
L'année dernière, nous avons lancé Soda SQL pour aider les ingénieurs de données à maintenir des pipelines de données fiables en production à l'aide d'un framework open-source. Il a été conçu pour exceller dans trois domaines avec des données accessibles via SQL : profiler, tester et surveiller les données.
C'était notre premier projet open-source visant à permettre aux ingénieurs de données de surveiller leurs flux de travail décisionnels critiques, sans la lutte de maintenir des solutions de test de données lourdes et artisanales.
Soda SQL a utilisé une combinaison d'entrée YAML et de requêtes SQL axées sur la fiabilité des données. Nous avons misé sur SQL pour trois raisons principales :
il vous permettait de laisser vos données exactement là où elles étaient, il offrait beaucoup de flexibilité, SQL est un langage de programmation populaire
il vous permettait de laisser vos données exactement là où elles étaient
il offrait beaucoup de flexibilité
SQL est un langage de programmation populaire
Vous pouvez en savoir plus dans mon article de blog qui a annoncé le lancement de Soda SQL l'année dernière dans la communauté.
Nous avons observé l'adoption de Soda SQL augmenter et avons fièrement vu la communauté Soda grandir et évoluer en un canal engageant. Mon expérience précédente dans la construction de projets open-source chez Activiti et jBPM m'a appris la valeur de la communauté et combien il est amusant de construire quelque chose ensemble.
Cela m'a également appris l'importance d'écouter et d'apprendre des utilisateurs. Avec l'open-source, bien sûr, nous ne connaissons pas chaque ingénieur ou organisation qui fait des milliers de téléchargements quotidiens, cependant, nous sommes en mesure de compter Disney, HelloFresh et Udemy parmi les principaux contributeurs à avoir déployé les outils de fiabilité des données de Soda et soutenu le développement de nos projets.
Ce qui était vrai alors l'est encore plus maintenant : la qualité des données est un sport d'équipe, et toute personne ayant un intérêt dans les données (c'est-à-dire tout le monde dans l'entreprise) doit la comprendre, lui faire confiance et rester à jour.
Presque toutes les entreprises automatisent des processus et créent de nouveaux produits et services innovants à l'aide de données, mais le défi principal pour les équipes de toute l'organisation est d'avoir des données suffisamment fiables pour répondre à ces besoins complexes et en évolution. En fournissant des capacités de test de données SQL open-source hautement configurables, nous avons fait le premier pas pour habiliter les ingénieurs de données avec les bons outils pour relever ces défis et établir une base solide de qualité de données fiable.
Mais nous savions qu'il y avait plus que nous pouvions faire pour mieux servir les ingénieurs de données et les analystes du monde entier, qui se retrouvent souvent à éteindre des incendies lorsque les rapports, les tableaux de bord ou les modèles d'apprentissage automatique se brisent.
Alors que notre équipe d'ingénieurs de données interagissait avec notre communauté et que nous observions l'utilisation et l'évolution de Soda SQL (et ses frères et sœurs Soda Spark et Soda Streaming) en production, il est devenu évident que nous devions passer au niveau supérieur. Nos utilisateurs ont confirmé que ce que nous avions était bon - ou génial, par rapport aux solutions existantes - mais leur plus grand défi était de permettre à leurs entreprises de maintenir la propriété et d'être responsables de leurs données.
Et c'est pourquoi Milan Lukac, Vijay Kiran, et moi avons passé les mois suivants à construire un nouveau langage spécifique au domaine pour la fiabilité des données en tant que code.
Pas un autre DSL
Je sais, "pourquoi le monde a-t-il besoin d'un autre langage spécifique au domaine ?" La question laisse entendre le fardeau perçu d'apprendre une autre langue et, horreur des horreurs, le verrouillage fournisseur. Nous savons, nous comprenons - ce sont les mêmes préoccupations que nous aurions aussi si nous envisagions d'utiliser un nouvel outil. Écoutez-moi bien.
