


Most data teams can tell you exactly which records are failing. Fixing them is another story.
What most teams don't have is a governed way to fix their failed records at scale. Issues pile up in spreadsheets, Slack threads while stewards chase record owners and apply fixes manually.
Today, Soda extends its data quality platform from detection into remediation. Soda Cleanse brings specialized AI agents into the same governed workflow stewards already use.
They propose fixes, route them for approval, and write corrections back to source. The same data contract that validates your data now powers the agent that fixes it.
The steward governs. The agent does the janitorial work.
Soda Cleanse is an add-on to Soda Cloud and is available today in Private Preview.
Business Teams Have ‘Data Quality Rights’ Too
When records go wrong, the people accountable for them don't wait for engineering to fix them. They fix them by hand, in spreadsheets, one cell at a time.
That's not a workflow. It's a tax on the teams closest to the data: Sales Operations, Finance Operations, HR Operations, and the stewards who answer to them.
The teams closest to the record shouldn't have to file an engineering ticket to clean up their own data. Sales Ops correcting a territory. Finance Ops reconciling a vendor. HR Ops deduplicating an employee. They should have their own workflow, their own audit trail, and their own control.
Cleanse is built so they do.
Stewards stop fixing records and start governing the process: approving what the agents propose, rejecting what doesn't hold up, and letting the audit trail do the rest.
How Soda Cleanse Works
Soda Cleanse is contract-driven, agent-specialized, and human-approved. Those three properties distinguish it from generic AI data cleaning approaches, and from the ad-hoc scripts most teams fall back on today.
The Inbox is Soda Cleanse's center of gravity. It’s where data stewards and record owners support triage, decide, and move on. It's not a dashboard and not a chatbot. It’s a workflow application with an audit trail.
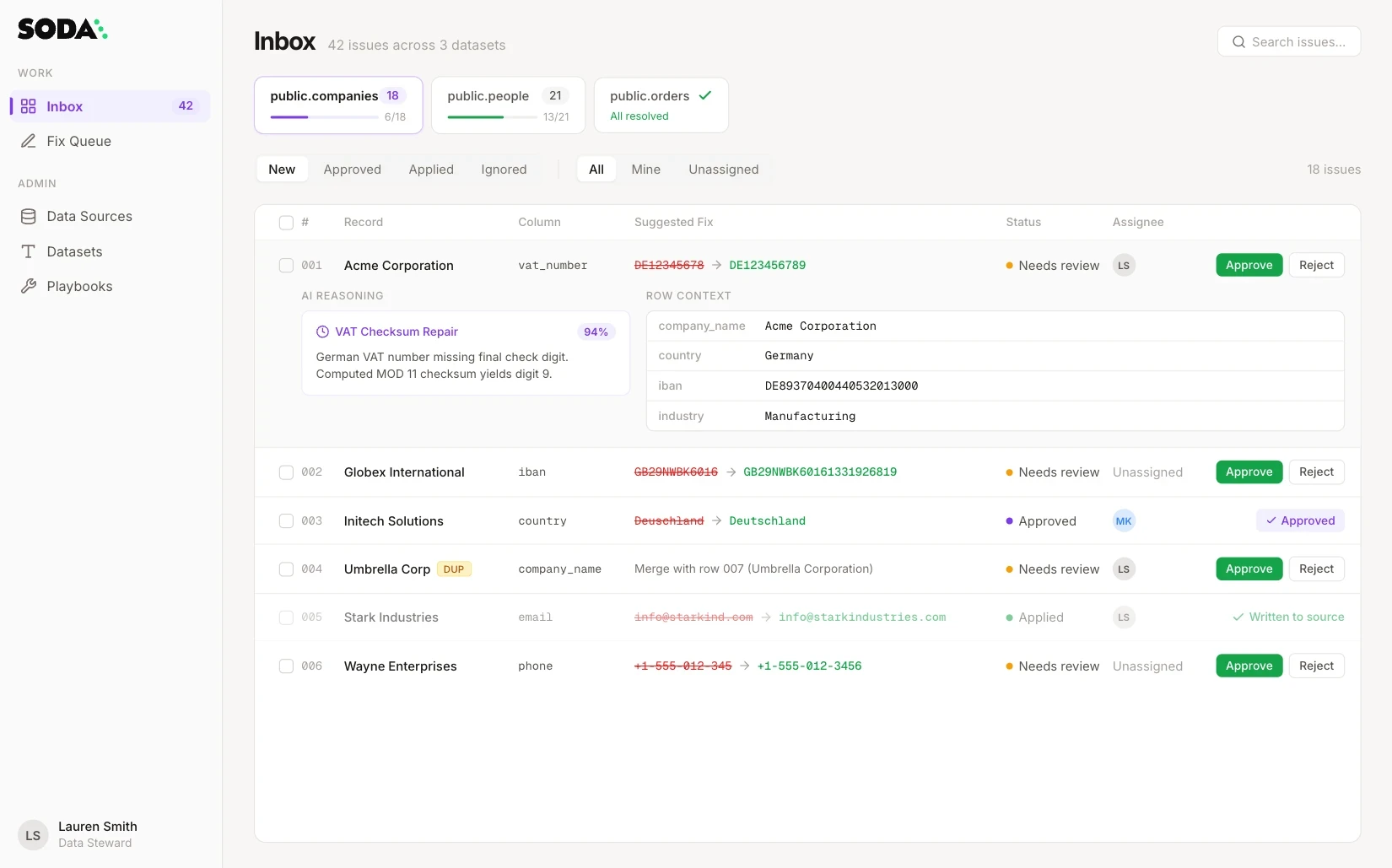
↗The Issues Inbox. Each row shows the record, affected column, suggested fix, and assigned steward. Expanding a row reveals the AI Reasoning panel (a plain-English explanation with a confidence score) alongside the Row Context fields the agent used to determine the fix.
