
I am a data architect. What use are data contracts to me?
It’s a fair question. Most data contract content is written for engineers who’ll write the YAML, or governance leads who’ll set the policies. But if you design data platforms at the enterprise level, contracts solve a different problem for you. They give you a structured way to enable data quality across domains without centralizing all execution work.
That matters more now than it did two years ago. Only 7% of enterprises say their data is completely ready for AI, according to a March 2026 report from Cloudera and Harvard Business Review Analytic Services. The platforms you’re designing need to serve AI workloads, and those workloads don’t tolerate inconsistent quality.
Key Takeaways |
|---|
|
Data contracts are the mechanism that makes quality enforceable, visible, and owned at the platform level.
They also have a habit of revealing uncomfortable truths — like the fact that a field you designed as non-nullable has more NULLs in production than you ever expected. Here are five organizational capabilities that data contracts unlock for data architects.
1. A Standardized Quality Model Across Every Layer
As an architect, you see the whole platform. One team uses dbt tests. Another writes custom Python scripts. A third does nothing at all. The result is a patchwork where “quality” means something different depending on who you ask and which pipeline you’re looking at.
That’s a problem you can’t fix by adding more checks. The issue isn’t the absence of testing. It’s the absence of a shared standard.
Data contracts give you a single quality model that applies across ingestion, transformation, and serving layers. Not a shared tool, necessarily, but a shared specification: what checks run, what thresholds apply, what “good” looks like for this dataset. When the model is standardized, quality becomes comparable across domains. You can answer “which datasets meet the bar?” without sending a Slack message to every team.
That comparability is what makes a platform AI-ready. AI models need consistent, reliable inputs. When your quality standards vary by team and pipeline stage, you can’t guarantee that.
2. An Enforceable Specification Layer, Not Just Documentation
In most organizations, the specifications defining “good quality” live in Confluence pages that nobody reads, Slack threads that disappear, and the heads of people who might leave next quarter. The intent is good. The enforcement is zero.
Contracts change where specifications live. They move them into version control, right alongside pipeline code. This matters for architects because it turns quality specifications into something enforceable. A Confluence page can say “every table must have a freshness SLA.” A data contract actually enforces it, automatically, every time the pipeline runs.
You don’t have to enforce every contract yourself. That’s the point. The system does it. Your role as architect is to design the framework: where contracts are stored, how they’re validated, what happens when one fails. You set the standard. Domain teams write and own their contracts within that standard. Automation handles the rest.
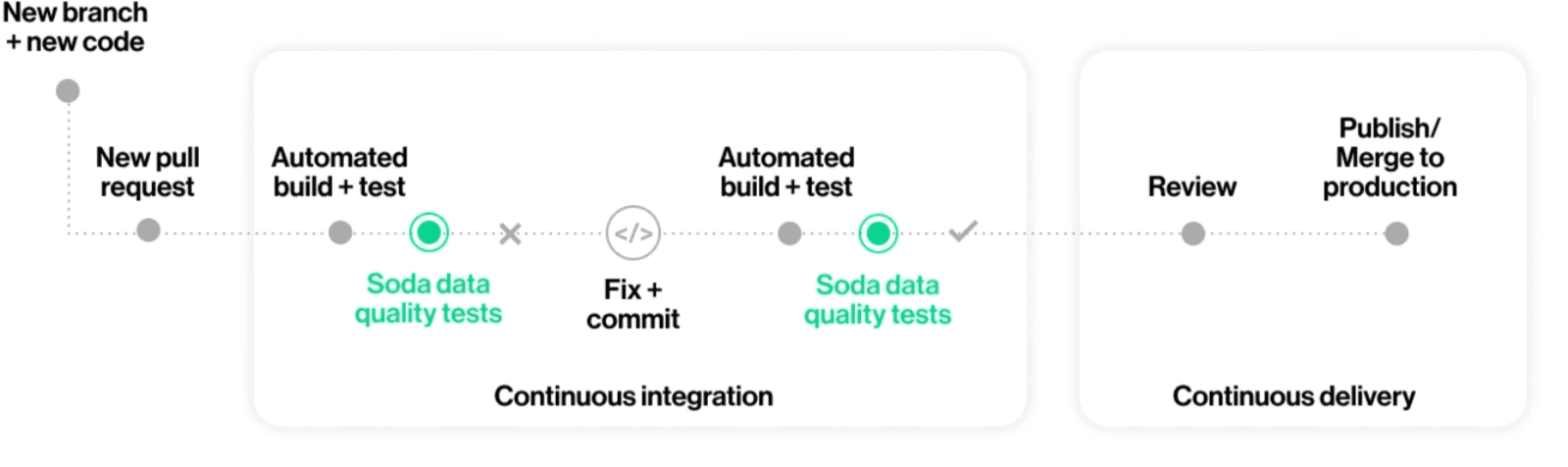
This is the shift from “we have a governance policy” to “we have an enforceable standard.” Anyone who’s sat through a quarterly data review where the same quality issues surface again knows the difference between those two things.
