Implementing Data Contracts in Retail: 5 Ready-to-Use Templates
Implementing Data Contracts in Retail: 5 Ready-to-Use Templates
Implementing Data Contracts in Retail: 5 Ready-to-Use Templates

Fabiana Ferraz
Fabiana Ferraz
Rédacteur technique chez Soda
Rédacteur technique chez Soda
Table des matières
Retail data ecosystems have grown exponentially complex. A single purchase now connects e-commerce platforms, point-of-sale systems, inventory management tools, payment processors, and marketing analytics, resulting in unprecedented data volume, velocity, and variety. This complexity places enormous demands on data quality in retail operations.
For far too long, data teams have operated in a reactive mode, repairing broken dashboards, debugging silent pipeline failures, and explaining why yesterday’s revenue reports do not match today’s figures. But there is a better way.
Data contracts act as automated checkpoints in your pipeline. If data meets defined quality standards, it proceeds downstream. If it doesn’t, the pipeline can block, quarantine, alert, or mark the dataset as invalid — depending on your enforcement strategy (i.e., how you integrate contracts into your pipelines).
In this guide, we’ll show you how to implement data contracts for retail with 5 ready-to-use templates you can deploy today.
Each template includes real-world failure scenarios and executable Soda contract examples that you can use right away by changing the thresholds and value sets to fit your environment.
What Are Data Contracts in Retail?
Data contracts are machine-readable agreements that define how data should be structured, validated, and governed as it moves between producers and consumers. As data flows through your pipelines, the contract automatically determines whether the data is fit to use according to agreed specifications.
In retail, this means creating explicit agreements between systems that generate data—like POS systems, e-commerce platforms, and inventory databases—and the teams that rely on them for analytics, inventory management, and business intelligence.
Instead of detecting problems during month-end close or regulatory submission, teams enforce expectations directly inside data pipelines. Together, domain teams and engineers set expectations about schema, freshness, quality rules, and more, and the contract makes those expectations testable.
Not all data contract implementations are equal, though. Some approaches focus on documentation and metadata standards only. Others — like Soda collaborative contracts — enforce data quality validation automatically during ingestion, transformation, or CI/CD workflows.
This means you can add automated checks for accuracy, completeness, and timeliness; prevent poor-quality data from reaching downstream systems; and set up proactive alerts to address issues before they escalate.
When a contract fails, it can:
Block pipeline execution (CI/CD gate)
Prevent downstream table updates
Trigger alerting workflows
Mark datasets as invalid in observability tools
In short, in retail, where data errors directly impact revenue, fulfillment, and customer trust, enforceable contracts transform reactive firefighting into predictable operations.
Why Retail Organizations Need Data Contracts
We’d say there are four compelling reasons:
First, they prevent silent data failures.
For example, if a developer renames “price” to “cost” without coordination, sales reports can suddenly show $0. Data contracts catch these breaking changes before they reach production, eliminating debugging emergencies.
Second, they define clear ownership boundaries.
When data quality issues arise, contracts specify exactly who fixes what. No more finger-pointing between teams or endless Slack threads trying to identify the responsible party.
Third, they enable safe change management.
Retail data management requires constant evolution—new product categories, updated payment methods, expanded markets. Data contracts enforce versioning and approval workflows, ensuring changes are intentional and coordinated rather than accidental and chaotic.
Fourth, they support compliance and governance requirements.
With regulations like GDPR and PCI DSS, retailers must track what customer data is collected, where it lives, and how long it’s retained. Data contracts can embed these governance rules directly into your data pipelines.
🟢 The advantage of data contracts for both producers and consumers is clear: less downtime, fewer surprises, and less time spent fixing other people’s changes.
Consider the example below of a raw invoice dataset from an online store. Without basic schema and data quality validation, the table can leave analysts guessing about data types, formats, and valid ranges.
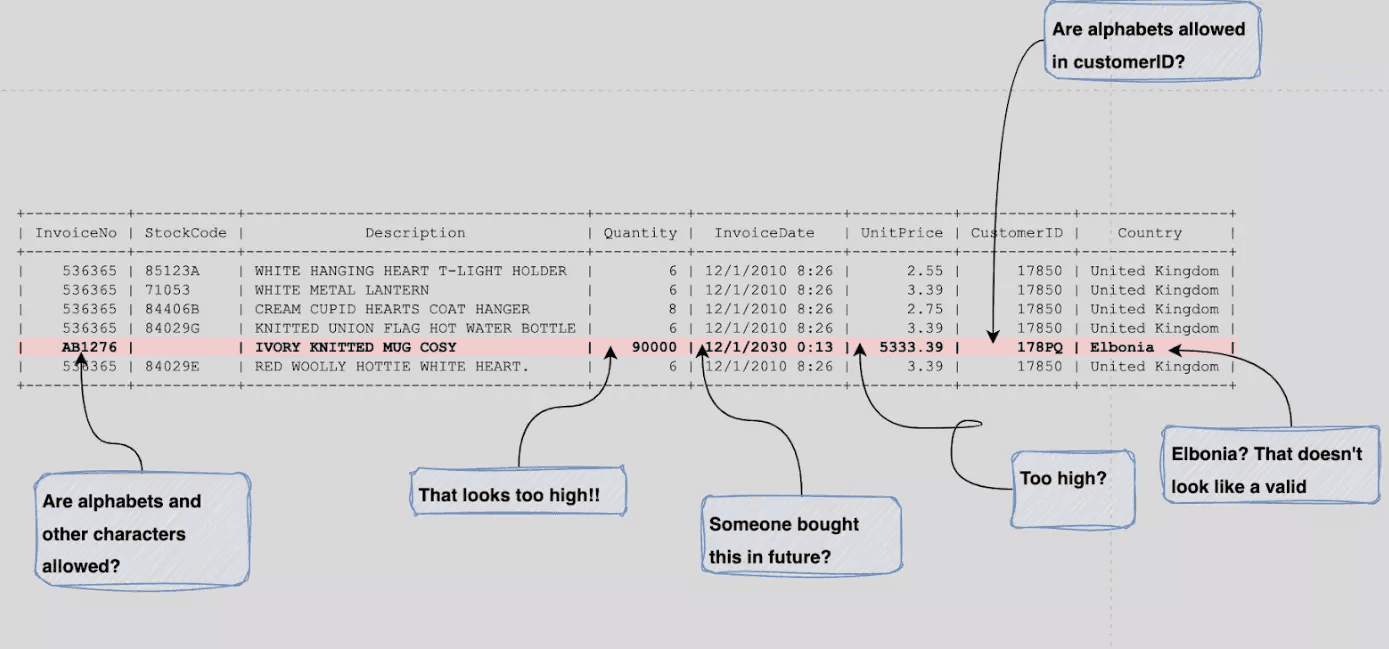
Image source: Atlan
Sometimes, by the time the issues are discovered and solved, you’ve lost sales and got frustrated customers.
Therefore, by establishing automated validation at every checkpoint, contracts transform data quality challenges into managed, predictable processes. And by catching issues at the data level, you avoid expensive operational failures and maintain customer trust.
If you would like to learn more about the foundational structure of a data contract, check our guide: The Definitive Guide to Data Contracts |
|---|
Now, let’s see how these contracts are structured and how you can apply them to your retail data.
Data Contracts Templates for the Retail Sector
We’ve just launched a data contract template gallery. Watch the short video below where Santiago shows how to access the gallery and how to read data contracts.
Let’s explore the structure of data contracts in practice by going over our 5 ready-to-use retail templates: Orders, Inventory, Sales, Product, and Customer.
Template #1: Retail Orders Data Contract
Each order in a retail system touches multiple downstream processes. Consequently, a single corrupted order record can trigger cascading failures across the entire data ecosystem.
Consider this real-world failure scenario:
A developer adds a new payment method value (“debit”) to the payment_method field without coordinating with downstream teams. As a result, your payment processor integration, expecting only “cash,” “credit_card,” or “transfer,” fails silently and orders start to pile up in a pending state.
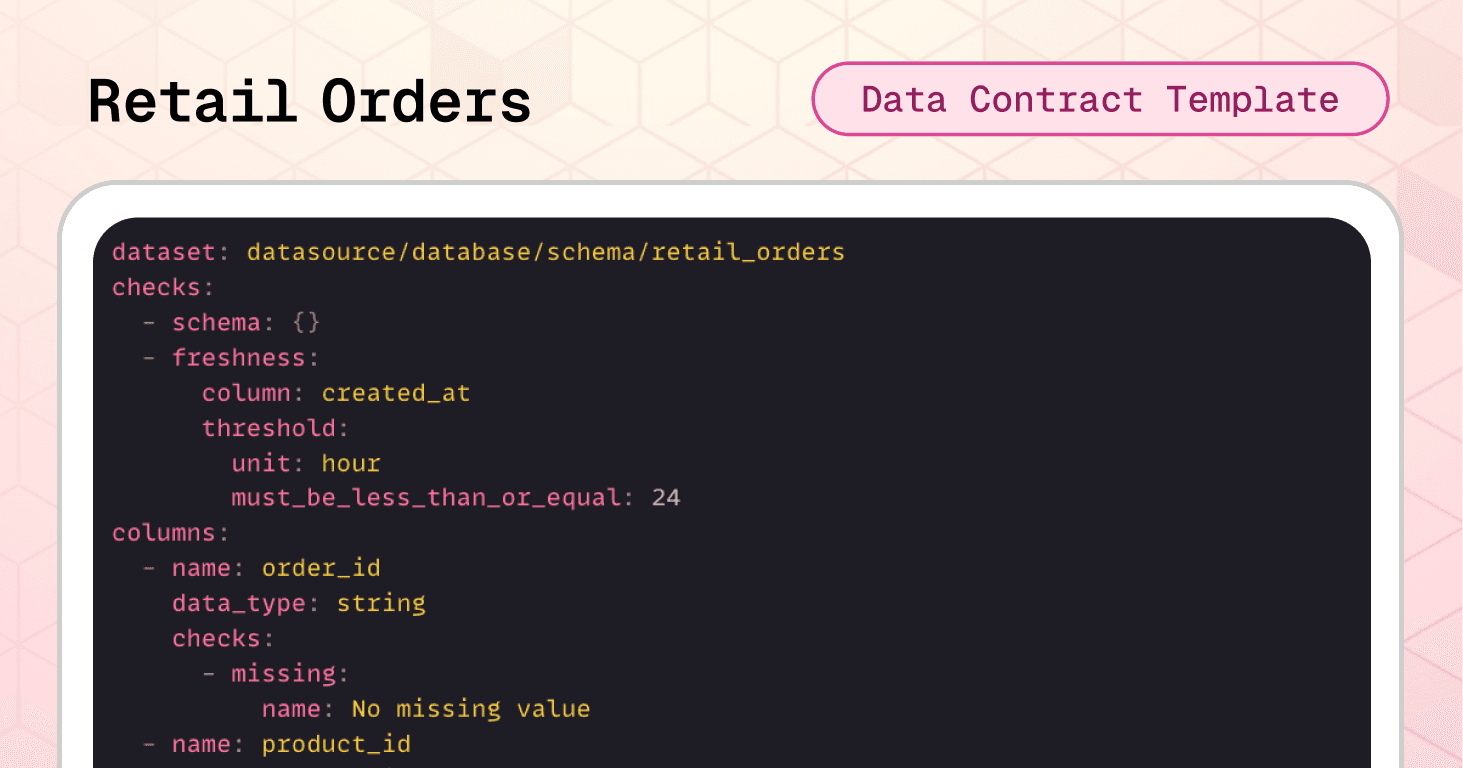
The retail orders data contract template prevents the scenario above with automated validation before data reaches critical systems. Let’s go over it.
Dataset-level protection:
The schema check catches structural changes immediately. The freshness check ensures order data is never older than 24 hours (critical for inventory management and fulfillment scheduling). The row count validation prevents empty datasets from reaching revenue reporting systems.
checks: - schema: {} # catches structural changes - freshness: column: created_at threshold: unit: hour must_be_less_than_or_equal: 24 # ensures orders are never older than 24 hours - row_count: threshold: must_be_greater_than: 0 # prevents empty datasets
Column-level validation:
Required fields like order_id, customer_id, billing_address, and shipping_address must never be null—without these, orders can’t be fulfilled or attributed to customers.
Value constraints ensure order_quantity is at least 1 and discount values are positive, preventing impossible business states.
Controlled values restrict payment_method to only “cash,” “credit_card,” or “transfer,” preventing integration failures with payment processors.
Format validation enforces a two-letter pattern for country_code fields, protecting shipping integrations and geographic reporting from invalid codes.
columns: - name: order_id data_type: string checks: - missing: # prevents null values name: No missing values - name: customer_id data_type: string checks: - missing: name: No missing values - name: order_quantity data_type: integer checks: - missing: - invalid: # prevents negative amounts name: Positive quantity valid_min: 1 - name: payment_method data_type: string checks: - missing: - invalid: name: Allowed payment methods valid_values: # prevents integration failures - cash - credit_card - transfer - name: country_code data_type: string checks: - missing: - invalid: # ensures format standardization name: Two-letter country code valid_format: regex
🟢 In terms of business impact, this contract alone prevents incomplete or invalid orders from breaking analytics dashboards, revenue reports, and customer segmentation models.
Template #2: Inventory Levels Data Contract
Inventory data is the operational core of retail. If inventory levels are wrong, everything downstream breaks: ordering, fulfillment, warehouse operations, and financial reporting. A single incorrect stock count can trigger a cascade of expensive mistakes across your entire supply chain.
Consider this other failure scenario:
Your inventory ETL job experiences delays overnight, and stock data arrives 36 hours stale. Your replenishment algorithms make ordering decisions based on outdated levels, and the allocation engine promises inventory to multiple orders that physically don’t exist.
