Mise en place de tests de qualité des données dans votre pipeline
Mise en place de tests de qualité des données dans votre pipeline
Mise en place de tests de qualité des données dans votre pipeline

Fabiana Ferraz
Fabiana Ferraz
Rédacteur technique chez Soda
Rédacteur technique chez Soda

Mathisse De Strooper
Mathisse De Strooper
Directeur de l'Ingénierie Client chez Soda
Directeur de l'Ingénierie Client chez Soda
Table des matières
Les institutions financières, y compris les banques, les assureurs, les prêteurs hypothécaires, les investisseurs et les créanciers, dépendent fortement d'informations précises, complètes et opportunes pour gérer des processus commerciaux critiques et prendre des décisions éclairées.
Une mauvaise qualité des données peut perturber les rapports financiers, les approbations de prêts, la détection de la fraude, la gestion des risques de crédit et les évaluations des risques, provoquant des perturbations importantes qui sapent la crédibilité des institutions et mettent en danger la confiance des clients.
Par conséquent, maintenir une haute qualité des données dans le secteur financier n'est pas seulement une bonne pratique, c'est également une exigence réglementaire. La norme numéro 239 du Comité de Bâle sur le contrôle bancaire (BCBS 239) souligne l'importance pour les banques d'améliorer leurs capacités d'agrégation de données de risque et leurs pratiques de rapport de risque interne. La conformité à BCBS 239 garantit que les institutions financières peuvent rapporter les risques avec précision et rapidité, améliorant ainsi la stabilité du système financier.
Par conséquent, la mise en œuvre de tests de qualité des données robustes en amont du flux de données, également connue sous le terme de tests "shift-left", permet aux organisations de détecter et de résoudre les problèmes de manière proactive, minimisant ainsi les conséquences en aval.
Dans cet article de blog, nous passerons en revue comment intégrer Soda dans un flux de données financières pour garantir la qualité des données, la conformité et la précision des rapports de risque. Nous aborderons comment configurer les vérifications Soda, automatiser les validations et conserver une piste d'audit pour garantir l'exactitude, la complétude et la ponctualité des transactions.
Le Pouvoir de l'Automatisation pour le Secteur Financier
Les vérifications manuelles traditionnelles sont chronophages, sujettes aux erreurs humaines et inadaptées aux processus financiers modernes à grande échelle. Avec des milliers de transactions par seconde, les institutions financières nécessitent une solution automatisée et évolutive pour garantir l'intégrité des données et la conformité réglementaire.
Sans automatisation, les institutions feront face à :
❌ un retard dans les rapports de risque qui augmente la vulnérabilité aux activités frauduleuses ;
❌ une validation de données incohérente qui peut mener à des analyses financières inexactes ;
❌ des coûts opérationnels élevés en raison des nécessités de ressources importantes des vérifications manuelles.
Pour atténuer ces risques, les organisations doivent intégrer des vérifications robustes de la qualité des données dans leurs canaux de données. Soda offre une solution puissante et automatisée pour la gestion de la qualité des données. Ses outils intégrés de test et d'observabilité sont capables de scanner les données financières pour détecter les anomalies, les valeurs manquantes et les incohérences en temps réel.
Cela garantit que les organisations peuvent :
✅ appliquer la conformité BCBS 239 avec des vérifications automatisées pour l'exactitude, la complétude et la rapidité ;
✅ empêcher les données de mauvaise qualité d'atteindre les systèmes en aval, réduisant ainsi les erreurs coûteuses ;
✅ mettre en place des alertes proactives pour résoudre les problèmes avant qu'ils ne s'aggravent.
Plutôt que de revoir manuellement les journaux de transactions, une institution financière peut configurer des vérifications Soda pour détecter les transactions en double avant qu'elles ne touchent les comptes des clients, surveiller les transactions manquantes ou retardées pour éviter les écarts de reporting, et signaler les schémas inhabituels, permettant ainsi aux équipes de détection de fraude d'intervenir plus rapidement.
Dans les sections suivantes, nous verrons comment cela fonctionne en pratique.
Configurer les Vérifications Automatisées avec Soda
L'automatisation des vérifications de la qualité des données est cruciale dans l'industrie financière car la précision des données a un impact direct sur la prise de décision, la conformité réglementaire et la confiance des clients.
Soda vous permet de surveiller proactivement vos données et d'identifier les problèmes potentiels en amont du pipeline. Il peut s'intégrer de manière transparente dans vos flux de travail existants tout en offrant une visibilité complète sur l'état de santé de vos données.
En suivant ce guide étape par étape, vous découvrirez comment déployer rapidement et intégrer Soda dans votre flux de données financières, rationaliser les efforts de conformité et réduire la supervision manuelle.
Choisir le Modèle de Déploiement Approprié
Pour évaluer la qualité de vos données avec Soda, vous devrez choisir un modèle de déploiement qui vous permet d'établir des connexions avec vos sources de données. Vous définirez ensuite les vérifications nécessaires de la qualité des données et exécuterez des analyses pour vous assurer qu'elles sont effectuées efficacement.
Cet article se concentrera sur l'utilisation de Soda Library, un outil Python qui vous donne un contrôle direct sur les vérifications de la qualité des données au sein de votre pipeline. Vous pourrez ensuite vérifier les résultats dans votre interface en ligne de commande (CLI) ainsi que dans votre compte Soda Cloud.
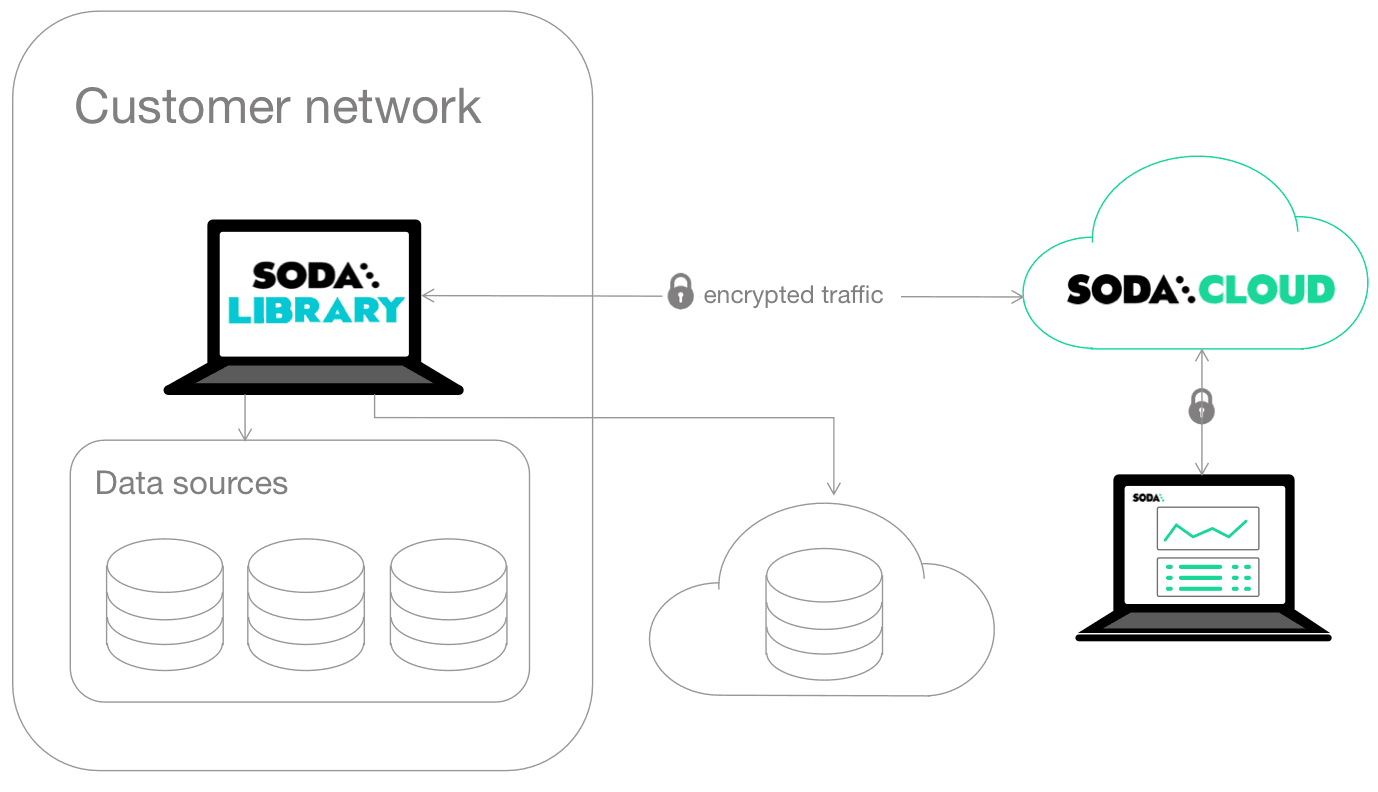
Vous pouvez également connecter vos sources de données directement à Soda Cloud, en utilisant une configuration de type SaaS où vous gérez la qualité des données sans aucun codage. Pour des conseils plus détaillés sur le choix du modèle de déploiement approprié, reportez-vous au guide de configuration de Soda.
Configuration Étape par Étape avec Soda Library
Vous pouvez intégrer Soda à plusieurs Sources de Données différentes, mais pour cet article, nous vous montrerons comment configurer Soda Library pour automatiser vos vérifications de la qualité des données en utilisant MySQL.
En suivant ces étapes, vous serez en mesure de configurer des connexions à votre base de données, de définir des vérifications critiques de la qualité des données, et de commencer à surveiller la qualité des données en temps réel.
Les objectifs techniques de cet article sont :
1. Installer Soda Library en utilisant votre CLI.
2. Configurer les fichiers YAML pour :
Se connecter à vos sources de données pour exécuter des analyses de qualité.
Lier votre configuration à Soda Cloud pour valider votre licence et voir les métriques de qualité des données.
Créer et personnaliser les vérifications de la qualité des données en fonction de vos besoins.
Après avoir terminé cette configuration, vous pourrez intégrer les vérifications de la qualité des données de Soda dans votre pipeline, garantissant que vos données financières restent fiables et conformes.
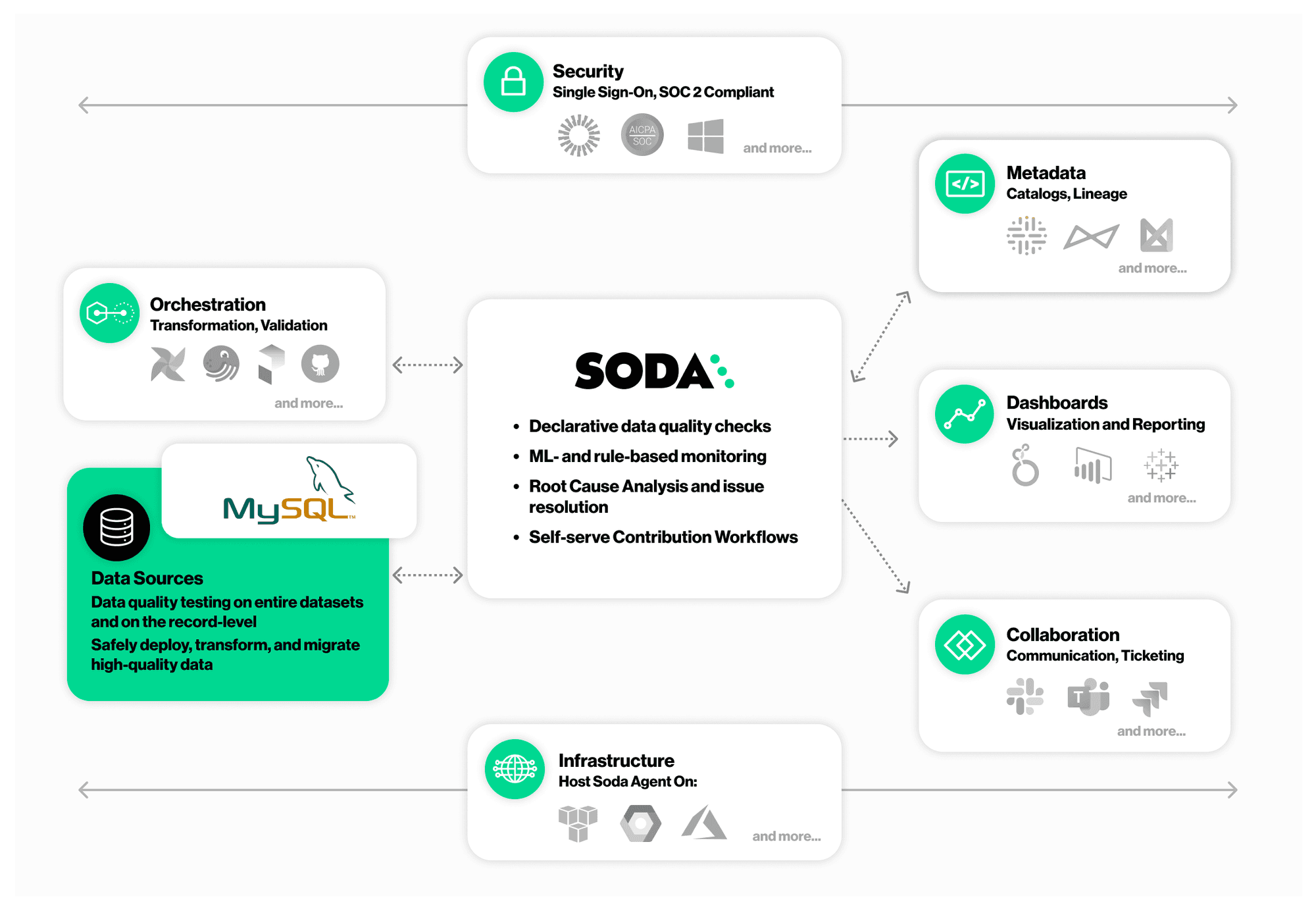
C'est une configuration simple dans laquelle vous installez Soda Library localement et la connectez à Soda Cloud via des clés API. Commençons.
1. Création de Compte et de Clés API
Étape 1 : Rejoindre Soda Cloud
Pour commencer, inscrivez-vous pour un compte Soda Cloud pour un essai gratuit de 45 jours.
La création de compte en libre-service pour Soda Cloud est temporairement suspendue car nous préparons la disponibilité générale de plusieurs mises à jour majeures. Si vous souhaitez essayer Soda Cloud en attendant, veuillez programmer un appel avec notre équipe d'experts, discutez de votre cas d'utilisation et commencez.
Pourquoi créer un compte ? Parce que votre Soda Library doit communiquer avec un compte Soda via des clés API pour valider votre licence ou essai gratuit.
Étape 2 : Générer des Clés API
Une fois votre compte créé, créez vos clés API dans Soda Cloud :
Allez à votre avatar > Profil, puis accédez à l'onglet Clés API.
Cliquez sur l'icône plus pour générer de nouvelles clés API
Copiez la configuration syntaxique de l'API soda_cloud et conservez-la en lieu sûr. Vous en aurez besoin pour configurer le fichier de connexion.

