Data Contracts vs Schema Registry
Data Contracts vs Schema Registry
Data Contracts vs Schema Registry

Fabiana Ferraz
Fabiana Ferraz
Rédacteur technique chez Soda
Rédacteur technique chez Soda
Table des matières
Modern data systems are no longer just simple pipelines moving data from one database to another. Today’s data infrastructure is distributed across cloud platforms, streaming systems, warehouses, APIs, SaaS applications, and machine learning workflows.
Data moves all the time between producers and consumers, often across teams that operate independently from one another. As those systems scale, one problem appears almost everywhere: upstream changes break downstream systems more often than teams expect.
A producer renames a field. A data type changes quietly in production. A required value suddenly becomes nullable. A Kafka consumer starts failing to deserialize events. A dashboard begins showing incomplete numbers without anyone immediately noticing why.
This is the exact environment where conversations around data contracts and schema registries tend to emerge. The two concepts are closely related and often discussed together in event-driven architectures and modern data engineering workflows — but they aren’t interchangeable.
A schema registry manages and validates schema evolution across streaming systems. A data contract goes further: it defines how the data should behave, who owns it, and what downstream consumers can rely on.
Understanding the difference matters because these systems solve different layers of the same reliability problem.
Key Takeaways |
|---|
|
What Is a Schema Registry?
A schema registry manages message schemas for event-driven and streaming systems. The registry sits alongside the broker — Confluent Schema Registry next to Kafka, AWS Glue Schema Registry next to MSK, Apicurio in self-hosted setups — and ensures producers and consumers agree on message structure as data moves through the stream.
The registry stores schema versions in one place and validates compatibility whenever a schema evolves. The validation runs before the new version is allowed into production: if the change breaks the configured compatibility rule, the registry rejects the schema and the producer cannot publish.
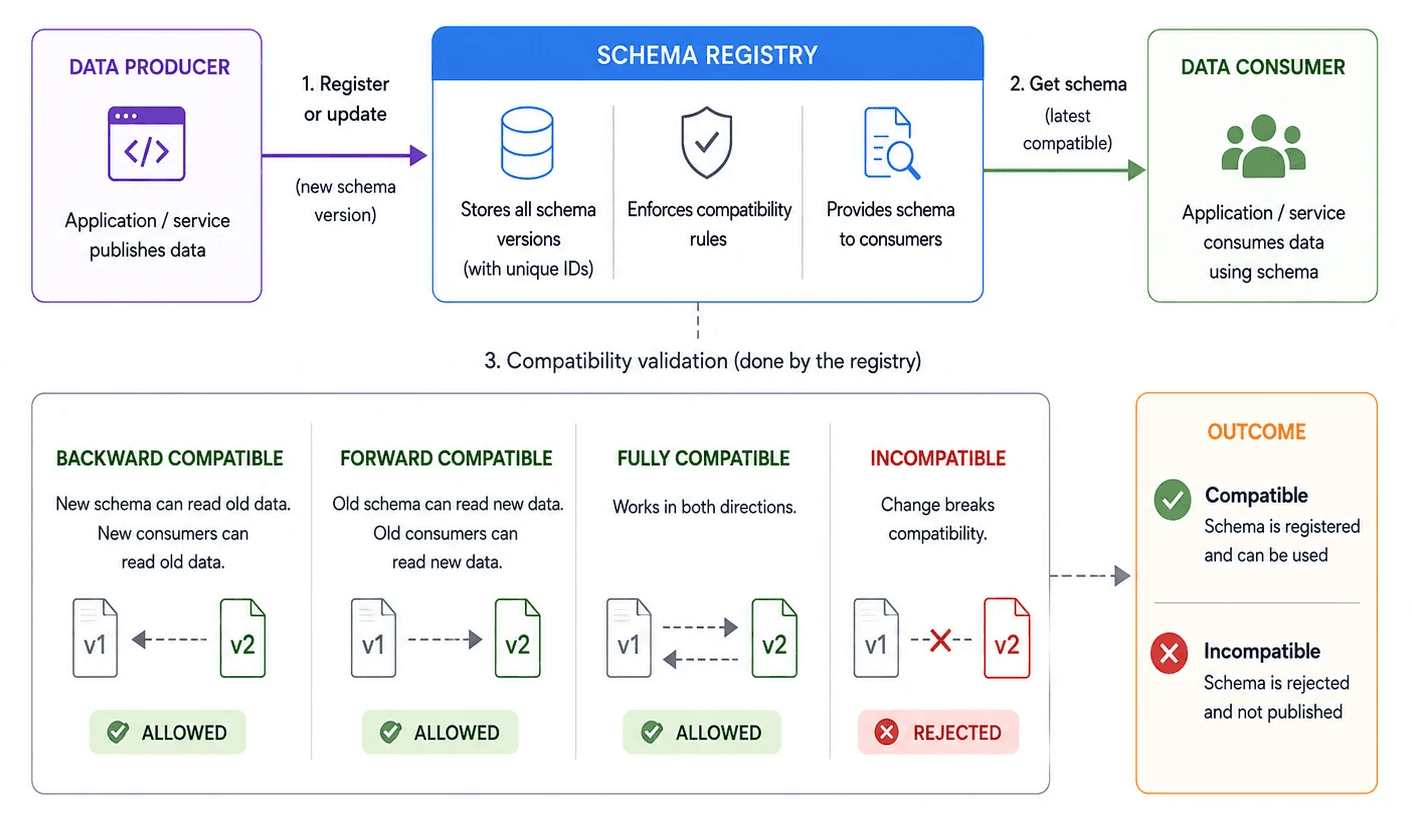
For example, a producer may attempt to register a new version of an event schema. The registry checks if the change is backward-compatible, forward-compatible, or fully compatible with existing consumers. It allows the update only then.
