
If you’ve been hearing the term “data contracts” everywhere but still don’t have a clear path from concept to implementation, you are not alone. Data contracts are gaining traction as distributed data ecosystems expand, but the path from theory to practice is far from straightforward. Most teams understand the idea of data contracts, but struggle to turn shared expectations into something that is actually enforced in production.
When quality rules are scattered across pipelines, teams lose a shared understanding of what “good data” actually means. Consumers cannot easily see what has been validated, producers do not know which guarantees downstream users rely on, and metadata quickly drifts away from reality. What works for individual pipelines fails at the organizational level, where trust needs to span teams, domains, and use cases.
Data contracts address this gap by introducing a shared, enforceable agreement between data producers and data consumers. Instead of relying on scattered, pipeline-specific checks, they provide a structured way to make expectations explicit, visible, and reliable across teams and systems.
This article walks through what a data contract is, why data quality programs built on shared documentation keep breaking, what shifts when contracts ship as code, and who actually owns them.
Key Takeaways |
|---|
|
What is a Data Contract?
A data contract is an enforceable agreement between data producers and data consumers that defines how data should be structured, validated, and governed as it moves through a pipeline.
It acts as an interface layer, explicitly defining what data is provided, under which conditions, and with which guarantees. Similar to an API in software development.
In software engineering, APIs define the sructure, guarantees, and behavior that downstream systems can rely on. They encapsulate internal logic and expose only intentional, stable interfaces. Data contracts apply the same principle to data engineering by defining the rules that producers must meet and the conditions that consumers can depend on.
At the same time, data contracts turn those expectations into executable specifications that can be continuously verified against production data.
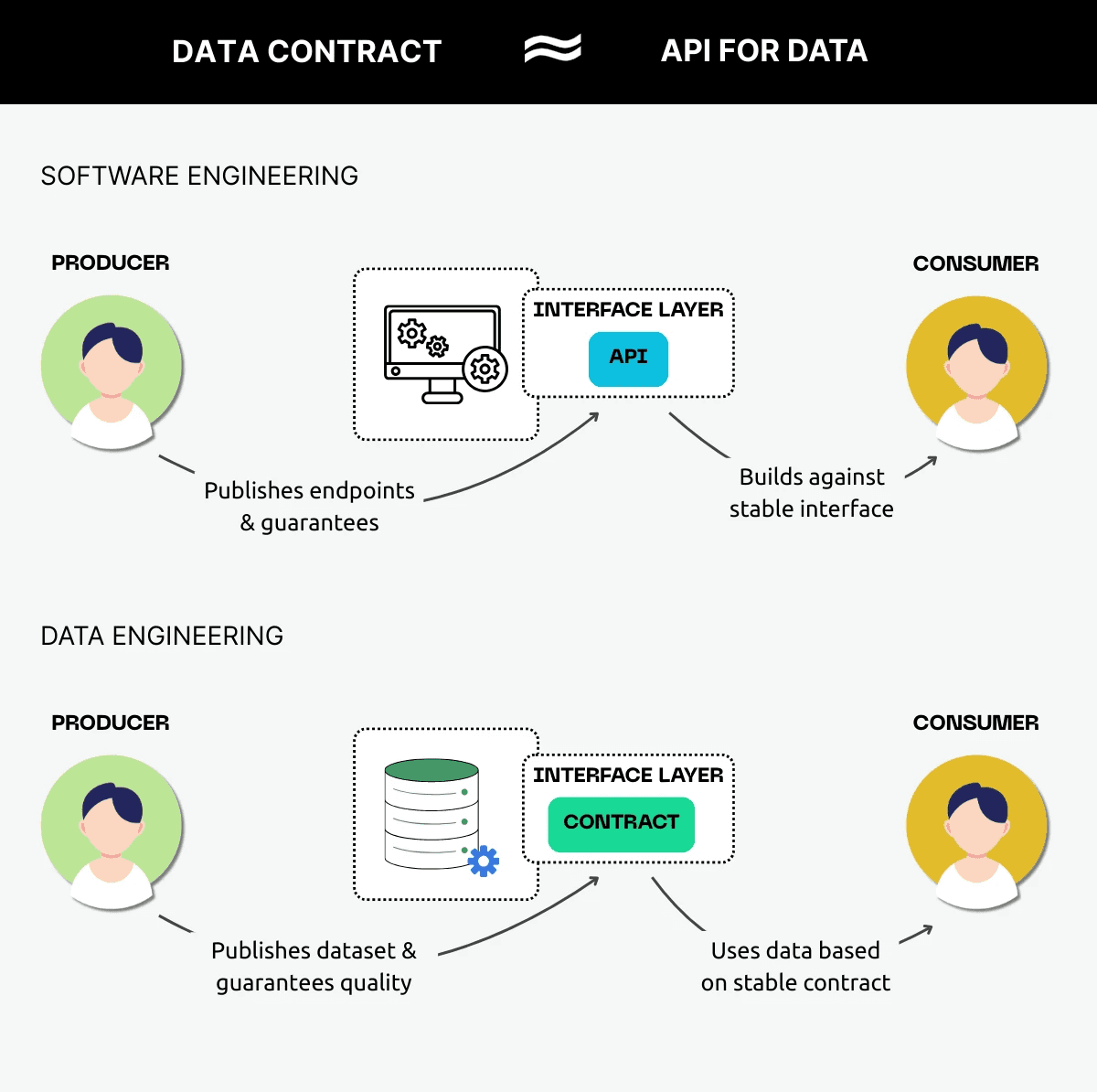
The data contract becomes a shared interface that both sides, producer and consumer, can access, understand, and validate against, creating a shared source of truth and turning expectations into explicit, reusable, and enforceable rules.
