Publié
10 juin 2021
Bienvenue sur Soda Cloud : Observabilité et collaboration de données de bout en bout

Je me suis impliqué dans le domaine des données lorsque j'ai rejoint Collibra, une plateforme pour la gouvernance des données, le catalogage et la découverte en 2010. À cette époque, le rôle de Chief Data Officer / Responsable des données n'existait pas, et les organisations avaient du mal à comprendre ce qu'il se passait avec leurs données, sans parler de gérer les problèmes de qualité des données, car les outils disponibles étaient encombrants et antiques, et ne répondaient pas aux besoins de l'entreprise (et ne le font toujours pas dans la plupart des cas). Lorsque j'ai été introduit à Tom Baeyens, mon cofondateur, il n'a pas fallu longtemps pour connecter les points — et les données — et réaliser qu'il y avait un problème réel que nous pouvions résoudre en combinant l'expérience open source de Tom et mon expérience dans les données.
Le problème du monde réel ? Les problèmes de données silencieuses
Le problème que nous avons identifié et soutenons aujourd'hui, ce sont les problèmes de données silencieuses. Les problèmes de données silencieuses sont au cœur de ce qui doit être résolu. La plupart des équipes de données aujourd'hui naviguent à l'aveugle sans systèmes ni processus pour détecter les problèmes liés aux données. Et en conséquence, les problèmes de données restent silencieux. Les problèmes de données sont cachés dans tout le stack de données d'une organisation et impactent principalement les produits de données — logiciels qui utilisent les données pour produire des résultats tels que la prise de décision automatisée, les algorithmes, les données dérivées, les données brutes et le soutien à la décision. Non seulement le volume de données continue de croître de manière exponentielle, mais le nombre de produits de données à gérer régulièrement augmente également. Les données de ces produits peuvent être compromises partout, à tout moment, alors qu'elles passent de la source à la prise de décision.
Le problème continue de s'amplifier à mesure que les systèmes continuent de traiter de mauvaises données, avec des conséquences incontrôlées, y compris produire des résultats inattendus ou erronés. C'est pourquoi nous les appelons sournoises — des problèmes de qualité des données qui ne sont identifiés que lorsque les ensembles de données sont utilisés dans des rapports, des campagnes, des modèles, et pour la prise de décision.
Cela peut, et souvent, entraîner les ingénieurs en données à consacrer trop de temps à éteindre un problème de données ; les consommateurs de données n'ont pas confiance pour avoir confiance dans les données ; et l'entreprise passe trop de temps à tenter de résoudre les effets et les conséquences de grande envergure.
Je veux être clair : la qualité des données est un problème ancien. Vous la trouverez mentionnée dans le corpus des connaissances en gestion des données de DAMA, dont la première édition a été publiée en 2009. Les principes généraux sont solides ; c'est le processus et la technologie qui doivent être rafraîchis.
Notre grande idée était de donner aux équipes de données les outils pour détecter et résoudre les problèmes qui comptent plus tôt en amont afin de permettre la confiance dans les données. Et ainsi, Tom, l'équipe et moi-même avons travaillé pour lever la peur de ne pas savoir et la douleur de découvrir trop tard qu'un problème de données silencieuses a eu un impact en aval.
Présentation de Soda Cloud
Au début de notre recherche de marché, il nous est apparu qu'il y avait un manque général de visibilité sur les systèmes de données (communément appelé Data Observability). De nombreuses organisations avaient un moyen d'indexer et de découvrir des données (catalogue), mais très peu d'organisations pouvaient découvrir automatiquement et suivre les problèmes de données à travers et entre les sources de données qui apparaissent dans le contexte de la création de produits de données. En conséquence, la plupart des problèmes de données restaient silencieux.
Lorsque les équipes mettaient en place un système pour détecter les problèmes, il s'agissait principalement d'un service de test basé sur des règles. Pour y parvenir, elles s'appuyaient sur des frameworks développés en interne, utilisant le plus souvent des fichiers YAML pour configurer les contrôles devant être exécutés chaque fois que de nouvelles données étaient reçues. À l'exécution, le DSL se traduit par un ensemble d'instructions de calcul pour calculer les métriques — généralement en SQL ou Spark — et évaluer les contrôles.
