Publié
16 avr. 2025
Mise en œuvre des Data Contracts à grande échelle

Un Data Contract est un accord formel entre les producteurs de données et les consommateurs de données qui définit à quoi devraient ressembler des « bonnes données ». Il fixe des attentes concernant le schéma, la fraîcheur, les règles de qualité, et bien plus encore, et rend ces attentes explicites et vérifiables.
Les contrats de données gagnent en popularité car ils introduisent l'encapsulation dans l'ingénierie des données. L'encapsulation en ingénierie logicielle est un principe visant à garder les différentes parties d'un système séparées pour que les modifications d'une partie ne perturbent pas le reste du système de manière involontaire.
Cependant, dans l'ingénierie des données, ce principe a été ignoré. Traditionnellement, la gestion des données s'est concentrée sur la détection et la résolution des problèmes après leur survenue. Les contrats de données modifient cette approche en prévenant les problèmes à la source. Ils créent des accords bien définis entre les producteurs de données (qui génèrent et gèrent les données) et les consommateurs de données (qui en dépendent).
Ces règles fonctionnent comme des API en logiciel, garantissant que les données suivent un format et un standard de qualité fixes. Cela simplifie la confiance et l'utilisation des données sans craindre des erreurs soudaines.
Lisez notre autre article sur les 5 avantages les plus importants que l'on peut obtenir grâce à l'adoption des contrats de données : Pourquoi les contrats de données : 5 raisons pour lesquelles les dirigeants devraient commencer dès maintenant
Tutoriel : Mettre en œuvre les contrats de données à grande échelle
Dans ce blog, nous vous guiderons à travers l'écriture et la vérification des contrats de données tout en mettant l'accent sur les meilleures pratiques. Nous verrons également comment plusieurs contrats peuvent interagir de manière fluide au sein d'une base de données de chaîne d'approvisionnement simple. C'est un blog complet qui vous aide à démarrer un contrat de données de zéro à son échelle.
Configuration de Soda pour les contrats de données
Pour ce tutoriel, nous utiliserons Soda. Si vous l'avez déjà installé et configuré sur une source de données, vous pouvez passer cette section et aller à Écrire votre premier contrat de données.
Étape 1 : Vérifier les prérequis
Soda nécessite une version de Python supérieure à 3.8. J'utilise Python 3.13 avec la version de pip 24.2. J'ai déjà configuré Docker Desktop et PostgresDB. Il existe des moyens de configurer Soda sans Docker. Pour explorer d'autres options, veuillez vous référer à la documentation.
Étape 2 : Installer Soda pour PostgreSQL
Ouvrez votre terminal et créez un répertoire pour votre projet Soda :
Il est préférable d'installer Soda dans un environnement virtuel pour garder les dépendances propres. Exécutez :
Puisque j'utilise une base de données PostgreSQL pour stocker mes données, j'installerai soda-Postgres.
Si vos données résident ailleurs, installez le connecteur Soda approprié. Dans votre environnement virtuel, exécutez la commande suivante :
Vérifiez l'installation et vous êtes prêt.
Étape 3 : Configurer un exemple de base de données PostgreSQL à l'aide de Docker
Pour vous permettre de prendre un premier goût de Soda, vous pouvez utiliser Docker pour créer rapidement une source de données PostgreSQL exemple contre laquelle vous pouvez lancer des analyses pour la qualité des données. La source de données exemple contient des données pour AdventureWorks, une organisation fictive de commerce électronique en ligne.
Ouvrez un nouvel onglet dans le Terminal.
Si ce n'est pas déjà fait, démarrez Docker Desktop.
Exécutez la commande suivante dans le Terminal pour configurer la source de données exemple prête.
Attendez le message : "Le système de données est prêt à accepter les connexions."
Cela signifie que la base de données est en marche ! Nous pouvons passer à l'écriture d'un contrat.
Écrire votre premier contrat de données
Un contrat de données est un accord formel entre les producteurs et les consommateurs de données qui définit la structure, la qualité et les attentes concernant les données.
Les contrats de données Soda constituent une bibliothèque Python qui applique la qualité des données en vérifiant les contrôles sur les données nouvellement produites ou transformées.
Les contrats sont définis dans des fichiers YAML et exécutés de manière programmatique via l'API Python, garantissant que les données respectent les standards prédéfinis avant de passer en aval.
Bien qu'ils soient encore expérimentaux, les contrats de données peuvent être intégrés dans les workflows CI/CD ou les pipelines de données pour détecter les problèmes précocement. La meilleure pratique consiste à vérifier les données dans des tables temporaires avant de les ajouter à des ensembles de données plus volumineux.
J'ai déjà créé une base de données appelée dairy_supply_chain dans mon dbms Postgres local. Les attributs utilisateur et mot de passe ne sont pas liés à Soda mais à la base de données. L'API Soda l'utilisera pour accéder à la base de données.
Ensuite, dans le répertoire racine de votre projet (dc_from_scratch/), créez un fichier de configuration de source de données nommé data_source.yml.
Le fichier source de données est un fichier de configuration qui définit comment Soda Core se connecte à une source de données spécifique.
Créez un répertoire pour stocker vos contrats de données et, à l'intérieur, créez un fichier .yml distinct pour chaque ensemble de données. Pour simplifier, je nomme chaque fichier de contrat d'après l'ensemble de données correspondant.
