La détection des enregistrements dupliqués peut vous faire économiser des millions
La détection des enregistrements dupliqués peut vous faire économiser des millions
La détection des enregistrements dupliqués peut vous faire économiser des millions

Fabiana Ferraz
Fabiana Ferraz
Rédacteur technique chez Soda
Rédacteur technique chez Soda
Table des matières
Une entreprise internationale de services financiers dépensait à son insu plus de 1,5 million de dollars par an à cause de la duplication silencieuse des données dans ses pipelines. Ils ont pu détecter et éliminer plus de 1 000 tables en double grâce à la plateforme de qualité des données low-code de Soda, économisant ainsi sur les coûts de calcul et de stockage, réduisant l'effort d'ingénierie et restaurant la confiance dans les analyses. La mise en œuvre a pris moins d'une journée. Et le résultat final ? Surveillance en temps réel, prévention proactive et retour sur investissement (ROI) à long terme.
«L'implémentation de Soda a transformé notre approche de la qualité des données - de la gestion de crise à la prévention. Les économies ont été immédiates, mais le bénéfice durable est la confiance que nous avons gagnée dans nos données.» - Responsable de l'ingénierie des données
Le coût caché des données dupliquées
Que vous soyez ingénieur en données, responsable analytique ou partie prenante de l'entreprise, les enregistrements en double dans vos pipelines de données peuvent être une source importante, mais souvent négligée, de gaspillage de budget.
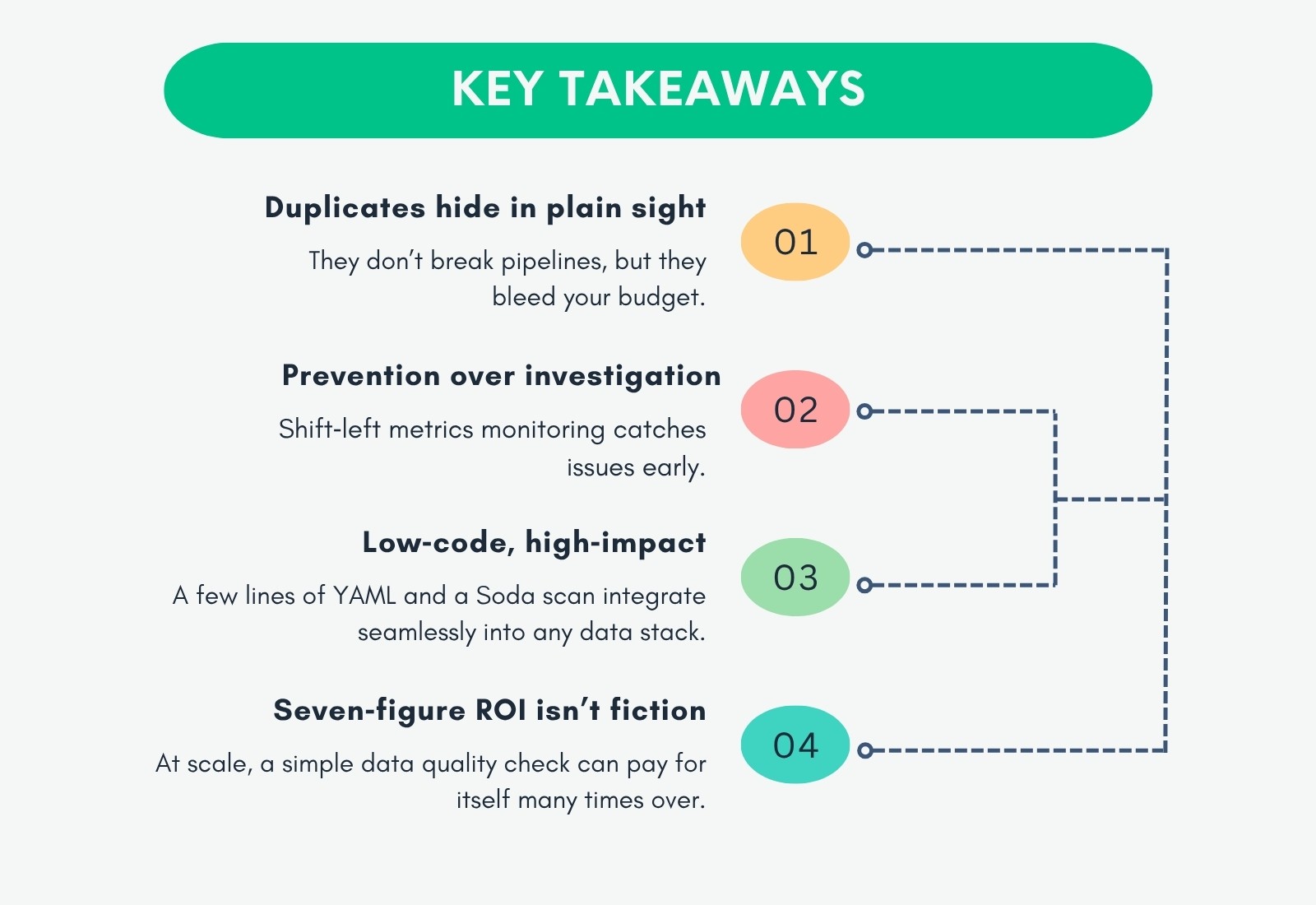
Parce qu'ils ne plantent pas vos tableaux de bord ou ne perturbent pas vos processus, ces entrées en double ont tendance à passer inaperçues. Dans les environnements à grande échelle, ce « gaspillage invisible » s'accumule rapidement, surtout lorsque vous payez pour chaque gigaoctet de données et chaque seconde de CPU dans le cloud.
