
"D'ici 2022, 70% des organisations suivront rigoureusement les niveaux de qualité des données via des métriques, augmentant la qualité des données de 60% afin de réduire significativement les risques opérationnels et les coûts."
Source : Gartner, 100 Data and Analytics Predictions Through 2024, Analysts : Graham Peters, Alan D. Duncan, 2020
Les organisations qui s'appuient sur les données pour stimuler l'innovation, maximiser les opportunités de revenus et prendre des décisions en temps opportun, ont besoin d'une manière évolutive et automatisée de mettre en évidence les problèmes de qualité des données dans leur stack. C'est pourquoi chez Soda, nous avons mis beaucoup d'importance sur notre capacité d'anomalie de détection des séries temporelles automatisée pour qu'elle soit facile à configurer et évolutive à l'échelle de l'entreprise.
L'anomalie de détection des séries temporelles est un nouveau type de surveillance facile à configurer, disponible sur la plateforme d'observation des données de Soda, qui peut être utilisé sur n'importe quelles métriques se développant au fil du temps. Pensez par exemple : ventes quotidiennes, ou le pourcentage de valeurs valides, par année, saison, mois ou semaine.
Commencer avec l'Anomalie de Détection des Séries Temporelles
Dans le cadre des fonctionnalités d'Intelligence de Soda, l'anomalie de détection des séries temporelles sert les data scientists, analystes, ainsi que les ingénieurs de plateforme et de données, dont le rôle est d'accroître la confiance dans les données et d'en extraire la valeur, afin que des décisions puissent être prises en toute confiance.
L'anomalie de détection des séries temporelles applique des algorithmes d'apprentissage automatique aux métriques de qualité des données de chaque ensemble de données et apprend leur comportement et leurs schémas au fil du temps, afin de détecter des points de données inhabituels ou anormaux. Le plus grand défi lors de la création d'un système d'anomalie de détection des séries temporelles est de s'assurer que ce système est capable de résister à l'épreuve du temps et de s'adapter aux données à mesure qu'elles évoluent et changent.
Une solution ou approche courante pour les outils développés en interne consiste pour les praticiens de données à configurer un système d'alerte basé sur des seuils. Cela peut fonctionner lorsqu'il y a une bonne compréhension des données sous-jacentes, mais cela nécessite une expertise du domaine et des itérations et adaptations constantes. Cela signifie également que le temps passé à maintenir une solution interne est du temps pris sur le modelage et l'analyse des données pour obtenir des insights commerciaux.
C'est pourquoi nous avons développé la fonctionnalité d'anomalie de détection des séries temporelles comme une capacité prête à l'emploi. Oui, c'est exact - aucune configuration requise. Pas de seuils initiaux à configurer et pas de logique métier complexe à codifier.
Soda construit un modèle prédictif qui utilise des données historiques pour comprendre les tendances communes et les schémas saisonniers des données de séries temporelles. Chaque mesure est un point au fil du temps. Lorsque les mesures sont anormales, elles seront signalées par un point coloré, indiquant si elles se trouvent dans les zones 'avertissement' (point jaune) ou 'critique' (point rouge), en fonction de la gravité de l'anomalie.