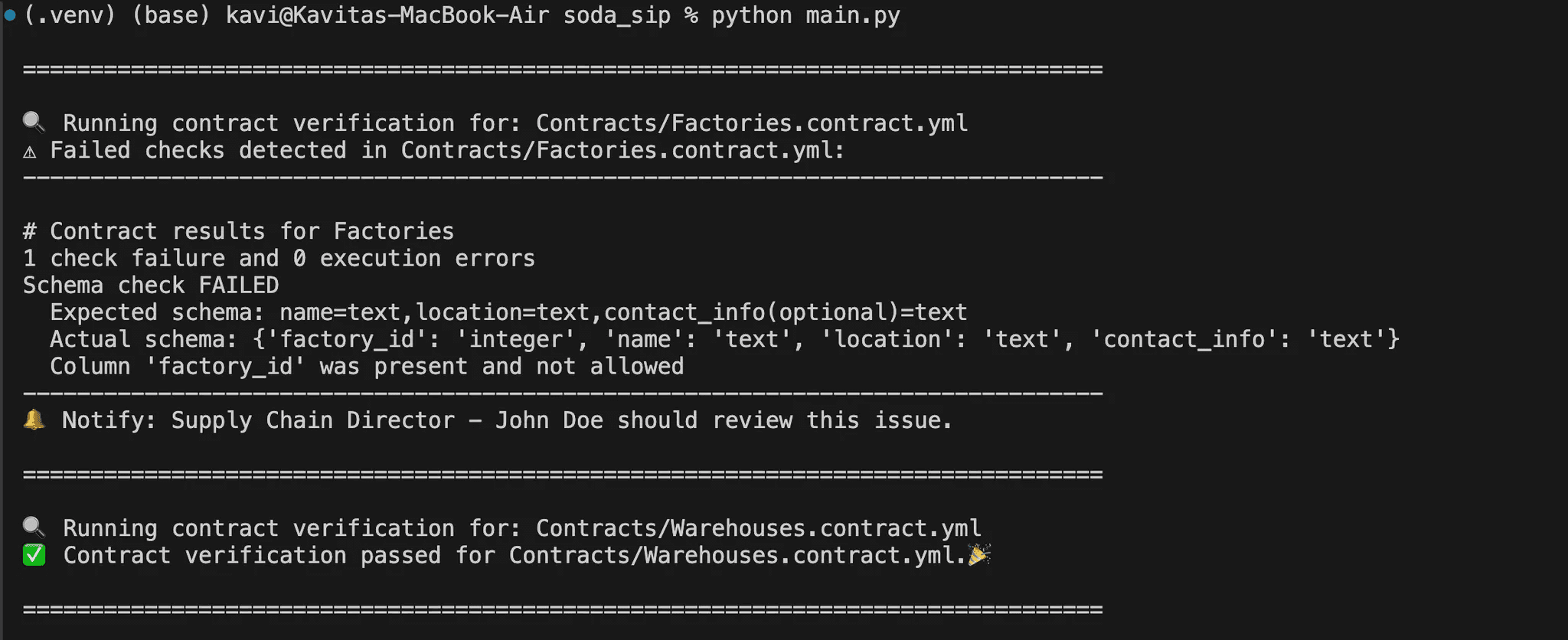
Par exemple, voici le fichier Factories.contract.yml pour l'ensemble de données Factories.
Chaque contrat définit les colonnes requises, leurs types de données, et vérifications de validation si nécessaire. Chaque colonne de l'ensemble de données doit être explicitement listée avec son type de données.
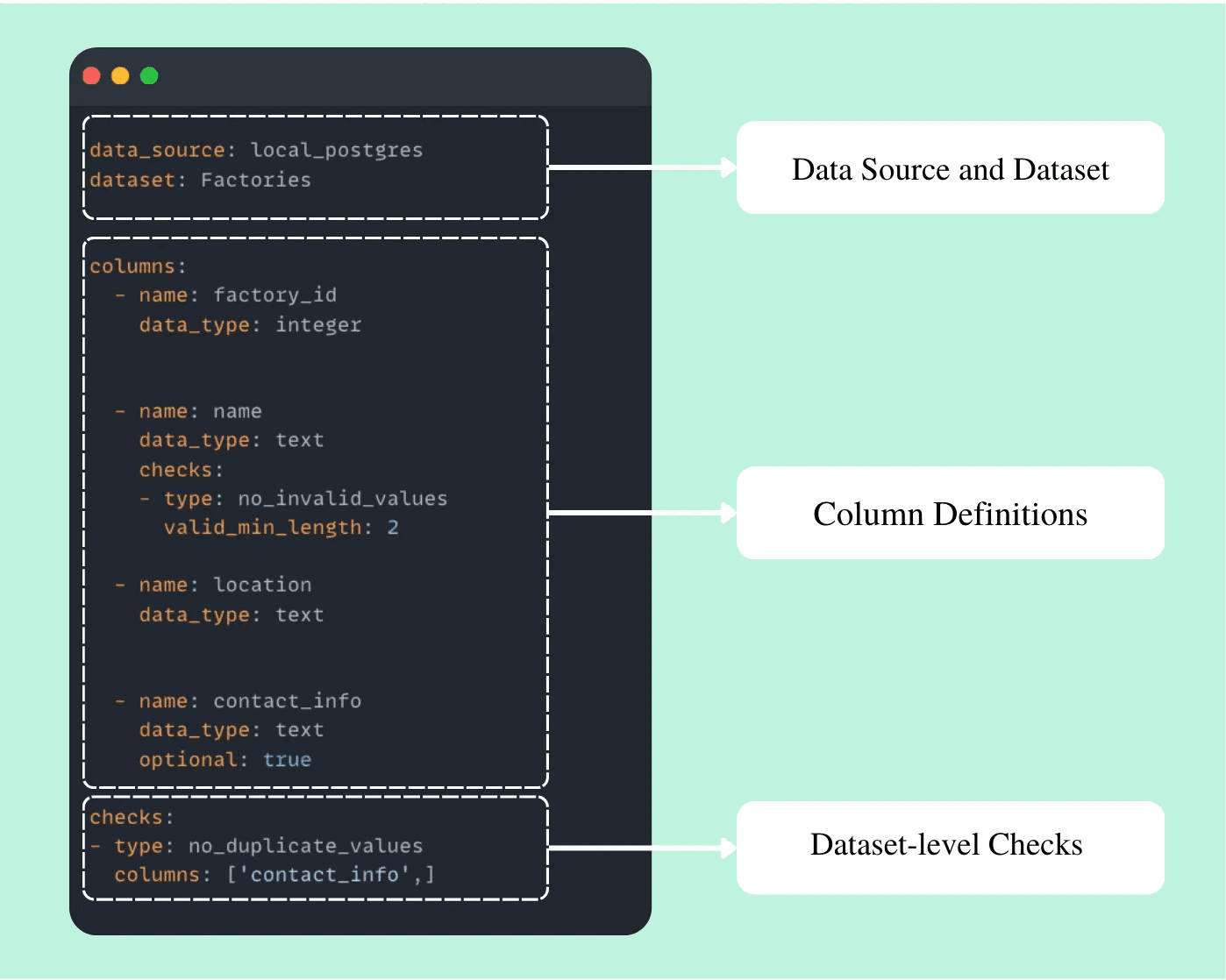
Vérifier un contrat de données
Ensuite, nous devons créer un fichier main.py qui sera responsable de l'exécution de la vérification des contrats de données à l'aide de Soda Core. Si une règle est violée, le script identifie l'échec et fournit des détails pour une action ultérieure.