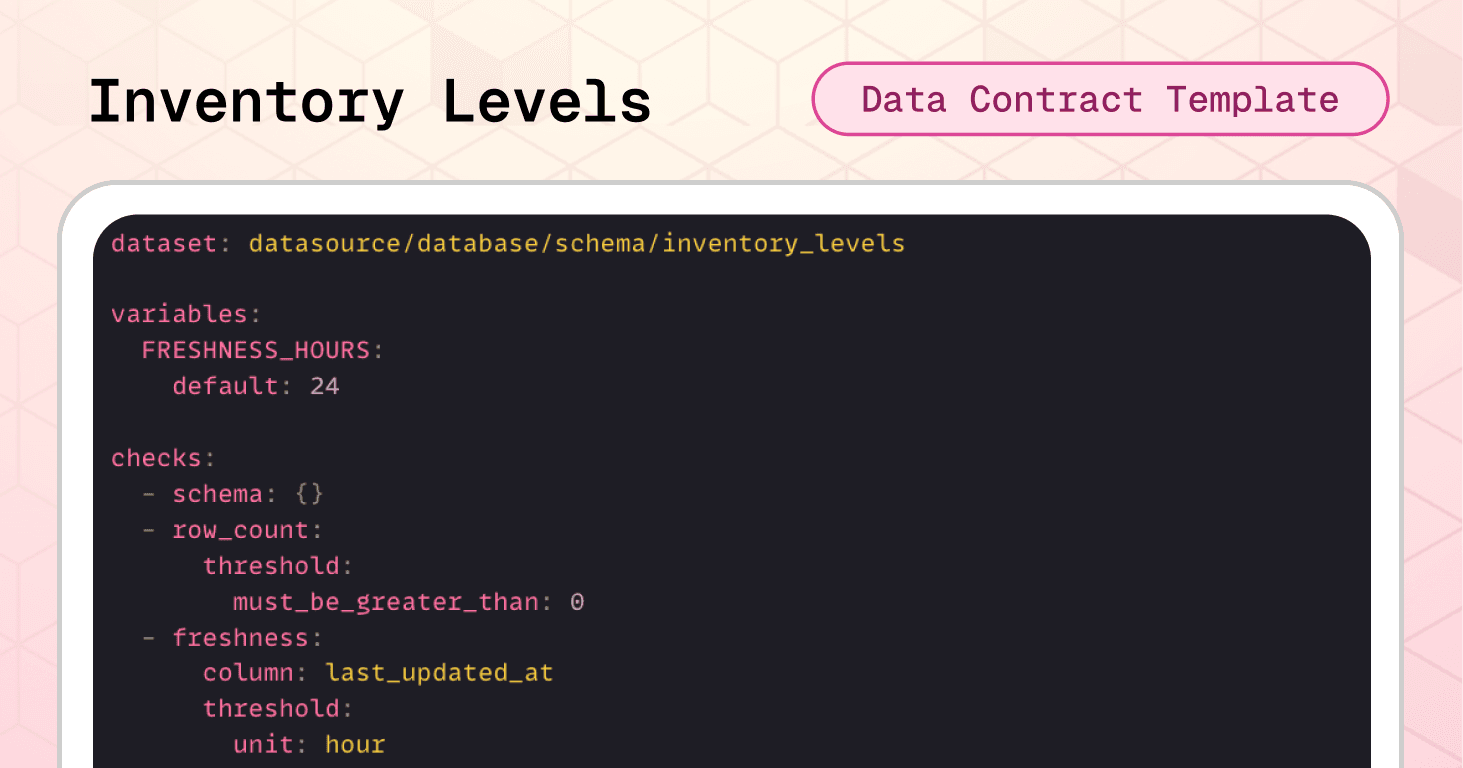
The inventory levels data contract template prevents that scenario by enforcing logical consistency and freshness requirements before data reaches critical systems.
Dataset-level protection:
The schema check immediately flags any structural changes to the inventory table. The row count validation ensures the dataset contains actual inventory records before consumption. The freshness check enforces a 24-hour SLA using the last_updated_at timestamp—critical for real-time allocation and replenishment decisions.
Note the use of variables, which allows teams to easily adjust the freshness threshold without editing multiple places in the contract.
variables: FRESHNESS_HOURS: default: 24 checks: - schema: {} # catches structural changes - row_count: threshold: must_be_greater_than: 0 # prevents empty datasets - freshness: column: last_updated_at threshold: unit: hour must_be_less_than_or_equal: ${var.FRESHNESS_HOURS} # ensures inventory is never older than 24 hours
Cross-field integrity checks
This is where inventory data contracts become especially powerful. Beyond validating individual columns, you can enforce relationships between fields. Failed rows checks identify specific records that violate business logic:
checks: - failed_rows: name: "Stock values must never be negative" qualifier: non_negative_stocks expression: > stock_on_hand < 0 OR stock_reserved < 0 OR stock_available < 0 - failed_rows: name: "Reserved stock cannot exceed stock on hand" qualifier: reserved_le_on_hand expression: stock_reserved > stock_on_hand - failed_rows: name: "Available stock must equal on_hand minus reserved" qualifier: available_equals_on_hand_minus_reserved expression: stock_available <> (stock_on_hand - stock_reserved) - failed_rows: name: "last_updated_at must not be in the future" qualifier: last_updated_not_future expression
The first check catches any negative values across all stock columns.
The second prevents the impossible scenario where reserved stock exceeds what’s physically available.
The third enforces the fundamental inventory equation: available inventory must always equal on-hand minus reserved.
The fourth check prevents timestamp anomalies where data appears to be from the future—a common sign of timezone issues or system clock problems.
Column-level validation:
Required fields like product_id, location_id, and last_updated_at must never be null. Without these identifiers, inventory records can’t be linked to products, locations, or tracked for freshness.
Non-negative constraints prevent impossible inventory states. All three stock columns—stock_on_hand, stock_reserved, and stock_available—must be zero or positive. Negative inventory is logically impossible and indicates data corruption or system errors.
columns: - name: product_id data_type: string checks: - missing: name: No missing values - name: location_id data_type: string checks: - missing: name: No missing values - name: stock_on_hand data_type: integer checks: - missing: - invalid: name: "Stock on hand must be zero or positive" valid_min: 0 - name: stock_reserved data_type: integer checks: - missing: - invalid: name: "Reserved stock must be zero or positive" valid_min: 0 - name: stock_available data_type: integer checks: - missing: - invalid: name: "Available stock must be zero or positive" valid_min: 0 - name: last_updated_at data_type: dateTime checks: - missing
🟢 As a result, this contract reduces overselling risk, prevents broken availability signals, and protects replenishment and allocation processes from operating on impossible or inconsistent inventory states.
Template #3: Sales Transactions Data Contract
Sales transactions data flows into revenue reports, margin analysis, channel performance metrics, and executive dashboards. When sales data is corrupted, operational decision-making is heavily compromised.
Let’s consider another possible scenario:
A point-of-sale system bug starts creating duplicate line items for the same product within orders, making revenue reports show inflated sales figures that suggest you’re hitting targets when you’re actually underperforming. Finance discovers the revenue inflation during quarter-end close, forcing a restatement that erodes executive confidence in your data systems.
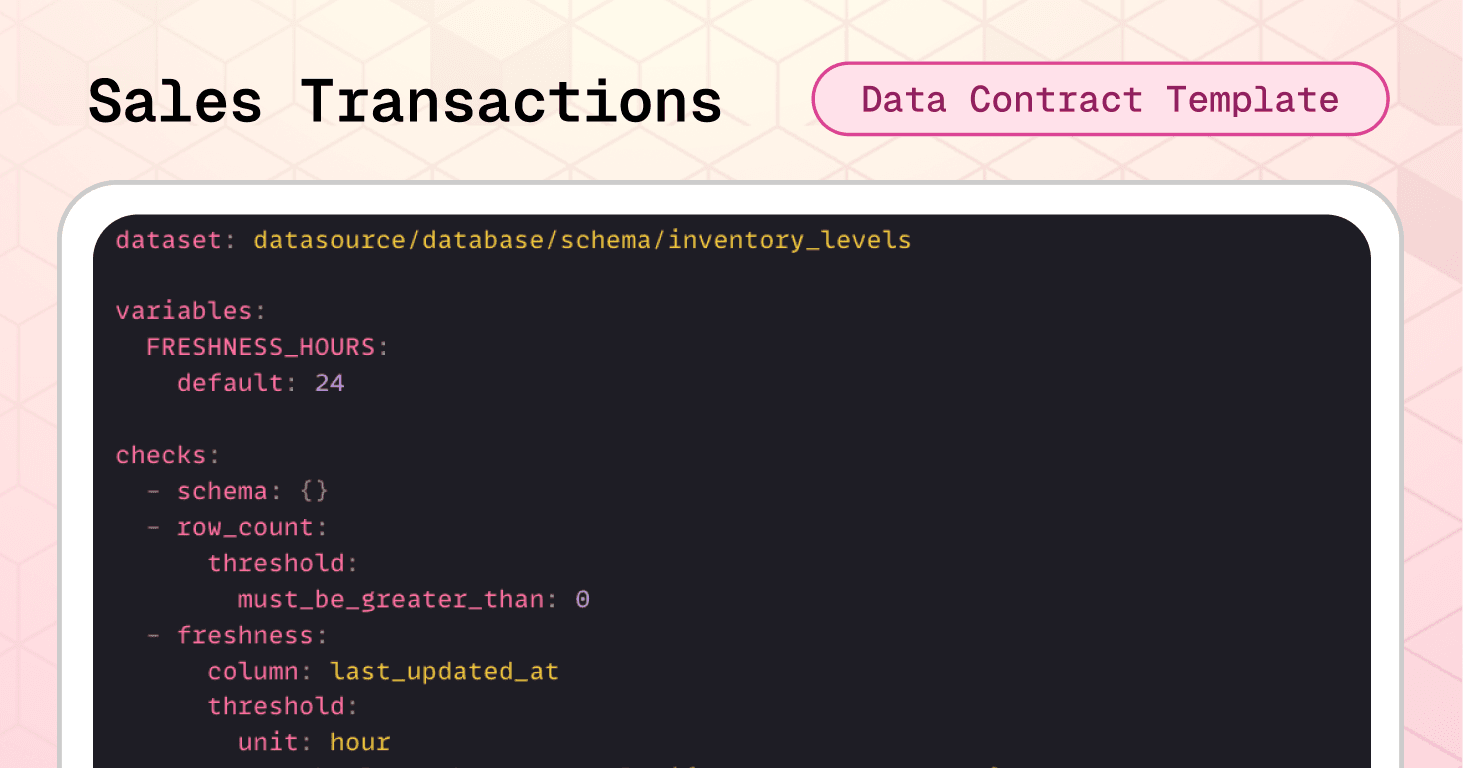
The sales transactions data contract template prevents that scenario by enforcing both individual field validation and critical cross-field financial logic.
Dataset-level protection:
Again, we want to protect schema, row count and freshness. And cross-field integrity checks prevent the most expensive sales data errors: future-dated transactions that break trending analysis, duplicate line items that inflate revenue, incorrect net amount calculations that corrupt margin reports, and impossible discounts that create negative margins.
variables: FRESHNESS_HOURS: default: 24 checks: - schema: # catches structural changes allow_extra_columns: false allow_other_column_order: false - row_count: threshold: must_be_greater_than: 0 # prevents empty datasets - freshness: # ensures transactions are never older than 24 hours column: order_date threshold: unit: hour must_be_less_than_or_equal: ${var.FRESHNESS_HOURS} - failed_rows: name: "order_date must not be in the future" qualifier: order_date_not_future expression: order_date > CURRENT_TIMESTAMP - failed_rows: name: "No duplicate line items per order" qualifier: dup_order_product query: | SELECT order_id, product_id FROM sales_transactions GROUP BY order_id, product_id HAVING COUNT(*) > 1 threshold: must_be: 0 - failed_rows: name: "net_amount must equal (quantity * unit_price) - discount_amount" qualifier: net_amount_formula expression: net_amount <> ((quantity * unit_price) - discount_amount) - failed_rows: name: "discount cannot exceed gross amount" qualifier: discount_le_gross expression
Note that you can also use full SQL query blocks for more complex validations. This is particularly useful when you need to check relationships across multiple tables or perform aggregations. In the contract above we use a SQL query to detect duplicate line items.
Column-level validation:
Required fields ensure every transaction can be traced to a specific order, customer, and product. Value constraints prevent impossible quantities (less than 1) or negative prices. Controlled channel values keep reporting consistent across all sales sources.
columns: - name: order_id data_type: string checks: - missing: - invalid: # prevents wrong ids valid_min_length: 1 valid_max_length: 64 - name: customer_id data_type: string checks: - missing: - name: product_id data_type: string checks: - missing: - name: quantity data_type: integer checks: - missing: - invalid: # prevents impossible quantities name: "Quantity must be positive" valid_min: 1 - name: unit_price data_type: float checks: - missing: - invalid: valid_min: 0 # prevents negative values - name: channel data_type: string checks: - missing: - invalid: name: "Allowed sales channels" valid_values: # ensures consistent values
🟢 Business-wise, this contract protects revenue reporting accuracy, prevents margin calculation errors, eliminates duplicate sales records, and ensures channel attribution works correctly across your entire retail ecosystem.
Template #4: Product Catalog Data Contract
A product catalog is the reference source of truth that every other retail system depends on. Orders reference product IDs, inventory tracks product SKUs, pricing engines pull list prices, and analytics aggregate by categories and brands. When product master data is corrupt or inconsistent, the entire retail operation fractures.
Consider the following scenario:
A merchandising team imports a new product line, accidentally creating duplicate SKUs for existing products because the import process doesn’t validate uniqueness. Your order system can’t determine which product record is correct for the duplicate SKUs, causing fulfillment errors and shipment delays. Meanwhile, analytics reports show inflated product counts due to the duplicates, leading executives to make merchandising decisions based on incorrect catalog size.
