Comment ajouter l'observabilité des données et les Data Contracts à Databricks
Comment ajouter l'observabilité des données et les Data Contracts à Databricks
Comment ajouter l'observabilité des données et les Data Contracts à Databricks

Kavita Rana
Kavita Rana
Rédacteur technique chez Soda
Rédacteur technique chez Soda

Fabiana Ferraz
Fabiana Ferraz
Rédacteur technique chez Soda
Rédacteur technique chez Soda
Table des matières
Following up on the Databricks Data and AI Conference and our Launch Week, we're excited to showcase Soda's newest features, which are specifically designed to improve data reliability within the Databricks ecosystem.
In this article, we’ll walk you through our exciting new features, Metrics Observability and Collaborative Data Contracts. These integrate effortlessly with your current Databricks workflow, empowering both technical and non-technical teams to collaborate on data quality like never before.
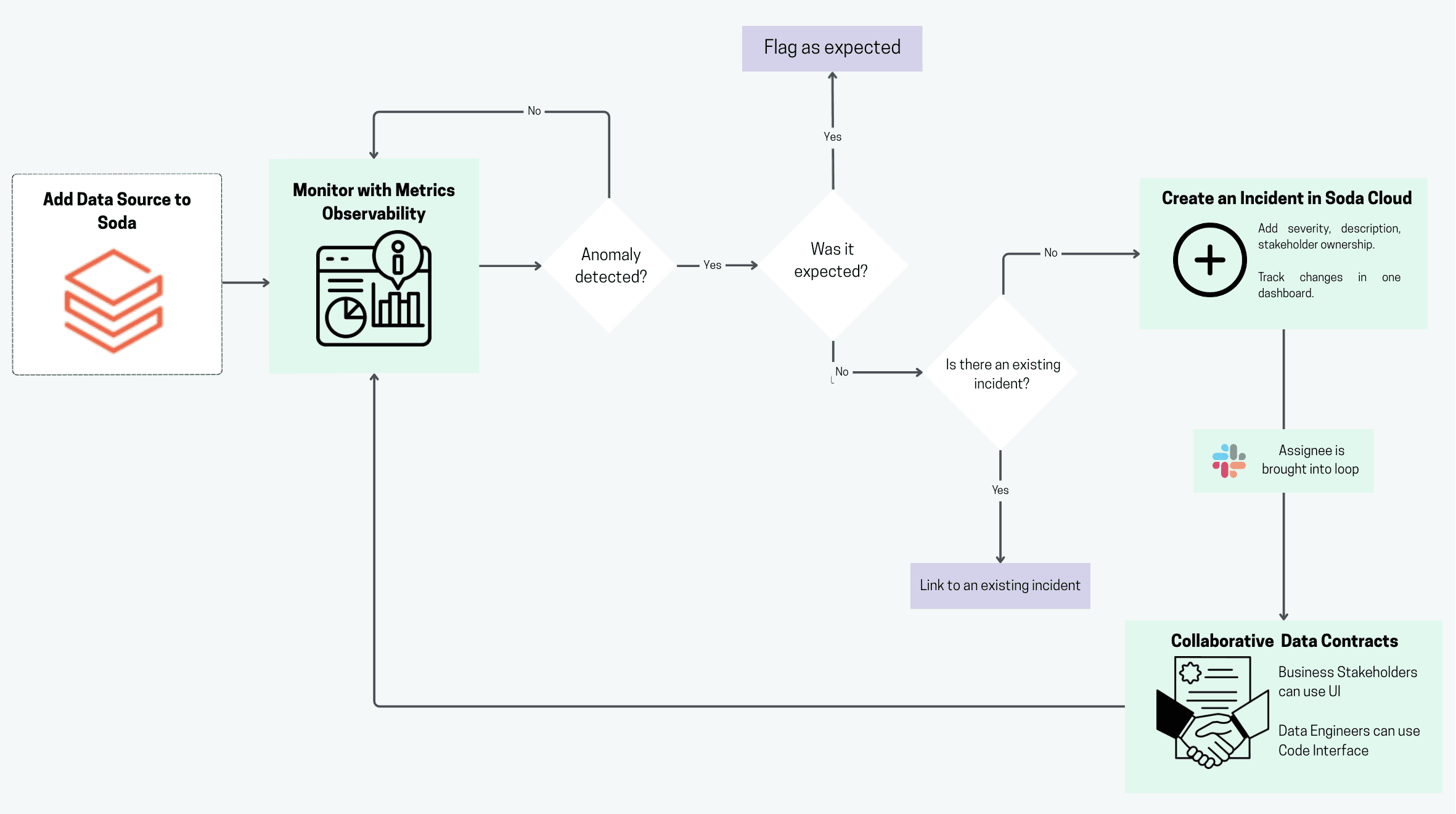
Getting Started
Databricks' tools are primarily code-centric and tied to their notebooks and Delta Live Tables, which can limit accessibility for non-technical users.
Soda, on the other hand, offers flexible integration paths with Databricks. Every user, from data engineers embedding checks to business users defining rules in Soda Cloud, can contribute to data analysis and decision-making without the need for coding.
Here’s how to get started:
Soda with Databricks SQL Warehouse
The new features are now available for Databricks SQL Warehouses. Users can easily connect data from a Unity catalog directly to Soda Cloud.
The Soda-hosted Agent enables Soda Cloud users to securely connect to data sources and perform automated data quality assessments.
For business users who prefer a fully no-code experience, Soda Cloud offers an intuitive web interface for defining and managing data quality checks.
Where to find Databricks credentials
In your Databricks dashboard, go to SQL → select SQL Warehouses → choose Serverless Starter Warehouse (or your specific warehouse) → select Connection details.
You'll also need to create a personal access token by clicking on the link on the right.
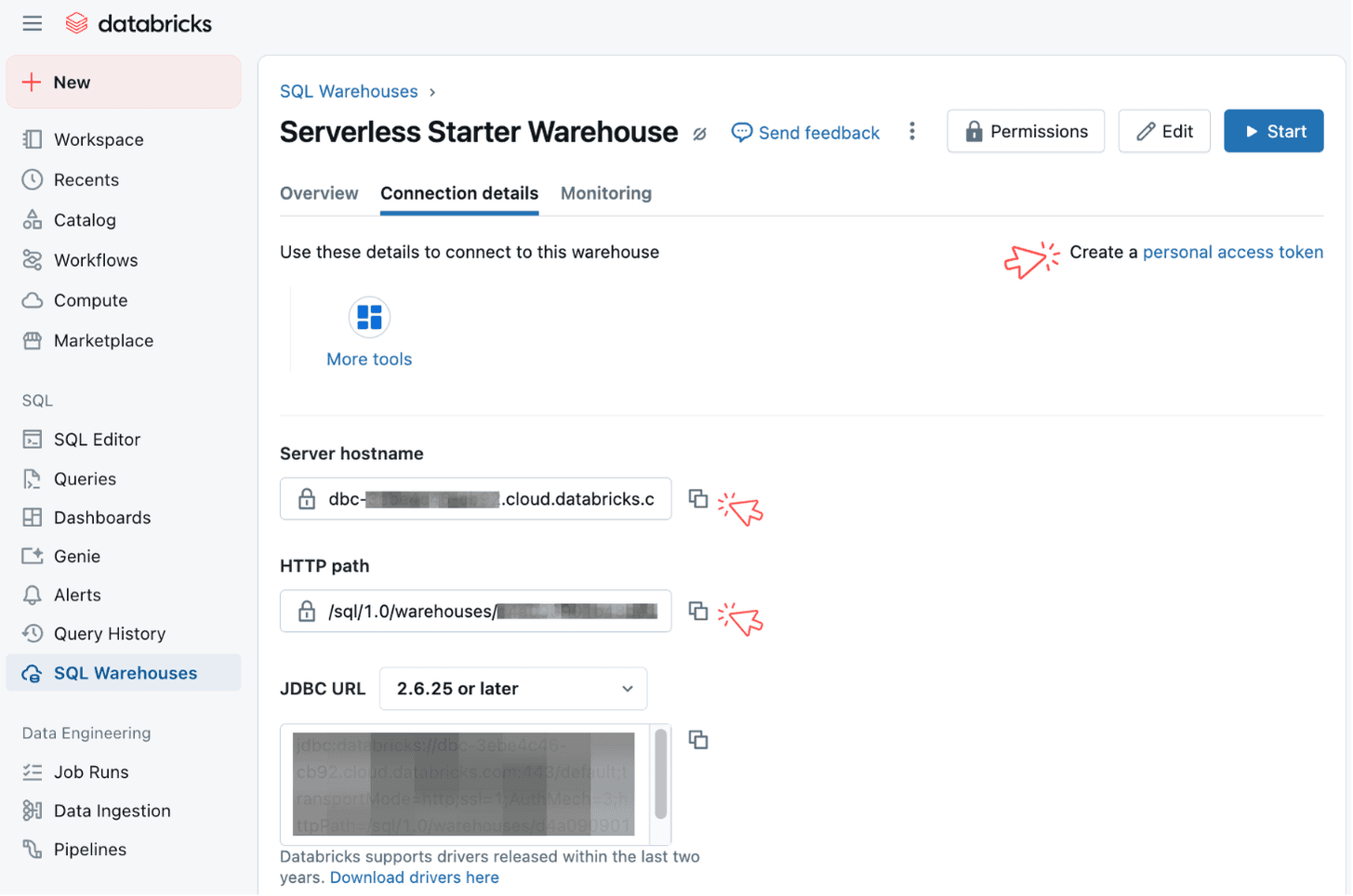
Connect Databricks to Soda Cloud
In Soda Cloud, you can connect your Databricks environment by providing the necessary credentials. For the detailed flow, please refer to our documentation.
