Shifting Data Quality Left with Data Contracts - Case Study with Make
Shifting Data Quality Left with Data Contracts - Case Study with Make
Shifting Data Quality Left with Data Contracts - Case Study with Make

Fabiana Ferraz
Fabiana Ferraz
Rédacteur technique chez Soda
Rédacteur technique chez Soda

Renata Hlavová
Renata Hlavová
Data Engineer at Make
Data Engineer at Make
Table des matières

Even before implementing Soda and trying to define the contract, there was this question: who should we even contact, and who owns this? So data contracts brought transparency and also bigger cooperation between different teams.
Even before implementing Soda and trying to define the contract, there was this question: who should we even contact, and who owns this? So data contracts brought transparency and also bigger cooperation between different teams.

Renata Hlavová
Renata Hlavová
Data Engineer
Data Engineer
Data Engineer
à
Make
Make
Make is an AI automation platform that lets teams build and automate workflows across 3,000+ apps — from CRMs and databases to accounting systems and custom APIs. Trusted by over 400,000 customers, Make is used across marketing, finance, operations, and IT to connect tools and automate processes.
Internally, Make’s data engineering team consolidates data from Salesforce, operational databases, and accounting systems into Snowflake, where it feeds the financial reports and dashboards that leadership depends on.
As with most fast-growing companies, data governance was initially deprioritized in favor of shipping. Over time, this created a familiar set of challenges: source systems changed without warning, ownership of datasets became unclear as teams evolved, and quality issues traveled all the way downstream before anyone caught them, surfacing as a discrepancy in a report rather than an alert in an engineering system.
By adopting Soda v4 and embedding data contracts at both the ingestion and transformation layers of their Airflow pipelines, Make shifted data testing upstream. Contracts now define what good data looks like before it enters the pipeline — catching schema breaks, null violations, duplicate keys, and business logic errors at the point of origin.
The result is dramatically fewer reactive interruptions, automated ARR reconciliation, and, for the first time, a shared understanding across teams of who owns what data and what downstream consumers depend on.
The challenge: data issues that only surface in reports
Three compounding problems made data quality a constant source of friction at Make.
Lack of visibility. Source system owners had no visibility into downstream dependencies. Salesforce admins would delete columns or migrate schemas without knowing that those fields were feeding dashboards. By the time the impact was visible, it was already in a KPI report.
Ownership was unclear. As teams evolved, institutional knowledge about dataset ownership disappeared. When a sync broke, the first two hours weren’t spent fixing code — they were spent finding out who currently owned the data.
Fixes treated symptoms, not causes. When something broke, the response was a SQL patch in the transformation layer. The root cause at the source went unaddressed, so the same problems recurred.
“Before, we would be notified usually by our users — and that’s a really reactive way to work on data quality.” — Renata Hlavová, Data Engineer at Make
The most sensitive area was the monthly ARR reconciliation. Finance and Analytics consumed the same source data but regularly arrived at different numbers. Without automated checks embedded in the pipeline, errors traveled all the way downstream. Every fix started with a stakeholder notification, not a monitoring alert — pulling engineers off planned projects to investigate issues that had already made it into reports.
The solution: data contracts at every layer
Make’s approach was to shift testing upstream: define expectations at the source, enforce them automatically, and stop bad data before it can propagate.
The team rebuilt their Soda implementation from the ground up when they adopted Soda v4 — becoming one of its earliest adopters. Data contracts formalized rules about what data should look like and became the mechanism for this shift-left strategy.
The architecture: Airflow + Soda, programmatically
Everything at Make runs through Airflow. So the team built a custom Airflow operator that triggers Soda contract evaluations in sync with each data model run. This means quality checks execute automatically when data moves through the pipeline.
Soda is embedded in two distinct layers, each with a different testing focus.
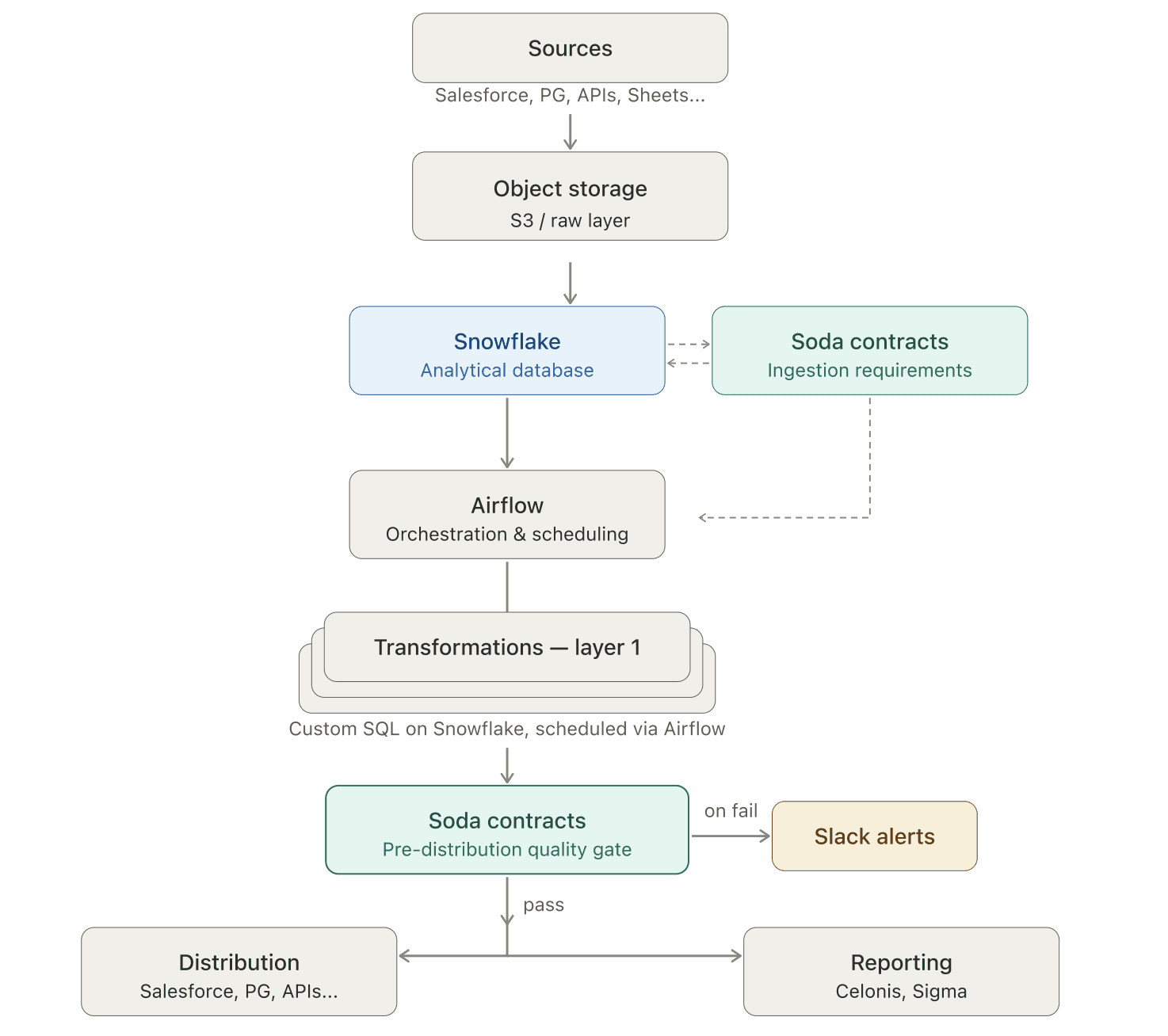
Layer 1: Ingestion requirements
Working with Finance and the Business Processes & Automation (BPnS) team — who manage Salesforce operations — Make’s data engineers established explicit expectations. When data arrives from external systems — Salesforce, accounting platforms, operational databases — a data contract validates the dataset before anything else runs.
