Les Dimensions de la Qualité des Données : Le guide sans fioritures avec des exemples
Les Dimensions de la Qualité des Données : Le guide sans fioritures avec des exemples
Les Dimensions de la Qualité des Données : Le guide sans fioritures avec des exemples

Aldana Rizzo
Aldana Rizzo
Rédacteur technique chez Soda
Rédacteur technique chez Soda
Table des matières
Chaque organisation sait que les données peuvent apporter beaucoup de valeur commerciale. Nous vivons à l'ère du Big Data, pleinement immergés dans un monde axé sur les données, etc. Mais voici le problème : moins de la moitié des équipes de données parviennent réellement à apporter une valeur réelle à leurs entreprises. Et soyons honnêtes, personne n'en parle. Ça ne nous met pas vraiment en valeur.
En tant qu'ingénieurs de données, analystes ou DSI, nous savons tous à quoi ressemblent les bonnes pratiques. Mais les mettre en œuvre ? C’est là que cela devient compliqué. C’est toujours plus facile à dire qu'à faire.
Prenons les dimensions de la Qualité des Données : nous savons qu’elles existent en théorie, mais en pratique, nous espérons souvent qu'elles restent à l'arrière de notre esprit. Elles sont généralement traitées comme des concepts abstraits liés aux meilleures pratiques que nous pensons suivre… sauf si nous ne les suivons pas. Mais comme personne ne les suit vraiment, et que personne ne demande de mise à jour trimestrielle, elles ont tendance à passer inaperçues.
Quelles sont les Dimensions de la Qualité des Données ?
Les dimensions de la qualité des données sont des critères standardisés (tels que l'exactitude, la complétude, la cohérence et la rapidité) utilisés pour évaluer si les données sont adaptées à leur objectif. Ces dimensions offrent un cadre pour mesurer, surveiller et améliorer la qualité des données dans les organisations.
À mon avis, le concept derrière les dimensions DQ est de déterminer ce qui peut mal tourner avec les données. Nous n'y pensons pas constamment. Et nous ne devrions pas, du moins activement. Encore moins avec tout le reste, je ne crois pas avoir la capacité mentale d'extrapoler chaque action que je fais en explications théoriques de pourquoi je le fais. Je doute être le seul. Mais, quand les choses tournent mal, c'est agréable d'avoir quelque chose à quoi se raccrocher qui fonctionne.
Voici ma liste complète de dimensions DQ que je me rappelle souvent. Par "ma propre liste", je veux dire celle du Guide DAMA de la Gestion des Données. Et par "souvent", j'entends chaque fois que je rencontre des problèmes inexplicables qui me forcent à revenir aux bases. Plus tard, nous pourrons explorer certains contrôles automatisés de la Qualité des Données et voir quelles dimensions ils peuvent couvrir.
Quelles sont les Dimensions Fondamentales de la Qualité des Données?
Bien qu'il existe de nombreux cadres pour catégoriser les dimensions de la qualité des données — incluant le Corps de Connaissances en Gestion des Données de DAMA, la norme ISO 8000, le Cadre de Qualité des Données de Gartner, et le Cadre Conceptuel de la Qualité des Données (Wang and Strong 1996) — la plupart convergent vers des concepts fondamentaux similaires.
Comparaison des Cadres :
Cadre | Caractéristiques principales |
|---|---|
DAMA DMBOK | 11 dimensions (le cadre utilisé dans ce guide) |
ISO 8000 | Se concentre sur l'exactitude, la complétude, la cohérence et la crédibilité |
Wang & Strong | 15 dimensions regroupées en 4 catégories (intrinsèque, contextuelle, représentationnelle, accessibilité) |
Gartner | Met l’accent sur 6 dimensions clés (exactitude, complétude, cohérence, rapidité, validité, unicité) |
Il convient de noter que toutes les organisations ne donneront pas la même priorité à chaque dimension. Votre cas d'utilisation spécifique, les réglementations de l'industrie et les exigences commerciales détermineront quelles dimensions sont les plus critiques à surveiller et à appliquer.
Ma Liste des 11 Dimensions DQ, Qui n'est Probablement pas Votre Liste
Si cette liste a bien une chose, elle est exhaustive. Tous les cas d'utilisation n'ont pas besoin de couvrir toutes ces dimensions DQ, ni de pouvoir intégrer des vérifications et des processus automatisés qui garantissent que chaque dimension est incluse. Cependant, il est bon de s'en souvenir et d'y réfléchir. Au moins de temps en temps.
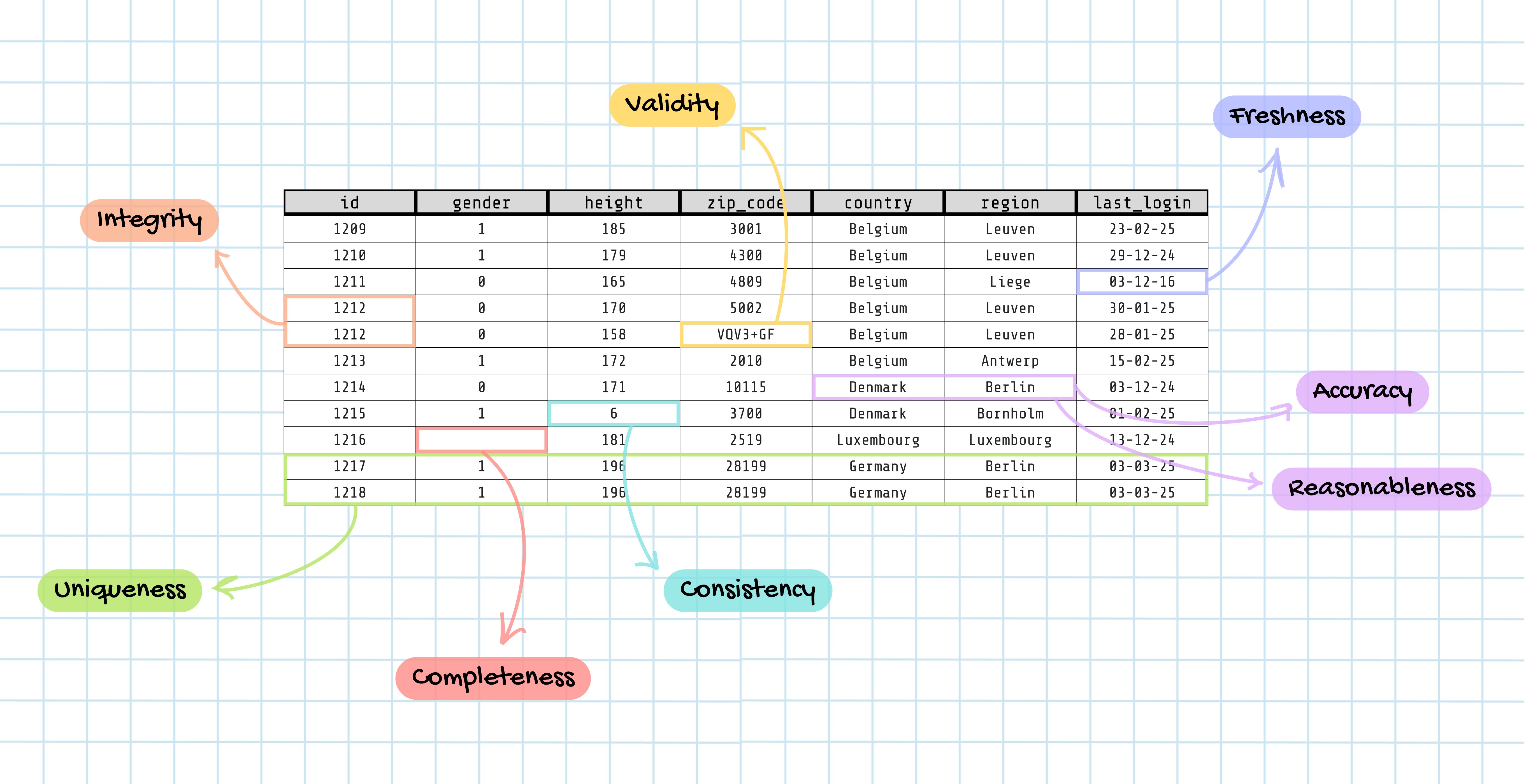
Complétude : Les données ont-elles des valeurs manquantes ? Si c’est le cas, sont-elles acceptables ou attendues ?
Exactitude : Mes données reflètent-elles la réalité ? Pour le savoir, ai-je suffisamment de connaissances sur l'industrie pour détecter quand ce n’est pas le cas ?
Cohérence : Y a-t-il des incohérences dans les données ? Tout le monde utilise-t-il les mêmes règles de formatage ? C'est-à-dire, les données d'un endroit correspondent-elles aux données pertinentes d'un autre endroit ?
Actualité : Ou, comme je préfère l’appeler, « fraîcheur ». Les données sont-elles à jour ? Décrivent-elles la réalité telle qu'elle est maintenant ?
Précision : Niveau de détail de l'élément de données. Cette colonne numérique a-t-elle besoin de quatre décimales ou est-il acceptable de trouver des valeurs tronquées ?
Confidentialité : Tout le monde peut-il accéder à cette table ? Devrait tout le monde avoir accès à cette table ? Comment puis-je surveiller qui a apporté des modifications ou consulté cet ensemble de données ?
Raisonnabilité : En gros et de manière redondante : les valeurs que je vois sont-elles raisonnables ? Est-ce déraisonnable que les ventes aujourd'hui soient 500% de la moyenne des ventes des 30 derniers jours ? Ou est-ce le 24 décembre ?
Intégrité Référentielle : On parle beaucoup dans l'industrie de ce qu'est l'intégrité en tant que dimension. Mais je vais l'ignorer parce que je le peux, et ne définir que l'intégrité référentielle : chaque fois qu'une clé étrangère agit comme un identifiant unique, l'enregistrement dans la table référencée doit a) exister, et b) être unique.
Rapidité : Quand l'information est-elle disponible ? Quand l'information est-elle attendue ? Les données sont-elles disponibles au moment voulu ?
Unicité : Assez explicite : y a-t-il des doublons ?
Validité : Les données ont-elles du sens ? Sont-elles utilisables pour (excusez la redondance) les utilisateurs, ou auront-ils des tas d'erreurs en essayant de les valider ?
Tout le monde ne sera pas complètement d'accord avec cette liste, mais la plupart des gens seront d'accord avec certains éléments. C'est tout ce qui compte. Chaque cas d'utilisation nécessitera l'examen de différentes dimensions, et chaque industrie aura une vision différente des parties de la Qualité des Données qui sont pertinentes dans le domaine. Cependant, la base de la Qualité des Données devrait être la même pour tout le monde. C'est pourquoi, à l'heure actuelle, nous devrions tous mettre en place des contrôles automatisés lors du traitement de quantités considérables de données.
Pourquoi Mettre en Place des Contrôles de Qualité des Données ?
Eh bien, tout d’abord, parce qu’il n’est tout simplement pas possible d’avoir de bonnes données si nous les déversons dans un lac de données et les utilisons telles quelles. Où est la fierté là-dedans. Mais ensuite, et voici comment nous convainquons les organisations d'investir dans des équipes de données et de nous donner des outils cool et plus de mains, parce que la Qualité des Données rapporte plus d’argent.
Les entreprises ayant de mauvais cadres de Qualité des Données sont à la traîne. De bonnes données conduisent à de bonnes décisions commerciales et à de bonnes pratiques commerciales. Elles se traduisent par de grandes prédictions qui permettent à toute organisation de se préparer aux changements de marché avant qu’ils ne se produisent, et non pas juste d'y réagir. Elles permettent de comprendre l'expérience utilisateur et les besoins. Et plus important encore : c'est rentable. De bonnes données évitent tous les coûts associés à la correction des données inexactes et à la réanalyse.
1. Meilleures Décisions Commerciales
Les insights et prédictions orientés par les données ont une base très claire. C'est sur le nom. Les données. Les bonnes données permettent aux organisations de prendre des décisions véritablement orientées par les données.
L'une des étapes vers de bonnes données est de mettre en place des contrôles de Qualité des Données, et cela n’a de sens que de les automatiser. Non seulement pour épargner à un ingénieur ce travail manuel, mais aussi pour avoir des vérifications cohérentes qui fonctionnent régulièrement et émettent des alertes dès que quelque chose tourne mal.