Il charge d'abord la configuration de la source de données depuis data_source.yml, qui contient les détails de connexion à la base de données. Ensuite, il exécute un processus de vérification de contrat en chargeant le fichier de contrat (Factories.contract.yml) et en vérifiant si l'ensemble de données respecte les règles définies.
Si la vérification réussit, il imprime un message de succès ; sinon, il imprime un message d'échec avec les détails de ce qui s'est mal passé.
Exécutez ce script pour vérifier le contrat.
⛔ Vous pourriez rencontrer une erreur ModuleNotFoundError :
No module named 'soda data_sources spark_df_contract_data_source’
Pour résoudre cela :
pip3 install soda-core-spark-df
Avant de nous lancer dans le développement du reste des contrats, regardons certains des erreurs que vous pourriez rencontrer dans le processus et comment les gérer.
Appliquer des contrats de données à plusieurs tables
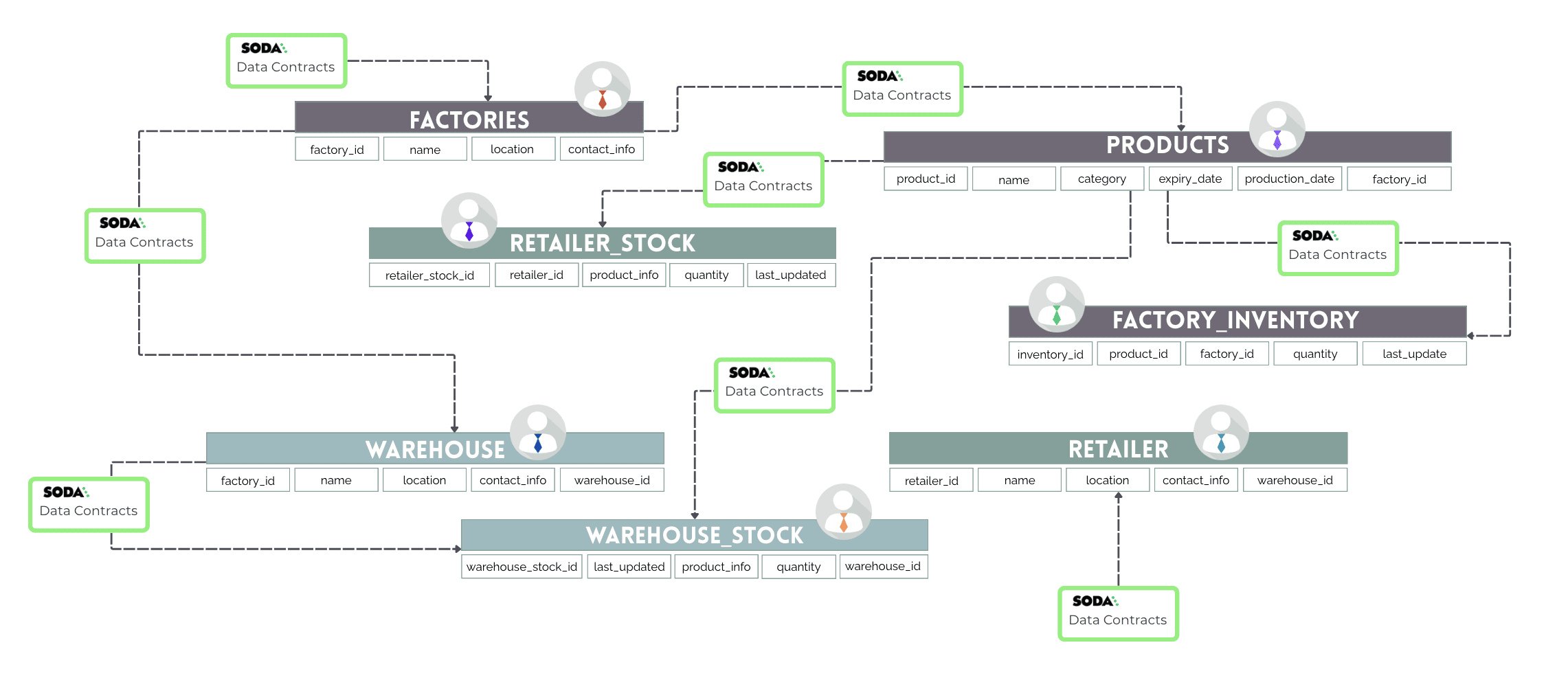
Reculons un peu et regardons le tableau d'ensemble de la façon dont l'ensemble complet de la base de données s'intègre.