In practice, the mode determines who has to move first: backward compatibility means new consumers can read old data, forward means old consumers can read new data, and full means both. Teams pick the mode based on which side of the producer-consumer relationship can deploy faster.
This is where the architectural enforcement lives. The registry isn’t a periodic scan or a separate validation step — it’s an inline gate in the streaming write path. A schema-incompatible message never enters the topic.
Schema registries are especially common in architectures built around:
Apache Kafka
Avro schemas
Protobuf
Event-driven microservices
Real-time data pipelines
What schema registries enforce is structural. A registered message conforms to a known shape, and schema evolution remains safe over time.
What they do not enforce, however, is whether the data inside the message is operationally correct — whether values make sense, whether records are complete, whether the event arrived when downstream consumers needed it.
What Are Data Contracts?
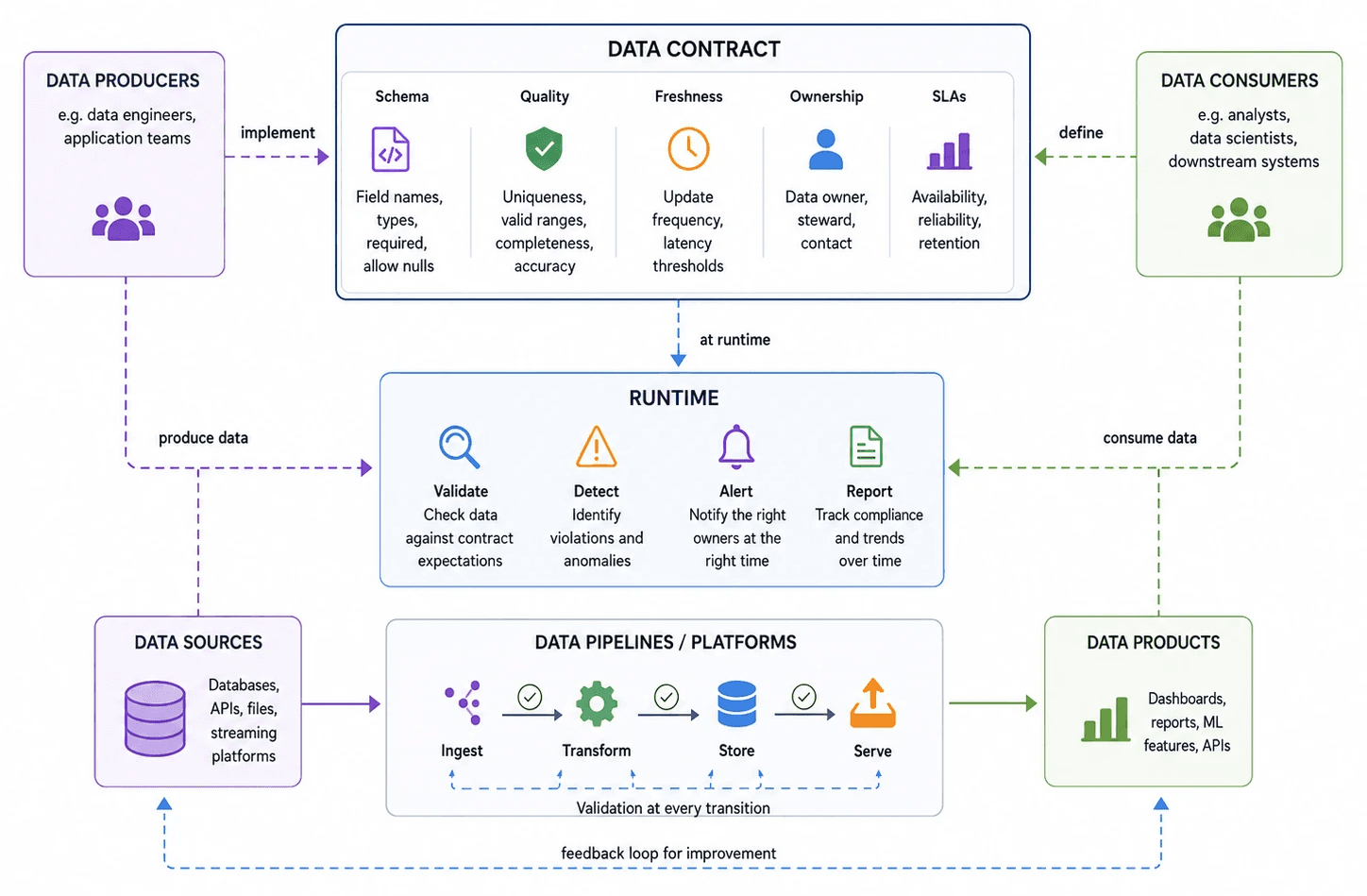
A data contract is an enforceable agreement between data producers and data consumers, expressed as executable checks in YAML. It defines what data should look like and how it should behave over time.
