
As data has evolved from analytics to ML to AI, the world has been enamoured with the possibilities. Influencers shout: “Anything is possible in this world. Big Data, ML, and AI will change the game”. Yet these people also forget a key component of this journey—the Data’s Quality.
Data professionals and organisational leaders (beyond just the engineers, analysts, or governance people) are beginning to notice, mostly out of necessity, but they are still noticing…
While fewer people are shouting ‘Data Quality’ from the rooftops (like they are for AI), the right tools, approaches, and processes are starting to find their way into organisations.
And if you’ve been following our data quality journey so far, you’ve seen what this means:
The underlying problem of root causes and the tendency for companies to only treat the symptoms
Overarching approaches for handling data quality
Understand how the domain has adapted to today’s data world
Exploring the role of detecting data issues through observability
Each of these articles lays the necessary groundwork in understanding how to manage data quality effectively. However, we haven’t even properly addressed the most ‘hype’ area of this industry: shifting left.

AI is so 2023, but AI with data quality, now that is in-fleek (or whatever the kids say nowadays)
Shifting left means moving quality considerations earlier in the data lifecycle and focusing on prevention rather than reaction. My view on observability is that it should be done at the source (as defined last week), which is a shift to the left. Furthermore, there is a need to implement preventive, business-led measures that stop issues before they propagate through your data ecosystem.
So as we continue to shift left, there are two key practices we need to explain further: Data Contracts and Testing.
Together, they represent a crucial evolution in data quality management, allowing organisations to move beyond the limitations of observability-only approaches and build quality into the very fabric of their data operations. Let’s jump in!
Data Quality Beyond Observability
Before we get into this shift left, it is worth circling back to Observability one last time.
While 5-10 years ago, there was MDM tooling and data catalogues, data quality really took off when companies started to invest in Data Observability tools. We discussed this at length in last week’s article, including the value these tools provide within a platform throughout the Data Ecosystem.
With Observability tools, we have visibility into data flows, anomaly alerts, and the ability to trace issues back to their sources with ease with intuitive quality health dashboards. Even this first step has been transformative for many organisations.
But observability is only the start. Within the platform play, it only addresses the detection component, and as data volumes/ sources grow exponentially and data ecosystems become increasingly complex, detection alone becomes insufficient for several reasons:
Reaction vs. Prevention: Observability functionality alerts you after problems have already occurred, meaning your data consumers may have already been affected
Scale Challenges: With massive data volumes, it becomes impossible to manually fix every error that observability tools detect
Root Cause Persistence: Without addressing underlying structural issues, the same problems will continue to recur
Alert Fatigue: Getting notified of errors/ issues is great, but not so great when those alerts don’t stop…
This is why most observability tools are evolving toward a comprehensive data quality platform approach that extends beyond detection to include preventative measures. This allows us to think about shifting left in a more holistic manner, considering the business requirements, quality standards, enforcement measures and ownership necessary to ensure data can be used and insights don’t go awry.
Within the ‘shift left’ idea, the data producer is responsible for the data’s quality (instead of the consumer) and this is done earlier on in the process (upstream). Still, both individuals must work together to ensure that the right requirements, tools, and governance processes are set up to address any issues.
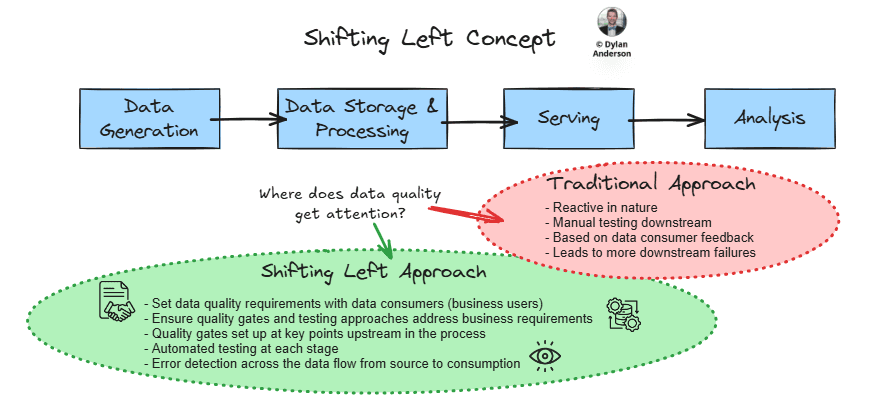
Shifting left is just about thinking further upstream, just like you’d think common sense would lead you.
So while detection is essential, enforcement is the next step companies need to take on their data quality journey.
