
Soda Cloud Metrics Store dynamise la capacité des ingénieurs de données à tester et valider la qualité des données. Il capture des informations historiques sur la santé des données pour soutenir le test intelligent des données dans chaque charge de travail et aide les équipes de données à empêcher que les problèmes de données aient un impact en aval.
Les valeurs historiques offrent une compréhension de base de ce à quoi ressemble de bonnes données. Sur la base de ces valeurs historiques, les ingénieurs en données et analystes peuvent tester et valider les données avec des systèmes de seuil dynamiques comme les changements dans le temps et la détection d'anomalies, dans le cadre d'un flux de travail complet de bout en bout qui aide à détecter et résoudre les problèmes, et alerte automatiquement les bonnes personnes au bon moment.
‼️ Soda Cloud Metrics Store a évolué et nous avons une toute nouvelle fonctionnalité.
En savoir plus à ce sujet ici : Plateforme de surveillance des données pour la détection d'anomalies en temps réel
Dans ce blog, nous parlons à Dirk et explorons un peu plus en profondeur les principales capacités du Cloud Metrics Store. Dirk est le chef de projet pour le Cloud Metrics Store.
Q : Pourquoi les tests sont-ils importants pour la qualité des données ?
Dirk : Soda a été créé pour répondre à la disponibilité des données, pour aider les équipes de données à découvrir, analyser et résoudre les problèmes de qualité des données. Afin de découvrir ces problèmes de données, les ingénieurs doivent tester les données pour s'assurer que leurs transformations continuent de fonctionner comme prévu.
Le premier endroit où vous devez tester les données est au point d'ingestion. Lors de l'ingestion des données, vous voulez être sûr que toutes les données ont été transférées avec succès de leur source à la destination cible. Le deuxième endroit où vous devez tester les données est au point de transformation. Avec les tests de transformation, vous vérifiez généralement les pré- et post-conditions, comme les vérifications de schéma, les vérifications de valeurs nulles, les vérifications de valeurs valides et les vérifications d'intégrité référentielle.
Lorsque cela est fait correctement, cela se traduit par une bonne couverture de test. Je suis sûr que vous avez souvent entendu dire que tester les données doit devenir une pratique standard en ingénierie des données, tout comme les tests unitaires le sont en ingénierie logicielle. C'est pourquoi cela doit se produire.
Q : Alors, dites-nous quel est le cas d'utilisation convaincant pour avoir et utiliser des métriques historiques.
Dirk : Bien sûr, c'est relativement simple. Lorsque vous écrivez des tests et des validations pour la qualité des données, vous pourriez constater qu'un simple test à seuil fixe n'est pas suffisant. Permettez-moi de vous esquisser un exemple.
Imaginons que vous souhaitiez implémenter un test dans votre pipeline de données pour vérifier si le nombre de lignes dans votre ensemble de données est stable ou changeant. Mettre cela en place avec des tests dans un environnement sans état est assez difficile car premièrement, il est difficile de définir. Deuxièmement, un test comme celui-ci nécessitera des mises à jour régulières qui ne sont pas seulement difficiles à gérer, mais aussi coûteuses et longues à maintenir, et deviennent rapidement peu fiables.
Pour résoudre ce problème, il est courant que les ingénieurs de données construisent leurs propres solutions maison impliquant des algorithmes complexes, des systèmes de stockage, et nécessitent inévitablement pas mal de ressources et de temps pour construire et maintenir.
Chez Soda, nous voulions trouver une autre voie pour que les équipes de données puissent se concentrer sur la création de produits de données fiables et que les organisations puissent utiliser leurs données en toute confiance.
Nous avons réalisé que la solution idéale impliquait l'utilisation d'informations historiques sur la santé des données. Dans Soda Cloud, les informations historiques sont capturées dans le cadre des mesures de métrique utilisées dans les tests. Nous pouvions désormais commencer à exploiter ces mesures pour écrire des tests de changement dans le temps.