As a result, schema, nullability, freshness, ranges, and domain constraints stop being informal guidelines and become explicit guarantees backed by automated validation before data moves downstream.
A data contract moves data governance from descriptive documentation toward executable expectations.
Mind you, a data contract is not static one-time documentation, a schema definition, or just a list of requirements. It is a system of record for metadata that is machine-readable, executable, and automatically verifiable. Above all, it is authoritative: a single shared interface where rules are defined, agreed upon, versioned, and enforced across the entire data lifecycle.

In short, a data contract separates two related concerns and brings them together in a controlled way:
As an interface for data, it defines what producers promise to deliver and what consumers can rely on in terms of structure, semantics, and usage.
As an executable specification, it continuously verifies key properties — such as schema and critical quality rules — on every new batch of data.
By creating a record for metadata and testing what is testable, data contracts prevent metadata from drifting away from reality and create a reliable source of truth that stays in sync with the data itself.
Why Data Contracts Matter
The core challenge in any data ecosystem is to deliver the right data, in the right place, at the right time, and with guarantees that consumers can trust. As organizations grow, data becomes more distributed across domains, teams, and systems. Yet the way data is validated and published rarely evolves at the same pace.
In practice, most organizations treat data production as an internal engineering concern rather than a release process. New batches of data are made available to consumers without consistently verifying whether they still match the expectations that downstream users depend on. This disconnection creates three systemic problems.
Misaligned expectations between producers and consumers, caused by the absence of a shared, explicit interface for data.
Fragmented and inconsistent validation, where quality checks depend on individual pipelines and engineering practices rather than enforced standards.
No authoritative source of truth, leaving consumers unable to verify whether data actually matches its published expectations.