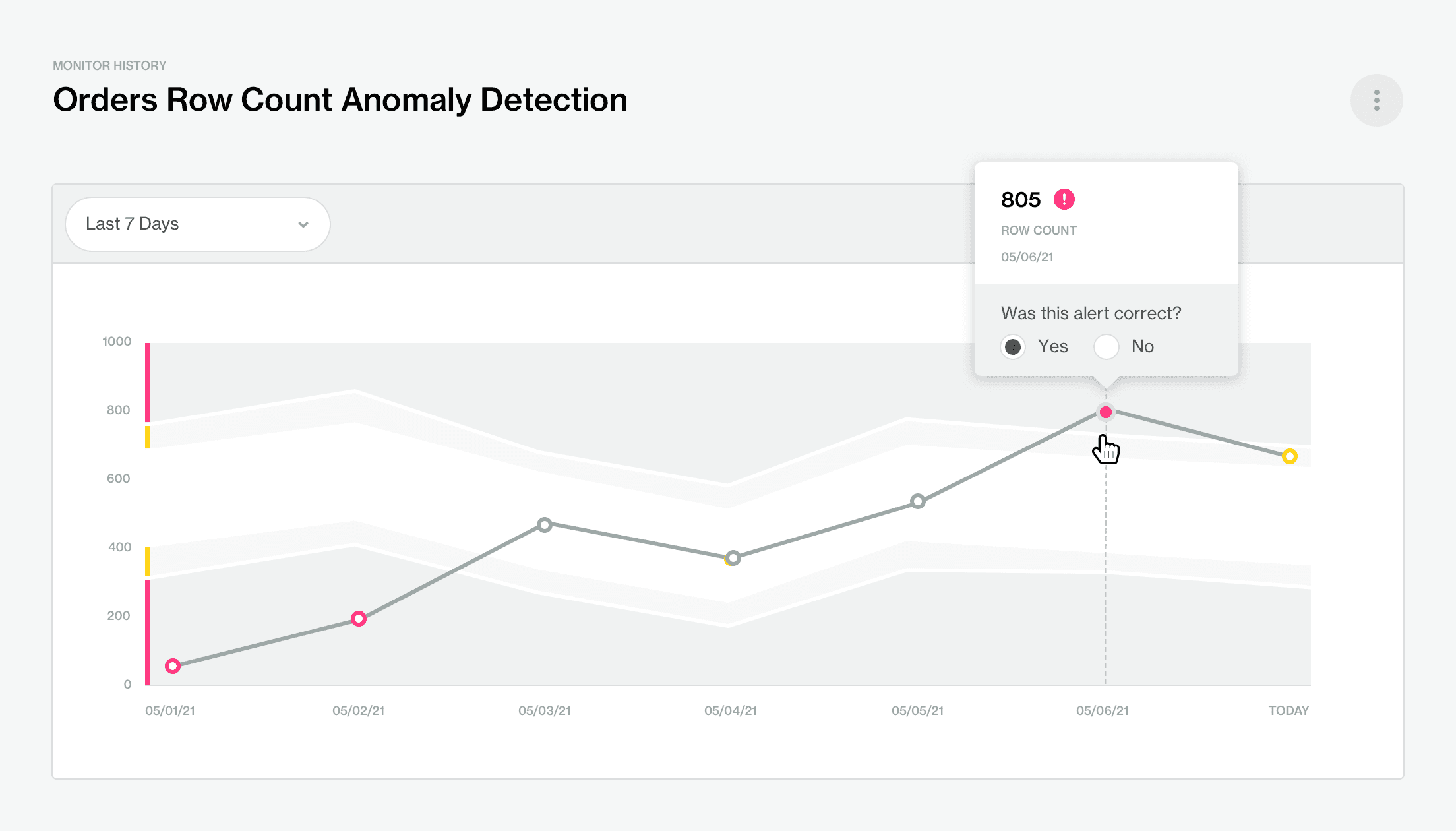
Éliminer les Lacunes dans l'Observabilité des Données
L'automatisation s'améliore lorsqu'un algorithme peut être formé et qu'il continue d'apprendre et de s'adapter aux retours des utilisateurs. Pour que cela se produise, il est parfois nécessaire que les experts en la matière des données ou les responsables de la gouvernance des données ajustent et affinent cela. Et c'est un autre avantage de l'utilisation de l'anomalie de détection des séries temporelles de Soda, car notre algorithme peut apprendre des retours des utilisateurs.
Si un utilisateur remarque qu'un point de données est signalé comme anormal alors qu'il s'agit en fait d'une variation attendue, comme une baisse du nombre de commandes pendant le week-end pour un détaillant en ligne de fournitures de bureau, l'utilisateur peut désigner cette anomalie via des annotations et le modèle ajustera ses hypothèses la prochaine fois qu'il s'exécutera.