Contracts are typically co-authored — engineers own the technical shape, while business and governance define what the data should mean and who’s accountable when it breaks.
At a basic level, a contract may include schema definitions such as column names, data types, and required fields. But modern data contracts usually go further than schema alone.
Data contracts often define:
Quality expectations
Freshness requirements
Ownership and accountability
Allowed values and constraints
Service-level expectations
Change management rules
Each of these expectations is expressed as a check inside the contract.
A schema check validates that a dataset’s columns and types match what the contract declared.
A freshness check validates that data arrived by the expected time.
A missing or invalid check validates the values inside the records.
Together, the checks make the contract enforceable — the contract isn’t just a description of what should be true, it’s the set of executable assertions that prove it.
Here’s what that looks like for a clickstream event stream:
# Contract for event_data — a source-aligned clickstream # from a marketplace platform's event pipeline checks: - schema: allow_extra_columns: false allow_other_column_order: false - row_count: threshold: must_be_greater_than: 0 - freshness: column: ingest_time threshold: unit: hour must_be_less_than: 1 columns: - name: event_id data_type: string checks: - missing: - duplicate: - invalid: name: "Event ID length guardrail" valid_min_length: 1 valid_max_length: 128 - name: event_name data_type: string checks: - missing: - invalid: name: "Valid event names" valid_values: - job_viewed - apply_clicked - search_performed - name: ingest_time data_type: timestamp checks: - missing: # ... other columns: user_id, session_id, platform, entity_type, etc.
Adapted from Soda’s source-aligned event contract template.
This contract governs event_data, a clickstream landing table. The dataset checks enforce structure (schema rejects unknown or reordered columns), basic delivery (row_count > 0), and timeliness (freshness: ingest_time < 1 hour — a registry can’t enforce that). Each column adds value-level rules: event_id must be present, unique (duplicate), and within length bounds; event_name must be one of the approved values (valid_values).
Most data failures are not caused by catastrophic infrastructure outages. They happen when data technically arrives, but no longer behaves the way downstream systems expect. A table may still exist while containing incomplete records. A pipeline may continue running while silently introducing duplicate values. A schema may technically remain compatible while still violating downstream business assumptions.
Data contracts reduce those failures by making expectations explicit and enforceable. In practice, contracts are increasingly integrated directly into CI/CD pipelines — validated during deployment, tracked in version control with pipeline code, used to stop breaking changes from reaching production unnoticed.
Where Each Fits
With both concepts in place, the question becomes where each one actually belongs.
The architectural difference
Data contracts diverge architecturally from schema registries:
A contract’s schema check runs at scan time, against a landed dataset — a warehouse table, a lakehouse table, or the table that a streaming pipeline writes to. It sits at the read boundary.
A schema registry runs at publish time, against a streaming message, and blocks incompatible message schemas before they hit the topic. It sits at the write boundary.
Both enforce schema, but in different places, at different times, against different artifacts.
Schema registries: fit and limits
Schema registries fit where the streaming infrastructure has to enforce structure before data lands.
They’re particularly effective in architectures built around Kafka or event-driven microservices, where producers frequently publish new versions of messages while downstream services continue consuming older formats. Without compatibility enforcement, even small schema changes can cascade into failures across multiple systems.
A schema registry introduces centralized control over that evolution process. Registries are the right tool when teams need to:
Enforce compatibility rules at publish time
Prevent invalid schema deployments
Version schemas safely
Coordinate producer-consumer evolution
Reduce serialization failures in production
Where schema registries stop being enough is the moment the data lands. A schema-compatible event may still arrive late, contain low-quality values, or violate downstream assumptions in ways the registry cannot detect on its own.
Picture a payment event where the amount field is typed as a decimal and the currency field is typed as a string. A message arrives with amount: -4500.00 and currency: "ZZZ". The schema registry accepts both — the decimal is a decimal, the string is a string. But the business doesn’t allow negative payment amounts, and “ZZZ” isn’t a real currency code. Both fields type-check. Neither is operationally correct.
That’s the boundary registries can’t cross. They protect systems from breaking structurally, but they don’t ensure that data remains trustworthy, usable, or aligned with operational reality once it enters the broader ecosystem.
Data contracts: fit and limits
Data contracts fit where multiple teams depend on shared datasets across analytics, reporting, and operational systems.
Take an analytics engineering team running a customer table that powers dashboards, forecasting models, and downstream business intelligence workflows. The team needs more than structural validation — they need confidence that the data remains usable, reliable, and predictable over time. That’s the gap data contracts close.
Contracts are the right tool when teams need to define:
Freshness expectations
Completeness rules
Valid business values
SLA requirements
Ownership
Change approval workflows
Contracts are especially useful across ETL pipelines, data warehouses, data lakes, batch and streaming systems, and cross-functional analytics teams managing shared business-critical datasets.
Where data contracts have limits is the cost side. Authoring contracts manually takes engineering effort, and the discipline only pays off when teams commit to ownership — without a clear owner, a contract drifts out of sync with the dataset it’s supposed to govern.
For low-stakes datasets owned by a single team that already has tight CI/CD on the producer — dbt tests gating every merge, or Pydantic validation in the producer service — a contract can be more overhead than benefit. The judgment call is whether the dataset is shared widely enough, and changes frequently enough, that explicit producer-consumer expectations earn their keep.