Voici la base de données de chaîne d'approvisionnement laitière. Elle est conçue pour suivre le flux des produits laitiers, des usines aux entrepôts, puis aux détaillants, garantissant le bon fonctionnement des opérations de chaîne d'approvisionnement.
Les usines sont au cœur, là où les produits sont fabriqués.
Les entrepôts agissent comme points de distribution, stockant les produits avant qu'ils n'atteignent les détaillants.
Les détaillants sont l'arrêt final, vendant les produits aux clients.
Les tables d'inventaire et de stock aux niveaux aident à gérer les quantités et suivre les mises à jour.
Chaque ensemble de données a une fonction clé et dépend des autres de différentes manières. Vos contrats devraient refléter ces différences et appliquer des règles qui maintiennent l'intégrité des données.
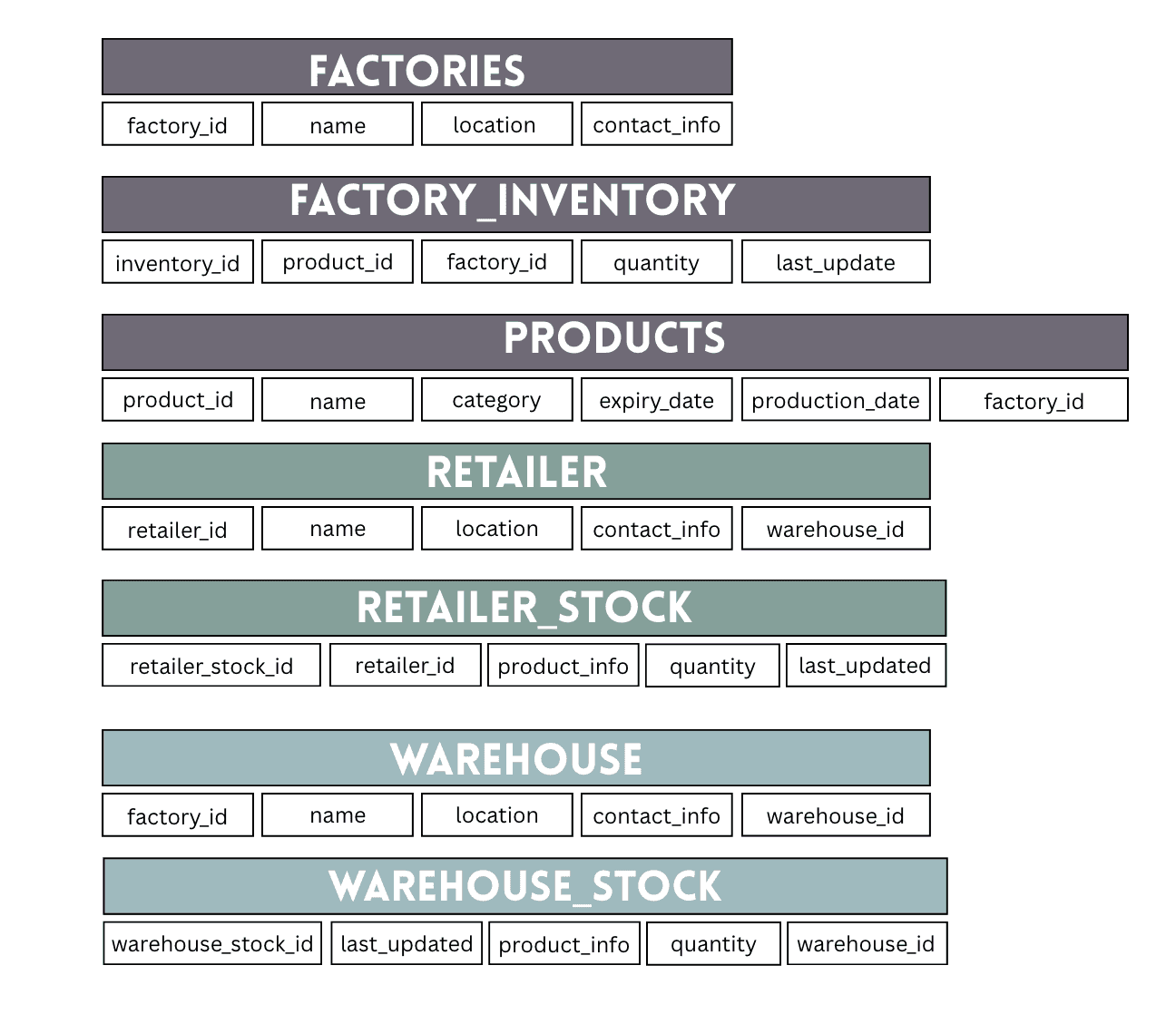
J'ai rédigé des contrats pour d'autres ensembles de données similaires à l'ensemble de données des usines. Je discute de certaines vérifications uniques que vous pouvez utiliser dans les contrats plus tard dans le blog. Pour l'instant, votre structure de répertoire sera similaire à celle-ci :

Contrats de données dynamiques
Notre script traite chaque contrat un par un dans une boucle, les vérifiant séquentiellement. Bien que cette approche fonctionne pour une configuration contrôlée, elle ne reflète pas le flux réel des données. Il n'y a pas d'ingestion de données dynamique, nous passons simplement en revue des contrats statiques après que les données ont déjà été ajoutées.
Si vous avez remarqué jusqu'à présent, les erreurs d'exécution provoquent la sortie du processus, mais le pipeline continue d'être exécuté même en cas d'échec de vérification. Cela compromettra certainement l'objectif des contrats.