Avec un langage spécifique au domaine, vous devez généralement faire face aux difficultés d'intégrer un nouveau DSL dans des systèmes existants et de travailler avec une faible offre de matériel de support et de praticiens. Et ce DSL n'éviterait pas magiquement ces défis, mais la fiabilité des données nécessite sa propre langue. Il a besoin d'une langue suffisamment spécifique pour s'attaquer aux problèmes que rencontrent les équipes de données, suffisamment accessible pour être utilisée par des non-ingénieurs et suffisamment flexible pour plonger dans beaucoup de types de données différents pour trouver, analyser et résoudre rapidement les problèmes. À long terme, cela vaudra l'investissement en capital à court terme de temps et d'efforts.
Outre le très réel besoin d'une langue de fiabilité des données, un nouveau DSL pourrait être ce qui débloque les tâches lourdes de détection et de résolution des problèmes de données, et alerter automatiquement les bonnes personnes au bon moment. Cet article de opensource.com intitulé Ce que les développeurs doivent savoir sur les langages spécifiques au domaine a renforcé notre enthousiasme lorsque nous envisagions initialement l'idée, nous oser imaginer Une Meilleure Façon de Faire Les Choses. C'est un geste audacieux, mais nous pensons qu'il est grand temps que les équipes de données et les outils qu'elles utilisent reçoivent une attention audacieuse et vivifiante.
Et c'est ainsi qu'est né un nouveau DSL open-source Soda : un langage lisible par l'humain qui révolutionnera la façon dont les équipes configurent et maintiennent des produits de données fiables et de haute qualité.
Nous savons qu'il y a des milliers de membres d'équipes de données qui recherchent une méthode simplifiée pour détecter, trier, diagnostiquer et résoudre les problèmes de qualité des données tout au long du cycle de vie des produits de données. Alors que les équipes de données cherchent à opérationnaliser les produits de données, cela pourrait être un véritable changeur de jeu.
L'ascension du Data Mesh
Je pense que nous assistons à une révolution dans la façon dont les données et les équipes de données fonctionnent au sein des organisations. D'après nos observations, nous avons vu les équipes de données changer leur façon de s'organiser : dans un data mesh, les équipes sont construites par domaine.
C'est un concept intéressant, à propos duquel un livre provocateur est en cours d'écriture (voir Data Mesh : Delivering Data-Driven Value at Scale de Zhamak Dehghani), et à mon avis, le data mesh s'aligne bien avec les technologies modernes de données d'aujourd'hui. Peu de personnes dans le domaine de la gestion des données n'explorent, n'adoptent, n'interprètent ou ne parlent pas du data mesh.
Voici comment Zhamak le décrit dans notre Podcast Data Dream Team avec Jesse Anderson :
"...le data mesh est vraiment une approche qui affecte à la fois la structure organisationnelle et l'architecture dans la gestion et le partage des données pour les cas d'utilisation analytique. [...] au cœur de cela c'est une approche décentralisée [...] qui croit à s'assurer que nos domaines - prenez les domaines de la ligne de métier - aient la responsabilité et le soutien pour partager des données, utiliser les données à des fins analytiques. [...] Donc, le cœur de cela est l'idée de la décentralisation du partage des données vers les domaines."
L'idée de « décentralisation du partage des données » résonne avec moi. Il est logique que la propriété des données soit partagée entre les équipes de domaines de données - des équipes composées d'ingénieurs de données, de propriétaires de produits de données et de scientifiques de données et d'analystes - et que ces équipes prennent en charge la qualité de leurs données.
Dans cet environnement, nous avons vu des équipes de domaines de données établir des objectifs de niveau de service ou des accords de niveau de service avec les consommateurs des produits de données. Ces accords fixent les attentes entre les domaines, afin que toute personne souhaitant utiliser les données pour créer un tableau de bord ou alimenter un algorithme d'apprentissage automatique ait une compréhension claire des données sur lesquelles elle travaille et puisse avoir confiance que les données sont opportunes, valides, précises et complètes. Que les données soient fiables.