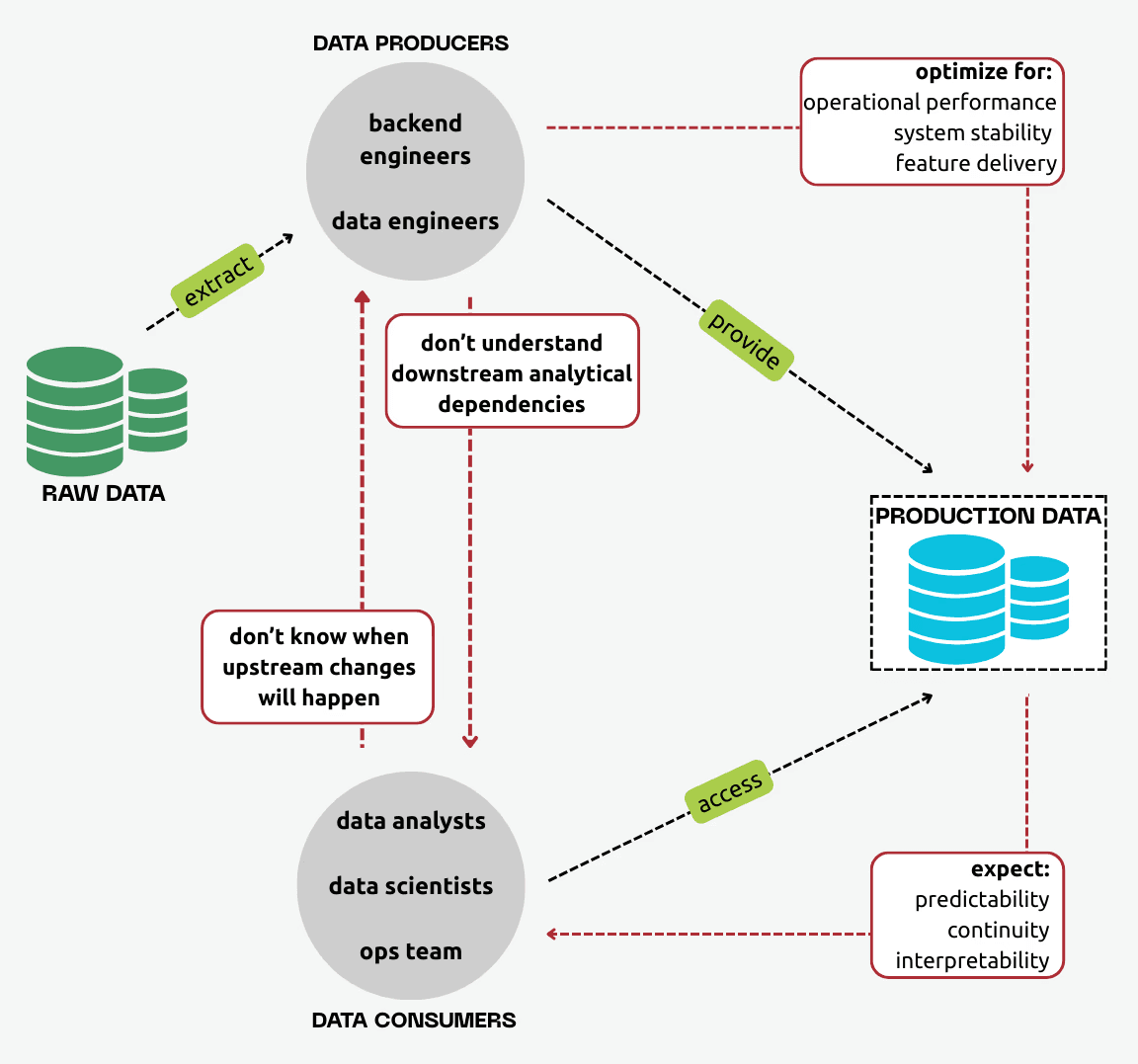
Misaligned Expectations Between Teams
Producers optimize for operational performance and speed of delivery, while consumers optimize for analytical continuity and interpretability. Data engineers sit between the two, trying to reconcile incompatible incentives while keeping pipelines reliable and scalable.
More often than not, producers have no visibility into what consumers depend on, and consumers have no guarantee that upstream changes won’t break them.
A producer might rename or remove a field because the change makes sense in the application they maintain, unaware that the same field feeds forecasting models, operational dashboards, or compliance reports.
Without an explicit, shared contract, expectations remain implicit and fragile. The solution requires a formal interface that clearly states what producers commit to deliver and what consumers are allowed to rely on.