Au lieu de vérifier tous les contrats dans une séquence fixe, nous devons passer à une approche plus basée sur des événements, où des vérifications sont déclenchées dynamiquement en fonction des données entrantes. Dans cette section, nous allons augmenter la complexité du pipeline de données maintenant que nous avons préparé nos contrats.
Avant tout, connectez la base de données avec votre environnement Python, comme ceci :
Le principe clé ici est qu'un contrat ne devrait être vérifié que lorsque ses dépendances sont satisfaites.
Un contrat de données bien implémenté fonctionne comme un gardien pour les mises à jour. Au lieu de permettre aveuglément les modifications, il vérifie et autorise l'entrée de données de haute qualité dans le système.
Par exemple, l'ensemble de données des Produits agit comme fondation pour le suivi des stocks.
Si un nouveau produit est ajouté ou mis à jour, il doit respecter toutes les normes de qualité des données avant de mettre à jour Inventory_Stock. Cela empêche que des enregistrements incorrects affectent les données historiques et maintient l'information exacte pour toutes les parties prenantes.
Ainsi, tous les ensembles de données ne dépendent pas les uns des autres. Si un contrat échoue pour un ensemble de données spécifique, les ensembles de données sans rapport ne devraient pas être affectés. Par exemple, même si la vérification des Produits échoue, l'ensemble de données des Entrepôts peut toujours traiter les mises à jour, car il fonctionne de manière indépendante.
Bien sûr, une mise en œuvre du monde réel du système serait plus sophistiquée, impliquant souvent des déclencheurs de bases de données et des mécanismes de mise en file d'attente pour gérer l'exécution des contrats efficacement.
Cependant, donné la portée de ce blog, nous nous concentrerons sur une version simplifiée pour illustrer le concept. Cela nous aidera à comprendre les principes de base de la mise en œuvre des contrats de données à grande échelle.
Ajoutez un Dependency_Map qui suit la relation de chaque ensemble de données, les contrats correspondants, le propriétaire des données et les ensembles de données associés.
Lorsqu'une requête est exécutée, le script vérifie d'abord les dépendances de l'ensemble de données à l'aide de DEPENDENCY_MAP. Chaque ensemble de données a un contrat correspondant et un propriétaire de données. Avant une mise à jour, il vérifie que tous les contrats requis ont réussi. Si une dépendance échoue, la mise à jour est bloquée, et une alerte est imprimée.
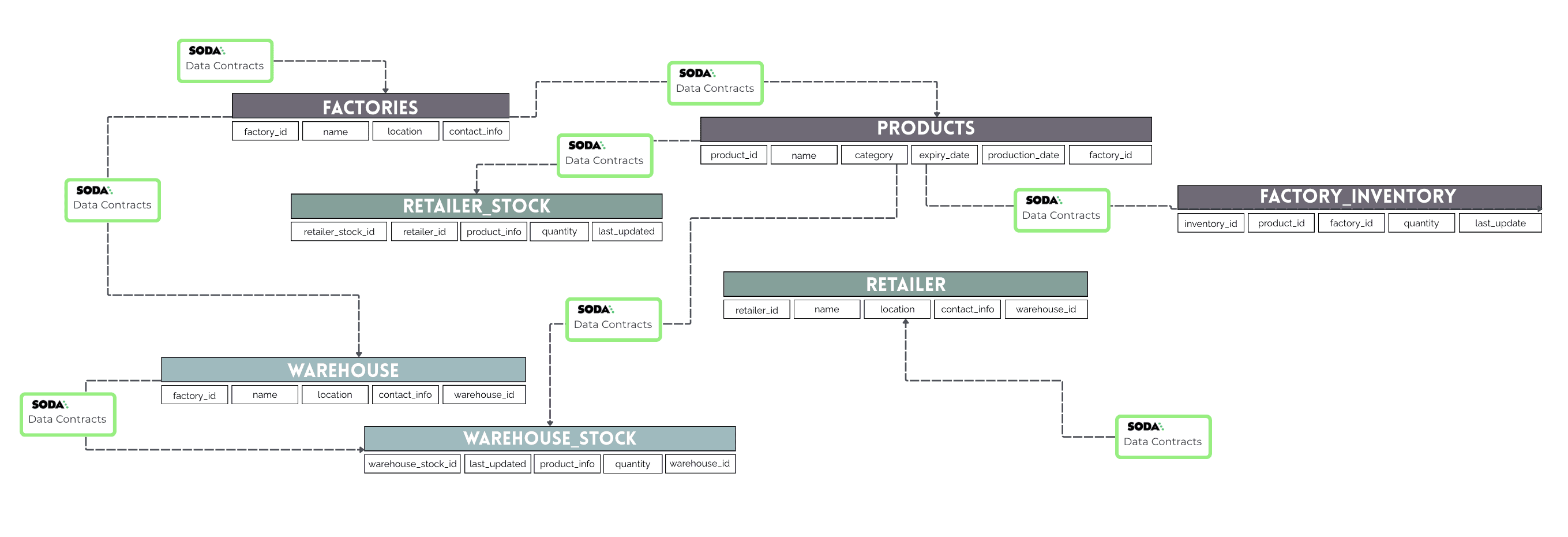
Si toutes les dépendances sont satisfaites, le script se connecte à la base de données PostgreSQL et exécute la requête. Toutes les erreurs rencontrées lors de l'insertion sont interceptées et affichées, empêchant les pannes du système.