Au-delà de la perte monétaire, les données dupliquées compromettent la fiabilité des tableaux de bord et des rapports. Les utilisateurs commerciaux peuvent à leur insu prendre des décisions sur la base de métriques gonflées, tandis que les équipes de données sont obligées de passer un temps précieux à résoudre des anomalies qui auraient pu être évitées.
Ce cycle non seulement réduit la productivité, mais compromet aussi la conformité réglementaire et la préparation aux audits.
Le défi est clair : sans surveillance proactive et prévention, les enregistrements en double peuvent silencieusement éroder à la fois la santé financière et la culture des données d'une organisation.
Dans cet article, nous partagerons une véritable histoire de client d'une entreprise internationale. Nous expliquerons comment l'approche low-code de Soda a identifié une duplication rampante avant qu'elle puisse affecter la couche modélisation, et nous quantifierons le retour sur investissement (ROI) substantiel - alerte spoiler : il se mesure en millions de dollars.
Nous garderons les aspects techniques au minimum, mettrons l'accent sur la valeur commerciale et démontrerons comment la surveillance automatique de la qualité des données peut transformer les coûts cachés en économies claires.
Histoire du client : Quand les copies deviennent coûteuses
Cette entreprise internationale gère des milliers de milliards de dollars en actifs et opère dans une industrie hautement réglementée où la qualité des données est cruciale pour le succès commercial. Leur équipe d'ingénierie des données exécute des milliers de modèles et de pipelines chaque jour, traitant d'énormes volumes de données transactionnelles qui alimentent les tableaux de bord, les rapports et les processus de conformité.
Avec une telle échelle, même les inefficacités mineures se multiplient rapidement, ce qui se passait précisément, inaperçu.
Récemment, ils ont mis en place Soda pour les tests et la surveillance des données dans tout leur écosystème.
Soda s'est révélé efficace pour identifier des problèmes courants tels que les valeurs nulles, les dérives de schéma et les pics de lignes. Cependant, il n'y avait pas de vérification prête à l'emploi pour signaler ce qui s'est avéré être un de leurs points aveugles les plus coûteux : la duplication à grande échelle.
Le défi : L'échelle et l'impact des doublons
À première vue, rien ne semblait anormal. Les pipelines étaient opérationnels. Les tableaux de bord avaient l'air précis et les modèles fonctionnaient comme prévu. Mais quelque chose semblait toujours bizarre à l'équipe.
La percée n'est pas venue d'une alerte standard, mais d'un travail analytique. En utilisant Soda pour surveiller les dérives de schéma et les pics de lignes, l'équipe a identifié une tendance préoccupante : des centaines de tables partageaient des comptes de lignes identiques et contenaient la même information, jusqu'à l'enregistrement.
Ce qu'ils ont découvert était étonnant : il y avait plus de 1 000 tables en double — même pas utilisées activement — chacune coûtant environ 4 $/jour à stocker et à traiter. Multipliez ce montant par 365 jours, et vous obtenez presque 1,5 million de dollars par an.
Il est devenu clair que certaines tables de sauvegarde et d'archivage étaient involontairement incluses dans les pipelines de production. En fin de compte, les ingénieurs en données ont passé un temps considérable à résoudre des anomalies qui auraient pu être évitées.
Bien que ces doublons ne causaient pas de problèmes immédiats, ils augmentaient silencieusement l'utilisation du calcul et du stockage à une échelle massive. Pire, ils faussaient des métriques clés et représentaient un risque dans les rapports réglementaires.
