Assurer la fiabilité des données : Intégrer Soda avec Databricks
Assurer la fiabilité des données : Intégrer Soda avec Databricks
Assurer la fiabilité des données : Intégrer Soda avec Databricks

Eric Kriner
Eric Kriner
Ingénieur client chez Soda
Ingénieur client chez Soda

Raja Perumal
Raja Perumal
Directeur des Alliances ISV chez Databricks
Directeur des Alliances ISV chez Databricks
Table des matières
Dans les entreprises modernes axées sur les données, à mesure que les organisations adoptent des plateformes évolutives comme Databricks, le besoin d'observabilité des données en temps réel et de maintien de pipelines de données fiables devient crucial.
Soda est une plateforme moderne de qualité des données spécialement conçue pour ce défi. Elle propose des vérifications automatisées de la qualité des données via une interface sans code et une intégration programmatique, facilitant ainsi la surveillance et l'amélioration de la fiabilité des données par l'ensemble de l'équipe data.
Avec les tests éprouvés de bout en bout de Soda, une observabilité complète des données (comme la surveillance des métriques et la détection des anomalies) et un workflow de résolution des problèmes soigneusement conçu, les équipes peuvent détecter les problèmes tôt, être alertées instantanément et empêcher que de mauvaises données ne se propagent en aval.
Que vous soyez un ingénieur data intégrant des vérifications dans un notebook Databricks ou un utilisateur métier définissant des règles dans Soda Cloud, chacun contribue sans avoir besoin d'écrire du code.
Cet article vous guide dans l'intégration de Soda avec Databricks, en mettant en avant les avantages pratiques pour les équipes data visant à instaurer la confiance dans leurs pipelines de données.
Présentation de l'intégration
Soda prend en charge deux principales voies d'intégration avec Databricks :
Option 1 : Soda avec Databricks SQL Warehouse
Option 2 : Soda avec PySpark utilisant le package
soda-spark-df
Les deux méthodes permettent aux utilisateurs techniques et non techniques de définir et d'exécuter des vérifications de qualité des données sur des tables Delta Lake ou des Spark DataFrames, offrant flexibilité selon les préférences et les compétences des utilisateurs.
Option 1 : Utiliser Soda avec Databricks SQL Warehouse
Cette approche est idéale pour les équipes travaillant dans des environnements centrés sur SQL. Elle prend en charge :
Soda Agent (surveillance DQ basée sur l'UI)
Soda Library (workflows pipeline basés sur le CLI)
Les deux outils se connectent directement à un Databricks SQL Warehouse en utilisant des paramètres de connexion simples.
Avec Soda Agent (Sans code)
Le Soda Agent est un outil qui permet aux utilisateurs de l'interface web de Soda de se connecter en toute sécurité aux sources de données et de réaliser des scans de qualité des données automatisés.
Configurez la connexion à Databricks via l'interface Soda Cloud pour déclencher automatiquement le service Soda Agent. Cela permet aux équipes de collaborer et de surveiller en continu la qualité des données directement depuis l'interface web.
Suivez ces étapes pour connecter Databricks dans Soda Cloud :
Étape 1 : Dans Soda Cloud, allez dans le coin supérieur droit :
Cliquez sur votre icône de profil → sélectionnez 'Data Sources' → ajoutez 'New Data Source' → configurez 'Attributes' → choisissez 'Databricks Usage Monitor'
Étape 2 : Sur la page 'Databricks Usage Monitor', configurez vos paramètres de connexion Databricks.
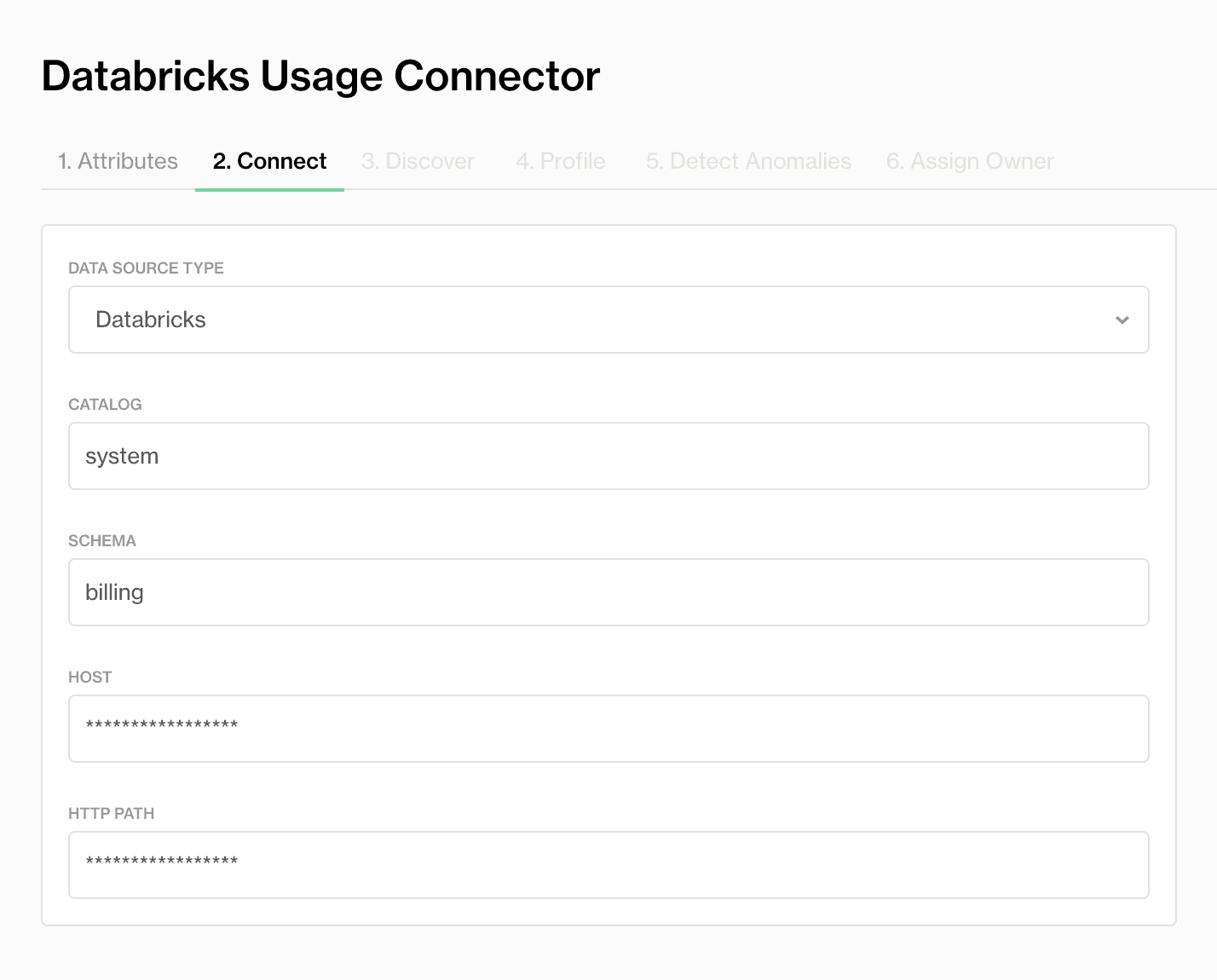
Étape 3 : Cliquez sur 'Test Connection' pour vérifier l'intégration réussie entre Databricks et Soda Cloud.