Data Contracts: Setting Standards Upfront
The business world revolves around contracts. Think about your SOWs, SLAs, employment contracts, rental agreements, etc.
Why is this? So that both parties involved in the agreement are aligned on the rules and specifications of what takes place within this action
Given that many problems in the Data Ecosystem stem from a lack of communication, the concept of contracts has considerable merit!
I mean, think about how much organisations are spending on their platforms without drawing the link between the data producers/ generators and data consumers. Andrew Jones (the guy who created the term Data Contracts) says it well in his book Driving Data Quality with Data Contracts:
“The data generators are far removed from the consumption points and have little to no idea of who is consuming their data, why they need the data, and the important business processes and outcomes that are driven by that data.
On the other side, the data consumers don’t even know who is generating the data they depend on so much and have no say in what the data should look like in order to meet their requirements.”
Therefore, at their core, data contracts are formal agreements between data producers and consumers that explicitly define expectations for how data should be structured, what it means, and who’s responsible for it.
Similar to many other aspects of data, contracts draw inspiration from software engineering and the principle of encapsulation. Encapsulation focuses on ensuring that a change in one part of a system does not disrupt the rest of the system. The contract, therefore, works to maintain the system, enforcing data management that adheres to the set requirements between producers and consumers.
With this in mind, an effective data contract stands on five core pillars:
Business Semantics: Clear definitions of what each data element represents in business terms, represented through a commonly agreed-upon interface (i.e. the contract) to allow everyone to share the same understanding
Data Expectations: Explicit specifications for schema, format, constraints, and quality thresholds that data must meet. These are often set and maintained in SLA formats
Clear Ownership: Defined responsibilities for who produces the data, who uses it, who maintains it, and who to contact when issues arise
Automated Enforcement: Mechanisms to automatically validate data against contract specifications and handle violations
Security & Privacy Requirements: Specifications for how data should be protected, who can access it, and how it can be used
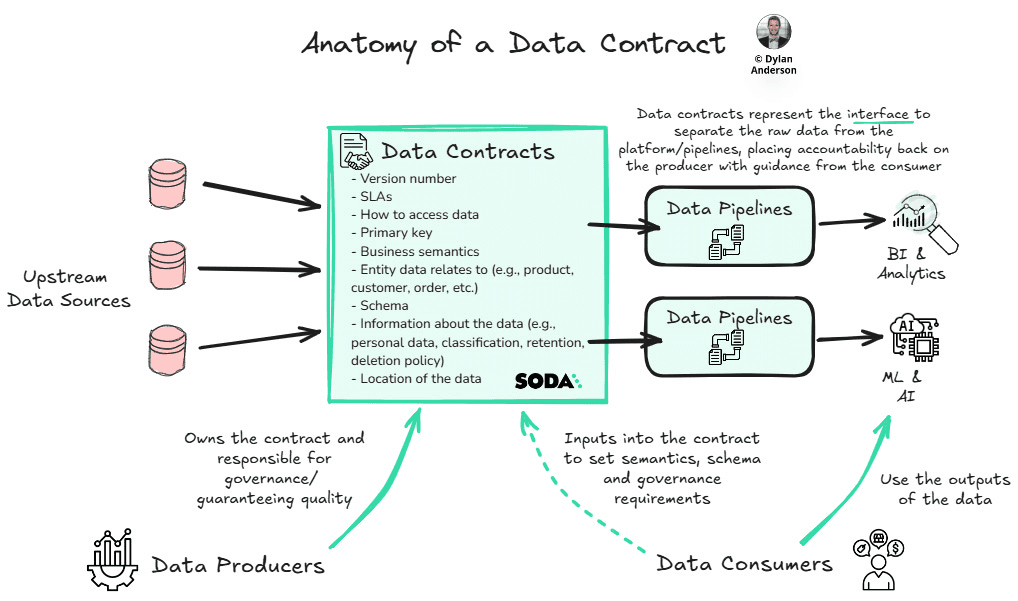
A high-level view of how a data contract sits in between the upstream sources and data pipelines, and how the producers & consumers interact with it.
Each of these pillars are important, as they provide the basis for improving and monitoring data quality. But even more than that, data contracts change the culture around how data is used and handled by applying discipline to how data is generated and handled to meet the requirements of data consumers. Instead of technical teams guessing how data should fulfil business expectations, they are given specific instructions to the business needs, how stakeholders will use that data, and specifications to manage it.
