Tests de qualité des données modernes pour les pipelines Spark
Tests de qualité des données modernes pour les pipelines Spark
Tests de qualité des données modernes pour les pipelines Spark

Vijay Kiran
Vijay Kiran
Ancien ingénieur principal en données chez Soda
Ancien ingénieur principal en données chez Soda
Table des matières
⛔️ Soda Spark a été abandonné.
Soda Spark était une extension de Soda SQL qui vous permettait d'exécuter les fonctionnalités de Soda SQL de manière programmatique sur un Spark DataFrame. Il a été remplacé par Soda Library conçu pour connecter Soda à Apache Spark.
Dans le cadre de la mission pour rapprocher chacun de ses données, Soda a introduit Soda Spark, un outil moderne de test, de surveillance et de fiabilité des données pour les équipes d'ingénieurs qui utilisent les PySpark DataFrames. Le dernier outil open-source dans la boîte à outils de fiabilité des données de Soda, Soda Spark a été construit pour les ingénieurs en données et en analytique travaillant dans des environnements intensifs en données, où des données fiables et de haute qualité sont d'une importance capitale.
Soda Spark atténue la difficulté de maintenir un haut niveau de confiance dans les données dans l'écosystème Spark, où les ingénieurs passent généralement beaucoup de temps à construire des cadres pour les vérifications de la qualité des données. Les ingénieurs en données et en analytique peuvent contrôler les tests qui dépistent les mauvaises données - ou comme nous aimons les appeler, les problèmes de données silencieux - et les métriques qui évaluent les résultats. En utilisant le dialecte Spark déjà disponible dans Soda SQL, la bibliothèque Soda Spark fournit une API pour extraire les métriques des données et les profils de colonnes selon les requêtes que vous écrivez dans les fichiers de configuration YAML.
Les ingénieurs en données utilisent Soda Spark pour écrire des tests de qualité de données déclaratifs pour les Spark DataFrames et détecter les données problématiques. Lorsque vous connectez Soda Spark à un compte Soda Cloud, vous pouvez configurer des alertes qui notifient votre équipe lorsque vos tests Soda Spark échouent. Les équipes obtiennent les bonnes informations instantanément pour commencer le triage, l'enquête et la résolution rapide des problèmes.
Tutoriel : Test de qualité des données pour les pipelines Spark
Les outils de fiabilité des données open-source de Soda peuvent fonctionner sur plusieurs charges de travail, moteurs et environnements de données, y compris Kafka, Spark, AWS S3, Azure Blob Storage, Google Cloud Datastore, Presto, Snowflake, Azure Synapse, Google BigQuery et Amazon Redshift.
Utiliser Soda Spark est simple : installez-le via pip et commencez à utiliser l'API directement dans vos programmes PySpark. Voici une petite vidéo sur comment installer, utiliser et tester vos Spark DataFrames avec Soda Spark.

Alternativement, si vous utilisez un environnement d'exécution Spark populaire comme Databricks, vous pouvez également utiliser facilement Soda Spark dans vos Notebooks, et intégrer les tests directement dans vos pipelines ou programmer des tests.
Suivez ce tutoriel en cinq étapes pour voir comment vous pouvez exécuter des tests de qualité de données des DataFrames Apache Spark fonctionnant sur un cluster Databricks. Si vous n'avez pas déjà un cluster Databricks en fonction, vous pouvez en créer un depuis la communauté Databricks.