2. Configuration de Soda à la Source de Données
Maintenant, connectons Soda Library à MySQL. Voici comment vous pouvez le faire.
Étape 1 : Installer les Dépendances
Ouvrez votre environnement de développement préféré (IDE) et assurez-vous que votre version de Python est ≤ 3.10 et pip est ≥ 21.0.
Étape 2 : Configurer le Répertoire du Projet
Créez un nouveau répertoire pour votre projet Soda dans votre environnement local et accédez-y via votre CLI. Votre structure de projet devrait ressembler à ceci :
your_project/ │── soda-env/ │ ├── configuration.yml │ ├── checks.yml
Étape 3 : Créer un Environnement Virtuel
Il est préférable d'installer Soda Library dans un environnement virtuel. Pour en créer un, exécutez les commandes suivantes :
py -3.10 -m venv soda-env .\soda-env\Scripts\Activate
Étape 4 : Installer Soda Library pour MySQL
Étant donné que nous utilisons MySQL, installez le package requis :
pip install soda-mysql
Si vous utilisez une source de données différente, assurez-vous d'installer le package correspondant. Vous pouvez trouver une liste des packages disponibles dans notre documentation.
Étape 5 : Configurer le Fichier de Configuration
Dans votre répertoire de projet Soda, créez un fichier nommé configuration.yml. Collez les détails de connexion suivants dans le fichier, en remplaçant les valeurs par vos informations réelles :
data_source your_database_name: type: mysql host: 127.0.0.1 #or 'root' or any host name you're using username: #mysql_username password: #mysql_password database: #your_database_name soda_cloud: host: cloud.soda.io api_key_id: #a4ac173d---c29 api_key_secret: #V13xLLEDG---flTw
Notez que c'est le fichier où vous devez passer votre syntaxe de configuration API.
Assurez-vous que les informations d'identification et l'information hôte sont exactes et que l'utilisateur dispose des permissions nécessaires pour accéder à la base de données. Pour des instructions plus détaillées, consultez la documentation de Soda sur la connexion à MySQL.
Vous pouvez également utiliser des variables système pour passer des informations sensibles (mots de passe et clés API) si vous le préférez. Pour plus d'informations à ce sujet, consultez notre documentation sur Comment Installer Soda Library.
Étape 6 : Tester la Connexion
Enregistrez le fichier configuration.yml et exécutez ensuite la commande suivante pour tester si Soda peut se connecter avec succès à votre base de données :
soda test-connection -d your_database_name -c configuration.yml
Si la connexion réussit, vous devriez voir un résultat similaire à :
Soda Core 3.5.0 Successfully connected to 'your_database_name'. Connection 'your_database_name' is valid
Une fois cette étape terminée, votre agent hébergé par Soda établira des connexions sécurisées avec Soda Cloud, vous permettant d'implémenter des vérifications automatisées de la qualité des données dans tout schéma à l'intérieur de votre base de données.
Cas d'Utilisation : Surveillance de la Qualité des Données Financières
Avec Soda Library installé et connecté à votre source de données, nous sommes prêts à passer à la définition de vos vérifications de la qualité des données et à l'exécution de scans automatisés sur vos données. Mais d'abord, examinons quelques principes clés pour comprendre quelles vérifications sont plus pertinentes pour notre gestion de la qualité des données financières.
Principes Clés pour la Gestion de la Qualité des Données Financières
En adhérant à quelques principes clés, vous pourrez vous assurer que vos données financières sont exactes, cohérentes et sécurisées. Voici quelques principes importants que les institutions financières devraient garder à l'esprit pour garantir une qualité de données optimale :
Exactitude et Cohérence : Des décisions financières fiables nécessitent des données à la fois précises et cohérentes. De petites erreurs ou incohérences peuvent entraîner des erreurs coûteuses.
Complétude et Pertinence : Les données incomplètes ou manquantes peuvent avoir un impact significatif sur les évaluations de risque et les opérations commerciales dans leur ensemble.
Actualité et Fraîcheur : Les données financières doivent être à jour. Des retards dans la mise à jour de vos données peuvent entraîner des évaluations financières incorrectes et des pénalités réglementaires potentielles.
Normalisation et Gouvernance : Des directives claires et des pratiques normalisées aident à éviter les incohérences et la confusion. Avec une gouvernance appropriée, vous pouvez garantir l'intégrité des données entre les départements et les systèmes.
Sécurité des Données et Conformité : Les données financières sont sensibles et leur protection est essentielle. La mise en œuvre d'un contrôle d'accès basé sur les rôles, le cryptage et les pistes d'audit garantit que seuls les utilisateurs autorisés ont accès aux données, les protégeant contre les violations, la fraude ou les mauvais usages.
Automatisation et Surveillance Continue : L'automatisation accélère les vérifications de la qualité des données, vous permettant de détecter les anomalies, les duplications et les incohérences en temps réel. La surveillance continue assure que les problèmes de qualité des données sont rapidement identifiés et résolus, conduisant à un système financier plus transparent et efficace.
En suivant ces principes, vous pouvez non seulement respecter les exigences réglementaires, mais aussi instaurer la confiance dans vos données financières, vous permettant ainsi de prendre de meilleures décisions et d'évoluer dans un environnement plus sécurisé.
Dans les prochaines étapes, nous vous guiderons à travers la création et la configuration de ces vérifications pour surveiller la qualité des données en temps réel. Mais avant cela, nous allons créer un jeu de données d'exemple.
1. Création d'un Jeu de Données Exemple
Pour surveiller efficacement la qualité des données financières, nous allons créer une table transactions qui simule des données financières du monde réel. Cette table inclura des problèmes de qualité des données intentionnels pour démontrer comment les détecter et les résoudre en utilisant les vérifications Soda.
Étape 1 : Configurer la Base de Données et la Table
Commencez par créer une nouvelle base de données nommée soda_trial et définir la table transactions avec les colonnes appropriées :
CREATE DATABASE soda_trial; USE soda_trial; CREATE TABLE transactions ( transaction_id INT PRIMARY KEY, account_number VARCHAR(20), transaction_date DATE, amount DECIMAL(15,2), currency CHAR(3), transaction_type VARCHAR(10) )
Étape 2 : Remplir la Table avec des Données d'Exemple
Ensuite, insérez des enregistrements exemples dans la table, incluant des problèmes de qualité des données intentionnels pour tester l'efficacité des vérifications Soda :
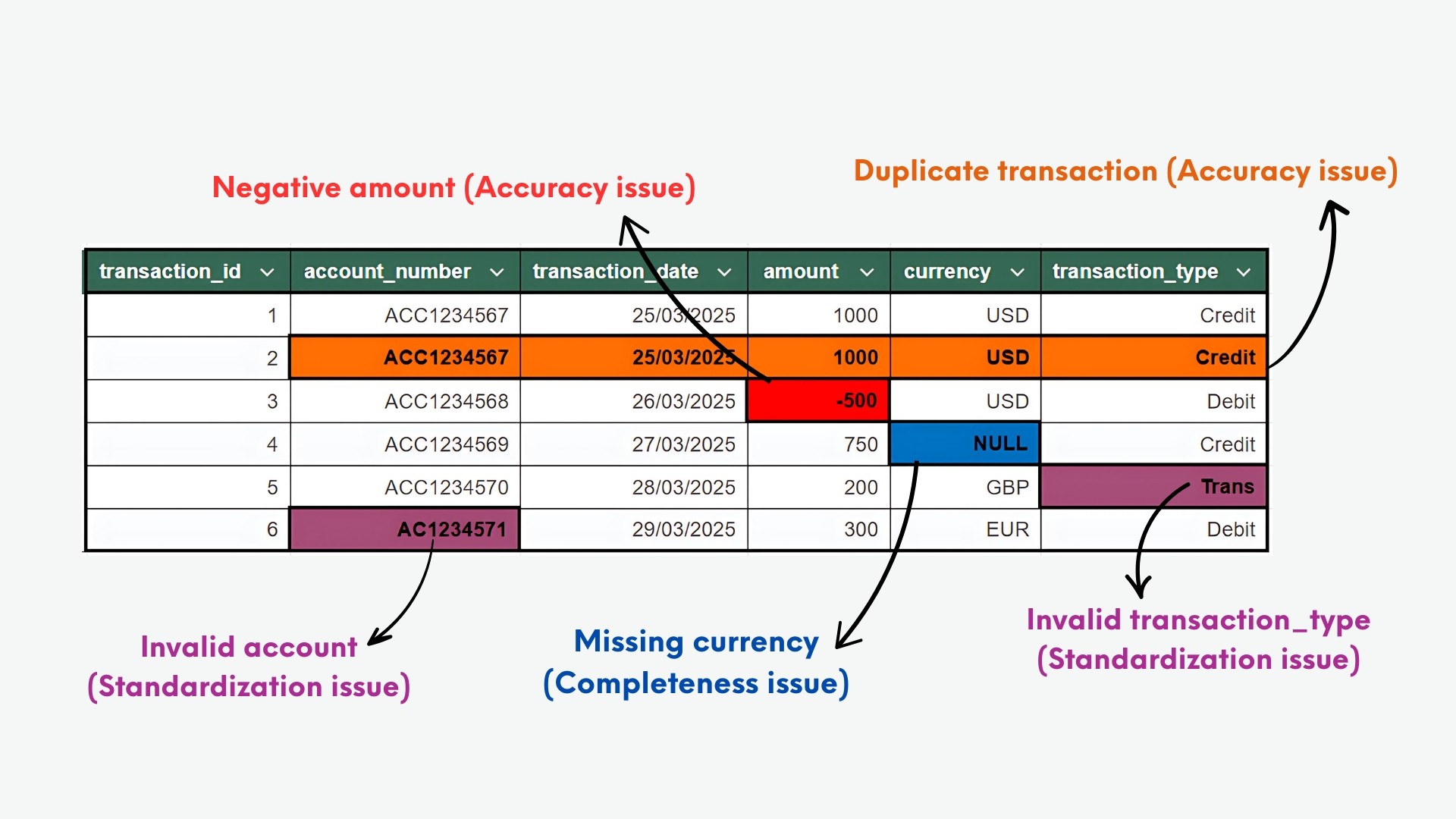
INSERT INTO transactions (transaction_id, account_number, transaction_date, amount, currency, transaction_type) VALUES (1, 'ACC1234567', '2025-03-25', 1000.00, 'USD', 'Credit'), (2, 'ACC1234567', '2025-03-25', 1000.00, 'USD', 'Credit'), (3, 'ACC1234568', '2025-03-26', -500.00, 'USD', 'Debit'), (4, 'ACC1234569','2025-03-27', 750.00, NULL, 'Credit'), (5, 'ACC1234570', '2025-03-28', 200.00, 'GBP', 'Trans'), (6, 'AC1234571', '2025-03-29', 300.00, 'EUR', 'Debit')
2. Configuration des Vérifications Soda
Les scans Soda sont conçus pour effectuer des vérifications de la qualité des données sur votre source de données, aidant à identifier les données non valides, manquantes ou inattendues. Avec le jeu de données exemple en place, nous pouvons maintenant définir les vérifications de la qualité des données en utilisant SodaCL (Soda Checks Language) pour identifier et résoudre les problèmes introduits.
Étape 1 : Comprendre les Concepts Clés
Tout d'abord, assurons-nous de bien comprendre certains concepts importants :
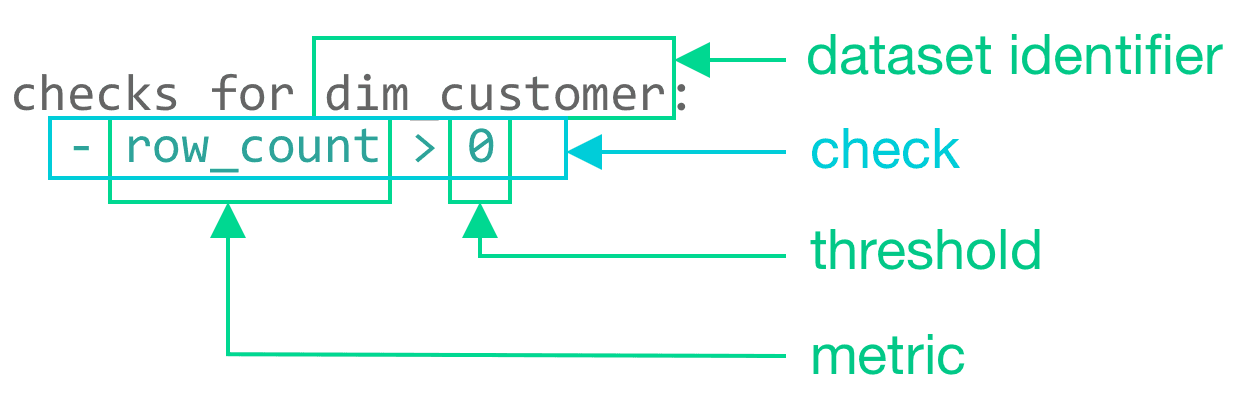
SodaCL : un langage basé sur YAML qui comprend plus de 25 métriques intégrées que vous pouvez utiliser pour écrire des vérifications, mais vous avez également l'option d'écrire vos propres requêtes SQL ou expressions.
Vérification Soda : une expression Python qui vérifie les métriques pendant un scan Soda pour voir si elles correspondent aux normes que vous avez fixées pour un seuil.
Métrique : Une propriété ou une mesure des données au sein de votre ensemble de données.
Seuil : La valeur ou l'intervalle qu'une métrique est comparée à dans une vérification.
Scan Soda : exécute plusieurs vérifications contre un ou plusieurs ensembles de données présents dans la base deonnées à laquelle vous êtes connecté à Soda.
Pour une liste complète des métriques et vérifications de SodaCL, consultez la Documentation de SodaCL.
Étape 2 : Conception des Vérifications Efficaces de la Qualité des Données
Maintenant, examinons certains des principes que nous avons vus ci-dessus. Nous avons choisi quelques dimensions cruciales pour les données financières et leurs problèmes associés afin de pouvoir créer nos vérifications en utilisant SodaCL.
Exactitude et Cohérence
Transactions en Double : Les entrées en double d'IDs de transactions peuvent gonfler les métriques financières et fausser les analyses.
Montants de Transaction Invalides : Les montants de transaction qui tombent en dehors des plages attendues peuvent indiquer des erreurs de saisie des données ou des fraudes.
Complétude et Pertinence
Dates ou Numéros de Compte de Transaction Manquants : Les enregistrements incomplets limitent la capacité à suivre et à rapprocher les transactions avec précision, compromettant la communication financière et posant des défis dans les processus d'audit.
Actualité et Fraîcheur
Transactions Obsolètes : Les mises à jour retardées peuvent entraîner des évaluations financières inexactes et des pénalités réglementaires potentielles.
Normalisation et Gouvernance
Types de Transactions ou Codes Monétaires Non Standard : Les formats de données incohérents peuvent entraîner des erreurs d'interprétation et de traitement.