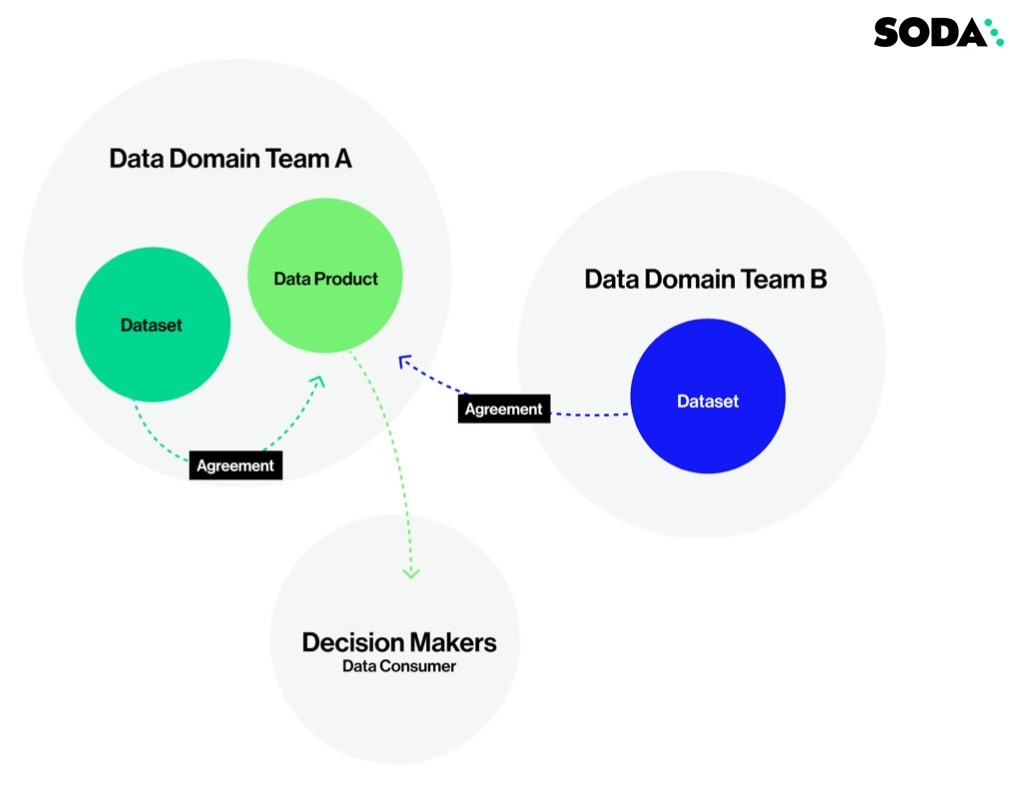
Les accords permettent aux producteurs et consommateurs de données de s'aligner sur les attentes en matière de qualité des données.
Comme Zhamak l'explique : « La promesse du data mesh de l'évolutivité ne peut être remplie que si le cycle de vie d'un produit de données peut être géré de manière autonome, lorsqu'un produit de données peut être construit, testé, déployé et exécuté sans friction et avec un impact limité sur d'autres produits de données. Cette promesse doit rester vraie alors même qu'il y a une interconnexion entre les produits de données — à travers leurs ports d'entrée et de sortie de données, le partage de données, ou les schémas. »[1]
SodaCL : Un langage de fiabilité des données pour le data mesh
Après avoir écouté nos utilisateurs et avoir été inspirés par nos observations d'organisations évoluant vers un data mesh, nous avons été encore plus encouragés à construire un DSL dont la fiabilité des données a besoin : SodaCL. Notre rêve collectif est que le langage des contrôles Soda devienne la norme open-source pour la fiabilité des données.

Dans l'image ci-dessus, Leslie et Will créent un accord qui garantit que les données pour le modèle de churn des clients de l'entreprise de Leslie sont fraîches et opportunes et que les enregistrements anormaux sont scrutés avant que les données ne soient livrées.
