
Au cours des cinq dernières années, nous avons constaté une immense afflux d'ingénieurs logiciels dans le domaine des données. Les données étaient, et sont toujours, très en vogue. Mon co-fondateur Tom, était l'un de ces ingénieurs. Attirés par des problèmes complexes et à fort impact, de nombreux ingénieurs logiciels ont rapidement réalisé que, bien que certains systèmes étaient incroyablement sophistiqués, d'autres étaient inexistants. Les meilleures pratiques que les ingénieurs logiciels avaient adoptées comme pratiques courantes n'étaient pas encore présentes dans le domaine des données, et cela causait beaucoup de maux de tête aux équipes construisant et opérationnalisant des produits de données - automatisations axées sur les données.
Nous avons également vu l'essor du modern data stack – des outils et technologies répondant aux besoins des équipes de données – exploser. Cette demande s'accompagne d'un changement de paradigme – oui, je parle de data mesh – dans la façon dont nous nous gérons et nous organisons à grande échelle autour des données. Avec toute cette innovation et ce développement, cela me fait sourire de penser que nous approchons d'une ère du post-modern data stack.
C'est Une Nouvelle Aube
Encore aujourd'hui, il y a beaucoup de travail fondamental à accomplir. Vous souvenez-vous d'il y a quelques années quand les statistiques à la une portaient sur le temps que les data scientists passaient à nettoyer et préparer les données pour entraîner leurs modèles ? Quatre-vingts pour cent. 80% ! Cela ne leur laissait que vingt pour cent de leurs heures de travail pour réaliser de véritables prouesses avec les données. Il n'a pas fallu longtemps pour que l'industrie réalise que plus de travail fondamental était nécessaire pour soulager ces douleurs. Un travail que seuls les ingénieurs de données pouvaient accomplir.
Dans la plupart des équipes, les ingénieurs de données sont responsables de la construction de systèmes et de pipelines pour ingérer, modéliser et livrer des produits de données à l'entreprise. Les produits de données sont devenus essentiels pour créer un avantage compétitif, permettant à une organisation de fournir des expériences client agréables ou d'explorer de nouveaux marchés.
Mais construire et maintenir des produits de données n'est pas une tâche facile. Une fois en production, les produits de données nécessitent une attention constante pour répondre aux changements de schémas et de structures de données, aux logiques de transformation cassées et aux dérives conceptuelles, qui affectent tous la fiabilité, la qualité et, en fin de compte, la confiance dans les données.
Et Le Sondage Dit…
Le rôle d'un ingénieur de données, à mon avis, est l'un des rôles les plus cruciaux dans une équipe de données. Il implique souvent la tâche incessante de corriger manuellement les problèmes de données qui ont déjà eu un impact en aval sur l'entreprise. Lorsque des rapports ou des modèles d'apprentissage automatique se brisent, l'avenir des revenus et du succès d'une organisation peut dépendre entièrement des ingénieurs de données luttant contre les problèmes de qualité des données qui causent ces problèmes. Lorsque cette alarme retentit, ils doivent s'empresser de découvrir ce qui a été cassé et ce qui a été impacté.