La solution : Visibilité et prévention avec Soda
Avec Soda offrant la visibilité nécessaire, l'équipe de données a utilisé son expertise du domaine pour :
Enquêter sur l'anomalie
Effectuer une analyse de la cause racine (RCA)
Comprendre comment les doublons sont entrés dans le système
Concevoir des vérifications low-code pour détecter et prévenir les problèmes à l'avenir
Soda ne leur a pas offert la solution, mais il leur a donné les signaux. C'est le savoir-faire de l'équipe qui a transformé ces signaux en actions.
C'est ce genre d'approche avec l'humain dans la boucle qui rend la qualité des données moderne efficace.
Leçons tirées : Prévention plutôt que investigation
De nombreuses équipes n'enquêtent que lorsqu'un problème survient. Mais les coûts ? Ils s'insinuent discrètement. Il n'y a rarement un seul signal rouge. Juste une montée lente et régulière des factures de stockage et de calcul qui passe inaperçue jusqu'à ce que quelqu'un demande enfin, « Pourquoi payons-nous autant ? »
Ainsi, plutôt que d'attendre de découvrir à nouveau des problèmes de qualité des données, notre client a mis en place des vérifications automatisées pour détecter les doublons avant que les données n'atteignent les modèles ou les tableaux de bord.
Avec l'approche légère et pilotée par YAML de Soda, ils ont :
Quantifié les taux de duplication au niveau des lignes.
Signalé des tables entières lorsque deux tables partageaient exactement le même nombre de lignes (un fort signal de duplication).
La mise en place de ces vérifications a pris moins d'une journée d'ingénierie - pas de travaux Spark ni de scripts personnalisés nécessaires.
Voyons comment ils ont procédé :
1. Définir une vérification “duplicate_percent”
checks for {{ table_name }}: - duplicate_percent(column_name)
Cette métrique simple calcule le pourcentage de lignes dupliquées sur la ou les colonnes spécifiées. Un seuil (par exemple, 0,1 %) déclenche des alertes.
2. Surface duplication au niveau table
checks for {{ table_name }}: - row_count
En faisant référence au nombre de lignes d'une autre table, Soda signale lorsque deux tables correspondent exactement - un moyen facile de détecter des tables clonées.
3. Intégration aux pipelines existants
Intégrez la CLI de Soda ou le SDK Python à la fin de votre travail d'ingestion.
Les analyses Soda s'exécutent en quelques secondes, émettent des rapports JSON et envoient des alertes à Slack ou PagerDuty.
C'est tout. Pas d'orchestration lourde ni de clusters de calcul supplémentaires. Soda s'exécute là où vos pipelines s'exécutent déjà.
Les alertes ont été envoyées en temps réel à l'équipe d'ingénierie des données. Et, au lieu de découvrir le problème des mois plus tard, les ingénieurs ont corrigé les déploiements de schéma, mis à jour les travaux d'ingestion et supprimé les copies redondantes en quelques heures.
Les résultats : Du gâchis invisible à un ROI mesurable
En bref, les enregistrements en double ne sont pas seulement un problème technique; ils représentent une menace importante et multiforme pour l'efficacité opérationnelle, la performance financière et la confiance organisationnelle.
Les vérifications automatisées de la qualité des données non seulement économisent des millions mais cultivent également une culture de confiance et d'efficacité. Le ROI financier et opérationnel est significatif et immédiat.
Métrique | Avant Soda | Après Soda |
|---|---|---|
Coût annuel des doublons | 1,5 M$+ | 0 |
Heures d'ingénierie | Élevé | Minimales |
Temps pour détecter les problèmes | Jours/semaines | En temps réel |
Confiance dans les données | Basse | Haute |
Risque de conformité | Élevé | Réduit |
Même si vos chiffres ne sont pas à cette échelle, les pourcentages d'économies et les garde-fous pour la croissance sont impossibles à ignorer.
Et ensuite ?
Avec Soda en place, l'équipe continue de :
Étendre la surveillance automatisée à de nouveaux pipelines.
Utiliser SodaCL pour mettre en œuvre davantage d'attentes contractuelles.
Explorer les fonctionnalités AI de Soda pour réduire l'écriture manuelle de règles.
Ce qui a commencé comme une solution à un seul problème coûteux s'est transformé en un modèle pour des opérations de données proactives.
🚫 Aucun pipeline n'a été endommagé lors de la création de cet article de blog.
Seules les tables gaspillées ont été supprimées.
Voulez-vous savoir ce qui se cache dans vos pipelines ?
Planifiez une démo avec l'équipe de Soda pour découvrir combien vous pourriez économiser, non seulement sur les doublons, mais sur l'ensemble de votre spectre de qualité des données.