Automatisation et Surveillance Continue
Manque de Vérifications Régulières de la Qualité des Données : Sans surveillance automatisée, les problèmes de données peuvent rester non détectés jusqu'à ce qu'ils causent des problèmes importants.
La mise en œuvre des vérifications Soda permet une identification proactive et la résolution de ces problèmes de qualité des données et d'autres, garantissant des données financières fiables pour une prise de décision éclairée. Alors, voyons cela en pratique.
Étape 3 : Mise en Œuvre des Vérifications
Soda prépare un scan en utilisant des vérifications et des configurations de connexion à la source de données, qu'il exécute ensuite contre des ensembles de données pour extraire des métadonnées et évaluer la qualité des données.
Pour cela, vous devrez aller dans votre répertoire de projet et créer un fichier checks.yml pour définir les vérifications pour notre ensemble de données. Nous nous concentrerons sur plusieurs dimensions clés de la qualité des données pertinentes pour les données financières.
Voici un code complet commenté que vous pouvez appliquer à notre base de données de test. Il définit un ensemble de vérifications de la qualité des données pour notre table transactions :
Il vérifie que les transactions ont des IDs uniques, que les montants sont valides et formatés correctement, et que les numéros de compte suivent un modèle spécifique.
Les vérifications de complétude assurent qu'il n'y a pas de valeurs manquantes dans les champs clés, tandis que les vérifications de fraîcheur confirment que les données de transactions sont mises à jour quotidiennement.
Les règles de normalisation appliquent des codes monétaires et des types de transaction valides.
Les mesures de conformité incluent des limites de nombre de lignes, et la validation du schéma détecte les changements non autorisés dans les colonnes nécessaires et les types de données.
Ces règles soutiennent la surveillance automatisée et continue de la qualité des données.
checks for transactions: # Remember to chose your table here # Accuracy and Consistency - duplicate_count(transaction_id) = 0 # Detect duplicate transaction_id entries - duplicate_count(account_number, amount, transaction_type): warn: when > 0 # ensure there are no duplicate transactions - invalid_count(amount) = 0: valid min: 0.01 # Ensure amount values are within a valid range valid format: decimal # Ensure formatting is consistent - invalid_count(account_number) = 0: valid regex: '^ACC.*' # Completeness # Verify no missing values - missing_count(transaction_id) = 0 - missing_count(account_number) = 0 - missing_count(transaction_date) = 0 - missing_count(amount) = 0 - missing_count(currency) = 0 - missing_count(transaction_type) = 0 # Timeliness and Freshness - freshness(transaction_date) < 1d # Assess that data is refreshed daily # Standardization and Governance - invalid_count(currency) = 0: valid values: ['USD', 'EUR', 'GBP'] # Add all acceptable currency codes invalid regex: '[^A-Z]{3}' # Ensure formatting is consistent - invalid_count(transaction_type) = 0: valid values: ['Credit', 'Debit', 'Transfer'] # Data Security and Compliance # Monitor that the table does not exceed a specified number of rows # to manage data volume and compliance. - row_count < 1000000 # Automation and Continuous Monitoring # Define the expected schema to detect unauthorized changes - schema: fail: when required column missing: - transaction_id - account_number - transaction_date - amount - currency - transaction_type when wrong column type: transaction_id: int account_number: varchar transaction_date: date amount: decimal currency: char transaction_type
Si vous avez besoin de scanner différents ensembles de données, n'oubliez pas de créer un fichier de vérification différent pour chacun (dans ce cas, chaque table de votre base de données MySQL).
3. Intégrer Soda dans Votre Pipeline
Pour automatiser les vérifications de la qualité des données au sein de vos flux de travail ETL (Extract, Transform, Load), intégrez une étape qui exécute des scans Soda après l'ingestion des données. Cette intégration garantit que la qualité des données est évaluée avant tout traitement ultérieur, permettant une détection précoce et la résolution des problèmes.
Utilisez la commande suivante pour exécuter un scan Soda sur votre ensemble de données :
soda scan -d soda_trial -c configuration.yml checks.yml
Dans cette commande :
-d soda_trialspécifie le nom de la source de données tel que défini dans votre fichier de configuration.-c configuration.ymldésigne votre fichier de configuration Soda contenant les détails de connexion.checks.ymlest le fichier où vous avez défini vos vérifications de la qualité des données en utilisant SodaCL.
4. Examiner les résultats du scan
En intégrant les scans Soda dans votre pipeline, vous établissez une approche proactive de la qualité des données, garantissant que les problèmes sont identifiés et résolus rapidement, assurant ainsi l'intégrité de vos données tout au long de leur cycle de vie.
Après un scan, chaque vérification aboutit à l'un des trois états par défaut :
passe : les données répondent aux seuils de qualité spécifiés.
échoue : les données ne respectent pas les seuils de qualité spécifiés.
erreur : il y a un problème avec la syntaxe ou l'exécution de la vérification.
État supplémentaire :
avertissement : un état configurable qui vous alerte sur des problèmes potentiels sans marquer la vérification comme un échec complet. Voir plus dans Ajouter des configurations d'alerte. Exemple d'avertissement de notre code :
- duplicate_count(account_number, amount, transaction_type): warn: when > 0
Lorsque les vérifications échouent, elles révèlent les données de basse qualité et fournissent des résultats qui vous aident à enquêter et résoudre les problèmes de qualité.
Vous pouvez examiner les résultats de vos scans Soda via deux canaux principaux :
1. Interface en ligne de commande (CLI) : À l'exécution d'un scan, Soda fournit un retour d'information immédiat dans le terminal, affichant les résultats de chaque vérification. Cette perspicacité en temps réel permet des évaluations rapides et des actions immédiates si nécessaire.
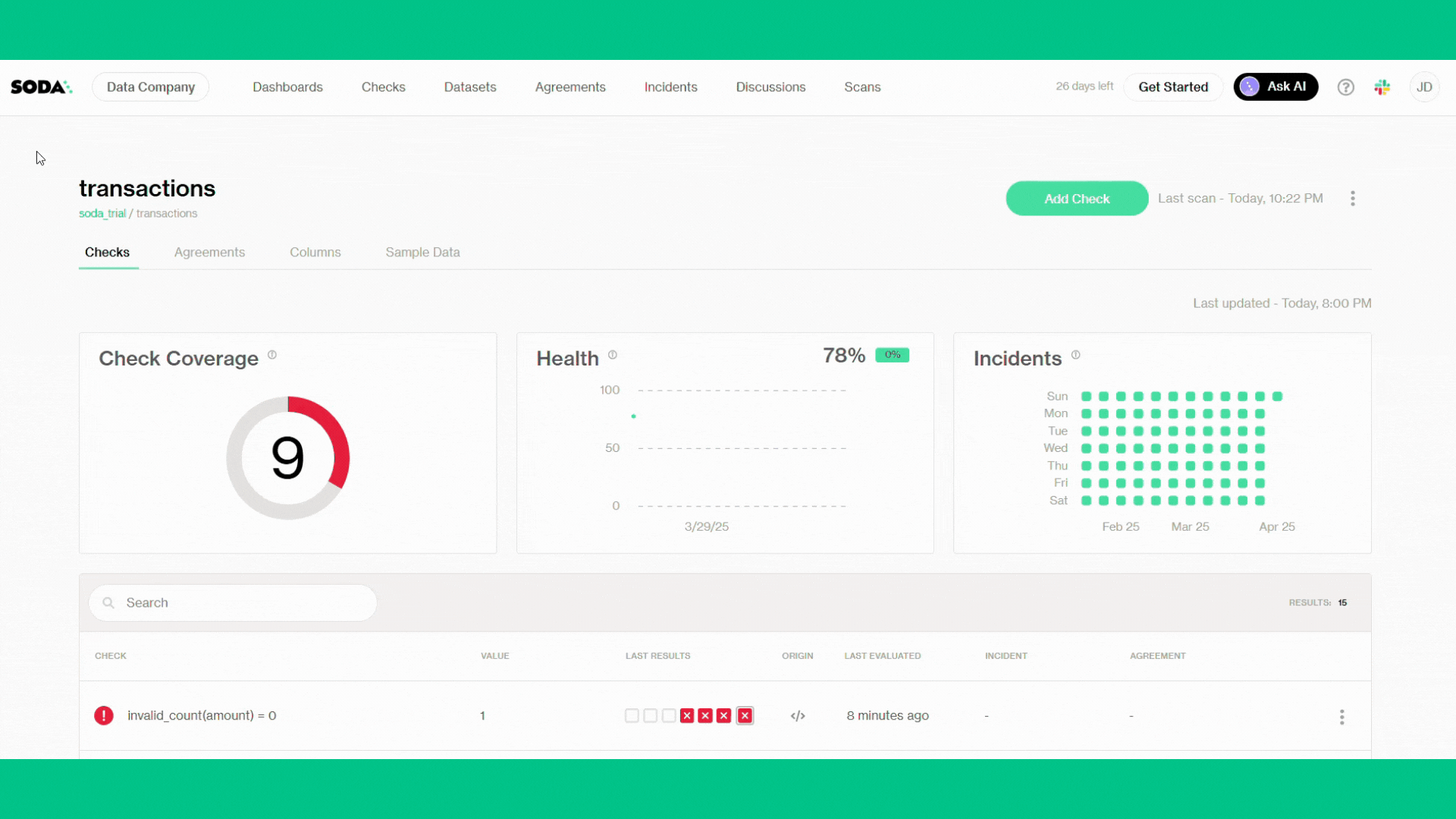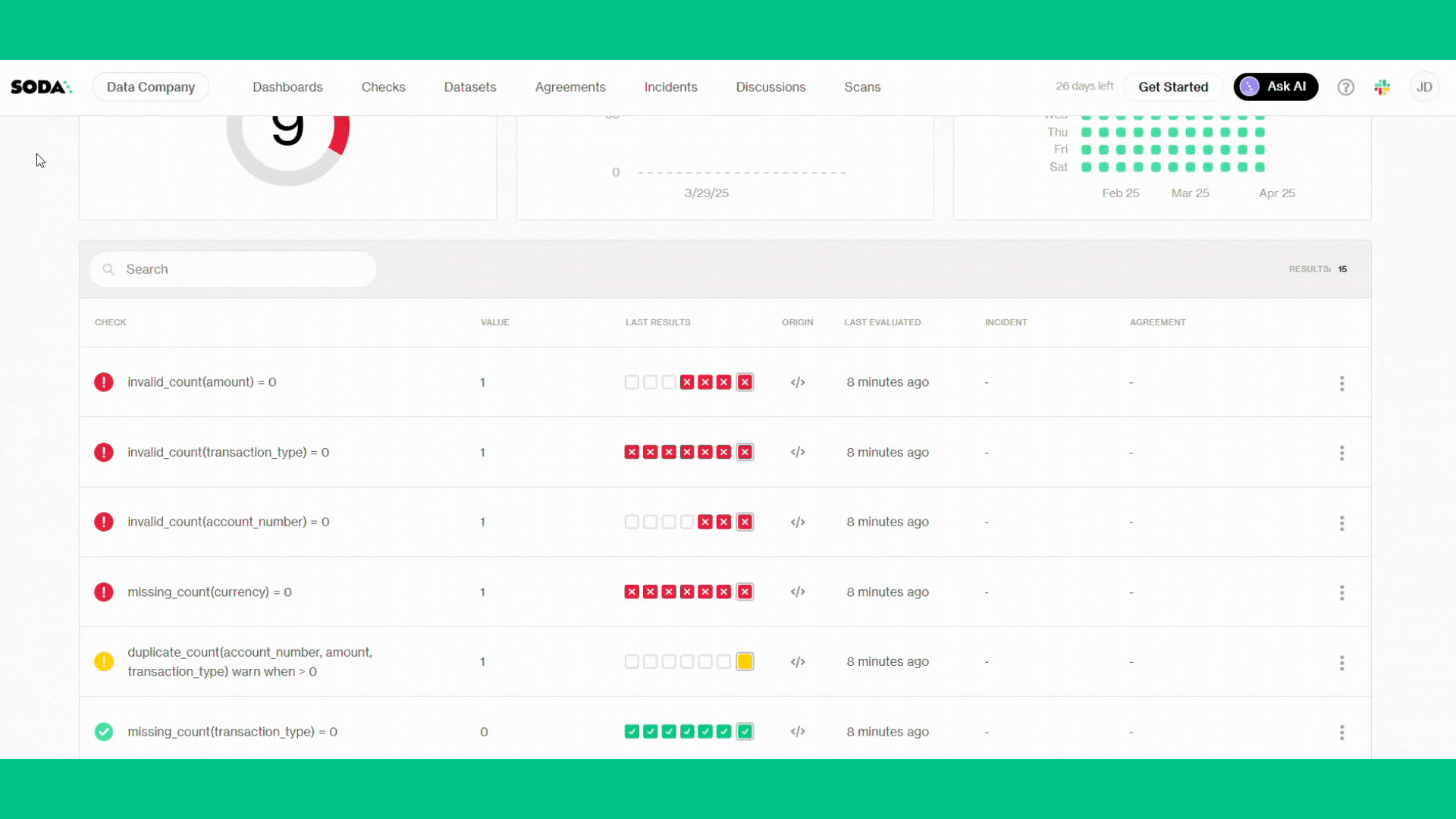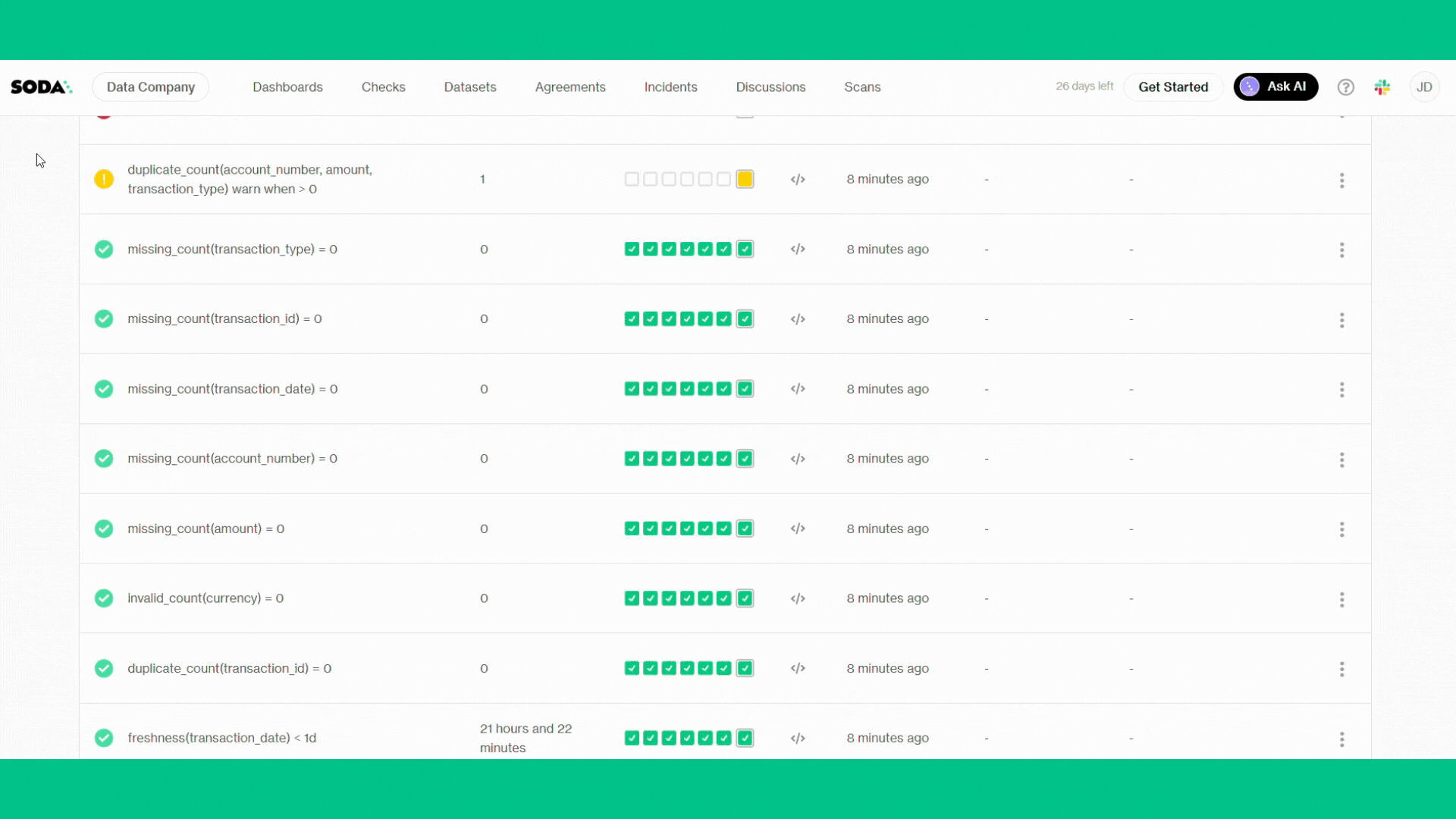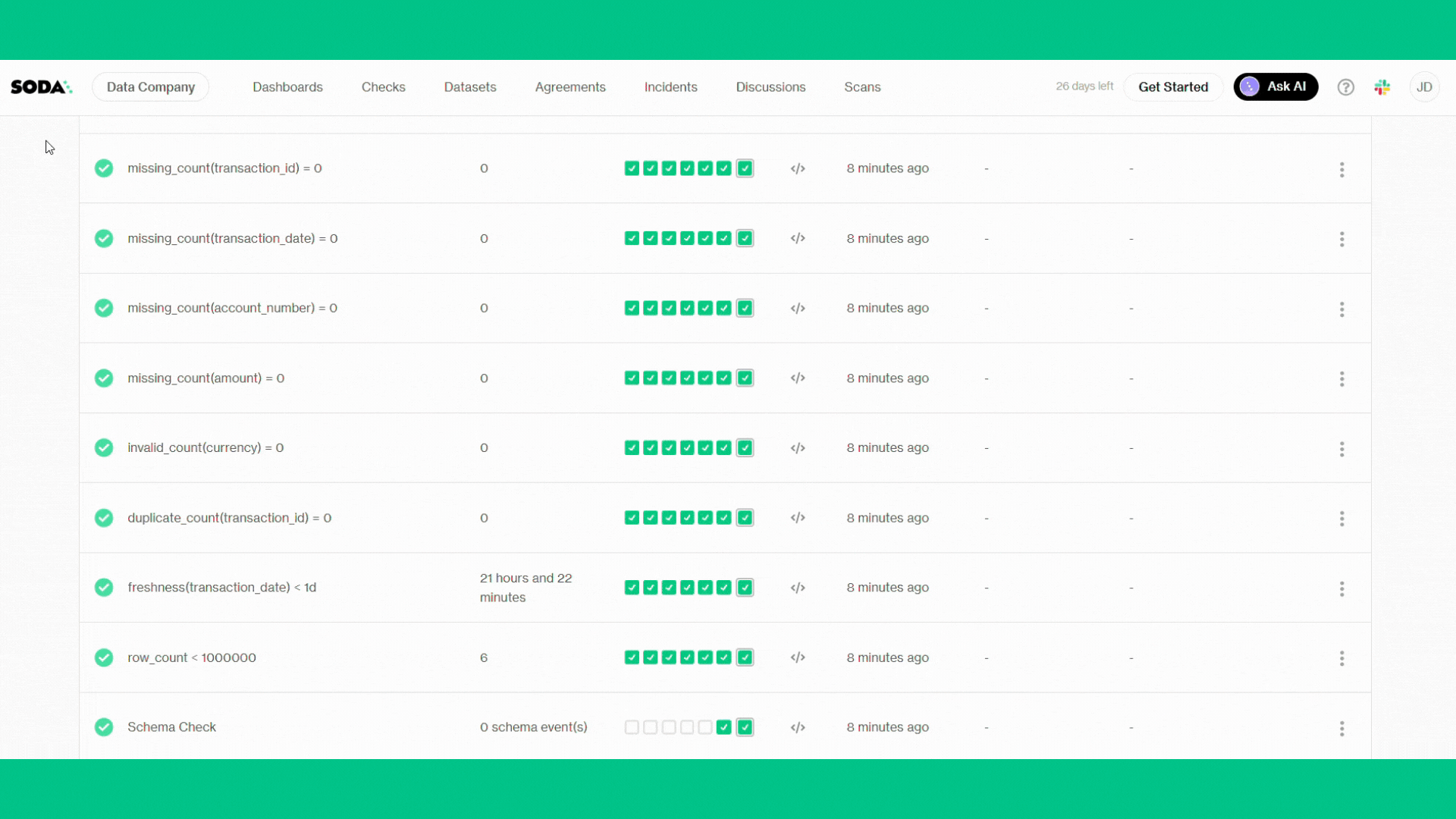
Soda Core 3.5.0 Sending failed row samples to Soda Cloud Sending failed row samples to Soda Cloud Sending failed row samples to Soda Cloud Sending failed row samples to Soda Cloud Sending failed row samples to Soda Cloud Scan summary: 10/15 checks PASSED: transactions in soda_trial row_count < 1000000 [PASSED] Schema Check [PASSED] duplicate_count(transaction_id) = 0 [PASSED] missing_count(transaction_id) = 0 [PASSED] missing_count(amount) = 0 [PASSED] missing_count(account_number) = 0 [PASSED] missing_count(transaction_date) = 0 [PASSED] freshness(transaction_date) < 1d [PASSED] invalid_count(currency) = 0 [PASSED] missing_count(transaction_type) = 0 [PASSED] 1/15 checks WARNED: transactions in soda_trial duplicate_count(account_number, amount, transaction_type) warn when > 0 [WARNED] check_value: 1 4/15 checks FAILED: transactions in soda_trial invalid_count(amount) = 0 [FAILED] check_value: 1 invalid_count(account_number) = 0 [FAILED] check_value: 1 missing_count(currency) = 0 [FAILED] check_value: 1 invalid_count(transaction_type) = 0 [FAILED] check_value: 1 Oops! 4 failures. 1 warning. 0 errors. 10 pass. Sending results to Soda Cloud
Les vérifications de schéma visent principalement à valider les aspects structurels de vos données, tels que la présence, l'absence et la position des colonnes, ainsi que les types de données qui leur sont affectés. Cependant, les vérifications de schéma n'incluent pas l'application de formats de données ou de contraintes spécifiques, comme s'assurer que les valeurs numériques respectent une précision décimale spécifique.
2. Soda Cloud : Pour un examen plus détaillé et collaboratif, dans Soda Cloud, vous pouvez :