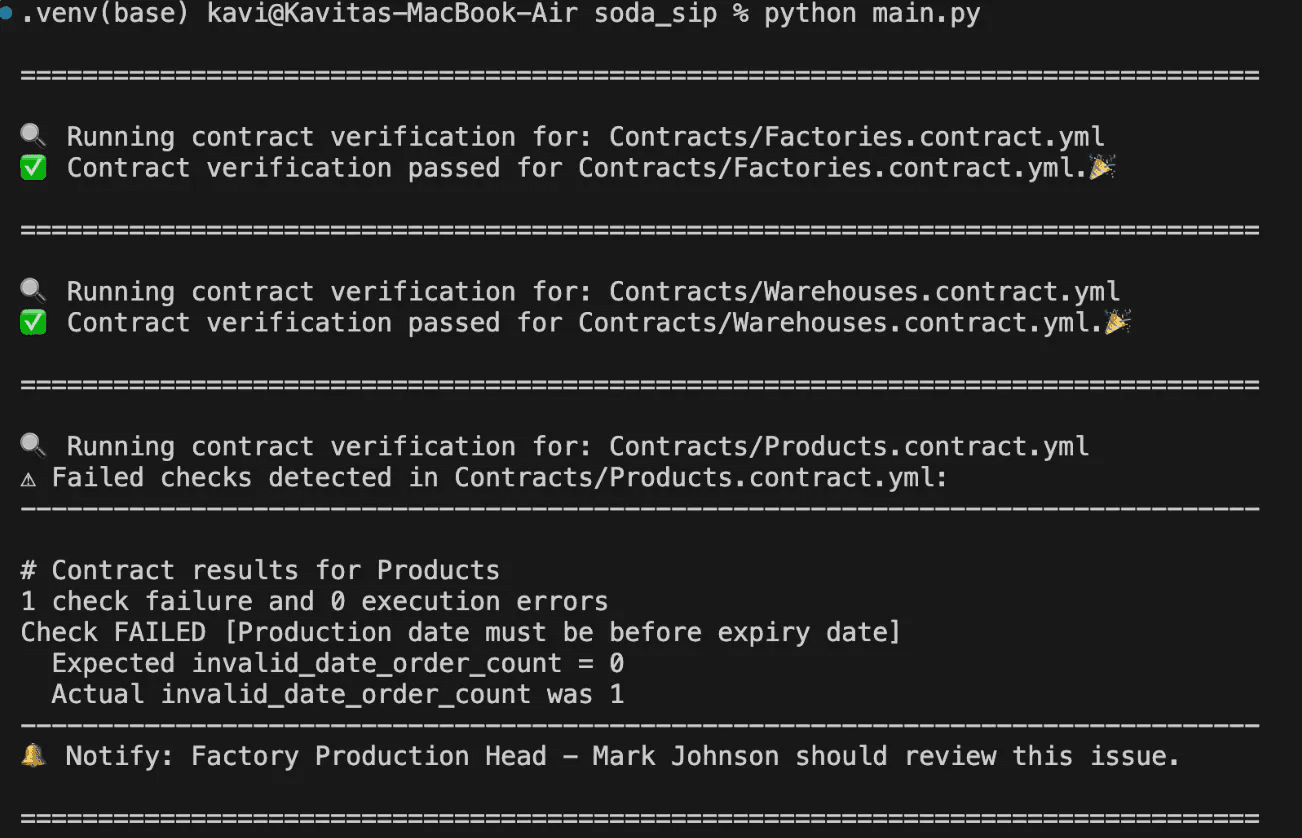
La sortie du script ci-dessus est la suivante :
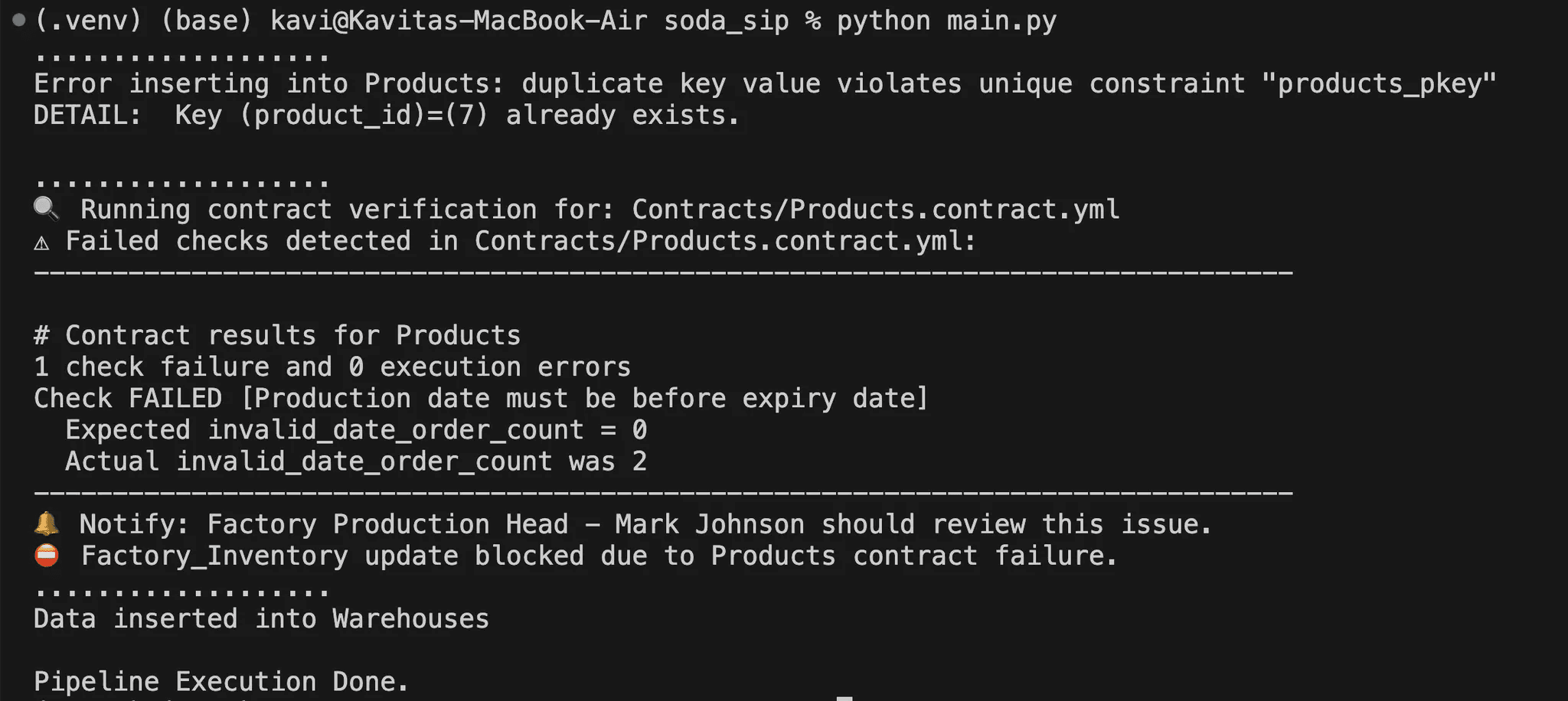
Lors de l'insertion de lignes de données, une vérification du contrat pour les Produits a détecté un problème : « La date de production doit être antérieure à la date d'expiration. »
Le contrat attendait zéro violation (invalid_date_order_count = 0), mais deux violations ont été trouvées. Cet échec a déclenché une notification au responsable de la production de l'usine, Mark Johnson, car il est le propriétaire des données.