The advent of GenAI and low-code/no-code tooling also adds another component. Tools like Soda are embedding simple, intuitive interfaces into a unified environment, enabling data consumers and business users to define business rules, establish data standards, and align preventive strategies, such as data contracts, with advanced capabilities like anomaly detection. This approach embraces both “shift left” and “shift right” methodologies, fostering a more proactive and responsive data management culture. Going back to the culture piece, enabling this collaboration helps create buy-in and is transformation/ change management in action (which is the hardest part of data management and usage).
So what are the benefits of this?
Enhances Data Culture – Instead of opaque processes and RACIs on how to use data, stakeholders have a straightforward interface and tool to set standards and definitions.
Ownership Clarity – Establishes who is responsible for datasets, enabling direct communication when issues arise or questions need to be answered. In many organisations, this is one of the main inhibitors of progress.
Semantically-Modelled Data – Engineering teams rely on a schema, but often this is not built with the business in mind. Aligning the two through contracts ensures that data consumers can gain insight from the data being generated.
Quality Verification – Data quality checks help validate data against contract requirements using the language and standards set by the business.
Transparency into Data Flows – Combined with observability and testing, data contracts break large pipelines into manageable data components, allowing for understanding of transformations and schemas, and improving time to resolution.
Honestly, there are many more benefits than just these five, but it really depends on how you implement and utilise data contracts. It is still a very early and emerging field, and teams can go multiple different directions with them (especially depending on what tools/ ways they embed it into their ecosystem). The key thing is to make sure both producers and consumers of data understand the need for the contracts and the interface for using them is clear/ easy to use.
This article doesn’t get into the technical detail of setting up a Data Contract, but I very much encourage you to read Andrew Jones’s book or check out Soda’s website on how to do it. Data quality platforms, like Soda’s, are even starting to enhance the UI of contract development with embedded ML and a low-code/no-code interface, making contract development easier. Making it more intuitive is definitely the next step and will immensely help organisations implement these useful tools!
Explaining Quality Checks & Testing
With contracts, we have established what “good” looks like.
We now need to enforce these specifications through data quality checks and testing. These two elements ensure the data actually meets those standards throughout its journey of data transformations.
This practice shifts quality checks from post-processing validation (standard in pure observability plays) to in-process verification, integrating directly with CI/CD workflows and data pipelines. Therefore, as code changes are made, teams can more effectively identify and address issues before they impact downstream systems.
While that all makes sense at a high level, the specifics get complicated fast. Writing this section took a long time because there are so many ways to approach testing, and this doesn’t always align with data quality checks, stage gates or contracts.
Let’s break it down into three steps that link contracts, quality stage gates, and testing.
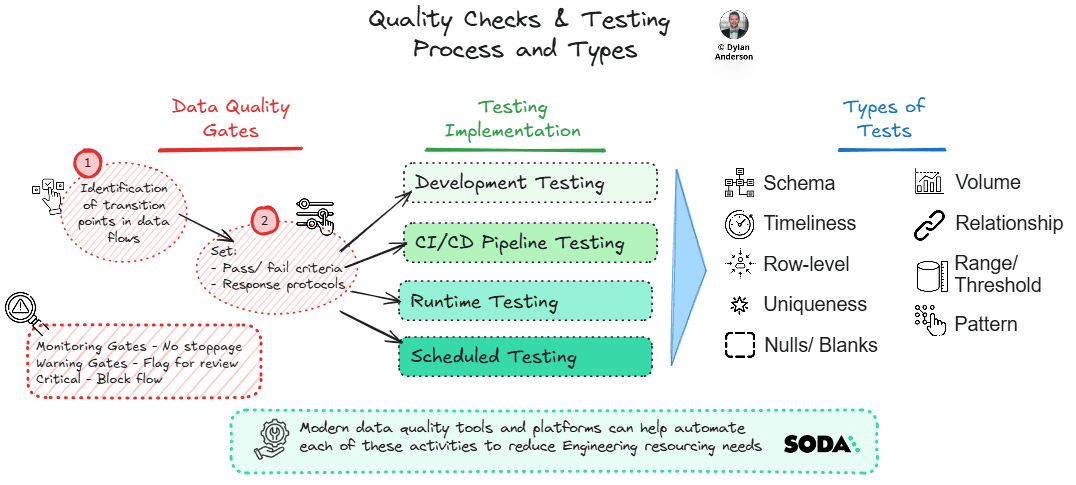
1) How to Set Up Quality Gates to Enforce Data Flows
Quality gates serve as checkpoints at critical junctures in your data flows where data must meet specified criteria before proceeding. They essentially operationalise your data contracts.