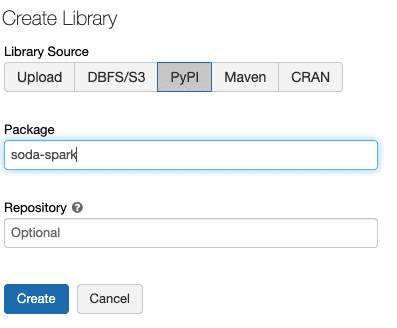
1. Pour installer Soda Spark dans votre Cluster Databricks, exécutez la commande suivante directement depuis votre notebook :
%pip install soda-spark
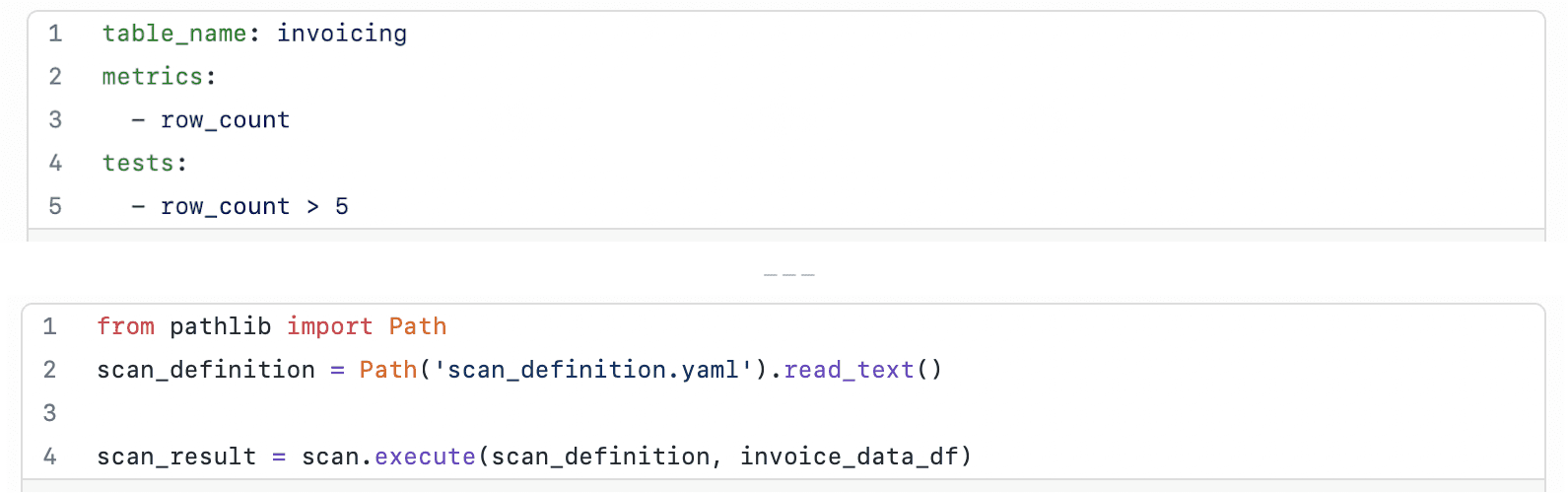
2. Chargez les données dans un DataFrame, puis créez une définition de scan avec des tests pour le DataFrame

3. Exécutez un scan Soda pour réaliser les tests que vous avez définis dans la définition du scan (fichier de configuration scan YAML)
Vous pouvez définir des tests dans deux endroits : 1) dans votre code comme une chaîne de caractères ou 2) dans un fichier YAML externe.
Dans ce tutoriel, nous définissons des tests dans un fichier de configuration YAML externe et utilisons ce fichier pour tester la qualité des données d'un DataFrame.
Lorsque le scan Soda est terminé, vous pouvez examiner les résultats des tests et les mesures dans la ligne de commande (voir image ci-dessous, haut), et la sortie dans le Notebook Databricks (voir image ci-dessous, bas).

4. Vérifiez les résultats des tests pour les tests ayant échoué durant le scan. Dans l'exemple de sortie ci-dessous, aucun test n'a échoué

Ce résultat affiche les métriques contre lesquelles Soda a testé vos données, les mesures résultantes, et le statut de réussite ou d'échec de chaque test.
5. Et maintenant, vous pouvez :
configurer Soda SQL pour envoyer les métriques et les résultats des tests à Soda Cloud.
rejoindre notre communauté Soda sur Slack pour poser des questions et faire des demandes de fonctionnalités.
devenir contributeur : nous cherchons toujours à améliorer notre bibliothèque. Toutes les contributions sont les bienvenues!
Un grand merci à Cor Zuurmond (GoDataDriven), le premier contributeur qui nous a aidés à développer Soda Spark, et à Abhishek Khare (HelloFresh) et Anil Kulkarni (Lululemon), pour leurs tests précoces et leurs précieux feedbacks! Consultez le dépôt Soda Spark ici.