Puisque Factory_Inventory dépend de Produits, et que le contrat de Produits a échoué, le système a empêché toute mise à jour de Factory_Inventory.
Un message indique explicitement : "Mise à jour de Factory_Inventory bloquée en raison de l'échec du contrat Produits."
Puisque Entrepôts est indépendant de Produits, sa mise à jour s'est poursuivie sans problème.
Qui est responsable des Data Contracts ?
Qui est responsable quand les choses tournent mal lors de la vérification des contrats ?
Pensez à un pipeline de données comme un système ferroviaire. Les ingénieurs des données sont les constructeurs de voies et de maintenance, c'est-à-dire qu'ils posent les rails, construisent des opérations, et maintiennent le bon fonctionnement de tout. Mais quand un train (des données) déraille en raison de marchandises incorrectes (mauvaises données), nous fait-on appel aux constructeurs de voies ? Non. Nous contactons le superviseur des marchandises qui est la personne responsable du chargement des matériaux.
C'est qui est le propriétaire des données. En gros :-
Les ingénieurs des données établissent les pipelines, vérifient la bonne ingestion des données, et maintiennent l'infrastructure.
Les propriétaires de données sont responsables de la fidélité des données elles-mêmes. Ce sont généralement des experts du domaine, ou quelqu'un qui supervise le processus de collecte de données pour l'ensemble de données correspondant.
Ici, dans notre chaîne d'approvisionnement, un directeur d'usine pourrait être le propriétaire des données pour l'inventaire de l'usine, tandis qu'un superviseur de vente au détail détient les données de stock des détaillants.
Créer un contrat de données est la première étape pour établir la propriété. Les ensembles de données sans propriétaire désigné sont foncièrement instables, souvent conduisant à des échecs dans les actifs consommateurs en aval. En tant que consommateur de données, vous devriez privilégier l'utilisation des ensembles de données ayant une propriété claire i.e. une personne responsable que vous pouvez contacter pour des questions ou des clarifications.

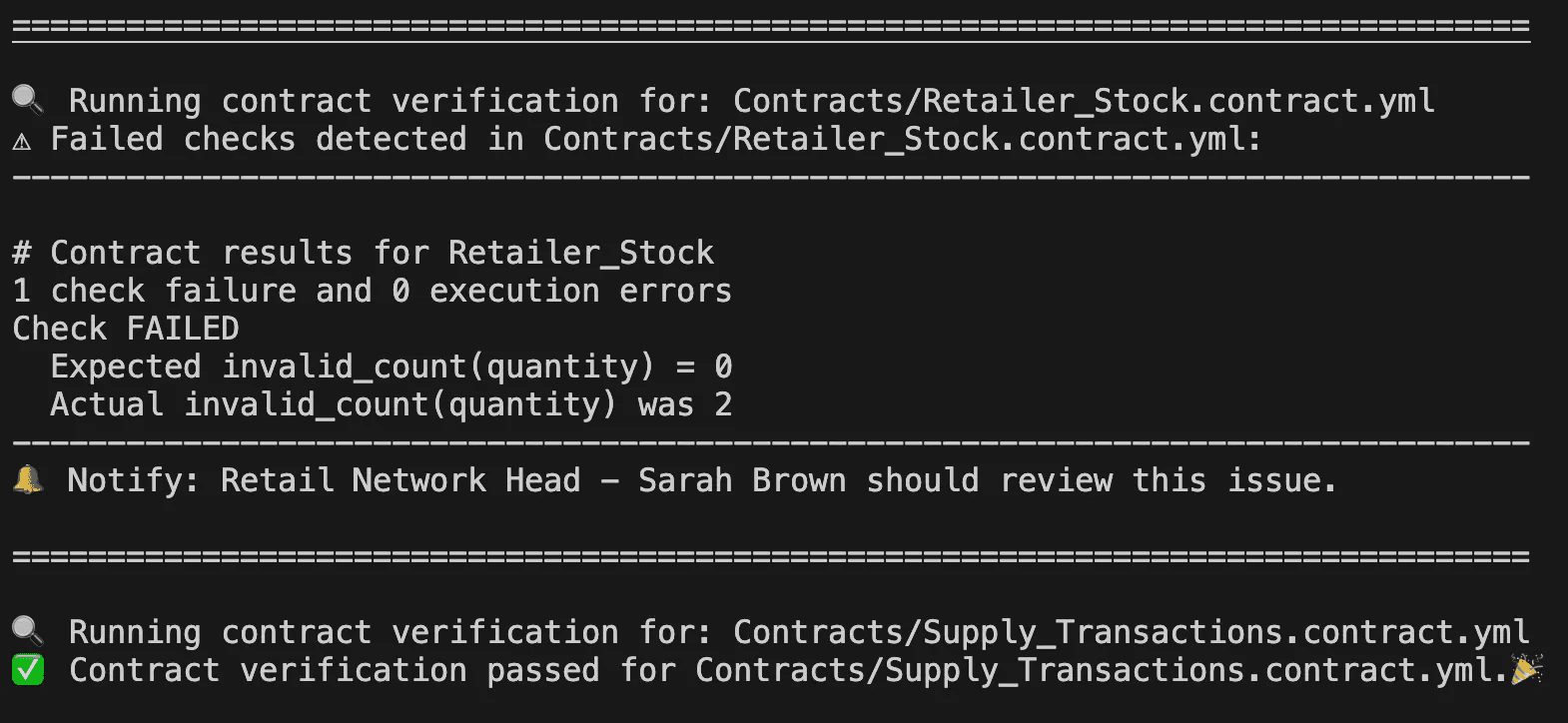
Regardez les deux alertes dans l'image ci-dessus.