The decision rule
If the failure mode you’re worried about happens at the broker, you need a schema registry; if it happens after the data has landed, you need a data contract; if both, you need both.
Why Mature Teams Often Use Both
In practice, mature data organizations rarely treat schema registries and data contracts as competing solutions. They solve different layers of the reliability problem.
A schema registry helps ensure events remain structurally compatible as schemas evolve — enforcement happens inline, at publish time, in the streaming infrastructure. A data contract defines broader expectations around quality, ownership, reliability, and downstream usability — enforcement happens at scan time, against landed datasets. One protects the write path. The other protects the read path. As data systems grow more distributed, both matter.
A streaming platform may successfully process millions of events per hour while downstream analytics systems quietly degrade because freshness expectations were violated or business logic changed unexpectedly. Schema compatibility alone does not guarantee operational reliability.
This is why many modern teams combine multiple layers of protection:
Schema registries for structural governance at the streaming edge
Data contracts for operational expectations across producers and consumers
Observability for runtime visibility into what actually shipped
Testing for automated validation in CI/CD
Most teams assemble this stack from separate vendors. Soda combines data contracts and data observability on one platform, so the structural layer and the operational layer share the same checks, the same ownership, and the same alerts — collapsing the coordination cost of treating reliability as four separate disciplines.
Contract coverage at scale is the next problem. Writing and maintaining contracts manually across hundreds of datasets becomes intractable for large data teams. Soda’s answer is a three-part contract layer: engineers hand-author contracts for the datasets that matter most, Contract Autopilot generates coverage for the long tail from observed data patterns and Soda AI’s profiling, and data observability catches what slips through at runtime.
To evaluate the contract layer before committing, you can start with Soda Core, an OSS CLI that enables you to write a YAML contract, run a scan against a sample dataset, and see what enforcement looks like in practice.
Frequently Asked Questions
Modern data systems are no longer just simple pipelines moving data from one database to another. Today’s data infrastructure is distributed across cloud platforms, streaming systems, warehouses, APIs, SaaS applications, and machine learning workflows.
Data moves all the time between producers and consumers, often across teams that operate independently from one another. As those systems scale, one problem appears almost everywhere: upstream changes break downstream systems more often than teams expect.
A producer renames a field. A data type changes quietly in production. A required value suddenly becomes nullable. A Kafka consumer starts failing to deserialize events. A dashboard begins showing incomplete numbers without anyone immediately noticing why.
This is the exact environment where conversations around data contracts and schema registries tend to emerge. The two concepts are closely related and often discussed together in event-driven architectures and modern data engineering workflows — but they aren’t interchangeable.
A schema registry manages and validates schema evolution across streaming systems. A data contract goes further: it defines how the data should behave, who owns it, and what downstream consumers can rely on.
Understanding the difference matters because these systems solve different layers of the same reliability problem.
Key Takeaways |
|---|
|
What Is a Schema Registry?
A schema registry manages message schemas for event-driven and streaming systems. The registry sits alongside the broker — Confluent Schema Registry next to Kafka, AWS Glue Schema Registry next to MSK, Apicurio in self-hosted setups — and ensures producers and consumers agree on message structure as data moves through the stream.
The registry stores schema versions in one place and validates compatibility whenever a schema evolves. The validation runs before the new version is allowed into production: if the change breaks the configured compatibility rule, the registry rejects the schema and the producer cannot publish.
For example, a producer may attempt to register a new version of an event schema. The registry checks if the change is backward-compatible, forward-compatible, or fully compatible with existing consumers. It allows the update only then.
In practice, the mode determines who has to move first: backward compatibility means new consumers can read old data, forward means old consumers can read new data, and full means both. Teams pick the mode based on which side of the producer-consumer relationship can deploy faster.
This is where the architectural enforcement lives. The registry isn’t a periodic scan or a separate validation step — it’s an inline gate in the streaming write path. A schema-incompatible message never enters the topic.
Schema registries are especially common in architectures built around:
Apache Kafka
Avro schemas
Protobuf
Event-driven microservices
Real-time data pipelines
What schema registries enforce is structural. A registered message conforms to a known shape, and schema evolution remains safe over time.
What they do not enforce, however, is whether the data inside the message is operationally correct — whether values make sense, whether records are complete, whether the event arrived when downstream consumers needed it.
What Are Data Contracts?
A data contract is an enforceable agreement between data producers and data consumers, expressed as executable checks in YAML. It defines what data should look like and how it should behave over time.
Contracts are typically co-authored — engineers own the technical shape, while business and governance define what the data should mean and who’s accountable when it breaks.
At a basic level, a contract may include schema definitions such as column names, data types, and required fields. But modern data contracts usually go further than schema alone.
Data contracts often define:
Quality expectations
Freshness requirements
Ownership and accountability
Allowed values and constraints
Service-level expectations
Change management rules
Each of these expectations is expressed as a check inside the contract.
A schema check validates that a dataset’s columns and types match what the contract declared.
A freshness check validates that data arrived by the expected time.
A missing or invalid check validates the values inside the records.
Together, the checks make the contract enforceable — the contract isn’t just a description of what should be true, it’s the set of executable assertions that prove it.