Fragmented and Inconsistent Validation
When expectations are not shared or explicit, changes propagate unpredictably, and teams discover issues only after downstream logic has already broken. Engineers may add checks to their pipelines, but whether data is tested, and how thoroughly, depends on individual judgment and local practices. As a result, some datasets are well validated, while others are barely checked at all.
From an organizational perspective, this makes it impossible to guarantee a minimum level of quality. For consumers discovering data in catalogs or discovery tools, there is no reliable way to know whether a dataset has been verified or what guarantees it actually provides.
Consequently, no one can see the full set of expectations, and no mechanism ensures they are applied consistently across datasets or environments.
If every new batch of data is effectively a release, then validation cannot be optional. It must be systematically enforced before data is published to consumers. This requires workflows and guidelines that ensure testing is a prerequisite for making data available.
Lack of Authoritative Source of Truth
Even when teams document expectations, that documentation is usually descriptive rather than enforceable. Because it is disconnected from execution, it becomes outdated as soon as the underlying data changes. Teams then end up relying on informal alignments and reactive debugging rather than explicit agreements.
Producers often do not know which expectations truly matter, and consumers cannot verify whether the data they receive still conforms to what was promised. The fundamental issue is the absence of a single, authoritative source of truth that reflects both intended expectations and actual data behavior.
What’s needed is an executable system of records, one that stays aligned with reality by continuously validating data against published expectations.
➡️ Read more at Why Data Contracts: 5 Reasons Leaders Should Start Now
To put it simply, misaligned expectations, fragmented validation, and the absence of a shared source of truth all point to the same underlying issue: data is published without a clearly defined and enforced interface. As a result, changes propagate unpredictably, and breakage is often discovered only after downstream systems fail.
A contract-driven development addresses the issues above by treating the data contract as the API for data, thereby making breaking changes visible, reviewable, and testable before they reach consumers.
Data Contracts as Code
Most data contracts in production today are descriptive: a YAML spec in a repo nobody reads, a Confluence page that captures last quarter’s expectations, a schema doc updated only after the next breakage. They tell you what should be true. They don’t enforce it.
That distinction is the missing layer. A contract that ships as code — versioned in Git, evaluated on every new batch of data, reviewed in pull requests — is what producers and consumers actually owe each other.
When the contract lives in the same workflow as the pipeline that produces the data, drift between specification and reality stops being possible. The pipeline either meets the contract or it does not, and either outcome is observable, owned, and actionable.
This is why Soda treats data contracts as the executable layer in modern data quality: not as a separate tooling category, but as the missing primitive that turns governance from descriptive intent into enforced reality.
Contract-Driven Development
Now, how does a data contract actually work in practice, and how does it prevent breakage over time?
In practice, contract-driven development introduces a shared workflow:
Consumers define the expectations they rely on to build reports, models, and applications.
Producers implement and enforce the contract, committing to deliver data that meets consumers’ expectations.
Pipelines enforce the contract automatically, validating every new batch of data before it is made available downstream.
