place, notre prochaine étape est d'intégrer Soda dans le pipeline Airflow.
Définir un Scan Soda dans DAG
Pour utiliser Soda avec notre pipeline de données Airflow, nous devons démarrer un workflow de Scan Soda dans un Airflow DAG. Dans un workflow de Scan Soda, Soda trouvera la source de données, obtiendra les identifiants d'accès (du configuration.yml), décidera quelles vérifications (du checks.yml) effectuer sur l'ensemble de données et fournira ensuite les résultats complets du scan.
Voici comment nous pouvons y parvenir avec deux étapes principales : d'abord, créer une fonction Python pour le workflow du Scan Soda, et ensuite, créer un nouveau fichier DAG et appeler cette fonction avec le décorateur @task.
Étape 1 : Créez une fonction check() dans un nouveau fichier python check_function.py dans le dossier Soda pour configurer le workflow du Scan Soda :
# Invoke Soda library def check(scan_name, checks_subpath=None, data_source='snowflake_db', project_root='include'): from soda.scan import Scan # Soda needs both configuration & checks files to exectue the check config_file = f'{project_root}/soda/configuration.yml' checks_path = f'{project_root}/soda/checks.yml' if checks_subpath: checks_subpath += f'/{checks_subpath}' scan = Scan() scan.set_verbose() scan.add_configuration_yaml_file(config_file) scan.set_data_source_name(data_source) scan.add_sodacl_yaml_files(checks_path) scan.set_scan_definition_name(scan_name) result = scan.execute() print(scan.get_logs_text()) if result != 0: raise ValueError('Soda Scan failed'
Étape 2 : Créez un Airflow DAG qui appelle la fonction check() comme une tâche externe Python. Dans le fichier DAG, nous importons et invoquons la fonction check() comme ceci :
# DAG file: Import the check method from check_function.py def customer(): @task.external_python(python='/usr/local/airflow/soda_venv/bin/python') def check_customer(scan_name='check_customer', checks_subpath='tables', data_source='snowflake_db'): # check_function.py from the Soda folder from include.soda.check_function import check check(scan_name, checks_subpath, data_source) check_customer()
Votre dossier de travail devrait maintenant ressembler à ceci :
airflow_demo/ ├── dags/ │ ├── dag_soda.py #step 2 ├── Soda/ │ ├── check_function.py #step 1 │ ├── configuration.yml │ └── checks.yml
Arrêt de Pipeline 1 : Vérifications Pré-Transformation
Avec tout en place, nous pouvons déclencher le Airflow DAG avec le Scan Soda avant que les données n'atteignent l'étape de transformation. Dans ce processus, Soda scannera les données dans Snowflake et signalera tout ce qui ne répond pas aux règles de qualité que nous avons établies. Pensez à ceci comme notre première ligne de défense, attrapant tout problème évident avant qu'il n'affecte le reste du pipeline.
Vérifications de qualité des données avant la transformation de stade 2
Dès que le DAG a été déclenché, nous avons remarqué un avertissement d'échec dans le journal, nous informant que la vérification des valeurs manquantes pour la colonne ORDER_ID n'a pas réussi. Réfléchissez-y – si ces ID manquants passent inaperçus, les analyses en aval pourraient ne pas tenir compte de ces enregistrements, ce qui pourrait affecter notre rapport sur les volumes de commande ou la satisfaction client. Cela montre vraiment à quel point une bonne qualité des données est importante et constitue un argument solide en faveur des tests E2E. Après que la première vérification a été lancée, nous avons obtenu les avertissements suivants dans le terminal :
Oups! 1 échec. 0 avertissements. 0 erreurs. 2 réussites.
Le drapeau montre qu'il y a des valeurs manquantes dans la table sous la colonne ORDER_ID. Pour résoudre cela, nous pouvons accéder à l'interface utilisateur de Soda Cloud pour obtenir plus de détails sur les lignes de cette colonne particulière :
Analyse des lignes manquantes de l'interface utilisateur de Soda Cloud
Grâce aux informations de l'Analyse des Lignes Échouées, nous pouvons trouver tous les enregistrements qui n'ont pas réussi à passer la vérification des valeurs manquantes. Cette information arrive en temps voulu, nous permettant de résoudre le problème dès les premiers stades. En conséquence, comme nous voulons nous assurer que tous les retours d'ordre client soient examinés et analysés plus tard, cela nous aide également à éviter les problèmes lors du processus de transformation.
Pour une résolution rapide du problème, nous pouvons soit essayer de récupérer des enregistrements manquants de la source, supprimer ces entrées de la table, ou augmenter la tolérance pour les valeurs manquantes. À des fins de démonstration, je choisis d'augmenter les seuils de tolérance et de permettre des enregistrements supplémentaires de 5 % sans ORDER_ID dans le fichier checks.yml précédent, pour vous montrer comment cela fonctionnerait :
- missing_percentage(ORDER_ID) = 5%: name
Lancez à nouveau le DAG, et sans surprise, nous obtenons la notification suivante affichant dans le terminal :
Tout est bon. Pas de défaillance. Pas d'avertissement. Pas d'erreurs.
Arrêt de Pipeline 2 : Transformation dbt
Maintenant que nous avons les données brutes vérifiées et validées, il est temps de lancer une transformation dbt dans le DAG. À ce stade, dbt fait sa magie habituelle – comme joindre des tables et appliquer des règles métier – afin que nous puissions préparer les données pour l'analyse ou le machine learning.
Dans cet exemple, le travail de dbt est de créer un modèle de données qui génère une nouvelle table basée sur celle d'origine. Cette nouvelle table RESPONSIVE_RATE devrait inclure une colonne RESPONSE_TIME_SECONDS pour suivre combien de temps il faut à un service client pour répondre aux demandes, mesuré en secondes.
Je ne rentrerai pas dans tous les détails concernant la rédaction des modèles dbt et le déclenchement du DAG, car ce n'est pas le point central de cette démonstration.
Avec le DAG Airflow déclenché, le scan préalablement défini intervient à nouveau (n'oublions pas que le scan Soda sera toujours déclenché puisqu'il s'agit de la première partie du DAG). Sans alertes cette fois-ci, nous pouvons trouver notre nouvelle table agrégée dans Snowflake !
Nouvelle table Responsive_Rate générée par la transformation dbt
Arrêt de Pipeline 3 : Vérifications Post-Transformation
Notre nouvelle table semble géniale, mais nous avons encore du travail à faire. Alors que dbt fait un excellent travail, il ne garantit pas que nos données sont de hautes normes. Il y a toujours une chance que quelque chose d'inattendu se produise.
Par exemple, après la transformation, nous aboutissons à une nouvelle table comportant la métrique response_time_seconds. Mais que se passe-t-il si cela mène à de nouveaux problèmes de qualité des données, comme des horodatages manquants, entraînant des enregistrements nuls ou invalides ?