Worth noting: this isn’t just a tooling change. It’s an organizational one.
Getting teams to agree on specifications in advance, before data flows, is harder than any YAML syntax. The tooling is the easy part. The real work is the conversation it forces between producers and consumers about what “good” means. That’s also why it’s valuable — it’s the same principle as encapsulation in software engineering: you define the interface, and each team owns its implementation.
If you want to see what enforcement looks like in practice, Soda’s guide to implementing and enforcing data contracts walks through the mechanics.
3. A Single Visibility Layer for the Whole Enterprise
Data leaders need to see what’s happening across domains. Not a dashboard that only one team maintains, but an actual enterprise view.
This is where contracts deliver something that governance frameworks alone can’t.
When contracts run across datasets, their pass/fail status feeds into a central visibility layer. You see which domains meet their defined standards. Where failures are clustering. How quality trends are evolving over time. This isn’t a reporting project someone has to build and maintain manually. It’s a natural output of the contract system itself.
For architects, this solves the “I can’t see across domains” problem that plagues every enterprise data platform. You finally get the view that supports executive reporting and risk management without adding another audit process. The contracts produce the evidence; dashboards surface it.
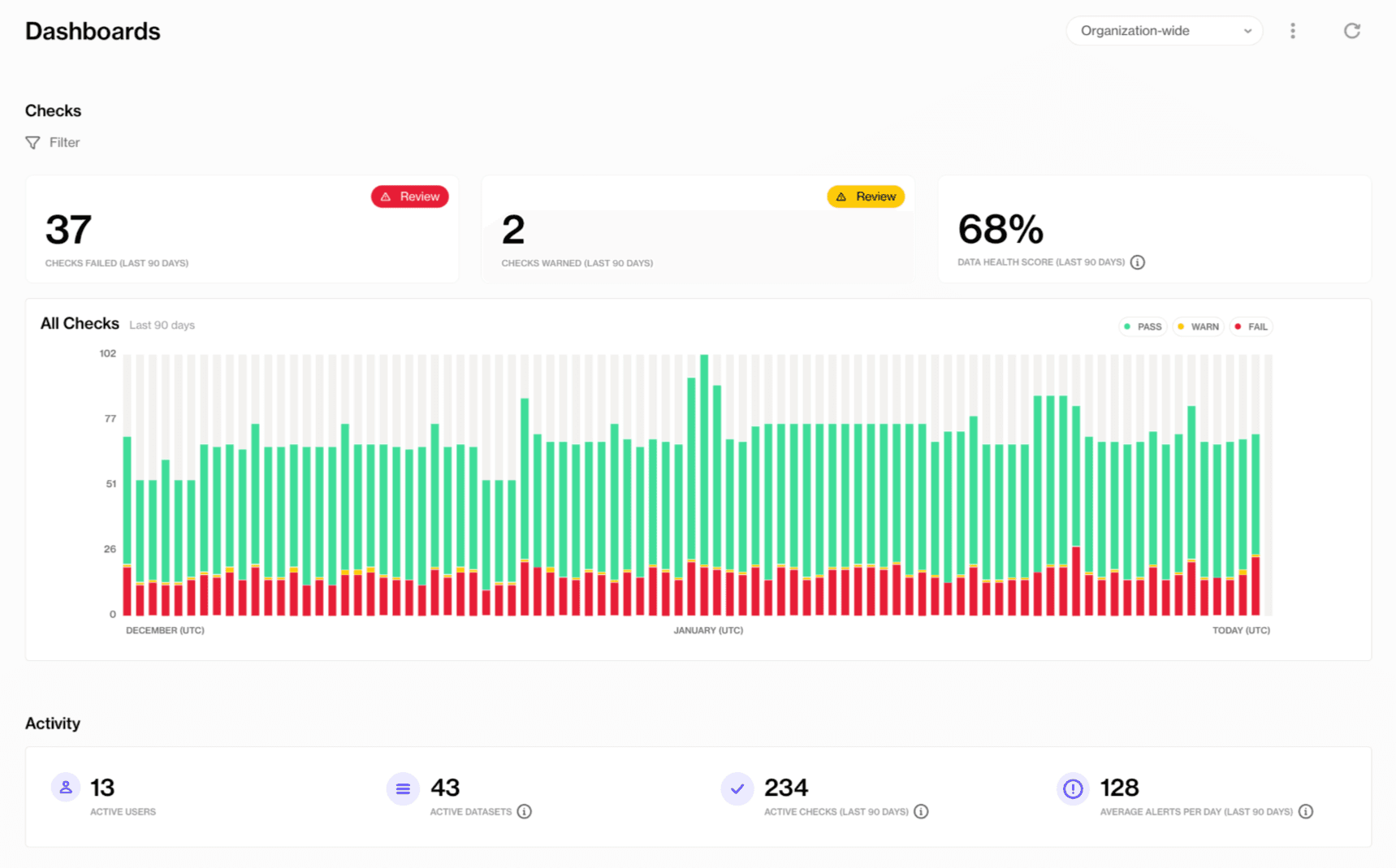
This also shifts governance from meeting-based to evidence-based. When a regulator asks for proof of data quality controls, you point to contract results, not a slide deck someone assembled the night before. That visibility supports executive reporting and risk management without introducing manual audits.