These contracts enforce structural expectations:
Required columns must exist (catching schema changes before they break downstream models)
Primary keys can’t contain duplicates
Critical fields can’t be null
Values must fall within acceptable ranges or match a defined set
This is the shift-left principle in practice: instead of discovering a missing column when a transformation fails three steps later, Soda catches it at the point of ingestion.
Here’s an excerpt from Make’s actual Salesforce Account ingestion contract. Notice how every check is attributed to the BPnS team — the team that manages Salesforce operations — with Slack notifications routed to #dq-bpns. The contract is a shared agreement between data engineering and the source system owners.
dataset: snowflake_raw_data/RAW_DATA/SALESFORCE_GDPR/ACCOUNT checks: - schema: allow_other_column_order: true attributes: teams: - BPnS severity: critical notify: - '#dq-bpns' - row_count: name: Row count > 0 attributes: teams: - BPnS severity: critical notify: - '#dq-bpns' - freshness: column: CREATED_AT threshold: level: warn unit: day must_be_less_than: 2 attributes: teams: - BPnS severity: minor columns: - name: ID data_type: text checks: - missing: attributes: teams: - BPnS severity: critical notify: - '#dq-bpns' - duplicate: attributes: teams: - BPnS severity: critical notify: - '#dq-bpns' - name: IS_DELETED data_type: number checks: - missing: attributes: teams: - BPnS severity: minor - name: NAME data_type: text checks: - missing: attributes: teams: - BPnS severity: major notify: - '#dq-bpns' - name: COMPANY_DOMAIN data_type: text checks: - invalid: name: Max character length valid_max_length: 255 attributes: teams: - BPnS severity: minor - name: COMPANY_DESCRIPTION data_type: text checks: - invalid: name: Max character length valid_max_length: 131000 attributes: teams: - BPnS severity: minor - name: CREATED_AT data_type: timestamp_tz checks: - missing: attributes: teams: - BPnS severity: critical notify: - '#dq-bpns'
Make applies the same pattern to their Salesforce Opportunity table, but adds a business logic check at the source. See the excerpt below:
dataset: snowflake_raw_data/RAW_DATA/SALESFORCE/OPPORTUNITY checks: - failed_rows: name: Close Won stage has correct flags expression: STAGE_NAME = 'Closed Won' and (IS_WON != 1 or IS_CLOSED != 1) threshold: must_be: 0 attributes: severity
This check ensures that every opportunity marked as “Closed Won” in Salesforce also has the correct IS_WON and IS_CLOSED flags. If the flags don’t match the stage, something changed upstream that shouldn’t have — and Soda catches it before the inconsistency reaches downstream models.
This is shift-left testing beyond schema: enforcing business rules at the point of origin.
Layer 2: Pre-distribution quality gates (testing business logic)
As data moves through modeling, the testing focus shifts from structural to semantic. The contracts here catch logical contradictions that pass schema checks but would make Finance question the numbers.
Make’s serving layer includes cross-table referential integrity checks — ensuring that no organization ID appears in downstream tables without a corresponding entry in the master table. The contract also has column-level checks to enforce completeness, validate categorical values against allowed lists, and apply conditional rules to specific record subsets — each tagged with a severity that determines whether a failure warns or blocks the pipeline.
See the excerpt below:
dataset: snowflake_make_data/MAKE_DATA/SERVING/SRV_ORGANIZATION_MONTH checks: - schema: - row_count: name: Row count > 0 - failed_rows: name: ORG_ID from FCT_CONTRACT is not missing in SRV_ORGANIZATION_MONTH qualifier: org_id_fct_contract_not_missing attributes: severity: major threshold: must_be: 0 query: | SELECT DISTINCT ORG_ID FROM FCT_CONTRACT WHERE ORG_ID IS NOT NULL EXCEPT SELECT DISTINCT ORG_ID FROM SRV_ORGANIZATION_MONTH - failed_rows: name: ORG_ID from SRV_CONTRACT_MONTH is not missing in SRV_ORGANIZATION_MONTH qualifier: org_id_srv_contract_month_not_missing attributes: severity: major threshold: must_be: 0 query: | SELECT DISTINCT ORG_ID FROM SRV_CONTRACT_MONTH WHERE ORG_ID IS NOT NULL EXCEPT SELECT DISTINCT ORG_ID FROM SRV_ORGANIZATION_MONTH columns: - name: ORG_ID data_type: text character_maximum_length: 50 checks: - missing: attributes: severity: major - name: ORG_NAME data_type: text character_maximum_length: 500 checks: - missing: attributes: severity: minor threshold: level: warn - name: ORG_TYPE data_type: text character_maximum_length: 55 checks: - invalid: attributes: severity: major valid_values: - enterprise - self-service invalid_values: - Invalid - Unknown - N/A - 'NULL' - None - missing: attributes: severity: major - name: ORG_KEY data_type: text character_maximum_length: 50 checks: - missing: attributes: severity: major filter: ORG_ID LIKE 'm_%'
The hard stop: a circuit breaker for critical data
For the ARR reconciliation — Make’s highest-priority data flow — the team took the shift-left approach one step further: a pipeline hard stop.