Une fois connecté, vous pouvez :
Ajouter des vérifications de qualité des données intégrées à des sources de données spécifiques
Planifier des scans automatisés
Activer la détection des anomalies en temps réel
Recevoir des alertes DQ en temps opportun
Résoudre des problèmes de manière collaborative via l'interface
Avec Soda Library (Programmatique)
Soda Library est un package Python pour réaliser des scans de qualité des données à la demande — idéal pour les pipelines CI/CD et les validations locales rapides. Il permet aux utilisateurs de définir des vérifications de qualité des données de manière programmatique et d'envoyer les résultats à Soda Cloud.
Vous pouvez utiliser Soda Library pour intégrer Soda à Databricks en suivant ces étapes :
Étape 1 : Installez Soda Library et installez le package soda-spark-df.
pip install -i https://pypi.cloud.soda.io soda-spark[databricks]
Pour plus de détails, consultez ce guide étape par étape : Connectez-vous à Spark pour Databricks SQL
Étape 2 : Préparez deux fichiers YAML pour permettre à Soda de se connecter à Databricks et d'exécuter votre premier scan DQ.
config.yml : contient les détails de connexion pour vos sources de données et votre compte Soda Cloud.
1data_source my_datasource_name: 2 type: spark 3 method: databricks 4 catalog: samples 5 schema: nyctaxi 6 host: hostname_from_Databricks_SQL_settings 7 http_path: http_path_from_Databricks_SQL_settings 8 token: my_access_token 9soda_cloud: 10 host: cloud.soda.io 11 api_key_id: ${API_KEY} 12 api_key_secret: ${API_SECRET} 13checks.yml: stores user-defined checks for routine data validation. 14# Checks for basic validations 15checks for YOUR_TABLE: 16 - row_count between 10 and 1000 17 - missing_count(column_name) = 0 18 - invalid_count(column_name) = 0: 19 valid min: 1 20 valid max: 6
Étape 3 : Tester la connexion
Pour confirmer que vous avez correctement configuré les détails de connexion dans votre fichier de configuration YAML, utilisez la commande test-connection. Si vous le souhaitez, ajoutez une option -V à la commande pour obtenir des résultats en mode verbeux dans le CLI.
soda test-connection -d my_datasource -c config.yml -V
Une fois configuré, les utilisateurs peuvent commencer à surveiller les anomalies et commencer à créer des vérifications définies par l'utilisateur, permettant une validation facile des données selon des règles prédéfinies.
Option 2 : Utiliser Soda avec PySpark dans les Notebooks Databricks
Pour les utilisateurs de PySpark, la bibliothèque soda-spark-df apporte de puissantes vérifications de qualité des données directement dans vos workflows de notebook. Cela rend facile l'intégration de l'observabilité des données dans des pipelines ETL ou ML, sans quitter l'écosystème Databricks.
Vous pouvez commencer immédiatement en utilisant ce notebook d'exemple. Il suffit de définir la table cible, de brancher vos clés API de Soda Cloud, et vous êtes prêt à y aller.
Vous pouvez installer ce package de deux manières :
Installation dans le Notebook :
pip install -i https://pypi.cloud.soda.io soda-spark-df
Ou au niveau du cluster :
Idéal pour les travaux de production ou les environnements collaboratifs. Cela permet à tous les notebooks au sein du cluster d'accéder à Soda sans configuration individuelle. Vous pouvez installer soda-spark-df directement dans votre cluster Databricks.
Une fois installé, vous pouvez commencer à utiliser Soda en important et configurant l'objet Scan :
from soda.scan import Scan # US Regions use: cloud.us.soda.io and EU Regions use: cloud.soda.io host = "cloud.soda.io" api_key_id = dbutils.secrets.get(scope = "SodaCloud", key = "keyid") api_key_secret = dbutils.secrets.get(scope = "SodaCloud", key = "keysecret") # Fully qualified table name to run DQ checks on fq_table_name = "unity_catalog.quickstart_schema.customers_daily" # This will be the name of the Data Source that appears in Soda Cloud. # If also using an agent, ensure this value is identical datasource_name = "databricksunitycatalogsql"
Cette configuration connecte directement votre notebook à Soda Cloud, vous permettant de définir des vérifications en YAML ou de les exécuter inline avec du code.
Vous pouvez aussi exécuter des vérifications Soda sur des sources externes comme PostgreSQL — tout cela depuis un notebook Databricks.
Soda vous permet de pousser des vérifications vers Postgres, afin qu'elles s'exécutent dans l'environnement Postgres, sans déplacer les données vers Databricks, économisant ainsi sur les coûts de calcul et de transfert de données.
Si toutes les vérifications passent, vous pouvez alors mettre à jour une table Delta existante dans Databricks.
Pour commencer, installez le connecteur Postgres :
pip install -i https://pypi.cloud.soda.io soda-postgres
Exemples : Exécuter des vérifications Soda dans un Notebook
Lors de l'utilisation de Soda dans un notebook Databricks, vous pouvez générer automatiquement des vérifications par défaut avec une configuration minimale, telles que les valeurs manquantes, les doublons de lignes, la fraîcheur et les changements de schéma.
Pour des validations plus avancées, telles que la réconciliation des données ou la logique métier personnalisée, vous pouvez soit utiliser SodaCL dans le notebook, soit configurer des règles via l'interface Soda Cloud.