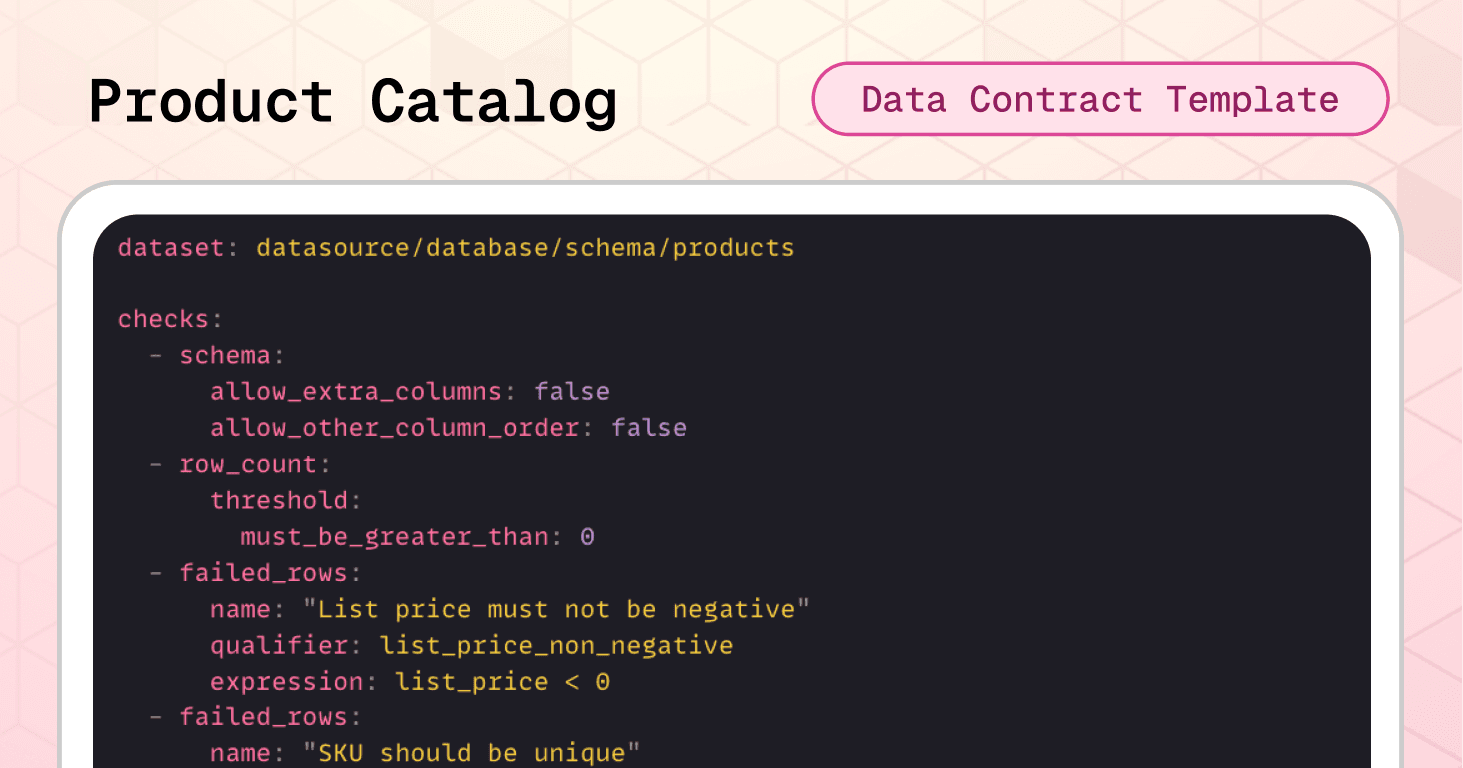
The product catalog data contract template prevents these scenarios by enforcing SKU uniqueness, format standards, and controlled status values before data reaches dependent systems.
Dataset-level protection:
One more time, the schema check prevents unexpected structural changes. The row count ensures the catalog contains products. Integrity checks prevent two catastrophic catalog errors: negative prices that break pricing engines and duplicate SKUs that corrupt order-to-inventory matching across your entire supply chain.
checks: - schema: allow_extra_columns: false allow_other_column_order: false - row_count: threshold: must_be_greater_than: 0 - failed_rows: name: "List price must not be negative" qualifier: list_price_non_negative expression: list_price < 0 - failed_rows: name: "SKU should be unique" qualifier: sku_unique query: | SELECT sku FROM datasource.database.schema.products WHERE sku IS NOT NULL GROUP BY sku HAVING COUNT(*) > 1 threshold: must_be: 0
Column-level validation:
Required fields ensure every product has a unique ID, SKU, name, category, and status. Format validation enforces SKU conventions (uppercase alphanumeric with hyphens/underscores), preventing inconsistent formatting that breaks catalog searches and integrations. Value constraints guarantee positive prices and reasonable field lengths. Controlled status values keep product lifecycle states consistent across e-commerce, inventory, and analytics systems.
columns: - name: product_id data_type: string checks: - missing: # prevents null values - duplicate: # prevents duplicated values - invalid: # ensures reasonable field lengths name: "product_id length guardrail" valid_min_length: 1 valid_max_length: 64 - name: sku data_type: string checks: - missing: - invalid: # prevents inconsistent formatting name: "sku must be uppercase letters/numbers with separators" valid_format: name: SKU format regex: "^[A-Z0-9][A-Z0-9_-]{0,63}$" - name: product_name data_type: string checks: - missing: - invalid: # ensures reasonable field lengths name: "product_name length guardrail" valid_min_length: 2 valid_max_length: 255 - name: category data_type: string checks: - missing: - invalid: # ensures reasonable field lengths name: "category length guardrail" valid_min_length: 2 valid_max_length: 100 - name: list_price data_type: float checks: - missing: - invalid: # prevents negative values name: "list_price must be zero or positive" valid_min: 0 - name: status data_type: string checks: - missing: - invalid: # ensures consistency name: "Allowed product statuses" valid_values
🟢 This contract prevents duplicate products that break order fulfillment, enforces pricing integrity across all sales channels, maintains SKU format consistency for integrations, and ensures product status values work correctly in every downstream system.
Template #5: Customer Master Data Contract
Customer data is the foundation of personalization, marketing attribution, and lifetime value analysis. When customer master data degrades, your ability to understand and serve your customers is seriously impacted.
Consider this last scenario:
A checkout flow bug creates duplicate customer records for the same email address, fragmenting purchase history across multiple IDs. Your customer lifetime value calculations become meaningless, Marketing sends duplicate emails to the same people, while retention programs underfund high-value customers who appear low-value due to split records.
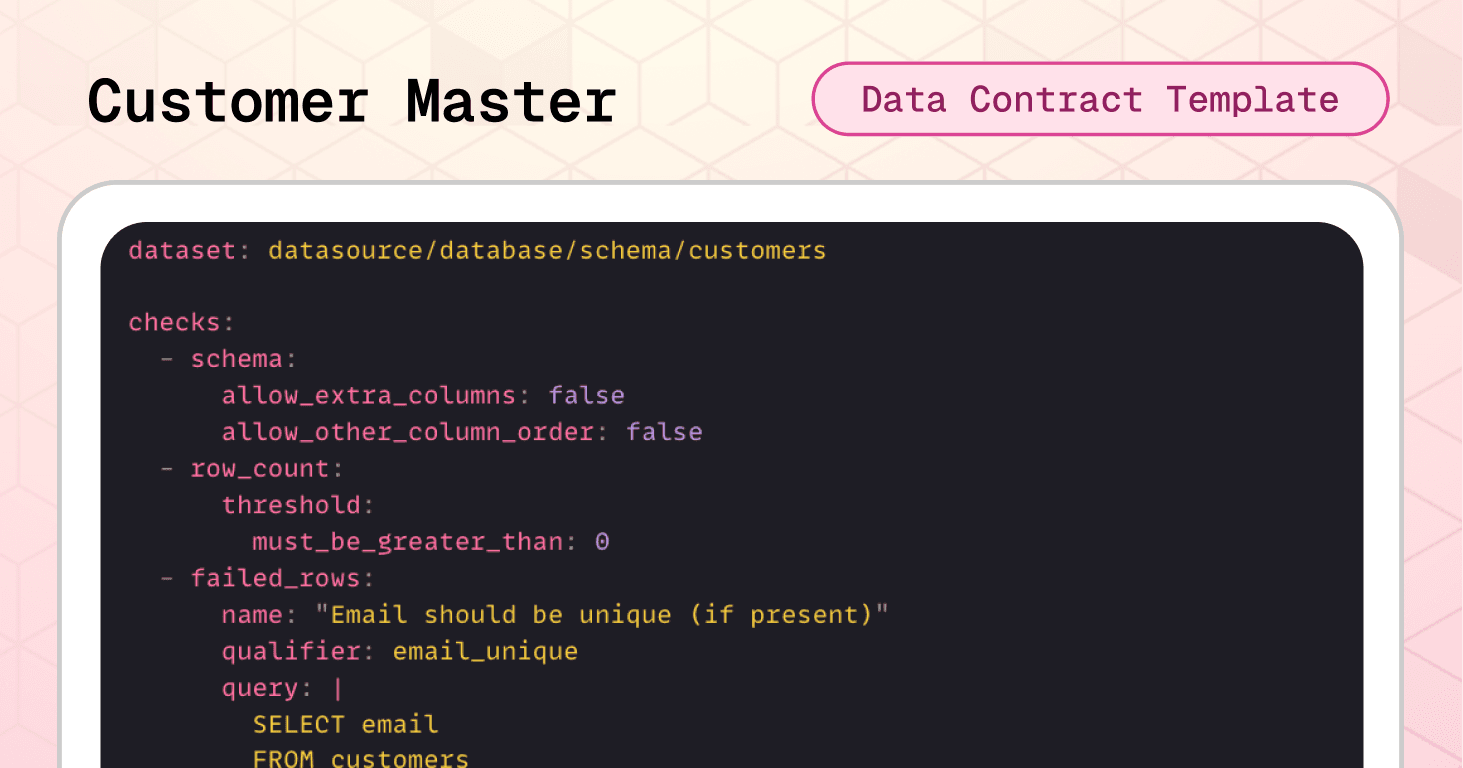
The customer master data contract template prevents this scenario by enforcing email uniqueness, format validation, and controlled values before data reaches CRM, marketing, and analytics systems.
Dataset-level protection:
The schema check prevents unexpected structural changes to customer records. The row count ensures the dataset contains customer data before consumption by downstream systems. And failed_rows prevents duplicate identities.
checks: - schema: allow_extra_columns: false allow_other_column_order: false - row_count: threshold: must_be_greater_than: 0 - failed_rows: name: "Email should be unique (if present)" qualifier: email_unique query: | SELECT email FROM customers WHERE email IS NOT NULL AND email <> '' GROUP BY email HAVING COUNT(*) > 1 threshold: must_be: 0
Column-level validation:
Duplicate checks ensure every customer has a unique ID, country code, status, and signup channel for proper segmentation and compliance. Invalid checks enforces email patterns and ISO-3166 country codes, preventing malformed data from breaking integrations. Note the use of a threshold on email validation—allowing up to 0.5% invalid emails to accommodate edge cases while still catching systematic issues. Invalid checks also keep customer lifecycle states and acquisition attribution consistent across marketing, analytics, and operations systems.
columns: - name: customer_id data_type: string checks: - missing: - duplicate: - invalid: valid_min_length: 1 valid_max_length: 64 - name: email data_type: string checks: - invalid: name: "email format (basic)" valid_format: regex: "^[^@\\\\s]+@[^@\\\\s]+\\\\.[^@\\\\s]+$" threshold: metric: percent must_be_less_than: 0.5 - name: country_code data_type: string checks: - missing: - invalid: name: "Two-letter country code (ISO-3166)" valid_format: regex: "^[A-Z]{2}$" - name: status data_type: string checks: - missing: - invalid: name: "Allowed customer statuses" valid_values: - active - inactive - banned - name: signup_channel data_type: string checks: - missing: - invalid: name: "Allowed signup channels" valid_values
🟢 This contract prevents duplicate customer identities that fragment LTV calculations, enforces email format validity for marketing automation, maintains country code standards for compliance and localization, and ensures signup channel attribution works correctly across all customer acquisition programs.
Implementation with Soda
Having the right data contract templates is only the beginning. The real value comes from embedding these contracts into your data pipelines so they actively prevent issues rather than documenting expectations that nobody enforces.
The retail templates we’ve covered provide starting points, but you’ll need to adjust thresholds, add company-specific validations, and align status values with your actual systems.
From Template to Production
→ Download templates from Soda’s template gallery and customize them for your specific business rules.
Step 1: Treat Contracts as Code
→ Store in version control using Git. Your contracts should live in a repository where changes are tracked, reviewed, and deployed through the same rigorous process as your production code. This creates an audit trail showing exactly when quality rules changed and why.
→ Review through pull requests before any contract changes reach production. When a team wants to relax a validation threshold or add a new allowed value, that change goes through code review, where stakeholders can assess the business impact. This prevents silent degradation of data quality standards over time.
Step 2: Verify Locally
Before deploying contracts to production, validate them against your actual data:
# pip install soda-{data source} for other data sources pip install soda-postgres # verify the contract locally against a data source soda contract verify -c contract.yml -ds
→ Test against real data sources in development or staging environments. Don’t just validate the YAML syntax, run actual queries against representative data to see which checks pass and which fail.
→ Iterate on thresholds and rules based on what you learn. If your inventory freshness check fails because weekend updates genuinely arrive after 24 hours, adjust the threshold to 48 hours rather than creating false positives that train teams to ignore alerts.
Step 3: Embed in Your Pipeline
Data contracts only protect you if they’re enforced at the right checkpoints. Strategic placement determines which issues you catch early versus which slip through to cause downstream damage.
Where to enforce contracts:
After data ingestion from POS systems - Validate order and sales transaction data immediately after it arrives from stores, catching issues while they’re still close to the source
Before loading into the data warehouse - Create a quality gate that prevents corrupt data from entering your analytical environment
At API layer for e-commerce platforms - Validate product catalog and customer data at the API boundary before it reaches internal systems
In ETL/ELT processes - Integrate with tools like dbt to validate data transformations at each stage
Enforcement mechanism: CI/CD pipelines check that schema changes are compatible with contracts before deployment. Data quality tools validate constraints against actual data on schedule or in real-time. When a contract fails, the data stops flowing until someone investigates and resolves the issue.
Step 4: Publish and Monitor
Once contracts are validated and embedded, publish them to Soda Cloud for continuous monitoring:
# publish and schedule the contract with Soda Cloud soda contract publish -c contract.yml -sc
→ Automated validation on schedule runs your contracts hourly, daily, or in real-time depending on your data freshness requirements. This creates a continuous quality feedback loop rather than one-time validation.
→ Smart alerting to the right owners routes failures to the teams responsible for fixing them. When the inventory contract fails because stock_reserved exceeds stock_on_hand, the alert goes to the warehouse management system team, not the data platform team. Clear ownership prevents alerts from being ignored as “someone else’s problem.”