If the row count drops by more than 100 compared to the previous snapshot — a sign of an incomplete sync or data loss — the pipeline stops. No transformation runs. No dashboard updates. The Finance team and the data engineering team are alerted simultaneously, and the conversation starts upstream.
Here’s the actual data contract check that powers the hard stop. It compares today’s row count against yesterday’s (with weekend logic to handle non-business days) and alerts both #dq-finance and #data-alerts with critical severity:
dataset: snowflake_make_data/MAKE_DATA/PREP_AGG/PRP_CONTRACT checks: - metric: name: CONTRACT - Row count for latest data must not decrease vs previous snapshot attributes: severity: critical teams: - Finance notify: - '#dq-finance' - '#data-alerts' tags: - ARR threshold: must_be_greater_than: -100 query: | SELECT( (SELECT COUNT(*) FROM STAGING_TABLE WHERE SNAPSHOT_DATE = CURRENT_DATE - 1) - (SELECT COUNT(*) FROM STAGING_TABLE WHERE SNAPSHOT_DATE = CURRENT_DATE - 2) ) AS latest_vs_previous_snapshot_check
Before this circuit breaker, incomplete syncs caused unexplained fluctuations in financial reports. Leadership would see sudden drops or spikes with no clear cause. Now, the pipeline catches the problem first, stops, alerts the relevant teams, and ensures the issue is resolved upstream.
The impact: from reactive patches to proactive testing
The shift from reactive fixing to proactive testing transformed both how Make’s team works and how the broader organization relates to data.
Manual reconciliation became automated.
The monthly ARR reconciliation — once a cross-team, multi-day effort — now runs with automated contract checks and alerts. Incomplete or inconsistent data is caught and stopped before it reaches reports.
Reactive interruptions dropped significantly.
Engineers spend more time on planned projects and less time investigating issues that have already made it into dashboards.
Data ownership became explicit.
For the first time, there is a clear map of how data flows from sources to downstream consumers. The process of defining contracts — starting with “who owns this dataset?” — created the transparency that was missing.
Non-technical teams gained visibility.
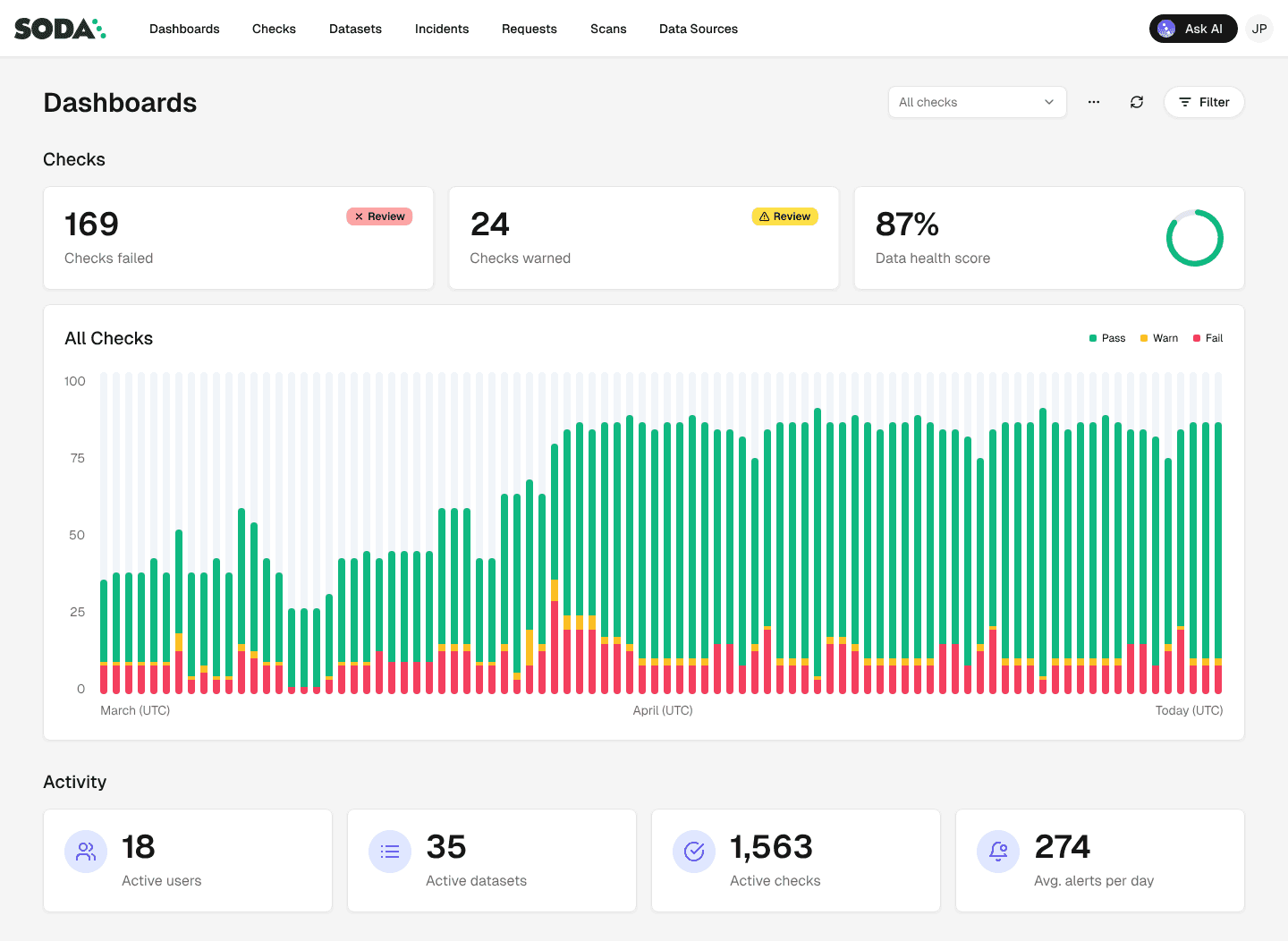
While the checks run programmatically, Soda Cloud UI plays a key role for non-technical stakeholders. Data owners can log in and immediately see the health of their datasets: what’s failing, what’s at risk, and how critical each issue is. Slack integration routes alerts by severity, so teams only get notified about what requires immediate attention.
In the end, the most significant outcome of adopting data contracts wasn’t technical, but organizational. Defining contracts forced conversations that had never happened before.