To set up effective quality gates:
Identify critical transition points in your data flow where quality validation provides maximum value
Define clear pass/fail criteria based on your data contracts
Establish response protocols for what happens when data fails to meet standards
Implement automated mechanisms to enforce these gates without manual intervention (data quality platforms/ tools are essential for this)
The most effective quality gate implementation follows a tiered approach:
Critical gates: Block non-conforming data entirely (e.g., rejecting records with missing required fields)
Warning gates: Allow data to proceed but flag potential issues for review (e.g., unusual value distributions)
Monitoring gates: Track quality metrics without impeding data flow (e.g., tracking field-level statistics)
This would integrate and align with any observability features the platform might have, alerting users or engineering teams based on priority. As observability tools start to embed Machine Learning and AI to better detect these quality breakdowns, we may see better diagnoses of the issue or even automated fixes. This will be crucial to will lessen the load on already overstretched engineering teams.
2) Where to Implement Testing at Different Data Lifecycle Stages
With quality gates set up and the data standards set by contracts, the next (and most important) enforcement mechanism comes into play—Testing!
Testing is a foundational practice across all engineering disciplines, but data quality testing presents unique challenges compared to traditional software testing. While software tests typically verify deterministic functions with clearly defined inputs and outputs, data quality testing must handle the inherent variability, volume, and evolving nature of data itself.
Across the modern data ecosystem, testing appears in different forms at key lifecycle stages:
1. Development Testing - Applied during code development to catch issues before they enter production. Data engineers implement unit tests for transformation logic and validation checks against sample datasets. Unlike traditional software testing, data development testing must account for representative data distributions and edge cases that might only appear in production-scale data. This stage is crucial because catching issues during development can be 10x less costly than addressing them in production.
2. CI/CD (Continuous Integration and Continuous Deployment/Delivery) Pipeline Testing - CI/CD is where many data teams, platforms, and tools fall short. Here, testing goes beyond code deployment processes and functionality, also validating data compatibility and quality preservation. Based on the contracts (or manual inputs), the pipelines are tested for schema evolution, backwards compatibility, and transformation accuracy. These tests ensure that changes to data pipelines don’t undermine existing quality standards or introduce subtle data distortions that might go unnoticed in functional testing.
3. Runtime Testing - As processing and transformations occur, this testing layer ensures that pipelines operate at production scale and speed while verifying that each transformation step preserves or improves data quality. Runtime testing catches issues that emerge only with production-scale data volumes or specific data patterns that weren’t present in test datasets. In modern data architectures, this often involves integrating quality checks directly into data processing frameworks like Spark, Flink, or dbt.
4. Scheduled Testing - This involves periodic testing to verify the ongoing quality of static datasets, which may be stored in a warehouse or data mart. Recognising that data quality is a continuous concern, these tests identify quality drift in existing datasets and detect emerging patterns or anomalies that develop over time. Scheduled testing ensures that your data assets remain reliable throughout their lifecycle.
There are a lot of other elements of testing we don’t go into here (e.g., ML Ops, systems, etc.), but what you can see from these four examples is that data quality testing is a lot of work. With the growing amount of data and multitude of sources, it must handle uncertainty, evolution, and context in ways that traditional testing doesn’t. Even if data values are technically valid, they may still represent issues in context (such as a sudden shift in distribution), and tests must be sophisticated enough to identify these nuanced problems while avoiding false alarms. Hence the combination with contracts and need to automate!
3) What Types of Testing are Commonly Done to Verify Data
Okay, now that we understand the stage gates and where testing is done, what types of tests are done? This goes back to my favourite graphic from my first data quality article, which discussed the different measures of quality, as each of these tests addresses a component of that.
It is worth noting that this is a subset of tests, and specific context or data sources may warrant unique tests/ approaches to determine and validate quality:
Schema: Validates that data adheres to expected structures, including field names, data types, and relationships, preventing basic structural issues that would break downstream processes
Timeliness: Ensures data meets freshness requirements and arrives within expected timeframes, preventing decision making on stale or delayed information
Row-level: Validates individual records against business rules and constraints. This includes format validation, required field checks, and compliance with business-specific requirements
Uniqueness: Verifies that values expected to be unique (like IDs or keys) don’t contain duplicates, helping maintain data integrity and preventing join issues
Null/ Blanks: Identifies missing values and ensures they’re handled appropriately based on business requirements, preventing unexpected null-related errors in transformations and analytics
Volume: Confirms that expected quantities of data are present, catching issues with incomplete data transfers or missing batches. This testing provides an early warning of ingestion or processing failures
Relationship: Validates that relationships between datasets are maintained, including referential integrity and expected cardinality. If an organisation has a correctly set up data model, this type of testing is crucial to maintain it!