Une entreprise internationale de services financiers dépensait à son insu plus de 1,5 million de dollars par an à cause de la duplication silencieuse des données dans ses pipelines. Ils ont pu détecter et éliminer plus de 1 000 tables en double grâce à la plateforme de qualité des données low-code de Soda, économisant ainsi sur les coûts de calcul et de stockage, réduisant l'effort d'ingénierie et restaurant la confiance dans les analyses. La mise en œuvre a pris moins d'une journée. Et le résultat final ? Surveillance en temps réel, prévention proactive et retour sur investissement (ROI) à long terme.
«L'implémentation de Soda a transformé notre approche de la qualité des données - de la gestion de crise à la prévention. Les économies ont été immédiates, mais le bénéfice durable est la confiance que nous avons gagnée dans nos données.» - Responsable de l'ingénierie des données
Le coût caché des données dupliquées
Que vous soyez ingénieur en données, responsable analytique ou partie prenante de l'entreprise, les enregistrements en double dans vos pipelines de données peuvent être une source importante, mais souvent négligée, de gaspillage de budget.
Parce qu'ils ne plantent pas vos tableaux de bord ou ne perturbent pas vos processus, ces entrées en double ont tendance à passer inaperçues. Dans les environnements à grande échelle, ce « gaspillage invisible » s'accumule rapidement, surtout lorsque vous payez pour chaque gigaoctet de données et chaque seconde de CPU dans le cloud.
Au-delà de la perte monétaire, les données dupliquées compromettent la fiabilité des tableaux de bord et des rapports. Les utilisateurs commerciaux peuvent à leur insu prendre des décisions sur la base de métriques gonflées, tandis que les équipes de données sont obligées de passer un temps précieux à résoudre des anomalies qui auraient pu être évitées.
Ce cycle non seulement réduit la productivité, mais compromet aussi la conformité réglementaire et la préparation aux audits.
Le défi est clair : sans surveillance proactive et prévention, les enregistrements en double peuvent silencieusement éroder à la fois la santé financière et la culture des données d'une organisation.
Dans cet article, nous partagerons une véritable histoire de client d'une entreprise internationale. Nous expliquerons comment l'approche low-code de Soda a identifié une duplication rampante avant qu'elle puisse affecter la couche modélisation, et nous quantifierons le retour sur investissement (ROI) substantiel - alerte spoiler : il se mesure en millions de dollars.
Nous garderons les aspects techniques au minimum, mettrons l'accent sur la valeur commerciale et démontrerons comment la surveillance automatique de la qualité des données peut transformer les coûts cachés en économies claires.
Histoire du client : Quand les copies deviennent coûteuses
Cette entreprise internationale gère des milliers de milliards de dollars en actifs et opère dans une industrie hautement réglementée où la qualité des données est cruciale pour le succès commercial. Leur équipe d'ingénierie des données exécute des milliers de modèles et de pipelines chaque jour, traitant d'énormes volumes de données transactionnelles qui alimentent les tableaux de bord, les rapports et les processus de conformité.
Avec une telle échelle, même les inefficacités mineures se multiplient rapidement, ce qui se passait précisément, inaperçu.
Récemment, ils ont mis en place Soda pour les tests et la surveillance des données dans tout leur écosystème.
Soda s'est révélé efficace pour identifier des problèmes courants tels que les valeurs nulles, les dérives de schéma et les pics de lignes. Cependant, il n'y avait pas de vérification prête à l'emploi pour signaler ce qui s'est avéré être un de leurs points aveugles les plus coûteux : la duplication à grande échelle.
Le défi : L'échelle et l'impact des doublons
À première vue, rien ne semblait anormal. Les pipelines étaient opérationnels. Les tableaux de bord avaient l'air précis et les modèles fonctionnaient comme prévu. Mais quelque chose semblait toujours bizarre à l'équipe.
La percée n'est pas venue d'une alerte standard, mais d'un travail analytique. En utilisant Soda pour surveiller les dérives de schéma et les pics de lignes, l'équipe a identifié une tendance préoccupante : des centaines de tables partageaient des comptes de lignes identiques et contenaient la même information, jusqu'à l'enregistrement.
Ce qu'ils ont découvert était étonnant : il y avait plus de 1 000 tables en double — même pas utilisées activement — chacune coûtant environ 4 $/jour à stocker et à traiter. Multipliez ce montant par 365 jours, et vous obtenez presque 1,5 million de dollars par an.
Il est devenu clair que certaines tables de sauvegarde et d'archivage étaient involontairement incluses dans les pipelines de production. En fin de compte, les ingénieurs en données ont passé un temps considérable à résoudre des anomalies qui auraient pu être évitées.
