Soda lance le moteur de contrat de données OSS
Soda lance le moteur de contrat de données OSS
Soda lance le moteur de contrat de données OSS

Tom Baeyens
Tom Baeyens
CTO et co-fondateur chez Soda
CTO et co-fondateur chez Soda
Table des matières
Pourquoi les Data Contracts ?
Les data contracts sont une fondation pour que les producteurs de données prennent la responsabilité des ensembles de données qu'ils possèdent. Dans un data contract, ils communiquent l'"API pour les données". Grâce au contrat, les consommateurs de données peuvent découvrir quelles données sont disponibles et comment elles peuvent être utilisées.
La focalisation sur cette "API pour les données" a été déclenchée par le mouvement Data Mesh initié par Zhamak Dehghani. Data Mesh est une excellente stratégie pour architecturer des produits de données à grande échelle. Il applique des principes d'ingénierie logicielle tels que le Domain-driven Design (DDD) et les microservices aux données.
Sans les idées de Data Mesh et une implémentation concrète de data contracts, il y a une tendance à construire des pipelines spaghetti dont personne ne peut prendre la responsabilité, et que personne n'ose toucher. L'introduction des data contracts est un facilitateur implicite pour établir la responsabilité. Si les producteurs de données peuvent se fier à leur entrée (grâce à des contrats fiables), ils peuvent, à leur tour, produire des contrats fiables pour tous les produits de données qu'ils produisent.
Pour que les contrats soient efficaces et ne s'écartent pas de la réalité, ils doivent être appliqués. Appliquer un contrat signifie vérifier en permanence que les nouvelles données correspondent au data contract chaque fois que de nouvelles données sont produites. C'est là que Soda entre en jeu. Considérez Soda comme le moteur d'application des data contracts. Soda s'assurera en permanence que votre contrat est à jour et correct.
L'utilisation d'un langage YAML comme base pour les contrats s'aligne avec le mouvement shift-left qui se produit dans les données. Cela signifie piloter les processus de gestion des données autant que possible à partir des artefacts d'ingénierie gérés par des ingénieurs, jusqu'à la source (alias amont). Cela permet une détection plus rapide des problèmes et plus d'options pour mettre en quarantaine les mauvaises données avant qu'elles ne fassent du tort aux applications de données.
Cas d'utilisation des Data Contracts
Les data contracts servent de nombreux cas d'utilisation importants.
L'API pour les données : Les consommateurs qui recherchent des données pour créer de nouveaux produits doivent comprendre quelles données sont disponibles et comment elles peuvent être utilisées. En ce sens, les data contracts deviennent le système d'enregistrement pour les métadonnées opérationnelles pouvant être affichées dans les catalogues de données. Protéger le stockage : Les bases de données ont des schémas pour empêcher les mauvaises données d'entrer dans le stockage. Kafka dispose de registres de schémas pour empêcher les mauvaises données d'entrer dans les sujets. De la même manière, les ensembles de données analytiques auront des contrats pour empêcher les mauvaises données d'être stockées. Protéger l'utilisation : Les consommateurs peuvent ajouter (ou laisser d'autres ajouter) des contrôles de qualité de données pertinents pour leur utilisation. Les utilisateurs ont souvent une connaissance beaucoup plus intime des données ou des exigences spécifiques. Leur permettre d'ajouter des contrôles de qualité des données leur permet de protéger leur utilisation.
L'API pour les données : Les consommateurs qui recherchent des données pour créer de nouveaux produits doivent comprendre quelles données sont disponibles et comment elles peuvent être utilisées. En ce sens, les data contracts deviennent le système d'enregistrement pour les métadonnées opérationnelles pouvant être affichées dans les catalogues de données.
Protéger le stockage : Les bases de données ont des schémas pour empêcher les mauvaises données d'entrer dans le stockage. Kafka dispose de registres de schémas pour empêcher les mauvaises données d'entrer dans les sujets. De la même manière, les ensembles de données analytiques auront des contrats pour empêcher les mauvaises données d'être stockées.
Protéger l'utilisation : Les consommateurs peuvent ajouter (ou laisser d'autres ajouter) des contrôles de qualité de données pertinents pour leur utilisation. Les utilisateurs ont souvent une connaissance beaucoup plus intime des données ou des exigences spécifiques. Leur permettre d'ajouter des contrôles de qualité des données leur permet de protéger leur utilisation.