“Now the teams are starting proactively asking questions like: ‘We are making this change — is this going to affect you?’ I think we are becoming more mature here; it’s not chaos with data scattered everywhere anymore.” — Renata Hlavová, Data Engineer at Make
What’s next: deeper contracts and self-service diagnostics
Make’s shift-left journey is still expanding. The team is extending data contracts to more source systems and deeper into the transformation layers.
Metrics monitoring is being refined for anomaly detection, such as detecting when a category value suddenly disappears from a column, signaling a silent upstream change.
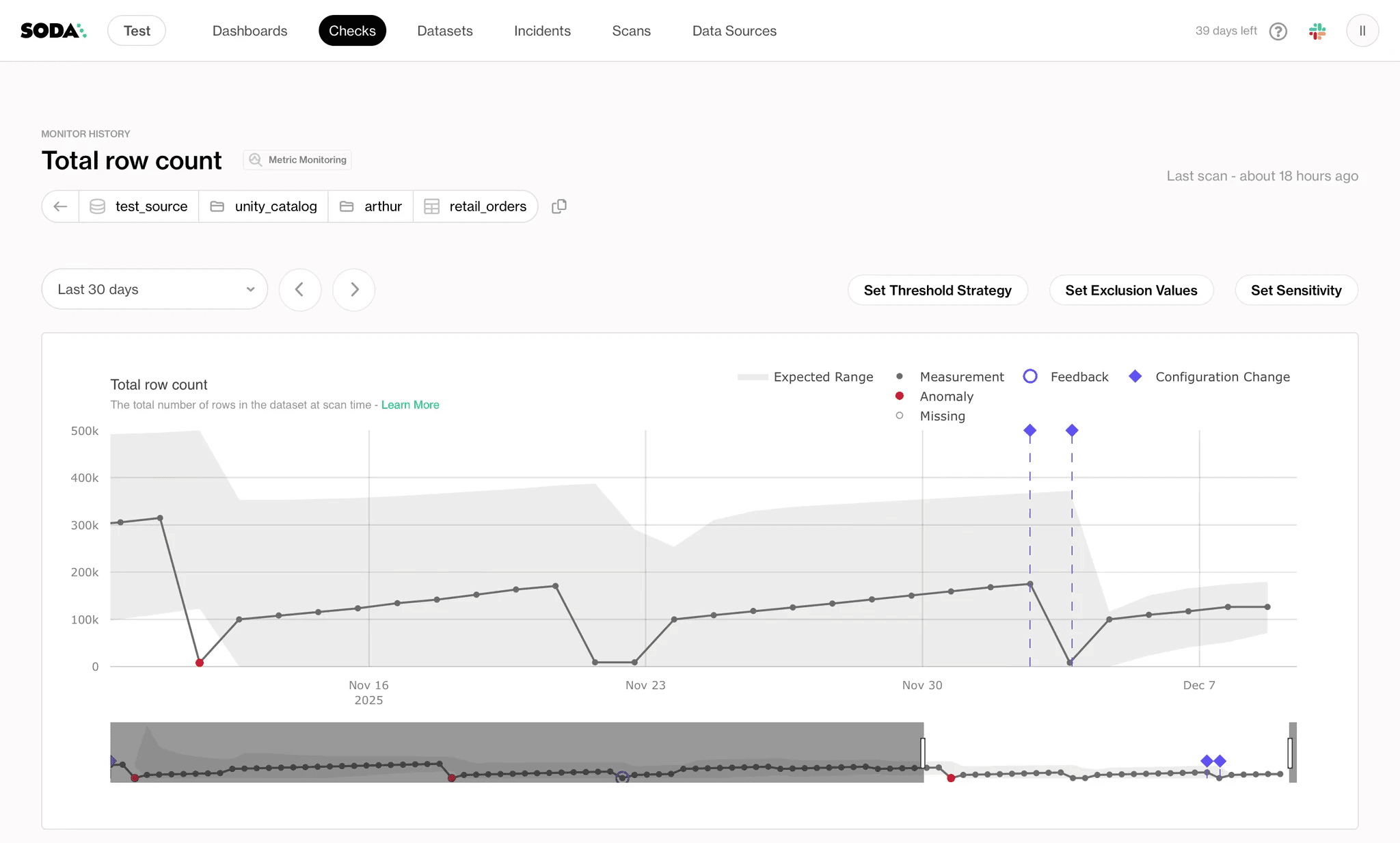
The next major milestone is a diagnostic warehouse in Sigma: failed records collected by Soda and sent to Snowflake, surfaced in a dashboard, filtered by team and severity. The vision is full self-service — any team will be able to inspect their own data quality issues without filing a ticket or waiting for a data engineer.
The longer-term goal isn’t just better contracts. It’s a company-wide shift toward data literacy, where every team that produces or consumes data understands how their changes affect the rest of the organization.
Get in touch
Schedule a demo with the Soda team or request a free account to see how data contracts can help your team shift data testing left, catching issues at the source before they reach your dashboards.
Make is an AI automation platform that lets teams build and automate workflows across 3,000+ apps — from CRMs and databases to accounting systems and custom APIs. Trusted by over 400,000 customers, Make is used across marketing, finance, operations, and IT to connect tools and automate processes.
Internally, Make’s data engineering team consolidates data from Salesforce, operational databases, and accounting systems into Snowflake, where it feeds the financial reports and dashboards that leadership depends on.
As with most fast-growing companies, data governance was initially deprioritized in favor of shipping. Over time, this created a familiar set of challenges: source systems changed without warning, ownership of datasets became unclear as teams evolved, and quality issues traveled all the way downstream before anyone caught them, surfacing as a discrepancy in a report rather than an alert in an engineering system.
By adopting Soda v4 and embedding data contracts at both the ingestion and transformation layers of their Airflow pipelines, Make shifted data testing upstream. Contracts now define what good data looks like before it enters the pipeline — catching schema breaks, null violations, duplicate keys, and business logic errors at the point of origin.
The result is dramatically fewer reactive interruptions, automated ARR reconciliation, and, for the first time, a shared understanding across teams of who owns what data and what downstream consumers depend on.
The challenge: data issues that only surface in reports
Three compounding problems made data quality a constant source of friction at Make.
Lack of visibility. Source system owners had no visibility into downstream dependencies. Salesforce admins would delete columns or migrate schemas without knowing that those fields were feeding dashboards. By the time the impact was visible, it was already in a KPI report.