Here’s what that looks like for a clickstream event stream:
# Contract for event_data — a source-aligned clickstream # from a marketplace platform's event pipeline checks: - schema: allow_extra_columns: false allow_other_column_order: false - row_count: threshold: must_be_greater_than: 0 - freshness: column: ingest_time threshold: unit: hour must_be_less_than: 1 columns: - name: event_id data_type: string checks: - missing: - duplicate: - invalid: name: "Event ID length guardrail" valid_min_length: 1 valid_max_length: 128 - name: event_name data_type: string checks: - missing: - invalid: name: "Valid event names" valid_values: - job_viewed - apply_clicked - search_performed - name: ingest_time data_type: timestamp checks: - missing: # ... other columns: user_id, session_id, platform, entity_type, etc.
Adapted from Soda’s source-aligned event contract template.
This contract governs event_data, a clickstream landing table. The dataset checks enforce structure (schema rejects unknown or reordered columns), basic delivery (row_count > 0), and timeliness (freshness: ingest_time < 1 hour — a registry can’t enforce that). Each column adds value-level rules: event_id must be present, unique (duplicate), and within length bounds; event_name must be one of the approved values (valid_values).
Most data failures are not caused by catastrophic infrastructure outages. They happen when data technically arrives, but no longer behaves the way downstream systems expect. A table may still exist while containing incomplete records. A pipeline may continue running while silently introducing duplicate values. A schema may technically remain compatible while still violating downstream business assumptions.
Data contracts reduce those failures by making expectations explicit and enforceable. In practice, contracts are increasingly integrated directly into CI/CD pipelines — validated during deployment, tracked in version control with pipeline code, used to stop breaking changes from reaching production unnoticed.
Where Each Fits
With both concepts in place, the question becomes where each one actually belongs.
The architectural difference
Data contracts diverge architecturally from schema registries:
A contract’s schema check runs at scan time, against a landed dataset — a warehouse table, a lakehouse table, or the table that a streaming pipeline writes to. It sits at the read boundary.
A schema registry runs at publish time, against a streaming message, and blocks incompatible message schemas before they hit the topic. It sits at the write boundary.
Both enforce schema, but in different places, at different times, against different artifacts.
Schema registries: fit and limits
Schema registries fit where the streaming infrastructure has to enforce structure before data lands.
They’re particularly effective in architectures built around Kafka or event-driven microservices, where producers frequently publish new versions of messages while downstream services continue consuming older formats. Without compatibility enforcement, even small schema changes can cascade into failures across multiple systems.
A schema registry introduces centralized control over that evolution process. Registries are the right tool when teams need to:
Enforce compatibility rules at publish time
Prevent invalid schema deployments
Version schemas safely
Coordinate producer-consumer evolution
Reduce serialization failures in production
Where schema registries stop being enough is the moment the data lands. A schema-compatible event may still arrive late, contain low-quality values, or violate downstream assumptions in ways the registry cannot detect on its own.
Picture a payment event where the amount field is typed as a decimal and the currency field is typed as a string. A message arrives with amount: -4500.00 and currency: "ZZZ". The schema registry accepts both — the decimal is a decimal, the string is a string. But the business doesn’t allow negative payment amounts, and “ZZZ” isn’t a real currency code. Both fields type-check. Neither is operationally correct.
That’s the boundary registries can’t cross. They protect systems from breaking structurally, but they don’t ensure that data remains trustworthy, usable, or aligned with operational reality once it enters the broader ecosystem.
Data contracts: fit and limits
Data contracts fit where multiple teams depend on shared datasets across analytics, reporting, and operational systems.
Take an analytics engineering team running a customer table that powers dashboards, forecasting models, and downstream business intelligence workflows. The team needs more than structural validation — they need confidence that the data remains usable, reliable, and predictable over time. That’s the gap data contracts close.
Contracts are the right tool when teams need to define:
Freshness expectations
Completeness rules
Valid business values
SLA requirements
Ownership
Change approval workflows
Contracts are especially useful across ETL pipelines, data warehouses, data lakes, batch and streaming systems, and cross-functional analytics teams managing shared business-critical datasets.
Where data contracts have limits is the cost side. Authoring contracts manually takes engineering effort, and the discipline only pays off when teams commit to ownership — without a clear owner, a contract drifts out of sync with the dataset it’s supposed to govern.
For low-stakes datasets owned by a single team that already has tight CI/CD on the producer — dbt tests gating every merge, or Pydantic validation in the producer service — a contract can be more overhead than benefit. The judgment call is whether the dataset is shared widely enough, and changes frequently enough, that explicit producer-consumer expectations earn their keep.
The decision rule
If the failure mode you’re worried about happens at the broker, you need a schema registry; if it happens after the data has landed, you need a data contract; if both, you need both.
Why Mature Teams Often Use Both
In practice, mature data organizations rarely treat schema registries and data contracts as competing solutions. They solve different layers of the reliability problem.
A schema registry helps ensure events remain structurally compatible as schemas evolve — enforcement happens inline, at publish time, in the streaming infrastructure. A data contract defines broader expectations around quality, ownership, reliability, and downstream usability — enforcement happens at scan time, against landed datasets. One protects the write path. The other protects the read path. As data systems grow more distributed, both matter.
A streaming platform may successfully process millions of events per hour while downstream analytics systems quietly degrade because freshness expectations were violated or business logic changed unexpectedly. Schema compatibility alone does not guarantee operational reliability.