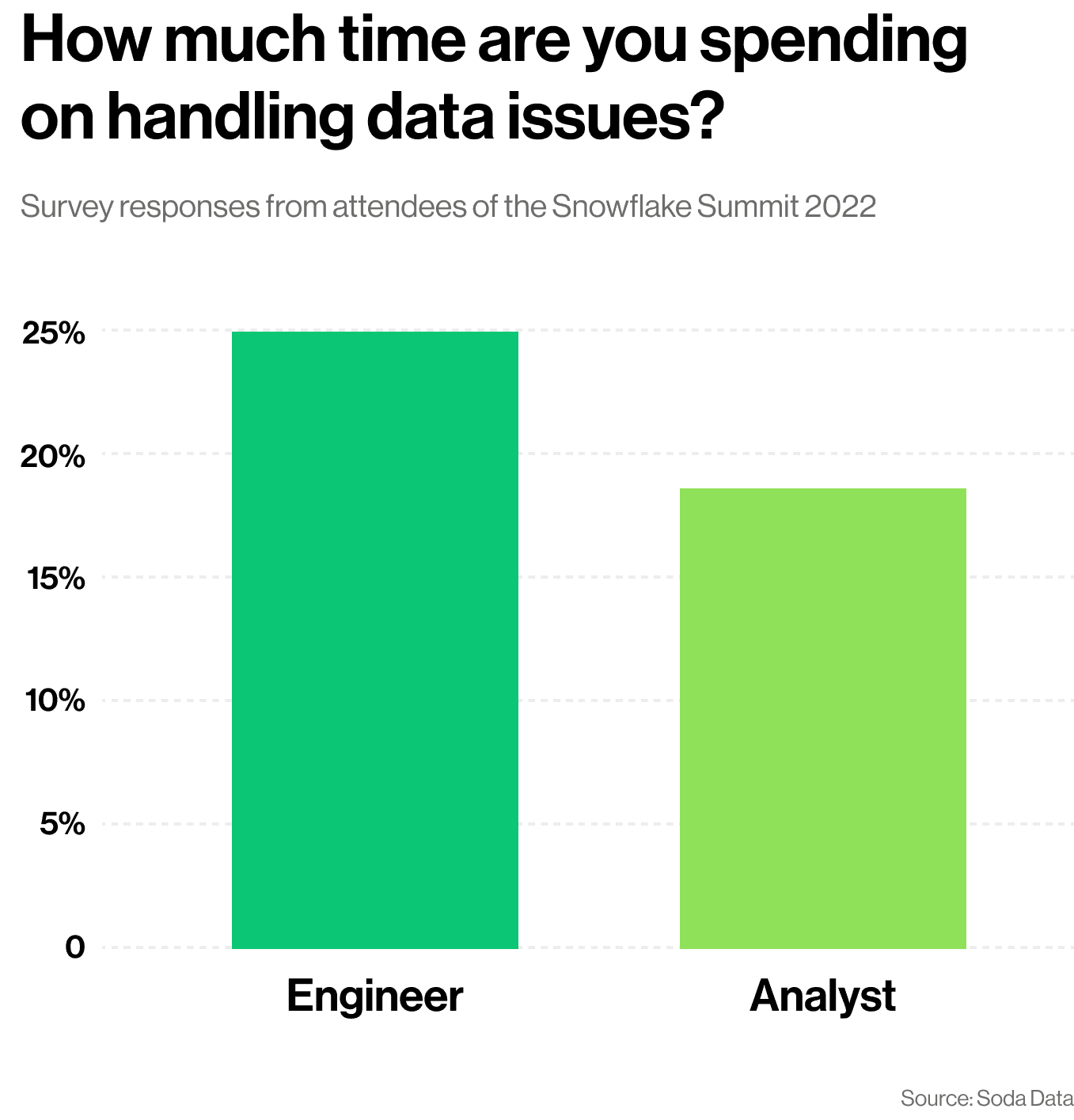
Un sondage récent mené par Soda lors du Snowflake Summit 2022 a montré que les ingénieurs de données passent en moyenne environ vingt-cinq pour cent de leur temps à gérer des problèmes de données. Pour les analystes de données, c'était environ vingt pour cent de leur temps.