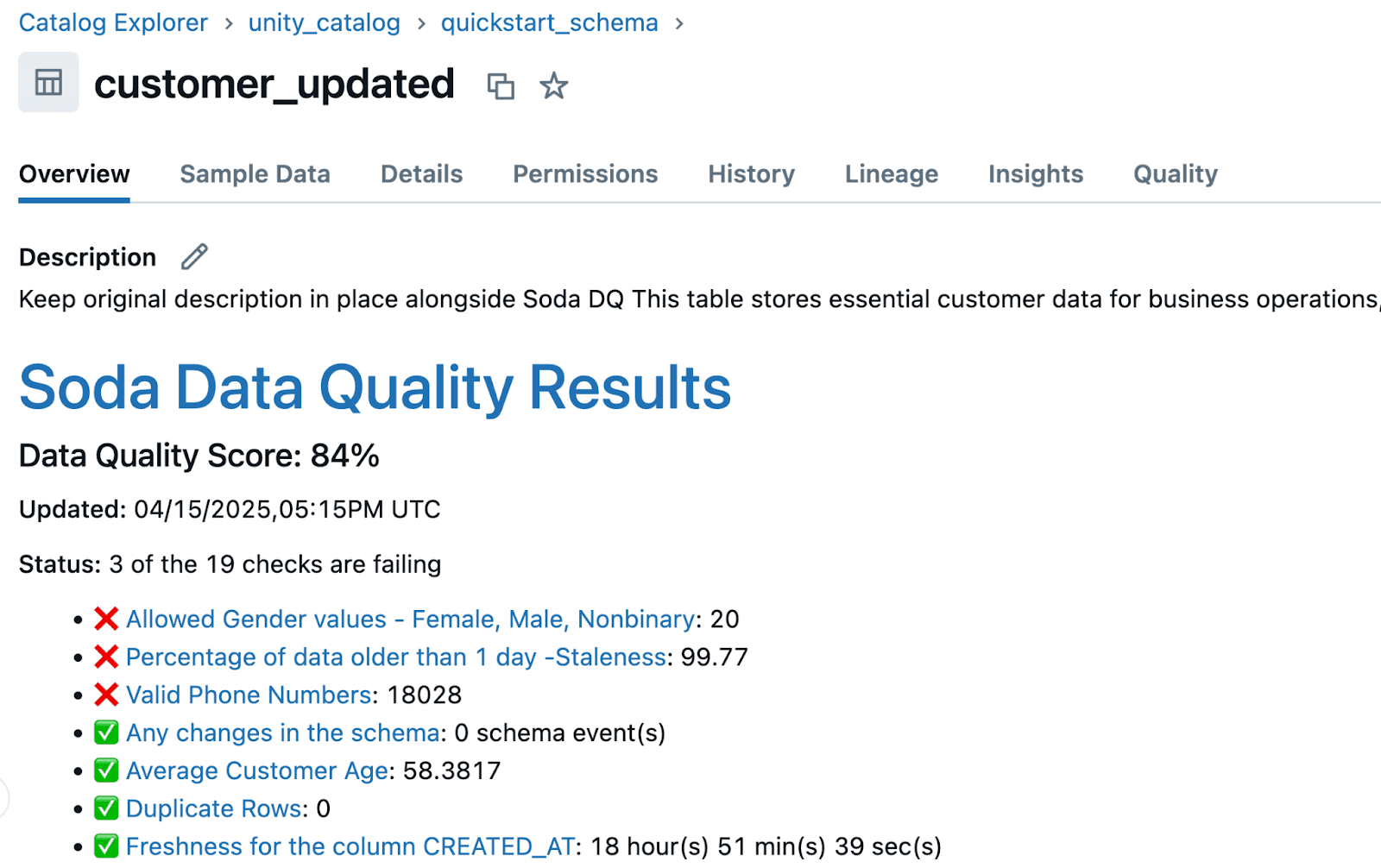
Voici un exemple de sortie d'un scan réussi
INFO | Scan summary: INFO | 11/11 checks PASSED: INFO | customer_updated in databricksunitycatalogsql INFO | Total rows should not be 0 [PASSED] INFO | Any changes in the schema [PASSED] INFO | Duplicate Rows [PASSED] INFO | No Missing values in ID [PASSED] INFO | No Missing values in EMAIL [PASSED] INFO | Freshness for
Catalog Unity :
Surveillance de la qualité des données sur l'interface Soda Cloud
Après intégration, Soda peut interagir avec Databricks via l'interface Soda Cloud, permettant aux utilisateurs techniques et non techniques de surveiller les métriques clés et de rester alignés sur la santé des données.
Principalement, vous pouvez surveiller la santé des données en surveillant les métriques DQ prédéfinies et la détection automatique des anomalies.
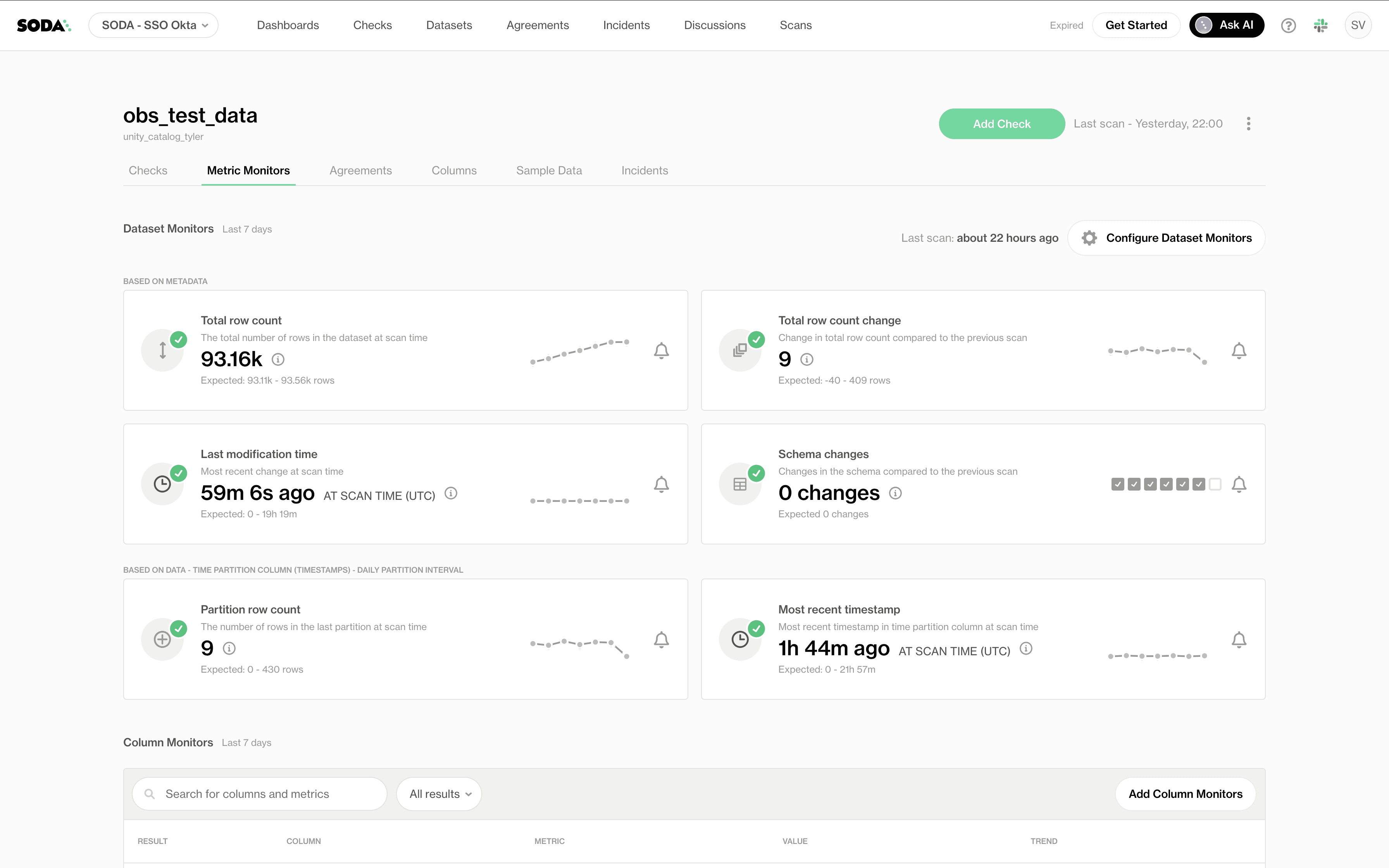
Surveillance des métriques
Ce tableau de bord donne un résumé en temps réel des métriques des datasets au cours des 7 derniers jours. Les équipes peuvent surveiller des tendances telles que :
Le nombre total de lignes et les changements de nombre de lignes, avec des seuils clairement définis et vérifiés à chaque scan
Les changements de schéma, comme les colonnes ajoutées ou supprimées
Heure de la dernière insertion et horodatages les plus récents, qui sont cruciaux pour le suivi de la fraîcheur et de l'opportunité
Valeurs manquantes par colonne, indiquées en bas comme partie des moniteurs de niveau colonne
Ces métriques aident les équipes à identifier les problèmes tôt, tels que des retards de données inattendus, des changements structurels, ou des fluctuations de volume, sans plonger dans les journaux ou le code.