4. Traceable Ownership That Sticks to the Data
When a data quality issue surfaces, it gets passed between teams. Nobody owns it because there’s no metadata tying a specific dataset to a specific owner. The ownership question turns into a Slack thread, and the Slack thread turns into a meeting, and the meeting ends without resolution.
Contracts fix this by attaching ownership directly to the dataset. Not in a catalog that nobody checks (though catalogs matter too). In the contract itself, sitting alongside schema definitions and freshness guarantees. When something breaks, there’s no ambiguity about who to call. The owner is right there in the specification that just failed.
You’ve probably tried to solve ownership through governance processes, RACI matrices, or metadata fields in a catalog. Those approaches work until they don’t: someone changes roles, a team reorganizes, the spreadsheet goes stale. Contracts keep ownership current because the contract is a living, running asset. If the owner leaves, the contract still fails, and someone has to update it.
Ownership isn’t a one-time exercise. It’s embedded in the infrastructure.
5. Controlled change management through versioning
A producer drops a column. A data type changes silently. A new field shows up without documentation. Downstream pipelines fail at 2 AM, and the on-call engineer spends hours figuring out what happened and who changed what. This isn’t a rare event. It’s a Tuesday.
Versioned data contracts make changes explicit. A producer can’t silently alter a schema because the contract update goes through the same review process as any code change. Consumers can see what’s coming before it breaks their pipeline. When something does change, there’s a clear audit trail: who changed what, when, and why.
The harder challenge is when different domains move at different speeds. One team ships schema changes weekly; another hasn’t touched theirs in a year. Aligning what counts as a breaking versus non-breaking change across those domains is where versioning becomes a governance question, not just a technical one.
Contracts don’t eliminate that tension, but they make it explicit. You can see which domains are evolving, which are stale, and where a proposed change will create downstream impact.
This is how architects design systems that absorb change gracefully. Not by preventing change, but by making it visible, reviewable, and trackable.
The Platform Primitive You’ve Been Missing
Data contracts aren’t a new governance process. They aren’t another tool for data engineers to configure. For architects, they’re a platform primitive: a standardized, enforceable, visible quality layer that works across every domain and every pipeline stage.
They give you what governance policies, catalogs, and observability tools alone don’t. A quality model everyone shares. Specifications that are enforced, not just documented. A visibility layer that feeds dashboards without manual effort. Ownership that sticks to the data. And change management that actually works, because it’s automated.
As platforms become AI-ready, the need for standardized quality enforcement only grows. Architects are the people positioned to make that happen.
Frequently Asked Questions
What's the difference between data contracts and data governance policies?
Governance policies define what "good" looks like. Contracts enforce it. A policy says "every dataset must have an owner." A contract names the owner, attaches it to the dataset, and fails the pipeline if the metadata is missing. The two are complementary: contracts operationalize governance, turning aspirational documentation into automated enforcement.
Do data contracts replace data catalogs?
No. Catalogs handle discoverability and metadata browsing. Contracts handle enforceable quality expectations. They work best together. Soda integrates bi-directionally with Collibra, Atlan, and Alation so contract status flows into the catalog, giving teams both discoverability and enforceable standards in one view.
Where should a data architect start with data contracts?
Pick three to five of your most critical, most-consumed datasets. Define what "good" means for each: schema shape, freshness, row count, key uniqueness. That's your first set of contracts. Once those are running and teams see the visibility they produce, scaling becomes an organizational conversation, not a technical one. See what data contracts are and why they matter for a thorough introduction.