Step 1: Sign up
If you don't have an account, sign up for free on https://soda.io/request-free.
After that, you'll be guided through the setup flow with an in-product tour.
We have created a beta environment specially for new trials where we host a data source with a dataset called regional_sales that gets updated daily. You can use this dataset and skip the next steps, or add a new datasource by following the instructions below.
Step 2: Add a Data Source
Soda Cloud’s no-code UI lets you connect to any Unity-Catalog–backed Databricks SQL Warehouse in minutes.
In Soda Cloud, click on Data Sources → + New Data Source
Name your data source "Databricks Demo" under Data Source Label
Switch to the Connect tab and fill in the following credentials to connect your Soda instance to Databricks.
Click Connect. This will test the connection and move to the next step.
Select the datasets you want to onboard on Soda Cloud.
Step 3: Enable Monitoring and Profiling
By default, Metric Monitoring is enabled to automatically track key metrics on all the datasets you onboard and alert you when anomalies are detected — more on that in the next sections.
This helps with:
Assessing how the data quality metrics were performing in the past.
Using them as training data for the anomaly detection algorithms.
Click Finish to conclude the onboarding of your datasets.
After the onboarding is finished, Soda runs a first scan using your Metric Monitoring settings. This initial scan provides baseline measurements that Soda uses to begin learning patterns and identifying anomalies.
The first step in building a scalable data quality strategy is enabling metric monitoring across all your datasets. Why start here? Because it's low-effort and high-impact.
Let's dive deeper into how it works.
Data Observability
Data observability involves continuously monitoring and assessing the health of your data throughout its lifecycle. It analyzes metadata, metrics, and logs to detect issues as they arise, helping teams maintain trust in their data.
Monitors track key data quality metrics over time, and our anomaly detection algorithm analyzes historical patterns when a metric behaves unexpectedly to decide if it should trigger an alert.
Anomalies are unexpected deviations in data that fall outside normal patterns, but don’t necessarily violate predefined rules or constraints. Unlike quality issues that can be detected through strict logic, anomalies typically manifest as subtle, context-dependent shifts. They often evade detection and quietly impact downstream systems.
Detecting them requires contextual awareness and an understanding of what “normal” looks like over time. And doing so, at the right time and with the right level of confidence, is not an easy feat.
Our metrics monitoring engine was developed from the ground up, without relying on off-the-shelf libraries or third-party components. This gave us full control over the modeling stack, from feature engineering to detection logic. It also means we’re not locked into rigid assumptions that compromise accuracy or interpretability.
We evaluate every model using a proprietary testing framework that runs experiments on hundreds of internally curated datasets containing known quality issues. This allows us to benchmark real performance, optimize for high precision, and reduce false positives that would otherwise flood alert channels.
Because we own every layer of the stack, we can explain predictions, trace anomalies back to their source, and continuously refine how the system behaves in production.
In tests against Facebook Prophet, our system detected over 70% more real data quality anomalies while sending significantly fewer false alarms.
Then, how can I get the best out of this feature and automatically obtain observable information about the quality of my data?
Metric Monitors
Soda's Metric monitoring is designed for broad, immediate coverage with minimal configuration.
Right after the onboarding of your data source, our tool efficiently scans metadata to track trends over time and automatically compares current behavior with historical baselines.
From day one, you gain visibility into essential indicators, such as whether data arrives on time, if the volume aligns with past patterns, and whether any schema changes have occurred.
All you have to do is select a dataset and then go to the Metric Monitors tab — Soda's metrics observability dashboard.
On this dashboard, you'll see that key metrics are automatically monitored by default, helping you detect pipeline issues, data delays, and unexpected structural changes as they happen.
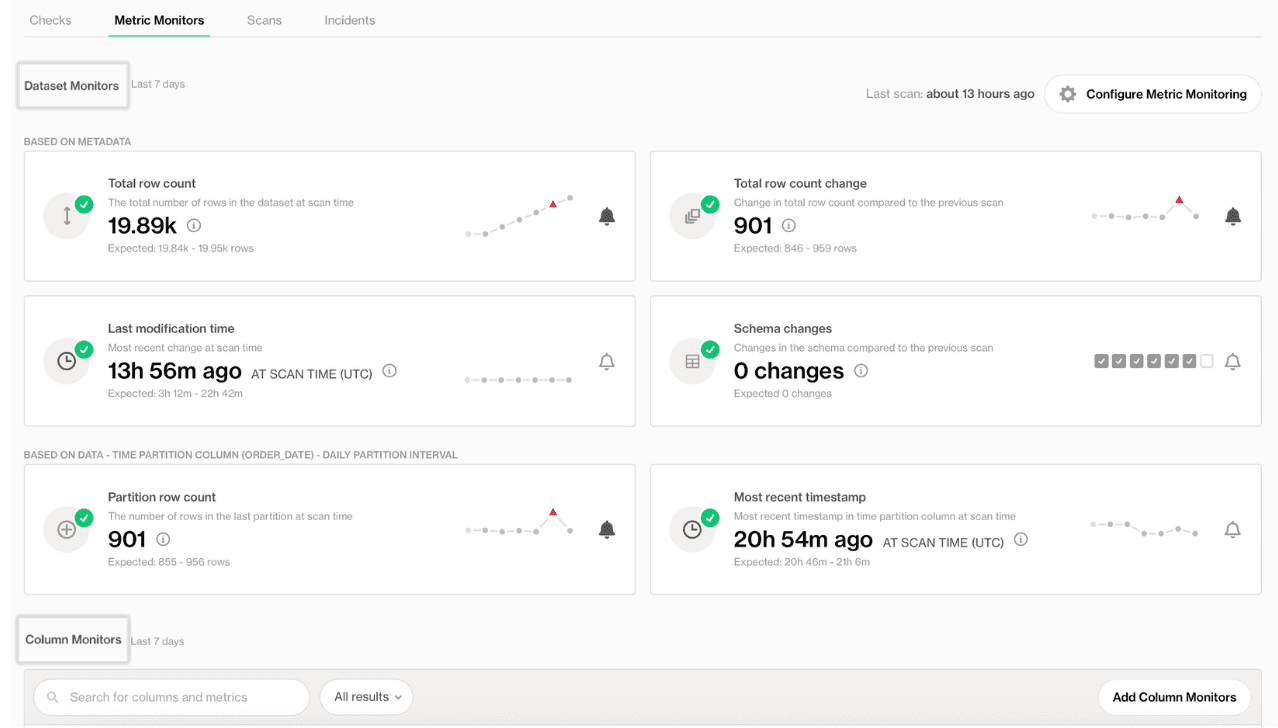
Soda offers two main types of monitors:
Dataset monitors: To monitor key metrics such as changes in row counts, schema updates, and insert activity. This makes them effective for identifying structural or pipeline-level issues across many datasets.