Ownership was unclear. As teams evolved, institutional knowledge about dataset ownership disappeared. When a sync broke, the first two hours weren’t spent fixing code — they were spent finding out who currently owned the data.
Fixes treated symptoms, not causes. When something broke, the response was a SQL patch in the transformation layer. The root cause at the source went unaddressed, so the same problems recurred.
“Before, we would be notified usually by our users — and that’s a really reactive way to work on data quality.” — Renata Hlavová, Data Engineer at Make
The most sensitive area was the monthly ARR reconciliation. Finance and Analytics consumed the same source data but regularly arrived at different numbers. Without automated checks embedded in the pipeline, errors traveled all the way downstream. Every fix started with a stakeholder notification, not a monitoring alert — pulling engineers off planned projects to investigate issues that had already made it into reports.
The solution: data contracts at every layer
Make’s approach was to shift testing upstream: define expectations at the source, enforce them automatically, and stop bad data before it can propagate.
The team rebuilt their Soda implementation from the ground up when they adopted Soda v4 — becoming one of its earliest adopters. Data contracts formalized rules about what data should look like and became the mechanism for this shift-left strategy.
The architecture: Airflow + Soda, programmatically
Everything at Make runs through Airflow. So the team built a custom Airflow operator that triggers Soda contract evaluations in sync with each data model run. This means quality checks execute automatically when data moves through the pipeline.
Soda is embedded in two distinct layers, each with a different testing focus.
Layer 1: Ingestion requirements
Working with Finance and the Business Processes & Automation (BPnS) team — who manage Salesforce operations — Make’s data engineers established explicit expectations. When data arrives from external systems — Salesforce, accounting platforms, operational databases — a data contract validates the dataset before anything else runs.
These contracts enforce structural expectations:
Required columns must exist (catching schema changes before they break downstream models)
Primary keys can’t contain duplicates
Critical fields can’t be null
Values must fall within acceptable ranges or match a defined set
This is the shift-left principle in practice: instead of discovering a missing column when a transformation fails three steps later, Soda catches it at the point of ingestion.
Here’s an excerpt from Make’s actual Salesforce Account ingestion contract. Notice how every check is attributed to the BPnS team — the team that manages Salesforce operations — with Slack notifications routed to #dq-bpns. The contract is a shared agreement between data engineering and the source system owners.
dataset: snowflake_raw_data/RAW_DATA/SALESFORCE_GDPR/ACCOUNT checks: - schema: allow_other_column_order: true attributes: teams: - BPnS severity: critical notify: - '#dq-bpns' - row_count: name: Row count > 0 attributes: teams: - BPnS severity: critical notify: - '#dq-bpns' - freshness: column: CREATED_AT threshold: level: warn unit: day must_be_less_than: 2 attributes: teams: - BPnS severity: minor columns: - name: ID data_type: text checks: - missing: attributes: teams: - BPnS severity: critical notify: - '#dq-bpns' - duplicate: attributes: teams: - BPnS severity: critical notify: - '#dq-bpns' - name: IS_DELETED data_type: number checks: - missing: attributes: teams: - BPnS severity: minor - name: NAME data_type: text checks: - missing: attributes: teams: - BPnS severity: major notify: - '#dq-bpns' - name: COMPANY_DOMAIN data_type: text checks: - invalid: name: Max character length valid_max_length: 255 attributes: teams: - BPnS severity: minor - name: COMPANY_DESCRIPTION data_type: text checks: - invalid: name: Max character length valid_max_length: 131000 attributes: teams: - BPnS severity: minor - name: CREATED_AT data_type: timestamp_tz checks: - missing: attributes: teams: - BPnS severity: critical notify: - '#dq-bpns'
Make applies the same pattern to their Salesforce Opportunity table, but adds a business logic check at the source. See the excerpt below:
dataset: snowflake_raw_data/RAW_DATA/SALESFORCE/OPPORTUNITY checks: - failed_rows: name: Close Won stage has correct flags expression: STAGE_NAME = 'Closed Won' and (IS_WON != 1 or IS_CLOSED != 1) threshold: must_be: 0 attributes: severity
This check ensures that every opportunity marked as “Closed Won” in Salesforce also has the correct IS_WON and IS_CLOSED flags. If the flags don’t match the stage, something changed upstream that shouldn’t have — and Soda catches it before the inconsistency reaches downstream models.
This is shift-left testing beyond schema: enforcing business rules at the point of origin.
Layer 2: Pre-distribution quality gates (testing business logic)
As data moves through modeling, the testing focus shifts from structural to semantic. The contracts here catch logical contradictions that pass schema checks but would make Finance question the numbers.
Make’s serving layer includes cross-table referential integrity checks — ensuring that no organization ID appears in downstream tables without a corresponding entry in the master table. The contract also has column-level checks to enforce completeness, validate categorical values against allowed lists, and apply conditional rules to specific record subsets — each tagged with a severity that determines whether a failure warns or blocks the pipeline.
See the excerpt below:
dataset: snowflake_make_data/MAKE_DATA/SERVING/SRV_ORGANIZATION_MONTH checks: - schema: - row_count: name: Row count > 0 - failed_rows: name: ORG_ID from FCT_CONTRACT is not missing in SRV_ORGANIZATION_MONTH qualifier: org_id_fct_contract_not_missing attributes: severity: major threshold: must_be: 0 query: | SELECT DISTINCT ORG_ID FROM FCT_CONTRACT WHERE ORG_ID IS NOT NULL EXCEPT SELECT DISTINCT ORG_ID FROM SRV_ORGANIZATION_MONTH - failed_rows: name: ORG_ID from SRV_CONTRACT_MONTH is not missing in SRV_ORGANIZATION_MONTH qualifier: org_id_srv_contract_month_not_missing attributes: severity: major threshold: must_be: 0 query: | SELECT DISTINCT ORG_ID FROM SRV_CONTRACT_MONTH WHERE ORG_ID IS NOT NULL EXCEPT SELECT DISTINCT ORG_ID FROM SRV_ORGANIZATION_MONTH columns: - name: ORG_ID data_type: text character_maximum_length: 50 checks: - missing: attributes: severity: major - name: ORG_NAME data_type: text character_maximum_length: 500 checks: - missing: attributes: severity: minor threshold: level: warn - name: ORG_TYPE data_type: text character_maximum_length: 55 checks: - invalid: attributes: severity: major valid_values: - enterprise - self-service invalid_values: - Invalid - Unknown - N/A - 'NULL' - None - missing: attributes: severity: major - name: ORG_KEY data_type: text character_maximum_length: 50 checks: - missing: attributes: severity: major filter: ORG_ID LIKE 'm_%'
The hard stop: a circuit breaker for critical data
For the ARR reconciliation — Make’s highest-priority data flow — the team took the shift-left approach one step further: a pipeline hard stop.