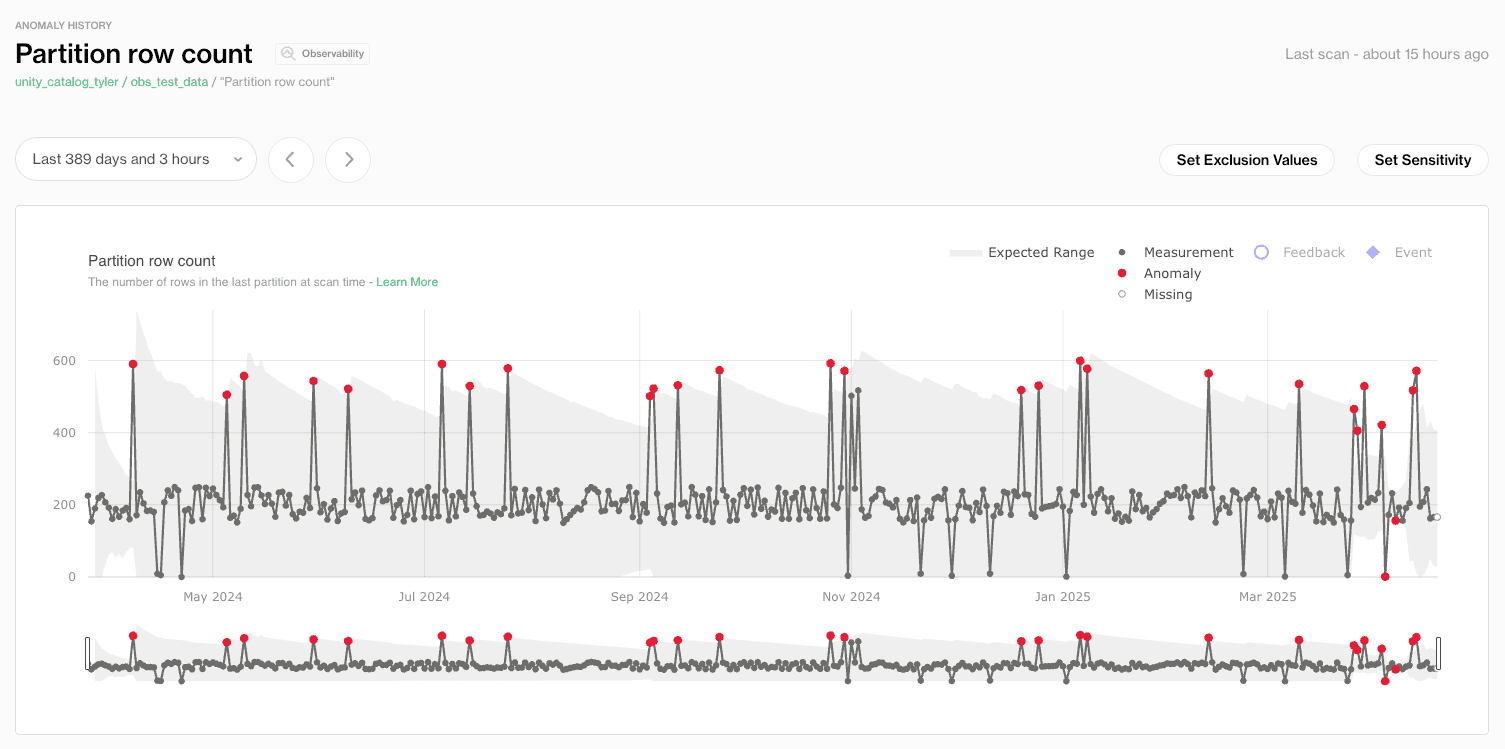
La vue de détection des anomalies vous permet de surveiller les tendances historiques et de détecter les problèmes de qualité des données en utilisant des seuils statistiques. Ici, le nombre de lignes par partition est suivi au fil du temps, avec les anomalies clairement marquées en rouge. Cela aide à :
Repérer la saisonnalité ou les pics de volume
Détecter la perte de données silencieuse (par ex., partitions non peuplées)
Ajuster la sensibilité des alertes en fonction des modèles opérationnels
Ce tableau de bord est particulièrement utile lors de l’investigation d'un comportement inattendu dans les pipelines, en offrant aux équipes le contexte nécessaire pour poser de meilleures questions ou automatiser la résolution.
Avantages de l'intégration
Au lieu de mettre la charge de la qualité des données sur une seule équipe, Soda en fait un processus collaboratif. Les problèmes deviennent visibles, exploitables et résolvables plus rapidement.
Cela signifie :
Les ingénieurs restent proches des pipelines.
Les utilisateurs métiers restent alignés avec la logique de domaine.
Tout le monde reste sur la même longueur d'onde.
Il permet également de débloquer les avantages suivants :
Évolutivité : Prend en charge nativement Spark et Delta Lake, permettant des vérifications sur des ensembles de données à grande échelle.
Automatisation : S’intègre parfaitement avec Databricks Jobs et Workflows, s'alignant avec les pipelines CI/CD.
Détection Précoce : Signale de manière proactive les dérives de schéma, les pics de nullité et d'autres anomalies avant qu'ils ne s’aggravent.
Gouvernance : Améliore Unity Catalog en ajoutant qualité des données et observabilité à travers les domaines.
Conclusion
Intégrer Soda avec Databricks permet aux équipes data d’intégrer un cadre de qualité des données robuste directement dans leurs workflows. En combinant la puissance de traitement de Databricks avec l'Observabilité des Données de Soda, les organisations peuvent évoluer en toute confiance sans sacrifier la confiance ou la fiabilité.