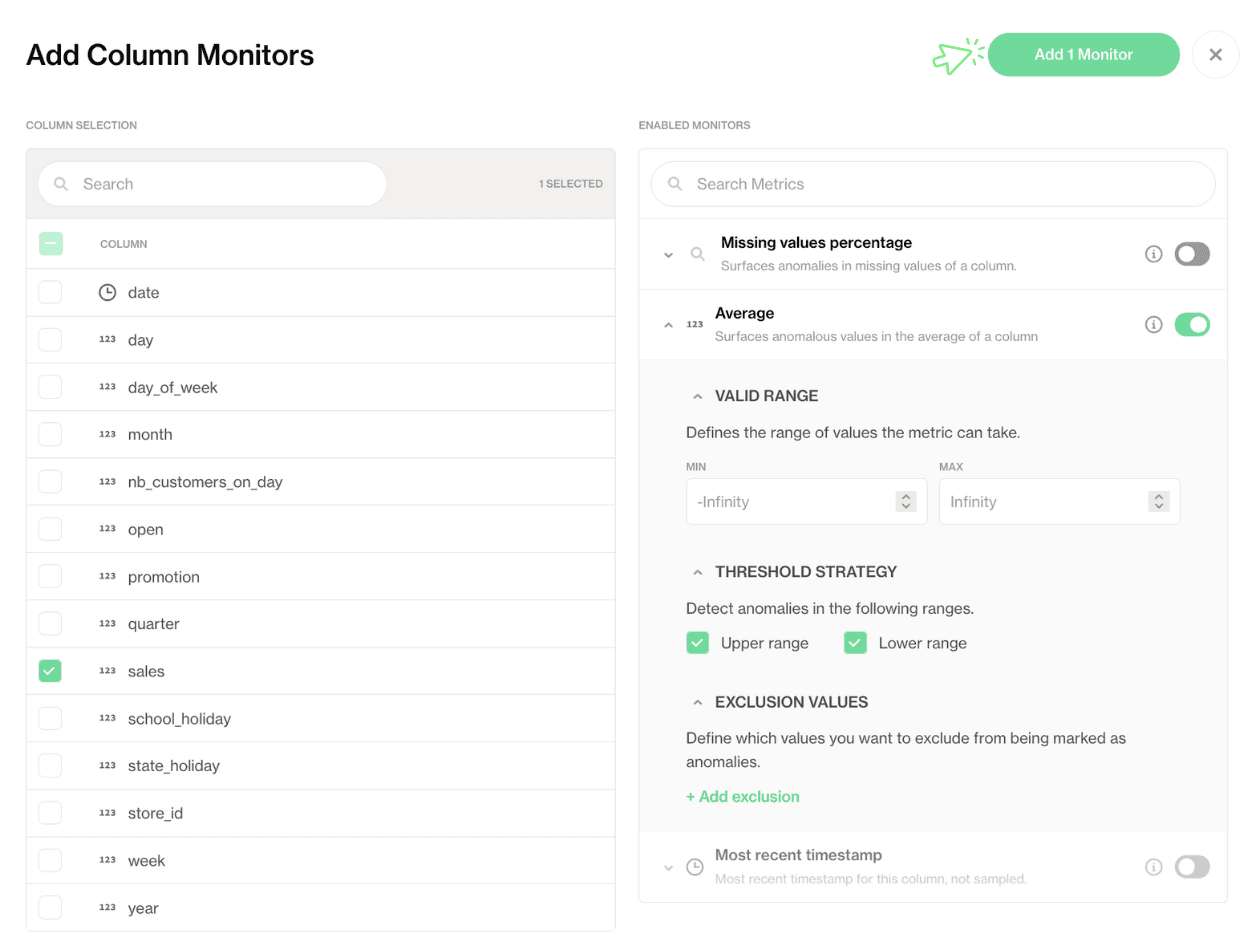
Column monitors: To target specific fields, enabling users to track missing values, averages, or freshness. These monitors capture data issues that affect accuracy or business logic at the column level.
You can customize what you monitor by hitting Configure Dataset Monitors or Add Column Monitors to monitor metrics based on either metadata or the time partition column.
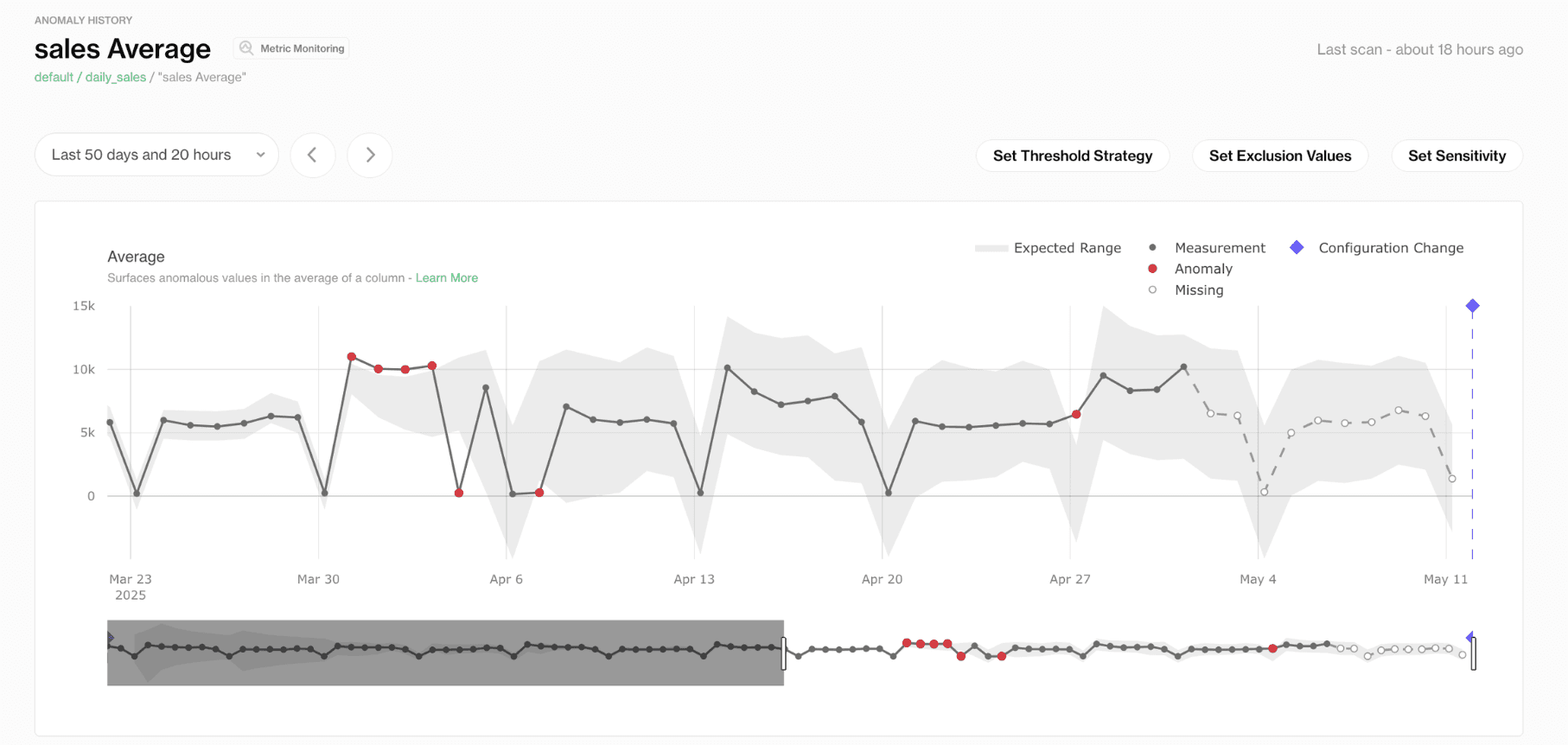
Then, to dive deeper into a specific metric, simply click on it. This will bring up detailed views, including the Anomaly History chart, where you can analyse the behavior of the selected metric over time.
This dashboard allows you to zoom in on specific time frames, enabling you to analyze issues more closely. You can click and drag to focus on a smaller time window, helping you isolate when exactly the anomaly occurred.
You can also adjust the timeline filters manually to view a custom date range that’s relevant to your investigation.
Soda's observability dashboard gives teams a proactive signal when something deviates from normal, even before downstream pipelines or dashboards break.
Configuring the Metrics Monitors
Users can further tailor the anomaly detection dashboard using three parameters: threshold strategy, exclusion values, and sensitivity.
1. Set Threshold Strategy
The threshold strategy allows you to set up which types of anomalies should be flagged.
Say you're monitoring the
total_row_countordaily_revenuemetrics in adaily_salesdataset. You might only care about unexpected spikes, a sudden surge in daily revenue due to a flash sale. In that case, you can disable the lower threshold, telling the system to only surface anomalies where the value exceeds the expected range.This level of control helps you tailor anomaly detection to your business context.
2. Set Exclusion Values
Setting exclusion values allows you to specify certain values or periods that should be ignored during anomaly detection. These excluded values will not be flagged as anomalies, even if they fall within the expected range.
3. Set Sensitivity
The sensitivity slider helps you control how strict or lenient the system is when detecting anomalies in your data.
If you move the sensitivity slider to the right, the expected range becomes wider. This means the system will only flag big changes as anomalies. For example, in that
daily_salesdataset, if you have a steady sales pattern, a wide expected range will make the system ignore small dips or spikes in sales and only flag bigger, more unusual changes.If you move the slider to the right, the expected range gets narrower. This is useful if you're looking to catch all possible deviations, even the less noticeable ones.
Most interestingly, the metrics monitoring engine is built to evolve. The model adapts to changes in your data, and it incorporates human feedback to improve over time.
Our new docs are looking really sharp. Head over there to learn more about how anomaly detection works at Soda, and check out the Data Observability section.
Now, once you’ve configured how anomalies are detected and displayed, the next step is handling them when they occur.
Creating an incident
Our machine learning model flags anomalous data points in red so that they can be easily spotted.
When you click on a red mark, a detail panel opens up showing more information about that measurement, including the metric and values involved.
From there, you can either mark the measurement as expected or as an anomaly — this helps the underlying model improve knowledge of your data patterns.
If you're unsure or want to investigate further, you can click Create Incident to log it. This opens an incident panel where you can add basic details as title and description.
After that, the incident will be available in the main Incidents tab where you can set the severity and the status, and assign a lead. The system automatically logs metadata of who reported it, when it was detected, and which dataset and quality check it relates to.