Visualiser les résultats du scan via des tableaux de bord intuitifs.
Surveiller les tendances de la qualité des données au fil du temps.
Recevoir des alertes pour les vérifications échouées ou les anomalies.
Collaborer avec les membres de votre équipe pour résoudre les problèmes de qualité des données.
Surveillance et Alerte pour la Qualité des Données
Soda permet la surveillance et l'alerte en temps réel, tenant les parties prenantes informées des problèmes de qualité des données. Configurez Soda pour envoyer des alertes à Slack, Jira ou MS Teams lorsque des vérifications échouent.
Pour activer les alertes, définissez des canaux de notification dans votre configuration Soda et spécifiez les conditions sous lesquelles elles doivent être déclenchées. Cette approche proactive garantit que les problèmes de qualité des données sont résolus rapidement, préservant l'intégrité de vos actifs de données.
Connexion avec MS Teams
Si vous y êtes autorisé, vous pouvez intégrer votre espace de travail Microsoft Teams dans Soda Cloud afin qu'il puisse interagir avec des individus et des chaînes.
Utilisez l'intégration Microsoft Teams pour :
Envoyer des alertes à Microsoft Teams pour les résultats de vérification (notifications d'avertissement ou d'échec).
Créer un canal Teams dédié pour enquêter sur les vérifications échouées et collaborer à la résolution des incidents.
Suivre les Discussions Soda pour une collaboration en temps réel sur la qualité des données avec votre équipe.
Pour configurer l'intégration :
1. Accéder aux Intégrations Soda Cloud : Connectez-vous à votre compte Soda Cloud, allez à votre avatar > Paramètres de l'organisation, et sélectionnez l'onglet Intégrations. Cliquez sur l'icône + dans le coin supérieur droit pour ajouter une nouvelle intégration.
2. Sélectionner MS Teams : Dans la boîte de dialogue Ajouter une Intégration, choisissez Microsoft Teams. Vous serez alors guidé à travers une configuration de workflow.
3. Créer un Workflow : Suivez le guide de configuration qui vous indique de vous connecter à votre compte MS Teams. Vous devrez créer un workflow dans Teams (voir la documentation de Microsoft pour "Créer un workflow à partir d'un canal dans Teams") en utilisant le modèle fourni pour poster sur un canal lorsqu'une requête de webhook est reçue.
4. Compléter l'Intégration : Une fois le workflow créé avec succès, copiez l'URL générée et revenez à Soda Cloud pour terminer les étapes guidées. Au cours de ce processus, vous configurerez les portées de l'intégration :
Périmètre de Notification d'Alerte : Permettre à Soda Cloud d'envoyer des notifications d'alertes (pour des résultats de vérification avertis et échoués) directement à votre canal MS Teams choisi. Cela permet aux utilisateurs de sélectionner MS Teams comme destination pour des alertes de vérification individuelles ou groupées.
Périmètre d'Incident : Configurez des notifications pour la création d'un nouvel incident dans Soda Cloud. Ce périmètre affichera un lien externe vers votre canal MS Teams dans les Détails de l'Incident, dirigeant votre équipe vers l'espace approprié pour résoudre l'incident.
Périmètre de Discussions : Configurez Soda Cloud pour publier sur un canal Teams spécifique chaque fois qu'une discussion est initiée ou modifiée. Cela facilite la collaboration continue sur la qualité des données au sein de votre organisation.
Avec l'intégration en place, Soda Cloud peut automatiquement envoyer des notifications à vos canaux MS Teams, garantissant que les alertes, les mises à jour d'incidents et les discussions collaboratives sont facilement partagées avec votre équipe, permettant une réponse rapide et une résolution efficace des problèmes.
Consultez notre documentation pour en savoir plus sur la Intégration avec MS Teams, et aussi sur comment Organiser les résultats, configurer des alertes, enquêter sur les problèmes.
Conclusion - Bonnes Pratiques pour Maintenir la Qualité des Données
Un pipeline de données financières bien architecturé, combiné à une validation et une surveillance automatisées, assure que les données sont constamment précises, complètes et fiables. La beauté de Soda Library réside dans sa capacité à s'intégrer directement dans votre pipeline, vous permettant d'automatiser les vérifications de la qualité des données à toutes les étapes, de l'ingestion au traitement.
En suivant ce guide, vous pouvez créer une solution efficace et évolutive qui permet à votre équipe d'assurer la qualité des données en temps réel tout en respectant les normes réglementaires telles que BCBS 239.
Pour l'avenir, restez à l'écoute des prochains articles de blog qui exploreront des améliorations pour votre pipeline, telles que :
Autonomiser les Utilisateurs Métier : Découvrez comment permettre aux utilisateurs métier de proposer et d'appliquer leurs propres règles métier directement dans votre pipeline.
Surveillance Automatisée des Métriques : Découvrez comment configurer la surveillance automatisée des métriques pour identifier des problèmes cachés à grande échelle, garantissant qu'aucun problème de qualité des données ne passe inaperçu.
N'hésitez pas à explorer davantage les capacités de Soda sur notre site web et dans notre documentation. Si vous souhaitez approfondir, vous pouvez toujours demander une démonstration pour une discussion en face à face sur la manière dont Soda peut transformer vos processus de qualité des données.
Les institutions financières, y compris les banques, les assureurs, les prêteurs hypothécaires, les investisseurs et les créanciers, dépendent fortement d'informations précises, complètes et opportunes pour gérer des processus commerciaux critiques et prendre des décisions éclairées.
Une mauvaise qualité des données peut perturber les rapports financiers, les approbations de prêts, la détection de la fraude, la gestion des risques de crédit et les évaluations des risques, provoquant des perturbations importantes qui sapent la crédibilité des institutions et mettent en danger la confiance des clients.
Par conséquent, maintenir une haute qualité des données dans le secteur financier n'est pas seulement une bonne pratique, c'est également une exigence réglementaire. La norme numéro 239 du Comité de Bâle sur le contrôle bancaire (BCBS 239) souligne l'importance pour les banques d'améliorer leurs capacités d'agrégation de données de risque et leurs pratiques de rapport de risque interne. La conformité à BCBS 239 garantit que les institutions financières peuvent rapporter les risques avec précision et rapidité, améliorant ainsi la stabilité du système financier.
Par conséquent, la mise en œuvre de tests de qualité des données robustes en amont du flux de données, également connue sous le terme de tests "shift-left", permet aux organisations de détecter et de résoudre les problèmes de manière proactive, minimisant ainsi les conséquences en aval.
Dans cet article de blog, nous passerons en revue comment intégrer Soda dans un flux de données financières pour garantir la qualité des données, la conformité et la précision des rapports de risque. Nous aborderons comment configurer les vérifications Soda, automatiser les validations et conserver une piste d'audit pour garantir l'exactitude, la complétude et la ponctualité des transactions.
Le Pouvoir de l'Automatisation pour le Secteur Financier
Les vérifications manuelles traditionnelles sont chronophages, sujettes aux erreurs humaines et inadaptées aux processus financiers modernes à grande échelle. Avec des milliers de transactions par seconde, les institutions financières nécessitent une solution automatisée et évolutive pour garantir l'intégrité des données et la conformité réglementaire.
Sans automatisation, les institutions feront face à :
❌ un retard dans les rapports de risque qui augmente la vulnérabilité aux activités frauduleuses ;
❌ une validation de données incohérente qui peut mener à des analyses financières inexactes ;
❌ des coûts opérationnels élevés en raison des nécessités de ressources importantes des vérifications manuelles.