This is why many modern teams combine multiple layers of protection:
Schema registries for structural governance at the streaming edge
Data contracts for operational expectations across producers and consumers
Observability for runtime visibility into what actually shipped
Testing for automated validation in CI/CD
Most teams assemble this stack from separate vendors. Soda combines data contracts and data observability on one platform, so the structural layer and the operational layer share the same checks, the same ownership, and the same alerts — collapsing the coordination cost of treating reliability as four separate disciplines.
Contract coverage at scale is the next problem. Writing and maintaining contracts manually across hundreds of datasets becomes intractable for large data teams. Soda’s answer is a three-part contract layer: engineers hand-author contracts for the datasets that matter most, Contract Autopilot generates coverage for the long tail from observed data patterns and Soda AI’s profiling, and data observability catches what slips through at runtime.
To evaluate the contract layer before committing, you can start with Soda Core, an OSS CLI that enables you to write a YAML contract, run a scan against a sample dataset, and see what enforcement looks like in practice.
Frequently Asked Questions
Modern data systems are no longer just simple pipelines moving data from one database to another. Today’s data infrastructure is distributed across cloud platforms, streaming systems, warehouses, APIs, SaaS applications, and machine learning workflows.
Data moves all the time between producers and consumers, often across teams that operate independently from one another. As those systems scale, one problem appears almost everywhere: upstream changes break downstream systems more often than teams expect.
A producer renames a field. A data type changes quietly in production. A required value suddenly becomes nullable. A Kafka consumer starts failing to deserialize events. A dashboard begins showing incomplete numbers without anyone immediately noticing why.
This is the exact environment where conversations around data contracts and schema registries tend to emerge. The two concepts are closely related and often discussed together in event-driven architectures and modern data engineering workflows — but they aren’t interchangeable.
A schema registry manages and validates schema evolution across streaming systems. A data contract goes further: it defines how the data should behave, who owns it, and what downstream consumers can rely on.
Understanding the difference matters because these systems solve different layers of the same reliability problem.
Key Takeaways |
|---|
|
What Is a Schema Registry?
A schema registry manages message schemas for event-driven and streaming systems. The registry sits alongside the broker — Confluent Schema Registry next to Kafka, AWS Glue Schema Registry next to MSK, Apicurio in self-hosted setups — and ensures producers and consumers agree on message structure as data moves through the stream.
The registry stores schema versions in one place and validates compatibility whenever a schema evolves. The validation runs before the new version is allowed into production: if the change breaks the configured compatibility rule, the registry rejects the schema and the producer cannot publish.
For example, a producer may attempt to register a new version of an event schema. The registry checks if the change is backward-compatible, forward-compatible, or fully compatible with existing consumers. It allows the update only then.
In practice, the mode determines who has to move first: backward compatibility means new consumers can read old data, forward means old consumers can read new data, and full means both. Teams pick the mode based on which side of the producer-consumer relationship can deploy faster.
This is where the architectural enforcement lives. The registry isn’t a periodic scan or a separate validation step — it’s an inline gate in the streaming write path. A schema-incompatible message never enters the topic.
Schema registries are especially common in architectures built around:
Apache Kafka
Avro schemas
Protobuf
Event-driven microservices
Real-time data pipelines
What schema registries enforce is structural. A registered message conforms to a known shape, and schema evolution remains safe over time.
What they do not enforce, however, is whether the data inside the message is operationally correct — whether values make sense, whether records are complete, whether the event arrived when downstream consumers needed it.
What Are Data Contracts?
A data contract is an enforceable agreement between data producers and data consumers, expressed as executable checks in YAML. It defines what data should look like and how it should behave over time.
Contracts are typically co-authored — engineers own the technical shape, while business and governance define what the data should mean and who’s accountable when it breaks.
At a basic level, a contract may include schema definitions such as column names, data types, and required fields. But modern data contracts usually go further than schema alone.
Data contracts often define:
Quality expectations
Freshness requirements
Ownership and accountability
Allowed values and constraints
Service-level expectations
Change management rules
Each of these expectations is expressed as a check inside the contract.
A schema check validates that a dataset’s columns and types match what the contract declared.
A freshness check validates that data arrived by the expected time.
A missing or invalid check validates the values inside the records.
Together, the checks make the contract enforceable — the contract isn’t just a description of what should be true, it’s the set of executable assertions that prove it.
Here’s what that looks like for a clickstream event stream:
# Contract for event_data — a source-aligned clickstream # from a marketplace platform's event pipeline checks: - schema: allow_extra_columns: false allow_other_column_order: false - row_count: threshold: must_be_greater_than: 0 - freshness: column: ingest_time threshold: unit: hour must_be_less_than: 1 columns: - name: event_id data_type: string checks: - missing: - duplicate: - invalid: name: "Event ID length guardrail" valid_min_length: 1 valid_max_length: 128 - name: event_name data_type: string checks: - missing: - invalid: name: "Valid event names" valid_values: - job_viewed - apply_clicked - search_performed - name: ingest_time data_type: timestamp checks: - missing: # ... other columns: user_id, session_id, platform, entity_type, etc.
Adapted from Soda’s source-aligned event contract template.
This contract governs event_data, a clickstream landing table. The dataset checks enforce structure (schema rejects unknown or reordered columns), basic delivery (row_count > 0), and timeliness (freshness: ingest_time < 1 hour — a registry can’t enforce that). Each column adds value-level rules: event_id must be present, unique (duplicate), and within length bounds; event_name must be one of the approved values (valid_values).