If the row count drops by more than 100 compared to the previous snapshot — a sign of an incomplete sync or data loss — the pipeline stops. No transformation runs. No dashboard updates. The Finance team and the data engineering team are alerted simultaneously, and the conversation starts upstream.
Here’s the actual data contract check that powers the hard stop. It compares today’s row count against yesterday’s (with weekend logic to handle non-business days) and alerts both #dq-finance and #data-alerts with critical severity:
dataset: snowflake_make_data/MAKE_DATA/PREP_AGG/PRP_CONTRACT checks: - metric: name: CONTRACT - Row count for latest data must not decrease vs previous snapshot attributes: severity: critical teams: - Finance notify: - '#dq-finance' - '#data-alerts' tags: - ARR threshold: must_be_greater_than: -100 query: | SELECT( (SELECT COUNT(*) FROM STAGING_TABLE WHERE SNAPSHOT_DATE = CURRENT_DATE - 1) - (SELECT COUNT(*) FROM STAGING_TABLE WHERE SNAPSHOT_DATE = CURRENT_DATE - 2) ) AS latest_vs_previous_snapshot_check
Before this circuit breaker, incomplete syncs caused unexplained fluctuations in financial reports. Leadership would see sudden drops or spikes with no clear cause. Now, the pipeline catches the problem first, stops, alerts the relevant teams, and ensures the issue is resolved upstream.
The impact: from reactive patches to proactive testing
The shift from reactive fixing to proactive testing transformed both how Make’s team works and how the broader organization relates to data.
Manual reconciliation became automated.
The monthly ARR reconciliation — once a cross-team, multi-day effort — now runs with automated contract checks and alerts. Incomplete or inconsistent data is caught and stopped before it reaches reports.
Reactive interruptions dropped significantly.
Engineers spend more time on planned projects and less time investigating issues that have already made it into dashboards.
Data ownership became explicit.
For the first time, there is a clear map of how data flows from sources to downstream consumers. The process of defining contracts — starting with “who owns this dataset?” — created the transparency that was missing.
Non-technical teams gained visibility.
While the checks run programmatically, Soda Cloud UI plays a key role for non-technical stakeholders. Data owners can log in and immediately see the health of their datasets: what’s failing, what’s at risk, and how critical each issue is. Slack integration routes alerts by severity, so teams only get notified about what requires immediate attention.
In the end, the most significant outcome of adopting data contracts wasn’t technical, but organizational. Defining contracts forced conversations that had never happened before.
“Now the teams are starting proactively asking questions like: ‘We are making this change — is this going to affect you?’ I think we are becoming more mature here; it’s not chaos with data scattered everywhere anymore.” — Renata Hlavová, Data Engineer at Make
What’s next: deeper contracts and self-service diagnostics
Make’s shift-left journey is still expanding. The team is extending data contracts to more source systems and deeper into the transformation layers.
Metrics monitoring is being refined for anomaly detection, such as detecting when a category value suddenly disappears from a column, signaling a silent upstream change.
The next major milestone is a diagnostic warehouse in Sigma: failed records collected by Soda and sent to Snowflake, surfaced in a dashboard, filtered by team and severity. The vision is full self-service — any team will be able to inspect their own data quality issues without filing a ticket or waiting for a data engineer.
The longer-term goal isn’t just better contracts. It’s a company-wide shift toward data literacy, where every team that produces or consumes data understands how their changes affect the rest of the organization.
Get in touch
Schedule a demo with the Soda team or request a free account to see how data contracts can help your team shift data testing left, catching issues at the source before they reach your dashboards.
Make is an AI automation platform that lets teams build and automate workflows across 3,000+ apps — from CRMs and databases to accounting systems and custom APIs. Trusted by over 400,000 customers, Make is used across marketing, finance, operations, and IT to connect tools and automate processes.
Internally, Make’s data engineering team consolidates data from Salesforce, operational databases, and accounting systems into Snowflake, where it feeds the financial reports and dashboards that leadership depends on.
As with most fast-growing companies, data governance was initially deprioritized in favor of shipping. Over time, this created a familiar set of challenges: source systems changed without warning, ownership of datasets became unclear as teams evolved, and quality issues traveled all the way downstream before anyone caught them, surfacing as a discrepancy in a report rather than an alert in an engineering system.
By adopting Soda v4 and embedding data contracts at both the ingestion and transformation layers of their Airflow pipelines, Make shifted data testing upstream. Contracts now define what good data looks like before it enters the pipeline — catching schema breaks, null violations, duplicate keys, and business logic errors at the point of origin.
The result is dramatically fewer reactive interruptions, automated ARR reconciliation, and, for the first time, a shared understanding across teams of who owns what data and what downstream consumers depend on.
The challenge: data issues that only surface in reports
Three compounding problems made data quality a constant source of friction at Make.
Lack of visibility. Source system owners had no visibility into downstream dependencies. Salesforce admins would delete columns or migrate schemas without knowing that those fields were feeding dashboards. By the time the impact was visible, it was already in a KPI report.
Ownership was unclear. As teams evolved, institutional knowledge about dataset ownership disappeared. When a sync broke, the first two hours weren’t spent fixing code — they were spent finding out who currently owned the data.
Fixes treated symptoms, not causes. When something broke, the response was a SQL patch in the transformation layer. The root cause at the source went unaddressed, so the same problems recurred.
“Before, we would be notified usually by our users — and that’s a really reactive way to work on data quality.” — Renata Hlavová, Data Engineer at Make
The most sensitive area was the monthly ARR reconciliation. Finance and Analytics consumed the same source data but regularly arrived at different numbers. Without automated checks embedded in the pipeline, errors traveled all the way downstream. Every fix started with a stakeholder notification, not a monitoring alert — pulling engineers off planned projects to investigate issues that had already made it into reports.
The solution: data contracts at every layer
Make’s approach was to shift testing upstream: define expectations at the source, enforce them automatically, and stop bad data before it can propagate.
The team rebuilt their Soda implementation from the ground up when they adopted Soda v4 — becoming one of its earliest adopters. Data contracts formalized rules about what data should look like and became the mechanism for this shift-left strategy.