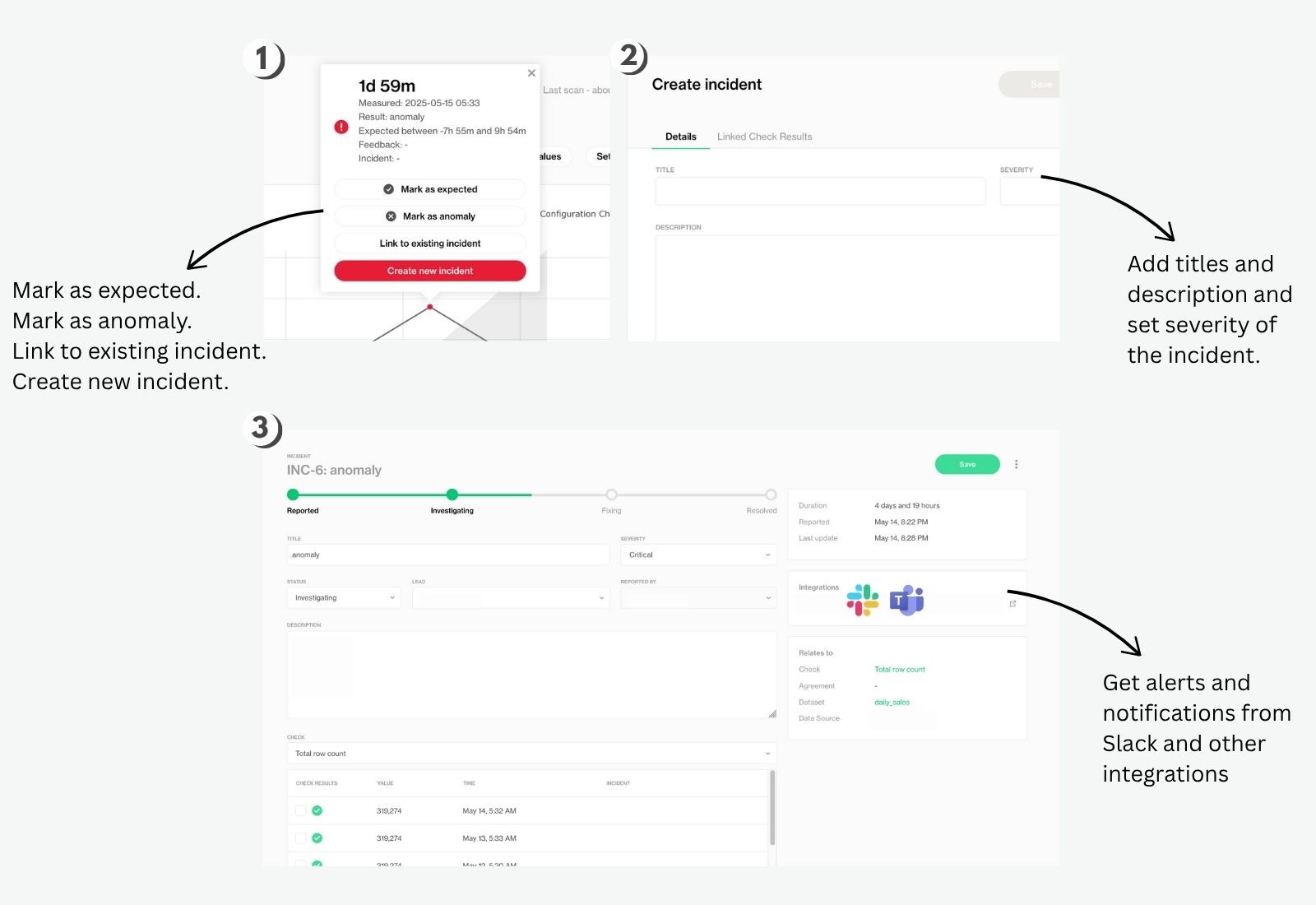
Once created, the incident moves through four stages: Reported, Investigating, Fixing, and Resolved, which you can track visually at the top of the screen. Then you can monitor progress and revisit historical data to ensure timely resolution.
A Slack, Jira, and MS Teams integration is also possible via webhooks. For more details on that, visit our Documentation page and check the section on Integrations.
When reviewing anomalies, use simple business logic and context to determine whether they truly require attention. For example, if there is a sudden spike, in say a sales column, then you can check if there was a marketing campaign, festival, or price drop that explains the surge. If yes, it’s expected and can be marked as such.
Think of anomalies as conversation starters. If you can confidently explain the root cause as part of normal operations, mark it as expected. Otherwise, open an incident to dig deeper and bring in the right people.
As you can see, data observability with Soda is very easy to set up, and you don't have to specify any rules manually.
With observability tools, we can see data flows, receive anomaly alerts, and easily trace issues back to their sources, automatically and at scale. But observability is only the beginning.
Once incidents are assessed and root causes understood, data producers and consumers can move toward defining stronger data quality standards, grounded in their specific business rules.
Data Testing
Data testing validates that your data meets the defined expectations before it reaches stakeholders, dashboards, or downstream systems. We start right and then shift left, bringing quality considerations earlier in the data lifecycle and focusing more on prevention than response.
At Soda, we believe that data quality should also be done at the source, on the left side of data pipelines. By shifting left, we can ensure that the data is trustworthy and the insights are correct, preventing problems from spreading throughout your data ecosystem.
If you've worked with production data systems, you’ve likely experienced the downstream impact of untracked changes. These problems aren't new, but they’ve become harder to ignore as organisations scale their data infrastructure and rely on increasingly interconnected pipelines.
A big part of the problem is that data quality has never had a clear owner. Producers generate the data, but the responsibility for verifying it often lands on consumers. Consumers could be analysts, data engineers, or business teams who are then left to patch problems downstream.
Without a shared definition of what the data should look like, teams implement ad hoc checks based on assumptions. These quality checks run post-ingestion or post-transformation, which means bad data is still in the loop, waiting to ruin someone's day.
Databricks’ built-in tools do a great job supporting data engineers within its ecosystem. But collaboration between producers and consumers is missing.
This is where we saw an opportunity to resolve this with Data Contracts.
Think of them as the Magna Carta for your datasets — a versioned agreement between producers and consumers that defines structure, quality expectations, and delivery guarantees:
Producers explicitly define the structure, quality metrics, and delivery expectations of the data they own. These definitions are enforced by the system, not left to interpretation.
Consumers operate with these clear guarantees. They can trust the data they depend on without needing to reverse-engineer upstream logic or build defensive checks around instability.
The contract serves as the single source of truth. It consolidates expectations into a shared, authoritative definition that is portable across environments and tools.
Collaborative Data Contracts
Data contracts have long been part of Soda’s CLI experience. With this release, we’ve taken it a step further and made Collaborative Data Contracts available in the UI.
Here’s what collaborative data contracts mean for data teams:
All changes to the contract are versioned and auditable. Schema updates, validation rule changes, and delivery modifications are tracked with full history for traceability and compliance.
Collaboration is built into the workflow. Contracts require producers and consumers to align on use cases and expectations before data moves through the system.
Engineers can also update the contracts from their favourite IDE, and the changes will be reflected in the Soda Cloud Data Contract (and vice versa).
Business users can define and manage expectations directly in Soda Cloud’s no-code interface.