Most data failures are not caused by catastrophic infrastructure outages. They happen when data technically arrives, but no longer behaves the way downstream systems expect. A table may still exist while containing incomplete records. A pipeline may continue running while silently introducing duplicate values. A schema may technically remain compatible while still violating downstream business assumptions.
Data contracts reduce those failures by making expectations explicit and enforceable. In practice, contracts are increasingly integrated directly into CI/CD pipelines — validated during deployment, tracked in version control with pipeline code, used to stop breaking changes from reaching production unnoticed.
Where Each Fits
With both concepts in place, the question becomes where each one actually belongs.
The architectural difference
Data contracts diverge architecturally from schema registries:
A contract’s schema check runs at scan time, against a landed dataset — a warehouse table, a lakehouse table, or the table that a streaming pipeline writes to. It sits at the read boundary.
A schema registry runs at publish time, against a streaming message, and blocks incompatible message schemas before they hit the topic. It sits at the write boundary.
Both enforce schema, but in different places, at different times, against different artifacts.
Schema registries: fit and limits
Schema registries fit where the streaming infrastructure has to enforce structure before data lands.
They’re particularly effective in architectures built around Kafka or event-driven microservices, where producers frequently publish new versions of messages while downstream services continue consuming older formats. Without compatibility enforcement, even small schema changes can cascade into failures across multiple systems.
A schema registry introduces centralized control over that evolution process. Registries are the right tool when teams need to:
Enforce compatibility rules at publish time
Prevent invalid schema deployments
Version schemas safely
Coordinate producer-consumer evolution
Reduce serialization failures in production
Where schema registries stop being enough is the moment the data lands. A schema-compatible event may still arrive late, contain low-quality values, or violate downstream assumptions in ways the registry cannot detect on its own.
Picture a payment event where the amount field is typed as a decimal and the currency field is typed as a string. A message arrives with amount: -4500.00 and currency: "ZZZ". The schema registry accepts both — the decimal is a decimal, the string is a string. But the business doesn’t allow negative payment amounts, and “ZZZ” isn’t a real currency code. Both fields type-check. Neither is operationally correct.
That’s the boundary registries can’t cross. They protect systems from breaking structurally, but they don’t ensure that data remains trustworthy, usable, or aligned with operational reality once it enters the broader ecosystem.
Data contracts: fit and limits
Data contracts fit where multiple teams depend on shared datasets across analytics, reporting, and operational systems.
Take an analytics engineering team running a customer table that powers dashboards, forecasting models, and downstream business intelligence workflows. The team needs more than structural validation — they need confidence that the data remains usable, reliable, and predictable over time. That’s the gap data contracts close.
Contracts are the right tool when teams need to define:
Freshness expectations
Completeness rules
Valid business values
SLA requirements
Ownership
Change approval workflows
Contracts are especially useful across ETL pipelines, data warehouses, data lakes, batch and streaming systems, and cross-functional analytics teams managing shared business-critical datasets.
Where data contracts have limits is the cost side. Authoring contracts manually takes engineering effort, and the discipline only pays off when teams commit to ownership — without a clear owner, a contract drifts out of sync with the dataset it’s supposed to govern.
For low-stakes datasets owned by a single team that already has tight CI/CD on the producer — dbt tests gating every merge, or Pydantic validation in the producer service — a contract can be more overhead than benefit. The judgment call is whether the dataset is shared widely enough, and changes frequently enough, that explicit producer-consumer expectations earn their keep.
The decision rule
If the failure mode you’re worried about happens at the broker, you need a schema registry; if it happens after the data has landed, you need a data contract; if both, you need both.
Why Mature Teams Often Use Both
In practice, mature data organizations rarely treat schema registries and data contracts as competing solutions. They solve different layers of the reliability problem.
A schema registry helps ensure events remain structurally compatible as schemas evolve — enforcement happens inline, at publish time, in the streaming infrastructure. A data contract defines broader expectations around quality, ownership, reliability, and downstream usability — enforcement happens at scan time, against landed datasets. One protects the write path. The other protects the read path. As data systems grow more distributed, both matter.
A streaming platform may successfully process millions of events per hour while downstream analytics systems quietly degrade because freshness expectations were violated or business logic changed unexpectedly. Schema compatibility alone does not guarantee operational reliability.
This is why many modern teams combine multiple layers of protection:
Schema registries for structural governance at the streaming edge
Data contracts for operational expectations across producers and consumers
Observability for runtime visibility into what actually shipped
Testing for automated validation in CI/CD
Most teams assemble this stack from separate vendors. Soda combines data contracts and data observability on one platform, so the structural layer and the operational layer share the same checks, the same ownership, and the same alerts — collapsing the coordination cost of treating reliability as four separate disciplines.
Contract coverage at scale is the next problem. Writing and maintaining contracts manually across hundreds of datasets becomes intractable for large data teams. Soda’s answer is a three-part contract layer: engineers hand-author contracts for the datasets that matter most, Contract Autopilot generates coverage for the long tail from observed data patterns and Soda AI’s profiling, and data observability catches what slips through at runtime.
To evaluate the contract layer before committing, you can start with Soda Core, an OSS CLI that enables you to write a YAML contract, run a scan against a sample dataset, and see what enforcement looks like in practice.