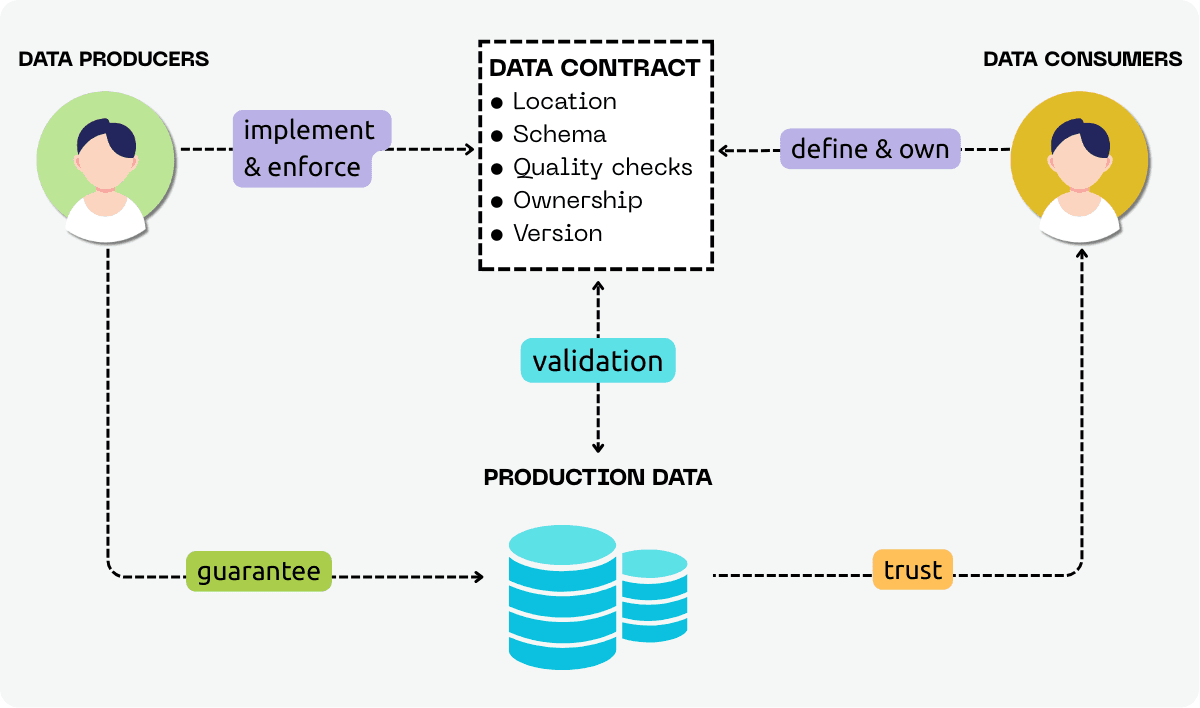
Contract validation is integrated into the pipeline as an automated guardrail. Every new batch of data is treated as a release and cross-checked against the published contract before it reaches consumers. Breaking changes are detected early, incompatible updates are identified quickly, and trust is maintained across teams.
As a result, data contracts generate:
a shared, explicit agreement between producers and consumers.
a unified, consistently enforced specification
a single authoritative specification that defines, versions, and enforces what quality means
Soda lets engineers define contracts as code in YAML, analysts manage them in a no-code Cloud UI, and anyone use the AI-assisted Contract Copilot to translate plain-language expectations into executable checks.
For an implementation walkthrough — including how contracts scale across datasets, version safely, and integrate with CI/CD — see The Definitive Guide to Data Contracts
What is Inside a Data Contract?
In practice, data contracts can include many elements: ownership, documentation, versioning, and compatibility guarantees. At Soda, we focus on the executable core of a data contract: the quality expectations that can be continuously validated against production data.
Therefore, implementing data contracts means approaching data quality as code. Teams can create a reproducible, testable, and continuously enforced quality layer by defining expectations in a version-controlled contract and executing them directly in the pipeline.
While implementations vary, a data contract typically includes the following core elements:
Dataset Information:
The contract is explicitly tied to a single dataset or data product and defines where that data lives.
Dataset Level Checks:
These are expectations that apply to the dataset as a whole, such as row count thresholds, freshness, completeness, or cross-column constraints.
It also usually includes schema and structural guarantees that enforce column names, data types, and required fields.
Column Level Checks:
These rules define acceptable values, ranges, patterns, or distributions that apply to specific columns, such as missing values, valid values (e.g., regex, range), and aggregations (e.g., average, sum).