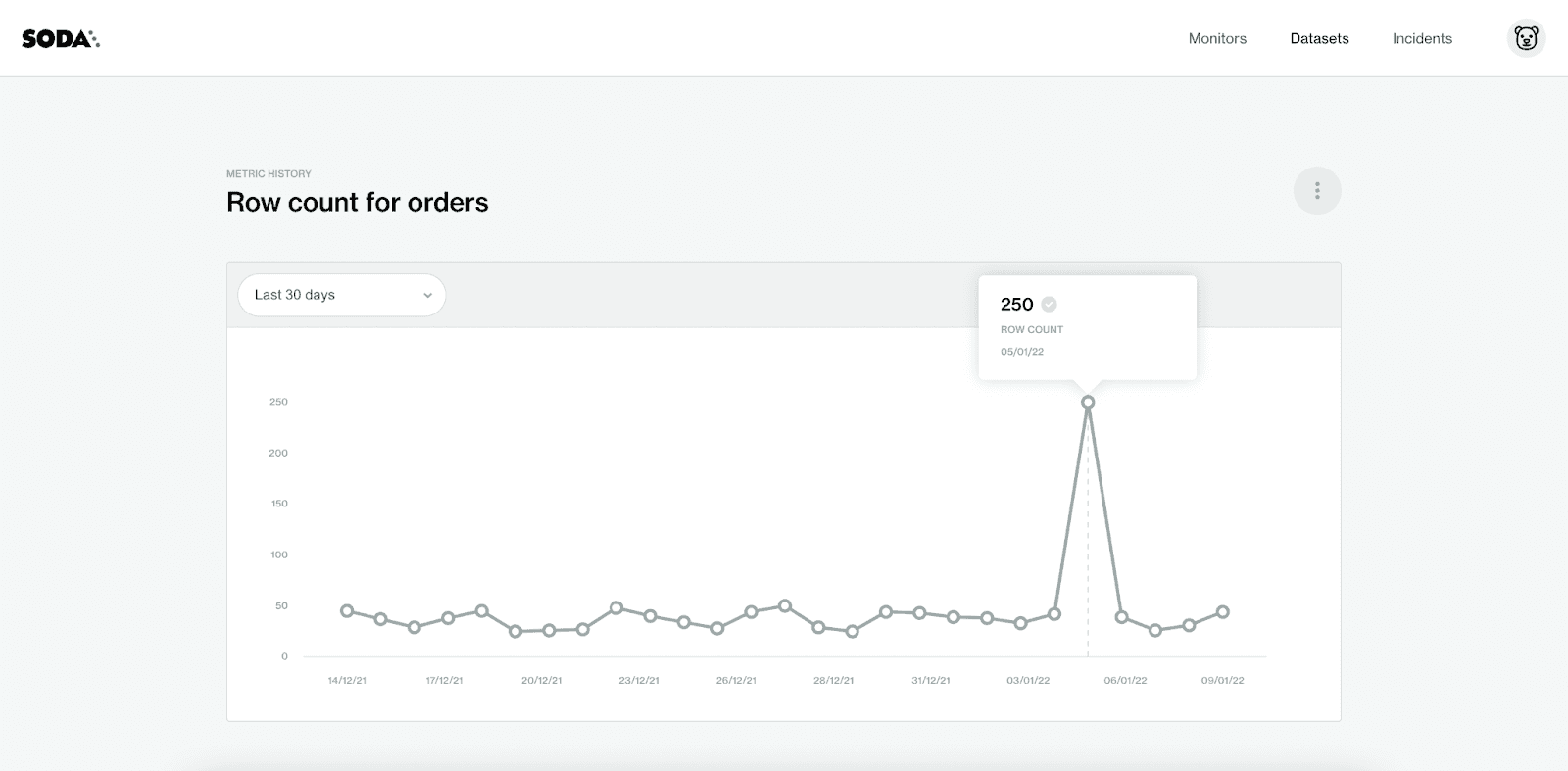
L'historique des métriques pour le moniteur ‘Nombre de lignes pour les commandes’ pour les 30 derniers jours.
Q : Cela semble être une solution idéale. Pouvez-vous nous expliquer en détail ?
Dirk : En mettant les mesures stockées pour une métrique à la disposition des ingénieurs de données, nous sommes en mesure de fournir des capacités de test avancées en tant que code qui permettent aux équipes de données de prendre de l'avance sur les problèmes de données de manière plus sophistiquée que jamais auparavant.