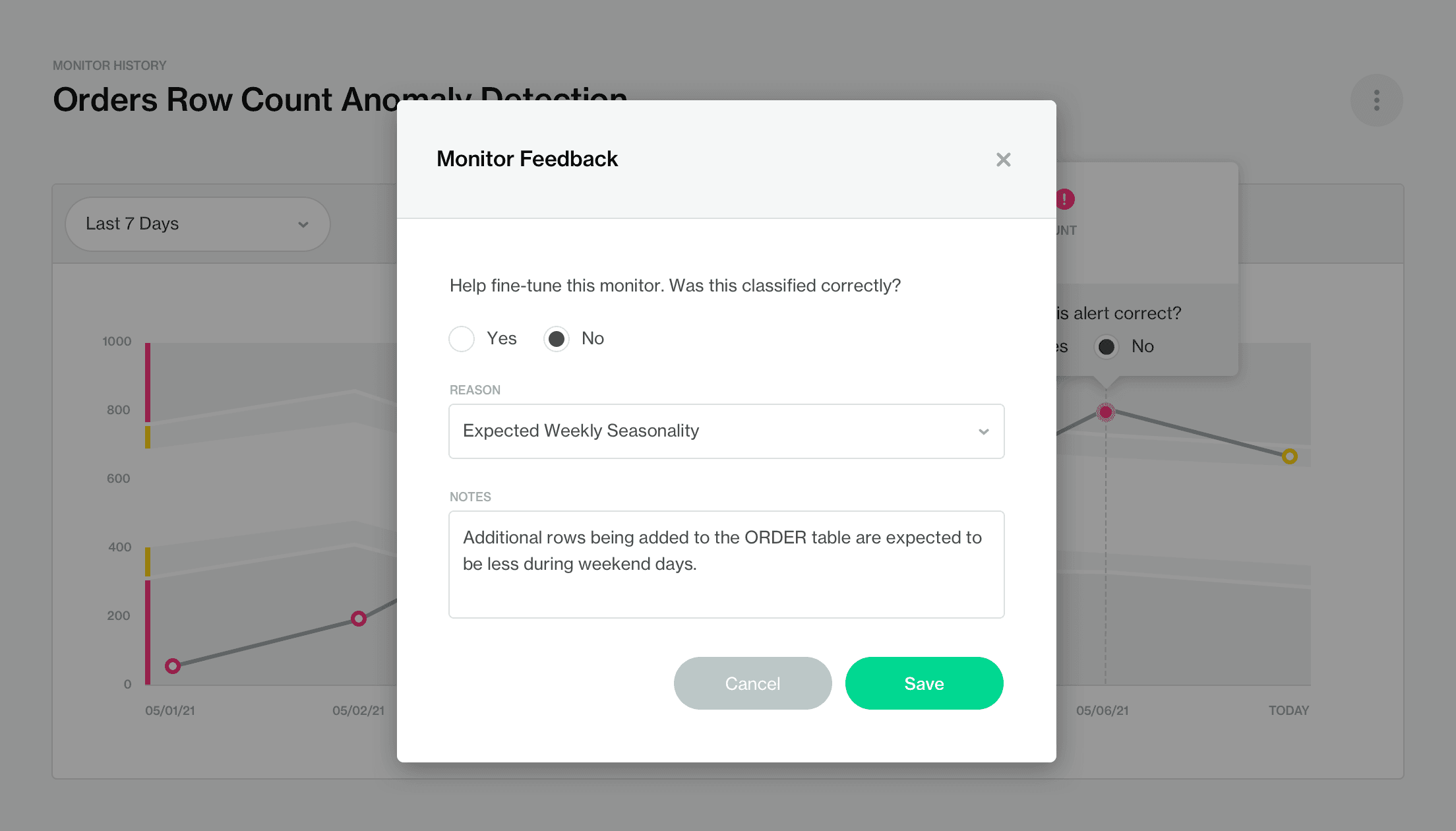
Parfois, même les machines ont besoin d'un coup de pouce - surtout si les données sont idiosyncratiques à votre entreprise. Un autre avantage de permettre le retour d'information des utilisateurs pour ajuster les mécanismes internes de l'algorithme est qu'il réduira plus rapidement le bruit ou le "syndrome d'alerte excessives" et vous permettra de vous concentrer sur ce qui compte vraiment.