→ Data observability dashboard provides visibility into contract health across all datasets. Teams can see which contracts are passing, which are failing, and trending metrics on data quality over time.
Book a demo to see how data contracts work in your specific environment with your actual data sources and business requirements.
AI-Powered Contract Generation
Don’t want to write YAML from scratch? Soda’s AI-powered contract autopilot can generate contracts automatically by analyzing your data structure and patterns.
One-click contract creation examines your tables and suggests appropriate checks based on data types, cardinality, and distribution patterns.
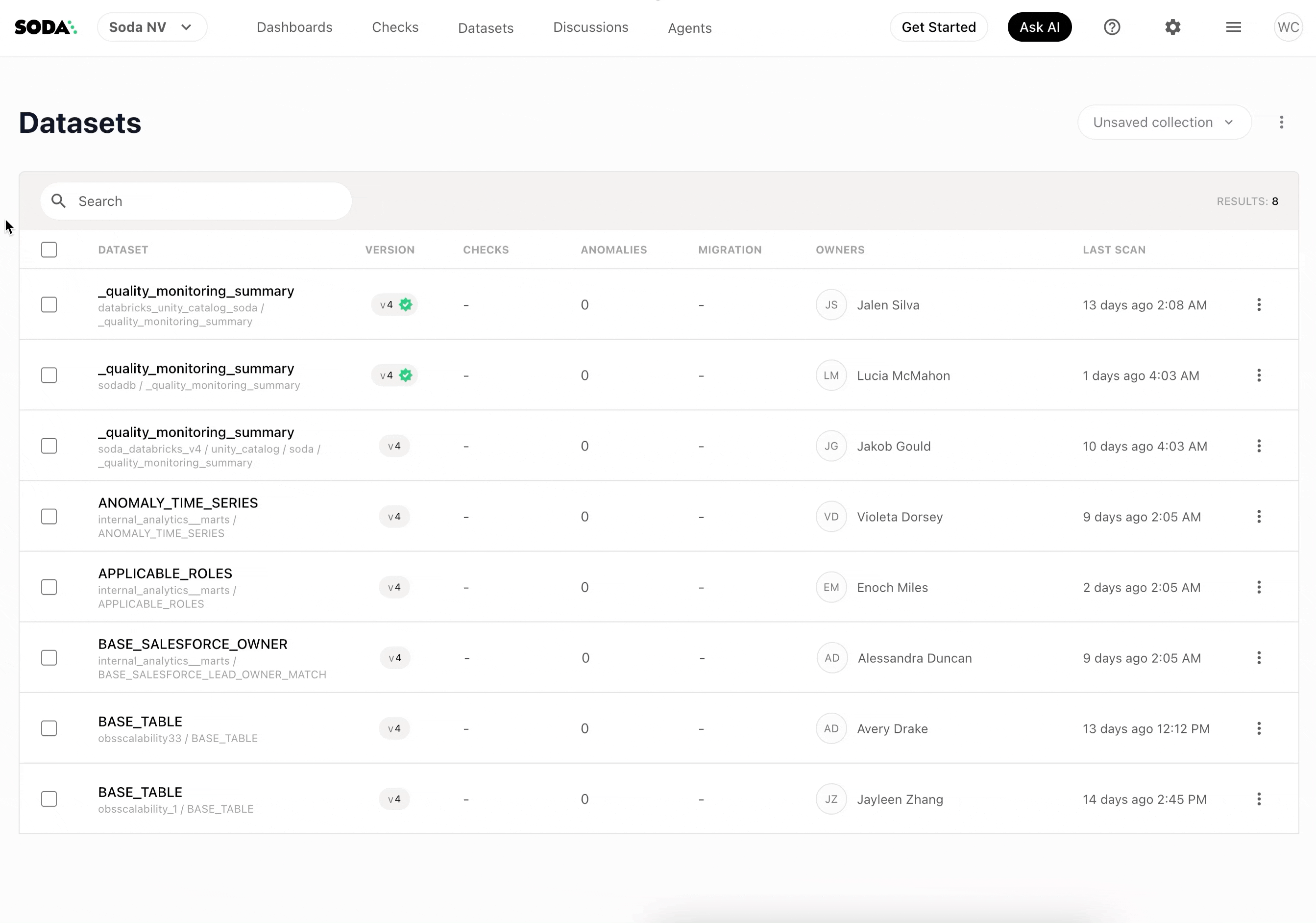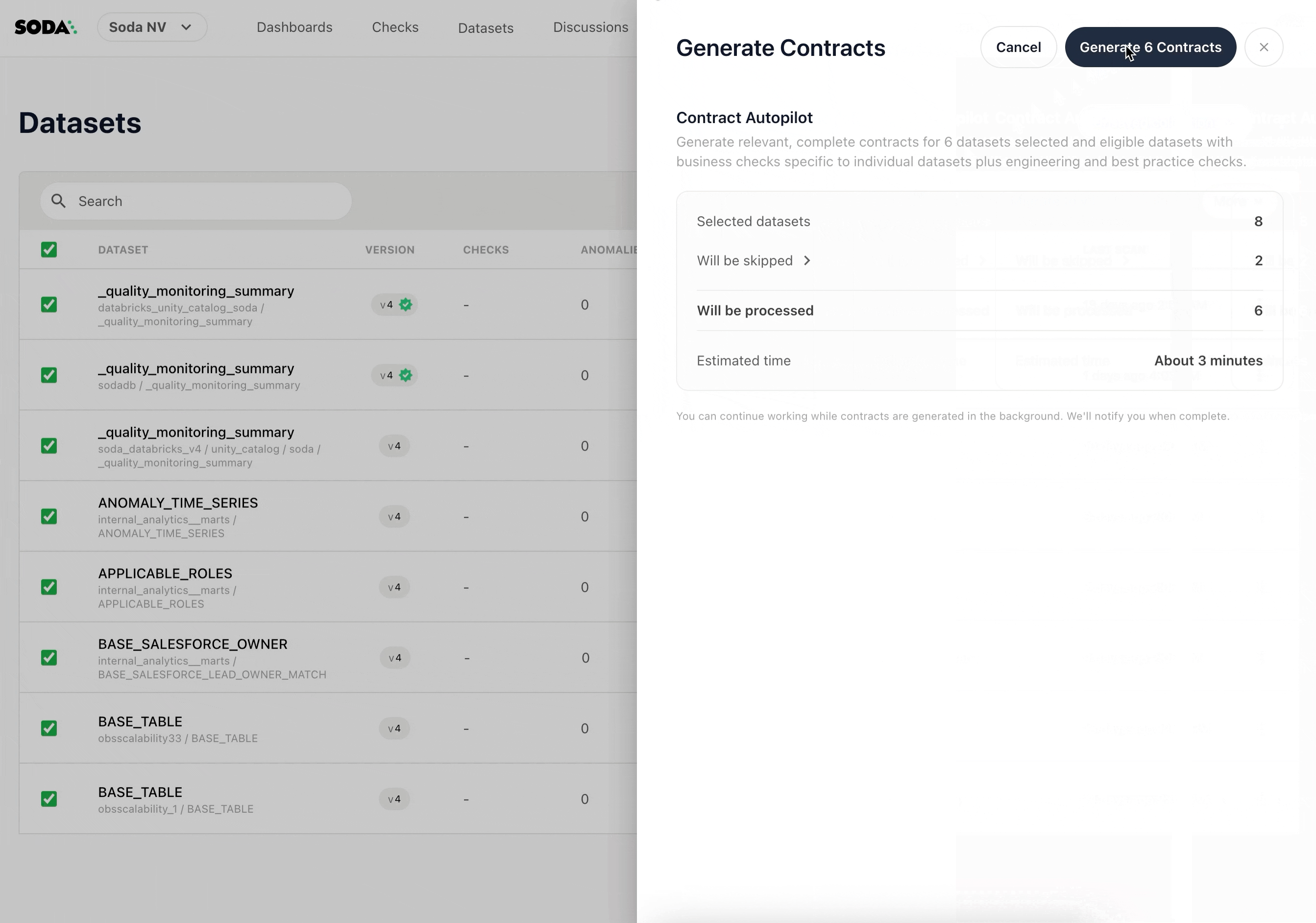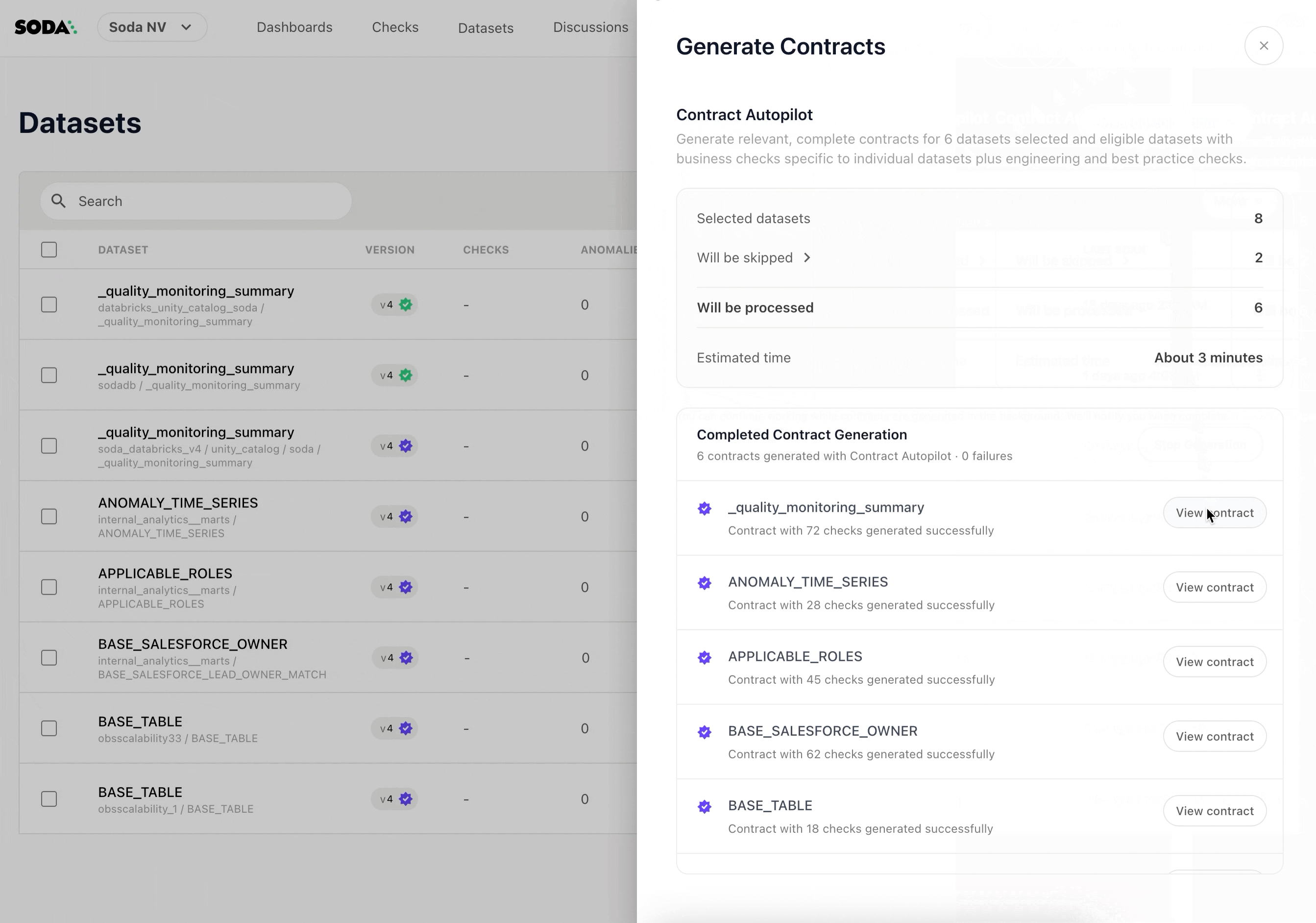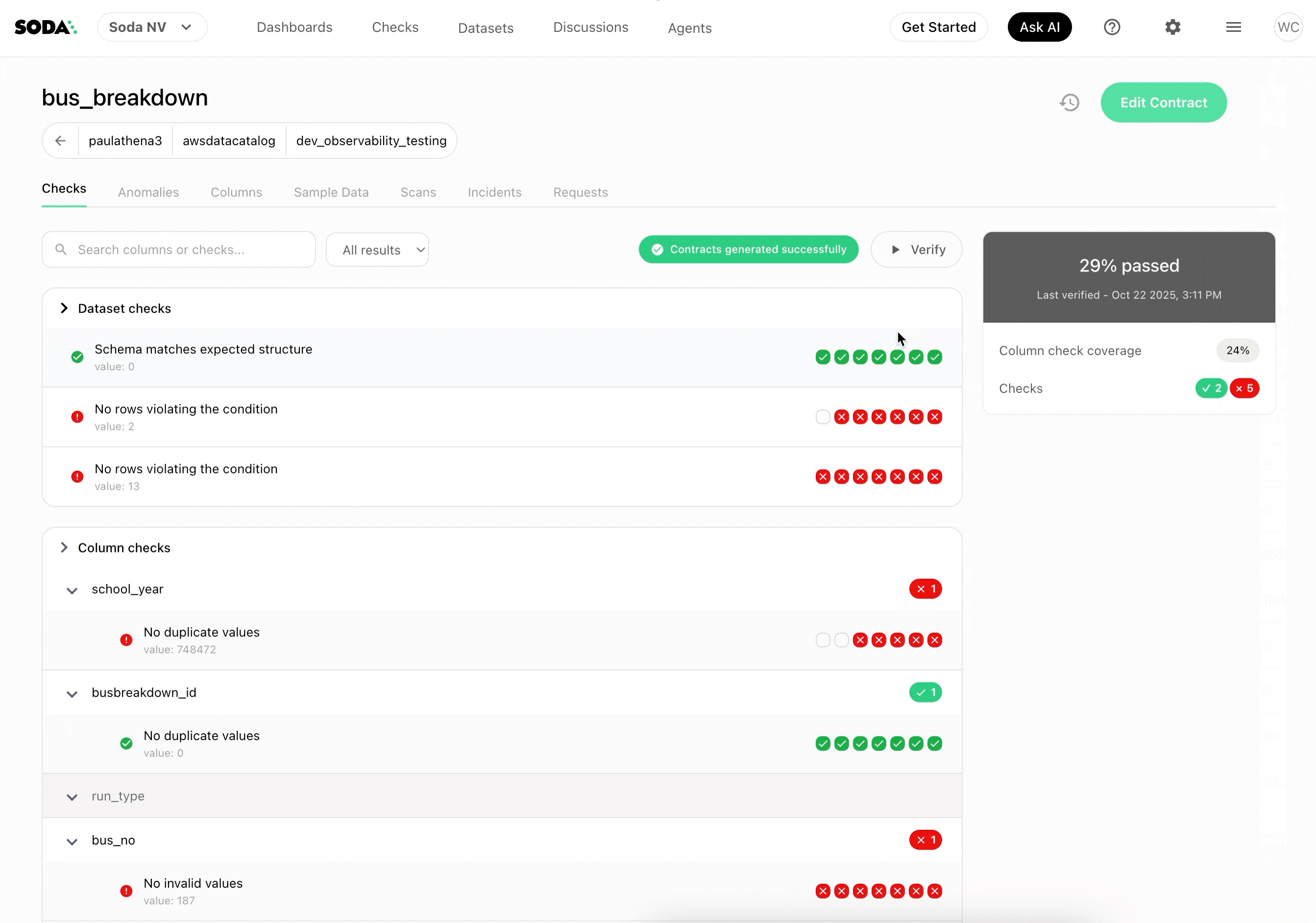
Start Small, Scale Systematically
Don’t try to implement contracts to all your datasets at once. Choose the ones that have the highest business impact to your use case. Get these contracts working smoothly, build confidence with stakeholders, then expand to the rest of your database.