Pourquoi Soda ajoute l'étincelle à vos pipelines
Soda est la société de fiabilité des données qui fournit des outils open-source (OSS) et des logiciels en tant que service (SaaS) permettant aux équipes de données de découvrir, de prioriser et de résoudre les problèmes de données. Nos outils de fiabilité des données OSS et notre plateforme cloud SaaS rapprochent tout le monde de ses données, aboutissant à des produits de données et des analyses en lesquels chacun peut avoir confiance. La communauté mondiale des données de Soda compte déjà Disney, HelloFresh et Udemy parmi les principaux contributeurs ayant déployé les outils de fiabilité des données de Soda.
Voici 8 bonnes raisons pour lesquelles nous pensons que votre équipe devrait utiliser Soda pour tester la qualité des données tout au long du cycle de vie de votre produit de données.
1. Prêt à l'emploi
Prêt à l'emploi, Soda supporte plusieurs sources de données, fournit une détection d'anomalies, des visualisations des résultats de tests historiques, et une gestion des incidents automatisée. Il est facile de commencer et simple de définir vos tests et attentes.
2. Installation
Installez facilement Soda Spark via pip, puis utilisez la ligne de commande pour vous connecter à une source de données, découvrir des ensembles de données, et lancer un scan en quelques minutes. Vous pouvez suivre des exemples documentés pour configurer des scans programmatiques depuis la ligne de commande et intégrer avec les outils de pipeline de données. La documentation de Soda est facile à suivre et hautement évaluée par la communauté et les observateurs. En utilisant SQL comme langage spécifique au domaine, il n'est pas nécessaire d'avoir de l'aide d'admin et il n'y a pas besoin de bien connaître les langages de programmation de haut niveau.
3. Bibliothèque de tests
Les docs de Soda fournissent plusieurs exemples pour utiliser les métriques intégrées, qui sont faciles à maintenir et simplifient la complexité de l'écriture des tests de qualité de données.
4. Partage et collaboration
Utilisez Soda Cloud pour inviter les membres de l'équipe, envoyer des notifications à Slack, partager les résultats des tests de données, et créer et suivre les incidents de qualité des données. Les membres de l'équipe peuvent examiner les résultats des scans et créer de nouveaux moniteurs dans Soda Cloud. Soda Cloud est plus inclusif pour une base d'utilisateurs non codeurs, ce qui facilite la collaboration dans une organisation.
5. Commencez avec une bonne documentation
Soda a investi dans l'écriture et la publication d'une documentation complète, concise, et à jour pour les outils de fiabilité des données open-source et la plateforme cloud. La documentation de Soda permet aux ingénieurs en données de découvrir et de surveiller immédiatement les problèmes de données grâce à une série de tests entièrement configurables.
6. Stockage des métriques cloud
Vous pouvez définir des métriques historiques afin que vous puissiez écrire des tests dans les fichiers scan YAML qui testent des données par rapport aux mesures historiques contenues dans le Stockage de métriques cloud de Soda. Essentiellement, ce type de métrique vous permet d'accéder aux mesures historiques dans le stockage de métriques cloud de Soda et d'écrire des tests qui utilisent ces mesures historiques.
7. Surveillance automatisée
Soda Cloud offre la détection d'anomalies en série temporelle et la surveillance de l'évolution des schémas. En fait, lorsque vous intégrez un ensemble de données, Soda Cloud crée automatiquement à la fois un moniteur de détection d'anomalies pour le comptage des lignes pour commencer à apprendre des modèles sur vos données immédiatement, et un moniteur d'évolution de schéma pour commencer à suivre les changements dans les colonnes de votre ensemble de données.
8. Visualisation de la surveillance des données
Dans Soda Cloud, l'historique complet des métriques et des tests peut être publié et visualisé sur un compte Soda Cloud.
Prêt ?
Commencez avec Soda Spark ici.
Vous pouvez commencer immédiatement et tester vos dataframes en quelques étapes simples. Obtenez Soda Spark ici.
Nous aimerions savoir comment Soda Spark fonctionne pour vous. Rejoignez notre communauté Soda sur Slack et dites-nous ce que vous en pensez.
Consultez les articles de Cor et Anil sur Soda Spark pour en apprendre davantage :
Soda - prendre de l'avance sur les problèmes de données silencieux, Cor Zuurmond
⛔️ Soda Spark a été abandonné.
Soda Spark était une extension de Soda SQL qui vous permettait d'exécuter les fonctionnalités de Soda SQL de manière programmatique sur un Spark DataFrame. Il a été remplacé par Soda Library conçu pour connecter Soda à Apache Spark.