Le plus gros problème que les équipes de données rencontrent avec cette configuration est qu'elle ne se met pas à l'échelle. Elle ne se met pas à l'échelle parce que les règles sont difficiles à configurer et à maintenir, et elle ne se met pas à l'échelle parce qu'il n'y a pas de systèmes automatisés de découverte des problèmes (par exemple, les tables ne se rafraîchissent pas en fonction du calendrier de rafraîchissement historique que nous avons déduit à partir des journaux de requêtes).
Un autre problème de mise à l'échelle, encore plus important, que nous avons identifié avait rien à voir avec la technologie, mais avec les personnes et le processus. La majorité des contrôles à forte valeur ajoutée étaient définis par des experts du sujet (SME) des données, qui ne sont souvent pas à l'aise avec Git + un DSL YAML. Cela limite considérablement l'adoption à la fois de ce nouveau processus et de la technologie.
Les équipes de données ont besoin d'un cadre commun pour définir et gérer les attentes en matière de comportement des données. Établir des « accords de niveau de service » entre les ingénieurs en données et les consommateurs de données apporterait clarté et cohérence aux équipes lors de la création de produits de données, éliminant les hypothèses (indésirables) et améliorant la qualité des données de manière continue (automatisée).
Soda Cloud est une nouvelle approche prescriptive pour anticiper les problèmes de données silencieuses et gérer la qualité des données. Il combine des capacités prédictives avec un système basé sur des règles super simple, mais puissant. Cela permet aux équipes de données de créer rapidement une couverture et d'obtenir une observation de bout en bout.