En plus de l'anomalie de détection des séries temporelles, les utilisateurs ont également la possibilité de configurer manuellement des modifications dans le temps ou des moniteurs basés sur des seuils dans Soda. C'est une alternative si vous avez des connaissances sur le comportement potentiel d'un ensemble de données que vous pouvez définir et établir les niveaux pour ce à quoi ressemblent de bonnes données et quel est le comportement anormal.
Parce que nous croyons que la qualité des données est un sport d'équipe, la plateforme de Soda est conçue pour permettre la collaboration. Les alertes sont dirigées vers les bonnes personnes, définies par rôles et responsabilités, pour un triage et une enquête dès qu'elles se produisent. Tout le monde ayant un intérêt dans les données peut les comprendre, leur faire confiance et rester informé. Les utilisateurs peuvent concentrer leur attention là où leurs compétences ont un impact sur l'entreprise.
Causes Inconnues Définies par Leur Impact en Amont & En Aval
Les effets en cascade et le coût des mauvaises données sont reconnus par les organisations, grandes et petites. La mauvaise qualité des données est coûteuse non seulement en termes de temps et de ressources mais aussi par son impact sur les opportunités de stimuler l'innovation, de prendre des décisions en temps opportun, de maximiser les opportunités de revenus et, finalement, la réputation.
Soda détecte les données anormales ou aberrantes et les porte à la surface pour permettre aux bonnes personnes de l'équipe d'analyser et de découvrir la cause profonde de l'incident. Mais cela ne devrait pas s'arrêter là.
La cause racine définitive d'un incident de mauvaise qualité de données est souvent inconnue, mais l'incident est souvent défini par son impact sur l'entreprise.
Analyse des Causes Racines pour Prévenir les Problèmes Futurs
Comprendre et parvenir à identifier la cause racine des données anormales, ainsi que la possibilité de prévenir de manière proactive les problèmes de données futurs, nécessite que les équipes de données enquêtent plus profondément et plus largement dans les données, au-delà des simples données anormales. Les erreurs difficiles à trouver et leurs causes sont souvent enfouies profondément dans les données et nous savons qu'il n'y a presque jamais qu'un seul problème, mais en réalité plusieurs faux pas.
L'équipe de données doit être capable de se concentrer sur la résolution de la cause racine plutôt que d'appliquer des correctifs à court terme en aval.