Bien que ces doublons ne causaient pas de problèmes immédiats, ils augmentaient silencieusement l'utilisation du calcul et du stockage à une échelle massive. Pire, ils faussaient des métriques clés et représentaient un risque dans les rapports réglementaires.
La solution : Visibilité et prévention avec Soda
Avec Soda offrant la visibilité nécessaire, l'équipe de données a utilisé son expertise du domaine pour :
Enquêter sur l'anomalie
Effectuer une analyse de la cause racine (RCA)
Comprendre comment les doublons sont entrés dans le système
Concevoir des vérifications low-code pour détecter et prévenir les problèmes à l'avenir
Soda ne leur a pas offert la solution, mais il leur a donné les signaux. C'est le savoir-faire de l'équipe qui a transformé ces signaux en actions.
C'est ce genre d'approche avec l'humain dans la boucle qui rend la qualité des données moderne efficace.
Leçons tirées : Prévention plutôt que investigation
De nombreuses équipes n'enquêtent que lorsqu'un problème survient. Mais les coûts ? Ils s'insinuent discrètement. Il n'y a rarement un seul signal rouge. Juste une montée lente et régulière des factures de stockage et de calcul qui passe inaperçue jusqu'à ce que quelqu'un demande enfin, « Pourquoi payons-nous autant ? »
Ainsi, plutôt que d'attendre de découvrir à nouveau des problèmes de qualité des données, notre client a mis en place des vérifications automatisées pour détecter les doublons avant que les données n'atteignent les modèles ou les tableaux de bord.
Avec l'approche légère et pilotée par YAML de Soda, ils ont :
Quantifié les taux de duplication au niveau des lignes.
Signalé des tables entières lorsque deux tables partageaient exactement le même nombre de lignes (un fort signal de duplication).
La mise en place de ces vérifications a pris moins d'une journée d'ingénierie - pas de travaux Spark ni de scripts personnalisés nécessaires.
Voyons comment ils ont procédé :
1. Définir une vérification “duplicate_percent”
checks for {{ table_name }}: - duplicate_percent(column_name)
Cette métrique simple calcule le pourcentage de lignes dupliquées sur la ou les colonnes spécifiées. Un seuil (par exemple, 0,1 %) déclenche des alertes.
2. Surface duplication au niveau table
checks for {{ table_name }}: - row_count
En faisant référence au nombre de lignes d'une autre table, Soda signale lorsque deux tables correspondent exactement - un moyen facile de détecter des tables clonées.
3. Intégration aux pipelines existants
Intégrez la CLI de Soda ou le SDK Python à la fin de votre travail d'ingestion.
Les analyses Soda s'exécutent en quelques secondes, émettent des rapports JSON et envoient des alertes à Slack ou PagerDuty.
C'est tout. Pas d'orchestration lourde ni de clusters de calcul supplémentaires. Soda s'exécute là où vos pipelines s'exécutent déjà.
Les alertes ont été envoyées en temps réel à l'équipe d'ingénierie des données. Et, au lieu de découvrir le problème des mois plus tard, les ingénieurs ont corrigé les déploiements de schéma, mis à jour les travaux d'ingestion et supprimé les copies redondantes en quelques heures.
Les résultats : Du gâchis invisible à un ROI mesurable
En bref, les enregistrements en double ne sont pas seulement un problème technique; ils représentent une menace importante et multiforme pour l'efficacité opérationnelle, la performance financière et la confiance organisationnelle.
Les vérifications automatisées de la qualité des données non seulement économisent des millions mais cultivent également une culture de confiance et d'efficacité. Le ROI financier et opérationnel est significatif et immédiat.
Métrique | Avant Soda | Après Soda |
|---|---|---|
Coût annuel des doublons | 1,5 M$+ | 0 |
Heures d'ingénierie | Élevé | Minimales |
Temps pour détecter les problèmes | Jours/semaines | En temps réel |
Confiance dans les données | Basse | Haute |
Risque de conformité | Élevé | Réduit |
Même si vos chiffres ne sont pas à cette échelle, les pourcentages d'économies et les garde-fous pour la croissance sont impossibles à ignorer.
Et ensuite ?
Avec Soda en place, l'équipe continue de :
Étendre la surveillance automatisée à de nouveaux pipelines.
Utiliser SodaCL pour mettre en œuvre davantage d'attentes contractuelles.
Explorer les fonctionnalités AI de Soda pour réduire l'écriture manuelle de règles.
Ce qui a commencé comme une solution à un seul problème coûteux s'est transformé en un modèle pour des opérations de données proactives.