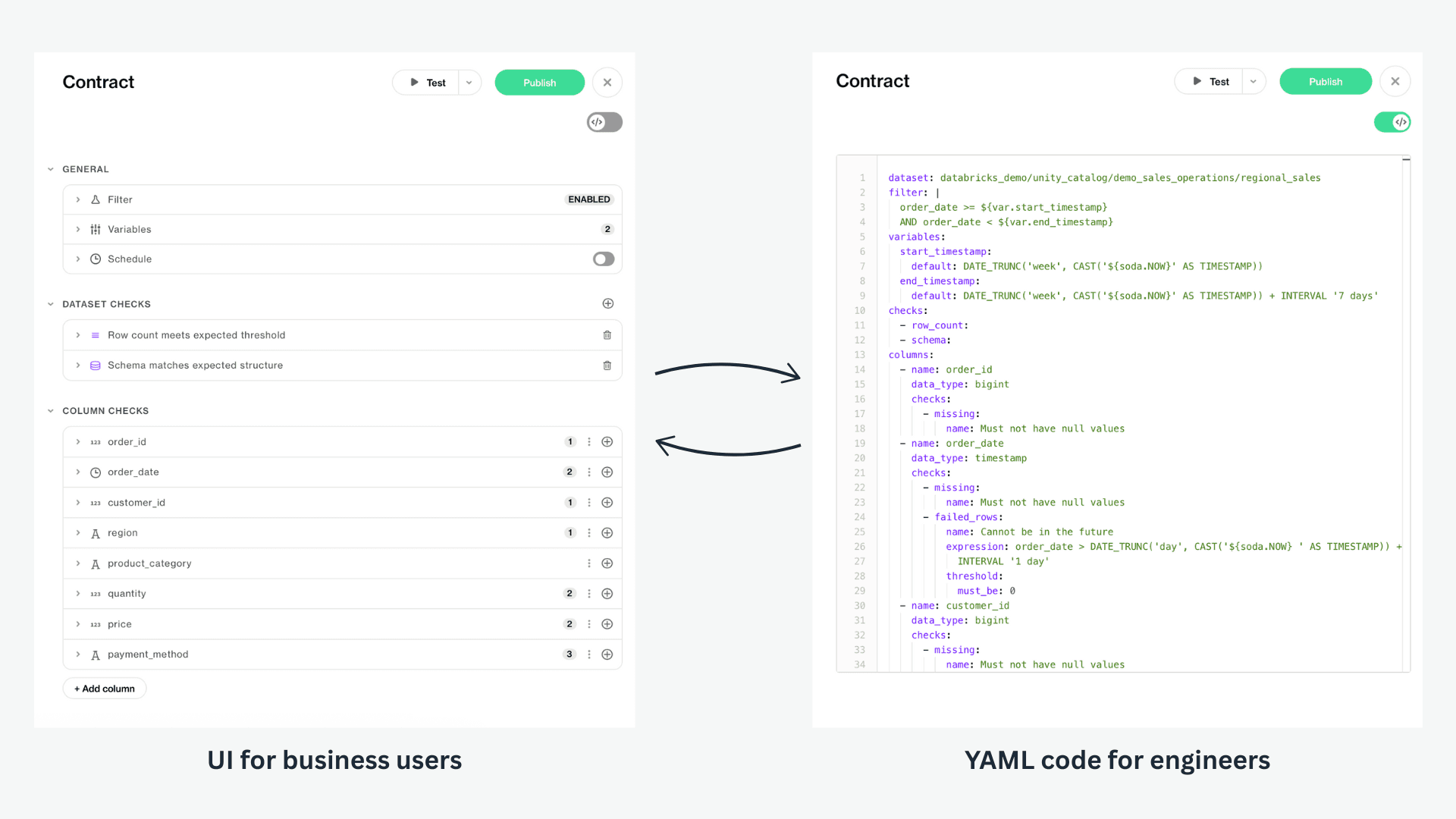
To try this in Soda, click on Create Contract on the dataset's Checks dashboard. This will open up the Data Contract UI, where you can define your data contracts in an easy-to-use interface.
If you prefer to work directly with the code, you can use the toggle to see the code. This allows developers to see the underlying code generated by the UI selections.
Users can then enforce rules on the dataset level, either on the columns or the schema structure, and enforce them on the column level.
Using the daily_sales dataset as an example, the data contract has two checks:
Column check:
store_idshould not be null.Dataset check: if a store is closed (
open = 0), there should be no promotions (promotion = 1). This flags rows where promotions are incorrectly logged for closed stores.
Once you’ve finished writing your data contract, it’s time to verify it. The system will check the dataset against the conditions you’ve set in the contract.
For example, after running this verification, there were 0 rows with a missing store_id, which passed the column check.
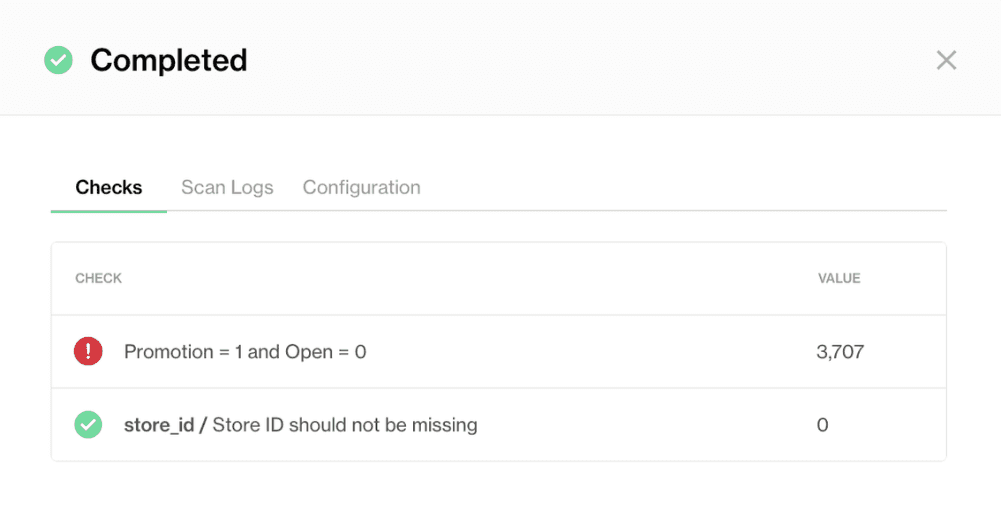
But, the dataset-level check flagged 3707 rows where promotions were recorded even though the store was marked as closed. This is invalid data that would have gone unnoticed without the contract. If the contract runs successfully and everything is verified, you can publish the contract. Once published, the contract will be active, and the dataset will be continuously validated against the contract rules.
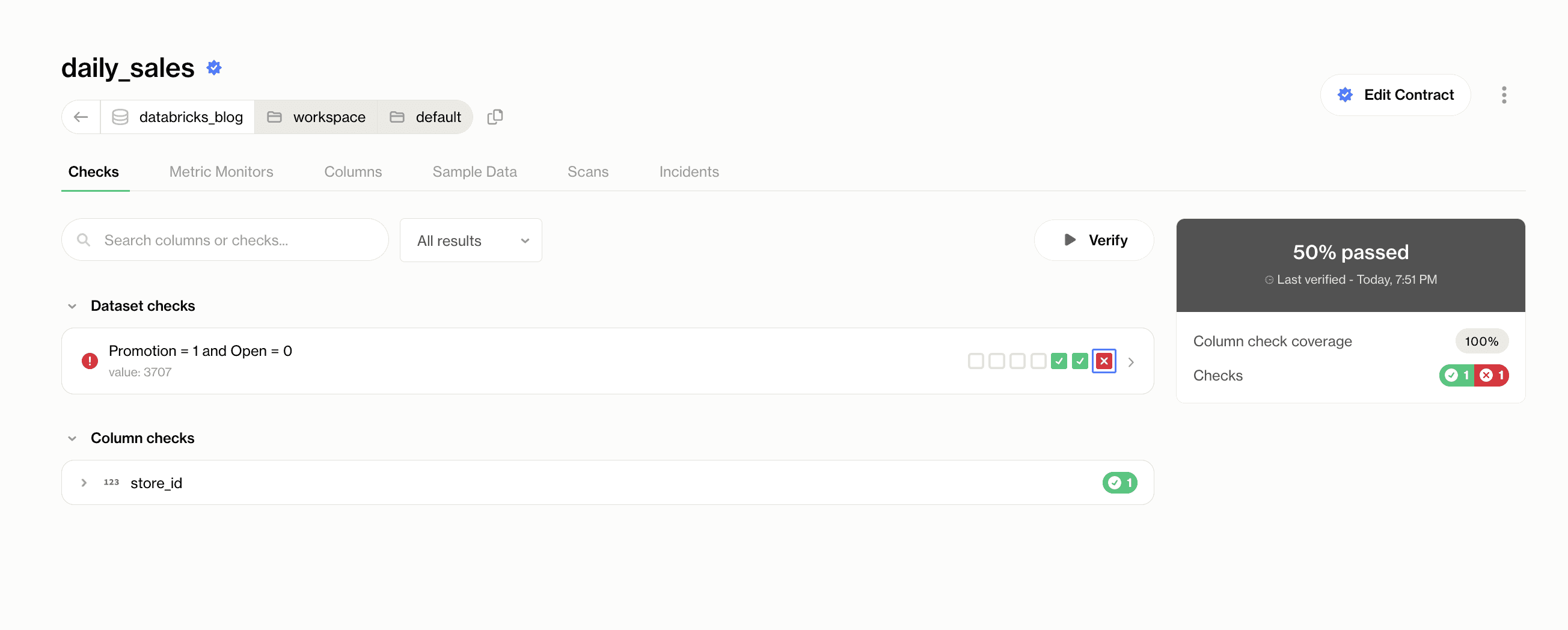
Depending on your organization's needs, the system can be set up to either completely stop the pipeline or send alerts while allowing the process to continue.
To learn more about our Data contracts capabilities, read the section on Data Testing in our documentation.
How Soda Complements Databricks's Data Quality Tool
Databricks DQX is particularly well-suited for certain scenarios:
When deep integration with native Databricks features is essential.
For teams already heavily invested in Databricks-native tools.
When working primarily with PySpark workloads and DataFrame operations.
For use cases requiring built-in quarantining capabilities within the Databricks environment.
DQX provides impressive capabilities, including support for all Spark workloads (including Delta Live Tables), different failure reactions (including quarantining invalid data), and different check severities.