The architecture: Airflow + Soda, programmatically
Everything at Make runs through Airflow. So the team built a custom Airflow operator that triggers Soda contract evaluations in sync with each data model run. This means quality checks execute automatically when data moves through the pipeline.
Soda is embedded in two distinct layers, each with a different testing focus.
Layer 1: Ingestion requirements
Working with Finance and the Business Processes & Automation (BPnS) team — who manage Salesforce operations — Make’s data engineers established explicit expectations. When data arrives from external systems — Salesforce, accounting platforms, operational databases — a data contract validates the dataset before anything else runs.
These contracts enforce structural expectations:
Required columns must exist (catching schema changes before they break downstream models)
Primary keys can’t contain duplicates
Critical fields can’t be null
Values must fall within acceptable ranges or match a defined set
This is the shift-left principle in practice: instead of discovering a missing column when a transformation fails three steps later, Soda catches it at the point of ingestion.
Here’s an excerpt from Make’s actual Salesforce Account ingestion contract. Notice how every check is attributed to the BPnS team — the team that manages Salesforce operations — with Slack notifications routed to #dq-bpns. The contract is a shared agreement between data engineering and the source system owners.
dataset: snowflake_raw_data/RAW_DATA/SALESFORCE_GDPR/ACCOUNT checks: - schema: allow_other_column_order: true attributes: teams: - BPnS severity: critical notify: - '#dq-bpns' - row_count: name: Row count > 0 attributes: teams: - BPnS severity: critical notify: - '#dq-bpns' - freshness: column: CREATED_AT threshold: level: warn unit: day must_be_less_than: 2 attributes: teams: - BPnS severity: minor columns: - name: ID data_type: text checks: - missing: attributes: teams: - BPnS severity: critical notify: - '#dq-bpns' - duplicate: attributes: teams: - BPnS severity: critical notify: - '#dq-bpns' - name: IS_DELETED data_type: number checks: - missing: attributes: teams: - BPnS severity: minor - name: NAME data_type: text checks: - missing: attributes: teams: - BPnS severity: major notify: - '#dq-bpns' - name: COMPANY_DOMAIN data_type: text checks: - invalid: name: Max character length valid_max_length: 255 attributes: teams: - BPnS severity: minor - name: COMPANY_DESCRIPTION data_type: text checks: - invalid: name: Max character length valid_max_length: 131000 attributes: teams: - BPnS severity: minor - name: CREATED_AT data_type: timestamp_tz checks: - missing: attributes: teams: - BPnS severity: critical notify: - '#dq-bpns'
Make applies the same pattern to their Salesforce Opportunity table, but adds a business logic check at the source. See the excerpt below:
dataset: snowflake_raw_data/RAW_DATA/SALESFORCE/OPPORTUNITY checks: - failed_rows: name: Close Won stage has correct flags expression: STAGE_NAME = 'Closed Won' and (IS_WON != 1 or IS_CLOSED != 1) threshold: must_be: 0 attributes: severity
This check ensures that every opportunity marked as “Closed Won” in Salesforce also has the correct IS_WON and IS_CLOSED flags. If the flags don’t match the stage, something changed upstream that shouldn’t have — and Soda catches it before the inconsistency reaches downstream models.
This is shift-left testing beyond schema: enforcing business rules at the point of origin.
Layer 2: Pre-distribution quality gates (testing business logic)
As data moves through modeling, the testing focus shifts from structural to semantic. The contracts here catch logical contradictions that pass schema checks but would make Finance question the numbers.
Make’s serving layer includes cross-table referential integrity checks — ensuring that no organization ID appears in downstream tables without a corresponding entry in the master table. The contract also has column-level checks to enforce completeness, validate categorical values against allowed lists, and apply conditional rules to specific record subsets — each tagged with a severity that determines whether a failure warns or blocks the pipeline.
See the excerpt below:
dataset: snowflake_make_data/MAKE_DATA/SERVING/SRV_ORGANIZATION_MONTH checks: - schema: - row_count: name: Row count > 0 - failed_rows: name: ORG_ID from FCT_CONTRACT is not missing in SRV_ORGANIZATION_MONTH qualifier: org_id_fct_contract_not_missing attributes: severity: major threshold: must_be: 0 query: | SELECT DISTINCT ORG_ID FROM FCT_CONTRACT WHERE ORG_ID IS NOT NULL EXCEPT SELECT DISTINCT ORG_ID FROM SRV_ORGANIZATION_MONTH - failed_rows: name: ORG_ID from SRV_CONTRACT_MONTH is not missing in SRV_ORGANIZATION_MONTH qualifier: org_id_srv_contract_month_not_missing attributes: severity: major threshold: must_be: 0 query: | SELECT DISTINCT ORG_ID FROM SRV_CONTRACT_MONTH WHERE ORG_ID IS NOT NULL EXCEPT SELECT DISTINCT ORG_ID FROM SRV_ORGANIZATION_MONTH columns: - name: ORG_ID data_type: text character_maximum_length: 50 checks: - missing: attributes: severity: major - name: ORG_NAME data_type: text character_maximum_length: 500 checks: - missing: attributes: severity: minor threshold: level: warn - name: ORG_TYPE data_type: text character_maximum_length: 55 checks: - invalid: attributes: severity: major valid_values: - enterprise - self-service invalid_values: - Invalid - Unknown - N/A - 'NULL' - None - missing: attributes: severity: major - name: ORG_KEY data_type: text character_maximum_length: 50 checks: - missing: attributes: severity: major filter: ORG_ID LIKE 'm_%'
The hard stop: a circuit breaker for critical data
For the ARR reconciliation — Make’s highest-priority data flow — the team took the shift-left approach one step further: a pipeline hard stop.
If the row count drops by more than 100 compared to the previous snapshot — a sign of an incomplete sync or data loss — the pipeline stops. No transformation runs. No dashboard updates. The Finance team and the data engineering team are alerted simultaneously, and the conversation starts upstream.
Here’s the actual data contract check that powers the hard stop. It compares today’s row count against yesterday’s (with weekend logic to handle non-business days) and alerts both #dq-finance and #data-alerts with critical severity:
dataset: snowflake_make_data/MAKE_DATA/PREP_AGG/PRP_CONTRACT checks: - metric: name: CONTRACT - Row count for latest data must not decrease vs previous snapshot attributes: severity: critical teams: - Finance notify: - '#dq-finance' - '#data-alerts' tags: - ARR threshold: must_be_greater_than: -100 query: | SELECT( (SELECT COUNT(*) FROM STAGING_TABLE WHERE SNAPSHOT_DATE = CURRENT_DATE - 1) - (SELECT COUNT(*) FROM STAGING_TABLE WHERE SNAPSHOT_DATE = CURRENT_DATE - 2) ) AS latest_vs_previous_snapshot_check
Before this circuit breaker, incomplete syncs caused unexplained fluctuations in financial reports. Leadership would see sudden drops or spikes with no clear cause. Now, the pipeline catches the problem first, stops, alerts the relevant teams, and ensures the issue is resolved upstream.