Three things happen on a loop:
1. Ingest
Every failed row from every failing check lands in the Inbox automatically, with its check context, scan history, and prior decisions attached. One record, one issue. No custom integration. No exports. No pipeline for the team to build.
2. Propose
The data contract declares how each failure should be fixed, picking the right tool for the problem: a safe default, a lookup, an AI-assisted suggestion, or a human call. AI is the last resort, not the first.
3. Apply
Approved fixes write back to the source system. If a team isn't ready to write directly to source yet, approved fixes stay in a staging view until they are. Nothing changes in your data without a steward signing off, and every decision lands in the audit trail.
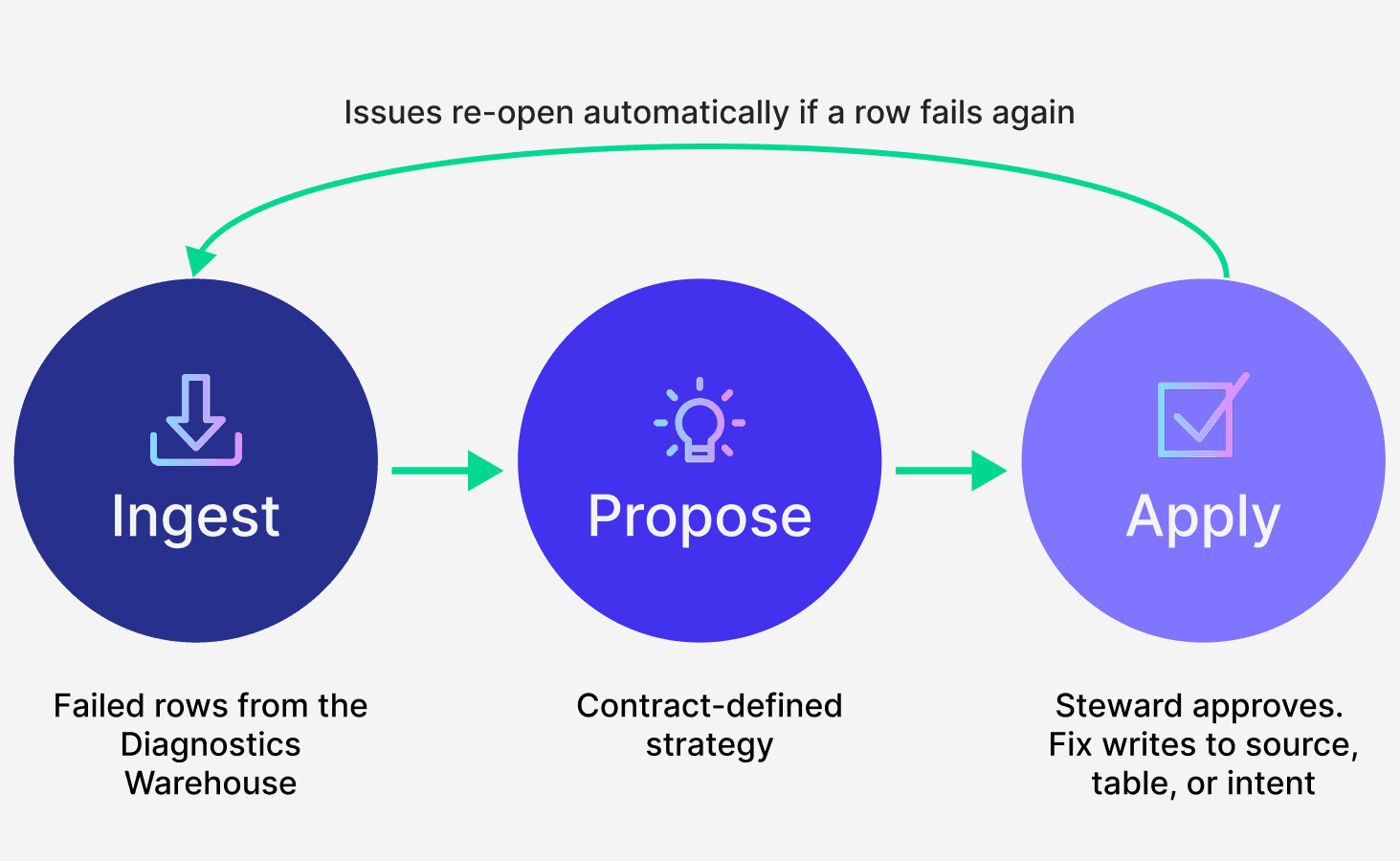
Soda Cleanse closes the loop on data quality. Contracts define correct. Agents fix what isn't. Stewards govern the outcome.