La stratégie des Data Contracts de Soda
Chez Soda, nous avons une expérience de création d'un moteur d'exécution pour les contrôles de qualité de données. Cela a commencé avec la sortie de Soda SQL en 2021 et Soda Core en 2022 (Apache 2.0). Ce moteur OSS est la base parfaite pour l'application des data contracts.
Aujourd'hui, il existe déjà plusieurs variations de langages de data contract utilisés et en cours d'élaboration. Afin d'atteindre le plus grand nombre d'utilisateurs possible, nous avons décidé de faciliter grandement le choix en tant que moteur d'application de la qualité des données pour toutes ces variations de langages de contrat.
Nous nous sommes concentrés sur la simplicité et la facilité d'adoption. Nouveau dans les data contracts ? Commencez simplement avec cette version comme outil autonome. Déjà utilisateur d'une autre spécification de data contract ? Vous pouvez connecter et utiliser Soda, car nous ignorons toute autre section de contrat. Déjà utilisateur de Soda Core/Library ? Les data contracts n'ajoutent qu'une nouvelle capacité et s'intègrent bien avec les déploiements Soda existants.
Soda reste engagé à fournir des logiciels open source à la communauté des données. Nous croyons que la meilleure façon pour la communauté d'apprendre, d'itérer et d'évoluer est de commencer dans l'OSS.
Comment ça fonctionne ?
Commençons par examiner un exemple de contrat Soda :
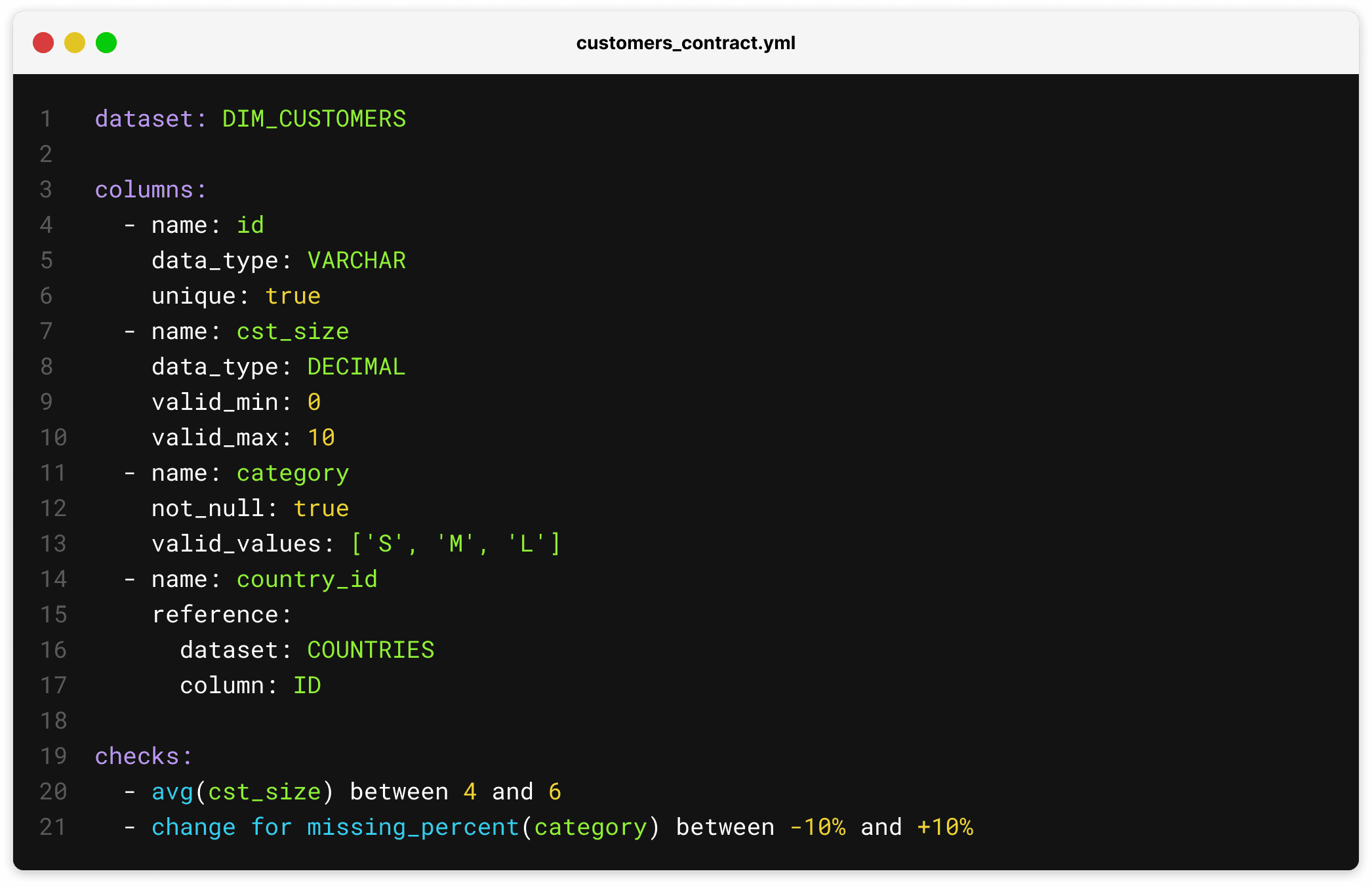
Notez que la section des colonnes spécifie le schéma complet. Le schéma de l'ensemble de données doit correspondre exactement au schéma spécifié, ce qui garantit que le contrat est toujours une représentation valide et complète de l'ensemble de données. Notez également comment la section des contrôles expose toute la puissance de SodaCL permettant aux utilisateurs d'ajouter tout contrôle de qualité des données.