La seconde alerte est beaucoup plus utile car elle :
✅ Indique ce qui a échoué
✅ Confirme qu'il s'agit d'un problème de données, pas d'une erreur d'exécution
✅ Identifie qui doit agir
Cela fait de ces alertes des "Alertes Contextuelles" et elles aident le système à devenir transparent et accélèrent le processus de résolution des problèmes.
Nous avons déjà implémenté une partie de la logique pour faire des alertes contextuelles en différenciant l'échec de vérification de l'erreur d'exécution. Ajoutons simplement les propriétaires de données à notre logique de vérification de contrat :
Regardez comme c'est parfait !
Rédiger des contrats devrait être accompagné d'une discussion avec l'équipe pour s'assurer que les attentes sont bien alignées. Gardez toujours le schéma de l'ensemble de données avec vous lors de la rédaction du contrat.
Vérifications importantes des Data Contracts
Maintenant que nous comprenons le flux de base de la vérification des contrats et avons configuré un scénario simple avec les meilleures pratiques, nous pouvons nous concentrer uniquement sur l'augmentation de la complexité des vérifications dans les contrats.
Vérification 1 : La quantité n'est jamais négative
Cette vérification garantit que la colonne quantité ne contient que des valeurs supérieures ou égales à 0, empêchant les nombres négatifs d'entrer dans le système.
Vérification 2 : La catégorie est toujours une valeur valide
Le champ category doit toujours avoir des valeurs valides car les entrées incorrectes ou inattendues peuvent causer des incohérences de données, des erreurs de rapport, et des pannes de système lors du filtrage ou de l'agrégation de données. Une vérification similaire serait de standardiser les unités à seulement "kg", "litres", ou "pièces".
Vérification 3 : La date d'expiration et la date de production doivent être valides
Une autre colonne d'intérêt ici est la colonne expiry_date et production_date.
Si un produit expire avant ou le jour où il a été produit, c'est clairement une erreur. Cette vérification empêche les mauvaises données qui pourraient entraîner des décisions d'inventaire incorrectes, des rapports défectueux, et des calculs de durée de vie incorrects. Elle apporte de la cohérence logique aux chronologies de produits.
La vérification ci-dessous garantit que toutes les dates de production sont soit aujourd'hui, soit dans le passé, maintenant la précision des données.
J'ai volontairement ajouté une valeur erronée dans la table, exécutons de nouveau le contrat.
Vérification 4 : Filtre SQL
Cette vérification impose une valeur minimale de 120 dans la colonne quantité, mais uniquement pour certains détaillants (retailer_id IN (1, 2)).
C'est utile lorsque différentes règles commerciales s'appliquent à différentes entités.
Quelques autres scénarios où une telle logique serait appliquée :
Solde minimum du compte : Maintenir un solde au-dessus d'un seuil fixé pour les clients premium.
Restriction d'âge minimum : Exiger un âge minimum de 18 ans pour les comptes nécessitant le statut légal d'adulte.
Validation du salaire : Appliquer un salaire minimum pour des rôles de travail spécifiques.
Si vous avez besoin d'en savoir plus sur les vérifications qui n'ont pas été couvertes dans ce blog, veuillez explorer cette documentation. Elle détaille toutes les vérifications et les instructions connexes pour vos contrats de données Soda.
Annexe : Débogage et gestion des erreurs
Lors de la vérification de vos contrats, vous rencontrerez deux types d'erreurs : échecs de vérification et erreurs d'exécution.
Le tableau ci-dessous compare les deux :
Sortie | Signification | Actions | Méthode |
|---|---|---|---|
Échecs de vérification | Un échec de vérification indique que les valeurs de l'ensemble de données ne correspondent pas ou ne se situent pas dans les seuils que vous avez spécifiés dans la vérification. | Examinez les données à leur source pour déterminer la cause de l'échec. | .has_failures() |
Erreurs d'exécution | Une erreur d'exécution signifie que Soda n'a pas pu évaluer une ou plusieurs vérifications dans le contrat de données. | Utilisez les journaux d'erreur pour enquêter sur la cause racine du problème. | .has_errors() |
Pour simplifier le débogage, vous pouvez utiliser l'une des deux méthodes ci-dessous pour afficher les erreurs et les résultats. Méthode 1 : Testez le résultat et obtenez un rapport.
Méthode 2 : Ajoutez .assert_ok() à la fin du résultat de vérification du contrat, ce qui produit une SodaException lorsque une vérification échoue ou lorsque des erreurs d'exécution se produisent. Le message d'exception inclut un rapport complet.