Revenons au test de nombre de lignes : utiliser les mesures historiques des tests de nombre de lignes signifie que vous pouvez implémenter ce test dans votre pipeline de données de manière simple - oserais-je dire facile - et fiable.
Lorsque Soda Scan est exécuté, les résultats apparaissent dans un tableau de ‘Résultats du Moniteur’. Les mesures résultant de chaque test exécuté contre les données sont stockées dans le Cloud Metrics Store. Vous pouvez accéder aux mesures historiques et écrire des tests qui utilisent ces mesures historiques.
Laissez-moi aller plus loin. Nous utilisons toujours ce scénario où vous devez implémenter un test dans votre pipeline de données pour vérifier si le nombre de lignes dans votre ensemble de données est stable ou croissant.
Testons pour “row_count > 5”.
Lorsque Soda scanne un ensemble de données, il effectue un test. Pendant un scan, Soda vérifie la métrique (row_count) pour déterminer si les données correspondent aux paramètres qui ont été définis pour la mesure (> 5). Suite au scan, chaque test passe ou échoue.
Les mesures de chaque test se trouvent dans le Cloud Metrics Store. Les résultats des tests sont affichés dans un graphique et les utilisateurs peuvent facilement visualiser comment leurs données changent au fil du temps. L'ensemble de données est-il stable ? Est-il en croissance ? Pourrait-il même être en diminution ? Et de combien ?
Q : Comment définissez-vous les métriques historiques pour écrire des tests ?
Dirk : Nous avons essayé de garder cela simple et de tirer parti de la pratique des tests avancés en tant que code. Le retour de notre communauté est que Soda est de classe mondiale parce qu'il permet aux ingénieurs de données d'exécuter des vérifications de fiabilité et de qualité des données (tests + validations), en tant que code.
Pour faire tout cela, nous avons introduit une syntaxe de mesures historiques. Vous pouvez écrire des tests dans des fichiers scan YAML qui testent les données par rapport aux mesures historiques contenues dans le Cloud Metrics Store. Regardez cet exemple où vous pouvez voir comment les métriques historiques sont utilisées pour tester si votre ensemble de données est en croissance :
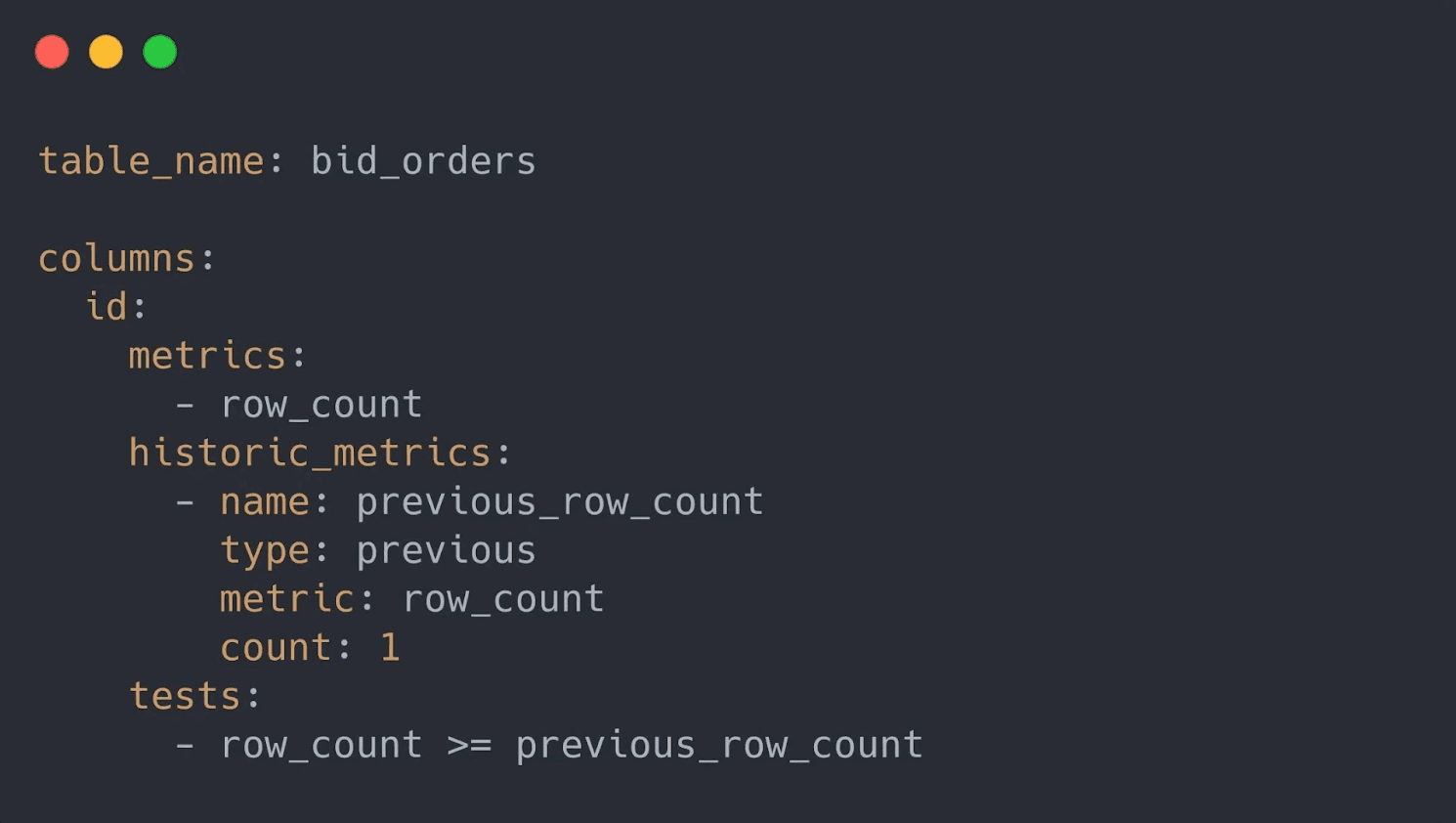