2. Prédictions & Prévisions Fiables
Lorsque les données sont bonnes, exactes et pertinentes, il est alors facile pour les différentes sections d'une organisation de faire des prédictions fiables. Cela est crucial pour voir les changements de marché quand ils s’annoncent.
Les différentes équipes se concentreront sur divers aspects de l'avenir à venir, mais elles construiront toutes leur prévision sur les mêmes données. C'est pourquoi elles doivent être bonnes à tous les niveaux.
3. Optimisation des Coûts par l'Alignement des Équipes
La communication entre les équipes est essentielle au succès de toute organisation. La plupart des entreprises n’ont plus d’équipes de données en silo : les ingénieurs de données travaillent main dans la main avec toutes les équipes non-IT, ce qui entraîne des appels sans fin pour déterminer ce qu'elles veulent et ce dont elles ont besoin.
Pour optimiser ces relations, il est essentiel de s'assurer que tout le monde est à jour sur ce qui est attendu des données, ce qu'elles seront utilisées pour et comment y arriver. Est-il acceptable qu'un ensemble de données ait des valeurs incomplètes ? Quelle devise utiliserons-nous dans toutes les tables ?
Les questions pertinentes ne se poseront pas toujours au sein de l'équipe de données, et elles ne devraient pas. Elles viendront des utilisateurs de données, qui seront ceux qui nous montreront quelles dimensions sont importantes. Avoir une communication ouverte avec tout le monde permet de gagner du temps, des efforts et de l'argent, en optimisant les processus de données en général.
4. Tranquillité d'Esprit avec la Surveillance Automatisée
Pour avoir de bons produits de données, nous avons besoin de bons systèmes de données. Cela couvre tous les processus par lesquels les données passent, de la collecte à l'analyse et aux prévisions.
Nous devons garder à l'esprit la Qualité des Données non seulement lors de la construction d'un pipeline ou de nos discussions avec les consommateurs de données sur leurs besoins, mais même après avoir terminé de travailler avec les données. Sera-t-elle durable à long terme ? À mesure qu'elles subissent des demandes et des transformations, les données resteront-elles bonnes ? C'est là que les contrôles automatisés jouent leur rôle.
En validant les données avant, pendant et après un pipeline, nous garantissons qu'un produit de données spécifique est digne de confiance. Et nous n’avons même pas eu besoin de bouger un muscle, parce que tout s’est passé automatiquement. La touche humaine est toujours là, dans la construction des pipelines, la conception des contrôles, leur écriture, l'analyse des résultats, la détermination de ce qui ne va pas. Mais nous avons la tranquillité d’esprit de savoir que, sauf alerte, les données vont bien.
Commencer avec les Contrôles Automatisés
Toute personne disposant de données peut commencer à appliquer des contrôles de Qualité des Données dès aujourd'hui. C'est un processus simple qui peut (et devrait) être mis en œuvre à chaque étape d’un système de données. Tout le monde est le bienvenu. Ce tutoriel couvrira quelques contrôles de DQ de base pour montrer à quel point il est simple d’en implémenter, même sans expérience en codage.
Alors, commençons !

Exigences
Un Soda Cloud et créer un compte gratuitement
Une source de données connectée (Dans Soda Cloud, "Votre Profil" > "Sources de Données" > "Nouvelle Source de Données")
Si vous utilisez Soda dans votre propre environnement, vous pouvez appliquer ces contrôles avec SodaCL (Langage de Contrôles Soda).
Si, par contre, vous souhaitez une solution sans code, allez dans "Checks" > "New Check" sur Soda Cloud et il vous suffit de remplir les blancs.

Pour des raisons de simplicité, les contrôles suivants sont implémentés sur une base de données jouet dans Snowflake. Elle inclut les ensembles de données ACCOUNTS et CUSTOMERS, tous deux avec des informations sur les transactions et, devinez quoi, les clients. Les contrôles sont écrits en SodaCL et peuvent être utilisés dans toute implémentation de Soda. Pour une approche conviviale pour les débutants, cela peut se produire sans quitter l'interface utilisateur de Soda.
Implémentation des Contrôles
Complétude
Le premier contrôle, et le plus courant à inclure avant ou après tout pipeline, est un contrôle de complétude. Dans ce cas, je souhaite que mon contrôle échoue lorsque l'identifiant client est manquant car cette entrée sera inutilisable.
checks for ACCOUNTS: - missing_count(CUSTOMER_ID): name: completeness fail
Cependant, je voudrais seulement une alerte lorsque les informations personnelles ne sont pas là. Pas besoin d'échecs, je veux juste savoir si nous manquons de valeurs et que les pipelines continuent de faire leur travail après ce contrôle même s'il y a des valeurs nulles.
checks for CUSTOMERS: - missing_count(LAST_NAME): name: completeness_surname warn: when > 0 - missing_count(EMAIL): name: completeness_email warn: when > 0 - missing_count(PHONE_NUMBER): name: completeness_phone warn
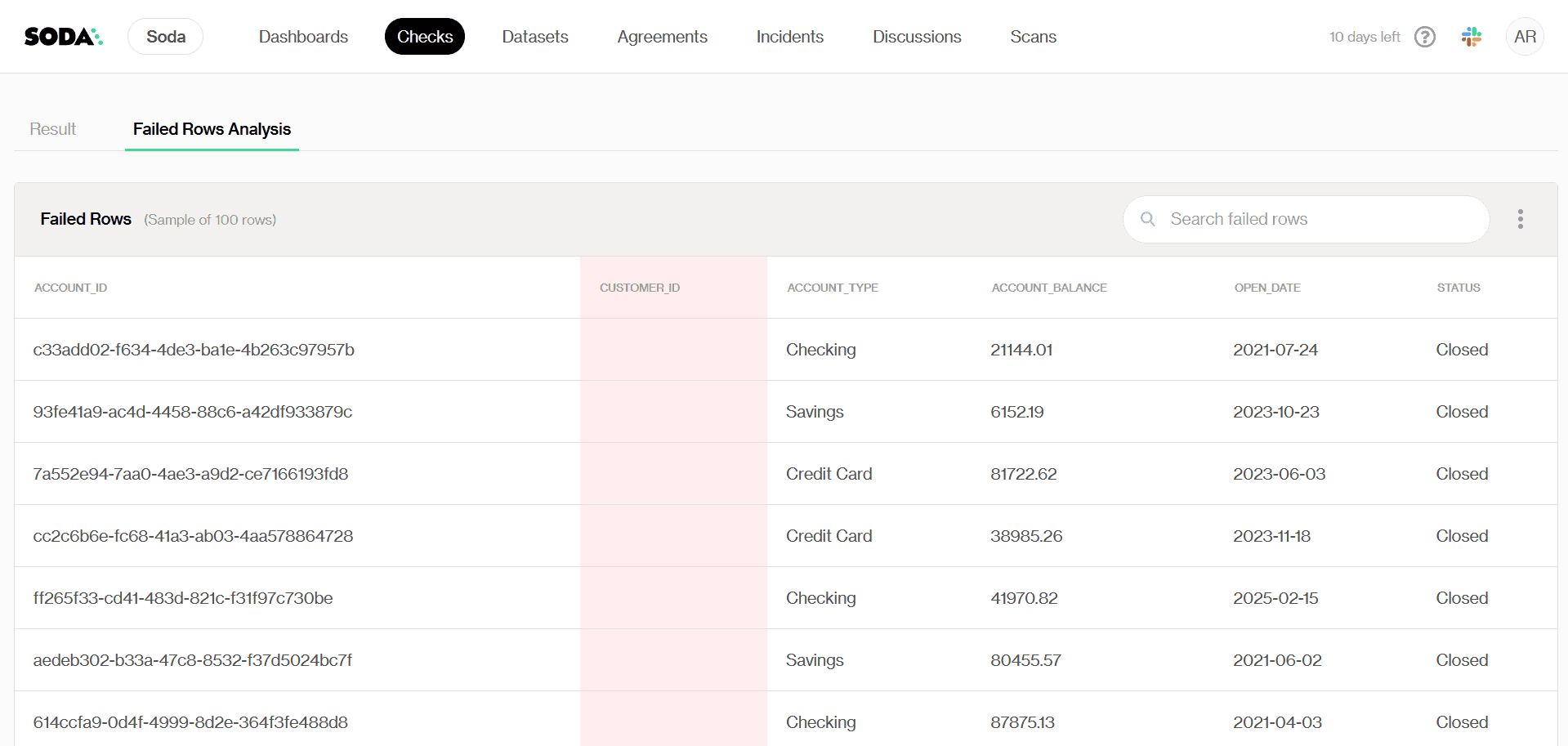
Si un contrôle échoue, nous pouvons analyser plus en détail pourquoi sur notre tableau de bord. Ici, en cliquant sur le contrôle complétude, il y a une vue détaillée des lignes qui manquent de CUSTOMER_ID :
Validité
La validité a beaucoup à voir avec l'utilisabilité. Supposons que les parties prenantes de l'entreprise utiliseront ces données pour établir une stratégie de vente par région. Si elles essaient d'obtenir des métriques à partir des codes postaux, l'équipe de données doit fournir des codes postaux utilisables qui peuvent être regroupés et cartographiés. Dans ce contrôle, l'équipe de données s'est mise d'accord avec les utilisateurs de données pour dire que les codes postaux doivent contenir un maximum de cinq chiffres.
L'objectif est que ce contrôle lève une alerte chaque fois qu'il y a des valeurs sous ZIP_CODE qui ne correspondent pas au format attendu.
checks for CUSTOMERS: - invalid_count(ZIP_CODE): valid max length: 5 valid format: integer name: valid_zip_code warn
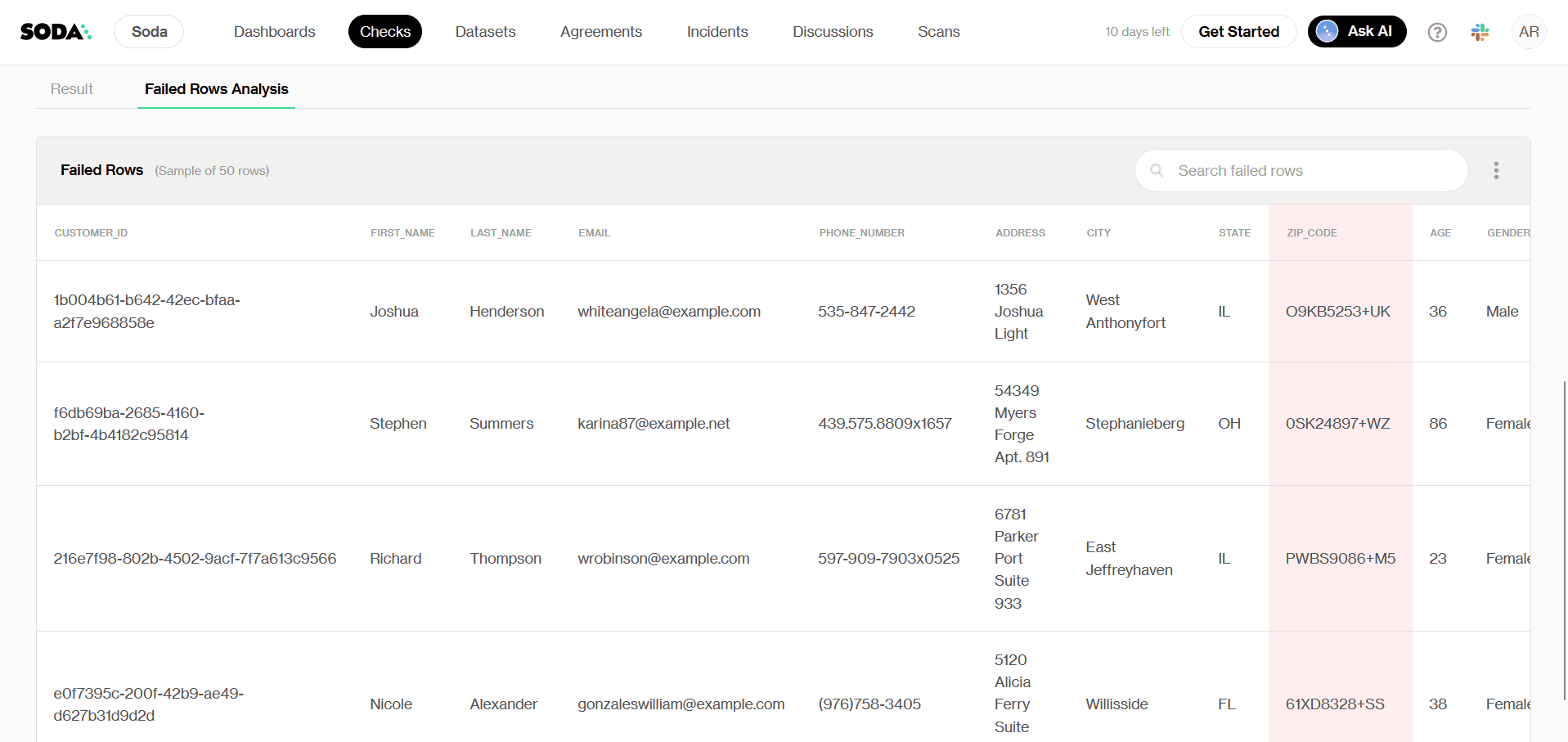
Comme dans l'exemple précédent, nous pouvons analyser plus avant quelles lignes ont échoué au contrôle et déclenché une alerte. Dans ce cas, la raison de l'échec est que certaines valeurs sous ZIP_CODE sont des Codes Plus écrits au format OLC, au lieu d'être des codes postaux écrits au format numérique attendu.