Je ne peux m'empêcher de dire que je suis vraiment fier de ce que notre équipe a accompli avec notre première itération de notre langage conçu à cet effet.
Tester et surveiller les contrôles de données en tant que code. Vous pouvez configurer des contrôles dynamiques, gérer les contrôles de données en tant que code depuis l'ingestion jusqu'à la transformation, et vous pouvez gérer les fichiers de contrôle en utilisant Git.
Profitez de plus de 30 types de contrôles intégrés. Obtenez de la valeur immédiatement en utilisant les métriques que nous avons intégrées dans le langage. Lorsque les choses deviennent plus compliquées, vous pouvez toujours revenir aux métriques SQL pour accomplir le travail.
Permettez à vos collègues de s'auto-servir. Tous les problèmes de données ne sont pas liés à l'ingénierie. Avec un langage intuitif et lisible par l'humain, tout le monde peut définir ce qui constitue de bonnes données, ce qui libère du temps précieux pour l'ingénierie.
Et ce n'est que le début !
Comme le français est la langue de l'amour, SodaCL est la langue de la fiabilité des données
Nos outils de fiabilité et d'observabilité des données sont construits par des ingénieurs de données et des propriétaires de produits, tous ayant une expérience de première main dans la construction de systèmes fiables produisant des données de haute qualité.
Nous savons que les équipes de données ont besoin d'un langage de fiabilité des données accessible via la ligne de commande et suffisamment flexible pour être intégré dans un environnement technique, tel que Airflow ou Prefect. Plus important encore, nous savons que les ingénieurs ont besoin d'une solution extensible offrant transparence et contrôle total.
Pourtant, comme Maarten Masschelein, PDG de Soda et mon co-fondateur, m'a toujours rappelé, et à toute l'équipe, notre bénéficiaire ultime est l'analyste des données, le consommateur des données. Nous devons permettre aux analystes de se servir complètement, car lorsqu'un analyste peut écrire ses propres contrôles de qualité des données, une entreprise peut vraiment commencer à évoluer dans la couverture de fiabilité des données.
Où les analystes de données dépendent fortement des ingénieurs de données pour implémenter des contrôles de données, il est impossible de croître sans rencontrer les goulots d'étranglement qui peuvent paralyser l'entreprise. Pour chaque organisation qui s'appuie sur les données pour générer des revenus grâce à une prise de décision confiante, chaque minute de disponibilité des données compte.