Frequently Asked Questions
What is the difference between a data contract and a schema registry?
A schema registry manages schema evolution and compatibility in streaming systems like Kafka. A data contract is a formal agreement that defines broader expectations around reliability, ownership, and quality across data producers and consumers.
Do data contracts replace schema registries?
No. Schema registries handle structural compatibility, while data contracts define operational expectations between data producers and consumers, including quality and usage rules.
When should teams use a schema registry?
Use schema registries in event-driven systems where data producers and consumers exchange structured data using formats like Avro, JSON Schema, or Protobuf, and need controlled schema versioning.
Can data contracts work with Kafka?
Yes. Data contracts complement Kafka setups by adding governance on top of whichever schema registry the team runs — Confluent Schema Registry, AWS Glue Schema Registry, Apicurio — extending enforcement from message structure to data quality, freshness, and ownership.
Are data contracts only for streaming systems?
No. They are used across data platforms like ETL pipelines and data warehouses, especially when managing data products that require reliability across multiple consumers.
What role does schema evolution play in data contracts?
In a schema registry, evolution is governed by a compatibility mode — backward, forward, or full — that gates which schema changes are allowed to publish. In a data contract, evolution is governed by the schema check (which fields are required, which types are allowed) plus a change approval workflow that defines who can change the contract and when downstream consumers need to be notified. Registries handle the message-level mechanics. Contracts handle the producer-consumer agreement.
Trusted by the world’s leading enterprises
Real stories from companies using Soda to keep their data reliable, accurate, and ready for action.
At the end of the day, we don’t want to be in there managing the checks, updating the checks, adding the checks. We just want to go and observe what’s happening, and that’s what Soda is enabling right now.

Sid Srivastava
Director of Data Governance, Quality and MLOps
Investing in data quality is key for cross-functional teams to make accurate, complete decisions with fewer risks and greater returns, using initiatives such as product thinking, data governance, and self-service platforms.

Mario Konschake
Director of Product-Data Platform
Soda has integrated seamlessly into our technology stack and given us the confidence to find, analyze, implement, and resolve data issues through a simple self-serve capability.

Sutaraj Dutta
Data Engineering Manager
Our goal was to deliver high-quality datasets in near real-time, ensuring dashboards reflect live data as it flows in. But beyond solving technical challenges, we wanted to spark a cultural shift - empowering the entire organization to make decisions grounded in accurate, timely data.

Gu Xie
Head of Data Engineering
4,4 sur 5
Commencez à faire confiance à vos données. Aujourd'hui.
Trouvez, comprenez et corrigez tout problème de qualité des données en quelques secondes.
Du niveau de la table au niveau des enregistrements.
Adopté par
Product








Trusted by the world’s leading enterprises
Real stories from companies using Soda to keep their data reliable, accurate, and ready for action.
At the end of the day, we don’t want to be in there managing the checks, updating the checks, adding the checks. We just want to go and observe what’s happening, and that’s what Soda is enabling right now.
Sid Srivastava
Director of Data Governance, Quality and MLOps
Investing in data quality is key for cross-functional teams to make accurate, complete decisions with fewer risks and greater returns, using initiatives such as product thinking, data governance, and self-service platforms.
Mario Konschake
Director of Product-Data Platform
Soda has integrated seamlessly into our technology stack and given us the confidence to find, analyze, implement, and resolve data issues through a simple self-serve capability.
Sutaraj Dutta
Data Engineering Manager
Our goal was to deliver high-quality datasets in near real-time, ensuring dashboards reflect live data as it flows in. But beyond solving technical challenges, we wanted to spark a cultural shift - empowering the entire organization to make decisions grounded in accurate, timely data.
Gu Xie
Head of Data Engineering
4,4 sur 5
Commencez à faire confiance à vos données. Aujourd'hui.
Trouvez, comprenez et corrigez tout problème de qualité des données en quelques secondes.
Du niveau de la table au niveau des enregistrements.
Adopté par
Product
Solutions
Trusted by the world’s leading enterprises
Real stories from companies using Soda to keep their data reliable, accurate, and ready for action.
At the end of the day, we don’t want to be in there managing the checks, updating the checks, adding the checks. We just want to go and observe what’s happening, and that’s what Soda is enabling right now.
Sid Srivastava
Director of Data Governance, Quality and MLOps
Investing in data quality is key for cross-functional teams to make accurate, complete decisions with fewer risks and greater returns, using initiatives such as product thinking, data governance, and self-service platforms.
Mario Konschake
Director of Product-Data Platform
Soda has integrated seamlessly into our technology stack and given us the confidence to find, analyze, implement, and resolve data issues through a simple self-serve capability.
Sutaraj Dutta
Data Engineering Manager
Our goal was to deliver high-quality datasets in near real-time, ensuring dashboards reflect live data as it flows in. But beyond solving technical challenges, we wanted to spark a cultural shift - empowering the entire organization to make decisions grounded in accurate, timely data.
Gu Xie
Head of Data Engineering
4,4 sur 5
Commencez à faire confiance à vos données. Aujourd'hui.
Trouvez, comprenez et corrigez tout problème de qualité des données en quelques secondes.
Du niveau de la table au niveau des enregistrements.
Adopté par
Product
Solutions
Company