Unicité
Les identifiants clients sont extrêmement pertinents dans cette base de données, donc je veux vérifier qu'ils ne sont pas dupliqués. S'ils le sont, ce contrôle doit échouer car toutes ces entrées seront inutilisables tant qu'elles ne seront pas corrigées ou supprimées.
checks for CUSTOMERS: - duplicate_count(CUSTOMER_ID): name: unique_id fail
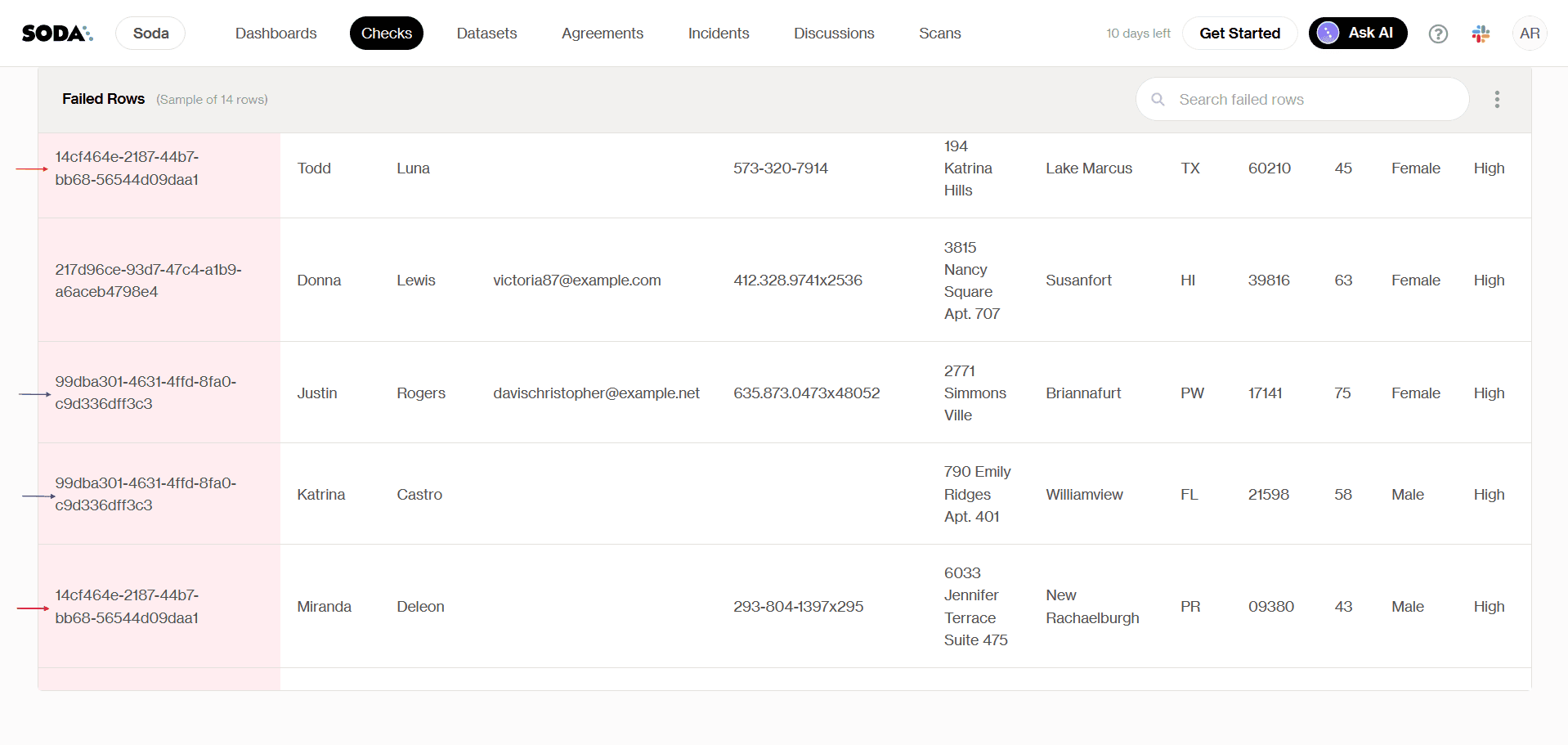
La vue sur le tableau de bord confirme qu'il y a des identifiants clients qui pointent vers plus d'un client.
Actualité
Pour la fraîcheur, ou l'actualité des données, nous allons mettre en œuvre un contrôle SQL personnalisé. Ce modèle peut fonctionner pour toute instruction SQL, ce qui le rend polyvalent pour tous les scénarios d'utilisation. Dans ce cas, je veux savoir à quel point l'information d'une entrée est récente en fonction de la dernière fois qu'un client s'est connecté à son compte. Si la connexion est antérieure à 5 ans, alors le contrôle lève une alerte.
Notez que le seul extrait SQL écrit ici est la requête échouée, tout le reste est du SodaCL.
checks for CUSTOMERS: - failed rows: samples limit: 100 fail query: |- SELECT * FROM CUSTOMERS WHERE LAST_LOGIN < DATEADD(YEAR, -5, CURRENT_DATE()) name: freshness warn
Encore une fois, chaque fois que des contrôles échouent, nous pouvons voir les métriques et les détails sur le tableau de bord. Dans ce cas, recevoir une alerte signifie qu'il y a plusieurs connexions datant de plus de 5 ans, ce qui pourrait être une information pertinente pour les parties prenantes de l'entreprise.
Ce type de contrôle SQL est très utile pour les validations qui n'existent pas par défaut sur Soda Cloud, ou même pour personnaliser les contrôles existants avec des besoins spécifiques à l'esprit.
Comment les Dimensions de la Qualité des Données se Rattachent aux Contrôles Automatisés
Comme pour toute question pertinente et la plupart des bonnes réponses : ça dépend. Ça dépend du type de données analysées, des types de contrôles, des attentes des parties prenantes concernant les données… Les trois contrôles que nous avons effectués ont couvert quelques dimensions. La plus évidente est la Complétude. Pas besoin d'expliquer celle-là. Une dimension pas si évidente couverte par le contrôle de complétude est l'Intégrité Référentielle. Lorsqu'une table pointe vers un identifiant client et que cette valeur manque, l'intégrité référentielle est violée, ce qui rend les données non utilisables à travers les ensembles de données.
Avec le deuxième contrôle (code_postal_valide), nous avons couvert, bien sûr, la Validité. Cette dimension doit être convenue par les équipes de données et les parties prenantes de l'entreprise. La validité dépendra de l'utilisation des données, donc les consommateurs de données doivent avoir leur mot à dire sur ce dont ils ont besoin et ce à quoi ils s'attendent. Ici, certains codes postaux ne sont pas valides. Mais pourquoi ? Ce n'est pas que quelqu'un ait simplement écrit "ma maison" à la place d'un code postal ; le code était là, il était simplement dans le mauvais format. Et cela a à voir avec la Cohérence. Lorsqu'on se met d'accord sur ce qui est valide et ce qui ne l'est pas, il y a aussi une conversation sur "que devrions-nous tous faire ?". Devons-nous saisir des codes postaux ou des Codes Plus ? Est-il préférable de simplement saisir le pays et la région ? De quel niveau de détail avons-nous besoin sur la démographie de nos clients ? (ce qui pourrait également se rattacher à la Précision. Je passe juste par là. Tout est connecté !). Lorsque les données sont cohérentes, la validité suit généralement. Aussi, un code postal avec 10 chiffres et lettres n'est pas Raisonnable.
Le troisième contrôle, id_unique valide, bien sûr, l'Unicité. Il le fait là où c'est important : dans les identifiants clients. Bien sûr, nous pouvons vérifier l'unicité à travers toutes les données, mais pourquoi ? L'âge ne sera pas unique dans une table avec des milliers d'entrées appartenant toutes à différentes personnes. Mais les identificateurs sont censés être uniques si nous voulons des données utilisables. De plus, nous vérifions à nouveau l'Intégrité Référentielle ; si les identifiants ne sont pas uniques, les tables qui ont CUSTOMER_ID comme clé étrangère pointeront vers deux points de données au lieu d'un.
Enfin, qu'est-ce que le contrôle fraîcheur couvre ? Actualité (ou Fraîcheur), pour commencer, puisqu'il examine à quel point un élément de données est ancien ou récent. Mais les contrôles de fraîcheur peuvent également nous aider à comprendre si les données reflètent la réalité telle qu'elle est maintenant. L'Exactitude n'a pas seulement à voir avec les valeurs réelles ou inexactes, mais aussi avec la façon dont la réalité se modifie et se transforme. Les salaires il y a dix ans ne sont pas comparables aux salaires actuels en valeurs absolues. Donc des données obsolètes peuvent être problématiques d’un point de vue de fraîcheur, mais aussi d'une perspective d'exactitude.
Référence Rapide : Mapping Contrôle-Dimension
Nom du Contrôle | Type de Contrôle SodaCL | Dimension(s) Principale(s) | Dimensions Secondaires | Action |
|---|---|---|---|---|
|
| Complétude | Intégrité Référentielle | Échoue lorsque l'identifiant client manque dans la table ACCOUNTS |
|
| Complétude | - | Avertit lorsque les informations personnelles manquent dans la table CUSTOMERS |
|
| Validité | Cohérence, Raisonnabilité | Attrape les Codes Plus au lieu de codes postaux à 5 chiffres |
|
| Unicité | Intégrité Référentielle | Identifie les identifiants clients dupliqués dans la table CUSTOMERS |
|
| Actualité (Fraîcheur) | Exactitude, Rapidité | Alerte lorsque le LAST_LOGIN date de plus de 5 ans |
Lisez plus sur des contrôles de qualité des données simples et efficaces que vous pouvez implémenter dès aujourd'hui pour aider votre entreprise à fonctionner plus efficacement ici : 6 Façons d'Améliorer votre Qualité de Données (avec des Contrôles d'Exemple de Qualité de Données)
La Valeur Commerciale de l'Approche Dimensionnelle
Réduction des Coûts
Adopter une approche multidimensionnelle pour comprendre la Qualité des Données dans une organisation signifie, tout d'abord, des réductions de coûts. Pourquoi ? Parce que moins de données inutilisables conduit à moins d'argent dépensé pour le stockage cloud. Moins de correctifs rapides entraîne moins de coûts opérationnels (et moins de coûts de santé mentale au sein de l'équipe de données, soyons réalistes). Cela signifie seulement qu'il y aura plus d'argent et d'énergie pour l'amélioration, la croissance, pour s'attaquer à ce problème de faible priorité qui traîne dans la liste de choses à faire depuis des mois. Gagne-gagne-gagne !