En utilisant SodaCL, les analystes équipés des connaissances sur le domaine des données peuvent simplement rédiger leurs propres contrôles, analyser les incidents et résoudre les problèmes afin que la qualité des données reste fiable et disponible à tout moment.
Besoin de vérifier les doublons ? Facile :
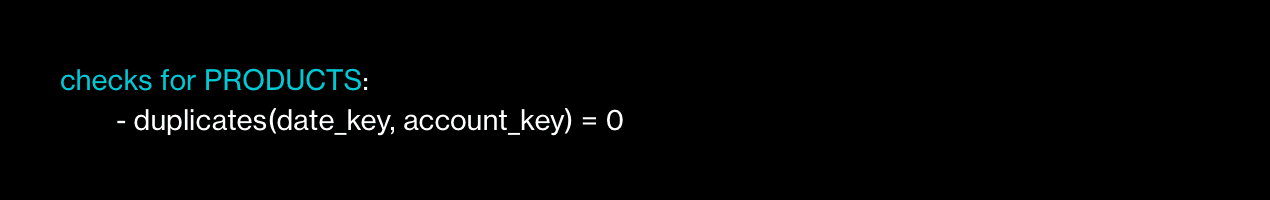
Comparer les comptes de lignes entre les sources de données ? Compris :

Obtenez un avertissement lorsqu'un schéma de jeu de données change ? Pas de problème :
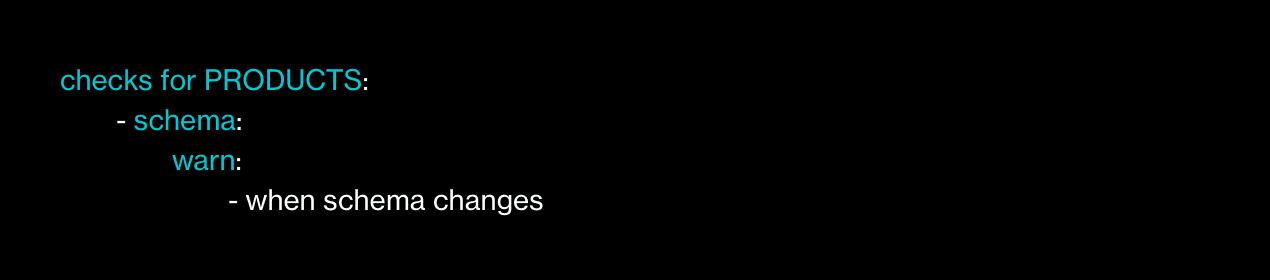
Ces métriques intégrées rendent beaucoup plus facile pour un plus large éventail de personnes de participer au travail d'établissement et de maintien de la qualité des données. Et là où ça devient difficile, où les métriques intégrées ne peuvent pas atteindre suffisamment loin dans la complexité des données pour vérifier ce qui doit être vérifié, un ingénieur de données ou un autre expert SQL peut intervenir et ajouter leurs propres requêtes SQL en utilisant le même cadre linguistique.
Équipes de données, écoutez-nous haut et clair : SodaCL a été construit pour rendre votre vie plus facile et vos données fiables.
Je voudrais apprendre au monde à coder en parfaite harmonie
Comme mentionné ci-dessus, les métriques intégrées prêtes à l'emploi de SodaCL visent à économiser du temps et des ressources. Votre équipe entière peut utiliser ces métriques pour écrire des contrôles faciles pour les ingénieurs de données à implémenter et qui réduisent le temps à valeur ajoutée en évitant d'avoir à écrire une tonne de SQL.
Voici un échantillon de plus de 30 métriques que nous avons incluses dans SodaCL, basées sur les problèmes de données les plus courants et fréquents qui affectent aujourd'hui les équipes de données.
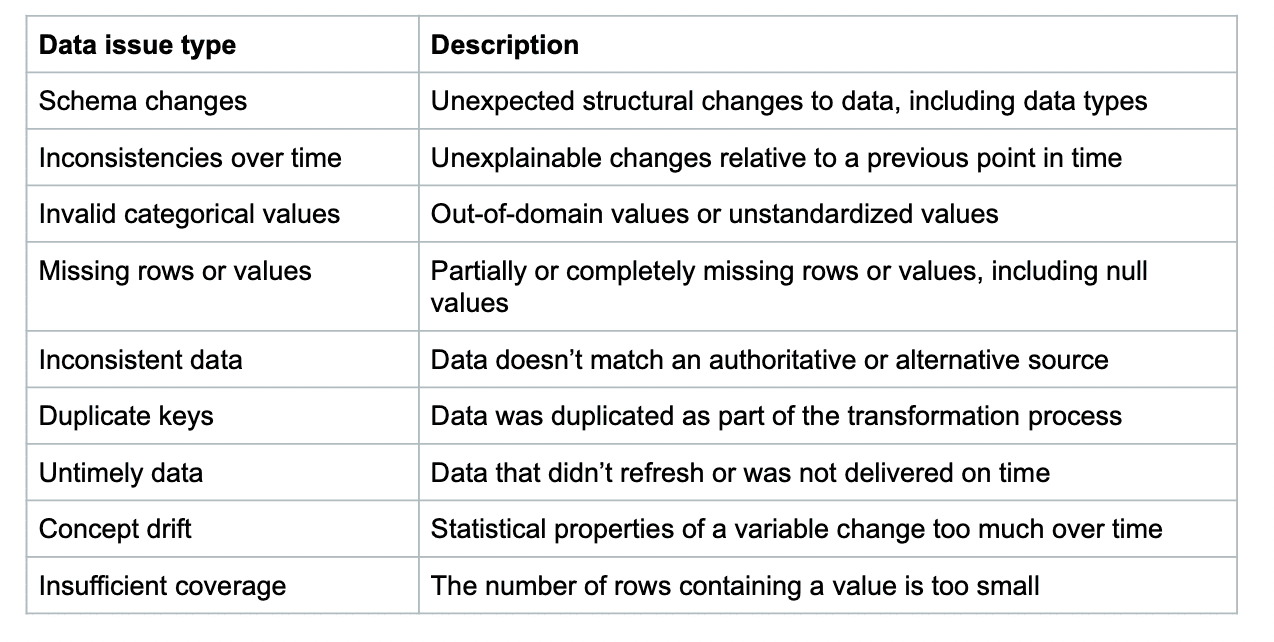
Les métriques que nous avons choisies d'inclure dans SodaCL sont distillées d'une liste de plus de 80 métriques que nous avons rassemblées auprès de nos utilisateurs de la communauté Soda. Nous avons également référencé les types de problèmes de données standard auprès d'associations telles que DAMA le définisseur original des principes de gouvernance des données.