Pour détecter ces problèmes potentiels, ajoutons quelques vérifications supplémentaires sur la qualité des données. Dans le même dossier appelé 'Soda', nous pouvons créer un nouveau fichier check_transform.yml qui contiendra des vérifications de qualité des données spécifiques pour cette table transformée :
checks for RESPONSIVE_RATE: - missing_count(RESPONSE_TIME_SECONDS) = 0: name: No missing response time - schema: warn: when schema changes: any name
Sauf pour les vérifications régulières du schéma, j'ai également inclus une nouvelle vérification des valeurs manquantes pour la nouvelle colonne RESPONSE_TIME_SECONDS. Après cela, nous pouvons répéter le processus similaire (vérification de la qualité des données à l'arrêt 1) et ajouter cette nouvelle tâche au DAG.
Maintenant, le fichier DAG aura un workflow complet comme suit :
Scan Soda → Transformation dbt → Scan Soda
# This is our dag workflow @dag( start_date=datetime(2024, 3, 1), schedule='@daily', catchup=False, tags=["customer pipeline"], ) # The DAG workflow def customer(): # Pre-transformation Soda Scan @task.external_python(python='/usr/local/airflow/soda_venv/bin/python') def check_customer(scan_name='check_customer', checks_subpath='tables', data_source='snowflake_db'): from include.soda.check_function import check check(scan_name, checks_subpath, data_source) # dbt Transformation transform = DbtTaskGroup( group_id='transform', project_config=DBT_PROJECT_CONFIG, profile_config=DBT_CONFIG, render_config=RenderConfig( load_method=LoadMode.DBT_LS, select=['path:models/transform'] ) ) # Post-transformation Soda Scan @task.external_python(python='/usr/local/airflow/soda_venv/bin/python') def check_transform(scan_name='response_rate_check', checks_subpath='tables', data_source='snowflake_db'): from include.soda.check_function import check check(scan_name, checks_subpath, data_source)
Enfin, le DAG est à nouveau déclenché, et ce que nous aurons est ce joli graphique DAG dans Airflow montrant que tout a été exécuté avec succès! 🎉
Workflow d'exécution du DAG
De plus, nous pouvons explorer les résultats du scan de la nouvelle table dans l'interface Soda Cloud d'une manière holistique, où nos collègues peuvent également avoir accès. Je n'expliquerai pas les détails ici, car c'est le sujet de la prochaine section :)
Résultats du scan Soda pour le nouvel ensemble de données dans l'interface Soda Cloud
Une fois que tout est vérifié, les données sont prêtes à être utilisées, que ce soit pour un tableau de bord dans un outil BI ou pour entraîner un modèle de machine learning. Lorsque elles arrivent à ces systèmes, nous avons effectué plusieurs contrôles, réduisant considérablement les surprises et les problèmes de dernière minute.
Surveillance de la Qualité des Données en Action
Bien que les tests E2E soient excellents pour s'assurer que notre pipeline de données reste robuste pendant le développement et les changements, des problèmes de qualité des données peuvent encore surgir à tout moment. Il est important de détecter ces problèmes rapidement et de les résoudre avant qu'ils ne causent des problèmes en aval.
Après tout, la qualité des données nécessite une assurance à long terme.
Soda surveille la qualité des données avec des règles, des seuils, et des tableaux de bord—comme ceux que nous allons explorer dans l'interface Soda Cloud UI—pour mesurer la santé de la qualité des données. Si une métrique dépasse un seuil prédéfini (par exemple, si le nombre de lignes traitées chute en dessous d'une référence connue) ou un changement de schéma simple, nous recevrons une alerte immédiatement.
Métriques, Seuils, et Stratégie d'Alertes
Rappelez-vous le nouvel ensemble de données responsive_rate que nous avons généré avec le DAG auparavant ? Il fournit de nouvelles informations sur le temps qu'il faut habituellement à un représentant du service client pour répondre à et résoudre les problèmes des clients.
D'un point de vue analytique, il serait bénéfique de s'assurer qu'aucun temps de réponse d'un représentant client ne soit négatif. C'est une nouvelle métrique de qualité des données que nous avons l'intention d'ajouter maintenant, mais qui n'était pas incluse lors de nos tests de bout en bout.
De plus, nous aimerions recevoir une alerte lorsque le nombre total de ces enregistrements invalides dépasse 2 %. Voyons comment nous pouvons y parvenir dans le tableau de bord de Soda!
Dans l'interface Soda Cloud UI, si nous trouvons le tableau de bord de l'ensemble de données, nous pourrons y trouver plusieurs vérifications prédéfinies de Soda, ainsi que des vérifications SQL personnalisables.
Ajout de la vérification de Validité prédéfinie
Pratiquement, nous pouvons définir une règle de validité (montrée comme suit) avec la vérification prédéfinie appelée 'Validité', où nous fixons la valeur de validité min à 0—donc tout ce qui est négatif est flaggé comme étant une valeur invalide. De plus, nous modifions notre niveau de tolérance aux valeurs invalides et recevons une alerte lorsque le nombre total de valeurs invalides atteint 2 % du total des enregistrements. Ainsi, le propriétaire des données peut corriger les erreurs à temps pour éviter d'autres problèmes en aval.
Ajout de la vérification de Validité prédéfinie
Une fois que nous avons configuré toutes les vérifications, avec les seuils et les alertes prêts à fonctionner, nous pouvons surveiller la santé de la qualité des données sur tous les ensembles de données avec des tableaux de bord, où nous verrons des journaux, des alertes, et des tendances tout au même endroit, sans avoir à deviner.
La plateforme Soda Cloud UI offre trois tableaux de bord avec trois niveaux de granularité :
Tableau de Bord Principal surveille l'état général de la source de données
Tableau de Bord de l'Ensemble de Données surveille un ensemble de données spécifique
Tableau de Bord des Métriques pour chaque vérification de la qualité des données.
Découvrons ensemble ces tableaux de bord, un par un.
Tableau de Bord Principal
Ce tableau de bord est notre vue d'ensemble des toutes les vérifications à travers un ou plusieurs ensembles de données. D'un coup d'œil, nous pouvons voir que nous avons 1 vérification qui a échoué au cours des 90 derniers jours, 0 vérification qui nécessite de l'attention et un score global de santé des données de 83 % de santé des données.
Ajout de la vérification de Validité prédéfinie
Remarquez comment chaque barre verticale représente une exécution de vérification à un moment donné :
vert pour réussi, rouge pour échoué, et jaune pour avertissements. Si vous passez votre souris sur les barres, vous pouvez voir combien de vérifications passent, nécessitent de l'attention ou échouent et doivent être résolues immédiatement. Comme celle-ci :
Aussi, l'option filtres nous aide à regrouper des ensembles de données spécifiques et nous permet de suivre toutes les vérifications qui ont été exécutées sur ceux-ci. Ici, le tableau de bord principal montre toutes les métriques en combinant les deux ensembles de données que nous avons mentionnés auparavant, l'ensemble de données original CUSTOMER_SATISFACTION, et RESPONSIVE_RATE.
Tableau de Bord de l'Ensemble de Données
Cette vue de tableau de bord offre un résumé en un coup d'œil de la santé de l'ensemble de données. S'il y a un signal d'alarme, tel que des valeurs manquantes, nous pouvons approfondir pour voir exactement quelles lignes ou colonnes ont déclenché l'échec, nous faisant gagner des heures de conjectures.