Dans le cadre de la mission pour rapprocher chacun de ses données, Soda a introduit Soda Spark, un outil moderne de test, de surveillance et de fiabilité des données pour les équipes d'ingénieurs qui utilisent les PySpark DataFrames. Le dernier outil open-source dans la boîte à outils de fiabilité des données de Soda, Soda Spark a été construit pour les ingénieurs en données et en analytique travaillant dans des environnements intensifs en données, où des données fiables et de haute qualité sont d'une importance capitale.
Soda Spark atténue la difficulté de maintenir un haut niveau de confiance dans les données dans l'écosystème Spark, où les ingénieurs passent généralement beaucoup de temps à construire des cadres pour les vérifications de la qualité des données. Les ingénieurs en données et en analytique peuvent contrôler les tests qui dépistent les mauvaises données - ou comme nous aimons les appeler, les problèmes de données silencieux - et les métriques qui évaluent les résultats. En utilisant le dialecte Spark déjà disponible dans Soda SQL, la bibliothèque Soda Spark fournit une API pour extraire les métriques des données et les profils de colonnes selon les requêtes que vous écrivez dans les fichiers de configuration YAML.
Les ingénieurs en données utilisent Soda Spark pour écrire des tests de qualité de données déclaratifs pour les Spark DataFrames et détecter les données problématiques. Lorsque vous connectez Soda Spark à un compte Soda Cloud, vous pouvez configurer des alertes qui notifient votre équipe lorsque vos tests Soda Spark échouent. Les équipes obtiennent les bonnes informations instantanément pour commencer le triage, l'enquête et la résolution rapide des problèmes.
Tutoriel : Test de qualité des données pour les pipelines Spark
Les outils de fiabilité des données open-source de Soda peuvent fonctionner sur plusieurs charges de travail, moteurs et environnements de données, y compris Kafka, Spark, AWS S3, Azure Blob Storage, Google Cloud Datastore, Presto, Snowflake, Azure Synapse, Google BigQuery et Amazon Redshift.
Utiliser Soda Spark est simple : installez-le via pip et commencez à utiliser l'API directement dans vos programmes PySpark. Voici une petite vidéo sur comment installer, utiliser et tester vos Spark DataFrames avec Soda Spark.
Alternativement, si vous utilisez un environnement d'exécution Spark populaire comme Databricks, vous pouvez également utiliser facilement Soda Spark dans vos Notebooks, et intégrer les tests directement dans vos pipelines ou programmer des tests.
Suivez ce tutoriel en cinq étapes pour voir comment vous pouvez exécuter des tests de qualité de données des DataFrames Apache Spark fonctionnant sur un cluster Databricks. Si vous n'avez pas déjà un cluster Databricks en fonction, vous pouvez en créer un depuis la communauté Databricks.
1. Pour installer Soda Spark dans votre Cluster Databricks, exécutez la commande suivante directement depuis votre notebook :
%pip install soda-spark
2. Chargez les données dans un DataFrame, puis créez une définition de scan avec des tests pour le DataFrame
3. Exécutez un scan Soda pour réaliser les tests que vous avez définis dans la définition du scan (fichier de configuration scan YAML)
Vous pouvez définir des tests dans deux endroits : 1) dans votre code comme une chaîne de caractères ou 2) dans un fichier YAML externe.
Dans ce tutoriel, nous définissons des tests dans un fichier de configuration YAML externe et utilisons ce fichier pour tester la qualité des données d'un DataFrame.
Lorsque le scan Soda est terminé, vous pouvez examiner les résultats des tests et les mesures dans la ligne de commande (voir image ci-dessous, haut), et la sortie dans le Notebook Databricks (voir image ci-dessous, bas).
4. Vérifiez les résultats des tests pour les tests ayant échoué durant le scan. Dans l'exemple de sortie ci-dessous, aucun test n'a échoué
Ce résultat affiche les métriques contre lesquelles Soda a testé vos données, les mesures résultantes, et le statut de réussite ou d'échec de chaque test.
5. Et maintenant, vous pouvez :
configurer Soda SQL pour envoyer les métriques et les résultats des tests à Soda Cloud.
rejoindre notre communauté Soda sur Slack pour poser des questions et faire des demandes de fonctionnalités.
devenir contributeur : nous cherchons toujours à améliorer notre bibliothèque. Toutes les contributions sont les bienvenues!