Prédictions Fiables
En ce qui concerne les avantages commerciaux, outre la réduction des coûts, avoir un système de données qui garde à l'esprit les dimensions de la Qualité des Données, et la Qualité des Données en général, conduit également à des analyses et/ou des prévisions plus fiables en aval. L'équipe de données sera heureuse, c'est sûr, mais la Vente sera aussi contente que leurs prévisions soient véritablement exactes, et le Produit sera satisfait des mesures qu'ils recueillent, et chaque équipe non-données qui n'écrit pas activement des requêtes SQL mais utilise en quelque sorte des données aimera la vie au lieu de sauter sur des appels pour réparer des tableaux de bord cassés.
Gouvernance des Données
Lorsque la Qualité des Données est appliquée, la Gouvernance des Données suit. Des sujets comme la conformité, la gestion, la sécurité et la surveillance deviennent beaucoup plus faciles si les utilisateurs de données accèdent à des informations fiables.
Argent
Et puis, nous bouclons la boucle. Tout cela (moins de coûts de données, des données fiables, de meilleurs insights, des équipes heureuses, des processus fluides) mène au point de vente principal du blog d'aujourd'hui : Plus d'Argent. Lorsqu'une entreprise utilise des données fiables, son image s'améliore, ses résultats commerciaux sont meilleurs et ses revenus augmentent. Toutes des victoires pour tout le monde.
Conclusion
Les contrôles de qualité des données sont essentiels pour toute organisation qui souhaite rester dans la course (en fait, plus de 50% des organisations ne mesurent même pas combien les mauvaises données leur coûtent). Tout comme un bon Ingénieur de Données tend à avoir une connaissance approfondie du secteur, une bonne Qualité des Données doit prendre en compte le contexte, ce qui donne aux entreprises le pouvoir d'obtenir les insights orientés par les données qu'elles désirent.
Analyser les dimensions de la Qualité des Données est un moyen de décider de ce qui est pertinent et de ce qui ne l'est pas. En ayant différents contrôles qui couvrent toutes les dimensions pertinentes, nous pouvons être rassurés sur la qualité des données. Et qui n’aime pas de bonnes données ?
De bonnes données fournissent de bons insights et, par-dessus tout, la fiabilité. Des données fiables sont l'objectif de tout Ingénieur de Données, ainsi que le rêve de toute équipe non-données. Personne ne veut de datasets qui ne sont pas exacts parce qu'aucune action valable ne peut en découler. Un ensemble de données avec 99% de complétude ne vaut rien si 50% des données sont dupliquées. Ainsi, en garantissant toutes les dimensions de la Qualité des Données, nous garantissons également que toute personne regardant les données puisse faire confiance à leur contenu.
Notre valeur en tant qu'experts des données est, bien sûr, des données fiables, mais aussi la valeur ajoutée qui en découle. De meilleures données mènent à de meilleures décisions, de meilleurs résultats, plus de croissance et, en fin de compte, plus d'argent. C'est la ligne que nous vendons à nos organisations pour obtenir de meilleurs logiciels (ou conserver celui qui fonctionne déjà).
L'implémentation d'outils de Qualité des Données comme Soda est un must pour chaque organisation aujourd'hui, et travailler à travers la lentille des dimensions de la Qualité des Données peut aider les équipes de données et non-données à atteindre leurs objectifs.
Questions Fréquemment Posées
Quel cadre devrais-je utiliser : DAMA, ISO 8000 ou Wang & Strong ?
Choisissez en fonction des besoins de votre organisation. DAMA est complet et largement adopté dans la gestion des données. ISO 8000 est idéal pour les industries axées sur la conformité. Wang & Strong fonctionne bien pour les contextes académiques ou de recherche. La plupart des cadres se chevauchent de manière significative dans les concepts fondamentaux.
Un contrôle peut-il couvrir plusieurs dimensions de qualité des données ?
Oui ! La plupart des contrôles automatisés valident simultanément plusieurs dimensions. Par exemple, un contrôle de valeur manquante couvre à la fois la complétude et l'intégrité référentielle lorsqu'il s'agit de clés étrangères.
Comment les dimensions de la qualité des données se rapportent-elles à la gouvernance des données ?
Les dimensions de la qualité des données fournissent les critères mesurables pour les politiques de gouvernance des données. Elles aident à définir les SLA, à établir les seuils de surveillance et à créer la responsabilité de la qualité des données à travers les équipes.
À quelle fréquence les contrôles de qualité des données doivent-ils être exécutés ?
Cela dépend de la criticité des données et de la fréquence des changements. Les contrôles en temps réel pour les pipelines critiques, les contrôles horaires/quotidiens pour les données opérationnelles, et les contrôles hebdomadaires/mensuels pour les données historiques ou de référence sont des schémas courants.
Chaque organisation sait que les données peuvent apporter beaucoup de valeur commerciale. Nous vivons à l'ère du Big Data, pleinement immergés dans un monde axé sur les données, etc. Mais voici le problème : moins de la moitié des équipes de données parviennent réellement à apporter une valeur réelle à leurs entreprises. Et soyons honnêtes, personne n'en parle. Ça ne nous met pas vraiment en valeur.
En tant qu'ingénieurs de données, analystes ou DSI, nous savons tous à quoi ressemblent les bonnes pratiques. Mais les mettre en œuvre ? C’est là que cela devient compliqué. C’est toujours plus facile à dire qu'à faire.
Prenons les dimensions de la Qualité des Données : nous savons qu’elles existent en théorie, mais en pratique, nous espérons souvent qu'elles restent à l'arrière de notre esprit. Elles sont généralement traitées comme des concepts abstraits liés aux meilleures pratiques que nous pensons suivre… sauf si nous ne les suivons pas. Mais comme personne ne les suit vraiment, et que personne ne demande de mise à jour trimestrielle, elles ont tendance à passer inaperçues.
Quelles sont les Dimensions de la Qualité des Données ?
Les dimensions de la qualité des données sont des critères standardisés (tels que l'exactitude, la complétude, la cohérence et la rapidité) utilisés pour évaluer si les données sont adaptées à leur objectif. Ces dimensions offrent un cadre pour mesurer, surveiller et améliorer la qualité des données dans les organisations.
À mon avis, le concept derrière les dimensions DQ est de déterminer ce qui peut mal tourner avec les données. Nous n'y pensons pas constamment. Et nous ne devrions pas, du moins activement. Encore moins avec tout le reste, je ne crois pas avoir la capacité mentale d'extrapoler chaque action que je fais en explications théoriques de pourquoi je le fais. Je doute être le seul. Mais, quand les choses tournent mal, c'est agréable d'avoir quelque chose à quoi se raccrocher qui fonctionne.
Voici ma liste complète de dimensions DQ que je me rappelle souvent. Par "ma propre liste", je veux dire celle du Guide DAMA de la Gestion des Données. Et par "souvent", j'entends chaque fois que je rencontre des problèmes inexplicables qui me forcent à revenir aux bases. Plus tard, nous pourrons explorer certains contrôles automatisés de la Qualité des Données et voir quelles dimensions ils peuvent couvrir.
Quelles sont les Dimensions Fondamentales de la Qualité des Données?
Bien qu'il existe de nombreux cadres pour catégoriser les dimensions de la qualité des données — incluant le Corps de Connaissances en Gestion des Données de DAMA, la norme ISO 8000, le Cadre de Qualité des Données de Gartner, et le Cadre Conceptuel de la Qualité des Données (Wang and Strong 1996) — la plupart convergent vers des concepts fondamentaux similaires.
Comparaison des Cadres :
Cadre | Caractéristiques principales |
|---|---|
DAMA DMBOK | 11 dimensions (le cadre utilisé dans ce guide) |
ISO 8000 | Se concentre sur l'exactitude, la complétude, la cohérence et la crédibilité |
Wang & Strong | 15 dimensions regroupées en 4 catégories (intrinsèque, contextuelle, représentationnelle, accessibilité) |
Gartner | Met l’accent sur 6 dimensions clés (exactitude, complétude, cohérence, rapidité, validité, unicité) |
Il convient de noter que toutes les organisations ne donneront pas la même priorité à chaque dimension. Votre cas d'utilisation spécifique, les réglementations de l'industrie et les exigences commerciales détermineront quelles dimensions sont les plus critiques à surveiller et à appliquer.
Ma Liste des 11 Dimensions DQ, Qui n'est Probablement pas Votre Liste
Si cette liste a bien une chose, elle est exhaustive. Tous les cas d'utilisation n'ont pas besoin de couvrir toutes ces dimensions DQ, ni de pouvoir intégrer des vérifications et des processus automatisés qui garantissent que chaque dimension est incluse. Cependant, il est bon de s'en souvenir et d'y réfléchir. Au moins de temps en temps.
Complétude : Les données ont-elles des valeurs manquantes ? Si c’est le cas, sont-elles acceptables ou attendues ?
Exactitude : Mes données reflètent-elles la réalité ? Pour le savoir, ai-je suffisamment de connaissances sur l'industrie pour détecter quand ce n’est pas le cas ?
Cohérence : Y a-t-il des incohérences dans les données ? Tout le monde utilise-t-il les mêmes règles de formatage ? C'est-à-dire, les données d'un endroit correspondent-elles aux données pertinentes d'un autre endroit ?
Actualité : Ou, comme je préfère l’appeler, « fraîcheur ». Les données sont-elles à jour ? Décrivent-elles la réalité telle qu'elle est maintenant ?
Précision : Niveau de détail de l'élément de données. Cette colonne numérique a-t-elle besoin de quatre décimales ou est-il acceptable de trouver des valeurs tronquées ?
Confidentialité : Tout le monde peut-il accéder à cette table ? Devrait tout le monde avoir accès à cette table ? Comment puis-je surveiller qui a apporté des modifications ou consulté cet ensemble de données ?
Raisonnabilité : En gros et de manière redondante : les valeurs que je vois sont-elles raisonnables ? Est-ce déraisonnable que les ventes aujourd'hui soient 500% de la moyenne des ventes des 30 derniers jours ? Ou est-ce le 24 décembre ?
Intégrité Référentielle : On parle beaucoup dans l'industrie de ce qu'est l'intégrité en tant que dimension. Mais je vais l'ignorer parce que je le peux, et ne définir que l'intégrité référentielle : chaque fois qu'une clé étrangère agit comme un identifiant unique, l'enregistrement dans la table référencée doit a) exister, et b) être unique.
Rapidité : Quand l'information est-elle disponible ? Quand l'information est-elle attendue ? Les données sont-elles disponibles au moment voulu ?
Unicité : Assez explicite : y a-t-il des doublons ?
Validité : Les données ont-elles du sens ? Sont-elles utilisables pour (excusez la redondance) les utilisateurs, ou auront-ils des tas d'erreurs en essayant de les valider ?
Tout le monde ne sera pas complètement d'accord avec cette liste, mais la plupart des gens seront d'accord avec certains éléments. C'est tout ce qui compte. Chaque cas d'utilisation nécessitera l'examen de différentes dimensions, et chaque industrie aura une vision différente des parties de la Qualité des Données qui sont pertinentes dans le domaine. Cependant, la base de la Qualité des Données devrait être la même pour tout le monde. C'est pourquoi, à l'heure actuelle, nous devrions tous mettre en place des contrôles automatisés lors du traitement de quantités considérables de données.
Pourquoi Mettre en Place des Contrôles de Qualité des Données ?
Eh bien, tout d’abord, parce qu’il n’est tout simplement pas possible d’avoir de bonnes données si nous les déversons dans un lac de données et les utilisons telles quelles. Où est la fierté là-dedans. Mais ensuite, et voici comment nous convainquons les organisations d'investir dans des équipes de données et de nous donner des outils cool et plus de mains, parce que la Qualité des Données rapporte plus d’argent.
Les entreprises ayant de mauvais cadres de Qualité des Données sont à la traîne. De bonnes données conduisent à de bonnes décisions commerciales et à de bonnes pratiques commerciales. Elles se traduisent par de grandes prédictions qui permettent à toute organisation de se préparer aux changements de marché avant qu’ils ne se produisent, et non pas juste d'y réagir. Elles permettent de comprendre l'expérience utilisateur et les besoins. Et plus important encore : c'est rentable. De bonnes données évitent tous les coûts associés à la correction des données inexactes et à la réanalyse.