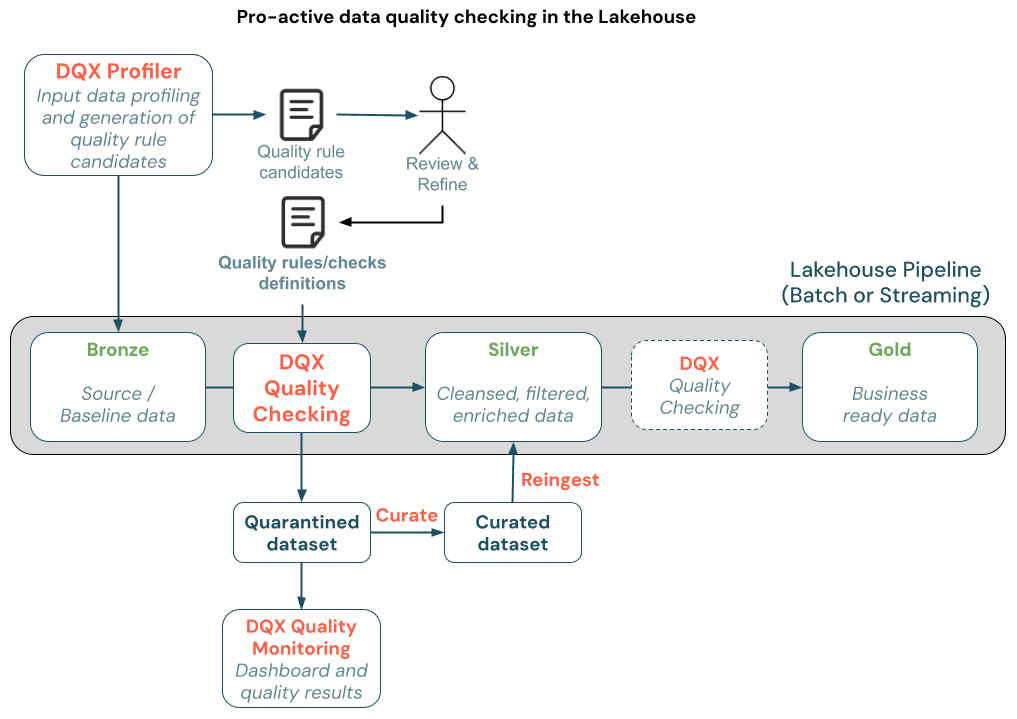
Soda enhances and broadens DQX's capabilities in several key ways.
Let's go over the main aspects and contrast them:
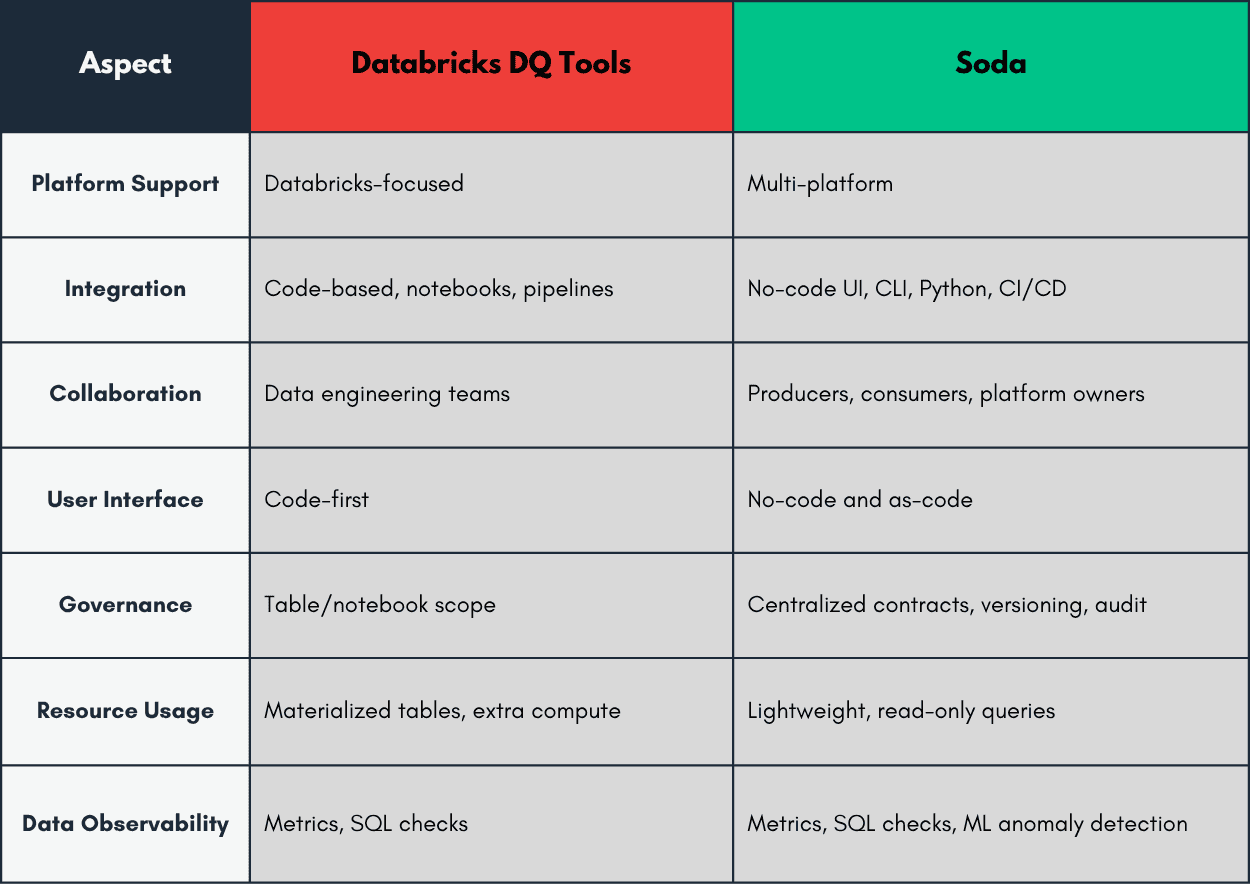
Soda's specialised platform expands Databricks' capabilities with dedicated features for cross-platform testing, advanced metrics monitoring, and collaborative data contracts.
Together, they form a solid foundation for ensuring that the data that feeds your critical business processes is reliable, accurate, and trustworthy.
This complementary approach creates a comprehensive data quality strategy that leverages the strengths of both platforms:
Use DQX for native Databricks quality checks integrated directly into your Spark workflows.
Leverage Soda for cross-platform testing, advanced monitoring, and organization-wide data quality governance.
Implement data contracts in Soda to establish formal quality expectations while using DQX for execution-time enforcement.
The combination of Soda's new features and Databricks' powerful processing capabilities results in a comprehensive approach to data quality that helps organisations avoid costly data issues before they disrupt business operations.
Our latest launch reworks the entire Soda platform to ensure seamless integration. By introducing a new major version, we are not only modernising the product's foundation but also delivering on our vision of data contracts as a unified, governable, and accessible approach to data quality based on ownership, trust, and collaboration.
Wrap up
By learning from historical patterns, Soda can detect both sudden and subtle shifts in data behavior, surfacing issues like broken pipelines, delayed loads, or unexpected schema changes before they escalate.
In large-scale environments with hundreds or thousands of tables, it's simply not practical to define a data contract for each one from the start. That’s why the smart move is to begin with Metrics monitoring: get broad coverage, catch issues early, and investigate root causes efficiently.
From there, you can take targeted action, shifting left by applying Data Contracts where they're most needed, directly at the source. This ensures that once a problem is solved, it stays solved.
We’ve rebuilt Soda to make this journey easier, combining observability, anomaly detection, and data contracts into one unified experience.
We wanted to make sure that Soda tools fit in well with the tools that people already trust and use every day. Even if you don't use Databricks, don't worry. The new version of Soda will be able to fully connect to all major data sources starting on June 30th.
Whether you’re working in Databricks or managing diverse data environments, Soda is designed to help you build trust in your data at scale.
Take Action!
Curious to try it out? Be first to try Soda’s new AI-powered metrics observability and collaborative data contracts.
Schedule a demo with the Soda team or request a free account to find out how much you could optimize your data quality strategy across your entire data ecosystem.
Following up on the Databricks Data and AI Conference and our Launch Week, we're excited to showcase Soda's newest features, which are specifically designed to improve data reliability within the Databricks ecosystem.
In this article, we’ll walk you through our exciting new features, Metrics Observability and Collaborative Data Contracts. These integrate effortlessly with your current Databricks workflow, empowering both technical and non-technical teams to collaborate on data quality like never before.
Getting Started
Databricks' tools are primarily code-centric and tied to their notebooks and Delta Live Tables, which can limit accessibility for non-technical users.
Soda, on the other hand, offers flexible integration paths with Databricks. Every user, from data engineers embedding checks to business users defining rules in Soda Cloud, can contribute to data analysis and decision-making without the need for coding.
Here’s how to get started:
Soda with Databricks SQL Warehouse
The new features are now available for Databricks SQL Warehouses. Users can easily connect data from a Unity catalog directly to Soda Cloud.
The Soda-hosted Agent enables Soda Cloud users to securely connect to data sources and perform automated data quality assessments.
For business users who prefer a fully no-code experience, Soda Cloud offers an intuitive web interface for defining and managing data quality checks.
Where to find Databricks credentials
In your Databricks dashboard, go to SQL → select SQL Warehouses → choose Serverless Starter Warehouse (or your specific warehouse) → select Connection details.
You'll also need to create a personal access token by clicking on the link on the right.