Ajout de la vérification de Validité prédéfinie
Nous pouvons également surveiller d'autres métriques :
Couverture des Vérifications (6) – Le nombre total de vérifications de qualité des données configurées pour cet ensemble de données.
Santé (100 %) – Un score visuel rapide indiquant le taux de réussite/échec global des vérifications récentes.
Incidents – Une grille de type calendrier affichant les jours où les vérifications ont échoué, réussi ou ont généré des avertissements.
En dessous, il y a une liste détaillée de chaque vérification. Dans cet exemple :
Doublons : Zéro doublons, donc cette vérification est verte et réussie.
Valeurs manquantes : Nous avons détecté des valeurs manquantes il y a plusieurs jours, ce qui explique pourquoi cette vérification a des indicateurs d'état d'échec rouge.
De plus, en utilisant l'option 'Colonne' depuis le panneau supérieur, nous pouvons examiner de plus près les détails de niveau de colonne. Ici, nous pouvons explorer chaque colonne pour rassembler des informations plus détaillées, fournissant des informations telles que des statistiques de base et identifiant des valeurs fréquentes et extrêmes.
Informations sur le niveau des colonnes de l'ensemble de données: customer_satisfaction
Tableau de Bord des Métriques
Chaque vérification a son propre tableau de bord ! Par exemple, nous pouvons zoomer sur une vérification spécifique, 'Valeurs Manquantes' du Tableau de Bord de l'Ensemble de Données précédent CUSTOMER_SATISFACTION. Ici, nous pouvons voir qu'il y avait une valeur manquante chaque jour pendant les quelques jours passés, mais elle a été résolue le 3/11/2025.
Le tableau de bord des métriques des valeurs manquantes
Les points rouges dans le graphique en ligne indiquent des échecs à chaque scan, facilitant la visualisation de la manière dont ce problème a été constant et n'a pas amélioré au fil du temps.
En dessous du graphique, dans l'onglet Analyse des Lignes Échouées, nous pouvons trouver des détails au niveau des lignes sur les enregistrements en échec. Si vous vous souvenez de la section précédente, c'est là que nous identifions les problèmes de valeurs manquantes après le premier échec de scan.
Hiérarchie des Tableaux de Bord de Surveillance Soda
Ceci devrait vous montrer comment zoomer sur des enregistrements de niveau de ligne spécifique à partir de la vue d'ensemble afin que vous puissiez avoir une meilleure compréhension de la hiérarchie des tableaux de bord de données Soda et de ce à quoi vous attendre pour votre cas d'utilisation spécifique. Commençons par le tableau de bord principal et voyons si nous pouvons trouver cette valeur manquante avec juste quelques clics! 😎
Observabilité des Anomalies
Il existe des problèmes de qualité de données qui ne peuvent être définis ou surveillés uniquement par des tests et une surveillance. Imaginez changer manuellement les seuils pour les 'comptes de lignes' appropriés chaque jour ou essayer de surveiller les changements de schéma légèrement différents à travers 100 tables.
Après tout, nous ne pouvons pas nous permettre de s'appuyer sur des seuils statiques et finir par être surpris par des anomalies inattendues.
Cela signifie que nous devons passer de la surveillance des tables une par une à leur observation toutes à la fois. Tous les nouveaux modèles qui émergent contre ce qui est 'normal', nous devons être prêts pour eux, et être préparés dès que possible.
C'est ce qu'on appelle l'Observabilité. Cela fonctionne indépendamment, en recherchant des anomalies qui pourraient être en dehors de notre vue immédiate. Soda y parvient en utilisant le machine learning pour observer les anomalies des données régulières et publie les résultats de détection sur le 'Tableau de Bord des Anomalies'.
Voici une liste de choses que le tableau de bord des anomalies nous aide à découvrir, à titre d'exemple :
Repérer les changements silencieux – Une diminution progressive du nombre de lignes ou des changements mineurs dans les colonnes numériques qui ne déclencheraient pas d'alertes de seuil basiques.
Découvrir des problèmes de données invisibles – Un nouveau flux de données a introduit des doublons subtils qui sont passés inaperçus.
Offrir un contexte plus approfondi – Le tableau de bord fournit une répartition des anomalies de niveau de colonne sur la semaine dernière afin que vous puissiez voir exactement quelles colonnes ou lignes nécessitent votre attention.
Le Tableau de Bord des Anomalies : Une Vue Approfondie
Le tableau de bord des anomalies détecte les anomalies de manière autonome et partitionnera les données et commencera des scans quotidiens. Une fois activé, il créera automatiquement des contrôles de détection des anomalies sur votre ensemble de données pour surveiller les changements inhabituels.
Le tableau de bord des métriques des valeurs manquantes
Du départ, Soda configure trois vérifications principales au niveau de l'ensemble de données :
Changements de Volume de Lignes – Surveille les pics ou baisses inattendus dans le nombre de lignes.
Fraisure des Données – Nous alerte si de nouveaux enregistrements cessent soudainement d'arriver quand ils arriveraient normalement.
Évolution du Schéma – Flague les colonnes qui ont été ajoutées, supprimées, ou significativement modifiées.
En même temps, au niveau de la colonne, Soda garde un œil sur :
Valeurs Manquantes – Repère des augmentations anormales des entrées nulles.
Valeurs dupliquées – Détecte toute augmentation des lignes en double.
Valeurs Moyennes dans les Colonnes Numériques – Recherche des changements inattendus dans les moyennes.
Après une courte période d'entraînement, généralement autour de cinq jours, le moteur de machine learning de Soda aura une idée de ce à quoi ressemblent les données 'normales'. Ensuite, chaque fois qu'il détecte quelque chose d'inhabituel, il met en évidence le problème sur le tableau de bord des anomalies.
Nous pouvons configurer des notifications (via Slack, MS Teams, etc.) pour nous alerter en temps réel afin que nous puissions intervenir sur toute anomalie avant qu'elle ne cause de plus gros maux de tête en aval.
La Synergie de l'Observabilité, des Tests, et de la Surveillance
À première vue, l'Observabilité, les Tests E2E, et la Surveillance peuvent sembler séparés. Mais une fois que nous les unissons, nous débloquerons une synergie puissante qui mène à une gouvernance de données beaucoup plus efficace.
Une résolution idéale des problèmes de qualité des données :
C'est une matinée normale pour votre équipe de données lorsqu'une alerte Slack apparaît - une anomalie signalée par le moteur d'observabilité de Soda. Le système a remarqué un petit changement dans le volume des lignes qui n'a pas déclenché une alerte standard, et personne n'avait spécifiquement testé cela dans une vérification E2E.
Jenny, l'analyste des données et propriétaire du dataset, vérifie rapidement le Tableau de Bord des Anomalies pour voir quelles colonnes sont affectées.
Pendant ce temps, Dave, l'ingénieur des données, ouvre le tableau de bord de surveillance pour obtenir plus de détails des statistiques de niveau de colonne. Il a remarqué que la colonne contenait maintenant une nouvelle forme de duplication, avec le même texte répété plusieurs fois dans la même ligne - une anomalie au-delà de ce que les vérifications de tests et surveillance actuelles pourraient détecter.