The impact: from reactive patches to proactive testing
The shift from reactive fixing to proactive testing transformed both how Make’s team works and how the broader organization relates to data.
Manual reconciliation became automated.
The monthly ARR reconciliation — once a cross-team, multi-day effort — now runs with automated contract checks and alerts. Incomplete or inconsistent data is caught and stopped before it reaches reports.
Reactive interruptions dropped significantly.
Engineers spend more time on planned projects and less time investigating issues that have already made it into dashboards.
Data ownership became explicit.
For the first time, there is a clear map of how data flows from sources to downstream consumers. The process of defining contracts — starting with “who owns this dataset?” — created the transparency that was missing.
Non-technical teams gained visibility.
While the checks run programmatically, Soda Cloud UI plays a key role for non-technical stakeholders. Data owners can log in and immediately see the health of their datasets: what’s failing, what’s at risk, and how critical each issue is. Slack integration routes alerts by severity, so teams only get notified about what requires immediate attention.
In the end, the most significant outcome of adopting data contracts wasn’t technical, but organizational. Defining contracts forced conversations that had never happened before.
“Now the teams are starting proactively asking questions like: ‘We are making this change — is this going to affect you?’ I think we are becoming more mature here; it’s not chaos with data scattered everywhere anymore.” — Renata Hlavová, Data Engineer at Make
What’s next: deeper contracts and self-service diagnostics
Make’s shift-left journey is still expanding. The team is extending data contracts to more source systems and deeper into the transformation layers.
Metrics monitoring is being refined for anomaly detection, such as detecting when a category value suddenly disappears from a column, signaling a silent upstream change.
The next major milestone is a diagnostic warehouse in Sigma: failed records collected by Soda and sent to Snowflake, surfaced in a dashboard, filtered by team and severity. The vision is full self-service — any team will be able to inspect their own data quality issues without filing a ticket or waiting for a data engineer.
The longer-term goal isn’t just better contracts. It’s a company-wide shift toward data literacy, where every team that produces or consumes data understands how their changes affect the rest of the organization.
Get in touch
Schedule a demo with the Soda team or request a free account to see how data contracts can help your team shift data testing left, catching issues at the source before they reach your dashboards.
Trusted by the world’s leading enterprises
Real stories from companies using Soda to keep their data reliable, accurate, and ready for action.
At the end of the day, we don’t want to be in there managing the checks, updating the checks, adding the checks. We just want to go and observe what’s happening, and that’s what Soda is enabling right now.

Sid Srivastava
Director of Data Governance, Quality and MLOps
Investing in data quality is key for cross-functional teams to make accurate, complete decisions with fewer risks and greater returns, using initiatives such as product thinking, data governance, and self-service platforms.

Mario Konschake
Director of Product-Data Platform
Soda has integrated seamlessly into our technology stack and given us the confidence to find, analyze, implement, and resolve data issues through a simple self-serve capability.

Sutaraj Dutta
Data Engineering Manager
Our goal was to deliver high-quality datasets in near real-time, ensuring dashboards reflect live data as it flows in. But beyond solving technical challenges, we wanted to spark a cultural shift - empowering the entire organization to make decisions grounded in accurate, timely data.

Gu Xie
Head of Data Engineering
4,4 sur 5
Commencez à faire confiance à vos données. Aujourd'hui.
Trouvez, comprenez et corrigez tout problème de qualité des données en quelques secondes.
Du niveau de la table au niveau des enregistrements.
Adopté par
Product








Trusted by the world’s leading enterprises
Real stories from companies using Soda to keep their data reliable, accurate, and ready for action.
At the end of the day, we don’t want to be in there managing the checks, updating the checks, adding the checks. We just want to go and observe what’s happening, and that’s what Soda is enabling right now.
Sid Srivastava
Director of Data Governance, Quality and MLOps
Investing in data quality is key for cross-functional teams to make accurate, complete decisions with fewer risks and greater returns, using initiatives such as product thinking, data governance, and self-service platforms.
Mario Konschake
Director of Product-Data Platform
Soda has integrated seamlessly into our technology stack and given us the confidence to find, analyze, implement, and resolve data issues through a simple self-serve capability.
Sutaraj Dutta
Data Engineering Manager
Our goal was to deliver high-quality datasets in near real-time, ensuring dashboards reflect live data as it flows in. But beyond solving technical challenges, we wanted to spark a cultural shift - empowering the entire organization to make decisions grounded in accurate, timely data.
Gu Xie
Head of Data Engineering
4,4 sur 5
Commencez à faire confiance à vos données. Aujourd'hui.
Trouvez, comprenez et corrigez tout problème de qualité des données en quelques secondes.
Du niveau de la table au niveau des enregistrements.
Adopté par
Product
Solutions
Trusted by the world’s leading enterprises
Real stories from companies using Soda to keep their data reliable, accurate, and ready for action.
At the end of the day, we don’t want to be in there managing the checks, updating the checks, adding the checks. We just want to go and observe what’s happening, and that’s what Soda is enabling right now.
Sid Srivastava
Director of Data Governance, Quality and MLOps
Investing in data quality is key for cross-functional teams to make accurate, complete decisions with fewer risks and greater returns, using initiatives such as product thinking, data governance, and self-service platforms.
Mario Konschake
Director of Product-Data Platform
Soda has integrated seamlessly into our technology stack and given us the confidence to find, analyze, implement, and resolve data issues through a simple self-serve capability.
Sutaraj Dutta
Data Engineering Manager
Our goal was to deliver high-quality datasets in near real-time, ensuring dashboards reflect live data as it flows in. But beyond solving technical challenges, we wanted to spark a cultural shift - empowering the entire organization to make decisions grounded in accurate, timely data.
Gu Xie
Head of Data Engineering
4,4 sur 5
Commencez à faire confiance à vos données. Aujourd'hui.
Trouvez, comprenez et corrigez tout problème de qualité des données en quelques secondes.
Du niveau de la table au niveau des enregistrements.
Adopté par
Product
Solutions
Company