Pour atténuer ces risques, les organisations doivent intégrer des vérifications robustes de la qualité des données dans leurs canaux de données. Soda offre une solution puissante et automatisée pour la gestion de la qualité des données. Ses outils intégrés de test et d'observabilité sont capables de scanner les données financières pour détecter les anomalies, les valeurs manquantes et les incohérences en temps réel.
Cela garantit que les organisations peuvent :
✅ appliquer la conformité BCBS 239 avec des vérifications automatisées pour l'exactitude, la complétude et la rapidité ;
✅ empêcher les données de mauvaise qualité d'atteindre les systèmes en aval, réduisant ainsi les erreurs coûteuses ;
✅ mettre en place des alertes proactives pour résoudre les problèmes avant qu'ils ne s'aggravent.
Plutôt que de revoir manuellement les journaux de transactions, une institution financière peut configurer des vérifications Soda pour détecter les transactions en double avant qu'elles ne touchent les comptes des clients, surveiller les transactions manquantes ou retardées pour éviter les écarts de reporting, et signaler les schémas inhabituels, permettant ainsi aux équipes de détection de fraude d'intervenir plus rapidement.
Dans les sections suivantes, nous verrons comment cela fonctionne en pratique.
Configurer les Vérifications Automatisées avec Soda
L'automatisation des vérifications de la qualité des données est cruciale dans l'industrie financière car la précision des données a un impact direct sur la prise de décision, la conformité réglementaire et la confiance des clients.
Soda vous permet de surveiller proactivement vos données et d'identifier les problèmes potentiels en amont du pipeline. Il peut s'intégrer de manière transparente dans vos flux de travail existants tout en offrant une visibilité complète sur l'état de santé de vos données.
En suivant ce guide étape par étape, vous découvrirez comment déployer rapidement et intégrer Soda dans votre flux de données financières, rationaliser les efforts de conformité et réduire la supervision manuelle.
Choisir le Modèle de Déploiement Approprié
Pour évaluer la qualité de vos données avec Soda, vous devrez choisir un modèle de déploiement qui vous permet d'établir des connexions avec vos sources de données. Vous définirez ensuite les vérifications nécessaires de la qualité des données et exécuterez des analyses pour vous assurer qu'elles sont effectuées efficacement.
Cet article se concentrera sur l'utilisation de Soda Library, un outil Python qui vous donne un contrôle direct sur les vérifications de la qualité des données au sein de votre pipeline. Vous pourrez ensuite vérifier les résultats dans votre interface en ligne de commande (CLI) ainsi que dans votre compte Soda Cloud.
Vous pouvez également connecter vos sources de données directement à Soda Cloud, en utilisant une configuration de type SaaS où vous gérez la qualité des données sans aucun codage. Pour des conseils plus détaillés sur le choix du modèle de déploiement approprié, reportez-vous au guide de configuration de Soda.
Configuration Étape par Étape avec Soda Library
Vous pouvez intégrer Soda à plusieurs Sources de Données différentes, mais pour cet article, nous vous montrerons comment configurer Soda Library pour automatiser vos vérifications de la qualité des données en utilisant MySQL.
En suivant ces étapes, vous serez en mesure de configurer des connexions à votre base de données, de définir des vérifications critiques de la qualité des données, et de commencer à surveiller la qualité des données en temps réel.
Les objectifs techniques de cet article sont :
1. Installer Soda Library en utilisant votre CLI.
2. Configurer les fichiers YAML pour :
Se connecter à vos sources de données pour exécuter des analyses de qualité.
Lier votre configuration à Soda Cloud pour valider votre licence et voir les métriques de qualité des données.
Créer et personnaliser les vérifications de la qualité des données en fonction de vos besoins.
Après avoir terminé cette configuration, vous pourrez intégrer les vérifications de la qualité des données de Soda dans votre pipeline, garantissant que vos données financières restent fiables et conformes.
C'est une configuration simple dans laquelle vous installez Soda Library localement et la connectez à Soda Cloud via des clés API. Commençons.
1. Création de Compte et de Clés API
Étape 1 : Rejoindre Soda Cloud
Pour commencer, inscrivez-vous pour un compte Soda Cloud pour un essai gratuit de 45 jours.
La création de compte en libre-service pour Soda Cloud est temporairement suspendue car nous préparons la disponibilité générale de plusieurs mises à jour majeures. Si vous souhaitez essayer Soda Cloud en attendant, veuillez programmer un appel avec notre équipe d'experts, discutez de votre cas d'utilisation et commencez.
Pourquoi créer un compte ? Parce que votre Soda Library doit communiquer avec un compte Soda via des clés API pour valider votre licence ou essai gratuit.
Étape 2 : Générer des Clés API
Une fois votre compte créé, créez vos clés API dans Soda Cloud :
Allez à votre avatar > Profil, puis accédez à l'onglet Clés API.
Cliquez sur l'icône plus pour générer de nouvelles clés API
Copiez la configuration syntaxique de l'API soda_cloud et conservez-la en lieu sûr. Vous en aurez besoin pour configurer le fichier de connexion.
2. Configuration de Soda à la Source de Données
Maintenant, connectons Soda Library à MySQL. Voici comment vous pouvez le faire.
Étape 1 : Installer les Dépendances
Ouvrez votre environnement de développement préféré (IDE) et assurez-vous que votre version de Python est ≤ 3.10 et pip est ≥ 21.0.
Étape 2 : Configurer le Répertoire du Projet
Créez un nouveau répertoire pour votre projet Soda dans votre environnement local et accédez-y via votre CLI. Votre structure de projet devrait ressembler à ceci :
your_project/ │── soda-env/ │ ├── configuration.yml │ ├── checks.yml
Étape 3 : Créer un Environnement Virtuel
Il est préférable d'installer Soda Library dans un environnement virtuel. Pour en créer un, exécutez les commandes suivantes :
py -3.10 -m venv soda-env .\soda-env\Scripts\Activate
Étape 4 : Installer Soda Library pour MySQL
Étant donné que nous utilisons MySQL, installez le package requis :
pip install soda-mysql
Si vous utilisez une source de données différente, assurez-vous d'installer le package correspondant. Vous pouvez trouver une liste des packages disponibles dans notre documentation.
Étape 5 : Configurer le Fichier de Configuration
Dans votre répertoire de projet Soda, créez un fichier nommé configuration.yml. Collez les détails de connexion suivants dans le fichier, en remplaçant les valeurs par vos informations réelles :
data_source your_database_name: type: mysql host: 127.0.0.1 #or 'root' or any host name you're using username: #mysql_username password: #mysql_password database: #your_database_name soda_cloud: host: cloud.soda.io api_key_id: #a4ac173d---c29 api_key_secret: #V13xLLEDG---flTw
Notez que c'est le fichier où vous devez passer votre syntaxe de configuration API.
Assurez-vous que les informations d'identification et l'information hôte sont exactes et que l'utilisateur dispose des permissions nécessaires pour accéder à la base de données. Pour des instructions plus détaillées, consultez la documentation de Soda sur la connexion à MySQL.
Vous pouvez également utiliser des variables système pour passer des informations sensibles (mots de passe et clés API) si vous le préférez. Pour plus d'informations à ce sujet, consultez notre documentation sur Comment Installer Soda Library.
Étape 6 : Tester la Connexion
Enregistrez le fichier configuration.yml et exécutez ensuite la commande suivante pour tester si Soda peut se connecter avec succès à votre base de données :
soda test-connection -d your_database_name -c configuration.yml
Si la connexion réussit, vous devriez voir un résultat similaire à :
Soda Core 3.5.0 Successfully connected to 'your_database_name'. Connection 'your_database_name' is valid
Une fois cette étape terminée, votre agent hébergé par Soda établira des connexions sécurisées avec Soda Cloud, vous permettant d'implémenter des vérifications automatisées de la qualité des données dans tout schéma à l'intérieur de votre base de données.
Cas d'Utilisation : Surveillance de la Qualité des Données Financières
Avec Soda Library installé et connecté à votre source de données, nous sommes prêts à passer à la définition de vos vérifications de la qualité des données et à l'exécution de scans automatisés sur vos données. Mais d'abord, examinons quelques principes clés pour comprendre quelles vérifications sont plus pertinentes pour notre gestion de la qualité des données financières.
Principes Clés pour la Gestion de la Qualité des Données Financières
En adhérant à quelques principes clés, vous pourrez vous assurer que vos données financières sont exactes, cohérentes et sécurisées. Voici quelques principes importants que les institutions financières devraient garder à l'esprit pour garantir une qualité de données optimale :
Exactitude et Cohérence : Des décisions financières fiables nécessitent des données à la fois précises et cohérentes. De petites erreurs ou incohérences peuvent entraîner des erreurs coûteuses.
Complétude et Pertinence : Les données incomplètes ou manquantes peuvent avoir un impact significatif sur les évaluations de risque et les opérations commerciales dans leur ensemble.
Actualité et Fraîcheur : Les données financières doivent être à jour. Des retards dans la mise à jour de vos données peuvent entraîner des évaluations financières incorrectes et des pénalités réglementaires potentielles.
Normalisation et Gouvernance : Des directives claires et des pratiques normalisées aident à éviter les incohérences et la confusion. Avec une gouvernance appropriée, vous pouvez garantir l'intégrité des données entre les départements et les systèmes.
Sécurité des Données et Conformité : Les données financières sont sensibles et leur protection est essentielle. La mise en œuvre d'un contrôle d'accès basé sur les rôles, le cryptage et les pistes d'audit garantit que seuls les utilisateurs autorisés ont accès aux données, les protégeant contre les violations, la fraude ou les mauvais usages.
Automatisation et Surveillance Continue : L'automatisation accélère les vérifications de la qualité des données, vous permettant de détecter les anomalies, les duplications et les incohérences en temps réel. La surveillance continue assure que les problèmes de qualité des données sont rapidement identifiés et résolus, conduisant à un système financier plus transparent et efficace.
En suivant ces principes, vous pouvez non seulement respecter les exigences réglementaires, mais aussi instaurer la confiance dans vos données financières, vous permettant ainsi de prendre de meilleures décisions et d'évoluer dans un environnement plus sécurisé.
Dans les prochaines étapes, nous vous guiderons à travers la création et la configuration de ces vérifications pour surveiller la qualité des données en temps réel. Mais avant cela, nous allons créer un jeu de données d'exemple.
1. Création d'un Jeu de Données Exemple
Pour surveiller efficacement la qualité des données financières, nous allons créer une table transactions qui simule des données financières du monde réel. Cette table inclura des problèmes de qualité des données intentionnels pour démontrer comment les détecter et les résoudre en utilisant les vérifications Soda.
Étape 1 : Configurer la Base de Données et la Table
Commencez par créer une nouvelle base de données nommée soda_trial et définir la table transactions avec les colonnes appropriées :
CREATE DATABASE soda_trial; USE soda_trial; CREATE TABLE transactions ( transaction_id INT PRIMARY KEY, account_number VARCHAR(20), transaction_date DATE, amount DECIMAL(15,2), currency CHAR(3), transaction_type VARCHAR(10) )
Étape 2 : Remplir la Table avec des Données d'Exemple
Ensuite, insérez des enregistrements exemples dans la table, incluant des problèmes de qualité des données intentionnels pour tester l'efficacité des vérifications Soda :
INSERT INTO transactions (transaction_id, account_number, transaction_date, amount, currency, transaction_type) VALUES (1, 'ACC1234567', '2025-03-25', 1000.00, 'USD', 'Credit'), (2, 'ACC1234567', '2025-03-25', 1000.00, 'USD', 'Credit'), (3, 'ACC1234568', '2025-03-26', -500.00, 'USD', 'Debit'), (4, 'ACC1234569','2025-03-27', 750.00, NULL, 'Credit'), (5, 'ACC1234570', '2025-03-28', 200.00, 'GBP', 'Trans'), (6, 'AC1234571', '2025-03-29', 300.00, 'EUR', 'Debit')
2. Configuration des Vérifications Soda
Les scans Soda sont conçus pour effectuer des vérifications de la qualité des données sur votre source de données, aidant à identifier les données non valides, manquantes ou inattendues. Avec le jeu de données exemple en place, nous pouvons maintenant définir les vérifications de la qualité des données en utilisant SodaCL (Soda Checks Language) pour identifier et résoudre les problèmes introduits.
Étape 1 : Comprendre les Concepts Clés
Tout d'abord, assurons-nous de bien comprendre certains concepts importants :
SodaCL : un langage basé sur YAML qui comprend plus de 25 métriques intégrées que vous pouvez utiliser pour écrire des vérifications, mais vous avez également l'option d'écrire vos propres requêtes SQL ou expressions.
Vérification Soda : une expression Python qui vérifie les métriques pendant un scan Soda pour voir si elles correspondent aux normes que vous avez fixées pour un seuil.
Métrique : Une propriété ou une mesure des données au sein de votre ensemble de données.
Seuil : La valeur ou l'intervalle qu'une métrique est comparée à dans une vérification.
Scan Soda : exécute plusieurs vérifications contre un ou plusieurs ensembles de données présents dans la base deonnées à laquelle vous êtes connecté à Soda.
Pour une liste complète des métriques et vérifications de SodaCL, consultez la Documentation de SodaCL.
Étape 2 : Conception des Vérifications Efficaces de la Qualité des Données
Maintenant, examinons certains des principes que nous avons vus ci-dessus. Nous avons choisi quelques dimensions cruciales pour les données financières et leurs problèmes associés afin de pouvoir créer nos vérifications en utilisant SodaCL.
Exactitude et Cohérence
Transactions en Double : Les entrées en double d'IDs de transactions peuvent gonfler les métriques financières et fausser les analyses.
Montants de Transaction Invalides : Les montants de transaction qui tombent en dehors des plages attendues peuvent indiquer des erreurs de saisie des données ou des fraudes.
Complétude et Pertinence
Dates ou Numéros de Compte de Transaction Manquants : Les enregistrements incomplets limitent la capacité à suivre et à rapprocher les transactions avec précision, compromettant la communication financière et posant des défis dans les processus d'audit.
Actualité et Fraîcheur
Transactions Obsolètes : Les mises à jour retardées peuvent entraîner des évaluations financières inexactes et des pénalités réglementaires potentielles.
Normalisation et Gouvernance
Types de Transactions ou Codes Monétaires Non Standard : Les formats de données incohérents peuvent entraîner des erreurs d'interprétation et de traitement.
Automatisation et Surveillance Continue
Manque de Vérifications Régulières de la Qualité des Données : Sans surveillance automatisée, les problèmes de données peuvent rester non détectés jusqu'à ce qu'ils causent des problèmes importants.
La mise en œuvre des vérifications Soda permet une identification proactive et la résolution de ces problèmes de qualité des données et d'autres, garantissant des données financières fiables pour une prise de décision éclairée. Alors, voyons cela en pratique.