Dave résout le problème à la source et ajuste le processus de transformation pour correspondre au nouveau changement, tandis que Jenny met à jour les vérifications de qualité des données existantes.
Après cela, Dave met à jour les nouvelles métriques de qualité des données pour le pipeline et effectue un nouveau test E2E. Avec la confirmation de Soda Scan de la correction, les tableaux de bord de surveillance et des anomalies restent verts pour le reste des mois. Au final, pas de surcommunication, du temps a été économisé pour tout le monde, et l'anomalie n'a pas affecté le pipeline en aval, la crise évitée.
Un rapide récapitulatif
La qualité des données n'est pas quelque chose que nous pouvons nous permettre de gérer de manière réactive. Les problèmes ne disparaîtront pas d'eux-mêmes, maintenant ou à l'avenir. Pour éviter les dette de données, nous devons repérer les problèmes rapidement, communiquer efficacement, et les résoudre en collaboration.
Imaginez un monde sans ingénieurs de données stressés ou plaintes constantes de la part des parties prenantes de l'entreprise. Tout le monde aurait plus de temps et d'énergie pour se concentrer sur ce qui compte vraiment. Au final, tout le monde gagne.
Les problèmes de qualité des données peuvent surgir n'importe où, parfois, nous ne savons pas ce qu'ils sont, où ils se produisent, ni quand ils pourraient apparaître. Cela rend nos correctifs réactifs, nous réparons les problèmes uniquement après les plaintes.
Plutôt que de tracer constamment la lignée et d'appliquer des correctifs en aval, nous pourrions toujours faire un pas en arrière et nous concentrer sur la détection précoce. Après tout, comprendre le problème est la première étape pour le résoudre.
Bien que nous ne puissions pas prédire chaque problème de qualité des données possible, nous savons où chercher et comment enquêter. En général, les problèmes de qualité des données peuvent être découverts par trois méthodes :
Développement du Pipeline – Problèmes détectés lors des tests de pipeline.
Métriques Prédéfinies – Problèmes connus suivis par des contrôles de qualité spécifiques ou des seuils.
Anomalies Cachées – Problèmes inattendus que les mesures standard ne couvrent pas mais peuvent être trouvés par la détection d'anomalies.
Cependant, ces trois angles ne suggèrent pas qu'un soit meilleur que l'autre. En fait, ils sont tous importants car chacun se concentre sur un aspect différent de la qualité des données, nous aidant à détecter les problèmes aussi tôt et aussi complètement que possible.
Causes courantes des problèmes de qualité des données et leurs méthodes de détection.
Les tests de qualité des données de bout en bout pendant le développement aident à identifier les problèmes tôt, évitant les problèmes en aval. La surveillance basée sur les métriques assure la cohérence en détectant les problèmes selon les métriques prédéfinies, tandis que l'observabilité dévoile les anomalies cachées que la surveillance traditionnelle pourrait manquer.
Dans ce blog, nous explorerons comment détecter efficacement les problèmes de qualité des données dans ces domaines en utilisant Soda, avec des exemples pratiques montrant comment ces méthodes fonctionnent ensemble pour créer des solutions proactives pour une meilleure gouvernance des données.
Avant de plonger, passons en revue quelques préparations nécessaires.
Rédaction de Vérifications de la Qualité des Données que Tout le Monde Veut Lire
Nous ne pouvons pas nous attendre à ce que tout le monde dans l'équipe comprenne SQL, mais cela signifie-t-il que la qualité des données devrait être réservée uniquement à ceux qui le font? Absolument pas. Assurer une bonne qualité des données est un effort d'équipe, et il est crucial que tout le monde reste sur la même longueur d'onde.
C'est pourquoi nous avons besoin d'une approche simple pour définir les attentes en matière de données afin que tout le monde puisse les comprendre. Soda Check Language (SodaCL) convient parfaitement : il est assez simple pour que les membres de l'équipe moins techniques le comprennent, mais suffisamment puissant pour que les développeurs le personnalisent.
Voici un petit exemple de comment rédiger une vérification de qualité des données pour un ensemble de données dim_customer. Dans les sections suivantes, nous verrons comment ces vérifications entrent en jeu dans divers flux de travail.
Structure d'une simple vérification SodaCL pour 'le nombre de lignes'
Test de la Qualité des Données de Bout en Bout avec Soda
Dans cette section, nous découvrirons comment valider et tester les données dans le pipeline de données avant qu'elles n'affectent la production avec les vérifications de qualité des données de Soda.
Les données circulent d'une étape à une autre dans un pipeline de données. Les tests de bout en bout (E2E) consistent à s'assurer que chaque étape du pipeline de données est fiable, du moment où les données arrivent dans l'entrepôt à celui où elles sont livrées à nos utilisateurs en aval.
Il est préférable de commencer les tests de qualité des données E2E aussi tôt que possible! Bien que nous puissions généralement gérer les problèmes de qualité des données à la source, ils peuvent être très difficiles à traiter s'ils surviennent plus tard.
Utiliser les vérifications de qualité des données de Soda avec SodaCL à chaque étape du pipeline de données aide à assurer la qualité des données et à maintenir le bon fonctionnement.
Ceci est particulièrement utile lorsque nous repérons des problèmes de qualité des données dans le pipeline en amont. Pour vous montrer comment cela fonctionne, j'ai créé un pipeline de données simple avec Airflow, où les données transitent de la base de données Snowflake, sont transformées avec DBT, et Soda exécute des vérifications de qualité des données entre chaque étape. Voici un aperçu rapide :
Pipeline de données Airflow DAG avec vérifications de qualité des données
Juste une petite remarque, cette section est un peu technique et longue, donc c'est super si vous savez déjà comment créer un pipeline de données, surtout avec le Airflow DAG. La démonstration se concentrera sur l'implémentation des scans de qualité des données Soda dans le pipeline de données Airflow, et elle commencera sous la condition que Snowflake soit connecté et configuré avec Airflow sur un système d'exploitation Windows.
Prérequis
Pour exécuter les vérifications de qualité des données Soda dans un pipeline de données, nous devons avoir la Soda Library installée, la configurer avec la source de données correspondante et spécifier quel type de vérifications nous voulons exécuter avec elle.
Installer Soda
Sous le répertoire projet actuel, dans notre cas 'Airflow_demo', créer un répertoire 'Soda' et créer un nouvel environnement virtuel.
Installer la bibliothèque Soda appropriée dans l'environnement virtuel en fonction de la source de données avec laquelle nous voulons travailler. Étant donné que j'utilise Snowflake, j'ai installé Soda avec
pip install -i https://pypi.cloud.soda.io soda-snowflake. Si vous utilisez un système d'exploitation différent ou devez configurer une autre source de données, veuillez vous référer à ce guide d'installation en conséquence.
La création de compte en libre-service pour Soda Cloud est temporairement suspendue tandis que nous préparons la disponibilité générale de plusieurs mises à jour majeures. Si vous souhaitez essayer Soda Cloud entre-temps, veuillez planifier un appel avec notre équipe d'experts, discuter de votre cas d'utilisation et commencer.