This progressive approach lets you refine your process (verification workflows, alerting configurations, ownership assignments) on high-value datasets before scaling across your entire data ecosystem.
Ownership and Accountability
Each contract needs a clearly named owner—a person or role responsible for responding to breaches and approving changes. Without clear ownership, failed contracts generate alerts that no one takes action on, and quality standards decline due to negligence.
For retail contracts, ownership typically aligns with business domains:
Orders contract → E-commerce or Order Management team
Inventory contract → Supply Chain or Warehouse Operations team
Sales Transactions contract → Finance or Revenue Operations team
Product Catalog contract → Merchandising or Product Management team
Customer Data contract → CRM or Customer Analytics team
This domain-aligned ownership ensures the people who best understand the business rules are responsible for maintaining contract quality over time.
Evolving Contracts Over Time
Data contracts aren’t static documents, they evolve as your business changes.
As requirements change, producers propose contract updates, discuss them with consumers, and roll out new versions in a controlled way. This feedback loop prevents the chaos of uncoordinated changes while allowing necessary evolution.
Watch the collaboration workflow demonstration below showing how business users define quality expectations in the UI while data engineers validate and publish contracts using code and CLI—bridging the gap between business knowledge and technical implementation.
Conclusion: Beyond Validation to True Ownership
The templates in this guide represent best practices for retail data quality today. Use them to build stability and prevent expensive data failures. But as you implement them, remember that the ultimate goal is empowering business domain experts to own their data quality.
The people closest to business decisions understand what data quality actually means in context. They know when a 2% error rate is acceptable versus catastrophic, they understand why certain changes are urgent while others can wait, and they can assess the tradeoff between strict validation and business flexibility.
The real gain with data contracts isn’t just specs validation; it’s ownership and collaboration.
If we assume data engineers build data products and the business simply consumes them, we’ve created distance between data and decisions. The contracts we’ve discussed today bridge that gap through collaboration: business stakeholders define quality expectations, engineers implement validation logic, and both parties review changes together.
Looking forward, the goal isn’t stricter interfaces that require engineering intervention for every change. It’s enabling those closest to decisions to shape, evolve, and validate data products themselves, with automation doing the heavy lifting.
Ready to implement data contracts in your retail data pipelines?
Download the templates: Access all 5 retail data contract templates and customize them for your business. We recommend starting with orders and inventory for immediate impact.
See it in action: Book a demo to see how data contracts work in your specific environment with your actual data sources and business requirements.
Explore more use cases: Visit the complete template gallery for data contracts across industries—from finance to healthcare to manufacturing—and discover patterns you can apply to your retail operations. See also our finance data contract templates and 4 data contract examples you can use today.
Retail data ecosystems have grown exponentially complex. A single purchase now connects e-commerce platforms, point-of-sale systems, inventory management tools, payment processors, and marketing analytics, resulting in unprecedented data volume, velocity, and variety. This complexity places enormous demands on data quality in retail operations.
For far too long, data teams have operated in a reactive mode, repairing broken dashboards, debugging silent pipeline failures, and explaining why yesterday’s revenue reports do not match today’s figures. But there is a better way.
Data contracts act as automated checkpoints in your pipeline. If data meets defined quality standards, it proceeds downstream. If it doesn’t, the pipeline can block, quarantine, alert, or mark the dataset as invalid — depending on your enforcement strategy (i.e., how you integrate contracts into your pipelines).
In this guide, we’ll show you how to implement data contracts for retail with 5 ready-to-use templates you can deploy today.
Each template includes real-world failure scenarios and executable Soda contract examples that you can use right away by changing the thresholds and value sets to fit your environment.
What Are Data Contracts in Retail?
Data contracts are machine-readable agreements that define how data should be structured, validated, and governed as it moves between producers and consumers. As data flows through your pipelines, the contract automatically determines whether the data is fit to use according to agreed specifications.
In retail, this means creating explicit agreements between systems that generate data—like POS systems, e-commerce platforms, and inventory databases—and the teams that rely on them for analytics, inventory management, and business intelligence.
Instead of detecting problems during month-end close or regulatory submission, teams enforce expectations directly inside data pipelines. Together, domain teams and engineers set expectations about schema, freshness, quality rules, and more, and the contract makes those expectations testable.
Not all data contract implementations are equal, though. Some approaches focus on documentation and metadata standards only. Others — like Soda collaborative contracts — enforce data quality validation automatically during ingestion, transformation, or CI/CD workflows.
This means you can add automated checks for accuracy, completeness, and timeliness; prevent poor-quality data from reaching downstream systems; and set up proactive alerts to address issues before they escalate.
When a contract fails, it can:
Block pipeline execution (CI/CD gate)
Prevent downstream table updates
Trigger alerting workflows
Mark datasets as invalid in observability tools
In short, in retail, where data errors directly impact revenue, fulfillment, and customer trust, enforceable contracts transform reactive firefighting into predictable operations.
Why Retail Organizations Need Data Contracts
We’d say there are four compelling reasons:
First, they prevent silent data failures.
For example, if a developer renames “price” to “cost” without coordination, sales reports can suddenly show $0. Data contracts catch these breaking changes before they reach production, eliminating debugging emergencies.
Second, they define clear ownership boundaries.
When data quality issues arise, contracts specify exactly who fixes what. No more finger-pointing between teams or endless Slack threads trying to identify the responsible party.
Third, they enable safe change management.
Retail data management requires constant evolution—new product categories, updated payment methods, expanded markets. Data contracts enforce versioning and approval workflows, ensuring changes are intentional and coordinated rather than accidental and chaotic.
Fourth, they support compliance and governance requirements.
With regulations like GDPR and PCI DSS, retailers must track what customer data is collected, where it lives, and how long it’s retained. Data contracts can embed these governance rules directly into your data pipelines.
🟢 The advantage of data contracts for both producers and consumers is clear: less downtime, fewer surprises, and less time spent fixing other people’s changes.
Consider the example below of a raw invoice dataset from an online store. Without basic schema and data quality validation, the table can leave analysts guessing about data types, formats, and valid ranges.
Image source: Atlan
Sometimes, by the time the issues are discovered and solved, you’ve lost sales and got frustrated customers.
Therefore, by establishing automated validation at every checkpoint, contracts transform data quality challenges into managed, predictable processes. And by catching issues at the data level, you avoid expensive operational failures and maintain customer trust.
If you would like to learn more about the foundational structure of a data contract, check our guide: The Definitive Guide to Data Contracts |
|---|
Now, let’s see how these contracts are structured and how you can apply them to your retail data.
Data Contracts Templates for the Retail Sector
We’ve just launched a data contract template gallery. Watch the short video below where Santiago shows how to access the gallery and how to read data contracts.
Let’s explore the structure of data contracts in practice by going over our 5 ready-to-use retail templates: Orders, Inventory, Sales, Product, and Customer.
Template #1: Retail Orders Data Contract
Each order in a retail system touches multiple downstream processes. Consequently, a single corrupted order record can trigger cascading failures across the entire data ecosystem.
Consider this real-world failure scenario:
A developer adds a new payment method value (“debit”) to the payment_method field without coordinating with downstream teams. As a result, your payment processor integration, expecting only “cash,” “credit_card,” or “transfer,” fails silently and orders start to pile up in a pending state.
The retail orders data contract template prevents the scenario above with automated validation before data reaches critical systems. Let’s go over it.
Dataset-level protection:
The schema check catches structural changes immediately. The freshness check ensures order data is never older than 24 hours (critical for inventory management and fulfillment scheduling). The row count validation prevents empty datasets from reaching revenue reporting systems.
checks: - schema: {} # catches structural changes - freshness: column: created_at threshold: unit: hour must_be_less_than_or_equal: 24 # ensures orders are never older than 24 hours - row_count: threshold: must_be_greater_than: 0 # prevents empty datasets
Column-level validation:
Required fields like order_id, customer_id, billing_address, and shipping_address must never be null—without these, orders can’t be fulfilled or attributed to customers.
Value constraints ensure order_quantity is at least 1 and discount values are positive, preventing impossible business states.
Controlled values restrict payment_method to only “cash,” “credit_card,” or “transfer,” preventing integration failures with payment processors.
Format validation enforces a two-letter pattern for country_code fields, protecting shipping integrations and geographic reporting from invalid codes.
columns: - name: order_id data_type: string checks: - missing: # prevents null values name: No missing values - name: customer_id data_type: string checks: - missing: name: No missing values - name: order_quantity data_type: integer checks: - missing: - invalid: # prevents negative amounts name: Positive quantity valid_min: 1 - name: payment_method data_type: string checks: - missing: - invalid: name: Allowed payment methods valid_values: # prevents integration failures - cash - credit_card - transfer - name: country_code data_type: string checks: - missing: - invalid: # ensures format standardization name: Two-letter country code valid_format: regex
🟢 In terms of business impact, this contract alone prevents incomplete or invalid orders from breaking analytics dashboards, revenue reports, and customer segmentation models.
Template #2: Inventory Levels Data Contract
Inventory data is the operational core of retail. If inventory levels are wrong, everything downstream breaks: ordering, fulfillment, warehouse operations, and financial reporting. A single incorrect stock count can trigger a cascade of expensive mistakes across your entire supply chain.
Consider this other failure scenario:
Your inventory ETL job experiences delays overnight, and stock data arrives 36 hours stale. Your replenishment algorithms make ordering decisions based on outdated levels, and the allocation engine promises inventory to multiple orders that physically don’t exist.
The inventory levels data contract template prevents that scenario by enforcing logical consistency and freshness requirements before data reaches critical systems.
Dataset-level protection:
The schema check immediately flags any structural changes to the inventory table. The row count validation ensures the dataset contains actual inventory records before consumption. The freshness check enforces a 24-hour SLA using the last_updated_at timestamp—critical for real-time allocation and replenishment decisions.
Note the use of variables, which allows teams to easily adjust the freshness threshold without editing multiple places in the contract.
variables: FRESHNESS_HOURS: default: 24 checks: - schema: {} # catches structural changes - row_count: threshold: must_be_greater_than: 0 # prevents empty datasets - freshness: column: last_updated_at threshold: unit: hour must_be_less_than_or_equal: ${var.FRESHNESS_HOURS} # ensures inventory is never older than 24 hours
Cross-field integrity checks
This is where inventory data contracts become especially powerful. Beyond validating individual columns, you can enforce relationships between fields. Failed rows checks identify specific records that violate business logic:
checks: - failed_rows: name: "Stock values must never be negative" qualifier: non_negative_stocks expression: > stock_on_hand < 0 OR stock_reserved < 0 OR stock_available < 0 - failed_rows: name: "Reserved stock cannot exceed stock on hand" qualifier: reserved_le_on_hand expression: stock_reserved > stock_on_hand - failed_rows: name: "Available stock must equal on_hand minus reserved" qualifier: available_equals_on_hand_minus_reserved expression: stock_available <> (stock_on_hand - stock_reserved) - failed_rows: name: "last_updated_at must not be in the future" qualifier: last_updated_not_future expression
The first check catches any negative values across all stock columns.
The second prevents the impossible scenario where reserved stock exceeds what’s physically available.
The third enforces the fundamental inventory equation: available inventory must always equal on-hand minus reserved.
The fourth check prevents timestamp anomalies where data appears to be from the future—a common sign of timezone issues or system clock problems.
Column-level validation:
Required fields like product_id, location_id, and last_updated_at must never be null. Without these identifiers, inventory records can’t be linked to products, locations, or tracked for freshness.
Non-negative constraints prevent impossible inventory states. All three stock columns—stock_on_hand, stock_reserved, and stock_available—must be zero or positive. Negative inventory is logically impossible and indicates data corruption or system errors.
columns: - name: product_id data_type: string checks: - missing: name: No missing values - name: location_id data_type: string checks: - missing: name: No missing values - name: stock_on_hand data_type: integer checks: - missing: - invalid: name: "Stock on hand must be zero or positive" valid_min: 0 - name: stock_reserved data_type: integer checks: - missing: - invalid: name: "Reserved stock must be zero or positive" valid_min: 0 - name: stock_available data_type: integer checks: - missing: - invalid: name: "Available stock must be zero or positive" valid_min: 0 - name: last_updated_at data_type: dateTime checks: - missing
🟢 As a result, this contract reduces overselling risk, prevents broken availability signals, and protects replenishment and allocation processes from operating on impossible or inconsistent inventory states.
Template #3: Sales Transactions Data Contract
Sales transactions data flows into revenue reports, margin analysis, channel performance metrics, and executive dashboards. When sales data is corrupted, operational decision-making is heavily compromised.