💡 For a deeper look at the evolution from manual scripts to agentic cleansing, read our Guide to Modern Data Cleansing.
What contract-driven cleansing gets you
The remediation strategies Cleanse runs live inside the same data contract the Soda customer is already maintaining. A customer who adds a new check gets the remediation slot for free: they fill it in when they're ready, and Cleanse picks it up automatically.
Four outcomes fall out of that:
One artifact, one workflow. Detection and remediation live inside the same data contract, so they can't drift apart. Every fix traces back to the rule that validates the data.
A safe on-ramp for risk-averse buyers. No team needs to grant production write-access on day one to get value out of Cleanse. That conversation can wait until you're ready for it.
Interpretable-first golden record selection. Advanced, interpretable heuristics pick the most likely correct record, and LLMs step in only to resolve ambiguous cases. Every merge decision is traceable back to the signals that drove it — defensible in an audit, without the black-box tradeoff.
Governed today, autonomous tomorrow. Every decision — proposal, approval, write, rejection — lands in an immutable audit log. When an auditor asks "who changed this record and why," the answer is already there. And the architecture that supervises today's workflow is the same one that scales toward fuller autonomy on your terms.
Soda Cloud finds it. Cleanse fixes it. One contract, one workflow, one audit trail.
Soda Cleanse requires Soda 4.0 and the Diagnostics Warehouse (Enterprise plan).
If you're not yet on Soda 4.0, talk to our team to understand how to get started.
What Soda Cleanse Can Fix
Soda Cleanse ships with specialized agents for four failure types. Each is built for the reasoning that type requires.
Entity normalization
Variant names for the same entity ("USA", "U.S.A.", "United States", "United States of America") break joins and inflate counts. The normalization agent derives the canonical form from surrounding data and contract context, then proposes it for approval.
Imputation
Missing values slip through schemas because NULL is often technically valid. The imputation agent reasons from the contract's definition of the field and surrounding data to propose a value that fits. The steward accepts, edits, or rejects.
Deduplication
Merge candidates surface in the Inbox with the full evidence behind each pick: the signals that drove the match, the fields that differ, and the recommended survivor record. The steward decides.
Reconciliation
When the same entity carries different values across sources, or drifts from a trusted reference dataset, the reconciliation agent identifies the mismatch and proposes a correction consistent with the contract's source of truth.
Ready to see how Cleanse handles these failures on the records your team owns? Request early access →
How To Get Started
Start with the records that cost your team the most. Tell us which records create the most manual cleanup for your team. Customer records in Salesforce, vendor records in your ERP, employee records in Workday. We'll work with you to get them into Cleanse. Your team approves the fixes. We handle the setup.
Not yet on Soda? Talk to our team and we'll plan the rollout so your stewards can be in the Inbox approving their first fixes in weeks
Either way, start narrow: pick the failure type causing the most manual cleanup work on your team, pick one dataset, and let the agent run. Expansion follows naturally from there.
What's Next
Private Preview is the beginning. We're working closely with early stewards and record owners to make sure agents produce proposals accurate enough to approve quickly, and to understand how different governance setups affect the review workflow.
As agents accumulate approval history specific to an organization's data standards, the review queue gets shorter. Cleanse is designed to get smarter with every decision a steward makes.
An MCP endpoint is on the roadmap. It will let external agents participate in the remediation workflow directly: driving triage, proposing fixes, and eventually closing the loop without a human for the fix types that have earned it.
Request access to get your records into the Inbox, or talk to our team if you're not yet on Soda.
Already a Soda user? Join the conversation in Soda Community Slack — your feedback on which failure types matter most shapes what we build next.
Frequently asked questions
Who is Soda Cleanse for?
Data stewards, record owners, and the business teams accountable for data in systems of record. Cleanse is designed so these teams can fix the records they own without depending on an engineering queue.
Does Soda send data to external systems for AI processing?
No. Failed rows, fix applications, and audit logs are recorded within the customer's own infrastructure, using the existing security and access controls of that environment.
Does Soda work with my existing stack?
Yes. Soda meets stewards where they already work. Quality results flow back to the catalog you already use (Collibra, Atlan, Alation), incidents and requests route through Slack, Jira, or Teams, and Soda scans the systems your data actually lives in: warehouses like Snowflake, Databricks, BigQuery, and Redshift, plus operational sources like Salesforce. Data stays in your environment under your existing access controls.
How long does it take to deploy Soda Cleanse?
For teams already on Soda 4.0 with data contracts in place, activation can be immediate with no new infrastructure required. For teams starting from scratch, deploying a first contract and running a pilot on one dataset typically takes days to weeks.
How is Soda Cleanse different from rule-based remediation platforms?
Rule-based platforms keep detection and remediation in separate systems, which means they can drift apart and take months to deploy and configure. Soda Cleanse is contract-driven: fix strategies are declared inside the same data contract that validates your data, so every fix traces back to the rule it satisfies.