Pour exécuter ou "appliquer" un contrat, veuillez vous référer à la documentation sur la manière dont les fichiers de contrat peuvent être exécutés de manière programmatique.
Considérations sur le déploiement
Nous recommandons que le fichier YAML du contrat soit placé dans le même dépôt git que le logiciel produisant les nouvelles données pour cet ensemble de données. Cela implique qu'après la production des données, le contrat (de la même version du dépôt) est vérifié. Il est plus facile de gérer l'évolution de cette manière.
Par exemple, en CI/CD, vous pouvez essayer de nouvelles versions du contrat sans aucun versionnage du contrat autre que git. Cela réduit le besoin d'un registre de contrat et tout l'embarras lié à la correspondance de l'application du contrat avec la bonne version du contrat. Cela réduit également le besoin d'avoir des constructions pour les colonnes à venir et obsolètes.
Très similaire aux API logicielles, la compatibilité rétroactive est très importante. En tant que producteur de données, vous ne pouvez pas simplement publier de nouvelles versions d'un ensemble de données qui ne sont pas compatibles avec les versions précédentes. L'ajout de colonnes est correct, mais la suppression de colonnes ou le changement des types de données est très risqué et compromettra les produits de données de vos consommateurs. Avoir un contrat obligera le producteur à documenter le schéma et d'autres propriétés de l'ensemble de données. Stocker cela dans git créera un historique des versions du contrat. L'historique de git aidera à rendre ces changements visibles. Même des outils peuvent être envisagés où, lors d'un commit qui a une modification, un contrat vérifiera si la modification est considérée comme rétrocompatible ou non.
Dans cette utilisation des contrats où le code du pipeline et les contrats sont dans le même dépôt, la publication du contrat doit être effectuée lorsqu'une nouvelle version du logiciel est publiée. Habituellement, dans le cas du CI/CD, cela est déclenché lorsqu'une branche est fusionnée dans main, et, en cas de modifications des fichiers de contrat, assurez-vous que la nouvelle version du contrat est poussée vers tous les autres systèmes qui en dépendent.
Et après ?
En tant que toute première itération expérimentale de data contracts, nous visons à explorer comment nos premiers utilisateurs l'adopteront dans le contexte de leurs propres produits de données. Nous sommes extrêmement impatients de recevoir des commentaires et serions effectivement heureux d'organiser une session en ligne pour que nous puissions explorer la manière dont la gestion des data contracts fonctionnera dans la réalité. Rejoignez-nous sur la communauté Soda et partagez votre histoire, question ou demande dans le #soda-core-channel !
Dans les prochaines semaines, nous allons réorganiser l'implémentation actuelle des data contracts dans Soda Cloud (appelée Agreements) pour être plus axée sur la création de contrôles basée sur l'UI et son intégration dans cette capacité de data contracts.
Où en apprendre plus
Pour télécharger et jouer avec la version, consultez les documents
Parlez-nous sur notre communauté Soda sur Slack dans le canal #soda-core
Les Data Contracts de Soda en action
Tom Baeyens, CTO et co-fondateur de Soda, prend 6 minutes pour expliquer ce qu'est un data contract et trois cas d'utilisation clé. Il donne également un aperçu de la stratégie des data contracts de Soda, et une avant-première des Data Contracts de Soda en action.
Les Data Contracts de Soda sont encore meilleurs.