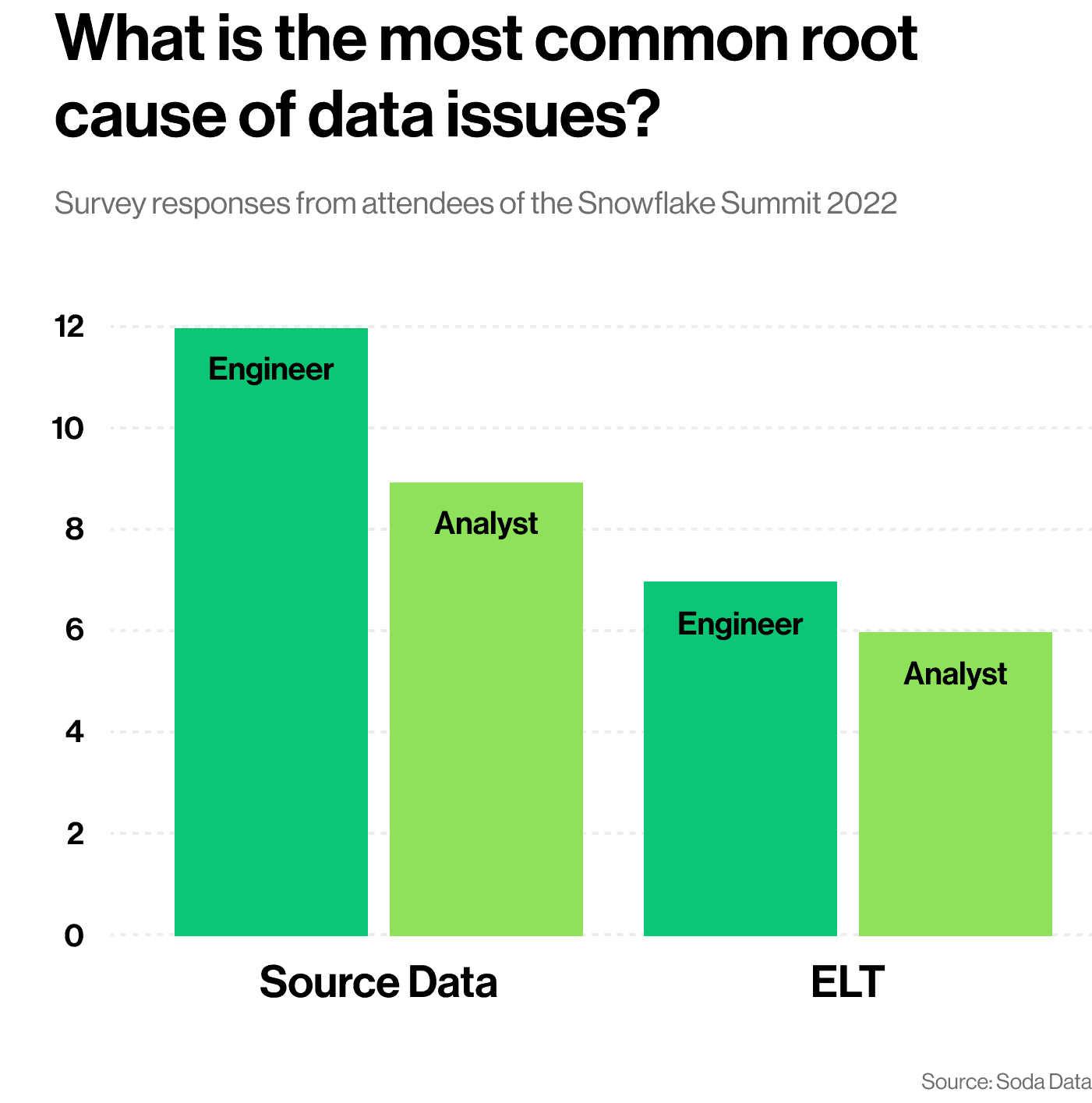
Lorsqu'un problème de données est détecté, dans soixante-deux pour cent des cas, la cause première se trouve à la source des données.
Au fur et à mesure que le nombre de sources et de types de données que les entreprises accumulent continue de croître en volume et en complexité – données de première partie générées en interne, données de deuxième partie produites par des collaborations, données de troisième partie acquises à l'externe – il devient facile de voir pourquoi nous avons besoin d'une meilleure façon de gérer les changements de données.
L'une des questions que nous avons posées dans notre sondage au Snowflake Summit 2022 était
“Quel est le goulet d'étranglement lorsqu'il s'agit d'analyser et de résoudre des problèmes de données ?”
L'écrasante majorité des réponses que nous avons reçues pointaient du doigt le manque d'outils, de processus, et d'expertise pour créer des ensembles de données plus fiables et de haute qualité.
Le coût et l'impact des temps d'arrêt des données signifient une perturbation de l'entreprise, une perte de revenus, une perte de productivité, des problèmes réglementaires ou de conformité, une diminution de la rétention des clients et une baisse de la satisfaction des employés. Plus important encore, les temps d'arrêt des données signifient un scepticisme accru envers les données elles-mêmes.