Les 3 actions recommandées que nous conseillons que les équipes de données entreprennent pour l'analyse des causes racines sont :
Analyser les points communs ou différences dans les lignes échouées et réussies
Utiliser la lignée des données pour retracer les erreurs jusqu'à la cause racine et comprendre l'impact au point le plus en amont et sur les dépendances en aval
Examiner les modifications du code analytique et identifier l'impact des nouvelles versions de code
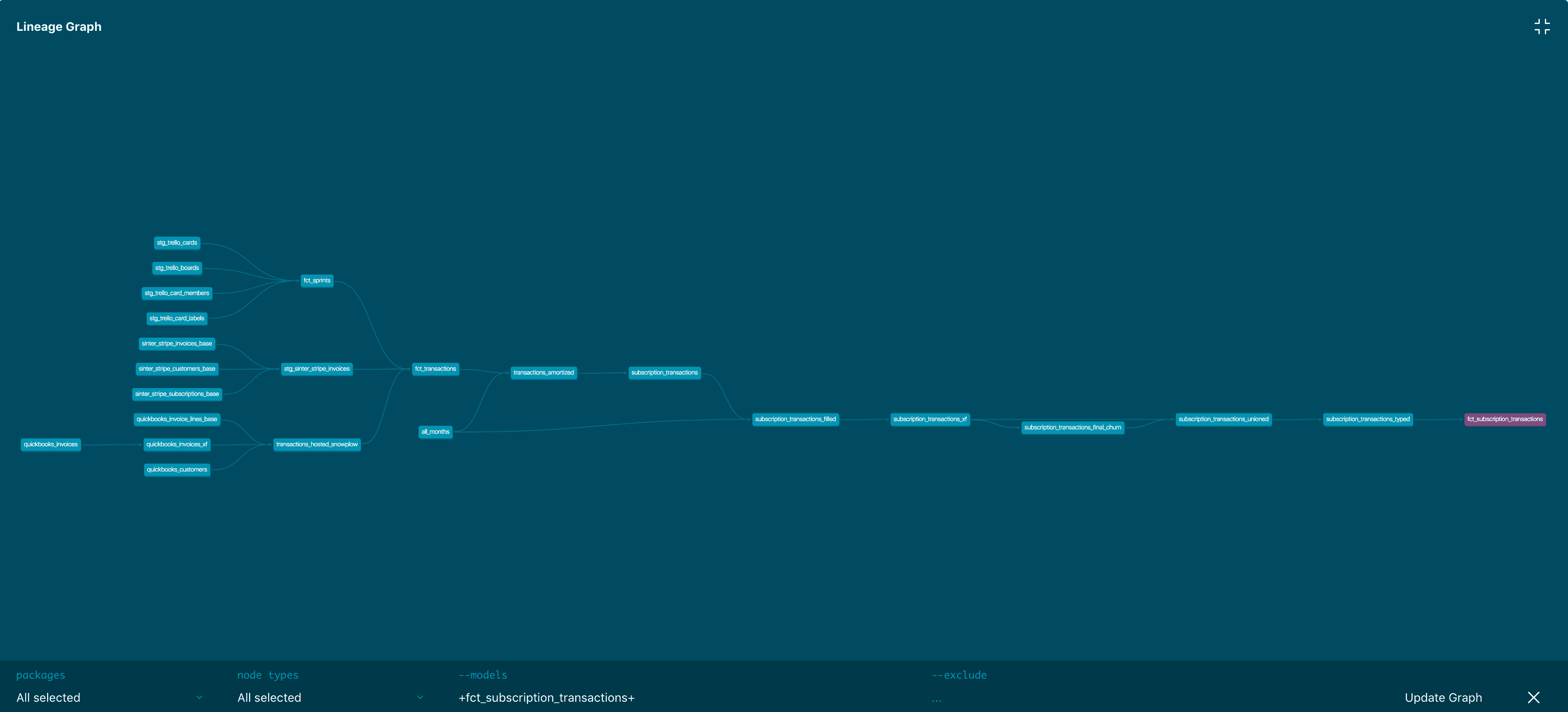
En observant la lignée des données, nous avons vu des équipes utiliser différents outils pour différentes capacités. Voici un exemple de dbt. Les équipes de données utilisent également leurs outils d'ingestion de données (ex : Airflow) ou leurs outils de transformation des données ou GitHub pour parvenir à leur analyse de causes racines. Source de l'image : dbt
Contrôle et Confiance pour Tous
S'attaquer de front à l'analyse des causes racines stabilise les données pour un avenir à l'épreuve du temps, aide les équipes de données à prévenir les problèmes récurrents et stabilise la qualité des données dans toute l'organisation. C'est à cela que devrait ressembler la résolution d'incidents et la prévention des problèmes de qualité à l'avance, et c'est pourquoi nous voulions que l'anomalie de détection des séries temporelles soit si facilement accessible. Elle peut être utilisée dans de nombreux secteurs et à des fins variées.
Bien qu'il existe de nombreux types d'anomalies, celles importantes pour les entreprises sont les outliers additifs (les pics inattendus ou les baisses soudaines dans les données) ; les changements temporels (tendances) ; et les changements de niveau saisonnier.
Vous verrez des exemples de ceux-ci dans le commerce électronique : changements soudains dans le nombre de transactions terminées ou pics de demande inattendus ; erreurs difficiles à trouver telles qu'un article mal tarifé ou un calcul fiscal inexact. Dans la fabrication : suivre et surveiller les équipements et machines avec des appareils IoT connectés pour prévenir les temps d'arrêt et les interruptions. Et dans la finance : suivre et surveiller le prix d'un ensemble d'actifs dans le temps pour détecter d'éventuels pics ou agrégations de données erronées.
Les Données Permettent la Transformation et le Changement
Alors que de nombreuses entreprises modifient leur modèle pour se concentrer sur l'expansion de leur portefeuille de produits numériques et créer cette expérience en ligne ultime, le besoin de données de haute qualité augmente.