🚫 Aucun pipeline n'a été endommagé lors de la création de cet article de blog.
Seules les tables gaspillées ont été supprimées.
Voulez-vous savoir ce qui se cache dans vos pipelines ?
Planifiez une démo avec l'équipe de Soda pour découvrir combien vous pourriez économiser, non seulement sur les doublons, mais sur l'ensemble de votre spectre de qualité des données.
Une entreprise internationale de services financiers dépensait à son insu plus de 1,5 million de dollars par an à cause de la duplication silencieuse des données dans ses pipelines. Ils ont pu détecter et éliminer plus de 1 000 tables en double grâce à la plateforme de qualité des données low-code de Soda, économisant ainsi sur les coûts de calcul et de stockage, réduisant l'effort d'ingénierie et restaurant la confiance dans les analyses. La mise en œuvre a pris moins d'une journée. Et le résultat final ? Surveillance en temps réel, prévention proactive et retour sur investissement (ROI) à long terme.
«L'implémentation de Soda a transformé notre approche de la qualité des données - de la gestion de crise à la prévention. Les économies ont été immédiates, mais le bénéfice durable est la confiance que nous avons gagnée dans nos données.» - Responsable de l'ingénierie des données
Le coût caché des données dupliquées
Que vous soyez ingénieur en données, responsable analytique ou partie prenante de l'entreprise, les enregistrements en double dans vos pipelines de données peuvent être une source importante, mais souvent négligée, de gaspillage de budget.
Parce qu'ils ne plantent pas vos tableaux de bord ou ne perturbent pas vos processus, ces entrées en double ont tendance à passer inaperçues. Dans les environnements à grande échelle, ce « gaspillage invisible » s'accumule rapidement, surtout lorsque vous payez pour chaque gigaoctet de données et chaque seconde de CPU dans le cloud.
Au-delà de la perte monétaire, les données dupliquées compromettent la fiabilité des tableaux de bord et des rapports. Les utilisateurs commerciaux peuvent à leur insu prendre des décisions sur la base de métriques gonflées, tandis que les équipes de données sont obligées de passer un temps précieux à résoudre des anomalies qui auraient pu être évitées.
Ce cycle non seulement réduit la productivité, mais compromet aussi la conformité réglementaire et la préparation aux audits.
Le défi est clair : sans surveillance proactive et prévention, les enregistrements en double peuvent silencieusement éroder à la fois la santé financière et la culture des données d'une organisation.
Dans cet article, nous partagerons une véritable histoire de client d'une entreprise internationale. Nous expliquerons comment l'approche low-code de Soda a identifié une duplication rampante avant qu'elle puisse affecter la couche modélisation, et nous quantifierons le retour sur investissement (ROI) substantiel - alerte spoiler : il se mesure en millions de dollars.
Nous garderons les aspects techniques au minimum, mettrons l'accent sur la valeur commerciale et démontrerons comment la surveillance automatique de la qualité des données peut transformer les coûts cachés en économies claires.
Histoire du client : Quand les copies deviennent coûteuses
Cette entreprise internationale gère des milliers de milliards de dollars en actifs et opère dans une industrie hautement réglementée où la qualité des données est cruciale pour le succès commercial. Leur équipe d'ingénierie des données exécute des milliers de modèles et de pipelines chaque jour, traitant d'énormes volumes de données transactionnelles qui alimentent les tableaux de bord, les rapports et les processus de conformité.
Avec une telle échelle, même les inefficacités mineures se multiplient rapidement, ce qui se passait précisément, inaperçu.
Récemment, ils ont mis en place Soda pour les tests et la surveillance des données dans tout leur écosystème.
Soda s'est révélé efficace pour identifier des problèmes courants tels que les valeurs nulles, les dérives de schéma et les pics de lignes. Cependant, il n'y avait pas de vérification prête à l'emploi pour signaler ce qui s'est avéré être un de leurs points aveugles les plus coûteux : la duplication à grande échelle.
Le défi : L'échelle et l'impact des doublons
À première vue, rien ne semblait anormal. Les pipelines étaient opérationnels. Les tableaux de bord avaient l'air précis et les modèles fonctionnaient comme prévu. Mais quelque chose semblait toujours bizarre à l'équipe.
La percée n'est pas venue d'une alerte standard, mais d'un travail analytique. En utilisant Soda pour surveiller les dérives de schéma et les pics de lignes, l'équipe a identifié une tendance préoccupante : des centaines de tables partageaient des comptes de lignes identiques et contenaient la même information, jusqu'à l'enregistrement.