Soda Cloud est conçu pour impliquer un large éventail de membres de l'équipe, des ingénieurs de la plateforme de données, aux ingénieurs en analytics, gestionnaires de produits et analystes. L'objectif est de les aider à découvrer, prioriser et résoudre les problèmes de données de manière collaborative — et plus tôt. Ainsi, le CDO / Responsable des données peut garder l'aperçu dont il a besoin pour aider à éliminer les obstacles et garantir la gouvernance.
Découvrez intelligemment les problèmes avec les produits de données
Grâce à la surveillance automatisée, les métadonnées sont collectées, suivies et surveillées à travers les dimensions clés de la qualité des données comme la ponctualité, la complétude, la cohérence et la validité. En suivant les ensembles de données au fil du temps, Soda apprend l'intervalle de rafraîchissement des données, le volume typique des données traitées, ainsi que tout changement dans le schéma de table (y compris les types déduits des modifications). En faisant cela automatiquement pour tous les ensembles de données, une grande partie des problèmes de données peuvent déjà être découverts.
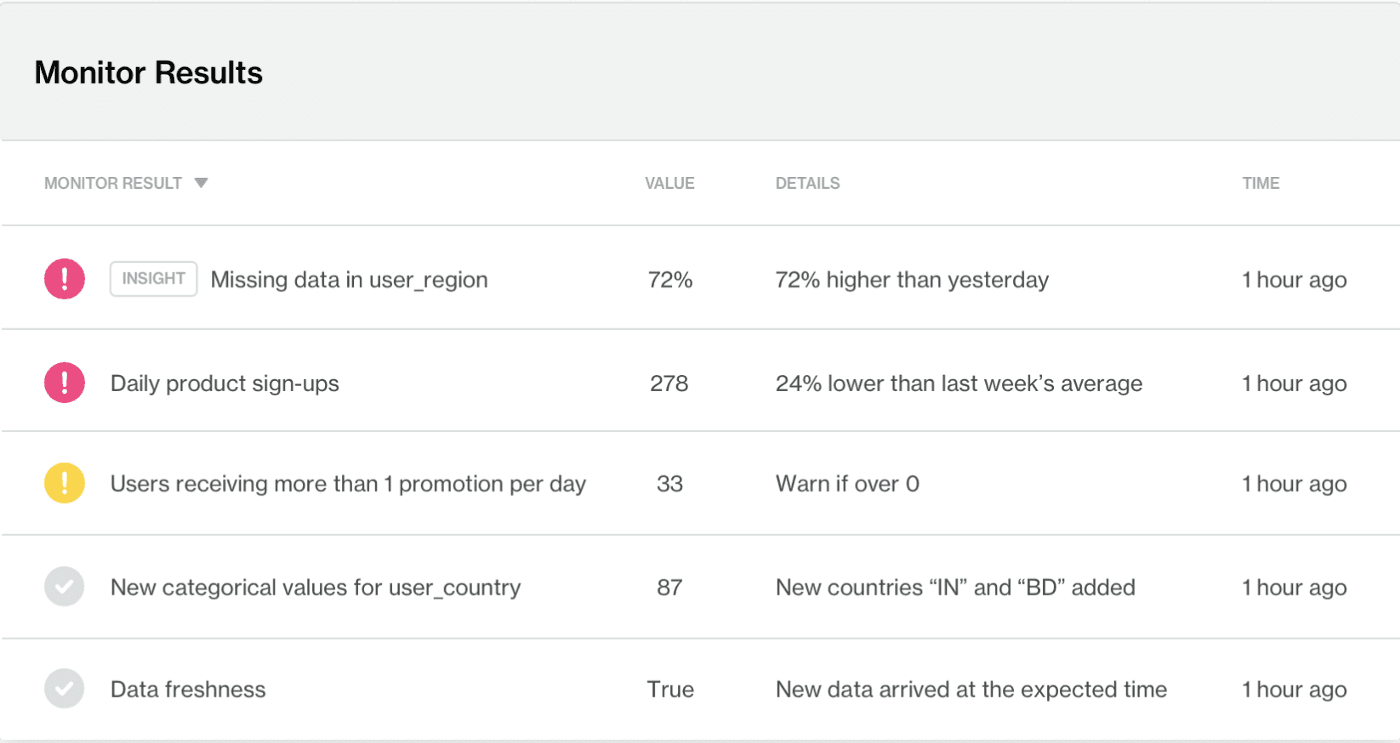
Ce tableau de bord Soda Cloud montre les résultats de la surveillance automatisée. Les aspects clés de vos données, tels que la fraîcheur, les volumes de données, les changements de schéma, les tests définis par l'utilisateur, et les métriques au niveau des colonnes sont rapportés.
En plus de cette détection automatique des anomalies pour les « inconnus connus », les problèmes de données peuvent également être découverts par des tests et validations des données. Pour cela, notre équipe a développé un langage spécifique au domaine simple mais très puissant (parfois appelé DSL) qui vous permet d'effectuer une large gamme de contrôles. Ceux-ci incluent, mais ne sont pas limités aux contrôles de cohérence sur le temps, aux réconciliations, aux contrôles de données de référence, et pratiquement toute logique commerciale.