En outre, nous avons étudié des organisations de pointe telles qu'Airbnb, Netflix et Uber pour adopter certaines de leurs meilleures pratiques et sagesse en matière de gestion des données. Alors que nous continuons à étudier des exemples réels et à recueillir plus d'entrées de nos utilisateurs, nous continuerons à étendre la bibliothèque de métriques intégrées de SodaCL.
Développer XaC (Tout en code)
Un langage de fiabilité des données peut aider à unifier les équipes de données tout au long du cycle de vie des produits de données et leur permettre de spécifier ce à quoi ressemblent de bonnes données, indépendamment des rôles, des compétences ou de l'expertise en la matière.
Mais un langage de fiabilité des données en tant que code?
Je ne suis pas sûr de pouvoir mieux le formuler qu'Adrian Bridgewater, journaliste technologique qui suit les développeurs et les données chez Computer Weekly, Forbes et IDG Connect, lorsqu'il écrit :
“[...] « Bien sûr, le code conduira tout ; c'est pourquoi nous construisons des applications, établissons des procédures de base de données et regardons vers l'avenir lorsque l'intelligence artificielle (IA) sortira enfin des films », a déclaré n'importe quel développeur de logiciels dans les années 1980 et probablement la plupart d'entre eux dans les années 1990 également.”
Tout en tant que code se trouve aujourd'hui à la base des pratiques logicielles et nous avons pu valider notre approche avec certains de nos partenaires d'intégration, tels que dbt. Eux aussi croient à rendre les équipes de données plus efficaces avec le code et leur éthique favorise le code par rapport à l'interface graphique.
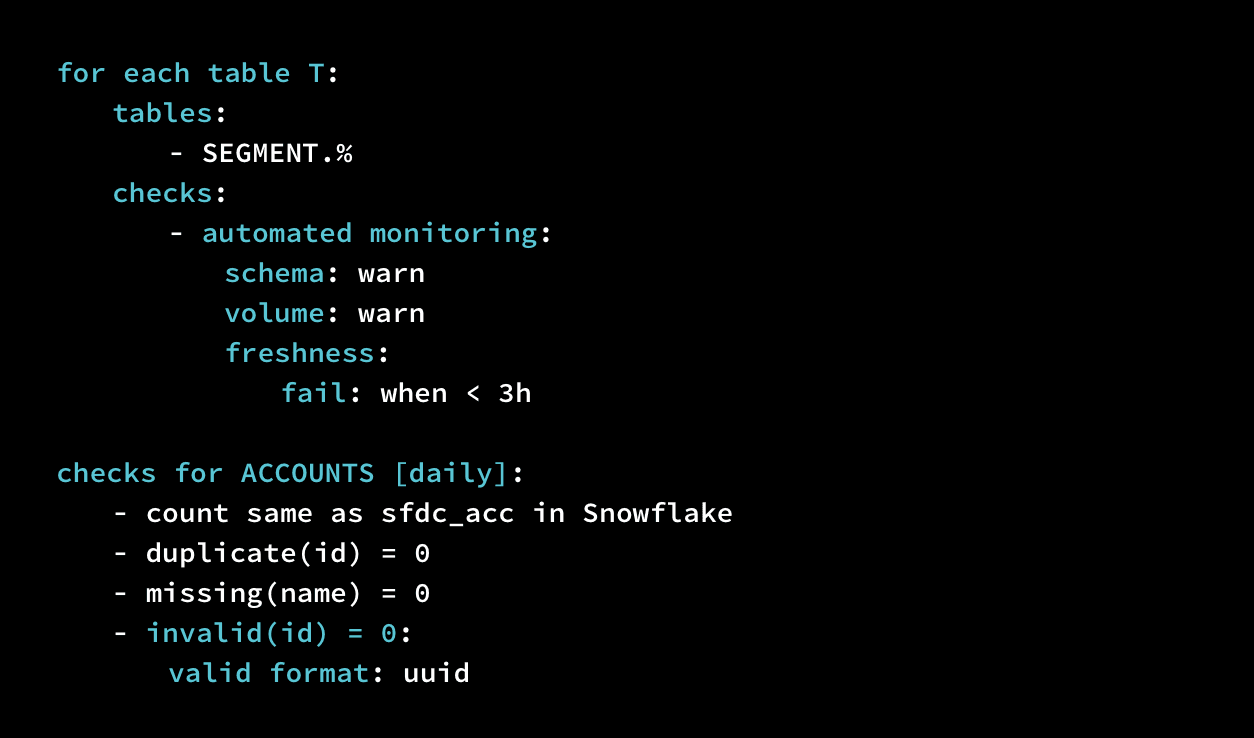
Utilisez SodaCL pour exécuter les mêmes contrôles pour chaque jeu de données dans une source de données.