Cet exemple démontre comment le test repose sur une variable dynamique qui fait référence au « nombre de lignes » du scan précédent, « previous_row_count ». Le scan précédent est accessible dans le Cloud Metrics Store. En utilisant quelques lignes supplémentaires dans le fichier YAML, il est facile de tester si un ensemble de données change de taille.
Q : Ce test fonctionne-t-il pour chaque scénario pour que je puisse agréger pour suivre des moyennes mobiles ?
Dirk : Non, malheureusement des scénarios de test comme celui-ci ne fonctionnent pas toujours pour chaque scénario, parce qu'ils testent par rapport à une seule mesure précédente. Venez, nous ne pouvions pas rendre cela si simple et facile!
La plupart d'entre vous, voire tous, qui lisez ceci savez que lorsque vous traitez des données en production, les caractéristiques sont souvent plus complexes. Pour ajouter à la complexité des caractéristiques, vous traitez avec du « bruit de données » ce qui rend difficile de se fier à des tests de seuils fixes qui créent probablement de faux positifs. Et personne ne s'épanouit avec la fatigue des alertes!
J'ai un exemple de la vie réelle. L'une des choses que j'adore dans mon rôle d'ingénieur chez Soda, c'est que je travaille avec des ingénieurs de données - et des praticiens - qui ont rencontré la plupart des problèmes pour lesquels nous travaillons chaque jour. Ces pompiers des problèmes de données sont dans mon bureau et ensemble nous construisons la meilleure plateforme qui changera la facilité avec laquelle les équipes de données collaborent pour rendre les données fiables disponibles 24/7.
L'un de l'équipe, appelons-le Smokey Bear, travaillait sur un projet où son équipe traitait un système qui reposait sur des données à haut débit. Pour cette équipe, chaque milliseconde de latence avait un impact direct et négatif sur le revenu du projet.

Le poster de débuts de Smokey Bear. Art par Albert Staehle.
Au fil du temps, Smokey et son équipe ont remarqué que leur revenu diminuait, mais ils étaient incapables de trouver la cause racine. En explorant les données, ils ont fini par découvrir que la moyenne d'une colonne contenait la latence du système. La moyenne de la colonne avait augmenté, peu à peu, au fil du temps. Parce qu'il avait été jugé acceptable pour la latence de monter et descendre au fil du temps, il n'y avait pas de vérification en place pour tester la moyenne de la colonne par rapport aux données historiques.