Dans les entreprises modernes axées sur les données, à mesure que les organisations adoptent des plateformes évolutives comme Databricks, le besoin d'observabilité des données en temps réel et de maintien de pipelines de données fiables devient crucial.
Soda est une plateforme moderne de qualité des données spécialement conçue pour ce défi. Elle propose des vérifications automatisées de la qualité des données via une interface sans code et une intégration programmatique, facilitant ainsi la surveillance et l'amélioration de la fiabilité des données par l'ensemble de l'équipe data.
Avec les tests éprouvés de bout en bout de Soda, une observabilité complète des données (comme la surveillance des métriques et la détection des anomalies) et un workflow de résolution des problèmes soigneusement conçu, les équipes peuvent détecter les problèmes tôt, être alertées instantanément et empêcher que de mauvaises données ne se propagent en aval.
Que vous soyez un ingénieur data intégrant des vérifications dans un notebook Databricks ou un utilisateur métier définissant des règles dans Soda Cloud, chacun contribue sans avoir besoin d'écrire du code.
Cet article vous guide dans l'intégration de Soda avec Databricks, en mettant en avant les avantages pratiques pour les équipes data visant à instaurer la confiance dans leurs pipelines de données.
Présentation de l'intégration
Soda prend en charge deux principales voies d'intégration avec Databricks :
Option 1 : Soda avec Databricks SQL Warehouse
Option 2 : Soda avec PySpark utilisant le package
soda-spark-df
Les deux méthodes permettent aux utilisateurs techniques et non techniques de définir et d'exécuter des vérifications de qualité des données sur des tables Delta Lake ou des Spark DataFrames, offrant flexibilité selon les préférences et les compétences des utilisateurs.
Option 1 : Utiliser Soda avec Databricks SQL Warehouse
Cette approche est idéale pour les équipes travaillant dans des environnements centrés sur SQL. Elle prend en charge :
Soda Agent (surveillance DQ basée sur l'UI)
Soda Library (workflows pipeline basés sur le CLI)
Les deux outils se connectent directement à un Databricks SQL Warehouse en utilisant des paramètres de connexion simples.
Avec Soda Agent (Sans code)
Le Soda Agent est un outil qui permet aux utilisateurs de l'interface web de Soda de se connecter en toute sécurité aux sources de données et de réaliser des scans de qualité des données automatisés.
Configurez la connexion à Databricks via l'interface Soda Cloud pour déclencher automatiquement le service Soda Agent. Cela permet aux équipes de collaborer et de surveiller en continu la qualité des données directement depuis l'interface web.
Suivez ces étapes pour connecter Databricks dans Soda Cloud :
Étape 1 : Dans Soda Cloud, allez dans le coin supérieur droit :
Cliquez sur votre icône de profil → sélectionnez 'Data Sources' → ajoutez 'New Data Source' → configurez 'Attributes' → choisissez 'Databricks Usage Monitor'
Étape 2 : Sur la page 'Databricks Usage Monitor', configurez vos paramètres de connexion Databricks.
Étape 3 : Cliquez sur 'Test Connection' pour vérifier l'intégration réussie entre Databricks et Soda Cloud.
Une fois connecté, vous pouvez :
Ajouter des vérifications de qualité des données intégrées à des sources de données spécifiques
Planifier des scans automatisés
Activer la détection des anomalies en temps réel
Recevoir des alertes DQ en temps opportun
Résoudre des problèmes de manière collaborative via l'interface
Avec Soda Library (Programmatique)
Soda Library est un package Python pour réaliser des scans de qualité des données à la demande — idéal pour les pipelines CI/CD et les validations locales rapides. Il permet aux utilisateurs de définir des vérifications de qualité des données de manière programmatique et d'envoyer les résultats à Soda Cloud.
Vous pouvez utiliser Soda Library pour intégrer Soda à Databricks en suivant ces étapes :
Étape 1 : Installez Soda Library et installez le package soda-spark-df.
pip install -i https://pypi.cloud.soda.io soda-spark[databricks]
Pour plus de détails, consultez ce guide étape par étape : Connectez-vous à Spark pour Databricks SQL
Étape 2 : Préparez deux fichiers YAML pour permettre à Soda de se connecter à Databricks et d'exécuter votre premier scan DQ.
config.yml : contient les détails de connexion pour vos sources de données et votre compte Soda Cloud.
1data_source my_datasource_name: 2 type: spark 3 method: databricks 4 catalog: samples 5 schema: nyctaxi 6 host: hostname_from_Databricks_SQL_settings 7 http_path: http_path_from_Databricks_SQL_settings 8 token: my_access_token 9soda_cloud: 10 host: cloud.soda.io 11 api_key_id: ${API_KEY} 12 api_key_secret: ${API_SECRET} 13checks.yml: stores user-defined checks for routine data validation. 14# Checks for basic validations 15checks for YOUR_TABLE: 16 - row_count between 10 and 1000 17 - missing_count(column_name) = 0 18 - invalid_count(column_name) = 0: 19 valid min: 1 20 valid max: 6
Étape 3 : Tester la connexion
Pour confirmer que vous avez correctement configuré les détails de connexion dans votre fichier de configuration YAML, utilisez la commande test-connection. Si vous le souhaitez, ajoutez une option -V à la commande pour obtenir des résultats en mode verbeux dans le CLI.
soda test-connection -d my_datasource -c config.yml -V
Une fois configuré, les utilisateurs peuvent commencer à surveiller les anomalies et commencer à créer des vérifications définies par l'utilisateur, permettant une validation facile des données selon des règles prédéfinies.
Option 2 : Utiliser Soda avec PySpark dans les Notebooks Databricks
Pour les utilisateurs de PySpark, la bibliothèque soda-spark-df apporte de puissantes vérifications de qualité des données directement dans vos workflows de notebook. Cela rend facile l'intégration de l'observabilité des données dans des pipelines ETL ou ML, sans quitter l'écosystème Databricks.
Vous pouvez commencer immédiatement en utilisant ce notebook d'exemple. Il suffit de définir la table cible, de brancher vos clés API de Soda Cloud, et vous êtes prêt à y aller.
Vous pouvez installer ce package de deux manières :
Installation dans le Notebook :
pip install -i https://pypi.cloud.soda.io soda-spark-df
Ou au niveau du cluster :
Idéal pour les travaux de production ou les environnements collaboratifs. Cela permet à tous les notebooks au sein du cluster d'accéder à Soda sans configuration individuelle. Vous pouvez installer soda-spark-df directement dans votre cluster Databricks.
Une fois installé, vous pouvez commencer à utiliser Soda en important et configurant l'objet Scan :
from soda.scan import Scan # US Regions use: cloud.us.soda.io and EU Regions use: cloud.soda.io host = "cloud.soda.io" api_key_id = dbutils.secrets.get(scope = "SodaCloud", key = "keyid") api_key_secret = dbutils.secrets.get(scope = "SodaCloud", key = "keysecret") # Fully qualified table name to run DQ checks on fq_table_name = "unity_catalog.quickstart_schema.customers_daily" # This will be the name of the Data Source that appears in Soda Cloud. # If also using an agent, ensure this value is identical datasource_name = "databricksunitycatalogsql"
Cette configuration connecte directement votre notebook à Soda Cloud, vous permettant de définir des vérifications en YAML ou de les exécuter inline avec du code.