Let’s consider another possible scenario:
A point-of-sale system bug starts creating duplicate line items for the same product within orders, making revenue reports show inflated sales figures that suggest you’re hitting targets when you’re actually underperforming. Finance discovers the revenue inflation during quarter-end close, forcing a restatement that erodes executive confidence in your data systems.
The sales transactions data contract template prevents that scenario by enforcing both individual field validation and critical cross-field financial logic.
Dataset-level protection:
Again, we want to protect schema, row count and freshness. And cross-field integrity checks prevent the most expensive sales data errors: future-dated transactions that break trending analysis, duplicate line items that inflate revenue, incorrect net amount calculations that corrupt margin reports, and impossible discounts that create negative margins.
variables: FRESHNESS_HOURS: default: 24 checks: - schema: # catches structural changes allow_extra_columns: false allow_other_column_order: false - row_count: threshold: must_be_greater_than: 0 # prevents empty datasets - freshness: # ensures transactions are never older than 24 hours column: order_date threshold: unit: hour must_be_less_than_or_equal: ${var.FRESHNESS_HOURS} - failed_rows: name: "order_date must not be in the future" qualifier: order_date_not_future expression: order_date > CURRENT_TIMESTAMP - failed_rows: name: "No duplicate line items per order" qualifier: dup_order_product query: | SELECT order_id, product_id FROM sales_transactions GROUP BY order_id, product_id HAVING COUNT(*) > 1 threshold: must_be: 0 - failed_rows: name: "net_amount must equal (quantity * unit_price) - discount_amount" qualifier: net_amount_formula expression: net_amount <> ((quantity * unit_price) - discount_amount) - failed_rows: name: "discount cannot exceed gross amount" qualifier: discount_le_gross expression
Note that you can also use full SQL query blocks for more complex validations. This is particularly useful when you need to check relationships across multiple tables or perform aggregations. In the contract above we use a SQL query to detect duplicate line items.
Column-level validation:
Required fields ensure every transaction can be traced to a specific order, customer, and product. Value constraints prevent impossible quantities (less than 1) or negative prices. Controlled channel values keep reporting consistent across all sales sources.
columns: - name: order_id data_type: string checks: - missing: - invalid: # prevents wrong ids valid_min_length: 1 valid_max_length: 64 - name: customer_id data_type: string checks: - missing: - name: product_id data_type: string checks: - missing: - name: quantity data_type: integer checks: - missing: - invalid: # prevents impossible quantities name: "Quantity must be positive" valid_min: 1 - name: unit_price data_type: float checks: - missing: - invalid: valid_min: 0 # prevents negative values - name: channel data_type: string checks: - missing: - invalid: name: "Allowed sales channels" valid_values: # ensures consistent values
🟢 Business-wise, this contract protects revenue reporting accuracy, prevents margin calculation errors, eliminates duplicate sales records, and ensures channel attribution works correctly across your entire retail ecosystem.
Template #4: Product Catalog Data Contract
A product catalog is the reference source of truth that every other retail system depends on. Orders reference product IDs, inventory tracks product SKUs, pricing engines pull list prices, and analytics aggregate by categories and brands. When product master data is corrupt or inconsistent, the entire retail operation fractures.
Consider the following scenario:
A merchandising team imports a new product line, accidentally creating duplicate SKUs for existing products because the import process doesn’t validate uniqueness. Your order system can’t determine which product record is correct for the duplicate SKUs, causing fulfillment errors and shipment delays. Meanwhile, analytics reports show inflated product counts due to the duplicates, leading executives to make merchandising decisions based on incorrect catalog size.
The product catalog data contract template prevents these scenarios by enforcing SKU uniqueness, format standards, and controlled status values before data reaches dependent systems.
Dataset-level protection:
One more time, the schema check prevents unexpected structural changes. The row count ensures the catalog contains products. Integrity checks prevent two catastrophic catalog errors: negative prices that break pricing engines and duplicate SKUs that corrupt order-to-inventory matching across your entire supply chain.
checks: - schema: allow_extra_columns: false allow_other_column_order: false - row_count: threshold: must_be_greater_than: 0 - failed_rows: name: "List price must not be negative" qualifier: list_price_non_negative expression: list_price < 0 - failed_rows: name: "SKU should be unique" qualifier: sku_unique query: | SELECT sku FROM datasource.database.schema.products WHERE sku IS NOT NULL GROUP BY sku HAVING COUNT(*) > 1 threshold: must_be: 0
Column-level validation:
Required fields ensure every product has a unique ID, SKU, name, category, and status. Format validation enforces SKU conventions (uppercase alphanumeric with hyphens/underscores), preventing inconsistent formatting that breaks catalog searches and integrations. Value constraints guarantee positive prices and reasonable field lengths. Controlled status values keep product lifecycle states consistent across e-commerce, inventory, and analytics systems.
columns: - name: product_id data_type: string checks: - missing: # prevents null values - duplicate: # prevents duplicated values - invalid: # ensures reasonable field lengths name: "product_id length guardrail" valid_min_length: 1 valid_max_length: 64 - name: sku data_type: string checks: - missing: - invalid: # prevents inconsistent formatting name: "sku must be uppercase letters/numbers with separators" valid_format: name: SKU format regex: "^[A-Z0-9][A-Z0-9_-]{0,63}$" - name: product_name data_type: string checks: - missing: - invalid: # ensures reasonable field lengths name: "product_name length guardrail" valid_min_length: 2 valid_max_length: 255 - name: category data_type: string checks: - missing: - invalid: # ensures reasonable field lengths name: "category length guardrail" valid_min_length: 2 valid_max_length: 100 - name: list_price data_type: float checks: - missing: - invalid: # prevents negative values name: "list_price must be zero or positive" valid_min: 0 - name: status data_type: string checks: - missing: - invalid: # ensures consistency name: "Allowed product statuses" valid_values
🟢 This contract prevents duplicate products that break order fulfillment, enforces pricing integrity across all sales channels, maintains SKU format consistency for integrations, and ensures product status values work correctly in every downstream system.
Template #5: Customer Master Data Contract
Customer data is the foundation of personalization, marketing attribution, and lifetime value analysis. When customer master data degrades, your ability to understand and serve your customers is seriously impacted.
Consider this last scenario:
A checkout flow bug creates duplicate customer records for the same email address, fragmenting purchase history across multiple IDs. Your customer lifetime value calculations become meaningless, Marketing sends duplicate emails to the same people, while retention programs underfund high-value customers who appear low-value due to split records.
The customer master data contract template prevents this scenario by enforcing email uniqueness, format validation, and controlled values before data reaches CRM, marketing, and analytics systems.
Dataset-level protection:
The schema check prevents unexpected structural changes to customer records. The row count ensures the dataset contains customer data before consumption by downstream systems. And failed_rows prevents duplicate identities.
checks: - schema: allow_extra_columns: false allow_other_column_order: false - row_count: threshold: must_be_greater_than: 0 - failed_rows: name: "Email should be unique (if present)" qualifier: email_unique query: | SELECT email FROM customers WHERE email IS NOT NULL AND email <> '' GROUP BY email HAVING COUNT(*) > 1 threshold: must_be: 0
Column-level validation:
Duplicate checks ensure every customer has a unique ID, country code, status, and signup channel for proper segmentation and compliance. Invalid checks enforces email patterns and ISO-3166 country codes, preventing malformed data from breaking integrations. Note the use of a threshold on email validation—allowing up to 0.5% invalid emails to accommodate edge cases while still catching systematic issues. Invalid checks also keep customer lifecycle states and acquisition attribution consistent across marketing, analytics, and operations systems.
columns: - name: customer_id data_type: string checks: - missing: - duplicate: - invalid: valid_min_length: 1 valid_max_length: 64 - name: email data_type: string checks: - invalid: name: "email format (basic)" valid_format: regex: "^[^@\\\\s]+@[^@\\\\s]+\\\\.[^@\\\\s]+$" threshold: metric: percent must_be_less_than: 0.5 - name: country_code data_type: string checks: - missing: - invalid: name: "Two-letter country code (ISO-3166)" valid_format: regex: "^[A-Z]{2}$" - name: status data_type: string checks: - missing: - invalid: name: "Allowed customer statuses" valid_values: - active - inactive - banned - name: signup_channel data_type: string checks: - missing: - invalid: name: "Allowed signup channels" valid_values
🟢 This contract prevents duplicate customer identities that fragment LTV calculations, enforces email format validity for marketing automation, maintains country code standards for compliance and localization, and ensures signup channel attribution works correctly across all customer acquisition programs.
Implementation with Soda
Having the right data contract templates is only the beginning. The real value comes from embedding these contracts into your data pipelines so they actively prevent issues rather than documenting expectations that nobody enforces.
The retail templates we’ve covered provide starting points, but you’ll need to adjust thresholds, add company-specific validations, and align status values with your actual systems.
From Template to Production
→ Download templates from Soda’s template gallery and customize them for your specific business rules.
Step 1: Treat Contracts as Code
→ Store in version control using Git. Your contracts should live in a repository where changes are tracked, reviewed, and deployed through the same rigorous process as your production code. This creates an audit trail showing exactly when quality rules changed and why.
→ Review through pull requests before any contract changes reach production. When a team wants to relax a validation threshold or add a new allowed value, that change goes through code review, where stakeholders can assess the business impact. This prevents silent degradation of data quality standards over time.
Step 2: Verify Locally
Before deploying contracts to production, validate them against your actual data:
# pip install soda-{data source} for other data sources pip install soda-postgres # verify the contract locally against a data source soda contract verify -c contract.yml -ds
→ Test against real data sources in development or staging environments. Don’t just validate the YAML syntax, run actual queries against representative data to see which checks pass and which fail.
→ Iterate on thresholds and rules based on what you learn. If your inventory freshness check fails because weekend updates genuinely arrive after 24 hours, adjust the threshold to 48 hours rather than creating false positives that train teams to ignore alerts.
Step 3: Embed in Your Pipeline
Data contracts only protect you if they’re enforced at the right checkpoints. Strategic placement determines which issues you catch early versus which slip through to cause downstream damage.
Where to enforce contracts:
After data ingestion from POS systems - Validate order and sales transaction data immediately after it arrives from stores, catching issues while they’re still close to the source
Before loading into the data warehouse - Create a quality gate that prevents corrupt data from entering your analytical environment
At API layer for e-commerce platforms - Validate product catalog and customer data at the API boundary before it reaches internal systems
In ETL/ELT processes - Integrate with tools like dbt to validate data transformations at each stage
Enforcement mechanism: CI/CD pipelines check that schema changes are compatible with contracts before deployment. Data quality tools validate constraints against actual data on schedule or in real-time. When a contract fails, the data stops flowing until someone investigates and resolves the issue.
Step 4: Publish and Monitor
Once contracts are validated and embedded, publish them to Soda Cloud for continuous monitoring:
# publish and schedule the contract with Soda Cloud soda contract publish -c contract.yml -sc
→ Automated validation on schedule runs your contracts hourly, daily, or in real-time depending on your data freshness requirements. This creates a continuous quality feedback loop rather than one-time validation.
→ Smart alerting to the right owners routes failures to the teams responsible for fixing them. When the inventory contract fails because stock_reserved exceeds stock_on_hand, the alert goes to the warehouse management system team, not the data platform team. Clear ownership prevents alerts from being ignored as “someone else’s problem.”
→ Data observability dashboard provides visibility into contract health across all datasets. Teams can see which contracts are passing, which are failing, and trending metrics on data quality over time.
Book a demo to see how data contracts work in your specific environment with your actual data sources and business requirements.
AI-Powered Contract Generation
Don’t want to write YAML from scratch? Soda’s AI-powered contract autopilot can generate contracts automatically by analyzing your data structure and patterns.
One-click contract creation examines your tables and suggests appropriate checks based on data types, cardinality, and distribution patterns.
Start Small, Scale Systematically
Don’t try to implement contracts to all your datasets at once. Choose the ones that have the highest business impact to your use case. Get these contracts working smoothly, build confidence with stakeholders, then expand to the rest of your database.
This progressive approach lets you refine your process (verification workflows, alerting configurations, ownership assignments) on high-value datasets before scaling across your entire data ecosystem.
Ownership and Accountability
Each contract needs a clearly named owner—a person or role responsible for responding to breaches and approving changes. Without clear ownership, failed contracts generate alerts that no one takes action on, and quality standards decline due to negligence.
For retail contracts, ownership typically aligns with business domains:
Orders contract → E-commerce or Order Management team
Inventory contract → Supply Chain or Warehouse Operations team
Sales Transactions contract → Finance or Revenue Operations team
Product Catalog contract → Merchandising or Product Management team
Customer Data contract → CRM or Customer Analytics team
This domain-aligned ownership ensures the people who best understand the business rules are responsible for maintaining contract quality over time.
Evolving Contracts Over Time
Data contracts aren’t static documents, they evolve as your business changes.
As requirements change, producers propose contract updates, discuss them with consumers, and roll out new versions in a controlled way. This feedback loop prevents the chaos of uncoordinated changes while allowing necessary evolution.
Watch the collaboration workflow demonstration below showing how business users define quality expectations in the UI while data engineers validate and publish contracts using code and CLI—bridging the gap between business knowledge and technical implementation.
Conclusion: Beyond Validation to True Ownership
The templates in this guide represent best practices for retail data quality today. Use them to build stability and prevent expensive data failures. But as you implement them, remember that the ultimate goal is empowering business domain experts to own their data quality.
The people closest to business decisions understand what data quality actually means in context. They know when a 2% error rate is acceptable versus catastrophic, they understand why certain changes are urgent while others can wait, and they can assess the tradeoff between strict validation and business flexibility.
The real gain with data contracts isn’t just specs validation; it’s ownership and collaboration.
If we assume data engineers build data products and the business simply consumes them, we’ve created distance between data and decisions. The contracts we’ve discussed today bridge that gap through collaboration: business stakeholders define quality expectations, engineers implement validation logic, and both parties review changes together.
Looking forward, the goal isn’t stricter interfaces that require engineering intervention for every change. It’s enabling those closest to decisions to shape, evolve, and validate data products themselves, with automation doing the heavy lifting.
Ready to implement data contracts in your retail data pipelines?
Download the templates: Access all 5 retail data contract templates and customize them for your business. We recommend starting with orders and inventory for immediate impact.
See it in action: Book a demo to see how data contracts work in your specific environment with your actual data sources and business requirements.