See the data contract example in YAML format below:
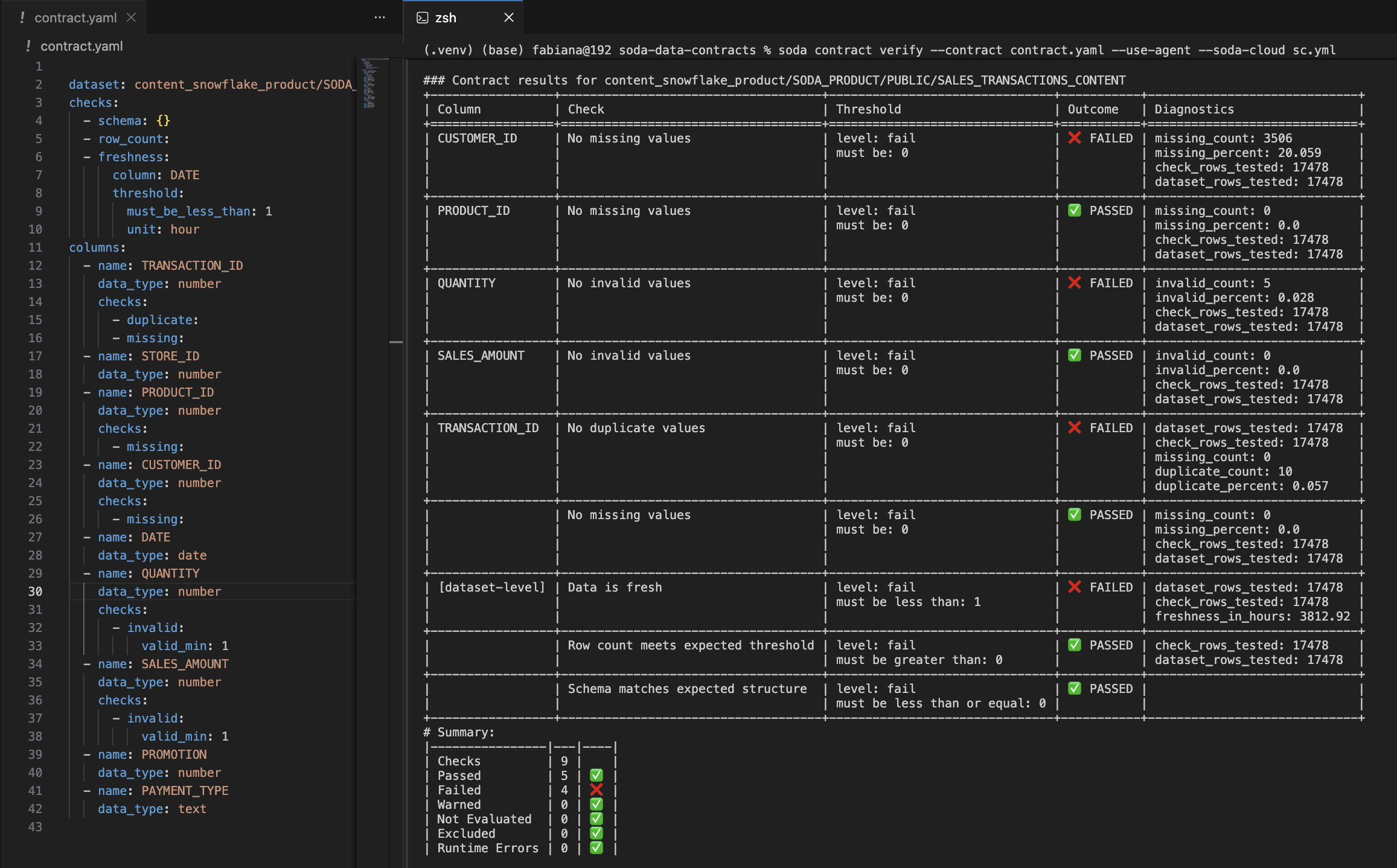
↗ Git-managed Soda data contract in YAML beside CLI verification output with per-check pass/fail results across columns.
When checks fail, they surface issues that should be investigated. When integrated in CI/CD pipelines, contracts can trigger notifications to the responsible teams or even halt the flow until the problem is found and fixed.
There will be no more partial guarantees buried in transformations, disconnected documentation, or guesswork about what “good data” means. The pipeline either meets the contract or does not, and when it does not, failures are documented with clear roots and actionable context.