Allez ici pour en savoir plus : Les premiers contrats de données collaboratifs au monde
Pourquoi les Data Contracts ?
Les data contracts sont une fondation pour que les producteurs de données prennent la responsabilité des ensembles de données qu'ils possèdent. Dans un data contract, ils communiquent l'"API pour les données". Grâce au contrat, les consommateurs de données peuvent découvrir quelles données sont disponibles et comment elles peuvent être utilisées.
La focalisation sur cette "API pour les données" a été déclenchée par le mouvement Data Mesh initié par Zhamak Dehghani. Data Mesh est une excellente stratégie pour architecturer des produits de données à grande échelle. Il applique des principes d'ingénierie logicielle tels que le Domain-driven Design (DDD) et les microservices aux données.
Sans les idées de Data Mesh et une implémentation concrète de data contracts, il y a une tendance à construire des pipelines spaghetti dont personne ne peut prendre la responsabilité, et que personne n'ose toucher. L'introduction des data contracts est un facilitateur implicite pour établir la responsabilité. Si les producteurs de données peuvent se fier à leur entrée (grâce à des contrats fiables), ils peuvent, à leur tour, produire des contrats fiables pour tous les produits de données qu'ils produisent.
Pour que les contrats soient efficaces et ne s'écartent pas de la réalité, ils doivent être appliqués. Appliquer un contrat signifie vérifier en permanence que les nouvelles données correspondent au data contract chaque fois que de nouvelles données sont produites. C'est là que Soda entre en jeu. Considérez Soda comme le moteur d'application des data contracts. Soda s'assurera en permanence que votre contrat est à jour et correct.
L'utilisation d'un langage YAML comme base pour les contrats s'aligne avec le mouvement shift-left qui se produit dans les données. Cela signifie piloter les processus de gestion des données autant que possible à partir des artefacts d'ingénierie gérés par des ingénieurs, jusqu'à la source (alias amont). Cela permet une détection plus rapide des problèmes et plus d'options pour mettre en quarantaine les mauvaises données avant qu'elles ne fassent du tort aux applications de données.
Cas d'utilisation des Data Contracts
Les data contracts servent de nombreux cas d'utilisation importants.
L'API pour les données : Les consommateurs qui recherchent des données pour créer de nouveaux produits doivent comprendre quelles données sont disponibles et comment elles peuvent être utilisées. En ce sens, les data contracts deviennent le système d'enregistrement pour les métadonnées opérationnelles pouvant être affichées dans les catalogues de données. Protéger le stockage : Les bases de données ont des schémas pour empêcher les mauvaises données d'entrer dans le stockage. Kafka dispose de registres de schémas pour empêcher les mauvaises données d'entrer dans les sujets. De la même manière, les ensembles de données analytiques auront des contrats pour empêcher les mauvaises données d'être stockées. Protéger l'utilisation : Les consommateurs peuvent ajouter (ou laisser d'autres ajouter) des contrôles de qualité de données pertinents pour leur utilisation. Les utilisateurs ont souvent une connaissance beaucoup plus intime des données ou des exigences spécifiques. Leur permettre d'ajouter des contrôles de qualité des données leur permet de protéger leur utilisation.
L'API pour les données : Les consommateurs qui recherchent des données pour créer de nouveaux produits doivent comprendre quelles données sont disponibles et comment elles peuvent être utilisées. En ce sens, les data contracts deviennent le système d'enregistrement pour les métadonnées opérationnelles pouvant être affichées dans les catalogues de données.
Protéger le stockage : Les bases de données ont des schémas pour empêcher les mauvaises données d'entrer dans le stockage. Kafka dispose de registres de schémas pour empêcher les mauvaises données d'entrer dans les sujets. De la même manière, les ensembles de données analytiques auront des contrats pour empêcher les mauvaises données d'être stockées.
Protéger l'utilisation : Les consommateurs peuvent ajouter (ou laisser d'autres ajouter) des contrôles de qualité de données pertinents pour leur utilisation. Les utilisateurs ont souvent une connaissance beaucoup plus intime des données ou des exigences spécifiques. Leur permettre d'ajouter des contrôles de qualité des données leur permet de protéger leur utilisation.
La stratégie des Data Contracts de Soda
Chez Soda, nous avons une expérience de création d'un moteur d'exécution pour les contrôles de qualité de données. Cela a commencé avec la sortie de Soda SQL en 2021 et Soda Core en 2022 (Apache 2.0). Ce moteur OSS est la base parfaite pour l'application des data contracts.