Vous pouvez aussi exécuter des vérifications Soda sur des sources externes comme PostgreSQL — tout cela depuis un notebook Databricks.
Soda vous permet de pousser des vérifications vers Postgres, afin qu'elles s'exécutent dans l'environnement Postgres, sans déplacer les données vers Databricks, économisant ainsi sur les coûts de calcul et de transfert de données.
Si toutes les vérifications passent, vous pouvez alors mettre à jour une table Delta existante dans Databricks.
Pour commencer, installez le connecteur Postgres :
pip install -i https://pypi.cloud.soda.io soda-postgres
Exemples : Exécuter des vérifications Soda dans un Notebook
Lors de l'utilisation de Soda dans un notebook Databricks, vous pouvez générer automatiquement des vérifications par défaut avec une configuration minimale, telles que les valeurs manquantes, les doublons de lignes, la fraîcheur et les changements de schéma.
Pour des validations plus avancées, telles que la réconciliation des données ou la logique métier personnalisée, vous pouvez soit utiliser SodaCL dans le notebook, soit configurer des règles via l'interface Soda Cloud.
Voici un exemple de sortie d'un scan réussi
INFO | Scan summary: INFO | 11/11 checks PASSED: INFO | customer_updated in databricksunitycatalogsql INFO | Total rows should not be 0 [PASSED] INFO | Any changes in the schema [PASSED] INFO | Duplicate Rows [PASSED] INFO | No Missing values in ID [PASSED] INFO | No Missing values in EMAIL [PASSED] INFO | Freshness for
Catalog Unity :
Surveillance de la qualité des données sur l'interface Soda Cloud
Après intégration, Soda peut interagir avec Databricks via l'interface Soda Cloud, permettant aux utilisateurs techniques et non techniques de surveiller les métriques clés et de rester alignés sur la santé des données.
Principalement, vous pouvez surveiller la santé des données en surveillant les métriques DQ prédéfinies et la détection automatique des anomalies.
Surveillance des métriques
Ce tableau de bord donne un résumé en temps réel des métriques des datasets au cours des 7 derniers jours. Les équipes peuvent surveiller des tendances telles que :
Le nombre total de lignes et les changements de nombre de lignes, avec des seuils clairement définis et vérifiés à chaque scan
Les changements de schéma, comme les colonnes ajoutées ou supprimées
Heure de la dernière insertion et horodatages les plus récents, qui sont cruciaux pour le suivi de la fraîcheur et de l'opportunité
Valeurs manquantes par colonne, indiquées en bas comme partie des moniteurs de niveau colonne
Ces métriques aident les équipes à identifier les problèmes tôt, tels que des retards de données inattendus, des changements structurels, ou des fluctuations de volume, sans plonger dans les journaux ou le code.
La vue de détection des anomalies vous permet de surveiller les tendances historiques et de détecter les problèmes de qualité des données en utilisant des seuils statistiques. Ici, le nombre de lignes par partition est suivi au fil du temps, avec les anomalies clairement marquées en rouge. Cela aide à :
Repérer la saisonnalité ou les pics de volume
Détecter la perte de données silencieuse (par ex., partitions non peuplées)
Ajuster la sensibilité des alertes en fonction des modèles opérationnels
Ce tableau de bord est particulièrement utile lors de l’investigation d'un comportement inattendu dans les pipelines, en offrant aux équipes le contexte nécessaire pour poser de meilleures questions ou automatiser la résolution.
Avantages de l'intégration
Au lieu de mettre la charge de la qualité des données sur une seule équipe, Soda en fait un processus collaboratif. Les problèmes deviennent visibles, exploitables et résolvables plus rapidement.
Cela signifie :
Les ingénieurs restent proches des pipelines.
Les utilisateurs métiers restent alignés avec la logique de domaine.
Tout le monde reste sur la même longueur d'onde.
Il permet également de débloquer les avantages suivants :
Évolutivité : Prend en charge nativement Spark et Delta Lake, permettant des vérifications sur des ensembles de données à grande échelle.
Automatisation : S’intègre parfaitement avec Databricks Jobs et Workflows, s'alignant avec les pipelines CI/CD.
Détection Précoce : Signale de manière proactive les dérives de schéma, les pics de nullité et d'autres anomalies avant qu'ils ne s’aggravent.
Gouvernance : Améliore Unity Catalog en ajoutant qualité des données et observabilité à travers les domaines.
Conclusion
Intégrer Soda avec Databricks permet aux équipes data d’intégrer un cadre de qualité des données robuste directement dans leurs workflows. En combinant la puissance de traitement de Databricks avec l'Observabilité des Données de Soda, les organisations peuvent évoluer en toute confiance sans sacrifier la confiance ou la fiabilité.
Dans les entreprises modernes axées sur les données, à mesure que les organisations adoptent des plateformes évolutives comme Databricks, le besoin d'observabilité des données en temps réel et de maintien de pipelines de données fiables devient crucial.
Soda est une plateforme moderne de qualité des données spécialement conçue pour ce défi. Elle propose des vérifications automatisées de la qualité des données via une interface sans code et une intégration programmatique, facilitant ainsi la surveillance et l'amélioration de la fiabilité des données par l'ensemble de l'équipe data.
Avec les tests éprouvés de bout en bout de Soda, une observabilité complète des données (comme la surveillance des métriques et la détection des anomalies) et un workflow de résolution des problèmes soigneusement conçu, les équipes peuvent détecter les problèmes tôt, être alertées instantanément et empêcher que de mauvaises données ne se propagent en aval.
Que vous soyez un ingénieur data intégrant des vérifications dans un notebook Databricks ou un utilisateur métier définissant des règles dans Soda Cloud, chacun contribue sans avoir besoin d'écrire du code.
Cet article vous guide dans l'intégration de Soda avec Databricks, en mettant en avant les avantages pratiques pour les équipes data visant à instaurer la confiance dans leurs pipelines de données.
Présentation de l'intégration
Soda prend en charge deux principales voies d'intégration avec Databricks :
Option 1 : Soda avec Databricks SQL Warehouse
Option 2 : Soda avec PySpark utilisant le package
soda-spark-df
Les deux méthodes permettent aux utilisateurs techniques et non techniques de définir et d'exécuter des vérifications de qualité des données sur des tables Delta Lake ou des Spark DataFrames, offrant flexibilité selon les préférences et les compétences des utilisateurs.
Option 1 : Utiliser Soda avec Databricks SQL Warehouse
Cette approche est idéale pour les équipes travaillant dans des environnements centrés sur SQL. Elle prend en charge :
Soda Agent (surveillance DQ basée sur l'UI)
Soda Library (workflows pipeline basés sur le CLI)
Les deux outils se connectent directement à un Databricks SQL Warehouse en utilisant des paramètres de connexion simples.