Configurer la Source de Données et Soda Cloud
Lorsque Soda doit exécuter des vérifications de qualité des données dans Airflow, il cherche un fichier configuration.yml pour trouver la source de données, ainsi qu'un autre fichier checks.yml contenant les vérifications de qualité des données que vous souhaitez effectuer. Assurez-vous que les deux fichiers sont préparés et enregistrés dans une structure similaire comme suit :
Dans le fichier configuration.yml, ajoutez les détails du compte Snowflake et les informations sur la source de données comme ceci, avec les détails du compte Soda Cloud à la fin :
data_source snowflake_db: type: snowflake connection: username: luca password: secret account: YOUR_SNOW_FLAKE_ACCOUNT database: ECOMMERCE_CUSTOMER_SATISFACTION warehouse: COMPUTE_WH role: ACCOUNTADMIN schema: CUSTOMER soda_cloud: host: cloud.soda.io api_key_id: secret api_key_secret
Spécifier les vérifications de qualité des données avec SodaCL
Dans le fichier checks.yml, nous écrirons les vérifications de qualité des données que Soda utilisera plus tard pour les exécuter sur notre ensemble de données. Écrire des vérifications est vraiment simple, comme ceci :
checks for CUSTOMER_SATISFACTION: - duplicate_count(ORDER_ID) = 0: name: No duplicate ORDER ID - missing_count(ORDER_ID) = 0: name: No missing ORDER ID - schema: warn: when schema changes: any name
J'ai inclus trois vérifications pour mon ensemble de données CUSTOMER_SATISFACTION : une vérification de duplication, un décompte des valeurs manquantes pour la colonne ORDER_ID, et une vérification du schéma qui nous alertera s'il y a des changements aux colonnes à l'avenir. Vous pouvez également découvrir plus de vérifications ou créer les vôtres en suivant les instructions dans cette documentation.
Enfin, dans la ligne de commande, tapons soda test-connection -d snowflake_db -c configuration.yml pour lancer un test et voir si Soda est connecté à ma source de données et fonctionne correctement.
Ayant tous les configurations en place, notre prochaine étape est d'intégrer Soda dans le pipeline Airflow.
Définir un Scan Soda dans DAG
Pour utiliser Soda avec notre pipeline de données Airflow, nous devons démarrer un workflow de Scan Soda dans un Airflow DAG. Dans un workflow de Scan Soda, Soda trouvera la source de données, obtiendra les identifiants d'accès (du configuration.yml), décidera quelles vérifications (du checks.yml) effectuer sur l'ensemble de données et fournira ensuite les résultats complets du scan.
Voici comment nous pouvons y parvenir avec deux étapes principales : d'abord, créer une fonction Python pour le workflow du Scan Soda, et ensuite, créer un nouveau fichier DAG et appeler cette fonction avec le décorateur @task.
Étape 1 : Créez une fonction check() dans un nouveau fichier python check_function.py dans le dossier Soda pour configurer le workflow du Scan Soda :
# Invoke Soda library def check(scan_name, checks_subpath=None, data_source='snowflake_db', project_root='include'): from soda.scan import Scan # Soda needs both configuration & checks files to exectue the check config_file = f'{project_root}/soda/configuration.yml' checks_path = f'{project_root}/soda/checks.yml' if checks_subpath: checks_subpath += f'/{checks_subpath}' scan = Scan() scan.set_verbose() scan.add_configuration_yaml_file(config_file) scan.set_data_source_name(data_source) scan.add_sodacl_yaml_files(checks_path) scan.set_scan_definition_name(scan_name) result = scan.execute() print(scan.get_logs_text()) if result != 0: raise ValueError('Soda Scan failed'
Étape 2 : Créez un Airflow DAG qui appelle la fonction check() comme une tâche externe Python. Dans le fichier DAG, nous importons et invoquons la fonction check() comme ceci :
# DAG file: Import the check method from check_function.py def customer(): @task.external_python(python='/usr/local/airflow/soda_venv/bin/python') def check_customer(scan_name='check_customer', checks_subpath='tables', data_source='snowflake_db'): # check_function.py from the Soda folder from include.soda.check_function import check check(scan_name, checks_subpath, data_source) check_customer()
Votre dossier de travail devrait maintenant ressembler à ceci :
airflow_demo/ ├── dags/ │ ├── dag_soda.py #step 2 ├── Soda/ │ ├── check_function.py #step 1 │ ├── configuration.yml │ └── checks.yml
Arrêt de Pipeline 1 : Vérifications Pré-Transformation
Avec tout en place, nous pouvons déclencher le Airflow DAG avec le Scan Soda avant que les données n'atteignent l'étape de transformation. Dans ce processus, Soda scannera les données dans Snowflake et signalera tout ce qui ne répond pas aux règles de qualité que nous avons établies. Pensez à ceci comme notre première ligne de défense, attrapant tout problème évident avant qu'il n'affecte le reste du pipeline.
Vérifications de qualité des données avant la transformation de stade 2
Dès que le DAG a été déclenché, nous avons remarqué un avertissement d'échec dans le journal, nous informant que la vérification des valeurs manquantes pour la colonne ORDER_ID n'a pas réussi. Réfléchissez-y – si ces ID manquants passent inaperçus, les analyses en aval pourraient ne pas tenir compte de ces enregistrements, ce qui pourrait affecter notre rapport sur les volumes de commande ou la satisfaction client. Cela montre vraiment à quel point une bonne qualité des données est importante et constitue un argument solide en faveur des tests E2E. Après que la première vérification a été lancée, nous avons obtenu les avertissements suivants dans le terminal :
Oups! 1 échec. 0 avertissements. 0 erreurs. 2 réussites.
Le drapeau montre qu'il y a des valeurs manquantes dans la table sous la colonne ORDER_ID. Pour résoudre cela, nous pouvons accéder à l'interface utilisateur de Soda Cloud pour obtenir plus de détails sur les lignes de cette colonne particulière :
Analyse des lignes manquantes de l'interface utilisateur de Soda Cloud
Grâce aux informations de l'Analyse des Lignes Échouées, nous pouvons trouver tous les enregistrements qui n'ont pas réussi à passer la vérification des valeurs manquantes. Cette information arrive en temps voulu, nous permettant de résoudre le problème dès les premiers stades. En conséquence, comme nous voulons nous assurer que tous les retours d'ordre client soient examinés et analysés plus tard, cela nous aide également à éviter les problèmes lors du processus de transformation.
Pour une résolution rapide du problème, nous pouvons soit essayer de récupérer des enregistrements manquants de la source, supprimer ces entrées de la table, ou augmenter la tolérance pour les valeurs manquantes. À des fins de démonstration, je choisis d'augmenter les seuils de tolérance et de permettre des enregistrements supplémentaires de 5 % sans ORDER_ID dans le fichier checks.yml précédent, pour vous montrer comment cela fonctionnerait :
- missing_percentage(ORDER_ID) = 5%: name
Lancez à nouveau le DAG, et sans surprise, nous obtenons la notification suivante affichant dans le terminal :
Tout est bon. Pas de défaillance. Pas d'avertissement. Pas d'erreurs.