Range/Threshold: Ensures numerical values fall within acceptable bounds and flags outliers for review
Pattern: Detects whether data matches expected patterns, such as email addresses or credit card numbers, to prevent invalid entries. This will be more common as ML/ AI advances and is a key differentiator in some existing data quality platforms
Any of these testing types can be used in conjunction with the different situations identified above to verify data quality at the specified quality gates. By combining these three elements, any person can see how quality management transitions from reactive detection to proactive prevention, thereby dramatically reducing the business impact of data quality issues.
Mapping How Data Flows from Source to Product (and Where You Need to Consider Quality!)
As we can see, enforcement is crucial to setting standards and maintaining high data quality across the organisation. The bigger question is, how do you implement it throughout your data lifecycle?
Below you can see the end-to-end Data Ecosystem view with enforcement—contracts, quality gates, and testing—components highlighted along the data journey.
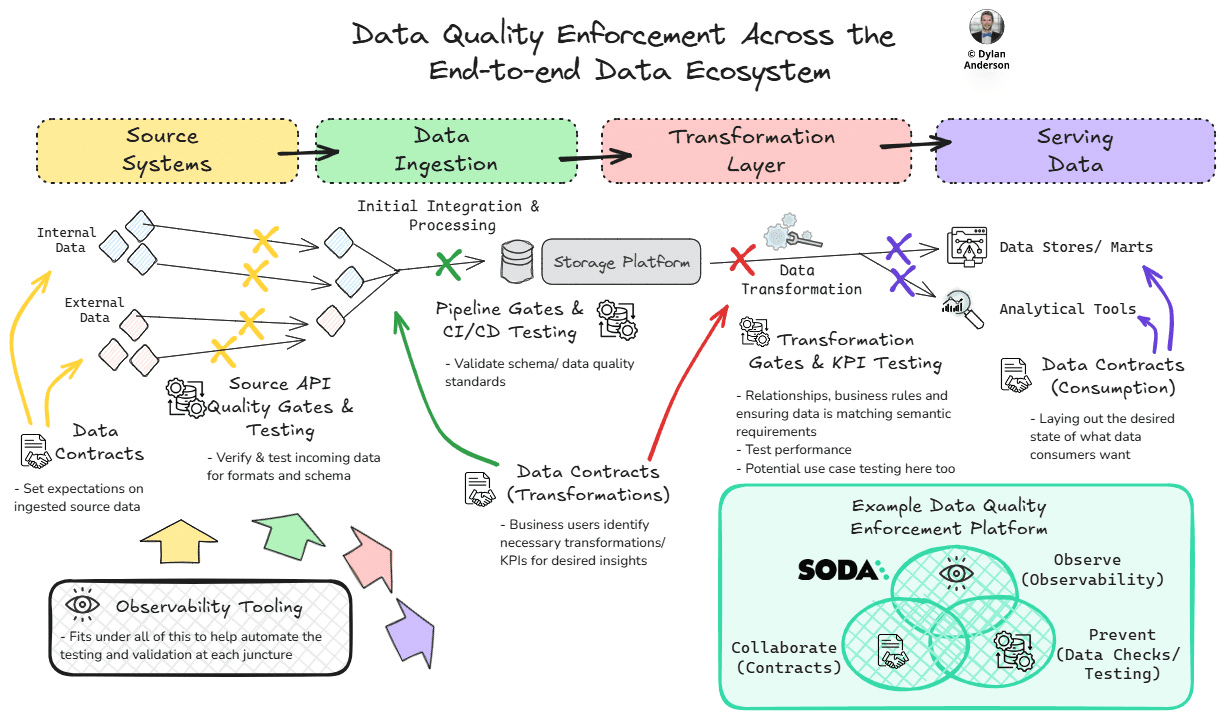
Having the proper testing, observability and contracts at the right points is crucial for an end-to-end data quality system.
Source Systems: Verifying Data at the Outset
As I have outlined before, data quality tracking needs to start where data originates, at the source. Data Contracts establish the original expectations for the data structure, semantics, and quality requirements from the data-producing systems. Working with source system owners, the data quality team/ engineers can establish clear expectations for the origin data quality. This should also include SLAs from the data source and information about their schema and connectors/ APIs.