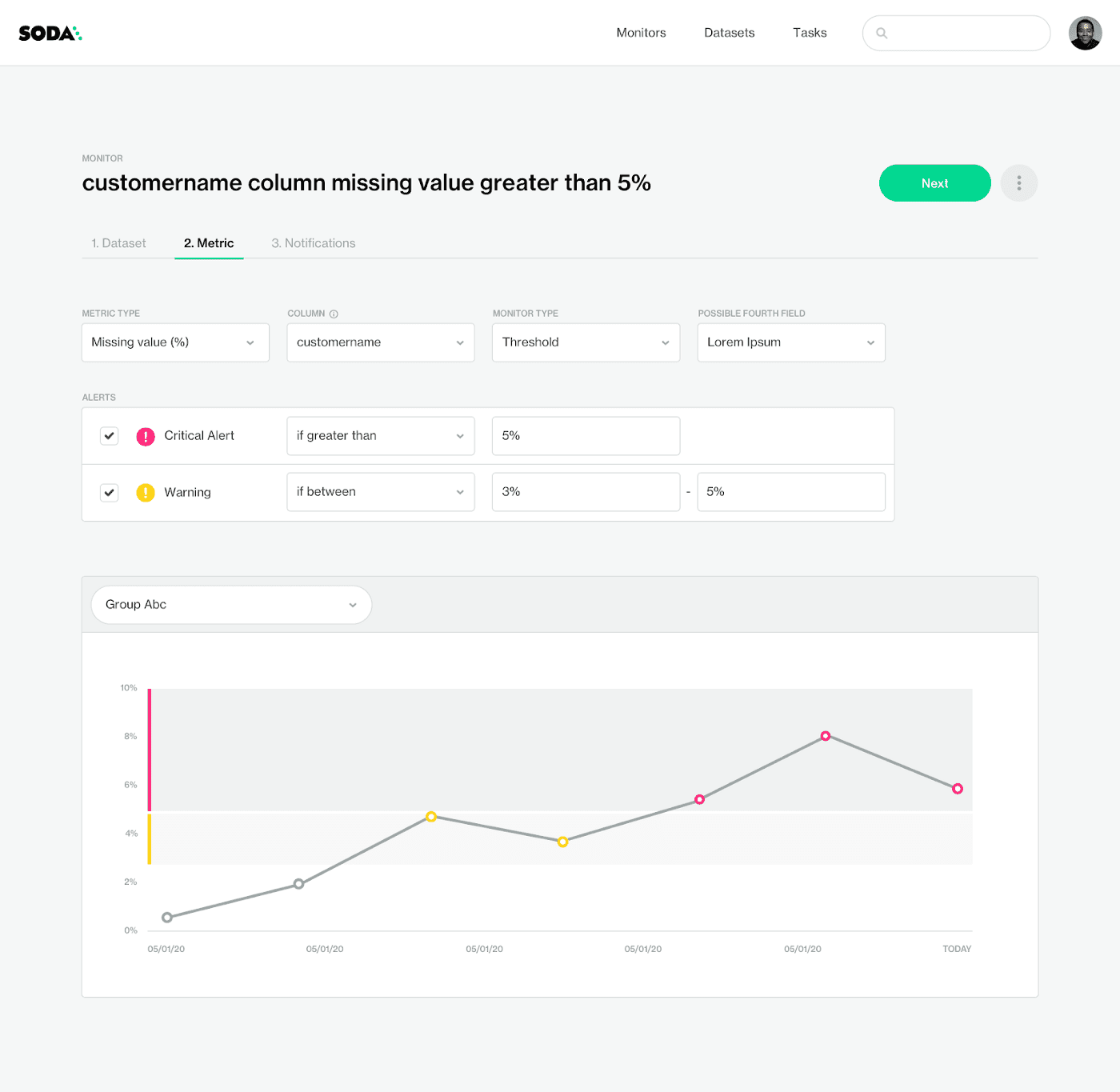
Cette expérience utilisateur de validation des données Soda Cloud permet aux utilisateurs non familiers avec SQL de mettre en place des validations complexes pour détecter les problèmes dans un scénario d'exception connu.
Prioriser les problèmes de données les plus importants
Trier et prioriser les problèmes de données aujourd'hui est devenu un défi de taille, principalement en raison du volume de données accumulées — et de la variété des différents propriétaires de données, consommateurs et parties prenantes au sein de l'entreprise. Les équipes de données réalisent que toutes les données ne sont pas égales, et pour maintenir une qualité élevée, un processus continu doit être mis en place où les propriétaires de données prennent la responsabilité de la priorisation et de la résolution des problèmes de données. Cette pensée a été récemment exposée dans le soi-disant maillage de données.
Tableaux de Bord Fraîcheur des Données — un mécanisme pour gérer la performance des produits
Soda Cloud offre aux équipes un cadre tangible pour définir, visualiser et suivre le comportement des données à travers les Tableaux de Bord Fraîcheur des Données. Que ce soit pour un rapport BI pour la finance, ou des instructions de machine learning mises en place par les opérations, cette approche permet aux propriétaires de données de gérer leurs données comme un produit, et de comprendre ce que chaque équipe attend des données en aval. Ces tableaux de bord montrent au propriétaire des données les problèmes de données découverts dans toute l'organisation pour accélérer à la fois la découverte et la résolution.