Arrêt de Pipeline 2 : Transformation dbt
Maintenant que nous avons les données brutes vérifiées et validées, il est temps de lancer une transformation dbt dans le DAG. À ce stade, dbt fait sa magie habituelle – comme joindre des tables et appliquer des règles métier – afin que nous puissions préparer les données pour l'analyse ou le machine learning.
Dans cet exemple, le travail de dbt est de créer un modèle de données qui génère une nouvelle table basée sur celle d'origine. Cette nouvelle table RESPONSIVE_RATE devrait inclure une colonne RESPONSE_TIME_SECONDS pour suivre combien de temps il faut à un service client pour répondre aux demandes, mesuré en secondes.
Je ne rentrerai pas dans tous les détails concernant la rédaction des modèles dbt et le déclenchement du DAG, car ce n'est pas le point central de cette démonstration.
Avec le DAG Airflow déclenché, le scan préalablement défini intervient à nouveau (n'oublions pas que le scan Soda sera toujours déclenché puisqu'il s'agit de la première partie du DAG). Sans alertes cette fois-ci, nous pouvons trouver notre nouvelle table agrégée dans Snowflake !
Nouvelle table Responsive_Rate générée par la transformation dbt
Arrêt de Pipeline 3 : Vérifications Post-Transformation
Notre nouvelle table semble géniale, mais nous avons encore du travail à faire. Alors que dbt fait un excellent travail, il ne garantit pas que nos données sont de hautes normes. Il y a toujours une chance que quelque chose d'inattendu se produise.
Par exemple, après la transformation, nous aboutissons à une nouvelle table comportant la métrique response_time_seconds. Mais que se passe-t-il si cela mène à de nouveaux problèmes de qualité des données, comme des horodatages manquants, entraînant des enregistrements nuls ou invalides ?
Pour détecter ces problèmes potentiels, ajoutons quelques vérifications supplémentaires sur la qualité des données. Dans le même dossier appelé 'Soda', nous pouvons créer un nouveau fichier check_transform.yml qui contiendra des vérifications de qualité des données spécifiques pour cette table transformée :
checks for RESPONSIVE_RATE: - missing_count(RESPONSE_TIME_SECONDS) = 0: name: No missing response time - schema: warn: when schema changes: any name
Sauf pour les vérifications régulières du schéma, j'ai également inclus une nouvelle vérification des valeurs manquantes pour la nouvelle colonne RESPONSE_TIME_SECONDS. Après cela, nous pouvons répéter le processus similaire (vérification de la qualité des données à l'arrêt 1) et ajouter cette nouvelle tâche au DAG.
Maintenant, le fichier DAG aura un workflow complet comme suit :
Scan Soda → Transformation dbt → Scan Soda
# This is our dag workflow @dag( start_date=datetime(2024, 3, 1), schedule='@daily', catchup=False, tags=["customer pipeline"], ) # The DAG workflow def customer(): # Pre-transformation Soda Scan @task.external_python(python='/usr/local/airflow/soda_venv/bin/python') def check_customer(scan_name='check_customer', checks_subpath='tables', data_source='snowflake_db'): from include.soda.check_function import check check(scan_name, checks_subpath, data_source) # dbt Transformation transform = DbtTaskGroup( group_id='transform', project_config=DBT_PROJECT_CONFIG, profile_config=DBT_CONFIG, render_config=RenderConfig( load_method=LoadMode.DBT_LS, select=['path:models/transform'] ) ) # Post-transformation Soda Scan @task.external_python(python='/usr/local/airflow/soda_venv/bin/python') def check_transform(scan_name='response_rate_check', checks_subpath='tables', data_source='snowflake_db'): from include.soda.check_function import check check(scan_name, checks_subpath, data_source)
Enfin, le DAG est à nouveau déclenché, et ce que nous aurons est ce joli graphique DAG dans Airflow montrant que tout a été exécuté avec succès! 🎉
Workflow d'exécution du DAG
De plus, nous pouvons explorer les résultats du scan de la nouvelle table dans l'interface Soda Cloud d'une manière holistique, où nos collègues peuvent également avoir accès. Je n'expliquerai pas les détails ici, car c'est le sujet de la prochaine section :)
Résultats du scan Soda pour le nouvel ensemble de données dans l'interface Soda Cloud
Une fois que tout est vérifié, les données sont prêtes à être utilisées, que ce soit pour un tableau de bord dans un outil BI ou pour entraîner un modèle de machine learning. Lorsque elles arrivent à ces systèmes, nous avons effectué plusieurs contrôles, réduisant considérablement les surprises et les problèmes de dernière minute.
Surveillance de la Qualité des Données en Action
Bien que les tests E2E soient excellents pour s'assurer que notre pipeline de données reste robuste pendant le développement et les changements, des problèmes de qualité des données peuvent encore surgir à tout moment. Il est important de détecter ces problèmes rapidement et de les résoudre avant qu'ils ne causent des problèmes en aval.
Après tout, la qualité des données nécessite une assurance à long terme.
Soda surveille la qualité des données avec des règles, des seuils, et des tableaux de bord—comme ceux que nous allons explorer dans l'interface Soda Cloud UI—pour mesurer la santé de la qualité des données. Si une métrique dépasse un seuil prédéfini (par exemple, si le nombre de lignes traitées chute en dessous d'une référence connue) ou un changement de schéma simple, nous recevrons une alerte immédiatement.
Métriques, Seuils, et Stratégie d'Alertes
Rappelez-vous le nouvel ensemble de données responsive_rate que nous avons généré avec le DAG auparavant ? Il fournit de nouvelles informations sur le temps qu'il faut habituellement à un représentant du service client pour répondre à et résoudre les problèmes des clients.
D'un point de vue analytique, il serait bénéfique de s'assurer qu'aucun temps de réponse d'un représentant client ne soit négatif. C'est une nouvelle métrique de qualité des données que nous avons l'intention d'ajouter maintenant, mais qui n'était pas incluse lors de nos tests de bout en bout.
De plus, nous aimerions recevoir une alerte lorsque le nombre total de ces enregistrements invalides dépasse 2 %. Voyons comment nous pouvons y parvenir dans le tableau de bord de Soda!
Dans l'interface Soda Cloud UI, si nous trouvons le tableau de bord de l'ensemble de données, nous pourrons y trouver plusieurs vérifications prédéfinies de Soda, ainsi que des vérifications SQL personnalisables.
Ajout de la vérification de Validité prédéfinie
Pratiquement, nous pouvons définir une règle de validité (montrée comme suit) avec la vérification prédéfinie appelée 'Validité', où nous fixons la valeur de validité min à 0—donc tout ce qui est négatif est flaggé comme étant une valeur invalide. De plus, nous modifions notre niveau de tolérance aux valeurs invalides et recevons une alerte lorsque le nombre total de valeurs invalides atteint 2 % du total des enregistrements. Ainsi, le propriétaire des données peut corriger les erreurs à temps pour éviter d'autres problèmes en aval.