Apporter l'Ingénierie de Fiabilité aux Données
En 2021, nous avons lancé Soda SQL pour aider les ingénieurs de données à maintenir des pipelines de données fiables en production en utilisant un cadre open-source. Plus tôt cette année, nous avons annoncé notre engagement continu à mieux servir les équipes avec le lancement d'un nouveau langage spécifique au domaine pour la fiabilité des données, et un cadre open-source amélioré. Le nouveau cadre permet aux équipes de données de vérifier les données comme un code, à travers chaque charge de travail de données, de l'ingestion à la transformation jusqu'à la consommation.
Tom a écrit un article de blog qui plonge dans les détails du Soda Checks Language.
Introduire un nouveau langage spécifique au domaine pour alimenter notre cadre open-source est un mouvement audacieux ! Mais en écoutant notre communauté et en analysant le paysage, nous savions que ce serait la clé pour permettre aux équipes de données de tenir la promesse d'une bonne qualité de données.
Et ainsi, roulement de tambour s'il vous plaît, permettez-moi de vous présenter la disponibilité générale de Soda Core, le cadre pour la qualité et la fiabilité des données !
L'Ingénierie des Données Devient Beaucoup Plus Facile
Maintenant généralement disponible, Soda Core est un cadre open-source pour les ingénieurs de données afin de commencer et d'évoluer avec l'ingénierie de fiabilité et la gestion de la qualité des données. Alimenté par Soda Checks Language (SodaCL), il libère des tâches fastidieuses de détection et de résolution des problèmes de données, et alerte automatiquement les bonnes personnes au bon moment.
SodaCL est puissant, lisible et inscriptible par les humains, et facile à configurer. Nous savons qu'il changera la façon dont les ingénieurs de données livrent des produits de données fiables.
Laissez-moi plonger dans les composants qui peuvent être intégrés dans votre architecture de données existante, et pourquoi ils sont importants.
Les Composants Importants
Profilage et classification des données
Utilisez les métadonnées des ensembles de données pour comprendre la forme des données - examinez et analysez des caractéristiques, y compris, mais sans s'y limiter, la moyenne, le minimum, le maximum, le centile, et la fréquence. Capturez les informations historiques sur la santé des données pour former une ligne de base et soutenir le test intelligent des données, à travers chaque charge de travail.
Métriques et vérifications
Utilisez des métriques et vérifications intégrées pour valider un grand nombre de paramètres de qualité des données. Les vérifications testent vos données, généralement dans le cadre du processus de livraison des données, après une transformation des données ou dans le cadre d'un accord de partage de données.
Créez une couverture large de vérifications pour faire ressortir le plus grand éventail de problèmes de qualité des données. Et, parce que chaque entreprise est différente, vous pouvez utiliser des vérifications définies par l'utilisateur pour répondre à des vérifications plus complexes et spécifiques au domaine pour la qualité des données.
Seuils fixes et dynamiques
Accédez aux mesures historiques et écrivez des tests qui les utilisent en une seule ligne de SodaCL. Testez et validez les données avec des systèmes de seuils dynamiques comme le changement au fil du temps et la détection des anomalies, dans le cadre d'un workflow complet de bout en bout qui aide à détecter et résoudre les problèmes, et alerte automatiquement les bonnes personnes au bon moment.
Alertes et notifications
Envoyez des alertes à vos systèmes de ticket ou de garde préférés. Tous les problèmes de données ne sont pas liés à l'ingénierie, il arrive donc un moment où les producteurs et consommateurs de données doivent également s'impliquer.
En élargissant Soda Core avec un compte Soda Cloud, vous pouvez router des notifications aux bonnes personnes et permettre aux utilisateurs moins techniques de s'impliquer en ajustant des seuils ou en ajoutant de nouvelles vérifications. Parce qu'il n'y a qu'un seul langage - inscriptible et lisible par (presque) tout le monde - tout le monde peut définir les seuils de ce à quoi ressemble une bonne qualité de données.
Jetons un coup d'œil à quelques exemples concrets :
Vérification Un, Vérification Deux
Vérifiez les données pendant le développement et en production
Lorsque les données passent des systèmes opérationnels aux systèmes analytiques, testez chaque étape du parcours pour détecter les problèmes imprévus. Tester les données est essentiel, tout aussi essentiel que les logiciels testent le code avant de les mettre en production. Nous avons appris que tester en production à des points de transfert critiques - lorsque les données sont ingérées - ainsi que lorsque le nouveau code analytique est mis en production, sont clés.