Avec Soda Agent (Sans code)
Le Soda Agent est un outil qui permet aux utilisateurs de l'interface web de Soda de se connecter en toute sécurité aux sources de données et de réaliser des scans de qualité des données automatisés.
Configurez la connexion à Databricks via l'interface Soda Cloud pour déclencher automatiquement le service Soda Agent. Cela permet aux équipes de collaborer et de surveiller en continu la qualité des données directement depuis l'interface web.
Suivez ces étapes pour connecter Databricks dans Soda Cloud :
Étape 1 : Dans Soda Cloud, allez dans le coin supérieur droit :
Cliquez sur votre icône de profil → sélectionnez 'Data Sources' → ajoutez 'New Data Source' → configurez 'Attributes' → choisissez 'Databricks Usage Monitor'
Étape 2 : Sur la page 'Databricks Usage Monitor', configurez vos paramètres de connexion Databricks.
Étape 3 : Cliquez sur 'Test Connection' pour vérifier l'intégration réussie entre Databricks et Soda Cloud.
Une fois connecté, vous pouvez :
Ajouter des vérifications de qualité des données intégrées à des sources de données spécifiques
Planifier des scans automatisés
Activer la détection des anomalies en temps réel
Recevoir des alertes DQ en temps opportun
Résoudre des problèmes de manière collaborative via l'interface
Avec Soda Library (Programmatique)
Soda Library est un package Python pour réaliser des scans de qualité des données à la demande — idéal pour les pipelines CI/CD et les validations locales rapides. Il permet aux utilisateurs de définir des vérifications de qualité des données de manière programmatique et d'envoyer les résultats à Soda Cloud.
Vous pouvez utiliser Soda Library pour intégrer Soda à Databricks en suivant ces étapes :
Étape 1 : Installez Soda Library et installez le package soda-spark-df.
pip install -i https://pypi.cloud.soda.io soda-spark[databricks]
Pour plus de détails, consultez ce guide étape par étape : Connectez-vous à Spark pour Databricks SQL
Étape 2 : Préparez deux fichiers YAML pour permettre à Soda de se connecter à Databricks et d'exécuter votre premier scan DQ.
config.yml : contient les détails de connexion pour vos sources de données et votre compte Soda Cloud.
1data_source my_datasource_name: 2 type: spark 3 method: databricks 4 catalog: samples 5 schema: nyctaxi 6 host: hostname_from_Databricks_SQL_settings 7 http_path: http_path_from_Databricks_SQL_settings 8 token: my_access_token 9soda_cloud: 10 host: cloud.soda.io 11 api_key_id: ${API_KEY} 12 api_key_secret: ${API_SECRET} 13checks.yml: stores user-defined checks for routine data validation. 14# Checks for basic validations 15checks for YOUR_TABLE: 16 - row_count between 10 and 1000 17 - missing_count(column_name) = 0 18 - invalid_count(column_name) = 0: 19 valid min: 1 20 valid max: 6
Étape 3 : Tester la connexion
Pour confirmer que vous avez correctement configuré les détails de connexion dans votre fichier de configuration YAML, utilisez la commande test-connection. Si vous le souhaitez, ajoutez une option -V à la commande pour obtenir des résultats en mode verbeux dans le CLI.
soda test-connection -d my_datasource -c config.yml -V
Une fois configuré, les utilisateurs peuvent commencer à surveiller les anomalies et commencer à créer des vérifications définies par l'utilisateur, permettant une validation facile des données selon des règles prédéfinies.
Option 2 : Utiliser Soda avec PySpark dans les Notebooks Databricks
Pour les utilisateurs de PySpark, la bibliothèque soda-spark-df apporte de puissantes vérifications de qualité des données directement dans vos workflows de notebook. Cela rend facile l'intégration de l'observabilité des données dans des pipelines ETL ou ML, sans quitter l'écosystème Databricks.
Vous pouvez commencer immédiatement en utilisant ce notebook d'exemple. Il suffit de définir la table cible, de brancher vos clés API de Soda Cloud, et vous êtes prêt à y aller.
Vous pouvez installer ce package de deux manières :
Installation dans le Notebook :
pip install -i https://pypi.cloud.soda.io soda-spark-df
Ou au niveau du cluster :
Idéal pour les travaux de production ou les environnements collaboratifs. Cela permet à tous les notebooks au sein du cluster d'accéder à Soda sans configuration individuelle. Vous pouvez installer soda-spark-df directement dans votre cluster Databricks.
Une fois installé, vous pouvez commencer à utiliser Soda en important et configurant l'objet Scan :
from soda.scan import Scan # US Regions use: cloud.us.soda.io and EU Regions use: cloud.soda.io host = "cloud.soda.io" api_key_id = dbutils.secrets.get(scope = "SodaCloud", key = "keyid") api_key_secret = dbutils.secrets.get(scope = "SodaCloud", key = "keysecret") # Fully qualified table name to run DQ checks on fq_table_name = "unity_catalog.quickstart_schema.customers_daily" # This will be the name of the Data Source that appears in Soda Cloud. # If also using an agent, ensure this value is identical datasource_name = "databricksunitycatalogsql"
Cette configuration connecte directement votre notebook à Soda Cloud, vous permettant de définir des vérifications en YAML ou de les exécuter inline avec du code.
Vous pouvez aussi exécuter des vérifications Soda sur des sources externes comme PostgreSQL — tout cela depuis un notebook Databricks.
Soda vous permet de pousser des vérifications vers Postgres, afin qu'elles s'exécutent dans l'environnement Postgres, sans déplacer les données vers Databricks, économisant ainsi sur les coûts de calcul et de transfert de données.
Si toutes les vérifications passent, vous pouvez alors mettre à jour une table Delta existante dans Databricks.
Pour commencer, installez le connecteur Postgres :
pip install -i https://pypi.cloud.soda.io soda-postgres
Exemples : Exécuter des vérifications Soda dans un Notebook
Lors de l'utilisation de Soda dans un notebook Databricks, vous pouvez générer automatiquement des vérifications par défaut avec une configuration minimale, telles que les valeurs manquantes, les doublons de lignes, la fraîcheur et les changements de schéma.
Pour des validations plus avancées, telles que la réconciliation des données ou la logique métier personnalisée, vous pouvez soit utiliser SodaCL dans le notebook, soit configurer des règles via l'interface Soda Cloud.
Voici un exemple de sortie d'un scan réussi
INFO | Scan summary: INFO | 11/11 checks PASSED: INFO | customer_updated in databricksunitycatalogsql INFO | Total rows should not be 0 [PASSED] INFO | Any changes in the schema [PASSED] INFO | Duplicate Rows [PASSED] INFO | No Missing values in ID [PASSED] INFO | No Missing values in EMAIL [PASSED] INFO | Freshness for
Catalog Unity :
Surveillance de la qualité des données sur l'interface Soda Cloud
Après intégration, Soda peut interagir avec Databricks via l'interface Soda Cloud, permettant aux utilisateurs techniques et non techniques de surveiller les métriques clés et de rester alignés sur la santé des données.