Explore more use cases: Visit the complete template gallery for data contracts across industries—from finance to healthcare to manufacturing—and discover patterns you can apply to your retail operations. See also our finance data contract templates and 4 data contract examples you can use today.
Retail data ecosystems have grown exponentially complex. A single purchase now connects e-commerce platforms, point-of-sale systems, inventory management tools, payment processors, and marketing analytics, resulting in unprecedented data volume, velocity, and variety. This complexity places enormous demands on data quality in retail operations.
For far too long, data teams have operated in a reactive mode, repairing broken dashboards, debugging silent pipeline failures, and explaining why yesterday’s revenue reports do not match today’s figures. But there is a better way.
Data contracts act as automated checkpoints in your pipeline. If data meets defined quality standards, it proceeds downstream. If it doesn’t, the pipeline can block, quarantine, alert, or mark the dataset as invalid — depending on your enforcement strategy (i.e., how you integrate contracts into your pipelines).
In this guide, we’ll show you how to implement data contracts for retail with 5 ready-to-use templates you can deploy today.
Each template includes real-world failure scenarios and executable Soda contract examples that you can use right away by changing the thresholds and value sets to fit your environment.
What Are Data Contracts in Retail?
Data contracts are machine-readable agreements that define how data should be structured, validated, and governed as it moves between producers and consumers. As data flows through your pipelines, the contract automatically determines whether the data is fit to use according to agreed specifications.
In retail, this means creating explicit agreements between systems that generate data—like POS systems, e-commerce platforms, and inventory databases—and the teams that rely on them for analytics, inventory management, and business intelligence.
Instead of detecting problems during month-end close or regulatory submission, teams enforce expectations directly inside data pipelines. Together, domain teams and engineers set expectations about schema, freshness, quality rules, and more, and the contract makes those expectations testable.
Not all data contract implementations are equal, though. Some approaches focus on documentation and metadata standards only. Others — like Soda collaborative contracts — enforce data quality validation automatically during ingestion, transformation, or CI/CD workflows.
This means you can add automated checks for accuracy, completeness, and timeliness; prevent poor-quality data from reaching downstream systems; and set up proactive alerts to address issues before they escalate.
When a contract fails, it can:
Block pipeline execution (CI/CD gate)
Prevent downstream table updates
Trigger alerting workflows
Mark datasets as invalid in observability tools
In short, in retail, where data errors directly impact revenue, fulfillment, and customer trust, enforceable contracts transform reactive firefighting into predictable operations.
Why Retail Organizations Need Data Contracts
We’d say there are four compelling reasons:
First, they prevent silent data failures.
For example, if a developer renames “price” to “cost” without coordination, sales reports can suddenly show $0. Data contracts catch these breaking changes before they reach production, eliminating debugging emergencies.
Second, they define clear ownership boundaries.
When data quality issues arise, contracts specify exactly who fixes what. No more finger-pointing between teams or endless Slack threads trying to identify the responsible party.
Third, they enable safe change management.
Retail data management requires constant evolution—new product categories, updated payment methods, expanded markets. Data contracts enforce versioning and approval workflows, ensuring changes are intentional and coordinated rather than accidental and chaotic.
Fourth, they support compliance and governance requirements.
With regulations like GDPR and PCI DSS, retailers must track what customer data is collected, where it lives, and how long it’s retained. Data contracts can embed these governance rules directly into your data pipelines.
🟢 The advantage of data contracts for both producers and consumers is clear: less downtime, fewer surprises, and less time spent fixing other people’s changes.
Consider the example below of a raw invoice dataset from an online store. Without basic schema and data quality validation, the table can leave analysts guessing about data types, formats, and valid ranges.
Image source: Atlan
Sometimes, by the time the issues are discovered and solved, you’ve lost sales and got frustrated customers.
Therefore, by establishing automated validation at every checkpoint, contracts transform data quality challenges into managed, predictable processes. And by catching issues at the data level, you avoid expensive operational failures and maintain customer trust.
If you would like to learn more about the foundational structure of a data contract, check our guide: The Definitive Guide to Data Contracts |
|---|
Now, let’s see how these contracts are structured and how you can apply them to your retail data.
Data Contracts Templates for the Retail Sector
We’ve just launched a data contract template gallery. Watch the short video below where Santiago shows how to access the gallery and how to read data contracts.
Let’s explore the structure of data contracts in practice by going over our 5 ready-to-use retail templates: Orders, Inventory, Sales, Product, and Customer.
Template #1: Retail Orders Data Contract
Each order in a retail system touches multiple downstream processes. Consequently, a single corrupted order record can trigger cascading failures across the entire data ecosystem.
Consider this real-world failure scenario:
A developer adds a new payment method value (“debit”) to the payment_method field without coordinating with downstream teams. As a result, your payment processor integration, expecting only “cash,” “credit_card,” or “transfer,” fails silently and orders start to pile up in a pending state.
The retail orders data contract template prevents the scenario above with automated validation before data reaches critical systems. Let’s go over it.
Dataset-level protection:
The schema check catches structural changes immediately. The freshness check ensures order data is never older than 24 hours (critical for inventory management and fulfillment scheduling). The row count validation prevents empty datasets from reaching revenue reporting systems.
checks: - schema: {} # catches structural changes - freshness: column: created_at threshold: unit: hour must_be_less_than_or_equal: 24 # ensures orders are never older than 24 hours - row_count: threshold: must_be_greater_than: 0 # prevents empty datasets
Column-level validation:
Required fields like order_id, customer_id, billing_address, and shipping_address must never be null—without these, orders can’t be fulfilled or attributed to customers.
Value constraints ensure order_quantity is at least 1 and discount values are positive, preventing impossible business states.
Controlled values restrict payment_method to only “cash,” “credit_card,” or “transfer,” preventing integration failures with payment processors.
Format validation enforces a two-letter pattern for country_code fields, protecting shipping integrations and geographic reporting from invalid codes.
columns: - name: order_id data_type: string checks: - missing: # prevents null values name: No missing values - name: customer_id data_type: string checks: - missing: name: No missing values - name: order_quantity data_type: integer checks: - missing: - invalid: # prevents negative amounts name: Positive quantity valid_min: 1 - name: payment_method data_type: string checks: - missing: - invalid: name: Allowed payment methods valid_values: # prevents integration failures - cash - credit_card - transfer - name: country_code data_type: string checks: - missing: - invalid: # ensures format standardization name: Two-letter country code valid_format: regex
🟢 In terms of business impact, this contract alone prevents incomplete or invalid orders from breaking analytics dashboards, revenue reports, and customer segmentation models.
Template #2: Inventory Levels Data Contract
Inventory data is the operational core of retail. If inventory levels are wrong, everything downstream breaks: ordering, fulfillment, warehouse operations, and financial reporting. A single incorrect stock count can trigger a cascade of expensive mistakes across your entire supply chain.
Consider this other failure scenario:
Your inventory ETL job experiences delays overnight, and stock data arrives 36 hours stale. Your replenishment algorithms make ordering decisions based on outdated levels, and the allocation engine promises inventory to multiple orders that physically don’t exist.
The inventory levels data contract template prevents that scenario by enforcing logical consistency and freshness requirements before data reaches critical systems.
Dataset-level protection:
The schema check immediately flags any structural changes to the inventory table. The row count validation ensures the dataset contains actual inventory records before consumption. The freshness check enforces a 24-hour SLA using the last_updated_at timestamp—critical for real-time allocation and replenishment decisions.
Note the use of variables, which allows teams to easily adjust the freshness threshold without editing multiple places in the contract.
variables: FRESHNESS_HOURS: default: 24 checks: - schema: {} # catches structural changes - row_count: threshold: must_be_greater_than: 0 # prevents empty datasets - freshness: column: last_updated_at threshold: unit: hour must_be_less_than_or_equal: ${var.FRESHNESS_HOURS} # ensures inventory is never older than 24 hours
Cross-field integrity checks
This is where inventory data contracts become especially powerful. Beyond validating individual columns, you can enforce relationships between fields. Failed rows checks identify specific records that violate business logic:
checks: - failed_rows: name: "Stock values must never be negative" qualifier: non_negative_stocks expression: > stock_on_hand < 0 OR stock_reserved < 0 OR stock_available < 0 - failed_rows: name: "Reserved stock cannot exceed stock on hand" qualifier: reserved_le_on_hand expression: stock_reserved > stock_on_hand - failed_rows: name: "Available stock must equal on_hand minus reserved" qualifier: available_equals_on_hand_minus_reserved expression: stock_available <> (stock_on_hand - stock_reserved) - failed_rows: name: "last_updated_at must not be in the future" qualifier: last_updated_not_future expression
The first check catches any negative values across all stock columns.
The second prevents the impossible scenario where reserved stock exceeds what’s physically available.
The third enforces the fundamental inventory equation: available inventory must always equal on-hand minus reserved.
The fourth check prevents timestamp anomalies where data appears to be from the future—a common sign of timezone issues or system clock problems.
Column-level validation:
Required fields like product_id, location_id, and last_updated_at must never be null. Without these identifiers, inventory records can’t be linked to products, locations, or tracked for freshness.
Non-negative constraints prevent impossible inventory states. All three stock columns—stock_on_hand, stock_reserved, and stock_available—must be zero or positive. Negative inventory is logically impossible and indicates data corruption or system errors.
columns: - name: product_id data_type: string checks: - missing: name: No missing values - name: location_id data_type: string checks: - missing: name: No missing values - name: stock_on_hand data_type: integer checks: - missing: - invalid: name: "Stock on hand must be zero or positive" valid_min: 0 - name: stock_reserved data_type: integer checks: - missing: - invalid: name: "Reserved stock must be zero or positive" valid_min: 0 - name: stock_available data_type: integer checks: - missing: - invalid: name: "Available stock must be zero or positive" valid_min: 0 - name: last_updated_at data_type: dateTime checks: - missing
🟢 As a result, this contract reduces overselling risk, prevents broken availability signals, and protects replenishment and allocation processes from operating on impossible or inconsistent inventory states.
Template #3: Sales Transactions Data Contract
Sales transactions data flows into revenue reports, margin analysis, channel performance metrics, and executive dashboards. When sales data is corrupted, operational decision-making is heavily compromised.
Let’s consider another possible scenario:
A point-of-sale system bug starts creating duplicate line items for the same product within orders, making revenue reports show inflated sales figures that suggest you’re hitting targets when you’re actually underperforming. Finance discovers the revenue inflation during quarter-end close, forcing a restatement that erodes executive confidence in your data systems.
The sales transactions data contract template prevents that scenario by enforcing both individual field validation and critical cross-field financial logic.
Dataset-level protection:
Again, we want to protect schema, row count and freshness. And cross-field integrity checks prevent the most expensive sales data errors: future-dated transactions that break trending analysis, duplicate line items that inflate revenue, incorrect net amount calculations that corrupt margin reports, and impossible discounts that create negative margins.
variables: FRESHNESS_HOURS: default: 24 checks: - schema: # catches structural changes allow_extra_columns: false allow_other_column_order: false - row_count: threshold: must_be_greater_than: 0 # prevents empty datasets - freshness: # ensures transactions are never older than 24 hours column: order_date threshold: unit: hour must_be_less_than_or_equal: ${var.FRESHNESS_HOURS} - failed_rows: name: "order_date must not be in the future" qualifier: order_date_not_future expression: order_date > CURRENT_TIMESTAMP - failed_rows: name: "No duplicate line items per order" qualifier: dup_order_product query: | SELECT order_id, product_id FROM sales_transactions GROUP BY order_id, product_id HAVING COUNT(*) > 1 threshold: must_be: 0 - failed_rows: name: "net_amount must equal (quantity * unit_price) - discount_amount" qualifier: net_amount_formula expression: net_amount <> ((quantity * unit_price) - discount_amount) - failed_rows: name: "discount cannot exceed gross amount" qualifier: discount_le_gross expression
Note that you can also use full SQL query blocks for more complex validations. This is particularly useful when you need to check relationships across multiple tables or perform aggregations. In the contract above we use a SQL query to detect duplicate line items.
Column-level validation:
Required fields ensure every transaction can be traced to a specific order, customer, and product. Value constraints prevent impossible quantities (less than 1) or negative prices. Controlled channel values keep reporting consistent across all sales sources.
columns: - name: order_id data_type: string checks: - missing: - invalid: # prevents wrong ids valid_min_length: 1 valid_max_length: 64 - name: customer_id data_type: string checks: - missing: - name: product_id data_type: string checks: - missing: - name: quantity data_type: integer checks: - missing: - invalid: # prevents impossible quantities name: "Quantity must be positive" valid_min: 1 - name: unit_price data_type: float checks: - missing: - invalid: valid_min: 0 # prevents negative values - name: channel data_type: string checks: - missing: - invalid: name: "Allowed sales channels" valid_values: # ensures consistent values
🟢 Business-wise, this contract protects revenue reporting accuracy, prevents margin calculation errors, eliminates duplicate sales records, and ensures channel attribution works correctly across your entire retail ecosystem.
Template #4: Product Catalog Data Contract
A product catalog is the reference source of truth that every other retail system depends on. Orders reference product IDs, inventory tracks product SKUs, pricing engines pull list prices, and analytics aggregate by categories and brands. When product master data is corrupt or inconsistent, the entire retail operation fractures.
Consider the following scenario:
A merchandising team imports a new product line, accidentally creating duplicate SKUs for existing products because the import process doesn’t validate uniqueness. Your order system can’t determine which product record is correct for the duplicate SKUs, causing fulfillment errors and shipment delays. Meanwhile, analytics reports show inflated product counts due to the duplicates, leading executives to make merchandising decisions based on incorrect catalog size.
The product catalog data contract template prevents these scenarios by enforcing SKU uniqueness, format standards, and controlled status values before data reaches dependent systems.