Un grand merci à Cor Zuurmond (GoDataDriven), le premier contributeur qui nous a aidés à développer Soda Spark, et à Abhishek Khare (HelloFresh) et Anil Kulkarni (Lululemon), pour leurs tests précoces et leurs précieux feedbacks! Consultez le dépôt Soda Spark ici.
Pourquoi Soda ajoute l'étincelle à vos pipelines
Soda est la société de fiabilité des données qui fournit des outils open-source (OSS) et des logiciels en tant que service (SaaS) permettant aux équipes de données de découvrir, de prioriser et de résoudre les problèmes de données. Nos outils de fiabilité des données OSS et notre plateforme cloud SaaS rapprochent tout le monde de ses données, aboutissant à des produits de données et des analyses en lesquels chacun peut avoir confiance. La communauté mondiale des données de Soda compte déjà Disney, HelloFresh et Udemy parmi les principaux contributeurs ayant déployé les outils de fiabilité des données de Soda.
Voici 8 bonnes raisons pour lesquelles nous pensons que votre équipe devrait utiliser Soda pour tester la qualité des données tout au long du cycle de vie de votre produit de données.
1. Prêt à l'emploi
Prêt à l'emploi, Soda supporte plusieurs sources de données, fournit une détection d'anomalies, des visualisations des résultats de tests historiques, et une gestion des incidents automatisée. Il est facile de commencer et simple de définir vos tests et attentes.
2. Installation
Installez facilement Soda Spark via pip, puis utilisez la ligne de commande pour vous connecter à une source de données, découvrir des ensembles de données, et lancer un scan en quelques minutes. Vous pouvez suivre des exemples documentés pour configurer des scans programmatiques depuis la ligne de commande et intégrer avec les outils de pipeline de données. La documentation de Soda est facile à suivre et hautement évaluée par la communauté et les observateurs. En utilisant SQL comme langage spécifique au domaine, il n'est pas nécessaire d'avoir de l'aide d'admin et il n'y a pas besoin de bien connaître les langages de programmation de haut niveau.
3. Bibliothèque de tests
Les docs de Soda fournissent plusieurs exemples pour utiliser les métriques intégrées, qui sont faciles à maintenir et simplifient la complexité de l'écriture des tests de qualité de données.
4. Partage et collaboration
Utilisez Soda Cloud pour inviter les membres de l'équipe, envoyer des notifications à Slack, partager les résultats des tests de données, et créer et suivre les incidents de qualité des données. Les membres de l'équipe peuvent examiner les résultats des scans et créer de nouveaux moniteurs dans Soda Cloud. Soda Cloud est plus inclusif pour une base d'utilisateurs non codeurs, ce qui facilite la collaboration dans une organisation.
5. Commencez avec une bonne documentation
Soda a investi dans l'écriture et la publication d'une documentation complète, concise, et à jour pour les outils de fiabilité des données open-source et la plateforme cloud. La documentation de Soda permet aux ingénieurs en données de découvrir et de surveiller immédiatement les problèmes de données grâce à une série de tests entièrement configurables.
6. Stockage des métriques cloud
Vous pouvez définir des métriques historiques afin que vous puissiez écrire des tests dans les fichiers scan YAML qui testent des données par rapport aux mesures historiques contenues dans le Stockage de métriques cloud de Soda. Essentiellement, ce type de métrique vous permet d'accéder aux mesures historiques dans le stockage de métriques cloud de Soda et d'écrire des tests qui utilisent ces mesures historiques.
7. Surveillance automatisée
Soda Cloud offre la détection d'anomalies en série temporelle et la surveillance de l'évolution des schémas. En fait, lorsque vous intégrez un ensemble de données, Soda Cloud crée automatiquement à la fois un moniteur de détection d'anomalies pour le comptage des lignes pour commencer à apprendre des modèles sur vos données immédiatement, et un moniteur d'évolution de schéma pour commencer à suivre les changements dans les colonnes de votre ensemble de données.
8. Visualisation de la surveillance des données
Dans Soda Cloud, l'historique complet des métriques et des tests peut être publié et visualisé sur un compte Soda Cloud.
Prêt ?
Commencez avec Soda Spark ici.