Étape 3 : Mise en Œuvre des Vérifications
Soda prépare un scan en utilisant des vérifications et des configurations de connexion à la source de données, qu'il exécute ensuite contre des ensembles de données pour extraire des métadonnées et évaluer la qualité des données.
Pour cela, vous devrez aller dans votre répertoire de projet et créer un fichier checks.yml pour définir les vérifications pour notre ensemble de données. Nous nous concentrerons sur plusieurs dimensions clés de la qualité des données pertinentes pour les données financières.
Voici un code complet commenté que vous pouvez appliquer à notre base de données de test. Il définit un ensemble de vérifications de la qualité des données pour notre table transactions :
Il vérifie que les transactions ont des IDs uniques, que les montants sont valides et formatés correctement, et que les numéros de compte suivent un modèle spécifique.
Les vérifications de complétude assurent qu'il n'y a pas de valeurs manquantes dans les champs clés, tandis que les vérifications de fraîcheur confirment que les données de transactions sont mises à jour quotidiennement.
Les règles de normalisation appliquent des codes monétaires et des types de transaction valides.
Les mesures de conformité incluent des limites de nombre de lignes, et la validation du schéma détecte les changements non autorisés dans les colonnes nécessaires et les types de données.
Ces règles soutiennent la surveillance automatisée et continue de la qualité des données.
checks for transactions: # Remember to chose your table here # Accuracy and Consistency - duplicate_count(transaction_id) = 0 # Detect duplicate transaction_id entries - duplicate_count(account_number, amount, transaction_type): warn: when > 0 # ensure there are no duplicate transactions - invalid_count(amount) = 0: valid min: 0.01 # Ensure amount values are within a valid range valid format: decimal # Ensure formatting is consistent - invalid_count(account_number) = 0: valid regex: '^ACC.*' # Completeness # Verify no missing values - missing_count(transaction_id) = 0 - missing_count(account_number) = 0 - missing_count(transaction_date) = 0 - missing_count(amount) = 0 - missing_count(currency) = 0 - missing_count(transaction_type) = 0 # Timeliness and Freshness - freshness(transaction_date) < 1d # Assess that data is refreshed daily # Standardization and Governance - invalid_count(currency) = 0: valid values: ['USD', 'EUR', 'GBP'] # Add all acceptable currency codes invalid regex: '[^A-Z]{3}' # Ensure formatting is consistent - invalid_count(transaction_type) = 0: valid values: ['Credit', 'Debit', 'Transfer'] # Data Security and Compliance # Monitor that the table does not exceed a specified number of rows # to manage data volume and compliance. - row_count < 1000000 # Automation and Continuous Monitoring # Define the expected schema to detect unauthorized changes - schema: fail: when required column missing: - transaction_id - account_number - transaction_date - amount - currency - transaction_type when wrong column type: transaction_id: int account_number: varchar transaction_date: date amount: decimal currency: char transaction_type
Si vous avez besoin de scanner différents ensembles de données, n'oubliez pas de créer un fichier de vérification différent pour chacun (dans ce cas, chaque table de votre base de données MySQL).
3. Intégrer Soda dans Votre Pipeline
Pour automatiser les vérifications de la qualité des données au sein de vos flux de travail ETL (Extract, Transform, Load), intégrez une étape qui exécute des scans Soda après l'ingestion des données. Cette intégration garantit que la qualité des données est évaluée avant tout traitement ultérieur, permettant une détection précoce et la résolution des problèmes.
Utilisez la commande suivante pour exécuter un scan Soda sur votre ensemble de données :
soda scan -d soda_trial -c configuration.yml checks.yml
Dans cette commande :
-d soda_trialspécifie le nom de la source de données tel que défini dans votre fichier de configuration.-c configuration.ymldésigne votre fichier de configuration Soda contenant les détails de connexion.checks.ymlest le fichier où vous avez défini vos vérifications de la qualité des données en utilisant SodaCL.
4. Examiner les résultats du scan
En intégrant les scans Soda dans votre pipeline, vous établissez une approche proactive de la qualité des données, garantissant que les problèmes sont identifiés et résolus rapidement, assurant ainsi l'intégrité de vos données tout au long de leur cycle de vie.
Après un scan, chaque vérification aboutit à l'un des trois états par défaut :
passe : les données répondent aux seuils de qualité spécifiés.
échoue : les données ne respectent pas les seuils de qualité spécifiés.
erreur : il y a un problème avec la syntaxe ou l'exécution de la vérification.
État supplémentaire :
avertissement : un état configurable qui vous alerte sur des problèmes potentiels sans marquer la vérification comme un échec complet. Voir plus dans Ajouter des configurations d'alerte. Exemple d'avertissement de notre code :
- duplicate_count(account_number, amount, transaction_type): warn: when > 0
Lorsque les vérifications échouent, elles révèlent les données de basse qualité et fournissent des résultats qui vous aident à enquêter et résoudre les problèmes de qualité.
Vous pouvez examiner les résultats de vos scans Soda via deux canaux principaux :
1. Interface en ligne de commande (CLI) : À l'exécution d'un scan, Soda fournit un retour d'information immédiat dans le terminal, affichant les résultats de chaque vérification. Cette perspicacité en temps réel permet des évaluations rapides et des actions immédiates si nécessaire.
Soda Core 3.5.0 Sending failed row samples to Soda Cloud Sending failed row samples to Soda Cloud Sending failed row samples to Soda Cloud Sending failed row samples to Soda Cloud Sending failed row samples to Soda Cloud Scan summary: 10/15 checks PASSED: transactions in soda_trial row_count < 1000000 [PASSED] Schema Check [PASSED] duplicate_count(transaction_id) = 0 [PASSED] missing_count(transaction_id) = 0 [PASSED] missing_count(amount) = 0 [PASSED] missing_count(account_number) = 0 [PASSED] missing_count(transaction_date) = 0 [PASSED] freshness(transaction_date) < 1d [PASSED] invalid_count(currency) = 0 [PASSED] missing_count(transaction_type) = 0 [PASSED] 1/15 checks WARNED: transactions in soda_trial duplicate_count(account_number, amount, transaction_type) warn when > 0 [WARNED] check_value: 1 4/15 checks FAILED: transactions in soda_trial invalid_count(amount) = 0 [FAILED] check_value: 1 invalid_count(account_number) = 0 [FAILED] check_value: 1 missing_count(currency) = 0 [FAILED] check_value: 1 invalid_count(transaction_type) = 0 [FAILED] check_value: 1 Oops! 4 failures. 1 warning. 0 errors. 10 pass. Sending results to Soda Cloud
Les vérifications de schéma visent principalement à valider les aspects structurels de vos données, tels que la présence, l'absence et la position des colonnes, ainsi que les types de données qui leur sont affectés. Cependant, les vérifications de schéma n'incluent pas l'application de formats de données ou de contraintes spécifiques, comme s'assurer que les valeurs numériques respectent une précision décimale spécifique.
2. Soda Cloud : Pour un examen plus détaillé et collaboratif, dans Soda Cloud, vous pouvez :
Visualiser les résultats du scan via des tableaux de bord intuitifs.
Surveiller les tendances de la qualité des données au fil du temps.
Recevoir des alertes pour les vérifications échouées ou les anomalies.
Collaborer avec les membres de votre équipe pour résoudre les problèmes de qualité des données.
Surveillance et Alerte pour la Qualité des Données
Soda permet la surveillance et l'alerte en temps réel, tenant les parties prenantes informées des problèmes de qualité des données. Configurez Soda pour envoyer des alertes à Slack, Jira ou MS Teams lorsque des vérifications échouent.
Pour activer les alertes, définissez des canaux de notification dans votre configuration Soda et spécifiez les conditions sous lesquelles elles doivent être déclenchées. Cette approche proactive garantit que les problèmes de qualité des données sont résolus rapidement, préservant l'intégrité de vos actifs de données.
Connexion avec MS Teams
Si vous y êtes autorisé, vous pouvez intégrer votre espace de travail Microsoft Teams dans Soda Cloud afin qu'il puisse interagir avec des individus et des chaînes.
Utilisez l'intégration Microsoft Teams pour :
Envoyer des alertes à Microsoft Teams pour les résultats de vérification (notifications d'avertissement ou d'échec).
Créer un canal Teams dédié pour enquêter sur les vérifications échouées et collaborer à la résolution des incidents.
Suivre les Discussions Soda pour une collaboration en temps réel sur la qualité des données avec votre équipe.
Pour configurer l'intégration :
1. Accéder aux Intégrations Soda Cloud : Connectez-vous à votre compte Soda Cloud, allez à votre avatar > Paramètres de l'organisation, et sélectionnez l'onglet Intégrations. Cliquez sur l'icône + dans le coin supérieur droit pour ajouter une nouvelle intégration.
2. Sélectionner MS Teams : Dans la boîte de dialogue Ajouter une Intégration, choisissez Microsoft Teams. Vous serez alors guidé à travers une configuration de workflow.
3. Créer un Workflow : Suivez le guide de configuration qui vous indique de vous connecter à votre compte MS Teams. Vous devrez créer un workflow dans Teams (voir la documentation de Microsoft pour "Créer un workflow à partir d'un canal dans Teams") en utilisant le modèle fourni pour poster sur un canal lorsqu'une requête de webhook est reçue.
4. Compléter l'Intégration : Une fois le workflow créé avec succès, copiez l'URL générée et revenez à Soda Cloud pour terminer les étapes guidées. Au cours de ce processus, vous configurerez les portées de l'intégration :
Périmètre de Notification d'Alerte : Permettre à Soda Cloud d'envoyer des notifications d'alertes (pour des résultats de vérification avertis et échoués) directement à votre canal MS Teams choisi. Cela permet aux utilisateurs de sélectionner MS Teams comme destination pour des alertes de vérification individuelles ou groupées.
Périmètre d'Incident : Configurez des notifications pour la création d'un nouvel incident dans Soda Cloud. Ce périmètre affichera un lien externe vers votre canal MS Teams dans les Détails de l'Incident, dirigeant votre équipe vers l'espace approprié pour résoudre l'incident.
Périmètre de Discussions : Configurez Soda Cloud pour publier sur un canal Teams spécifique chaque fois qu'une discussion est initiée ou modifiée. Cela facilite la collaboration continue sur la qualité des données au sein de votre organisation.
Avec l'intégration en place, Soda Cloud peut automatiquement envoyer des notifications à vos canaux MS Teams, garantissant que les alertes, les mises à jour d'incidents et les discussions collaboratives sont facilement partagées avec votre équipe, permettant une réponse rapide et une résolution efficace des problèmes.
Consultez notre documentation pour en savoir plus sur la Intégration avec MS Teams, et aussi sur comment Organiser les résultats, configurer des alertes, enquêter sur les problèmes.
Conclusion - Bonnes Pratiques pour Maintenir la Qualité des Données
Un pipeline de données financières bien architecturé, combiné à une validation et une surveillance automatisées, assure que les données sont constamment précises, complètes et fiables. La beauté de Soda Library réside dans sa capacité à s'intégrer directement dans votre pipeline, vous permettant d'automatiser les vérifications de la qualité des données à toutes les étapes, de l'ingestion au traitement.
En suivant ce guide, vous pouvez créer une solution efficace et évolutive qui permet à votre équipe d'assurer la qualité des données en temps réel tout en respectant les normes réglementaires telles que BCBS 239.
Pour l'avenir, restez à l'écoute des prochains articles de blog qui exploreront des améliorations pour votre pipeline, telles que :
Autonomiser les Utilisateurs Métier : Découvrez comment permettre aux utilisateurs métier de proposer et d'appliquer leurs propres règles métier directement dans votre pipeline.
Surveillance Automatisée des Métriques : Découvrez comment configurer la surveillance automatisée des métriques pour identifier des problèmes cachés à grande échelle, garantissant qu'aucun problème de qualité des données ne passe inaperçu.
N'hésitez pas à explorer davantage les capacités de Soda sur notre site web et dans notre documentation. Si vous souhaitez approfondir, vous pouvez toujours demander une démonstration pour une discussion en face à face sur la manière dont Soda peut transformer vos processus de qualité des données.
Les institutions financières, y compris les banques, les assureurs, les prêteurs hypothécaires, les investisseurs et les créanciers, dépendent fortement d'informations précises, complètes et opportunes pour gérer des processus commerciaux critiques et prendre des décisions éclairées.
Une mauvaise qualité des données peut perturber les rapports financiers, les approbations de prêts, la détection de la fraude, la gestion des risques de crédit et les évaluations des risques, provoquant des perturbations importantes qui sapent la crédibilité des institutions et mettent en danger la confiance des clients.
Par conséquent, maintenir une haute qualité des données dans le secteur financier n'est pas seulement une bonne pratique, c'est également une exigence réglementaire. La norme numéro 239 du Comité de Bâle sur le contrôle bancaire (BCBS 239) souligne l'importance pour les banques d'améliorer leurs capacités d'agrégation de données de risque et leurs pratiques de rapport de risque interne. La conformité à BCBS 239 garantit que les institutions financières peuvent rapporter les risques avec précision et rapidité, améliorant ainsi la stabilité du système financier.
Par conséquent, la mise en œuvre de tests de qualité des données robustes en amont du flux de données, également connue sous le terme de tests "shift-left", permet aux organisations de détecter et de résoudre les problèmes de manière proactive, minimisant ainsi les conséquences en aval.
Dans cet article de blog, nous passerons en revue comment intégrer Soda dans un flux de données financières pour garantir la qualité des données, la conformité et la précision des rapports de risque. Nous aborderons comment configurer les vérifications Soda, automatiser les validations et conserver une piste d'audit pour garantir l'exactitude, la complétude et la ponctualité des transactions.
Le Pouvoir de l'Automatisation pour le Secteur Financier
Les vérifications manuelles traditionnelles sont chronophages, sujettes aux erreurs humaines et inadaptées aux processus financiers modernes à grande échelle. Avec des milliers de transactions par seconde, les institutions financières nécessitent une solution automatisée et évolutive pour garantir l'intégrité des données et la conformité réglementaire.
Sans automatisation, les institutions feront face à :
❌ un retard dans les rapports de risque qui augmente la vulnérabilité aux activités frauduleuses ;
❌ une validation de données incohérente qui peut mener à des analyses financières inexactes ;
❌ des coûts opérationnels élevés en raison des nécessités de ressources importantes des vérifications manuelles.
Pour atténuer ces risques, les organisations doivent intégrer des vérifications robustes de la qualité des données dans leurs canaux de données. Soda offre une solution puissante et automatisée pour la gestion de la qualité des données. Ses outils intégrés de test et d'observabilité sont capables de scanner les données financières pour détecter les anomalies, les valeurs manquantes et les incohérences en temps réel.
Cela garantit que les organisations peuvent :
✅ appliquer la conformité BCBS 239 avec des vérifications automatisées pour l'exactitude, la complétude et la rapidité ;
✅ empêcher les données de mauvaise qualité d'atteindre les systèmes en aval, réduisant ainsi les erreurs coûteuses ;
✅ mettre en place des alertes proactives pour résoudre les problèmes avant qu'ils ne s'aggravent.