Alors qu'ils travaillaient pour résoudre le problème de données, Smokey et son équipe ont réalisé que le problème aurait pu être détecté plus tôt s'ils avaient mis en place une simple moyenne mobile dans leurs tests de données. Cependant, la nécessité d'intégrer un test incluant des mesures précédentes n'était pas où ils pouvaient investir leur temps et leurs ressources.
Je sais - si seulement Smokey et son équipe avaient connu le Cloud Metrics Store de Soda parce que c'est exactement le type de scénario qui mettra la fonctionnalité de métriques historiques de Soda à l'épreuve.
Avec quelques lignes de la syntaxe YAML, Smokey pourrait utiliser une agrégation sur plusieurs mesures précédentes. Soda enlève la complexité pour rendre l'implémentation d'une simple moyenne mobile simple.

Utilisant quelques lignes de la syntaxe YAML, vous pouvez calculer une delta basée sur la moyenne des sept dernières mesures. Lorsque le delta dépasse le seuil fixe, le test échoue et le pipeline s'arrête. Les mauvaises données sont efficacement mises en quarantaine pour inspection avant d'être mises à disposition pour les produits de données et les consommateurs en aval.
Lorsque des produits de données, tels que des rapports ou des modèles ML, tombent en panne, les équipes sont incapables de prendre des décisions éclairées basées sur les données avec confiance, et la confiance dans les données s'érode, et donc je pense que maintenant est un bon moment pour rappeler que Soda fonctionne tout au long du cycle de vie des produits de données. Nous avons travaillé dur pour rendre facile pour les ingénieurs de données de tester les données à l'ingestion et pour les gestionnaires de produits de données de valider les données avant la consommation dans des outils comme Snowflake.
Tous les contrôles peuvent être écrits sous forme de code dans un langage de configuration facile à apprendre. Les fichiers de configuration sont contrôlés par version, et utilisés pour déterminer quels tests exécuter chaque fois que de nouvelles données arrivent dans votre plateforme de données. Soda prend en charge toutes les charges de travail de données, y compris l'infrastructure de données, la science, l'analyse, et les charges de travail en streaming, à la fois sur site et dans le cloud.
Q : Comment une équipe de données peut-elle commencer ?
Dirk : Si vous êtes nouveau chez Soda, vous pouvez rapidement (et facilement !) commencer gratuitement. Vous devrez installer les outils Soda, disponibles en open source, et connecter Soda Cloud, un compte gratuit disponible en version d'essai. Les utilisateurs existants peuvent commencer avec la documentation sur les métriques historiques. Si vous avez besoin d'aide, contactez l'équipe Soda dans notre communauté Soda sur Slack.
J'aimerais savoir ce que vous pensez et comment vous avez utilisé cette fonctionnalité dans votre projet. Que ce soit en utilisant des mesures précédentes dans vos tests de pipeline ou en implémentant des seuils dynamiques, veuillez partager votre expérience !
Q : Quelles autres fonctionnalités enrichissent le Soda Cloud Metrics Store ?
Dirk : Oh bien, presque tout parce que nous construisons le flux de travail complet de qualité des données afin que les équipes de données puissent atteindre l'observabilité des données de bout en bout. Notre plateforme est conçue pour que tous les membres d'une équipe de données moderne puissent s'impliquer dans la recherche, l'analyse et la résolution des problèmes de données. J'ai peut-être une préférence particulière pour Soda Incidents car il complète le flux de travail pour détecter et résoudre les problèmes.
Q : Qu'est-ce qui vous excite ?
Dirk : Il se passe beaucoup de choses chez Soda et dans le grand monde de la gestion des données ! Notre plus récente intégration, dbt + Soda, apporte les capacités puissantes des Soda Incidents (et en réalité, l'ensemble de la plateforme Soda Cloud) à l'outil de transformation puissant qu'est dbt. La chose la plus cool qui m'excite le plus, c'est le nouveau langage sur lequel nous travaillons. Cela promet d'être une capacité révolutionnaire pour tout le monde : peu de code pour la victoire !
Et il y a bien plus encore. Restez connecté et à jour dans la Soda Community sur Slack.
En savoir plus sur comment démarrer avec le Cloud Metrics Store dans notre Documentation Soda.
Merci Dirk et équipe !