Aujourd'hui, il existe déjà plusieurs variations de langages de data contract utilisés et en cours d'élaboration. Afin d'atteindre le plus grand nombre d'utilisateurs possible, nous avons décidé de faciliter grandement le choix en tant que moteur d'application de la qualité des données pour toutes ces variations de langages de contrat.
Nous nous sommes concentrés sur la simplicité et la facilité d'adoption. Nouveau dans les data contracts ? Commencez simplement avec cette version comme outil autonome. Déjà utilisateur d'une autre spécification de data contract ? Vous pouvez connecter et utiliser Soda, car nous ignorons toute autre section de contrat. Déjà utilisateur de Soda Core/Library ? Les data contracts n'ajoutent qu'une nouvelle capacité et s'intègrent bien avec les déploiements Soda existants.
Soda reste engagé à fournir des logiciels open source à la communauté des données. Nous croyons que la meilleure façon pour la communauté d'apprendre, d'itérer et d'évoluer est de commencer dans l'OSS.
Comment ça fonctionne ?
Commençons par examiner un exemple de contrat Soda :
Notez que la section des colonnes spécifie le schéma complet. Le schéma de l'ensemble de données doit correspondre exactement au schéma spécifié, ce qui garantit que le contrat est toujours une représentation valide et complète de l'ensemble de données. Notez également comment la section des contrôles expose toute la puissance de SodaCL permettant aux utilisateurs d'ajouter tout contrôle de qualité des données.
Pour exécuter ou "appliquer" un contrat, veuillez vous référer à la documentation sur la manière dont les fichiers de contrat peuvent être exécutés de manière programmatique.
Considérations sur le déploiement
Nous recommandons que le fichier YAML du contrat soit placé dans le même dépôt git que le logiciel produisant les nouvelles données pour cet ensemble de données. Cela implique qu'après la production des données, le contrat (de la même version du dépôt) est vérifié. Il est plus facile de gérer l'évolution de cette manière.
Par exemple, en CI/CD, vous pouvez essayer de nouvelles versions du contrat sans aucun versionnage du contrat autre que git. Cela réduit le besoin d'un registre de contrat et tout l'embarras lié à la correspondance de l'application du contrat avec la bonne version du contrat. Cela réduit également le besoin d'avoir des constructions pour les colonnes à venir et obsolètes.
Très similaire aux API logicielles, la compatibilité rétroactive est très importante. En tant que producteur de données, vous ne pouvez pas simplement publier de nouvelles versions d'un ensemble de données qui ne sont pas compatibles avec les versions précédentes. L'ajout de colonnes est correct, mais la suppression de colonnes ou le changement des types de données est très risqué et compromettra les produits de données de vos consommateurs. Avoir un contrat obligera le producteur à documenter le schéma et d'autres propriétés de l'ensemble de données. Stocker cela dans git créera un historique des versions du contrat. L'historique de git aidera à rendre ces changements visibles. Même des outils peuvent être envisagés où, lors d'un commit qui a une modification, un contrat vérifiera si la modification est considérée comme rétrocompatible ou non.
Dans cette utilisation des contrats où le code du pipeline et les contrats sont dans le même dépôt, la publication du contrat doit être effectuée lorsqu'une nouvelle version du logiciel est publiée. Habituellement, dans le cas du CI/CD, cela est déclenché lorsqu'une branche est fusionnée dans main, et, en cas de modifications des fichiers de contrat, assurez-vous que la nouvelle version du contrat est poussée vers tous les autres systèmes qui en dépendent.
Et après ?
En tant que toute première itération expérimentale de data contracts, nous visons à explorer comment nos premiers utilisateurs l'adopteront dans le contexte de leurs propres produits de données. Nous sommes extrêmement impatients de recevoir des commentaires et serions effectivement heureux d'organiser une session en ligne pour que nous puissions explorer la manière dont la gestion des data contracts fonctionnera dans la réalité. Rejoignez-nous sur la communauté Soda et partagez votre histoire, question ou demande dans le #soda-core-channel !
Dans les prochaines semaines, nous allons réorganiser l'implémentation actuelle des data contracts dans Soda Cloud (appelée Agreements) pour être plus axée sur la création de contrôles basée sur l'UI et son intégration dans cette capacité de data contracts.
Où en apprendre plus
Pour télécharger et jouer avec la version, consultez les documents
Parlez-nous sur notre communauté Soda sur Slack dans le canal #soda-core
Les Data Contracts de Soda en action
Tom Baeyens, CTO et co-fondateur de Soda, prend 6 minutes pour expliquer ce qu'est un data contract et trois cas d'utilisation clé. Il donne également un aperçu de la stratégie des data contracts de Soda, et une avant-première des Data Contracts de Soda en action.