1. Meilleures Décisions Commerciales
Les insights et prédictions orientés par les données ont une base très claire. C'est sur le nom. Les données. Les bonnes données permettent aux organisations de prendre des décisions véritablement orientées par les données.
L'une des étapes vers de bonnes données est de mettre en place des contrôles de Qualité des Données, et cela n’a de sens que de les automatiser. Non seulement pour épargner à un ingénieur ce travail manuel, mais aussi pour avoir des vérifications cohérentes qui fonctionnent régulièrement et émettent des alertes dès que quelque chose tourne mal.
2. Prédictions & Prévisions Fiables
Lorsque les données sont bonnes, exactes et pertinentes, il est alors facile pour les différentes sections d'une organisation de faire des prédictions fiables. Cela est crucial pour voir les changements de marché quand ils s’annoncent.
Les différentes équipes se concentreront sur divers aspects de l'avenir à venir, mais elles construiront toutes leur prévision sur les mêmes données. C'est pourquoi elles doivent être bonnes à tous les niveaux.
3. Optimisation des Coûts par l'Alignement des Équipes
La communication entre les équipes est essentielle au succès de toute organisation. La plupart des entreprises n’ont plus d’équipes de données en silo : les ingénieurs de données travaillent main dans la main avec toutes les équipes non-IT, ce qui entraîne des appels sans fin pour déterminer ce qu'elles veulent et ce dont elles ont besoin.
Pour optimiser ces relations, il est essentiel de s'assurer que tout le monde est à jour sur ce qui est attendu des données, ce qu'elles seront utilisées pour et comment y arriver. Est-il acceptable qu'un ensemble de données ait des valeurs incomplètes ? Quelle devise utiliserons-nous dans toutes les tables ?
Les questions pertinentes ne se poseront pas toujours au sein de l'équipe de données, et elles ne devraient pas. Elles viendront des utilisateurs de données, qui seront ceux qui nous montreront quelles dimensions sont importantes. Avoir une communication ouverte avec tout le monde permet de gagner du temps, des efforts et de l'argent, en optimisant les processus de données en général.
4. Tranquillité d'Esprit avec la Surveillance Automatisée
Pour avoir de bons produits de données, nous avons besoin de bons systèmes de données. Cela couvre tous les processus par lesquels les données passent, de la collecte à l'analyse et aux prévisions.
Nous devons garder à l'esprit la Qualité des Données non seulement lors de la construction d'un pipeline ou de nos discussions avec les consommateurs de données sur leurs besoins, mais même après avoir terminé de travailler avec les données. Sera-t-elle durable à long terme ? À mesure qu'elles subissent des demandes et des transformations, les données resteront-elles bonnes ? C'est là que les contrôles automatisés jouent leur rôle.
En validant les données avant, pendant et après un pipeline, nous garantissons qu'un produit de données spécifique est digne de confiance. Et nous n’avons même pas eu besoin de bouger un muscle, parce que tout s’est passé automatiquement. La touche humaine est toujours là, dans la construction des pipelines, la conception des contrôles, leur écriture, l'analyse des résultats, la détermination de ce qui ne va pas. Mais nous avons la tranquillité d’esprit de savoir que, sauf alerte, les données vont bien.
Commencer avec les Contrôles Automatisés
Toute personne disposant de données peut commencer à appliquer des contrôles de Qualité des Données dès aujourd'hui. C'est un processus simple qui peut (et devrait) être mis en œuvre à chaque étape d’un système de données. Tout le monde est le bienvenu. Ce tutoriel couvrira quelques contrôles de DQ de base pour montrer à quel point il est simple d’en implémenter, même sans expérience en codage.
Alors, commençons !
Exigences
Un Soda Cloud et créer un compte gratuitement
Une source de données connectée (Dans Soda Cloud, "Votre Profil" > "Sources de Données" > "Nouvelle Source de Données")
Si vous utilisez Soda dans votre propre environnement, vous pouvez appliquer ces contrôles avec SodaCL (Langage de Contrôles Soda).
Si, par contre, vous souhaitez une solution sans code, allez dans "Checks" > "New Check" sur Soda Cloud et il vous suffit de remplir les blancs.
Pour des raisons de simplicité, les contrôles suivants sont implémentés sur une base de données jouet dans Snowflake. Elle inclut les ensembles de données ACCOUNTS et CUSTOMERS, tous deux avec des informations sur les transactions et, devinez quoi, les clients. Les contrôles sont écrits en SodaCL et peuvent être utilisés dans toute implémentation de Soda. Pour une approche conviviale pour les débutants, cela peut se produire sans quitter l'interface utilisateur de Soda.
Implémentation des Contrôles
Complétude
Le premier contrôle, et le plus courant à inclure avant ou après tout pipeline, est un contrôle de complétude. Dans ce cas, je souhaite que mon contrôle échoue lorsque l'identifiant client est manquant car cette entrée sera inutilisable.
checks for ACCOUNTS: - missing_count(CUSTOMER_ID): name: completeness fail
Cependant, je voudrais seulement une alerte lorsque les informations personnelles ne sont pas là. Pas besoin d'échecs, je veux juste savoir si nous manquons de valeurs et que les pipelines continuent de faire leur travail après ce contrôle même s'il y a des valeurs nulles.
checks for CUSTOMERS: - missing_count(LAST_NAME): name: completeness_surname warn: when > 0 - missing_count(EMAIL): name: completeness_email warn: when > 0 - missing_count(PHONE_NUMBER): name: completeness_phone warn
Si un contrôle échoue, nous pouvons analyser plus en détail pourquoi sur notre tableau de bord. Ici, en cliquant sur le contrôle complétude, il y a une vue détaillée des lignes qui manquent de CUSTOMER_ID :
Validité
La validité a beaucoup à voir avec l'utilisabilité. Supposons que les parties prenantes de l'entreprise utiliseront ces données pour établir une stratégie de vente par région. Si elles essaient d'obtenir des métriques à partir des codes postaux, l'équipe de données doit fournir des codes postaux utilisables qui peuvent être regroupés et cartographiés. Dans ce contrôle, l'équipe de données s'est mise d'accord avec les utilisateurs de données pour dire que les codes postaux doivent contenir un maximum de cinq chiffres.
L'objectif est que ce contrôle lève une alerte chaque fois qu'il y a des valeurs sous ZIP_CODE qui ne correspondent pas au format attendu.
checks for CUSTOMERS: - invalid_count(ZIP_CODE): valid max length: 5 valid format: integer name: valid_zip_code warn
Comme dans l'exemple précédent, nous pouvons analyser plus avant quelles lignes ont échoué au contrôle et déclenché une alerte. Dans ce cas, la raison de l'échec est que certaines valeurs sous ZIP_CODE sont des Codes Plus écrits au format OLC, au lieu d'être des codes postaux écrits au format numérique attendu.
Unicité
Les identifiants clients sont extrêmement pertinents dans cette base de données, donc je veux vérifier qu'ils ne sont pas dupliqués. S'ils le sont, ce contrôle doit échouer car toutes ces entrées seront inutilisables tant qu'elles ne seront pas corrigées ou supprimées.
checks for CUSTOMERS: - duplicate_count(CUSTOMER_ID): name: unique_id fail
La vue sur le tableau de bord confirme qu'il y a des identifiants clients qui pointent vers plus d'un client.
Actualité
Pour la fraîcheur, ou l'actualité des données, nous allons mettre en œuvre un contrôle SQL personnalisé. Ce modèle peut fonctionner pour toute instruction SQL, ce qui le rend polyvalent pour tous les scénarios d'utilisation. Dans ce cas, je veux savoir à quel point l'information d'une entrée est récente en fonction de la dernière fois qu'un client s'est connecté à son compte. Si la connexion est antérieure à 5 ans, alors le contrôle lève une alerte.
Notez que le seul extrait SQL écrit ici est la requête échouée, tout le reste est du SodaCL.
checks for CUSTOMERS: - failed rows: samples limit: 100 fail query: |- SELECT * FROM CUSTOMERS WHERE LAST_LOGIN < DATEADD(YEAR, -5, CURRENT_DATE()) name: freshness warn
Encore une fois, chaque fois que des contrôles échouent, nous pouvons voir les métriques et les détails sur le tableau de bord. Dans ce cas, recevoir une alerte signifie qu'il y a plusieurs connexions datant de plus de 5 ans, ce qui pourrait être une information pertinente pour les parties prenantes de l'entreprise.
Ce type de contrôle SQL est très utile pour les validations qui n'existent pas par défaut sur Soda Cloud, ou même pour personnaliser les contrôles existants avec des besoins spécifiques à l'esprit.
Comment les Dimensions de la Qualité des Données se Rattachent aux Contrôles Automatisés
Comme pour toute question pertinente et la plupart des bonnes réponses : ça dépend. Ça dépend du type de données analysées, des types de contrôles, des attentes des parties prenantes concernant les données… Les trois contrôles que nous avons effectués ont couvert quelques dimensions. La plus évidente est la Complétude. Pas besoin d'expliquer celle-là. Une dimension pas si évidente couverte par le contrôle de complétude est l'Intégrité Référentielle. Lorsqu'une table pointe vers un identifiant client et que cette valeur manque, l'intégrité référentielle est violée, ce qui rend les données non utilisables à travers les ensembles de données.
Avec le deuxième contrôle (code_postal_valide), nous avons couvert, bien sûr, la Validité. Cette dimension doit être convenue par les équipes de données et les parties prenantes de l'entreprise. La validité dépendra de l'utilisation des données, donc les consommateurs de données doivent avoir leur mot à dire sur ce dont ils ont besoin et ce à quoi ils s'attendent. Ici, certains codes postaux ne sont pas valides. Mais pourquoi ? Ce n'est pas que quelqu'un ait simplement écrit "ma maison" à la place d'un code postal ; le code était là, il était simplement dans le mauvais format. Et cela a à voir avec la Cohérence. Lorsqu'on se met d'accord sur ce qui est valide et ce qui ne l'est pas, il y a aussi une conversation sur "que devrions-nous tous faire ?". Devons-nous saisir des codes postaux ou des Codes Plus ? Est-il préférable de simplement saisir le pays et la région ? De quel niveau de détail avons-nous besoin sur la démographie de nos clients ? (ce qui pourrait également se rattacher à la Précision. Je passe juste par là. Tout est connecté !). Lorsque les données sont cohérentes, la validité suit généralement. Aussi, un code postal avec 10 chiffres et lettres n'est pas Raisonnable.
Le troisième contrôle, id_unique valide, bien sûr, l'Unicité. Il le fait là où c'est important : dans les identifiants clients. Bien sûr, nous pouvons vérifier l'unicité à travers toutes les données, mais pourquoi ? L'âge ne sera pas unique dans une table avec des milliers d'entrées appartenant toutes à différentes personnes. Mais les identificateurs sont censés être uniques si nous voulons des données utilisables. De plus, nous vérifions à nouveau l'Intégrité Référentielle ; si les identifiants ne sont pas uniques, les tables qui ont CUSTOMER_ID comme clé étrangère pointeront vers deux points de données au lieu d'un.
Enfin, qu'est-ce que le contrôle fraîcheur couvre ? Actualité (ou Fraîcheur), pour commencer, puisqu'il examine à quel point un élément de données est ancien ou récent. Mais les contrôles de fraîcheur peuvent également nous aider à comprendre si les données reflètent la réalité telle qu'elle est maintenant. L'Exactitude n'a pas seulement à voir avec les valeurs réelles ou inexactes, mais aussi avec la façon dont la réalité se modifie et se transforme. Les salaires il y a dix ans ne sont pas comparables aux salaires actuels en valeurs absolues. Donc des données obsolètes peuvent être problématiques d’un point de vue de fraîcheur, mais aussi d'une perspective d'exactitude.