Ce qu'ils ont découvert était étonnant : il y avait plus de 1 000 tables en double — même pas utilisées activement — chacune coûtant environ 4 $/jour à stocker et à traiter. Multipliez ce montant par 365 jours, et vous obtenez presque 1,5 million de dollars par an.
Il est devenu clair que certaines tables de sauvegarde et d'archivage étaient involontairement incluses dans les pipelines de production. En fin de compte, les ingénieurs en données ont passé un temps considérable à résoudre des anomalies qui auraient pu être évitées.
Bien que ces doublons ne causaient pas de problèmes immédiats, ils augmentaient silencieusement l'utilisation du calcul et du stockage à une échelle massive. Pire, ils faussaient des métriques clés et représentaient un risque dans les rapports réglementaires.
La solution : Visibilité et prévention avec Soda
Avec Soda offrant la visibilité nécessaire, l'équipe de données a utilisé son expertise du domaine pour :
Enquêter sur l'anomalie
Effectuer une analyse de la cause racine (RCA)
Comprendre comment les doublons sont entrés dans le système
Concevoir des vérifications low-code pour détecter et prévenir les problèmes à l'avenir
Soda ne leur a pas offert la solution, mais il leur a donné les signaux. C'est le savoir-faire de l'équipe qui a transformé ces signaux en actions.
C'est ce genre d'approche avec l'humain dans la boucle qui rend la qualité des données moderne efficace.
Leçons tirées : Prévention plutôt que investigation
De nombreuses équipes n'enquêtent que lorsqu'un problème survient. Mais les coûts ? Ils s'insinuent discrètement. Il n'y a rarement un seul signal rouge. Juste une montée lente et régulière des factures de stockage et de calcul qui passe inaperçue jusqu'à ce que quelqu'un demande enfin, « Pourquoi payons-nous autant ? »
Ainsi, plutôt que d'attendre de découvrir à nouveau des problèmes de qualité des données, notre client a mis en place des vérifications automatisées pour détecter les doublons avant que les données n'atteignent les modèles ou les tableaux de bord.
Avec l'approche légère et pilotée par YAML de Soda, ils ont :
Quantifié les taux de duplication au niveau des lignes.
Signalé des tables entières lorsque deux tables partageaient exactement le même nombre de lignes (un fort signal de duplication).
La mise en place de ces vérifications a pris moins d'une journée d'ingénierie - pas de travaux Spark ni de scripts personnalisés nécessaires.
Voyons comment ils ont procédé :
1. Définir une vérification “duplicate_percent”
checks for {{ table_name }}: - duplicate_percent(column_name)
Cette métrique simple calcule le pourcentage de lignes dupliquées sur la ou les colonnes spécifiées. Un seuil (par exemple, 0,1 %) déclenche des alertes.
2. Surface duplication au niveau table
checks for {{ table_name }}: - row_count
En faisant référence au nombre de lignes d'une autre table, Soda signale lorsque deux tables correspondent exactement - un moyen facile de détecter des tables clonées.
3. Intégration aux pipelines existants
Intégrez la CLI de Soda ou le SDK Python à la fin de votre travail d'ingestion.
Les analyses Soda s'exécutent en quelques secondes, émettent des rapports JSON et envoient des alertes à Slack ou PagerDuty.
C'est tout. Pas d'orchestration lourde ni de clusters de calcul supplémentaires. Soda s'exécute là où vos pipelines s'exécutent déjà.
Les alertes ont été envoyées en temps réel à l'équipe d'ingénierie des données. Et, au lieu de découvrir le problème des mois plus tard, les ingénieurs ont corrigé les déploiements de schéma, mis à jour les travaux d'ingestion et supprimé les copies redondantes en quelques heures.
Les résultats : Du gâchis invisible à un ROI mesurable
En bref, les enregistrements en double ne sont pas seulement un problème technique; ils représentent une menace importante et multiforme pour l'efficacité opérationnelle, la performance financière et la confiance organisationnelle.
Les vérifications automatisées de la qualité des données non seulement économisent des millions mais cultivent également une culture de confiance et d'efficacité. Le ROI financier et opérationnel est significatif et immédiat.
Métrique | Avant Soda | Après Soda |
|---|---|---|
Coût annuel des doublons | 1,5 M$+ | 0 |
Heures d'ingénierie | Élevé | Minimales |
Temps pour détecter les problèmes | Jours/semaines | En temps réel |
Confiance dans les données | Basse | Haute |
Risque de conformité | Élevé | Réduit |
Même si vos chiffres ne sont pas à cette échelle, les pourcentages d'économies et les garde-fous pour la croissance sont impossibles à ignorer.
Et ensuite ?