Les Data Contracts de Soda sont encore meilleurs.
Allez ici pour en savoir plus : Les premiers contrats de données collaboratifs au monde
Pourquoi les Data Contracts ?
Les data contracts sont une fondation pour que les producteurs de données prennent la responsabilité des ensembles de données qu'ils possèdent. Dans un data contract, ils communiquent l'"API pour les données". Grâce au contrat, les consommateurs de données peuvent découvrir quelles données sont disponibles et comment elles peuvent être utilisées.
La focalisation sur cette "API pour les données" a été déclenchée par le mouvement Data Mesh initié par Zhamak Dehghani. Data Mesh est une excellente stratégie pour architecturer des produits de données à grande échelle. Il applique des principes d'ingénierie logicielle tels que le Domain-driven Design (DDD) et les microservices aux données.
Sans les idées de Data Mesh et une implémentation concrète de data contracts, il y a une tendance à construire des pipelines spaghetti dont personne ne peut prendre la responsabilité, et que personne n'ose toucher. L'introduction des data contracts est un facilitateur implicite pour établir la responsabilité. Si les producteurs de données peuvent se fier à leur entrée (grâce à des contrats fiables), ils peuvent, à leur tour, produire des contrats fiables pour tous les produits de données qu'ils produisent.
Pour que les contrats soient efficaces et ne s'écartent pas de la réalité, ils doivent être appliqués. Appliquer un contrat signifie vérifier en permanence que les nouvelles données correspondent au data contract chaque fois que de nouvelles données sont produites. C'est là que Soda entre en jeu. Considérez Soda comme le moteur d'application des data contracts. Soda s'assurera en permanence que votre contrat est à jour et correct.
L'utilisation d'un langage YAML comme base pour les contrats s'aligne avec le mouvement shift-left qui se produit dans les données. Cela signifie piloter les processus de gestion des données autant que possible à partir des artefacts d'ingénierie gérés par des ingénieurs, jusqu'à la source (alias amont). Cela permet une détection plus rapide des problèmes et plus d'options pour mettre en quarantaine les mauvaises données avant qu'elles ne fassent du tort aux applications de données.
Cas d'utilisation des Data Contracts
Les data contracts servent de nombreux cas d'utilisation importants.
L'API pour les données : Les consommateurs qui recherchent des données pour créer de nouveaux produits doivent comprendre quelles données sont disponibles et comment elles peuvent être utilisées. En ce sens, les data contracts deviennent le système d'enregistrement pour les métadonnées opérationnelles pouvant être affichées dans les catalogues de données. Protéger le stockage : Les bases de données ont des schémas pour empêcher les mauvaises données d'entrer dans le stockage. Kafka dispose de registres de schémas pour empêcher les mauvaises données d'entrer dans les sujets. De la même manière, les ensembles de données analytiques auront des contrats pour empêcher les mauvaises données d'être stockées. Protéger l'utilisation : Les consommateurs peuvent ajouter (ou laisser d'autres ajouter) des contrôles de qualité de données pertinents pour leur utilisation. Les utilisateurs ont souvent une connaissance beaucoup plus intime des données ou des exigences spécifiques. Leur permettre d'ajouter des contrôles de qualité des données leur permet de protéger leur utilisation.
L'API pour les données : Les consommateurs qui recherchent des données pour créer de nouveaux produits doivent comprendre quelles données sont disponibles et comment elles peuvent être utilisées. En ce sens, les data contracts deviennent le système d'enregistrement pour les métadonnées opérationnelles pouvant être affichées dans les catalogues de données.
Protéger le stockage : Les bases de données ont des schémas pour empêcher les mauvaises données d'entrer dans le stockage. Kafka dispose de registres de schémas pour empêcher les mauvaises données d'entrer dans les sujets. De la même manière, les ensembles de données analytiques auront des contrats pour empêcher les mauvaises données d'être stockées.
Protéger l'utilisation : Les consommateurs peuvent ajouter (ou laisser d'autres ajouter) des contrôles de qualité de données pertinents pour leur utilisation. Les utilisateurs ont souvent une connaissance beaucoup plus intime des données ou des exigences spécifiques. Leur permettre d'ajouter des contrôles de qualité des données leur permet de protéger leur utilisation.