Regardez ces exemples :

Comparez le jeu de données CUSTOMERS avec RAW_CUSTOMERS dans une autre source de données.

Vérifiez la fraîcheur de votre jeu de données en utilisant la colonne timestamp row_added_ts.
Surveiller ou disjoncter
Une fois que des données de mauvaise qualité ont pénétré le système analytique, cela devient un cauchemar à nettoyer. Typiquement, vous devez effectuer des corrections sur les données historiques (rafraîchissement). C'est manuel, chronophage et sujet aux erreurs.
Les disjoncteurs peuvent prévenir cela. Les disjoncteurs sont des vérifications qui, lorsqu'elles échouent, stoppent le pipeline et mettent en quarantaine les mauvaises données pour que le producteur ou le consommateur de données les examine. Configurez un scan programmatique pour ajouter un disjoncteur à votre orchestrateur, ou ajoutez des vérifications de surveillance à tous vos jeux de données comme démontré ci-dessous :
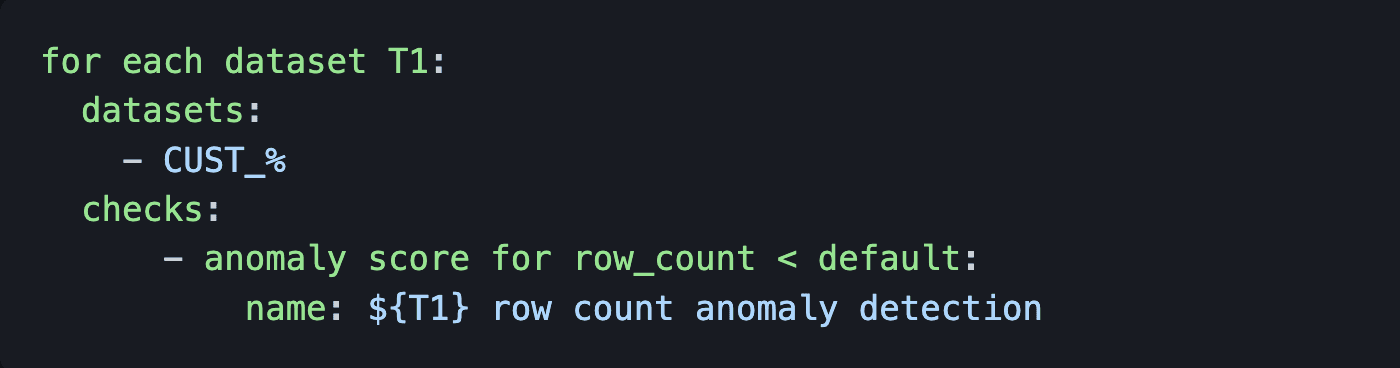
Vérifiez les anomalies dans le nombre de lignes de tous les jeux de données commençant par “CUST_”.
Définir des niveaux de qualité, de fiabilité et de bonne qualité des données
Aussi pénible que cela puisse être à entendre, les équipes de données ne devraient presque jamais aspirer à une qualité de données à cent pour cent car il est difficile à atteindre, et cela résulte souvent en de faibles gains marginaux pour beaucoup d'efforts supplémentaires. Dans presque tous les cas, l'impact pour l'utilisateur au-delà d'un certain pourcentage est négligeable.
Le nouveau langage DSL lisible par les humains de Soda, facilite le traitement des problèmes de qualité de données pour les producteurs ou consommateurs de données. En tant que DSL plus accessible, SodaCL donne à une gamme beaucoup plus large de membres de l'équipe la capacité de s'engager dans la quête continue et en constante évolution de données de bonne qualité.