Avec Soda en place, l'équipe continue de :
Étendre la surveillance automatisée à de nouveaux pipelines.
Utiliser SodaCL pour mettre en œuvre davantage d'attentes contractuelles.
Explorer les fonctionnalités AI de Soda pour réduire l'écriture manuelle de règles.
Ce qui a commencé comme une solution à un seul problème coûteux s'est transformé en un modèle pour des opérations de données proactives.
🚫 Aucun pipeline n'a été endommagé lors de la création de cet article de blog.
Seules les tables gaspillées ont été supprimées.
Voulez-vous savoir ce qui se cache dans vos pipelines ?
Planifiez une démo avec l'équipe de Soda pour découvrir combien vous pourriez économiser, non seulement sur les doublons, mais sur l'ensemble de votre spectre de qualité des données.
Trusted by the world’s leading enterprises
Real stories from companies using Soda to keep their data reliable, accurate, and ready for action.
At the end of the day, we don’t want to be in there managing the checks, updating the checks, adding the checks. We just want to go and observe what’s happening, and that’s what Soda is enabling right now.

Sid Srivastava
Director of Data Governance, Quality and MLOps
Investing in data quality is key for cross-functional teams to make accurate, complete decisions with fewer risks and greater returns, using initiatives such as product thinking, data governance, and self-service platforms.

Mario Konschake
Director of Product-Data Platform
Soda has integrated seamlessly into our technology stack and given us the confidence to find, analyze, implement, and resolve data issues through a simple self-serve capability.

Sutaraj Dutta
Data Engineering Manager
Our goal was to deliver high-quality datasets in near real-time, ensuring dashboards reflect live data as it flows in. But beyond solving technical challenges, we wanted to spark a cultural shift - empowering the entire organization to make decisions grounded in accurate, timely data.

Gu Xie
Head of Data Engineering
4,4 sur 5
Commencez à faire confiance à vos données. Aujourd'hui.
Trouvez, comprenez et corrigez tout problème de qualité des données en quelques secondes.
Du niveau de la table au niveau des enregistrements.
Adopté par
Product








Trusted by the world’s leading enterprises
Real stories from companies using Soda to keep their data reliable, accurate, and ready for action.
At the end of the day, we don’t want to be in there managing the checks, updating the checks, adding the checks. We just want to go and observe what’s happening, and that’s what Soda is enabling right now.
Sid Srivastava
Director of Data Governance, Quality and MLOps
Investing in data quality is key for cross-functional teams to make accurate, complete decisions with fewer risks and greater returns, using initiatives such as product thinking, data governance, and self-service platforms.
Mario Konschake
Director of Product-Data Platform
Soda has integrated seamlessly into our technology stack and given us the confidence to find, analyze, implement, and resolve data issues through a simple self-serve capability.
Sutaraj Dutta
Data Engineering Manager
Our goal was to deliver high-quality datasets in near real-time, ensuring dashboards reflect live data as it flows in. But beyond solving technical challenges, we wanted to spark a cultural shift - empowering the entire organization to make decisions grounded in accurate, timely data.
Gu Xie
Head of Data Engineering
4,4 sur 5
Commencez à faire confiance à vos données. Aujourd'hui.
Trouvez, comprenez et corrigez tout problème de qualité des données en quelques secondes.
Du niveau de la table au niveau des enregistrements.
Adopté par
Product
Solutions
Trusted by the world’s leading enterprises
Real stories from companies using Soda to keep their data reliable, accurate, and ready for action.
At the end of the day, we don’t want to be in there managing the checks, updating the checks, adding the checks. We just want to go and observe what’s happening, and that’s what Soda is enabling right now.
Sid Srivastava
Director of Data Governance, Quality and MLOps
Investing in data quality is key for cross-functional teams to make accurate, complete decisions with fewer risks and greater returns, using initiatives such as product thinking, data governance, and self-service platforms.
Mario Konschake
Director of Product-Data Platform
Soda has integrated seamlessly into our technology stack and given us the confidence to find, analyze, implement, and resolve data issues through a simple self-serve capability.
Sutaraj Dutta
Data Engineering Manager
Our goal was to deliver high-quality datasets in near real-time, ensuring dashboards reflect live data as it flows in. But beyond solving technical challenges, we wanted to spark a cultural shift - empowering the entire organization to make decisions grounded in accurate, timely data.
Gu Xie
Head of Data Engineering
4,4 sur 5
Commencez à faire confiance à vos données. Aujourd'hui.
Trouvez, comprenez et corrigez tout problème de qualité des données en quelques secondes.
Du niveau de la table au niveau des enregistrements.
Adopté par
Product
Solutions
Company