Référence Rapide : Mapping Contrôle-Dimension
Nom du Contrôle | Type de Contrôle SodaCL | Dimension(s) Principale(s) | Dimensions Secondaires | Action |
|---|---|---|---|---|
|
| Complétude | Intégrité Référentielle | Échoue lorsque l'identifiant client manque dans la table ACCOUNTS |
|
| Complétude | - | Avertit lorsque les informations personnelles manquent dans la table CUSTOMERS |
|
| Validité | Cohérence, Raisonnabilité | Attrape les Codes Plus au lieu de codes postaux à 5 chiffres |
|
| Unicité | Intégrité Référentielle | Identifie les identifiants clients dupliqués dans la table CUSTOMERS |
|
| Actualité (Fraîcheur) | Exactitude, Rapidité | Alerte lorsque le LAST_LOGIN date de plus de 5 ans |
Lisez plus sur des contrôles de qualité des données simples et efficaces que vous pouvez implémenter dès aujourd'hui pour aider votre entreprise à fonctionner plus efficacement ici : 6 Façons d'Améliorer votre Qualité de Données (avec des Contrôles d'Exemple de Qualité de Données)
La Valeur Commerciale de l'Approche Dimensionnelle
Réduction des Coûts
Adopter une approche multidimensionnelle pour comprendre la Qualité des Données dans une organisation signifie, tout d'abord, des réductions de coûts. Pourquoi ? Parce que moins de données inutilisables conduit à moins d'argent dépensé pour le stockage cloud. Moins de correctifs rapides entraîne moins de coûts opérationnels (et moins de coûts de santé mentale au sein de l'équipe de données, soyons réalistes). Cela signifie seulement qu'il y aura plus d'argent et d'énergie pour l'amélioration, la croissance, pour s'attaquer à ce problème de faible priorité qui traîne dans la liste de choses à faire depuis des mois. Gagne-gagne-gagne !
Prédictions Fiables
En ce qui concerne les avantages commerciaux, outre la réduction des coûts, avoir un système de données qui garde à l'esprit les dimensions de la Qualité des Données, et la Qualité des Données en général, conduit également à des analyses et/ou des prévisions plus fiables en aval. L'équipe de données sera heureuse, c'est sûr, mais la Vente sera aussi contente que leurs prévisions soient véritablement exactes, et le Produit sera satisfait des mesures qu'ils recueillent, et chaque équipe non-données qui n'écrit pas activement des requêtes SQL mais utilise en quelque sorte des données aimera la vie au lieu de sauter sur des appels pour réparer des tableaux de bord cassés.
Gouvernance des Données
Lorsque la Qualité des Données est appliquée, la Gouvernance des Données suit. Des sujets comme la conformité, la gestion, la sécurité et la surveillance deviennent beaucoup plus faciles si les utilisateurs de données accèdent à des informations fiables.
Argent
Et puis, nous bouclons la boucle. Tout cela (moins de coûts de données, des données fiables, de meilleurs insights, des équipes heureuses, des processus fluides) mène au point de vente principal du blog d'aujourd'hui : Plus d'Argent. Lorsqu'une entreprise utilise des données fiables, son image s'améliore, ses résultats commerciaux sont meilleurs et ses revenus augmentent. Toutes des victoires pour tout le monde.
Conclusion
Les contrôles de qualité des données sont essentiels pour toute organisation qui souhaite rester dans la course (en fait, plus de 50% des organisations ne mesurent même pas combien les mauvaises données leur coûtent). Tout comme un bon Ingénieur de Données tend à avoir une connaissance approfondie du secteur, une bonne Qualité des Données doit prendre en compte le contexte, ce qui donne aux entreprises le pouvoir d'obtenir les insights orientés par les données qu'elles désirent.
Analyser les dimensions de la Qualité des Données est un moyen de décider de ce qui est pertinent et de ce qui ne l'est pas. En ayant différents contrôles qui couvrent toutes les dimensions pertinentes, nous pouvons être rassurés sur la qualité des données. Et qui n’aime pas de bonnes données ?
De bonnes données fournissent de bons insights et, par-dessus tout, la fiabilité. Des données fiables sont l'objectif de tout Ingénieur de Données, ainsi que le rêve de toute équipe non-données. Personne ne veut de datasets qui ne sont pas exacts parce qu'aucune action valable ne peut en découler. Un ensemble de données avec 99% de complétude ne vaut rien si 50% des données sont dupliquées. Ainsi, en garantissant toutes les dimensions de la Qualité des Données, nous garantissons également que toute personne regardant les données puisse faire confiance à leur contenu.
Notre valeur en tant qu'experts des données est, bien sûr, des données fiables, mais aussi la valeur ajoutée qui en découle. De meilleures données mènent à de meilleures décisions, de meilleurs résultats, plus de croissance et, en fin de compte, plus d'argent. C'est la ligne que nous vendons à nos organisations pour obtenir de meilleurs logiciels (ou conserver celui qui fonctionne déjà).
L'implémentation d'outils de Qualité des Données comme Soda est un must pour chaque organisation aujourd'hui, et travailler à travers la lentille des dimensions de la Qualité des Données peut aider les équipes de données et non-données à atteindre leurs objectifs.
Questions Fréquemment Posées
Quel cadre devrais-je utiliser : DAMA, ISO 8000 ou Wang & Strong ?
Choisissez en fonction des besoins de votre organisation. DAMA est complet et largement adopté dans la gestion des données. ISO 8000 est idéal pour les industries axées sur la conformité. Wang & Strong fonctionne bien pour les contextes académiques ou de recherche. La plupart des cadres se chevauchent de manière significative dans les concepts fondamentaux.
Un contrôle peut-il couvrir plusieurs dimensions de qualité des données ?
Oui ! La plupart des contrôles automatisés valident simultanément plusieurs dimensions. Par exemple, un contrôle de valeur manquante couvre à la fois la complétude et l'intégrité référentielle lorsqu'il s'agit de clés étrangères.
Comment les dimensions de la qualité des données se rapportent-elles à la gouvernance des données ?
Les dimensions de la qualité des données fournissent les critères mesurables pour les politiques de gouvernance des données. Elles aident à définir les SLA, à établir les seuils de surveillance et à créer la responsabilité de la qualité des données à travers les équipes.
À quelle fréquence les contrôles de qualité des données doivent-ils être exécutés ?
Cela dépend de la criticité des données et de la fréquence des changements. Les contrôles en temps réel pour les pipelines critiques, les contrôles horaires/quotidiens pour les données opérationnelles, et les contrôles hebdomadaires/mensuels pour les données historiques ou de référence sont des schémas courants.
Chaque organisation sait que les données peuvent apporter beaucoup de valeur commerciale. Nous vivons à l'ère du Big Data, pleinement immergés dans un monde axé sur les données, etc. Mais voici le problème : moins de la moitié des équipes de données parviennent réellement à apporter une valeur réelle à leurs entreprises. Et soyons honnêtes, personne n'en parle. Ça ne nous met pas vraiment en valeur.
En tant qu'ingénieurs de données, analystes ou DSI, nous savons tous à quoi ressemblent les bonnes pratiques. Mais les mettre en œuvre ? C’est là que cela devient compliqué. C’est toujours plus facile à dire qu'à faire.
Prenons les dimensions de la Qualité des Données : nous savons qu’elles existent en théorie, mais en pratique, nous espérons souvent qu'elles restent à l'arrière de notre esprit. Elles sont généralement traitées comme des concepts abstraits liés aux meilleures pratiques que nous pensons suivre… sauf si nous ne les suivons pas. Mais comme personne ne les suit vraiment, et que personne ne demande de mise à jour trimestrielle, elles ont tendance à passer inaperçues.
Quelles sont les Dimensions de la Qualité des Données ?
Les dimensions de la qualité des données sont des critères standardisés (tels que l'exactitude, la complétude, la cohérence et la rapidité) utilisés pour évaluer si les données sont adaptées à leur objectif. Ces dimensions offrent un cadre pour mesurer, surveiller et améliorer la qualité des données dans les organisations.
À mon avis, le concept derrière les dimensions DQ est de déterminer ce qui peut mal tourner avec les données. Nous n'y pensons pas constamment. Et nous ne devrions pas, du moins activement. Encore moins avec tout le reste, je ne crois pas avoir la capacité mentale d'extrapoler chaque action que je fais en explications théoriques de pourquoi je le fais. Je doute être le seul. Mais, quand les choses tournent mal, c'est agréable d'avoir quelque chose à quoi se raccrocher qui fonctionne.
Voici ma liste complète de dimensions DQ que je me rappelle souvent. Par "ma propre liste", je veux dire celle du Guide DAMA de la Gestion des Données. Et par "souvent", j'entends chaque fois que je rencontre des problèmes inexplicables qui me forcent à revenir aux bases. Plus tard, nous pourrons explorer certains contrôles automatisés de la Qualité des Données et voir quelles dimensions ils peuvent couvrir.
Quelles sont les Dimensions Fondamentales de la Qualité des Données?
Bien qu'il existe de nombreux cadres pour catégoriser les dimensions de la qualité des données — incluant le Corps de Connaissances en Gestion des Données de DAMA, la norme ISO 8000, le Cadre de Qualité des Données de Gartner, et le Cadre Conceptuel de la Qualité des Données (Wang and Strong 1996) — la plupart convergent vers des concepts fondamentaux similaires.
Comparaison des Cadres :
Cadre | Caractéristiques principales |
|---|---|
DAMA DMBOK | 11 dimensions (le cadre utilisé dans ce guide) |
ISO 8000 | Se concentre sur l'exactitude, la complétude, la cohérence et la crédibilité |
Wang & Strong | 15 dimensions regroupées en 4 catégories (intrinsèque, contextuelle, représentationnelle, accessibilité) |
Gartner | Met l’accent sur 6 dimensions clés (exactitude, complétude, cohérence, rapidité, validité, unicité) |
Il convient de noter que toutes les organisations ne donneront pas la même priorité à chaque dimension. Votre cas d'utilisation spécifique, les réglementations de l'industrie et les exigences commerciales détermineront quelles dimensions sont les plus critiques à surveiller et à appliquer.
Ma Liste des 11 Dimensions DQ, Qui n'est Probablement pas Votre Liste
Si cette liste a bien une chose, elle est exhaustive. Tous les cas d'utilisation n'ont pas besoin de couvrir toutes ces dimensions DQ, ni de pouvoir intégrer des vérifications et des processus automatisés qui garantissent que chaque dimension est incluse. Cependant, il est bon de s'en souvenir et d'y réfléchir. Au moins de temps en temps.
Complétude : Les données ont-elles des valeurs manquantes ? Si c’est le cas, sont-elles acceptables ou attendues ?
Exactitude : Mes données reflètent-elles la réalité ? Pour le savoir, ai-je suffisamment de connaissances sur l'industrie pour détecter quand ce n’est pas le cas ?
Cohérence : Y a-t-il des incohérences dans les données ? Tout le monde utilise-t-il les mêmes règles de formatage ? C'est-à-dire, les données d'un endroit correspondent-elles aux données pertinentes d'un autre endroit ?
Actualité : Ou, comme je préfère l’appeler, « fraîcheur ». Les données sont-elles à jour ? Décrivent-elles la réalité telle qu'elle est maintenant ?
Précision : Niveau de détail de l'élément de données. Cette colonne numérique a-t-elle besoin de quatre décimales ou est-il acceptable de trouver des valeurs tronquées ?
Confidentialité : Tout le monde peut-il accéder à cette table ? Devrait tout le monde avoir accès à cette table ? Comment puis-je surveiller qui a apporté des modifications ou consulté cet ensemble de données ?
Raisonnabilité : En gros et de manière redondante : les valeurs que je vois sont-elles raisonnables ? Est-ce déraisonnable que les ventes aujourd'hui soient 500% de la moyenne des ventes des 30 derniers jours ? Ou est-ce le 24 décembre ?
Intégrité Référentielle : On parle beaucoup dans l'industrie de ce qu'est l'intégrité en tant que dimension. Mais je vais l'ignorer parce que je le peux, et ne définir que l'intégrité référentielle : chaque fois qu'une clé étrangère agit comme un identifiant unique, l'enregistrement dans la table référencée doit a) exister, et b) être unique.
Rapidité : Quand l'information est-elle disponible ? Quand l'information est-elle attendue ? Les données sont-elles disponibles au moment voulu ?
Unicité : Assez explicite : y a-t-il des doublons ?
Validité : Les données ont-elles du sens ? Sont-elles utilisables pour (excusez la redondance) les utilisateurs, ou auront-ils des tas d'erreurs en essayant de les valider ?