Ajout de la vérification de Validité prédéfinie
Une fois que nous avons configuré toutes les vérifications, avec les seuils et les alertes prêts à fonctionner, nous pouvons surveiller la santé de la qualité des données sur tous les ensembles de données avec des tableaux de bord, où nous verrons des journaux, des alertes, et des tendances tout au même endroit, sans avoir à deviner.
La plateforme Soda Cloud UI offre trois tableaux de bord avec trois niveaux de granularité :
Tableau de Bord Principal surveille l'état général de la source de données
Tableau de Bord de l'Ensemble de Données surveille un ensemble de données spécifique
Tableau de Bord des Métriques pour chaque vérification de la qualité des données.
Découvrons ensemble ces tableaux de bord, un par un.
Tableau de Bord Principal
Ce tableau de bord est notre vue d'ensemble des toutes les vérifications à travers un ou plusieurs ensembles de données. D'un coup d'œil, nous pouvons voir que nous avons 1 vérification qui a échoué au cours des 90 derniers jours, 0 vérification qui nécessite de l'attention et un score global de santé des données de 83 % de santé des données.
Ajout de la vérification de Validité prédéfinie
Remarquez comment chaque barre verticale représente une exécution de vérification à un moment donné :
vert pour réussi, rouge pour échoué, et jaune pour avertissements. Si vous passez votre souris sur les barres, vous pouvez voir combien de vérifications passent, nécessitent de l'attention ou échouent et doivent être résolues immédiatement. Comme celle-ci :
Aussi, l'option filtres nous aide à regrouper des ensembles de données spécifiques et nous permet de suivre toutes les vérifications qui ont été exécutées sur ceux-ci. Ici, le tableau de bord principal montre toutes les métriques en combinant les deux ensembles de données que nous avons mentionnés auparavant, l'ensemble de données original CUSTOMER_SATISFACTION, et RESPONSIVE_RATE.
Tableau de Bord de l'Ensemble de Données
Cette vue de tableau de bord offre un résumé en un coup d'œil de la santé de l'ensemble de données. S'il y a un signal d'alarme, tel que des valeurs manquantes, nous pouvons approfondir pour voir exactement quelles lignes ou colonnes ont déclenché l'échec, nous faisant gagner des heures de conjectures.
Ajout de la vérification de Validité prédéfinie
Nous pouvons également surveiller d'autres métriques :
Couverture des Vérifications (6) – Le nombre total de vérifications de qualité des données configurées pour cet ensemble de données.
Santé (100 %) – Un score visuel rapide indiquant le taux de réussite/échec global des vérifications récentes.
Incidents – Une grille de type calendrier affichant les jours où les vérifications ont échoué, réussi ou ont généré des avertissements.
En dessous, il y a une liste détaillée de chaque vérification. Dans cet exemple :
Doublons : Zéro doublons, donc cette vérification est verte et réussie.
Valeurs manquantes : Nous avons détecté des valeurs manquantes il y a plusieurs jours, ce qui explique pourquoi cette vérification a des indicateurs d'état d'échec rouge.
De plus, en utilisant l'option 'Colonne' depuis le panneau supérieur, nous pouvons examiner de plus près les détails de niveau de colonne. Ici, nous pouvons explorer chaque colonne pour rassembler des informations plus détaillées, fournissant des informations telles que des statistiques de base et identifiant des valeurs fréquentes et extrêmes.
Informations sur le niveau des colonnes de l'ensemble de données: customer_satisfaction
Tableau de Bord des Métriques
Chaque vérification a son propre tableau de bord ! Par exemple, nous pouvons zoomer sur une vérification spécifique, 'Valeurs Manquantes' du Tableau de Bord de l'Ensemble de Données précédent CUSTOMER_SATISFACTION. Ici, nous pouvons voir qu'il y avait une valeur manquante chaque jour pendant les quelques jours passés, mais elle a été résolue le 3/11/2025.
Le tableau de bord des métriques des valeurs manquantes
Les points rouges dans le graphique en ligne indiquent des échecs à chaque scan, facilitant la visualisation de la manière dont ce problème a été constant et n'a pas amélioré au fil du temps.
En dessous du graphique, dans l'onglet Analyse des Lignes Échouées, nous pouvons trouver des détails au niveau des lignes sur les enregistrements en échec. Si vous vous souvenez de la section précédente, c'est là que nous identifions les problèmes de valeurs manquantes après le premier échec de scan.
Hiérarchie des Tableaux de Bord de Surveillance Soda
Ceci devrait vous montrer comment zoomer sur des enregistrements de niveau de ligne spécifique à partir de la vue d'ensemble afin que vous puissiez avoir une meilleure compréhension de la hiérarchie des tableaux de bord de données Soda et de ce à quoi vous attendre pour votre cas d'utilisation spécifique. Commençons par le tableau de bord principal et voyons si nous pouvons trouver cette valeur manquante avec juste quelques clics! 😎
Observabilité des Anomalies
Il existe des problèmes de qualité de données qui ne peuvent être définis ou surveillés uniquement par des tests et une surveillance. Imaginez changer manuellement les seuils pour les 'comptes de lignes' appropriés chaque jour ou essayer de surveiller les changements de schéma légèrement différents à travers 100 tables.
Après tout, nous ne pouvons pas nous permettre de s'appuyer sur des seuils statiques et finir par être surpris par des anomalies inattendues.
Cela signifie que nous devons passer de la surveillance des tables une par une à leur observation toutes à la fois. Tous les nouveaux modèles qui émergent contre ce qui est 'normal', nous devons être prêts pour eux, et être préparés dès que possible.
C'est ce qu'on appelle l'Observabilité. Cela fonctionne indépendamment, en recherchant des anomalies qui pourraient être en dehors de notre vue immédiate. Soda y parvient en utilisant le machine learning pour observer les anomalies des données régulières et publie les résultats de détection sur le 'Tableau de Bord des Anomalies'.
Voici une liste de choses que le tableau de bord des anomalies nous aide à découvrir, à titre d'exemple :
Repérer les changements silencieux – Une diminution progressive du nombre de lignes ou des changements mineurs dans les colonnes numériques qui ne déclencheraient pas d'alertes de seuil basiques.
Découvrir des problèmes de données invisibles – Un nouveau flux de données a introduit des doublons subtils qui sont passés inaperçus.
Offrir un contexte plus approfondi – Le tableau de bord fournit une répartition des anomalies de niveau de colonne sur la semaine dernière afin que vous puissiez voir exactement quelles colonnes ou lignes nécessitent votre attention.
Le Tableau de Bord des Anomalies : Une Vue Approfondie
Le tableau de bord des anomalies détecte les anomalies de manière autonome et partitionnera les données et commencera des scans quotidiens. Une fois activé, il créera automatiquement des contrôles de détection des anomalies sur votre ensemble de données pour surveiller les changements inhabituels.
Le tableau de bord des métriques des valeurs manquantes
Du départ, Soda configure trois vérifications principales au niveau de l'ensemble de données :
Changements de Volume de Lignes – Surveille les pics ou baisses inattendus dans le nombre de lignes.
Fraisure des Données – Nous alerte si de nouveaux enregistrements cessent soudainement d'arriver quand ils arriveraient normalement.
Évolution du Schéma – Flague les colonnes qui ont été ajoutées, supprimées, ou significativement modifiées.