Zalando SE est une plateforme de vente au détail de mode en ligne européenne, fondée en 2008 à Berlin, en Allemagne. Des données et une technologie de bonne qualité sont une partie importante de la culture avec des équipes construisant des produits de données sur lesquels toutes les décisions commerciales sont basées. Son ambition est de devenir le point de départ de la mode à travers l'Europe. Avec 42 millions de clients dans 20 marchés, c'est l'une des entreprises qui a bénéficié de la pandémie, comme l'a partagé le Dr Alex Borek lors de Soda Live. Alex a expliqué que Zalando soutenait les détaillants hors ligne pour qu'ils deviennent en ligne, en tant que moyen de rendre à la communauté, car beaucoup de détaillants et d'entreprises de mode ont lutté lorsque les magasins physiques ont fermé.
Les entreprises capables d'utiliser les données en toute confiance sont également mieux préparées pour comprendre les besoins soudains et en constante évolution de leurs clients et mieux anticiper l'augmentation des transactions de commerce électronique et la montée de l'activité en ligne pour s'aligner sur les priorités et offrir une expérience client numérique superbe.
NN Investment Partners (NN IP) est un gestionnaire d'actifs néerlandais avec un siège social à La Haye, aux Pays-Bas, et des bureaux dans 15 pays à travers le monde. Chez NN IP, les données et la technologie sont utilisées pour les décisions d'investissement - l'analyse fondamentale, les données en temps réel et l'intelligence artificielle aident NN IP à investir de manière responsable et à obtenir les rendements maximums pour leurs clients. "L'ensemble de l'expérience client chez NN Investment Partners est en fait sécurisé grâce à des vérifications et des équilibres appropriés autour des données," a partagé Martijn Spaan, Chef des Données & Surveillance, pendant Soda Live. Combiner la créativité humaine et la rigueur des machines conduit à des prises de décision plus solides.
Les Avantages d'Observer un Comportement Anormal dans les Données
L'anomalie de détection des séries temporelles dans Soda est toujours activée. Dès que les ensembles de données sont intégrés, la détection d'anomalies est automatiquement configurée pour les principales métriques de qualité des données, telles que le nombre de lignes (volumes) et les temps d'arrivée (fraîcheur).
Beaucoup d'entre nous chez Soda ont, à un moment ou à un autre, fait partie d'une équipe de données travaillant tard dans la nuit pour identifier et résoudre des problèmes de données. Nous comprenons la peur de ne pas savoir, de découvrir des problèmes de données trop tard et la douleur de remettre les choses en ordre après coup. Tant de temps est passé - et gaspillé - à éteindre des incendies.
L'objectif est de permettre à tout le monde d'utiliser les données. La valeur réside dans les insights que les anomalies fournissent pour permettre aux utilisateurs d'intervenir, d'initier une analyse plus approfondie et de prendre des mesures. Pour toute organisation, cela se traduira par un contrôle et une confiance dans les données, et des avantages commerciaux, y compris des revenus et des efficacités accrus, une expérience client améliorée, des risques réduits et un avantage concurrentiel.
Toutes les organisations devraient pouvoir transformer et automatiser avec des données auxquelles elles peuvent faire confiance.
Si vous souhaitez mettre en œuvre l'anomalie de détection des séries temporelles de Soda sur vos données, inscrivez-vous pour un essai gratuit. Si vous avez besoin de données d'exemple, recherchez sur Google’s dataset.
Ce qui viendra ensuite
Chez Soda, ce n'est que le début de notre voyage pour construire des fonctionnalités intelligentes qui donnent aux équipes de données la capacité et le contrôle de créer des données de qualité, dignes de confiance, pour une organisation afin de stimuler des processus automatisés, des efficacités et des insights et décisions.
Voici un aperçu de ce que nous résolvons ensuite :
Suggestions de moniteur automatique basées sur les schémas et le comportement de vos données
Regroupement automatique des alertes provenant de flux de données similaires
Aider à identifier la cause racine des problèmes de données en analysant les données de diagnostic
Pour rester à jour, rejoignez notre communauté Slack ou inscrivez-vous pour rester connecté avec les nouvelles et mises à jour de Soda.
Pour demander une démonstration, veuillez nous contacter.












{kind=link}