Plutôt que de revoir manuellement les journaux de transactions, une institution financière peut configurer des vérifications Soda pour détecter les transactions en double avant qu'elles ne touchent les comptes des clients, surveiller les transactions manquantes ou retardées pour éviter les écarts de reporting, et signaler les schémas inhabituels, permettant ainsi aux équipes de détection de fraude d'intervenir plus rapidement.
Dans les sections suivantes, nous verrons comment cela fonctionne en pratique.
Configurer les Vérifications Automatisées avec Soda
L'automatisation des vérifications de la qualité des données est cruciale dans l'industrie financière car la précision des données a un impact direct sur la prise de décision, la conformité réglementaire et la confiance des clients.
Soda vous permet de surveiller proactivement vos données et d'identifier les problèmes potentiels en amont du pipeline. Il peut s'intégrer de manière transparente dans vos flux de travail existants tout en offrant une visibilité complète sur l'état de santé de vos données.
En suivant ce guide étape par étape, vous découvrirez comment déployer rapidement et intégrer Soda dans votre flux de données financières, rationaliser les efforts de conformité et réduire la supervision manuelle.
Choisir le Modèle de Déploiement Approprié
Pour évaluer la qualité de vos données avec Soda, vous devrez choisir un modèle de déploiement qui vous permet d'établir des connexions avec vos sources de données. Vous définirez ensuite les vérifications nécessaires de la qualité des données et exécuterez des analyses pour vous assurer qu'elles sont effectuées efficacement.
Cet article se concentrera sur l'utilisation de Soda Library, un outil Python qui vous donne un contrôle direct sur les vérifications de la qualité des données au sein de votre pipeline. Vous pourrez ensuite vérifier les résultats dans votre interface en ligne de commande (CLI) ainsi que dans votre compte Soda Cloud.
Vous pouvez également connecter vos sources de données directement à Soda Cloud, en utilisant une configuration de type SaaS où vous gérez la qualité des données sans aucun codage. Pour des conseils plus détaillés sur le choix du modèle de déploiement approprié, reportez-vous au guide de configuration de Soda.
Configuration Étape par Étape avec Soda Library
Vous pouvez intégrer Soda à plusieurs Sources de Données différentes, mais pour cet article, nous vous montrerons comment configurer Soda Library pour automatiser vos vérifications de la qualité des données en utilisant MySQL.
En suivant ces étapes, vous serez en mesure de configurer des connexions à votre base de données, de définir des vérifications critiques de la qualité des données, et de commencer à surveiller la qualité des données en temps réel.
Les objectifs techniques de cet article sont :
1. Installer Soda Library en utilisant votre CLI.
2. Configurer les fichiers YAML pour :
Se connecter à vos sources de données pour exécuter des analyses de qualité.
Lier votre configuration à Soda Cloud pour valider votre licence et voir les métriques de qualité des données.
Créer et personnaliser les vérifications de la qualité des données en fonction de vos besoins.
Après avoir terminé cette configuration, vous pourrez intégrer les vérifications de la qualité des données de Soda dans votre pipeline, garantissant que vos données financières restent fiables et conformes.
C'est une configuration simple dans laquelle vous installez Soda Library localement et la connectez à Soda Cloud via des clés API. Commençons.
1. Création de Compte et de Clés API
Étape 1 : Rejoindre Soda Cloud
Pour commencer, inscrivez-vous pour un compte Soda Cloud pour un essai gratuit de 45 jours.
La création de compte en libre-service pour Soda Cloud est temporairement suspendue car nous préparons la disponibilité générale de plusieurs mises à jour majeures. Si vous souhaitez essayer Soda Cloud en attendant, veuillez programmer un appel avec notre équipe d'experts, discutez de votre cas d'utilisation et commencez.
Pourquoi créer un compte ? Parce que votre Soda Library doit communiquer avec un compte Soda via des clés API pour valider votre licence ou essai gratuit.
Étape 2 : Générer des Clés API
Une fois votre compte créé, créez vos clés API dans Soda Cloud :
Allez à votre avatar > Profil, puis accédez à l'onglet Clés API.
Cliquez sur l'icône plus pour générer de nouvelles clés API
Copiez la configuration syntaxique de l'API soda_cloud et conservez-la en lieu sûr. Vous en aurez besoin pour configurer le fichier de connexion.
2. Configuration de Soda à la Source de Données
Maintenant, connectons Soda Library à MySQL. Voici comment vous pouvez le faire.
Étape 1 : Installer les Dépendances
Ouvrez votre environnement de développement préféré (IDE) et assurez-vous que votre version de Python est ≤ 3.10 et pip est ≥ 21.0.
Étape 2 : Configurer le Répertoire du Projet
Créez un nouveau répertoire pour votre projet Soda dans votre environnement local et accédez-y via votre CLI. Votre structure de projet devrait ressembler à ceci :
your_project/ │── soda-env/ │ ├── configuration.yml │ ├── checks.yml
Étape 3 : Créer un Environnement Virtuel
Il est préférable d'installer Soda Library dans un environnement virtuel. Pour en créer un, exécutez les commandes suivantes :
py -3.10 -m venv soda-env .\soda-env\Scripts\Activate
Étape 4 : Installer Soda Library pour MySQL
Étant donné que nous utilisons MySQL, installez le package requis :
pip install soda-mysql
Si vous utilisez une source de données différente, assurez-vous d'installer le package correspondant. Vous pouvez trouver une liste des packages disponibles dans notre documentation.
Étape 5 : Configurer le Fichier de Configuration
Dans votre répertoire de projet Soda, créez un fichier nommé configuration.yml. Collez les détails de connexion suivants dans le fichier, en remplaçant les valeurs par vos informations réelles :
data_source your_database_name: type: mysql host: 127.0.0.1 #or 'root' or any host name you're using username: #mysql_username password: #mysql_password database: #your_database_name soda_cloud: host: cloud.soda.io api_key_id: #a4ac173d---c29 api_key_secret: #V13xLLEDG---flTw
Notez que c'est le fichier où vous devez passer votre syntaxe de configuration API.
Assurez-vous que les informations d'identification et l'information hôte sont exactes et que l'utilisateur dispose des permissions nécessaires pour accéder à la base de données. Pour des instructions plus détaillées, consultez la documentation de Soda sur la connexion à MySQL.
Vous pouvez également utiliser des variables système pour passer des informations sensibles (mots de passe et clés API) si vous le préférez. Pour plus d'informations à ce sujet, consultez notre documentation sur Comment Installer Soda Library.
Étape 6 : Tester la Connexion
Enregistrez le fichier configuration.yml et exécutez ensuite la commande suivante pour tester si Soda peut se connecter avec succès à votre base de données :
soda test-connection -d your_database_name -c configuration.yml
Si la connexion réussit, vous devriez voir un résultat similaire à :
Soda Core 3.5.0 Successfully connected to 'your_database_name'. Connection 'your_database_name' is valid
Une fois cette étape terminée, votre agent hébergé par Soda établira des connexions sécurisées avec Soda Cloud, vous permettant d'implémenter des vérifications automatisées de la qualité des données dans tout schéma à l'intérieur de votre base de données.
Cas d'Utilisation : Surveillance de la Qualité des Données Financières
Avec Soda Library installé et connecté à votre source de données, nous sommes prêts à passer à la définition de vos vérifications de la qualité des données et à l'exécution de scans automatisés sur vos données. Mais d'abord, examinons quelques principes clés pour comprendre quelles vérifications sont plus pertinentes pour notre gestion de la qualité des données financières.
Principes Clés pour la Gestion de la Qualité des Données Financières
En adhérant à quelques principes clés, vous pourrez vous assurer que vos données financières sont exactes, cohérentes et sécurisées. Voici quelques principes importants que les institutions financières devraient garder à l'esprit pour garantir une qualité de données optimale :
Exactitude et Cohérence : Des décisions financières fiables nécessitent des données à la fois précises et cohérentes. De petites erreurs ou incohérences peuvent entraîner des erreurs coûteuses.
Complétude et Pertinence : Les données incomplètes ou manquantes peuvent avoir un impact significatif sur les évaluations de risque et les opérations commerciales dans leur ensemble.
Actualité et Fraîcheur : Les données financières doivent être à jour. Des retards dans la mise à jour de vos données peuvent entraîner des évaluations financières incorrectes et des pénalités réglementaires potentielles.
Normalisation et Gouvernance : Des directives claires et des pratiques normalisées aident à éviter les incohérences et la confusion. Avec une gouvernance appropriée, vous pouvez garantir l'intégrité des données entre les départements et les systèmes.
Sécurité des Données et Conformité : Les données financières sont sensibles et leur protection est essentielle. La mise en œuvre d'un contrôle d'accès basé sur les rôles, le cryptage et les pistes d'audit garantit que seuls les utilisateurs autorisés ont accès aux données, les protégeant contre les violations, la fraude ou les mauvais usages.
Automatisation et Surveillance Continue : L'automatisation accélère les vérifications de la qualité des données, vous permettant de détecter les anomalies, les duplications et les incohérences en temps réel. La surveillance continue assure que les problèmes de qualité des données sont rapidement identifiés et résolus, conduisant à un système financier plus transparent et efficace.
En suivant ces principes, vous pouvez non seulement respecter les exigences réglementaires, mais aussi instaurer la confiance dans vos données financières, vous permettant ainsi de prendre de meilleures décisions et d'évoluer dans un environnement plus sécurisé.
Dans les prochaines étapes, nous vous guiderons à travers la création et la configuration de ces vérifications pour surveiller la qualité des données en temps réel. Mais avant cela, nous allons créer un jeu de données d'exemple.
1. Création d'un Jeu de Données Exemple
Pour surveiller efficacement la qualité des données financières, nous allons créer une table transactions qui simule des données financières du monde réel. Cette table inclura des problèmes de qualité des données intentionnels pour démontrer comment les détecter et les résoudre en utilisant les vérifications Soda.
Étape 1 : Configurer la Base de Données et la Table
Commencez par créer une nouvelle base de données nommée soda_trial et définir la table transactions avec les colonnes appropriées :
CREATE DATABASE soda_trial; USE soda_trial; CREATE TABLE transactions ( transaction_id INT PRIMARY KEY, account_number VARCHAR(20), transaction_date DATE, amount DECIMAL(15,2), currency CHAR(3), transaction_type VARCHAR(10) )
Étape 2 : Remplir la Table avec des Données d'Exemple
Ensuite, insérez des enregistrements exemples dans la table, incluant des problèmes de qualité des données intentionnels pour tester l'efficacité des vérifications Soda :
INSERT INTO transactions (transaction_id, account_number, transaction_date, amount, currency, transaction_type) VALUES (1, 'ACC1234567', '2025-03-25', 1000.00, 'USD', 'Credit'), (2, 'ACC1234567', '2025-03-25', 1000.00, 'USD', 'Credit'), (3, 'ACC1234568', '2025-03-26', -500.00, 'USD', 'Debit'), (4, 'ACC1234569','2025-03-27', 750.00, NULL, 'Credit'), (5, 'ACC1234570', '2025-03-28', 200.00, 'GBP', 'Trans'), (6, 'AC1234571', '2025-03-29', 300.00, 'EUR', 'Debit')
2. Configuration des Vérifications Soda
Les scans Soda sont conçus pour effectuer des vérifications de la qualité des données sur votre source de données, aidant à identifier les données non valides, manquantes ou inattendues. Avec le jeu de données exemple en place, nous pouvons maintenant définir les vérifications de la qualité des données en utilisant SodaCL (Soda Checks Language) pour identifier et résoudre les problèmes introduits.
Étape 1 : Comprendre les Concepts Clés
Tout d'abord, assurons-nous de bien comprendre certains concepts importants :
SodaCL : un langage basé sur YAML qui comprend plus de 25 métriques intégrées que vous pouvez utiliser pour écrire des vérifications, mais vous avez également l'option d'écrire vos propres requêtes SQL ou expressions.
Vérification Soda : une expression Python qui vérifie les métriques pendant un scan Soda pour voir si elles correspondent aux normes que vous avez fixées pour un seuil.
Métrique : Une propriété ou une mesure des données au sein de votre ensemble de données.
Seuil : La valeur ou l'intervalle qu'une métrique est comparée à dans une vérification.
Scan Soda : exécute plusieurs vérifications contre un ou plusieurs ensembles de données présents dans la base deonnées à laquelle vous êtes connecté à Soda.
Pour une liste complète des métriques et vérifications de SodaCL, consultez la Documentation de SodaCL.
Étape 2 : Conception des Vérifications Efficaces de la Qualité des Données
Maintenant, examinons certains des principes que nous avons vus ci-dessus. Nous avons choisi quelques dimensions cruciales pour les données financières et leurs problèmes associés afin de pouvoir créer nos vérifications en utilisant SodaCL.
Exactitude et Cohérence
Transactions en Double : Les entrées en double d'IDs de transactions peuvent gonfler les métriques financières et fausser les analyses.
Montants de Transaction Invalides : Les montants de transaction qui tombent en dehors des plages attendues peuvent indiquer des erreurs de saisie des données ou des fraudes.
Complétude et Pertinence
Dates ou Numéros de Compte de Transaction Manquants : Les enregistrements incomplets limitent la capacité à suivre et à rapprocher les transactions avec précision, compromettant la communication financière et posant des défis dans les processus d'audit.
Actualité et Fraîcheur
Transactions Obsolètes : Les mises à jour retardées peuvent entraîner des évaluations financières inexactes et des pénalités réglementaires potentielles.
Normalisation et Gouvernance
Types de Transactions ou Codes Monétaires Non Standard : Les formats de données incohérents peuvent entraîner des erreurs d'interprétation et de traitement.
Automatisation et Surveillance Continue
Manque de Vérifications Régulières de la Qualité des Données : Sans surveillance automatisée, les problèmes de données peuvent rester non détectés jusqu'à ce qu'ils causent des problèmes importants.
La mise en œuvre des vérifications Soda permet une identification proactive et la résolution de ces problèmes de qualité des données et d'autres, garantissant des données financières fiables pour une prise de décision éclairée. Alors, voyons cela en pratique.
Étape 3 : Mise en Œuvre des Vérifications
Soda prépare un scan en utilisant des vérifications et des configurations de connexion à la source de données, qu'il exécute ensuite contre des ensembles de données pour extraire des métadonnées et évaluer la qualité des données.
Pour cela, vous devrez aller dans votre répertoire de projet et créer un fichier checks.yml pour définir les vérifications pour notre ensemble de données. Nous nous concentrerons sur plusieurs dimensions clés de la qualité des données pertinentes pour les données financières.
Voici un code complet commenté que vous pouvez appliquer à notre base de données de test. Il définit un ensemble de vérifications de la qualité des données pour notre table transactions :
Il vérifie que les transactions ont des IDs uniques, que les montants sont valides et formatés correctement, et que les numéros de compte suivent un modèle spécifique.