Tout le monde ne sera pas complètement d'accord avec cette liste, mais la plupart des gens seront d'accord avec certains éléments. C'est tout ce qui compte. Chaque cas d'utilisation nécessitera l'examen de différentes dimensions, et chaque industrie aura une vision différente des parties de la Qualité des Données qui sont pertinentes dans le domaine. Cependant, la base de la Qualité des Données devrait être la même pour tout le monde. C'est pourquoi, à l'heure actuelle, nous devrions tous mettre en place des contrôles automatisés lors du traitement de quantités considérables de données.
Pourquoi Mettre en Place des Contrôles de Qualité des Données ?
Eh bien, tout d’abord, parce qu’il n’est tout simplement pas possible d’avoir de bonnes données si nous les déversons dans un lac de données et les utilisons telles quelles. Où est la fierté là-dedans. Mais ensuite, et voici comment nous convainquons les organisations d'investir dans des équipes de données et de nous donner des outils cool et plus de mains, parce que la Qualité des Données rapporte plus d’argent.
Les entreprises ayant de mauvais cadres de Qualité des Données sont à la traîne. De bonnes données conduisent à de bonnes décisions commerciales et à de bonnes pratiques commerciales. Elles se traduisent par de grandes prédictions qui permettent à toute organisation de se préparer aux changements de marché avant qu’ils ne se produisent, et non pas juste d'y réagir. Elles permettent de comprendre l'expérience utilisateur et les besoins. Et plus important encore : c'est rentable. De bonnes données évitent tous les coûts associés à la correction des données inexactes et à la réanalyse.
1. Meilleures Décisions Commerciales
Les insights et prédictions orientés par les données ont une base très claire. C'est sur le nom. Les données. Les bonnes données permettent aux organisations de prendre des décisions véritablement orientées par les données.
L'une des étapes vers de bonnes données est de mettre en place des contrôles de Qualité des Données, et cela n’a de sens que de les automatiser. Non seulement pour épargner à un ingénieur ce travail manuel, mais aussi pour avoir des vérifications cohérentes qui fonctionnent régulièrement et émettent des alertes dès que quelque chose tourne mal.
2. Prédictions & Prévisions Fiables
Lorsque les données sont bonnes, exactes et pertinentes, il est alors facile pour les différentes sections d'une organisation de faire des prédictions fiables. Cela est crucial pour voir les changements de marché quand ils s’annoncent.
Les différentes équipes se concentreront sur divers aspects de l'avenir à venir, mais elles construiront toutes leur prévision sur les mêmes données. C'est pourquoi elles doivent être bonnes à tous les niveaux.
3. Optimisation des Coûts par l'Alignement des Équipes
La communication entre les équipes est essentielle au succès de toute organisation. La plupart des entreprises n’ont plus d’équipes de données en silo : les ingénieurs de données travaillent main dans la main avec toutes les équipes non-IT, ce qui entraîne des appels sans fin pour déterminer ce qu'elles veulent et ce dont elles ont besoin.
Pour optimiser ces relations, il est essentiel de s'assurer que tout le monde est à jour sur ce qui est attendu des données, ce qu'elles seront utilisées pour et comment y arriver. Est-il acceptable qu'un ensemble de données ait des valeurs incomplètes ? Quelle devise utiliserons-nous dans toutes les tables ?
Les questions pertinentes ne se poseront pas toujours au sein de l'équipe de données, et elles ne devraient pas. Elles viendront des utilisateurs de données, qui seront ceux qui nous montreront quelles dimensions sont importantes. Avoir une communication ouverte avec tout le monde permet de gagner du temps, des efforts et de l'argent, en optimisant les processus de données en général.
4. Tranquillité d'Esprit avec la Surveillance Automatisée
Pour avoir de bons produits de données, nous avons besoin de bons systèmes de données. Cela couvre tous les processus par lesquels les données passent, de la collecte à l'analyse et aux prévisions.
Nous devons garder à l'esprit la Qualité des Données non seulement lors de la construction d'un pipeline ou de nos discussions avec les consommateurs de données sur leurs besoins, mais même après avoir terminé de travailler avec les données. Sera-t-elle durable à long terme ? À mesure qu'elles subissent des demandes et des transformations, les données resteront-elles bonnes ? C'est là que les contrôles automatisés jouent leur rôle.
En validant les données avant, pendant et après un pipeline, nous garantissons qu'un produit de données spécifique est digne de confiance. Et nous n’avons même pas eu besoin de bouger un muscle, parce que tout s’est passé automatiquement. La touche humaine est toujours là, dans la construction des pipelines, la conception des contrôles, leur écriture, l'analyse des résultats, la détermination de ce qui ne va pas. Mais nous avons la tranquillité d’esprit de savoir que, sauf alerte, les données vont bien.
Commencer avec les Contrôles Automatisés
Toute personne disposant de données peut commencer à appliquer des contrôles de Qualité des Données dès aujourd'hui. C'est un processus simple qui peut (et devrait) être mis en œuvre à chaque étape d’un système de données. Tout le monde est le bienvenu. Ce tutoriel couvrira quelques contrôles de DQ de base pour montrer à quel point il est simple d’en implémenter, même sans expérience en codage.
Alors, commençons !
Exigences
Un Soda Cloud et créer un compte gratuitement
Une source de données connectée (Dans Soda Cloud, "Votre Profil" > "Sources de Données" > "Nouvelle Source de Données")
Si vous utilisez Soda dans votre propre environnement, vous pouvez appliquer ces contrôles avec SodaCL (Langage de Contrôles Soda).
Si, par contre, vous souhaitez une solution sans code, allez dans "Checks" > "New Check" sur Soda Cloud et il vous suffit de remplir les blancs.
Pour des raisons de simplicité, les contrôles suivants sont implémentés sur une base de données jouet dans Snowflake. Elle inclut les ensembles de données ACCOUNTS et CUSTOMERS, tous deux avec des informations sur les transactions et, devinez quoi, les clients. Les contrôles sont écrits en SodaCL et peuvent être utilisés dans toute implémentation de Soda. Pour une approche conviviale pour les débutants, cela peut se produire sans quitter l'interface utilisateur de Soda.
Implémentation des Contrôles
Complétude
Le premier contrôle, et le plus courant à inclure avant ou après tout pipeline, est un contrôle de complétude. Dans ce cas, je souhaite que mon contrôle échoue lorsque l'identifiant client est manquant car cette entrée sera inutilisable.
checks for ACCOUNTS: - missing_count(CUSTOMER_ID): name: completeness fail
Cependant, je voudrais seulement une alerte lorsque les informations personnelles ne sont pas là. Pas besoin d'échecs, je veux juste savoir si nous manquons de valeurs et que les pipelines continuent de faire leur travail après ce contrôle même s'il y a des valeurs nulles.
checks for CUSTOMERS: - missing_count(LAST_NAME): name: completeness_surname warn: when > 0 - missing_count(EMAIL): name: completeness_email warn: when > 0 - missing_count(PHONE_NUMBER): name: completeness_phone warn
Si un contrôle échoue, nous pouvons analyser plus en détail pourquoi sur notre tableau de bord. Ici, en cliquant sur le contrôle complétude, il y a une vue détaillée des lignes qui manquent de CUSTOMER_ID :
Validité
La validité a beaucoup à voir avec l'utilisabilité. Supposons que les parties prenantes de l'entreprise utiliseront ces données pour établir une stratégie de vente par région. Si elles essaient d'obtenir des métriques à partir des codes postaux, l'équipe de données doit fournir des codes postaux utilisables qui peuvent être regroupés et cartographiés. Dans ce contrôle, l'équipe de données s'est mise d'accord avec les utilisateurs de données pour dire que les codes postaux doivent contenir un maximum de cinq chiffres.
L'objectif est que ce contrôle lève une alerte chaque fois qu'il y a des valeurs sous ZIP_CODE qui ne correspondent pas au format attendu.
checks for CUSTOMERS: - invalid_count(ZIP_CODE): valid max length: 5 valid format: integer name: valid_zip_code warn
Comme dans l'exemple précédent, nous pouvons analyser plus avant quelles lignes ont échoué au contrôle et déclenché une alerte. Dans ce cas, la raison de l'échec est que certaines valeurs sous ZIP_CODE sont des Codes Plus écrits au format OLC, au lieu d'être des codes postaux écrits au format numérique attendu.
Unicité
Les identifiants clients sont extrêmement pertinents dans cette base de données, donc je veux vérifier qu'ils ne sont pas dupliqués. S'ils le sont, ce contrôle doit échouer car toutes ces entrées seront inutilisables tant qu'elles ne seront pas corrigées ou supprimées.
checks for CUSTOMERS: - duplicate_count(CUSTOMER_ID): name: unique_id fail
La vue sur le tableau de bord confirme qu'il y a des identifiants clients qui pointent vers plus d'un client.
Actualité
Pour la fraîcheur, ou l'actualité des données, nous allons mettre en œuvre un contrôle SQL personnalisé. Ce modèle peut fonctionner pour toute instruction SQL, ce qui le rend polyvalent pour tous les scénarios d'utilisation. Dans ce cas, je veux savoir à quel point l'information d'une entrée est récente en fonction de la dernière fois qu'un client s'est connecté à son compte. Si la connexion est antérieure à 5 ans, alors le contrôle lève une alerte.
Notez que le seul extrait SQL écrit ici est la requête échouée, tout le reste est du SodaCL.
checks for CUSTOMERS: - failed rows: samples limit: 100 fail query: |- SELECT * FROM CUSTOMERS WHERE LAST_LOGIN < DATEADD(YEAR, -5, CURRENT_DATE()) name: freshness warn
Encore une fois, chaque fois que des contrôles échouent, nous pouvons voir les métriques et les détails sur le tableau de bord. Dans ce cas, recevoir une alerte signifie qu'il y a plusieurs connexions datant de plus de 5 ans, ce qui pourrait être une information pertinente pour les parties prenantes de l'entreprise.
Ce type de contrôle SQL est très utile pour les validations qui n'existent pas par défaut sur Soda Cloud, ou même pour personnaliser les contrôles existants avec des besoins spécifiques à l'esprit.
Comment les Dimensions de la Qualité des Données se Rattachent aux Contrôles Automatisés
Comme pour toute question pertinente et la plupart des bonnes réponses : ça dépend. Ça dépend du type de données analysées, des types de contrôles, des attentes des parties prenantes concernant les données… Les trois contrôles que nous avons effectués ont couvert quelques dimensions. La plus évidente est la Complétude. Pas besoin d'expliquer celle-là. Une dimension pas si évidente couverte par le contrôle de complétude est l'Intégrité Référentielle. Lorsqu'une table pointe vers un identifiant client et que cette valeur manque, l'intégrité référentielle est violée, ce qui rend les données non utilisables à travers les ensembles de données.
Avec le deuxième contrôle (code_postal_valide), nous avons couvert, bien sûr, la Validité. Cette dimension doit être convenue par les équipes de données et les parties prenantes de l'entreprise. La validité dépendra de l'utilisation des données, donc les consommateurs de données doivent avoir leur mot à dire sur ce dont ils ont besoin et ce à quoi ils s'attendent. Ici, certains codes postaux ne sont pas valides. Mais pourquoi ? Ce n'est pas que quelqu'un ait simplement écrit "ma maison" à la place d'un code postal ; le code était là, il était simplement dans le mauvais format. Et cela a à voir avec la Cohérence. Lorsqu'on se met d'accord sur ce qui est valide et ce qui ne l'est pas, il y a aussi une conversation sur "que devrions-nous tous faire ?". Devons-nous saisir des codes postaux ou des Codes Plus ? Est-il préférable de simplement saisir le pays et la région ? De quel niveau de détail avons-nous besoin sur la démographie de nos clients ? (ce qui pourrait également se rattacher à la Précision. Je passe juste par là. Tout est connecté !). Lorsque les données sont cohérentes, la validité suit généralement. Aussi, un code postal avec 10 chiffres et lettres n'est pas Raisonnable.