Starting with the most important datasets, teams can gradually expand using a collaborative approach where stakeholders propose checks, decide on thresholds, and define data quality standards together.
Who Owns the Data Contract?
Ownership of a data contract does not mean responsibility for implementation. Instead, it reflects who defines the requirements versus who is accountable for enforcing them in production.
Effectively, data contract ownership should sit with data consumers, not producers. Because producers optimize for operational concerns and often don’t see downstream analytical impact, if producers define contract expectations by themselves, contracts tend to reflect what’s easy to produce, not what’s safe to consume.
Consumers are uniquely positioned to define contract requirements because they understand the analytical and business impact of data quality failures. They are the only ones who truly know:
which fields are business-critical
which value ranges are acceptable
which freshness, completeness, and reliability guarantees are required
This does not mean consumers enforce contracts themselves.
Enforcement belongs in the pipeline, typically owned by data engineers and producers. Consumers set expectations, producers commit to deliver them, and pipelines automatically make sure they are met.
Best Practices for Effective Data Contracts
A data contract addresses the struggle data governance has long had to bring data standards and documentation from “paper” to code. It not only defines what the data should look like, but also consistently verifies the specifications added so that the right teams can be alerted when a condition fails.
However, implementing data contracts should not require a complete redesign of your data architecture. You can start small, demonstrate value, and then gradually scale up.
Start with critical data. Putting every dataset under a contract is impractical. Begin with business-critical dashboards and ML inputs that require consistency, so effort is directed where it is most effective. Then expand coverage based on pain points and business value.
Enable cross-team collaboration. Contracts succeed when producers understand value and consumers express their needs. Both parties should work together to define the contract.
Formalize communication. Treat contract changes as first-class events. Use tickets, change logs, or pull requests to document updates. Good communication reduces surprises and increases team trust.
Define clear ownership. Ensure that when things break, someone is notified and can approve changes.
Automate enforcement. Automate CI pipeline checks and set up breach alerts.
Version contracts deliberately. Control contract updates, including new versions and backward compatibility checks
Monitor over time. Set up monitoring on key contracts to detect anomalies or drift over time.
Integrating these practices into the data engineering workflow leads to improvement of the data ecosystem, resulting in context-rich, well-governed, and trustworthy data.
Whether verifying row counts, missing or invalid values, or schema integrity, the goal is to catch issues early, reduce incidents, and reassure data consumers. By introducing validation rules and clarifying expectations, data contracts enhance transparency and make the data ecosystem inherently more robust.
Have Questions?
Schedule a talk with our team of experts or request a free account to discover how Soda integrates with your existing stack to address current challenges.
Frequently Asked Questions
How do data contracts integrate with CI/CD pipelines?
Contract definitions are stored as code (for example, in YAML) and versioned in Git. During CI/CD runs, contract checks are executed as part of ingestion, transformation, or deployment steps.
Why is YAML Soda’s language for Data Contracts?
YAML is a format compatible with any Git-based version control, allowing for versioning, pull requests, and integration into an engineering workflow. Also, it offers readability and does not require any coding knowledge, enabling all personas (analysts, domain experts, business users) to read and understand the contract.
Are data contracts a process or a technical change?
Both. Technically, they introduce executable specifications, automated validation, and contract enforcement in pipelines. Organizationally, they formalize producer-consumer collaboration by making expectations explicit, versioned, and reviewable.
Do data contracts replace data observability tools?
No. Data contracts and data observability solve different, complementary problems. Data contracts are preventative measures that define and enforce known expectations (schema, constraints, freshness, and business rules) before data is consumed. Data observability is a detective technique that monitors datasets in production to identify unknown issues such as drift, anomalies, or unexpected distribution changes.
What happens when a contract check fails in production?
When a contract check fails, the outcome depends on how the pipeline is configured. Common actions include: routing failed records to quarantine or error tables; triggering alerts for investigation without stopping the pipeline; blocking propagation of invalid data to downstream systems; or failing the pipeline entirely for critical violations.