La stratégie des Data Contracts de Soda
Chez Soda, nous avons une expérience de création d'un moteur d'exécution pour les contrôles de qualité de données. Cela a commencé avec la sortie de Soda SQL en 2021 et Soda Core en 2022 (Apache 2.0). Ce moteur OSS est la base parfaite pour l'application des data contracts.
Aujourd'hui, il existe déjà plusieurs variations de langages de data contract utilisés et en cours d'élaboration. Afin d'atteindre le plus grand nombre d'utilisateurs possible, nous avons décidé de faciliter grandement le choix en tant que moteur d'application de la qualité des données pour toutes ces variations de langages de contrat.
Nous nous sommes concentrés sur la simplicité et la facilité d'adoption. Nouveau dans les data contracts ? Commencez simplement avec cette version comme outil autonome. Déjà utilisateur d'une autre spécification de data contract ? Vous pouvez connecter et utiliser Soda, car nous ignorons toute autre section de contrat. Déjà utilisateur de Soda Core/Library ? Les data contracts n'ajoutent qu'une nouvelle capacité et s'intègrent bien avec les déploiements Soda existants.
Soda reste engagé à fournir des logiciels open source à la communauté des données. Nous croyons que la meilleure façon pour la communauté d'apprendre, d'itérer et d'évoluer est de commencer dans l'OSS.
Comment ça fonctionne ?
Commençons par examiner un exemple de contrat Soda :
Notez que la section des colonnes spécifie le schéma complet. Le schéma de l'ensemble de données doit correspondre exactement au schéma spécifié, ce qui garantit que le contrat est toujours une représentation valide et complète de l'ensemble de données. Notez également comment la section des contrôles expose toute la puissance de SodaCL permettant aux utilisateurs d'ajouter tout contrôle de qualité des données.
Pour exécuter ou "appliquer" un contrat, veuillez vous référer à la documentation sur la manière dont les fichiers de contrat peuvent être exécutés de manière programmatique.
Considérations sur le déploiement
Nous recommandons que le fichier YAML du contrat soit placé dans le même dépôt git que le logiciel produisant les nouvelles données pour cet ensemble de données. Cela implique qu'après la production des données, le contrat (de la même version du dépôt) est vérifié. Il est plus facile de gérer l'évolution de cette manière.
Par exemple, en CI/CD, vous pouvez essayer de nouvelles versions du contrat sans aucun versionnage du contrat autre que git. Cela réduit le besoin d'un registre de contrat et tout l'embarras lié à la correspondance de l'application du contrat avec la bonne version du contrat. Cela réduit également le besoin d'avoir des constructions pour les colonnes à venir et obsolètes.
Très similaire aux API logicielles, la compatibilité rétroactive est très importante. En tant que producteur de données, vous ne pouvez pas simplement publier de nouvelles versions d'un ensemble de données qui ne sont pas compatibles avec les versions précédentes. L'ajout de colonnes est correct, mais la suppression de colonnes ou le changement des types de données est très risqué et compromettra les produits de données de vos consommateurs. Avoir un contrat obligera le producteur à documenter le schéma et d'autres propriétés de l'ensemble de données. Stocker cela dans git créera un historique des versions du contrat. L'historique de git aidera à rendre ces changements visibles. Même des outils peuvent être envisagés où, lors d'un commit qui a une modification, un contrat vérifiera si la modification est considérée comme rétrocompatible ou non.
Dans cette utilisation des contrats où le code du pipeline et les contrats sont dans le même dépôt, la publication du contrat doit être effectuée lorsqu'une nouvelle version du logiciel est publiée. Habituellement, dans le cas du CI/CD, cela est déclenché lorsqu'une branche est fusionnée dans main, et, en cas de modifications des fichiers de contrat, assurez-vous que la nouvelle version du contrat est poussée vers tous les autres systèmes qui en dépendent.
Et après ?
En tant que toute première itération expérimentale de data contracts, nous visons à explorer comment nos premiers utilisateurs l'adopteront dans le contexte de leurs propres produits de données. Nous sommes extrêmement impatients de recevoir des commentaires et serions effectivement heureux d'organiser une session en ligne pour que nous puissions explorer la manière dont la gestion des data contracts fonctionnera dans la réalité. Rejoignez-nous sur la communauté Soda et partagez votre histoire, question ou demande dans le #soda-core-channel !
Dans les prochaines semaines, nous allons réorganiser l'implémentation actuelle des data contracts dans Soda Cloud (appelée Agreements) pour être plus axée sur la création de contrôles basée sur l'UI et son intégration dans cette capacité de data contracts.