Bien sûr, une telle autonomie et fonctionnalité en libre-service nécessite des garde-fous et une gouvernance qui permettent à chacun de travailler en toute sécurité et confortablement avec du code. À cette fin, SodaCL a adopté les principes de la gouvernance computationnelle [2], intégrant les normes et politiques globales auxquelles doivent adhérer tous les domaines de données. Cela libère l'utilisateur de SodaCL pour se concentrer sur la définition de données de bonne qualité, la construction de produits de données fiables et le rapprochement de tout le monde de leurs données.
Dans l'un des articles d'Adrian, il conclut que :
“Notre monde est maintenant dominé par le cloud, le code et les données. Avec le tout-en-code faisant avancer les solutions de données, il sera important de garder un œil sur l'avenir de l'innovation des données.”
Et voilà, ça commence
Pour commencer à obtenir des retours sur notre première version fonctionnelle de SodaCL, nous avons lancé un programme de prévisualisation qui garantira que nous prenons les mesures responsables pour nous assurer que nous faisons bien les choses pour les ingénieurs de données. Nous avons eu du mal à contenir notre excitation à propos de la sortie de cette nouvelle approche innovante pour collaborer sur la fiabilité des données, et nous sommes donc heureux de trouver un moyen de la partager avec la communauté dans l'esprit de l'open-source !
Voici un enregistrement de Vijay Kiran, notre ingénieur data principal, offrant aux participants du programme de prévisualisation un aperçu de SodaCL en action.
Si vous êtes déjà un utilisateur de Soda et que vous souhaitez en savoir plus, contactez notre équipe de succès client.
Si vous êtes nouveau sur Soda et que vous souhaitez rejoindre le programme de prévisualisation, veuillez vous inscrire ci-dessous et nous vous répondrons sous 48 heures.
En attendant, nous serons occupés à peaufiner les derniers détails pour rendre SodaCL généralement disponible dans seulement quelques semaines. L'excitation est palpable ! Rejoignez la communauté Soda sur Slack poure être parmi les premiers à savoir quand SodaCL sortira!