Principalement, vous pouvez surveiller la santé des données en surveillant les métriques DQ prédéfinies et la détection automatique des anomalies.
Surveillance des métriques
Ce tableau de bord donne un résumé en temps réel des métriques des datasets au cours des 7 derniers jours. Les équipes peuvent surveiller des tendances telles que :
Le nombre total de lignes et les changements de nombre de lignes, avec des seuils clairement définis et vérifiés à chaque scan
Les changements de schéma, comme les colonnes ajoutées ou supprimées
Heure de la dernière insertion et horodatages les plus récents, qui sont cruciaux pour le suivi de la fraîcheur et de l'opportunité
Valeurs manquantes par colonne, indiquées en bas comme partie des moniteurs de niveau colonne
Ces métriques aident les équipes à identifier les problèmes tôt, tels que des retards de données inattendus, des changements structurels, ou des fluctuations de volume, sans plonger dans les journaux ou le code.
La vue de détection des anomalies vous permet de surveiller les tendances historiques et de détecter les problèmes de qualité des données en utilisant des seuils statistiques. Ici, le nombre de lignes par partition est suivi au fil du temps, avec les anomalies clairement marquées en rouge. Cela aide à :
Repérer la saisonnalité ou les pics de volume
Détecter la perte de données silencieuse (par ex., partitions non peuplées)
Ajuster la sensibilité des alertes en fonction des modèles opérationnels
Ce tableau de bord est particulièrement utile lors de l’investigation d'un comportement inattendu dans les pipelines, en offrant aux équipes le contexte nécessaire pour poser de meilleures questions ou automatiser la résolution.
Avantages de l'intégration
Au lieu de mettre la charge de la qualité des données sur une seule équipe, Soda en fait un processus collaboratif. Les problèmes deviennent visibles, exploitables et résolvables plus rapidement.
Cela signifie :
Les ingénieurs restent proches des pipelines.
Les utilisateurs métiers restent alignés avec la logique de domaine.
Tout le monde reste sur la même longueur d'onde.
Il permet également de débloquer les avantages suivants :
Évolutivité : Prend en charge nativement Spark et Delta Lake, permettant des vérifications sur des ensembles de données à grande échelle.
Automatisation : S’intègre parfaitement avec Databricks Jobs et Workflows, s'alignant avec les pipelines CI/CD.
Détection Précoce : Signale de manière proactive les dérives de schéma, les pics de nullité et d'autres anomalies avant qu'ils ne s’aggravent.
Gouvernance : Améliore Unity Catalog en ajoutant qualité des données et observabilité à travers les domaines.
Conclusion
Intégrer Soda avec Databricks permet aux équipes data d’intégrer un cadre de qualité des données robuste directement dans leurs workflows. En combinant la puissance de traitement de Databricks avec l'Observabilité des Données de Soda, les organisations peuvent évoluer en toute confiance sans sacrifier la confiance ou la fiabilité.
Trusted by the world’s leading enterprises
Real stories from companies using Soda to keep their data reliable, accurate, and ready for action.
At the end of the day, we don’t want to be in there managing the checks, updating the checks, adding the checks. We just want to go and observe what’s happening, and that’s what Soda is enabling right now.

Sid Srivastava
Director of Data Governance, Quality and MLOps
Investing in data quality is key for cross-functional teams to make accurate, complete decisions with fewer risks and greater returns, using initiatives such as product thinking, data governance, and self-service platforms.

Mario Konschake
Director of Product-Data Platform
Soda has integrated seamlessly into our technology stack and given us the confidence to find, analyze, implement, and resolve data issues through a simple self-serve capability.

Sutaraj Dutta
Data Engineering Manager
Our goal was to deliver high-quality datasets in near real-time, ensuring dashboards reflect live data as it flows in. But beyond solving technical challenges, we wanted to spark a cultural shift - empowering the entire organization to make decisions grounded in accurate, timely data.

Gu Xie
Head of Data Engineering
4,4 sur 5
Commencez à faire confiance à vos données. Aujourd'hui.
Trouvez, comprenez et corrigez tout problème de qualité des données en quelques secondes.
Du niveau de la table au niveau des enregistrements.
Adopté par
Product








Trusted by the world’s leading enterprises
Real stories from companies using Soda to keep their data reliable, accurate, and ready for action.
At the end of the day, we don’t want to be in there managing the checks, updating the checks, adding the checks. We just want to go and observe what’s happening, and that’s what Soda is enabling right now.
Sid Srivastava
Director of Data Governance, Quality and MLOps
Investing in data quality is key for cross-functional teams to make accurate, complete decisions with fewer risks and greater returns, using initiatives such as product thinking, data governance, and self-service platforms.
Mario Konschake
Director of Product-Data Platform
Soda has integrated seamlessly into our technology stack and given us the confidence to find, analyze, implement, and resolve data issues through a simple self-serve capability.
Sutaraj Dutta
Data Engineering Manager
Our goal was to deliver high-quality datasets in near real-time, ensuring dashboards reflect live data as it flows in. But beyond solving technical challenges, we wanted to spark a cultural shift - empowering the entire organization to make decisions grounded in accurate, timely data.
Gu Xie
Head of Data Engineering
4,4 sur 5
Commencez à faire confiance à vos données. Aujourd'hui.
Trouvez, comprenez et corrigez tout problème de qualité des données en quelques secondes.
Du niveau de la table au niveau des enregistrements.
Adopté par
Product
Solutions
Trusted by the world’s leading enterprises
Real stories from companies using Soda to keep their data reliable, accurate, and ready for action.
At the end of the day, we don’t want to be in there managing the checks, updating the checks, adding the checks. We just want to go and observe what’s happening, and that’s what Soda is enabling right now.
Sid Srivastava
Director of Data Governance, Quality and MLOps
Investing in data quality is key for cross-functional teams to make accurate, complete decisions with fewer risks and greater returns, using initiatives such as product thinking, data governance, and self-service platforms.
Mario Konschake
Director of Product-Data Platform
Soda has integrated seamlessly into our technology stack and given us the confidence to find, analyze, implement, and resolve data issues through a simple self-serve capability.
Sutaraj Dutta
Data Engineering Manager
Our goal was to deliver high-quality datasets in near real-time, ensuring dashboards reflect live data as it flows in. But beyond solving technical challenges, we wanted to spark a cultural shift - empowering the entire organization to make decisions grounded in accurate, timely data.
Gu Xie
Head of Data Engineering
4,4 sur 5
Commencez à faire confiance à vos données. Aujourd'hui.
Trouvez, comprenez et corrigez tout problème de qualité des données en quelques secondes.
Du niveau de la table au niveau des enregistrements.
Adopté par
Product
Solutions
Company