Où en apprendre plus
Pour télécharger et jouer avec la version, consultez les documents
Parlez-nous sur notre communauté Soda sur Slack dans le canal #soda-core
Les Data Contracts de Soda en action
Tom Baeyens, CTO et co-fondateur de Soda, prend 6 minutes pour expliquer ce qu'est un data contract et trois cas d'utilisation clé. Il donne également un aperçu de la stratégie des data contracts de Soda, et une avant-première des Data Contracts de Soda en action.
Les Data Contracts de Soda sont encore meilleurs.
Allez ici pour en savoir plus : Les premiers contrats de données collaboratifs au monde
Trusted by the world’s leading enterprises
Real stories from companies using Soda to keep their data reliable, accurate, and ready for action.
At the end of the day, we don’t want to be in there managing the checks, updating the checks, adding the checks. We just want to go and observe what’s happening, and that’s what Soda is enabling right now.

Sid Srivastava
Director of Data Governance, Quality and MLOps
Investing in data quality is key for cross-functional teams to make accurate, complete decisions with fewer risks and greater returns, using initiatives such as product thinking, data governance, and self-service platforms.

Mario Konschake
Director of Product-Data Platform
Soda has integrated seamlessly into our technology stack and given us the confidence to find, analyze, implement, and resolve data issues through a simple self-serve capability.

Sutaraj Dutta
Data Engineering Manager
Our goal was to deliver high-quality datasets in near real-time, ensuring dashboards reflect live data as it flows in. But beyond solving technical challenges, we wanted to spark a cultural shift - empowering the entire organization to make decisions grounded in accurate, timely data.

Gu Xie
Head of Data Engineering
4,4 sur 5
Commencez à faire confiance à vos données. Aujourd'hui.
Trouvez, comprenez et corrigez tout problème de qualité des données en quelques secondes.
Du niveau de la table au niveau des enregistrements.
Adopté par
Product








Trusted by the world’s leading enterprises
Real stories from companies using Soda to keep their data reliable, accurate, and ready for action.
At the end of the day, we don’t want to be in there managing the checks, updating the checks, adding the checks. We just want to go and observe what’s happening, and that’s what Soda is enabling right now.
Sid Srivastava
Director of Data Governance, Quality and MLOps
Investing in data quality is key for cross-functional teams to make accurate, complete decisions with fewer risks and greater returns, using initiatives such as product thinking, data governance, and self-service platforms.
Mario Konschake
Director of Product-Data Platform
Soda has integrated seamlessly into our technology stack and given us the confidence to find, analyze, implement, and resolve data issues through a simple self-serve capability.
Sutaraj Dutta
Data Engineering Manager
Our goal was to deliver high-quality datasets in near real-time, ensuring dashboards reflect live data as it flows in. But beyond solving technical challenges, we wanted to spark a cultural shift - empowering the entire organization to make decisions grounded in accurate, timely data.
Gu Xie
Head of Data Engineering
4,4 sur 5
Commencez à faire confiance à vos données. Aujourd'hui.
Trouvez, comprenez et corrigez tout problème de qualité des données en quelques secondes.
Du niveau de la table au niveau des enregistrements.
Adopté par
Product
Solutions
Trusted by the world’s leading enterprises
Real stories from companies using Soda to keep their data reliable, accurate, and ready for action.
At the end of the day, we don’t want to be in there managing the checks, updating the checks, adding the checks. We just want to go and observe what’s happening, and that’s what Soda is enabling right now.
Sid Srivastava
Director of Data Governance, Quality and MLOps
Investing in data quality is key for cross-functional teams to make accurate, complete decisions with fewer risks and greater returns, using initiatives such as product thinking, data governance, and self-service platforms.
Mario Konschake
Director of Product-Data Platform
Soda has integrated seamlessly into our technology stack and given us the confidence to find, analyze, implement, and resolve data issues through a simple self-serve capability.
Sutaraj Dutta
Data Engineering Manager
Our goal was to deliver high-quality datasets in near real-time, ensuring dashboards reflect live data as it flows in. But beyond solving technical challenges, we wanted to spark a cultural shift - empowering the entire organization to make decisions grounded in accurate, timely data.
Gu Xie
Head of Data Engineering
4,4 sur 5
Commencez à faire confiance à vos données. Aujourd'hui.
Trouvez, comprenez et corrigez tout problème de qualité des données en quelques secondes.
Du niveau de la table au niveau des enregistrements.
Adopté par
Product
Solutions
Company