Dataset-level protection:
One more time, the schema check prevents unexpected structural changes. The row count ensures the catalog contains products. Integrity checks prevent two catastrophic catalog errors: negative prices that break pricing engines and duplicate SKUs that corrupt order-to-inventory matching across your entire supply chain.
checks: - schema: allow_extra_columns: false allow_other_column_order: false - row_count: threshold: must_be_greater_than: 0 - failed_rows: name: "List price must not be negative" qualifier: list_price_non_negative expression: list_price < 0 - failed_rows: name: "SKU should be unique" qualifier: sku_unique query: | SELECT sku FROM datasource.database.schema.products WHERE sku IS NOT NULL GROUP BY sku HAVING COUNT(*) > 1 threshold: must_be: 0
Column-level validation:
Required fields ensure every product has a unique ID, SKU, name, category, and status. Format validation enforces SKU conventions (uppercase alphanumeric with hyphens/underscores), preventing inconsistent formatting that breaks catalog searches and integrations. Value constraints guarantee positive prices and reasonable field lengths. Controlled status values keep product lifecycle states consistent across e-commerce, inventory, and analytics systems.
columns: - name: product_id data_type: string checks: - missing: # prevents null values - duplicate: # prevents duplicated values - invalid: # ensures reasonable field lengths name: "product_id length guardrail" valid_min_length: 1 valid_max_length: 64 - name: sku data_type: string checks: - missing: - invalid: # prevents inconsistent formatting name: "sku must be uppercase letters/numbers with separators" valid_format: name: SKU format regex: "^[A-Z0-9][A-Z0-9_-]{0,63}$" - name: product_name data_type: string checks: - missing: - invalid: # ensures reasonable field lengths name: "product_name length guardrail" valid_min_length: 2 valid_max_length: 255 - name: category data_type: string checks: - missing: - invalid: # ensures reasonable field lengths name: "category length guardrail" valid_min_length: 2 valid_max_length: 100 - name: list_price data_type: float checks: - missing: - invalid: # prevents negative values name: "list_price must be zero or positive" valid_min: 0 - name: status data_type: string checks: - missing: - invalid: # ensures consistency name: "Allowed product statuses" valid_values
🟢 This contract prevents duplicate products that break order fulfillment, enforces pricing integrity across all sales channels, maintains SKU format consistency for integrations, and ensures product status values work correctly in every downstream system.
Template #5: Customer Master Data Contract
Customer data is the foundation of personalization, marketing attribution, and lifetime value analysis. When customer master data degrades, your ability to understand and serve your customers is seriously impacted.
Consider this last scenario:
A checkout flow bug creates duplicate customer records for the same email address, fragmenting purchase history across multiple IDs. Your customer lifetime value calculations become meaningless, Marketing sends duplicate emails to the same people, while retention programs underfund high-value customers who appear low-value due to split records.
The customer master data contract template prevents this scenario by enforcing email uniqueness, format validation, and controlled values before data reaches CRM, marketing, and analytics systems.
Dataset-level protection:
The schema check prevents unexpected structural changes to customer records. The row count ensures the dataset contains customer data before consumption by downstream systems. And failed_rows prevents duplicate identities.
checks: - schema: allow_extra_columns: false allow_other_column_order: false - row_count: threshold: must_be_greater_than: 0 - failed_rows: name: "Email should be unique (if present)" qualifier: email_unique query: | SELECT email FROM customers WHERE email IS NOT NULL AND email <> '' GROUP BY email HAVING COUNT(*) > 1 threshold: must_be: 0
Column-level validation:
Duplicate checks ensure every customer has a unique ID, country code, status, and signup channel for proper segmentation and compliance. Invalid checks enforces email patterns and ISO-3166 country codes, preventing malformed data from breaking integrations. Note the use of a threshold on email validation—allowing up to 0.5% invalid emails to accommodate edge cases while still catching systematic issues. Invalid checks also keep customer lifecycle states and acquisition attribution consistent across marketing, analytics, and operations systems.
columns: - name: customer_id data_type: string checks: - missing: - duplicate: - invalid: valid_min_length: 1 valid_max_length: 64 - name: email data_type: string checks: - invalid: name: "email format (basic)" valid_format: regex: "^[^@\\\\s]+@[^@\\\\s]+\\\\.[^@\\\\s]+$" threshold: metric: percent must_be_less_than: 0.5 - name: country_code data_type: string checks: - missing: - invalid: name: "Two-letter country code (ISO-3166)" valid_format: regex: "^[A-Z]{2}$" - name: status data_type: string checks: - missing: - invalid: name: "Allowed customer statuses" valid_values: - active - inactive - banned - name: signup_channel data_type: string checks: - missing: - invalid: name: "Allowed signup channels" valid_values
🟢 This contract prevents duplicate customer identities that fragment LTV calculations, enforces email format validity for marketing automation, maintains country code standards for compliance and localization, and ensures signup channel attribution works correctly across all customer acquisition programs.
Implementation with Soda
Having the right data contract templates is only the beginning. The real value comes from embedding these contracts into your data pipelines so they actively prevent issues rather than documenting expectations that nobody enforces.
The retail templates we’ve covered provide starting points, but you’ll need to adjust thresholds, add company-specific validations, and align status values with your actual systems.
From Template to Production
→ Download templates from Soda’s template gallery and customize them for your specific business rules.
Step 1: Treat Contracts as Code
→ Store in version control using Git. Your contracts should live in a repository where changes are tracked, reviewed, and deployed through the same rigorous process as your production code. This creates an audit trail showing exactly when quality rules changed and why.
→ Review through pull requests before any contract changes reach production. When a team wants to relax a validation threshold or add a new allowed value, that change goes through code review, where stakeholders can assess the business impact. This prevents silent degradation of data quality standards over time.
Step 2: Verify Locally
Before deploying contracts to production, validate them against your actual data:
# pip install soda-{data source} for other data sources pip install soda-postgres # verify the contract locally against a data source soda contract verify -c contract.yml -ds
→ Test against real data sources in development or staging environments. Don’t just validate the YAML syntax, run actual queries against representative data to see which checks pass and which fail.
→ Iterate on thresholds and rules based on what you learn. If your inventory freshness check fails because weekend updates genuinely arrive after 24 hours, adjust the threshold to 48 hours rather than creating false positives that train teams to ignore alerts.
Step 3: Embed in Your Pipeline
Data contracts only protect you if they’re enforced at the right checkpoints. Strategic placement determines which issues you catch early versus which slip through to cause downstream damage.
Where to enforce contracts:
After data ingestion from POS systems - Validate order and sales transaction data immediately after it arrives from stores, catching issues while they’re still close to the source
Before loading into the data warehouse - Create a quality gate that prevents corrupt data from entering your analytical environment
At API layer for e-commerce platforms - Validate product catalog and customer data at the API boundary before it reaches internal systems
In ETL/ELT processes - Integrate with tools like dbt to validate data transformations at each stage
Enforcement mechanism: CI/CD pipelines check that schema changes are compatible with contracts before deployment. Data quality tools validate constraints against actual data on schedule or in real-time. When a contract fails, the data stops flowing until someone investigates and resolves the issue.
Step 4: Publish and Monitor
Once contracts are validated and embedded, publish them to Soda Cloud for continuous monitoring:
# publish and schedule the contract with Soda Cloud soda contract publish -c contract.yml -sc
→ Automated validation on schedule runs your contracts hourly, daily, or in real-time depending on your data freshness requirements. This creates a continuous quality feedback loop rather than one-time validation.
→ Smart alerting to the right owners routes failures to the teams responsible for fixing them. When the inventory contract fails because stock_reserved exceeds stock_on_hand, the alert goes to the warehouse management system team, not the data platform team. Clear ownership prevents alerts from being ignored as “someone else’s problem.”
→ Data observability dashboard provides visibility into contract health across all datasets. Teams can see which contracts are passing, which are failing, and trending metrics on data quality over time.
Book a demo to see how data contracts work in your specific environment with your actual data sources and business requirements.
AI-Powered Contract Generation
Don’t want to write YAML from scratch? Soda’s AI-powered contract autopilot can generate contracts automatically by analyzing your data structure and patterns.
One-click contract creation examines your tables and suggests appropriate checks based on data types, cardinality, and distribution patterns.
Start Small, Scale Systematically
Don’t try to implement contracts to all your datasets at once. Choose the ones that have the highest business impact to your use case. Get these contracts working smoothly, build confidence with stakeholders, then expand to the rest of your database.
This progressive approach lets you refine your process (verification workflows, alerting configurations, ownership assignments) on high-value datasets before scaling across your entire data ecosystem.
Ownership and Accountability
Each contract needs a clearly named owner—a person or role responsible for responding to breaches and approving changes. Without clear ownership, failed contracts generate alerts that no one takes action on, and quality standards decline due to negligence.
For retail contracts, ownership typically aligns with business domains:
Orders contract → E-commerce or Order Management team
Inventory contract → Supply Chain or Warehouse Operations team
Sales Transactions contract → Finance or Revenue Operations team
Product Catalog contract → Merchandising or Product Management team
Customer Data contract → CRM or Customer Analytics team
This domain-aligned ownership ensures the people who best understand the business rules are responsible for maintaining contract quality over time.
Evolving Contracts Over Time
Data contracts aren’t static documents, they evolve as your business changes.
As requirements change, producers propose contract updates, discuss them with consumers, and roll out new versions in a controlled way. This feedback loop prevents the chaos of uncoordinated changes while allowing necessary evolution.
Watch the collaboration workflow demonstration below showing how business users define quality expectations in the UI while data engineers validate and publish contracts using code and CLI—bridging the gap between business knowledge and technical implementation.
Conclusion: Beyond Validation to True Ownership
The templates in this guide represent best practices for retail data quality today. Use them to build stability and prevent expensive data failures. But as you implement them, remember that the ultimate goal is empowering business domain experts to own their data quality.
The people closest to business decisions understand what data quality actually means in context. They know when a 2% error rate is acceptable versus catastrophic, they understand why certain changes are urgent while others can wait, and they can assess the tradeoff between strict validation and business flexibility.
The real gain with data contracts isn’t just specs validation; it’s ownership and collaboration.
If we assume data engineers build data products and the business simply consumes them, we’ve created distance between data and decisions. The contracts we’ve discussed today bridge that gap through collaboration: business stakeholders define quality expectations, engineers implement validation logic, and both parties review changes together.
Looking forward, the goal isn’t stricter interfaces that require engineering intervention for every change. It’s enabling those closest to decisions to shape, evolve, and validate data products themselves, with automation doing the heavy lifting.
Ready to implement data contracts in your retail data pipelines?
Download the templates: Access all 5 retail data contract templates and customize them for your business. We recommend starting with orders and inventory for immediate impact.
See it in action: Book a demo to see how data contracts work in your specific environment with your actual data sources and business requirements.
Explore more use cases: Visit the complete template gallery for data contracts across industries—from finance to healthcare to manufacturing—and discover patterns you can apply to your retail operations. See also our finance data contract templates and 4 data contract examples you can use today.
Trusted by the world’s leading enterprises
Real stories from companies using Soda to keep their data reliable, accurate, and ready for action.
At the end of the day, we don’t want to be in there managing the checks, updating the checks, adding the checks. We just want to go and observe what’s happening, and that’s what Soda is enabling right now.

Sid Srivastava
Director of Data Governance, Quality and MLOps
Investing in data quality is key for cross-functional teams to make accurate, complete decisions with fewer risks and greater returns, using initiatives such as product thinking, data governance, and self-service platforms.

Mario Konschake
Director of Product-Data Platform
Soda has integrated seamlessly into our technology stack and given us the confidence to find, analyze, implement, and resolve data issues through a simple self-serve capability.

Sutaraj Dutta
Data Engineering Manager
Our goal was to deliver high-quality datasets in near real-time, ensuring dashboards reflect live data as it flows in. But beyond solving technical challenges, we wanted to spark a cultural shift - empowering the entire organization to make decisions grounded in accurate, timely data.

Gu Xie
Head of Data Engineering
4,4 sur 5
Commencez à faire confiance à vos données. Aujourd'hui.
Trouvez, comprenez et corrigez tout problème de qualité des données en quelques secondes.
Du niveau de la table au niveau des enregistrements.
Adopté par
Product








Trusted by the world’s leading enterprises
Real stories from companies using Soda to keep their data reliable, accurate, and ready for action.
At the end of the day, we don’t want to be in there managing the checks, updating the checks, adding the checks. We just want to go and observe what’s happening, and that’s what Soda is enabling right now.
Sid Srivastava
Director of Data Governance, Quality and MLOps
Investing in data quality is key for cross-functional teams to make accurate, complete decisions with fewer risks and greater returns, using initiatives such as product thinking, data governance, and self-service platforms.
Mario Konschake
Director of Product-Data Platform
Soda has integrated seamlessly into our technology stack and given us the confidence to find, analyze, implement, and resolve data issues through a simple self-serve capability.
Sutaraj Dutta
Data Engineering Manager
Our goal was to deliver high-quality datasets in near real-time, ensuring dashboards reflect live data as it flows in. But beyond solving technical challenges, we wanted to spark a cultural shift - empowering the entire organization to make decisions grounded in accurate, timely data.
Gu Xie
Head of Data Engineering
4,4 sur 5
Commencez à faire confiance à vos données. Aujourd'hui.
Trouvez, comprenez et corrigez tout problème de qualité des données en quelques secondes.
Du niveau de la table au niveau des enregistrements.
Adopté par
Product
Solutions
Trusted by the world’s leading enterprises
Real stories from companies using Soda to keep their data reliable, accurate, and ready for action.
At the end of the day, we don’t want to be in there managing the checks, updating the checks, adding the checks. We just want to go and observe what’s happening, and that’s what Soda is enabling right now.
Sid Srivastava
Director of Data Governance, Quality and MLOps
Investing in data quality is key for cross-functional teams to make accurate, complete decisions with fewer risks and greater returns, using initiatives such as product thinking, data governance, and self-service platforms.
Mario Konschake
Director of Product-Data Platform
Soda has integrated seamlessly into our technology stack and given us the confidence to find, analyze, implement, and resolve data issues through a simple self-serve capability.
Sutaraj Dutta
Data Engineering Manager
Our goal was to deliver high-quality datasets in near real-time, ensuring dashboards reflect live data as it flows in. But beyond solving technical challenges, we wanted to spark a cultural shift - empowering the entire organization to make decisions grounded in accurate, timely data.
Gu Xie
Head of Data Engineering
4,4 sur 5
Commencez à faire confiance à vos données. Aujourd'hui.
Trouvez, comprenez et corrigez tout problème de qualité des données en quelques secondes.
Du niveau de la table au niveau des enregistrements.
Adopté par
Product
Solutions
Company