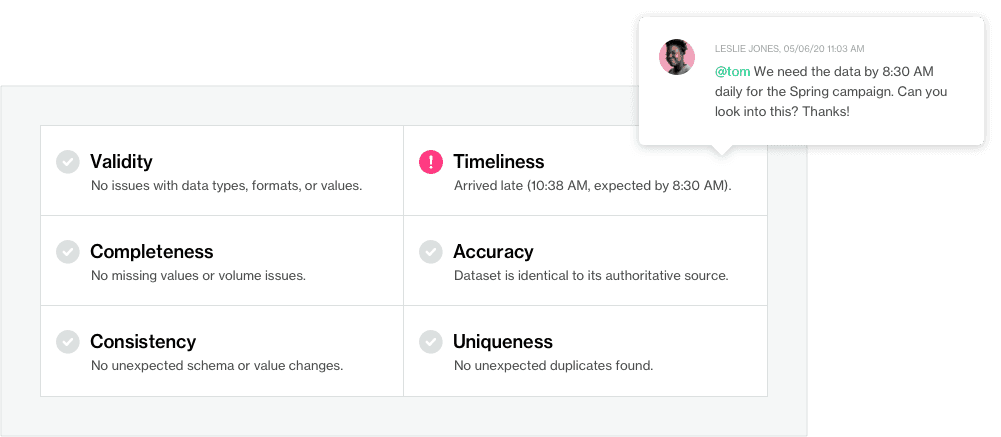
Dans cette zone de Soda Cloud, évaluer la santé et la bonne forme des données à l'aide des dimensions de qualité des données peut déclencher une alerte, par exemple, si une colonne particulière manque de valeurs, ou si une alerte critique manque plus de 5%. Cette fonctionnalité définit « à quoi ressemblent de bonnes données » basé sur les attentes des utilisateurs et aide à éliminer la fatigue des alertes.
Une analyse approfondie de la cause première d'un problème de données est souvent nécessaire. Cela peut être réalisé par exemple en explorant la lignée des données dans votre outil de transformation, d'orchestration et/ou de catalogage des données.
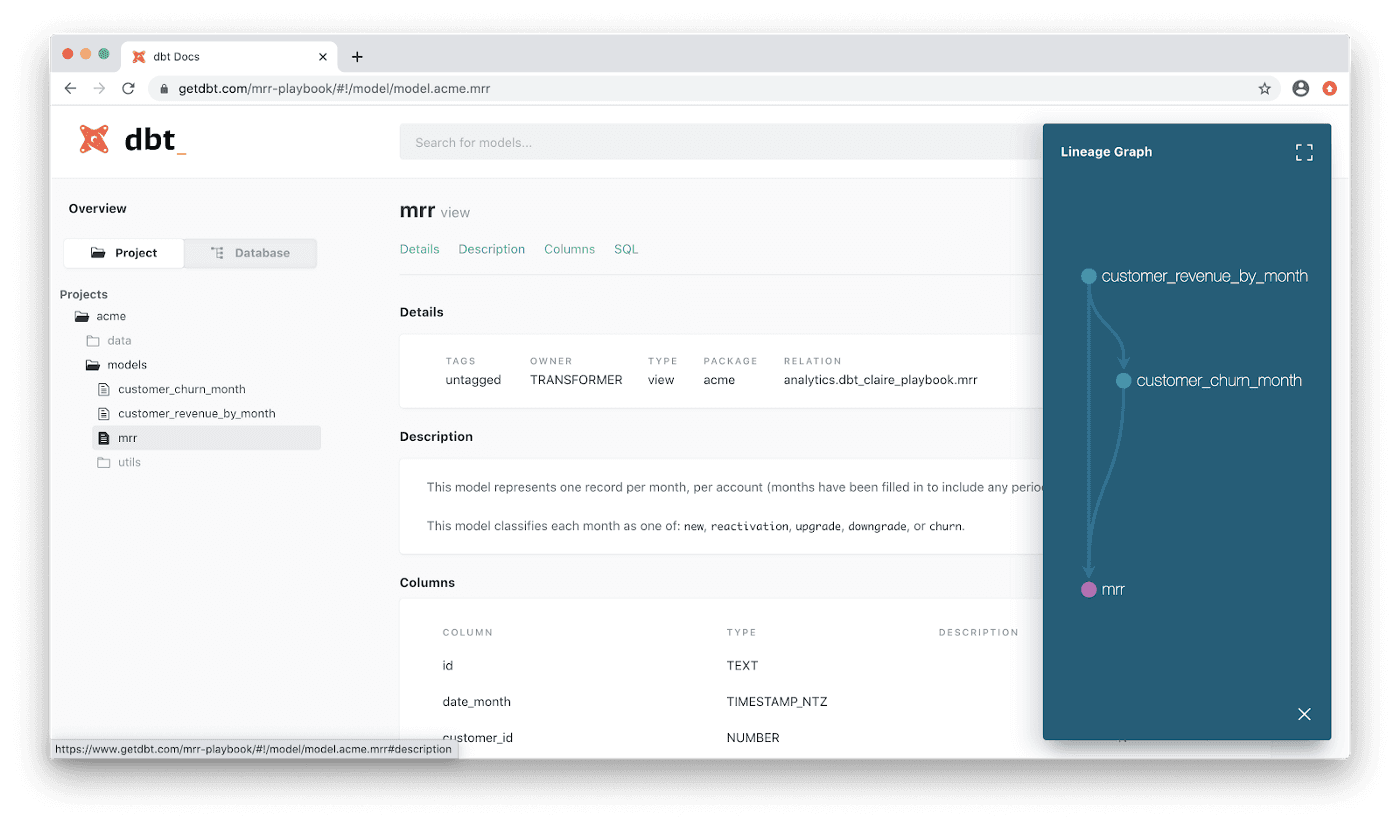
Graphe de lignée dans l'outil de transformation de données DBT.