Vous pouvez commencer immédiatement et tester vos dataframes en quelques étapes simples. Obtenez Soda Spark ici.
Nous aimerions savoir comment Soda Spark fonctionne pour vous. Rejoignez notre communauté Soda sur Slack et dites-nous ce que vous en pensez.
Consultez les articles de Cor et Anil sur Soda Spark pour en apprendre davantage :
Soda - prendre de l'avance sur les problèmes de données silencieux, Cor Zuurmond
Trusted by the world’s leading enterprises
Real stories from companies using Soda to keep their data reliable, accurate, and ready for action.
At the end of the day, we don’t want to be in there managing the checks, updating the checks, adding the checks. We just want to go and observe what’s happening, and that’s what Soda is enabling right now.

Sid Srivastava
Director of Data Governance, Quality and MLOps
Investing in data quality is key for cross-functional teams to make accurate, complete decisions with fewer risks and greater returns, using initiatives such as product thinking, data governance, and self-service platforms.

Mario Konschake
Director of Product-Data Platform
Soda has integrated seamlessly into our technology stack and given us the confidence to find, analyze, implement, and resolve data issues through a simple self-serve capability.

Sutaraj Dutta
Data Engineering Manager
Our goal was to deliver high-quality datasets in near real-time, ensuring dashboards reflect live data as it flows in. But beyond solving technical challenges, we wanted to spark a cultural shift - empowering the entire organization to make decisions grounded in accurate, timely data.

Gu Xie
Head of Data Engineering
4,4 sur 5
Commencez à faire confiance à vos données. Aujourd'hui.
Trouvez, comprenez et corrigez tout problème de qualité des données en quelques secondes.
Du niveau de la table au niveau des enregistrements.
Adopté par







Trusted by the world’s leading enterprises
Real stories from companies using Soda to keep their data reliable, accurate, and ready for action.
At the end of the day, we don’t want to be in there managing the checks, updating the checks, adding the checks. We just want to go and observe what’s happening, and that’s what Soda is enabling right now.
Sid Srivastava
Director of Data Governance, Quality and MLOps
Investing in data quality is key for cross-functional teams to make accurate, complete decisions with fewer risks and greater returns, using initiatives such as product thinking, data governance, and self-service platforms.
Mario Konschake
Director of Product-Data Platform
Soda has integrated seamlessly into our technology stack and given us the confidence to find, analyze, implement, and resolve data issues through a simple self-serve capability.
Sutaraj Dutta
Data Engineering Manager
Our goal was to deliver high-quality datasets in near real-time, ensuring dashboards reflect live data as it flows in. But beyond solving technical challenges, we wanted to spark a cultural shift - empowering the entire organization to make decisions grounded in accurate, timely data.
Gu Xie
Head of Data Engineering
4,4 sur 5
Commencez à faire confiance à vos données. Aujourd'hui.
Trouvez, comprenez et corrigez tout problème de qualité des données en quelques secondes.
Du niveau de la table au niveau des enregistrements.
Adopté par
Solutions
Trusted by the world’s leading enterprises
Real stories from companies using Soda to keep their data reliable, accurate, and ready for action.
At the end of the day, we don’t want to be in there managing the checks, updating the checks, adding the checks. We just want to go and observe what’s happening, and that’s what Soda is enabling right now.
Sid Srivastava
Director of Data Governance, Quality and MLOps
Investing in data quality is key for cross-functional teams to make accurate, complete decisions with fewer risks and greater returns, using initiatives such as product thinking, data governance, and self-service platforms.
Mario Konschake
Director of Product-Data Platform
Soda has integrated seamlessly into our technology stack and given us the confidence to find, analyze, implement, and resolve data issues through a simple self-serve capability.
Sutaraj Dutta
Data Engineering Manager
Our goal was to deliver high-quality datasets in near real-time, ensuring dashboards reflect live data as it flows in. But beyond solving technical challenges, we wanted to spark a cultural shift - empowering the entire organization to make decisions grounded in accurate, timely data.
Gu Xie
Head of Data Engineering
4,4 sur 5
Commencez à faire confiance à vos données. Aujourd'hui.
Trouvez, comprenez et corrigez tout problème de qualité des données en quelques secondes.
Du niveau de la table au niveau des enregistrements.
Adopté par
Solutions
Company