Le troisième contrôle, id_unique valide, bien sûr, l'Unicité. Il le fait là où c'est important : dans les identifiants clients. Bien sûr, nous pouvons vérifier l'unicité à travers toutes les données, mais pourquoi ? L'âge ne sera pas unique dans une table avec des milliers d'entrées appartenant toutes à différentes personnes. Mais les identificateurs sont censés être uniques si nous voulons des données utilisables. De plus, nous vérifions à nouveau l'Intégrité Référentielle ; si les identifiants ne sont pas uniques, les tables qui ont CUSTOMER_ID comme clé étrangère pointeront vers deux points de données au lieu d'un.
Enfin, qu'est-ce que le contrôle fraîcheur couvre ? Actualité (ou Fraîcheur), pour commencer, puisqu'il examine à quel point un élément de données est ancien ou récent. Mais les contrôles de fraîcheur peuvent également nous aider à comprendre si les données reflètent la réalité telle qu'elle est maintenant. L'Exactitude n'a pas seulement à voir avec les valeurs réelles ou inexactes, mais aussi avec la façon dont la réalité se modifie et se transforme. Les salaires il y a dix ans ne sont pas comparables aux salaires actuels en valeurs absolues. Donc des données obsolètes peuvent être problématiques d’un point de vue de fraîcheur, mais aussi d'une perspective d'exactitude.
Référence Rapide : Mapping Contrôle-Dimension
Nom du Contrôle | Type de Contrôle SodaCL | Dimension(s) Principale(s) | Dimensions Secondaires | Action |
|---|---|---|---|---|
|
| Complétude | Intégrité Référentielle | Échoue lorsque l'identifiant client manque dans la table ACCOUNTS |
|
| Complétude | - | Avertit lorsque les informations personnelles manquent dans la table CUSTOMERS |
|
| Validité | Cohérence, Raisonnabilité | Attrape les Codes Plus au lieu de codes postaux à 5 chiffres |
|
| Unicité | Intégrité Référentielle | Identifie les identifiants clients dupliqués dans la table CUSTOMERS |
|
| Actualité (Fraîcheur) | Exactitude, Rapidité | Alerte lorsque le LAST_LOGIN date de plus de 5 ans |
Lisez plus sur des contrôles de qualité des données simples et efficaces que vous pouvez implémenter dès aujourd'hui pour aider votre entreprise à fonctionner plus efficacement ici : 6 Façons d'Améliorer votre Qualité de Données (avec des Contrôles d'Exemple de Qualité de Données)
La Valeur Commerciale de l'Approche Dimensionnelle
Réduction des Coûts
Adopter une approche multidimensionnelle pour comprendre la Qualité des Données dans une organisation signifie, tout d'abord, des réductions de coûts. Pourquoi ? Parce que moins de données inutilisables conduit à moins d'argent dépensé pour le stockage cloud. Moins de correctifs rapides entraîne moins de coûts opérationnels (et moins de coûts de santé mentale au sein de l'équipe de données, soyons réalistes). Cela signifie seulement qu'il y aura plus d'argent et d'énergie pour l'amélioration, la croissance, pour s'attaquer à ce problème de faible priorité qui traîne dans la liste de choses à faire depuis des mois. Gagne-gagne-gagne !
Prédictions Fiables
En ce qui concerne les avantages commerciaux, outre la réduction des coûts, avoir un système de données qui garde à l'esprit les dimensions de la Qualité des Données, et la Qualité des Données en général, conduit également à des analyses et/ou des prévisions plus fiables en aval. L'équipe de données sera heureuse, c'est sûr, mais la Vente sera aussi contente que leurs prévisions soient véritablement exactes, et le Produit sera satisfait des mesures qu'ils recueillent, et chaque équipe non-données qui n'écrit pas activement des requêtes SQL mais utilise en quelque sorte des données aimera la vie au lieu de sauter sur des appels pour réparer des tableaux de bord cassés.
Gouvernance des Données
Lorsque la Qualité des Données est appliquée, la Gouvernance des Données suit. Des sujets comme la conformité, la gestion, la sécurité et la surveillance deviennent beaucoup plus faciles si les utilisateurs de données accèdent à des informations fiables.
Argent
Et puis, nous bouclons la boucle. Tout cela (moins de coûts de données, des données fiables, de meilleurs insights, des équipes heureuses, des processus fluides) mène au point de vente principal du blog d'aujourd'hui : Plus d'Argent. Lorsqu'une entreprise utilise des données fiables, son image s'améliore, ses résultats commerciaux sont meilleurs et ses revenus augmentent. Toutes des victoires pour tout le monde.
Conclusion
Les contrôles de qualité des données sont essentiels pour toute organisation qui souhaite rester dans la course (en fait, plus de 50% des organisations ne mesurent même pas combien les mauvaises données leur coûtent). Tout comme un bon Ingénieur de Données tend à avoir une connaissance approfondie du secteur, une bonne Qualité des Données doit prendre en compte le contexte, ce qui donne aux entreprises le pouvoir d'obtenir les insights orientés par les données qu'elles désirent.
Analyser les dimensions de la Qualité des Données est un moyen de décider de ce qui est pertinent et de ce qui ne l'est pas. En ayant différents contrôles qui couvrent toutes les dimensions pertinentes, nous pouvons être rassurés sur la qualité des données. Et qui n’aime pas de bonnes données ?
De bonnes données fournissent de bons insights et, par-dessus tout, la fiabilité. Des données fiables sont l'objectif de tout Ingénieur de Données, ainsi que le rêve de toute équipe non-données. Personne ne veut de datasets qui ne sont pas exacts parce qu'aucune action valable ne peut en découler. Un ensemble de données avec 99% de complétude ne vaut rien si 50% des données sont dupliquées. Ainsi, en garantissant toutes les dimensions de la Qualité des Données, nous garantissons également que toute personne regardant les données puisse faire confiance à leur contenu.
Notre valeur en tant qu'experts des données est, bien sûr, des données fiables, mais aussi la valeur ajoutée qui en découle. De meilleures données mènent à de meilleures décisions, de meilleurs résultats, plus de croissance et, en fin de compte, plus d'argent. C'est la ligne que nous vendons à nos organisations pour obtenir de meilleurs logiciels (ou conserver celui qui fonctionne déjà).
L'implémentation d'outils de Qualité des Données comme Soda est un must pour chaque organisation aujourd'hui, et travailler à travers la lentille des dimensions de la Qualité des Données peut aider les équipes de données et non-données à atteindre leurs objectifs.
Questions Fréquemment Posées
Quel cadre devrais-je utiliser : DAMA, ISO 8000 ou Wang & Strong ?
Choisissez en fonction des besoins de votre organisation. DAMA est complet et largement adopté dans la gestion des données. ISO 8000 est idéal pour les industries axées sur la conformité. Wang & Strong fonctionne bien pour les contextes académiques ou de recherche. La plupart des cadres se chevauchent de manière significative dans les concepts fondamentaux.
Un contrôle peut-il couvrir plusieurs dimensions de qualité des données ?
Oui ! La plupart des contrôles automatisés valident simultanément plusieurs dimensions. Par exemple, un contrôle de valeur manquante couvre à la fois la complétude et l'intégrité référentielle lorsqu'il s'agit de clés étrangères.
Comment les dimensions de la qualité des données se rapportent-elles à la gouvernance des données ?
Les dimensions de la qualité des données fournissent les critères mesurables pour les politiques de gouvernance des données. Elles aident à définir les SLA, à établir les seuils de surveillance et à créer la responsabilité de la qualité des données à travers les équipes.
À quelle fréquence les contrôles de qualité des données doivent-ils être exécutés ?
Cela dépend de la criticité des données et de la fréquence des changements. Les contrôles en temps réel pour les pipelines critiques, les contrôles horaires/quotidiens pour les données opérationnelles, et les contrôles hebdomadaires/mensuels pour les données historiques ou de référence sont des schémas courants.
Which framework should I use: DAMA, ISO 8000, or Wang & Strong?
Choose based on your organization's needs. DAMA is comprehensive and widely adopted in data management. ISO 8000 is ideal for compliance-focused industries. Wang & Strong works well for academic or research contexts. Most frameworks overlap significantly in core concepts.
Can one check cover multiple data quality dimensions?
Yes! Most automated checks validate multiple dimensions simultaneously. For example, a missing value check covers both completeness and referential integrity when dealing with foreign keys.
How do data quality dimensions relate to data governance?
Data quality dimensions provide the measurable criteria for data governance policies. They help define SLAs, establish monitoring thresholds, and create accountability for data quality across teams.
How often should data quality checks run?
This depends on data criticality and change frequency. Real-time checks for mission-critical pipelines, hourly/daily for operational data, and weekly/monthly for historical or reference data are common patterns.
Trusted by the world’s leading enterprises
Real stories from companies using Soda to keep their data reliable, accurate, and ready for action.
At the end of the day, we don’t want to be in there managing the checks, updating the checks, adding the checks. We just want to go and observe what’s happening, and that’s what Soda is enabling right now.

Sid Srivastava
Director of Data Governance, Quality and MLOps
Investing in data quality is key for cross-functional teams to make accurate, complete decisions with fewer risks and greater returns, using initiatives such as product thinking, data governance, and self-service platforms.

Mario Konschake
Director of Product-Data Platform
Soda has integrated seamlessly into our technology stack and given us the confidence to find, analyze, implement, and resolve data issues through a simple self-serve capability.

Sutaraj Dutta
Data Engineering Manager
Our goal was to deliver high-quality datasets in near real-time, ensuring dashboards reflect live data as it flows in. But beyond solving technical challenges, we wanted to spark a cultural shift - empowering the entire organization to make decisions grounded in accurate, timely data.

Gu Xie
Head of Data Engineering
4,4 sur 5
Commencez à faire confiance à vos données. Aujourd'hui.
Trouvez, comprenez et corrigez tout problème de qualité des données en quelques secondes.
Du niveau de la table au niveau des enregistrements.
Adopté par
Product








Trusted by the world’s leading enterprises
Real stories from companies using Soda to keep their data reliable, accurate, and ready for action.
At the end of the day, we don’t want to be in there managing the checks, updating the checks, adding the checks. We just want to go and observe what’s happening, and that’s what Soda is enabling right now.
Sid Srivastava
Director of Data Governance, Quality and MLOps
Investing in data quality is key for cross-functional teams to make accurate, complete decisions with fewer risks and greater returns, using initiatives such as product thinking, data governance, and self-service platforms.
Mario Konschake
Director of Product-Data Platform
Soda has integrated seamlessly into our technology stack and given us the confidence to find, analyze, implement, and resolve data issues through a simple self-serve capability.
Sutaraj Dutta
Data Engineering Manager
Our goal was to deliver high-quality datasets in near real-time, ensuring dashboards reflect live data as it flows in. But beyond solving technical challenges, we wanted to spark a cultural shift - empowering the entire organization to make decisions grounded in accurate, timely data.
Gu Xie
Head of Data Engineering
4,4 sur 5
Commencez à faire confiance à vos données. Aujourd'hui.
Trouvez, comprenez et corrigez tout problème de qualité des données en quelques secondes.
Du niveau de la table au niveau des enregistrements.
Adopté par
Product
Solutions
Trusted by the world’s leading enterprises
Real stories from companies using Soda to keep their data reliable, accurate, and ready for action.
At the end of the day, we don’t want to be in there managing the checks, updating the checks, adding the checks. We just want to go and observe what’s happening, and that’s what Soda is enabling right now.
Sid Srivastava
Director of Data Governance, Quality and MLOps
Investing in data quality is key for cross-functional teams to make accurate, complete decisions with fewer risks and greater returns, using initiatives such as product thinking, data governance, and self-service platforms.
Mario Konschake
Director of Product-Data Platform
Soda has integrated seamlessly into our technology stack and given us the confidence to find, analyze, implement, and resolve data issues through a simple self-serve capability.
Sutaraj Dutta
Data Engineering Manager
Our goal was to deliver high-quality datasets in near real-time, ensuring dashboards reflect live data as it flows in. But beyond solving technical challenges, we wanted to spark a cultural shift - empowering the entire organization to make decisions grounded in accurate, timely data.
Gu Xie
Head of Data Engineering
4,4 sur 5
Commencez à faire confiance à vos données. Aujourd'hui.
Trouvez, comprenez et corrigez tout problème de qualité des données en quelques secondes.
Du niveau de la table au niveau des enregistrements.
Adopté par
Product
Solutions
Company