Connect Databricks to Soda Cloud
In Soda Cloud, you can connect your Databricks environment by providing the necessary credentials. For the detailed flow, please refer to our documentation.
Step 1: Sign up
If you don't have an account, sign up for free on https://soda.io/request-free.
After that, you'll be guided through the setup flow with an in-product tour.
We have created a beta environment specially for new trials where we host a data source with a dataset called regional_sales that gets updated daily. You can use this dataset and skip the next steps, or add a new datasource by following the instructions below.
Step 2: Add a Data Source
Soda Cloud’s no-code UI lets you connect to any Unity-Catalog–backed Databricks SQL Warehouse in minutes.
In Soda Cloud, click on Data Sources → + New Data Source
Name your data source "Databricks Demo" under Data Source Label
Switch to the Connect tab and fill in the following credentials to connect your Soda instance to Databricks.
Click Connect. This will test the connection and move to the next step.
Select the datasets you want to onboard on Soda Cloud.
Step 3: Enable Monitoring and Profiling
By default, Metric Monitoring is enabled to automatically track key metrics on all the datasets you onboard and alert you when anomalies are detected — more on that in the next sections.
This helps with:
Assessing how the data quality metrics were performing in the past.
Using them as training data for the anomaly detection algorithms.
Click Finish to conclude the onboarding of your datasets.
After the onboarding is finished, Soda runs a first scan using your Metric Monitoring settings. This initial scan provides baseline measurements that Soda uses to begin learning patterns and identifying anomalies.
The first step in building a scalable data quality strategy is enabling metric monitoring across all your datasets. Why start here? Because it's low-effort and high-impact.
Let's dive deeper into how it works.
Data Observability
Data observability involves continuously monitoring and assessing the health of your data throughout its lifecycle. It analyzes metadata, metrics, and logs to detect issues as they arise, helping teams maintain trust in their data.
Monitors track key data quality metrics over time, and our anomaly detection algorithm analyzes historical patterns when a metric behaves unexpectedly to decide if it should trigger an alert.
Anomalies are unexpected deviations in data that fall outside normal patterns, but don’t necessarily violate predefined rules or constraints. Unlike quality issues that can be detected through strict logic, anomalies typically manifest as subtle, context-dependent shifts. They often evade detection and quietly impact downstream systems.
Detecting them requires contextual awareness and an understanding of what “normal” looks like over time. And doing so, at the right time and with the right level of confidence, is not an easy feat.
Our metrics monitoring engine was developed from the ground up, without relying on off-the-shelf libraries or third-party components. This gave us full control over the modeling stack, from feature engineering to detection logic. It also means we’re not locked into rigid assumptions that compromise accuracy or interpretability.
We evaluate every model using a proprietary testing framework that runs experiments on hundreds of internally curated datasets containing known quality issues. This allows us to benchmark real performance, optimize for high precision, and reduce false positives that would otherwise flood alert channels.
Because we own every layer of the stack, we can explain predictions, trace anomalies back to their source, and continuously refine how the system behaves in production.
In tests against Facebook Prophet, our system detected over 70% more real data quality anomalies while sending significantly fewer false alarms.
Then, how can I get the best out of this feature and automatically obtain observable information about the quality of my data?
Metric Monitors
Soda's Metric monitoring is designed for broad, immediate coverage with minimal configuration.
Right after the onboarding of your data source, our tool efficiently scans metadata to track trends over time and automatically compares current behavior with historical baselines.
From day one, you gain visibility into essential indicators, such as whether data arrives on time, if the volume aligns with past patterns, and whether any schema changes have occurred.
All you have to do is select a dataset and then go to the Metric Monitors tab — Soda's metrics observability dashboard.
On this dashboard, you'll see that key metrics are automatically monitored by default, helping you detect pipeline issues, data delays, and unexpected structural changes as they happen.
Soda offers two main types of monitors:
Dataset monitors: To monitor key metrics such as changes in row counts, schema updates, and insert activity. This makes them effective for identifying structural or pipeline-level issues across many datasets.
Column monitors: To target specific fields, enabling users to track missing values, averages, or freshness. These monitors capture data issues that affect accuracy or business logic at the column level.
You can customize what you monitor by hitting Configure Dataset Monitors or Add Column Monitors to monitor metrics based on either metadata or the time partition column.
Then, to dive deeper into a specific metric, simply click on it. This will bring up detailed views, including the Anomaly History chart, where you can analyse the behavior of the selected metric over time.
This dashboard allows you to zoom in on specific time frames, enabling you to analyze issues more closely. You can click and drag to focus on a smaller time window, helping you isolate when exactly the anomaly occurred.
You can also adjust the timeline filters manually to view a custom date range that’s relevant to your investigation.
Soda's observability dashboard gives teams a proactive signal when something deviates from normal, even before downstream pipelines or dashboards break.
Configuring the Metrics Monitors
Users can further tailor the anomaly detection dashboard using three parameters: threshold strategy, exclusion values, and sensitivity.
1. Set Threshold Strategy
The threshold strategy allows you to set up which types of anomalies should be flagged.
Say you're monitoring the
total_row_countordaily_revenuemetrics in adaily_salesdataset. You might only care about unexpected spikes, a sudden surge in daily revenue due to a flash sale. In that case, you can disable the lower threshold, telling the system to only surface anomalies where the value exceeds the expected range.This level of control helps you tailor anomaly detection to your business context.
2. Set Exclusion Values
Setting exclusion values allows you to specify certain values or periods that should be ignored during anomaly detection. These excluded values will not be flagged as anomalies, even if they fall within the expected range.
3. Set Sensitivity
The sensitivity slider helps you control how strict or lenient the system is when detecting anomalies in your data.
If you move the sensitivity slider to the right, the expected range becomes wider. This means the system will only flag big changes as anomalies. For example, in that
daily_salesdataset, if you have a steady sales pattern, a wide expected range will make the system ignore small dips or spikes in sales and only flag bigger, more unusual changes.If you move the slider to the right, the expected range gets narrower. This is useful if you're looking to catch all possible deviations, even the less noticeable ones.
Most interestingly, the metrics monitoring engine is built to evolve. The model adapts to changes in your data, and it incorporates human feedback to improve over time.
Our new docs are looking really sharp. Head over there to learn more about how anomaly detection works at Soda, and check out the Data Observability section.
Now, once you’ve configured how anomalies are detected and displayed, the next step is handling them when they occur.
Creating an incident
Our machine learning model flags anomalous data points in red so that they can be easily spotted.
When you click on a red mark, a detail panel opens up showing more information about that measurement, including the metric and values involved.
From there, you can either mark the measurement as expected or as an anomaly — this helps the underlying model improve knowledge of your data patterns.
If you're unsure or want to investigate further, you can click Create Incident to log it. This opens an incident panel where you can add basic details as title and description.
After that, the incident will be available in the main Incidents tab where you can set the severity and the status, and assign a lead. The system automatically logs metadata of who reported it, when it was detected, and which dataset and quality check it relates to.
Once created, the incident moves through four stages: Reported, Investigating, Fixing, and Resolved, which you can track visually at the top of the screen. Then you can monitor progress and revisit historical data to ensure timely resolution.
A Slack, Jira, and MS Teams integration is also possible via webhooks. For more details on that, visit our Documentation page and check the section on Integrations.
When reviewing anomalies, use simple business logic and context to determine whether they truly require attention. For example, if there is a sudden spike, in say a sales column, then you can check if there was a marketing campaign, festival, or price drop that explains the surge. If yes, it’s expected and can be marked as such.
Think of anomalies as conversation starters. If you can confidently explain the root cause as part of normal operations, mark it as expected. Otherwise, open an incident to dig deeper and bring in the right people.
As you can see, data observability with Soda is very easy to set up, and you don't have to specify any rules manually.
With observability tools, we can see data flows, receive anomaly alerts, and easily trace issues back to their sources, automatically and at scale. But observability is only the beginning.
Once incidents are assessed and root causes understood, data producers and consumers can move toward defining stronger data quality standards, grounded in their specific business rules.
Data Testing
Data testing validates that your data meets the defined expectations before it reaches stakeholders, dashboards, or downstream systems. We start right and then shift left, bringing quality considerations earlier in the data lifecycle and focusing more on prevention than response.
At Soda, we believe that data quality should also be done at the source, on the left side of data pipelines. By shifting left, we can ensure that the data is trustworthy and the insights are correct, preventing problems from spreading throughout your data ecosystem.
If you've worked with production data systems, you’ve likely experienced the downstream impact of untracked changes. These problems aren't new, but they’ve become harder to ignore as organisations scale their data infrastructure and rely on increasingly interconnected pipelines.
A big part of the problem is that data quality has never had a clear owner. Producers generate the data, but the responsibility for verifying it often lands on consumers. Consumers could be analysts, data engineers, or business teams who are then left to patch problems downstream.
Without a shared definition of what the data should look like, teams implement ad hoc checks based on assumptions. These quality checks run post-ingestion or post-transformation, which means bad data is still in the loop, waiting to ruin someone's day.
Databricks’ built-in tools do a great job supporting data engineers within its ecosystem. But collaboration between producers and consumers is missing.