Résoudre les problèmes de données de manière collaborative à la source
Il ne sert à rien de découvrir et de prioriser les problèmes de données s'il n'y a pas de processus de suivi robuste pour les résoudre. Derrière notre mission se cache l'éthique que les bonnes personnes doivent être réunies, au bon moment. Dans cette partie du processus, il s'agit de résoudre les problèmes de manière collaborative, et en fin de compte de les prévenir.
Chez Soda, nous croyons que la qualité des données est un sport d'équipe ; cependant, vous devez vous assurer que ce sont les bonnes personnes qui s'impliquent grâce à des alertes basées sur les rôles. La plateforme Soda facilite la collaboration en créant un contexte partagé et un flux de travail clair de résolution pour prioriser et résoudre les problèmes et attribuer les tâches qui comptent le plus pour l'entreprise.
Notre approche et nos workflows prennent en compte et reconnaissent que c'est le propriétaire des données qui peut finalement prendre des décisions sur où investir temps et efforts pour améliorer la qualité des données. Les propriétaires de données devraient être en mesure de demander facilement l'aide des ingénieurs en données et des SME des données dans l'entreprise pour aider à analyser et résoudre les problèmes. Pour rationaliser les communications, des options d'intégration sont disponibles pour les canaux les plus utilisés tels que l'e-mail, le chat, Slack ou ServiceNow.
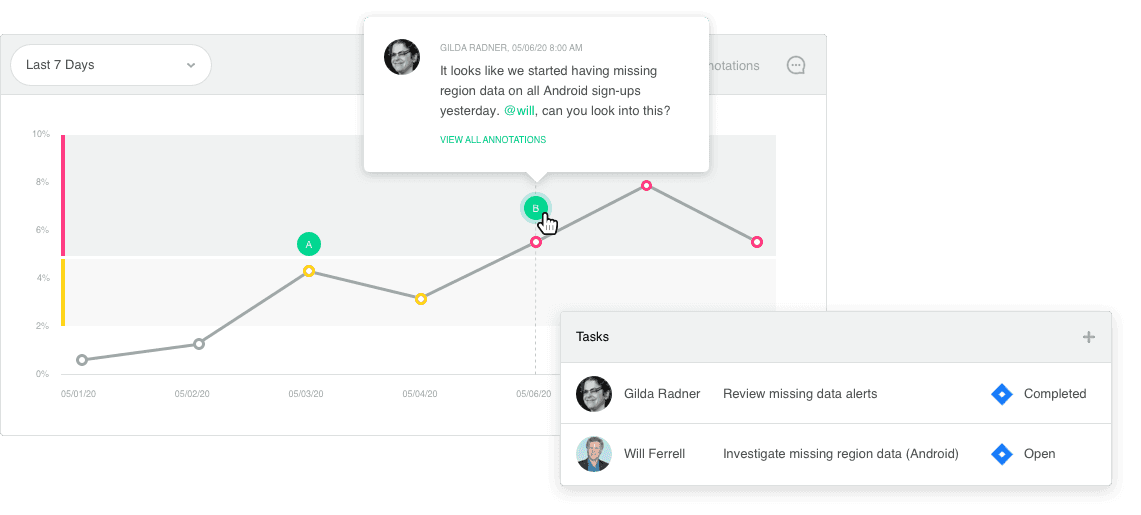
La résolution et l'analyse des causes profondes commencent par la fonctionnalité d'annotation. Ci-dessus, un propriétaire de données ou des utilisateurs métiers peuvent commenter une observation concernant les données et attribuer une tâche pour le suivi.