En même temps, au niveau de la colonne, Soda garde un œil sur :
Valeurs Manquantes – Repère des augmentations anormales des entrées nulles.
Valeurs dupliquées – Détecte toute augmentation des lignes en double.
Valeurs Moyennes dans les Colonnes Numériques – Recherche des changements inattendus dans les moyennes.
Après une courte période d'entraînement, généralement autour de cinq jours, le moteur de machine learning de Soda aura une idée de ce à quoi ressemblent les données 'normales'. Ensuite, chaque fois qu'il détecte quelque chose d'inhabituel, il met en évidence le problème sur le tableau de bord des anomalies.
Nous pouvons configurer des notifications (via Slack, MS Teams, etc.) pour nous alerter en temps réel afin que nous puissions intervenir sur toute anomalie avant qu'elle ne cause de plus gros maux de tête en aval.
La Synergie de l'Observabilité, des Tests, et de la Surveillance
À première vue, l'Observabilité, les Tests E2E, et la Surveillance peuvent sembler séparés. Mais une fois que nous les unissons, nous débloquerons une synergie puissante qui mène à une gouvernance de données beaucoup plus efficace.
Une résolution idéale des problèmes de qualité des données :
C'est une matinée normale pour votre équipe de données lorsqu'une alerte Slack apparaît - une anomalie signalée par le moteur d'observabilité de Soda. Le système a remarqué un petit changement dans le volume des lignes qui n'a pas déclenché une alerte standard, et personne n'avait spécifiquement testé cela dans une vérification E2E.
Jenny, l'analyste des données et propriétaire du dataset, vérifie rapidement le Tableau de Bord des Anomalies pour voir quelles colonnes sont affectées.
Pendant ce temps, Dave, l'ingénieur des données, ouvre le tableau de bord de surveillance pour obtenir plus de détails des statistiques de niveau de colonne. Il a remarqué que la colonne contenait maintenant une nouvelle forme de duplication, avec le même texte répété plusieurs fois dans la même ligne - une anomalie au-delà de ce que les vérifications de tests et surveillance actuelles pourraient détecter.
Dave résout le problème à la source et ajuste le processus de transformation pour correspondre au nouveau changement, tandis que Jenny met à jour les vérifications de qualité des données existantes.
Après cela, Dave met à jour les nouvelles métriques de qualité des données pour le pipeline et effectue un nouveau test E2E. Avec la confirmation de Soda Scan de la correction, les tableaux de bord de surveillance et des anomalies restent verts pour le reste des mois. Au final, pas de surcommunication, du temps a été économisé pour tout le monde, et l'anomalie n'a pas affecté le pipeline en aval, la crise évitée.
Un rapide récapitulatif
La qualité des données n'est pas quelque chose que nous pouvons nous permettre de gérer de manière réactive. Les problèmes ne disparaîtront pas d'eux-mêmes, maintenant ou à l'avenir. Pour éviter les dette de données, nous devons repérer les problèmes rapidement, communiquer efficacement, et les résoudre en collaboration.
Imaginez un monde sans ingénieurs de données stressés ou plaintes constantes de la part des parties prenantes de l'entreprise. Tout le monde aurait plus de temps et d'énergie pour se concentrer sur ce qui compte vraiment. Au final, tout le monde gagne.
Trusted by the world’s leading enterprises
Real stories from companies using Soda to keep their data reliable, accurate, and ready for action.
At the end of the day, we don’t want to be in there managing the checks, updating the checks, adding the checks. We just want to go and observe what’s happening, and that’s what Soda is enabling right now.

Sid Srivastava
Director of Data Governance, Quality and MLOps
Investing in data quality is key for cross-functional teams to make accurate, complete decisions with fewer risks and greater returns, using initiatives such as product thinking, data governance, and self-service platforms.

Mario Konschake
Director of Product-Data Platform
Soda has integrated seamlessly into our technology stack and given us the confidence to find, analyze, implement, and resolve data issues through a simple self-serve capability.

Sutaraj Dutta
Data Engineering Manager
Our goal was to deliver high-quality datasets in near real-time, ensuring dashboards reflect live data as it flows in. But beyond solving technical challenges, we wanted to spark a cultural shift - empowering the entire organization to make decisions grounded in accurate, timely data.

Gu Xie
Head of Data Engineering
4,4 sur 5
Commencez à faire confiance à vos données. Aujourd'hui.
Trouvez, comprenez et corrigez tout problème de qualité des données en quelques secondes.
Du niveau de la table au niveau des enregistrements.
Adopté par
Product








Trusted by the world’s leading enterprises
Real stories from companies using Soda to keep their data reliable, accurate, and ready for action.
At the end of the day, we don’t want to be in there managing the checks, updating the checks, adding the checks. We just want to go and observe what’s happening, and that’s what Soda is enabling right now.
Sid Srivastava
Director of Data Governance, Quality and MLOps
Investing in data quality is key for cross-functional teams to make accurate, complete decisions with fewer risks and greater returns, using initiatives such as product thinking, data governance, and self-service platforms.
Mario Konschake
Director of Product-Data Platform
Soda has integrated seamlessly into our technology stack and given us the confidence to find, analyze, implement, and resolve data issues through a simple self-serve capability.
Sutaraj Dutta
Data Engineering Manager
Our goal was to deliver high-quality datasets in near real-time, ensuring dashboards reflect live data as it flows in. But beyond solving technical challenges, we wanted to spark a cultural shift - empowering the entire organization to make decisions grounded in accurate, timely data.
Gu Xie
Head of Data Engineering
4,4 sur 5
Commencez à faire confiance à vos données. Aujourd'hui.
Trouvez, comprenez et corrigez tout problème de qualité des données en quelques secondes.
Du niveau de la table au niveau des enregistrements.
Adopté par
Product
Solutions
Trusted by the world’s leading enterprises
Real stories from companies using Soda to keep their data reliable, accurate, and ready for action.
At the end of the day, we don’t want to be in there managing the checks, updating the checks, adding the checks. We just want to go and observe what’s happening, and that’s what Soda is enabling right now.
Sid Srivastava
Director of Data Governance, Quality and MLOps
Investing in data quality is key for cross-functional teams to make accurate, complete decisions with fewer risks and greater returns, using initiatives such as product thinking, data governance, and self-service platforms.
Mario Konschake
Director of Product-Data Platform
Soda has integrated seamlessly into our technology stack and given us the confidence to find, analyze, implement, and resolve data issues through a simple self-serve capability.
Sutaraj Dutta
Data Engineering Manager
Our goal was to deliver high-quality datasets in near real-time, ensuring dashboards reflect live data as it flows in. But beyond solving technical challenges, we wanted to spark a cultural shift - empowering the entire organization to make decisions grounded in accurate, timely data.
Gu Xie
Head of Data Engineering
4,4 sur 5
Commencez à faire confiance à vos données. Aujourd'hui.
Trouvez, comprenez et corrigez tout problème de qualité des données en quelques secondes.
Du niveau de la table au niveau des enregistrements.
Adopté par
Product
Solutions
Company