Les vérifications de complétude assurent qu'il n'y a pas de valeurs manquantes dans les champs clés, tandis que les vérifications de fraîcheur confirment que les données de transactions sont mises à jour quotidiennement.
Les règles de normalisation appliquent des codes monétaires et des types de transaction valides.
Les mesures de conformité incluent des limites de nombre de lignes, et la validation du schéma détecte les changements non autorisés dans les colonnes nécessaires et les types de données.
Ces règles soutiennent la surveillance automatisée et continue de la qualité des données.
checks for transactions: # Remember to chose your table here # Accuracy and Consistency - duplicate_count(transaction_id) = 0 # Detect duplicate transaction_id entries - duplicate_count(account_number, amount, transaction_type): warn: when > 0 # ensure there are no duplicate transactions - invalid_count(amount) = 0: valid min: 0.01 # Ensure amount values are within a valid range valid format: decimal # Ensure formatting is consistent - invalid_count(account_number) = 0: valid regex: '^ACC.*' # Completeness # Verify no missing values - missing_count(transaction_id) = 0 - missing_count(account_number) = 0 - missing_count(transaction_date) = 0 - missing_count(amount) = 0 - missing_count(currency) = 0 - missing_count(transaction_type) = 0 # Timeliness and Freshness - freshness(transaction_date) < 1d # Assess that data is refreshed daily # Standardization and Governance - invalid_count(currency) = 0: valid values: ['USD', 'EUR', 'GBP'] # Add all acceptable currency codes invalid regex: '[^A-Z]{3}' # Ensure formatting is consistent - invalid_count(transaction_type) = 0: valid values: ['Credit', 'Debit', 'Transfer'] # Data Security and Compliance # Monitor that the table does not exceed a specified number of rows # to manage data volume and compliance. - row_count < 1000000 # Automation and Continuous Monitoring # Define the expected schema to detect unauthorized changes - schema: fail: when required column missing: - transaction_id - account_number - transaction_date - amount - currency - transaction_type when wrong column type: transaction_id: int account_number: varchar transaction_date: date amount: decimal currency: char transaction_type
Si vous avez besoin de scanner différents ensembles de données, n'oubliez pas de créer un fichier de vérification différent pour chacun (dans ce cas, chaque table de votre base de données MySQL).
3. Intégrer Soda dans Votre Pipeline
Pour automatiser les vérifications de la qualité des données au sein de vos flux de travail ETL (Extract, Transform, Load), intégrez une étape qui exécute des scans Soda après l'ingestion des données. Cette intégration garantit que la qualité des données est évaluée avant tout traitement ultérieur, permettant une détection précoce et la résolution des problèmes.
Utilisez la commande suivante pour exécuter un scan Soda sur votre ensemble de données :
soda scan -d soda_trial -c configuration.yml checks.yml
Dans cette commande :
-d soda_trialspécifie le nom de la source de données tel que défini dans votre fichier de configuration.-c configuration.ymldésigne votre fichier de configuration Soda contenant les détails de connexion.checks.ymlest le fichier où vous avez défini vos vérifications de la qualité des données en utilisant SodaCL.
4. Examiner les résultats du scan
En intégrant les scans Soda dans votre pipeline, vous établissez une approche proactive de la qualité des données, garantissant que les problèmes sont identifiés et résolus rapidement, assurant ainsi l'intégrité de vos données tout au long de leur cycle de vie.
Après un scan, chaque vérification aboutit à l'un des trois états par défaut :
passe : les données répondent aux seuils de qualité spécifiés.
échoue : les données ne respectent pas les seuils de qualité spécifiés.
erreur : il y a un problème avec la syntaxe ou l'exécution de la vérification.
État supplémentaire :
avertissement : un état configurable qui vous alerte sur des problèmes potentiels sans marquer la vérification comme un échec complet. Voir plus dans Ajouter des configurations d'alerte. Exemple d'avertissement de notre code :
- duplicate_count(account_number, amount, transaction_type): warn: when > 0
Lorsque les vérifications échouent, elles révèlent les données de basse qualité et fournissent des résultats qui vous aident à enquêter et résoudre les problèmes de qualité.
Vous pouvez examiner les résultats de vos scans Soda via deux canaux principaux :
1. Interface en ligne de commande (CLI) : À l'exécution d'un scan, Soda fournit un retour d'information immédiat dans le terminal, affichant les résultats de chaque vérification. Cette perspicacité en temps réel permet des évaluations rapides et des actions immédiates si nécessaire.
Soda Core 3.5.0 Sending failed row samples to Soda Cloud Sending failed row samples to Soda Cloud Sending failed row samples to Soda Cloud Sending failed row samples to Soda Cloud Sending failed row samples to Soda Cloud Scan summary: 10/15 checks PASSED: transactions in soda_trial row_count < 1000000 [PASSED] Schema Check [PASSED] duplicate_count(transaction_id) = 0 [PASSED] missing_count(transaction_id) = 0 [PASSED] missing_count(amount) = 0 [PASSED] missing_count(account_number) = 0 [PASSED] missing_count(transaction_date) = 0 [PASSED] freshness(transaction_date) < 1d [PASSED] invalid_count(currency) = 0 [PASSED] missing_count(transaction_type) = 0 [PASSED] 1/15 checks WARNED: transactions in soda_trial duplicate_count(account_number, amount, transaction_type) warn when > 0 [WARNED] check_value: 1 4/15 checks FAILED: transactions in soda_trial invalid_count(amount) = 0 [FAILED] check_value: 1 invalid_count(account_number) = 0 [FAILED] check_value: 1 missing_count(currency) = 0 [FAILED] check_value: 1 invalid_count(transaction_type) = 0 [FAILED] check_value: 1 Oops! 4 failures. 1 warning. 0 errors. 10 pass. Sending results to Soda Cloud
Les vérifications de schéma visent principalement à valider les aspects structurels de vos données, tels que la présence, l'absence et la position des colonnes, ainsi que les types de données qui leur sont affectés. Cependant, les vérifications de schéma n'incluent pas l'application de formats de données ou de contraintes spécifiques, comme s'assurer que les valeurs numériques respectent une précision décimale spécifique.
2. Soda Cloud : Pour un examen plus détaillé et collaboratif, dans Soda Cloud, vous pouvez :
Visualiser les résultats du scan via des tableaux de bord intuitifs.
Surveiller les tendances de la qualité des données au fil du temps.
Recevoir des alertes pour les vérifications échouées ou les anomalies.
Collaborer avec les membres de votre équipe pour résoudre les problèmes de qualité des données.
Surveillance et Alerte pour la Qualité des Données
Soda permet la surveillance et l'alerte en temps réel, tenant les parties prenantes informées des problèmes de qualité des données. Configurez Soda pour envoyer des alertes à Slack, Jira ou MS Teams lorsque des vérifications échouent.
Pour activer les alertes, définissez des canaux de notification dans votre configuration Soda et spécifiez les conditions sous lesquelles elles doivent être déclenchées. Cette approche proactive garantit que les problèmes de qualité des données sont résolus rapidement, préservant l'intégrité de vos actifs de données.
Connexion avec MS Teams
Si vous y êtes autorisé, vous pouvez intégrer votre espace de travail Microsoft Teams dans Soda Cloud afin qu'il puisse interagir avec des individus et des chaînes.
Utilisez l'intégration Microsoft Teams pour :
Envoyer des alertes à Microsoft Teams pour les résultats de vérification (notifications d'avertissement ou d'échec).
Créer un canal Teams dédié pour enquêter sur les vérifications échouées et collaborer à la résolution des incidents.
Suivre les Discussions Soda pour une collaboration en temps réel sur la qualité des données avec votre équipe.
Pour configurer l'intégration :
1. Accéder aux Intégrations Soda Cloud : Connectez-vous à votre compte Soda Cloud, allez à votre avatar > Paramètres de l'organisation, et sélectionnez l'onglet Intégrations. Cliquez sur l'icône + dans le coin supérieur droit pour ajouter une nouvelle intégration.
2. Sélectionner MS Teams : Dans la boîte de dialogue Ajouter une Intégration, choisissez Microsoft Teams. Vous serez alors guidé à travers une configuration de workflow.
3. Créer un Workflow : Suivez le guide de configuration qui vous indique de vous connecter à votre compte MS Teams. Vous devrez créer un workflow dans Teams (voir la documentation de Microsoft pour "Créer un workflow à partir d'un canal dans Teams") en utilisant le modèle fourni pour poster sur un canal lorsqu'une requête de webhook est reçue.
4. Compléter l'Intégration : Une fois le workflow créé avec succès, copiez l'URL générée et revenez à Soda Cloud pour terminer les étapes guidées. Au cours de ce processus, vous configurerez les portées de l'intégration :
Périmètre de Notification d'Alerte : Permettre à Soda Cloud d'envoyer des notifications d'alertes (pour des résultats de vérification avertis et échoués) directement à votre canal MS Teams choisi. Cela permet aux utilisateurs de sélectionner MS Teams comme destination pour des alertes de vérification individuelles ou groupées.
Périmètre d'Incident : Configurez des notifications pour la création d'un nouvel incident dans Soda Cloud. Ce périmètre affichera un lien externe vers votre canal MS Teams dans les Détails de l'Incident, dirigeant votre équipe vers l'espace approprié pour résoudre l'incident.
Périmètre de Discussions : Configurez Soda Cloud pour publier sur un canal Teams spécifique chaque fois qu'une discussion est initiée ou modifiée. Cela facilite la collaboration continue sur la qualité des données au sein de votre organisation.
Avec l'intégration en place, Soda Cloud peut automatiquement envoyer des notifications à vos canaux MS Teams, garantissant que les alertes, les mises à jour d'incidents et les discussions collaboratives sont facilement partagées avec votre équipe, permettant une réponse rapide et une résolution efficace des problèmes.
Consultez notre documentation pour en savoir plus sur la Intégration avec MS Teams, et aussi sur comment Organiser les résultats, configurer des alertes, enquêter sur les problèmes.
Conclusion - Bonnes Pratiques pour Maintenir la Qualité des Données
Un pipeline de données financières bien architecturé, combiné à une validation et une surveillance automatisées, assure que les données sont constamment précises, complètes et fiables. La beauté de Soda Library réside dans sa capacité à s'intégrer directement dans votre pipeline, vous permettant d'automatiser les vérifications de la qualité des données à toutes les étapes, de l'ingestion au traitement.
En suivant ce guide, vous pouvez créer une solution efficace et évolutive qui permet à votre équipe d'assurer la qualité des données en temps réel tout en respectant les normes réglementaires telles que BCBS 239.
Pour l'avenir, restez à l'écoute des prochains articles de blog qui exploreront des améliorations pour votre pipeline, telles que :
Autonomiser les Utilisateurs Métier : Découvrez comment permettre aux utilisateurs métier de proposer et d'appliquer leurs propres règles métier directement dans votre pipeline.
Surveillance Automatisée des Métriques : Découvrez comment configurer la surveillance automatisée des métriques pour identifier des problèmes cachés à grande échelle, garantissant qu'aucun problème de qualité des données ne passe inaperçu.
N'hésitez pas à explorer davantage les capacités de Soda sur notre site web et dans notre documentation. Si vous souhaitez approfondir, vous pouvez toujours demander une démonstration pour une discussion en face à face sur la manière dont Soda peut transformer vos processus de qualité des données.
Trusted by the world’s leading enterprises
Real stories from companies using Soda to keep their data reliable, accurate, and ready for action.
At the end of the day, we don’t want to be in there managing the checks, updating the checks, adding the checks. We just want to go and observe what’s happening, and that’s what Soda is enabling right now.

Sid Srivastava
Director of Data Governance, Quality and MLOps
Investing in data quality is key for cross-functional teams to make accurate, complete decisions with fewer risks and greater returns, using initiatives such as product thinking, data governance, and self-service platforms.

Mario Konschake
Director of Product-Data Platform
Soda has integrated seamlessly into our technology stack and given us the confidence to find, analyze, implement, and resolve data issues through a simple self-serve capability.

Sutaraj Dutta
Data Engineering Manager
Our goal was to deliver high-quality datasets in near real-time, ensuring dashboards reflect live data as it flows in. But beyond solving technical challenges, we wanted to spark a cultural shift - empowering the entire organization to make decisions grounded in accurate, timely data.

Gu Xie
Head of Data Engineering
4,4 sur 5
Commencez à faire confiance à vos données. Aujourd'hui.
Trouvez, comprenez et corrigez tout problème de qualité des données en quelques secondes.
Du niveau de la table au niveau des enregistrements.
Adopté par
Product








Trusted by the world’s leading enterprises
Real stories from companies using Soda to keep their data reliable, accurate, and ready for action.
At the end of the day, we don’t want to be in there managing the checks, updating the checks, adding the checks. We just want to go and observe what’s happening, and that’s what Soda is enabling right now.
Sid Srivastava
Director of Data Governance, Quality and MLOps
Investing in data quality is key for cross-functional teams to make accurate, complete decisions with fewer risks and greater returns, using initiatives such as product thinking, data governance, and self-service platforms.
Mario Konschake
Director of Product-Data Platform
Soda has integrated seamlessly into our technology stack and given us the confidence to find, analyze, implement, and resolve data issues through a simple self-serve capability.
Sutaraj Dutta
Data Engineering Manager
Our goal was to deliver high-quality datasets in near real-time, ensuring dashboards reflect live data as it flows in. But beyond solving technical challenges, we wanted to spark a cultural shift - empowering the entire organization to make decisions grounded in accurate, timely data.
Gu Xie
Head of Data Engineering
4,4 sur 5
Commencez à faire confiance à vos données. Aujourd'hui.
Trouvez, comprenez et corrigez tout problème de qualité des données en quelques secondes.
Du niveau de la table au niveau des enregistrements.
Adopté par
Product
Solutions
Trusted by the world’s leading enterprises
Real stories from companies using Soda to keep their data reliable, accurate, and ready for action.
At the end of the day, we don’t want to be in there managing the checks, updating the checks, adding the checks. We just want to go and observe what’s happening, and that’s what Soda is enabling right now.
Sid Srivastava
Director of Data Governance, Quality and MLOps
Investing in data quality is key for cross-functional teams to make accurate, complete decisions with fewer risks and greater returns, using initiatives such as product thinking, data governance, and self-service platforms.
Mario Konschake
Director of Product-Data Platform
Soda has integrated seamlessly into our technology stack and given us the confidence to find, analyze, implement, and resolve data issues through a simple self-serve capability.
Sutaraj Dutta
Data Engineering Manager
Our goal was to deliver high-quality datasets in near real-time, ensuring dashboards reflect live data as it flows in. But beyond solving technical challenges, we wanted to spark a cultural shift - empowering the entire organization to make decisions grounded in accurate, timely data.
Gu Xie
Head of Data Engineering
4,4 sur 5
Commencez à faire confiance à vos données. Aujourd'hui.
Trouvez, comprenez et corrigez tout problème de qualité des données en quelques secondes.
Du niveau de la table au niveau des enregistrements.
Adopté par
Product
Solutions
Company