La Qualité des Données est un Sport d'Équipe : Soda Cloud rassemble tout le monde
Fortement motivé par la communauté qui se forme, nous construisons et sommes motivés par notre mantra selon lequel la qualité des données est un sport d'équipe. Le moment où une organisation peut rapprocher tout le monde (et nous croyons que cela inclut chaque personne dans l'entreprise) des données, c'est lorsque — eh bien, la magie opère !
L'approche de Soda est différente. Bien qu'il y ait un certain nombre d'offres sur le marché (avec de plus en plus qui rejoignent cet espace croissant des données chaque jour), elles ont tendance à se concentrer uniquement sur une partie du problème, ou à résoudre les défis d'un seul rôle dans l'équipe de données.
Avec Soda Cloud, l'ensemble du processus de qualité des données de bout en bout est réuni en une seule plateforme, intégrée et centralisée. Chaque utilisateur peut travailler avec les bons outils et workflows, dans un environnement qui correspond le mieux à ses besoins et son expertise. C'est ce que nous entendons lorsque nous disons que Soda rapproche tout le monde des données.
Nous résolvons le problème avec une combinaison d'une plateforme cloud et un ensemble d'outils de développement open source.
C'est le Monde Moderne de la Qualité des Données
Soda Cloud résout de manière prescriptive le problème de découvrir les problèmes de données silencieuses qui comptent, en offrant aux équipes de données une plateforme centrale pour suivre et noter la santé des données à travers les dimensions de qualité clés. Pour nous, l'observabilité de bout en bout et la collaboration en temps réel ne se produiront que lorsque :
Les ingénieurs de la plateforme de données disposent d'une infrastructure centrale pour permettre la surveillance en tant que service, afin que d'autres puissent créer des produits de données dessus.
Les ingénieurs en données et analytics sont équipés d'un moyen simple de tester les données chaque fois qu'elles sont transformées, pour garantir que les pipelines de données sont plus fiables. À partir de la boîte à outils de développement, ils peuvent utiliser Soda SQL pour arrêter facilement la production de données et mettre en quarantaine les données défectueuses. Soda Cloud visualisera la santé des ensembles de données et servira de hub de communication pour les problèmes de données.
Les analystes, gestionnaires et experts des données peuvent valider les données de manière autonome.
Les propriétaires de données et les gestionnaires de produits de données peuvent obtenir une vue d'ensemble de toutes les attentes en matière de données pour pouvoir facilement prioriser les problèmes à résoudre.
Les responsables des données et analyses, ou les Chief Data Officers, sont en mesure d'implémenter une culture de l'appropriation des données et une communauté de bonnes pratiques en matière de données.
Rejoignez la Communauté
Pour nous, l'objectif de notre communauté est de simplifier l'effort et de partager les meilleures pratiques. Tout le monde cherche à résoudre des problèmes communs avec des solutions communes. Et pour aider, nous sommes ouverts et réduisons les frictions pour démarrer rapidement avec le test et la surveillance des données. Nous voulons également réduire la peur, la douleur et les nuits blanches causées par l'absence de solution ou des solutions maison qui ne résolvent pas le problème.
Soda SQL est livré selon une approche en boîte blanche qui donne aux ingénieurs le contrôle. Le kit d'outils de développement de Soda, disponible sur GitHub, est conçu pour s'intégrer naturellement au workflow de l'ingénieur de données.
Soda Cloud est disponible en version d'essai gratuite (maintenant prolongée jusqu'au 30 juin 2021). Les utilisateurs peuvent obtenir une surveillance en quelques minutes et réaliser la puissance de Soda sur leurs propres données.
Il y a de la puissance dans la communauté et il y a de la puissance dans de bonnes données.
Je vous invite à accéder à nos Outils de Développeur ou Soda Cloud aujourd'hui. Il est temps pour chaque équipe de données moderne de créer la confiance dans les données.
Si je peux aider, faites-le moi savoir.