Quality Gates should be set up at the API endpoints and where data is extracted from the source, ensuring data is aligned to those standards. Finally, Testing should focus on format validation, completeness and business rule verification during data creation. Therefore, if source systems change their schema, format or APIs, the data team will know. Observability tools are a significant help in this regard, automating many aspects of testing at the source.
Data Ingestion: Where Most Problems Occur
Data ingestion is a challenge; transitioning from external to internal systems is rarely straightforward. This is where data ownership begins and where data evolves from raw to somewhat cleansed, with initial processing and standardisation built into ingestion pipelines (although most of the cleaning is addressed at the transformation layer).
You can likely use the same Data Contract components as those set up for the initial source system. However, there should be more specific post-ingestion and consumer-led requirements that need to be noted. These would focus on initial processing changes or KPI standardisation, especially if multiple data sources are coming together. Likely, though, all of this will be baked into the original contract.
If you employ a standard ETL approach, Quality Gates can be set up between the extraction and loading phases to identify issues during the transition from source to storage. CI/CD and other pipeline testing will be crucial at this juncture, as they validate the schema and data standards, volume, and duplication as the data enters the internal systems. This is similar to source system testing, but quality standards across systems (and adherence to the organisation’s data model) will be more pronounced. Failure to match these standards will result in rejection and notification to the engineers.
Transformation Layer: Preserving Quality Through Change
The transformation layer often sees the highest concentration of data quality issues, as transformations can introduce errors, inconsistencies, or unintended side effects. This is where more robust cleaning and standardisation take place, helping build the foundational data assets that analytics and business teams will use in their data work.
As before, the Data Contracts should include stipulating the transformations required for data consumers to gather the insights they want/ need. Here, the focus will be on business rules, ensuring that business logic is correctly applied and maintained through transformations. The Quality Gates should sit between key transformation stages (e.g., transforming KPIs, merging customer data from multiple sources, etc.), as this is where processing is most likely to go wrong. To verify the quality gates, Testing should validate similar elements as before (e.g., nulls, blanks, volume, ranges, etc.) as well as relationships and business rules. Performance testing by engineers should also be considered here, as reducing the computational resources required benefits from both a cost and time perspective.
Serving Layer: Validating Quality for Consumers
The serving layer is where data consumers start accessing the data and assessing whether they actually trust it. Therefore, a high-quality serving layer is essential for driving adoption and ensuring business value from data investments.
Here is where the Data Contracts are fulfilled. Does the served data match what the data consumers want? Quality Gates established between the storage and data access points should verify this, ensuring the data is of high quality and meets the contract standards. Within Testing, the same tests may occur as before to ensure the quality, but you may add on specific use cases or freshness testing to ensure the data will work against the consumer’s needs.
With that, the data becomes available, and trust is established—or not. Another point is to include feedback mechanisms and channels for data consumers to report quality issues or suggest new quality checks. Data quality platform tools are helpful for this, given their integration of alerts and notifications, which provide a mechanism of communication between data producers, fixers (also known as engineers), and consumers.
The Holistic Consideration of Enforcing Data Quality
As attention on data quality continues to evolve, it is clear that thinking more holistically is the answer.
The shift from reactive to proactive is taking place as we speak and organisations are recognising the need to build quality into their data ecosystem rather than trying to inspect it in after the fact.
And it is incredibly encouraging to see companies build holistic products that encompass observability and enforcement. By providing an end-to-end solution for validating data quality, these tools enable companies to set, monitor, and manage their data from source to consumption. With data contracts establishing the standards, testing validating those standards, and quality gates enforcing them at critical junctures, organisations get a unified platform to improve on one of their biggest pain points.

What makes a platform approach powerful is how it connects different quality control mechanisms. When a pipeline test fails, the platform immediately links it to relevant contract specifications, provides context from observability data, and triggers appropriate gate actions—all within a single workflow.
As data volumes continue to grow and ecosystems become more complex, the organisations that thrive will be those that embrace proactive quality management. The shift left approach isn’t just a technical improvement—it’s a cultural change that affects how data teams work, collaborate, and deliver value.
With this in mind, part of building quality into the very fabric of your data operations leads to our next topic—ownership. Having data owners, governing it, and setting the proper accountability is one of the most challenging tasks in data today, so it is worth ten minutes of your reading time in our next article! Until then, have a great Sunday and don’t forget to subscribe, comment, and share this piece!
Take action!
Schedule a talk with our team of experts or request a free account to discover how Soda integrates with your existing stack to address current challenges.