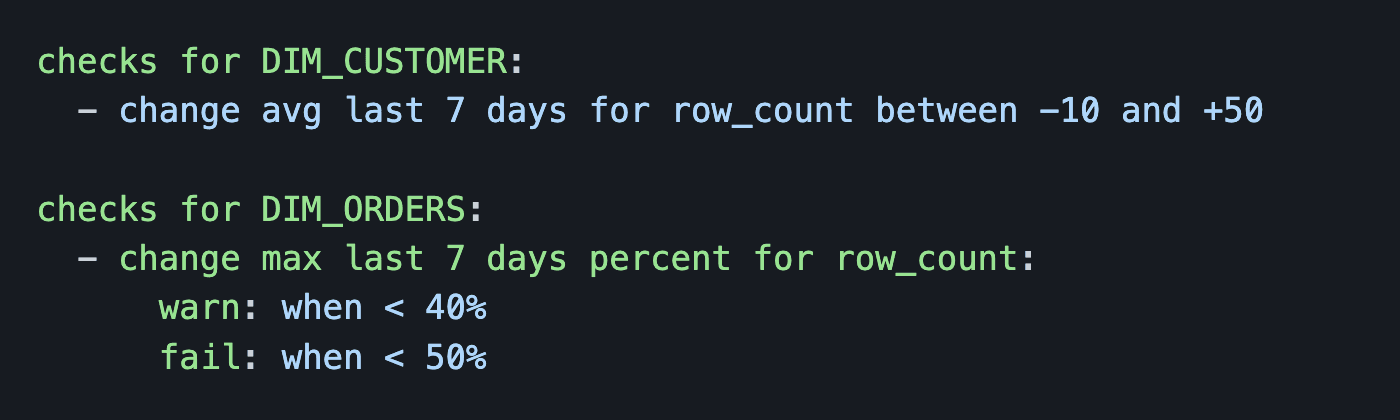
Vérifiez la moyenne glissante sur 7 jours de votre nombre de lignes. Et vérifiez la différence en pourcentage relative entre le maximum des 7 derniers jours avec la valeur actuelle, avec un niveau d'avertissement et d'échec.
Développé Avec Principe
Facile à utiliser, avec des dépendances minimales
Lors de la conception de Soda Core, nous nous sommes concentrés sur la facilité d'utilisation. Cela a abouti à des centaines de petites décisions, comme rendre disponibles deux modes différents : une interface en ligne de commande et une bibliothèque Python pour créer des analyses programmatiques ; et garder la liste des dépendances à installer aussi minimale que possible.
Configurations de vérification lisibles et inscriptibles par les humains
Livrer des produits de données de haute qualité et fiables que vos utilisateurs aiment ne peut pas se faire en isolement. Pour y parvenir, différents acteurs et équipes doivent travailler ensemble. C'est pourquoi avoir des configurations de vérification lisibles et inscriptibles par les humains est essentiel, car cela permet à tout le monde de s'impliquer.
Capable de fonctionner partout pour créer une observabilité de bout en bout
Nombre des équipes avec lesquelles nous avons travaillé voulaient pouvoir tester les données le plus tôt possible en amont. Soda a commencé par analyser les données accessibles via SQL, mais a rapidement inclus Spark DataFrames et Streaming également.
Dans la Nature
Les retours de la communauté durant la dernière année ont été incroyables. Des milliers d'équipes de données ont commencé à utiliser notre logiciel Soda open-source. Nous devons nos remerciements aux premières incarnations du logiciel Soda OSS, Soda SQL, et Soda Spark.
Les programmes de visualisation et bêta que nous avons menés pour SodaCL et Soda Core, en plus des contributions de sociétés comme HelloFresh, Disney, Udemy, ont considérablement contribué à rendre notre logiciel open-source encore meilleur.
Qu'est-ce qui Suivra ?
Tout d'abord, l'équipe et moi-même attendrons avec impatience les premières utilisations de Soda Core lors du jour de la disponibilité générale, le mardi 28 juin, et nous verrons les étoiles GitHub et les téléchargements augmenter !
Nous sommes ravis et très excités de mettre Soda Core à disposition de tous les ingénieurs de données du monde entier, sachant que cela leur facilitera grandement la vie.
Ensuite, nous tournons notre attention vers Soda Cloud et améliorons les capacités de libre-service pour les consommateurs de données, alors que nous continuons à simplifier le processus de détection, de triage, de diagnostic et de résolution des problèmes de données - pour tout le monde - tout au long du cycle de vie des produits de données.
Maintenant, c'est à vous d'aller explorer Soda Core. Nous serions ravis d'entendre vos commentaires.
Rejoignez la conversation dans notre Communauté Slack .