This is where we saw an opportunity to resolve this with Data Contracts.
Think of them as the Magna Carta for your datasets — a versioned agreement between producers and consumers that defines structure, quality expectations, and delivery guarantees:
Producers explicitly define the structure, quality metrics, and delivery expectations of the data they own. These definitions are enforced by the system, not left to interpretation.
Consumers operate with these clear guarantees. They can trust the data they depend on without needing to reverse-engineer upstream logic or build defensive checks around instability.
The contract serves as the single source of truth. It consolidates expectations into a shared, authoritative definition that is portable across environments and tools.
Collaborative Data Contracts
Data contracts have long been part of Soda’s CLI experience. With this release, we’ve taken it a step further and made Collaborative Data Contracts available in the UI.
Here’s what collaborative data contracts mean for data teams:
All changes to the contract are versioned and auditable. Schema updates, validation rule changes, and delivery modifications are tracked with full history for traceability and compliance.
Collaboration is built into the workflow. Contracts require producers and consumers to align on use cases and expectations before data moves through the system.
Engineers can also update the contracts from their favourite IDE, and the changes will be reflected in the Soda Cloud Data Contract (and vice versa).
Business users can define and manage expectations directly in Soda Cloud’s no-code interface.
To try this in Soda, click on Create Contract on the dataset's Checks dashboard. This will open up the Data Contract UI, where you can define your data contracts in an easy-to-use interface.
If you prefer to work directly with the code, you can use the toggle to see the code. This allows developers to see the underlying code generated by the UI selections.
Users can then enforce rules on the dataset level, either on the columns or the schema structure, and enforce them on the column level.
Using the daily_sales dataset as an example, the data contract has two checks:
Column check:
store_idshould not be null.Dataset check: if a store is closed (
open = 0), there should be no promotions (promotion = 1). This flags rows where promotions are incorrectly logged for closed stores.
Once you’ve finished writing your data contract, it’s time to verify it. The system will check the dataset against the conditions you’ve set in the contract.
For example, after running this verification, there were 0 rows with a missing store_id, which passed the column check.
But, the dataset-level check flagged 3707 rows where promotions were recorded even though the store was marked as closed. This is invalid data that would have gone unnoticed without the contract. If the contract runs successfully and everything is verified, you can publish the contract. Once published, the contract will be active, and the dataset will be continuously validated against the contract rules.
Depending on your organization's needs, the system can be set up to either completely stop the pipeline or send alerts while allowing the process to continue.
To learn more about our Data contracts capabilities, read the section on Data Testing in our documentation.
How Soda Complements Databricks's Data Quality Tool
Databricks DQX is particularly well-suited for certain scenarios:
When deep integration with native Databricks features is essential.
For teams already heavily invested in Databricks-native tools.
When working primarily with PySpark workloads and DataFrame operations.
For use cases requiring built-in quarantining capabilities within the Databricks environment.
DQX provides impressive capabilities, including support for all Spark workloads (including Delta Live Tables), different failure reactions (including quarantining invalid data), and different check severities.
Soda enhances and broadens DQX's capabilities in several key ways.
Let's go over the main aspects and contrast them:
Soda's specialised platform expands Databricks' capabilities with dedicated features for cross-platform testing, advanced metrics monitoring, and collaborative data contracts.
Together, they form a solid foundation for ensuring that the data that feeds your critical business processes is reliable, accurate, and trustworthy.
This complementary approach creates a comprehensive data quality strategy that leverages the strengths of both platforms:
Use DQX for native Databricks quality checks integrated directly into your Spark workflows.
Leverage Soda for cross-platform testing, advanced monitoring, and organization-wide data quality governance.
Implement data contracts in Soda to establish formal quality expectations while using DQX for execution-time enforcement.
The combination of Soda's new features and Databricks' powerful processing capabilities results in a comprehensive approach to data quality that helps organisations avoid costly data issues before they disrupt business operations.
Our latest launch reworks the entire Soda platform to ensure seamless integration. By introducing a new major version, we are not only modernising the product's foundation but also delivering on our vision of data contracts as a unified, governable, and accessible approach to data quality based on ownership, trust, and collaboration.
Wrap up
By learning from historical patterns, Soda can detect both sudden and subtle shifts in data behavior, surfacing issues like broken pipelines, delayed loads, or unexpected schema changes before they escalate.
In large-scale environments with hundreds or thousands of tables, it's simply not practical to define a data contract for each one from the start. That’s why the smart move is to begin with Metrics monitoring: get broad coverage, catch issues early, and investigate root causes efficiently.
From there, you can take targeted action, shifting left by applying Data Contracts where they're most needed, directly at the source. This ensures that once a problem is solved, it stays solved.
We’ve rebuilt Soda to make this journey easier, combining observability, anomaly detection, and data contracts into one unified experience.
We wanted to make sure that Soda tools fit in well with the tools that people already trust and use every day. Even if you don't use Databricks, don't worry. The new version of Soda will be able to fully connect to all major data sources starting on June 30th.
Whether you’re working in Databricks or managing diverse data environments, Soda is designed to help you build trust in your data at scale.
Take Action!
Curious to try it out? Be first to try Soda’s new AI-powered metrics observability and collaborative data contracts.
Schedule a demo with the Soda team or request a free account to find out how much you could optimize your data quality strategy across your entire data ecosystem.
Trusted by the world’s leading enterprises
Real stories from companies using Soda to keep their data reliable, accurate, and ready for action.
At the end of the day, we don’t want to be in there managing the checks, updating the checks, adding the checks. We just want to go and observe what’s happening, and that’s what Soda is enabling right now.

Sid Srivastava
Director of Data Governance, Quality and MLOps
Investing in data quality is key for cross-functional teams to make accurate, complete decisions with fewer risks and greater returns, using initiatives such as product thinking, data governance, and self-service platforms.

Mario Konschake
Director of Product-Data Platform
Soda has integrated seamlessly into our technology stack and given us the confidence to find, analyze, implement, and resolve data issues through a simple self-serve capability.

Sutaraj Dutta
Data Engineering Manager
Our goal was to deliver high-quality datasets in near real-time, ensuring dashboards reflect live data as it flows in. But beyond solving technical challenges, we wanted to spark a cultural shift - empowering the entire organization to make decisions grounded in accurate, timely data.

Gu Xie
Head of Data Engineering
4,4 sur 5
Commencez à faire confiance à vos données. Aujourd'hui.
Trouvez, comprenez et corrigez tout problème de qualité des données en quelques secondes.
Du niveau de la table au niveau des enregistrements.
Adopté par
Product








Trusted by the world’s leading enterprises
Real stories from companies using Soda to keep their data reliable, accurate, and ready for action.
At the end of the day, we don’t want to be in there managing the checks, updating the checks, adding the checks. We just want to go and observe what’s happening, and that’s what Soda is enabling right now.
Sid Srivastava
Director of Data Governance, Quality and MLOps
Investing in data quality is key for cross-functional teams to make accurate, complete decisions with fewer risks and greater returns, using initiatives such as product thinking, data governance, and self-service platforms.
Mario Konschake
Director of Product-Data Platform
Soda has integrated seamlessly into our technology stack and given us the confidence to find, analyze, implement, and resolve data issues through a simple self-serve capability.
Sutaraj Dutta
Data Engineering Manager
Our goal was to deliver high-quality datasets in near real-time, ensuring dashboards reflect live data as it flows in. But beyond solving technical challenges, we wanted to spark a cultural shift - empowering the entire organization to make decisions grounded in accurate, timely data.
Gu Xie
Head of Data Engineering
4,4 sur 5
Commencez à faire confiance à vos données. Aujourd'hui.
Trouvez, comprenez et corrigez tout problème de qualité des données en quelques secondes.
Du niveau de la table au niveau des enregistrements.
Adopté par
Product
Solutions
Trusted by the world’s leading enterprises
Real stories from companies using Soda to keep their data reliable, accurate, and ready for action.
At the end of the day, we don’t want to be in there managing the checks, updating the checks, adding the checks. We just want to go and observe what’s happening, and that’s what Soda is enabling right now.
Sid Srivastava
Director of Data Governance, Quality and MLOps
Investing in data quality is key for cross-functional teams to make accurate, complete decisions with fewer risks and greater returns, using initiatives such as product thinking, data governance, and self-service platforms.
Mario Konschake
Director of Product-Data Platform
Soda has integrated seamlessly into our technology stack and given us the confidence to find, analyze, implement, and resolve data issues through a simple self-serve capability.
Sutaraj Dutta
Data Engineering Manager
Our goal was to deliver high-quality datasets in near real-time, ensuring dashboards reflect live data as it flows in. But beyond solving technical challenges, we wanted to spark a cultural shift - empowering the entire organization to make decisions grounded in accurate, timely data.
Gu Xie
Head of Data Engineering
4,4 sur 5
Commencez à faire confiance à vos données. Aujourd'hui.
Trouvez, comprenez et corrigez tout problème de qualité des données en quelques secondes.
Du niveau de la table au niveau des enregistrements.
Adopté par
Product
Solutions
Company