Why YAML Is the Best Syntax for Data Quality Checks
Why YAML Is the Best Syntax for Data Quality Checks
Why YAML Is the Best Syntax for Data Quality Checks

Tom Baeyens
Tom Baeyens
CTO et co-fondateur chez Soda
CTO et co-fondateur chez Soda
Table des matières
Precisely’s 2025 State of Data Integrity survey (conducted with Drexel University’s LeBow College of Business) found that 77% of organizations rate their data quality as average or worse, and 67% don’t fully trust the data they use for decision-making. When asked why, 49% pointed to the same root cause: inadequate tools to automate data quality processes.
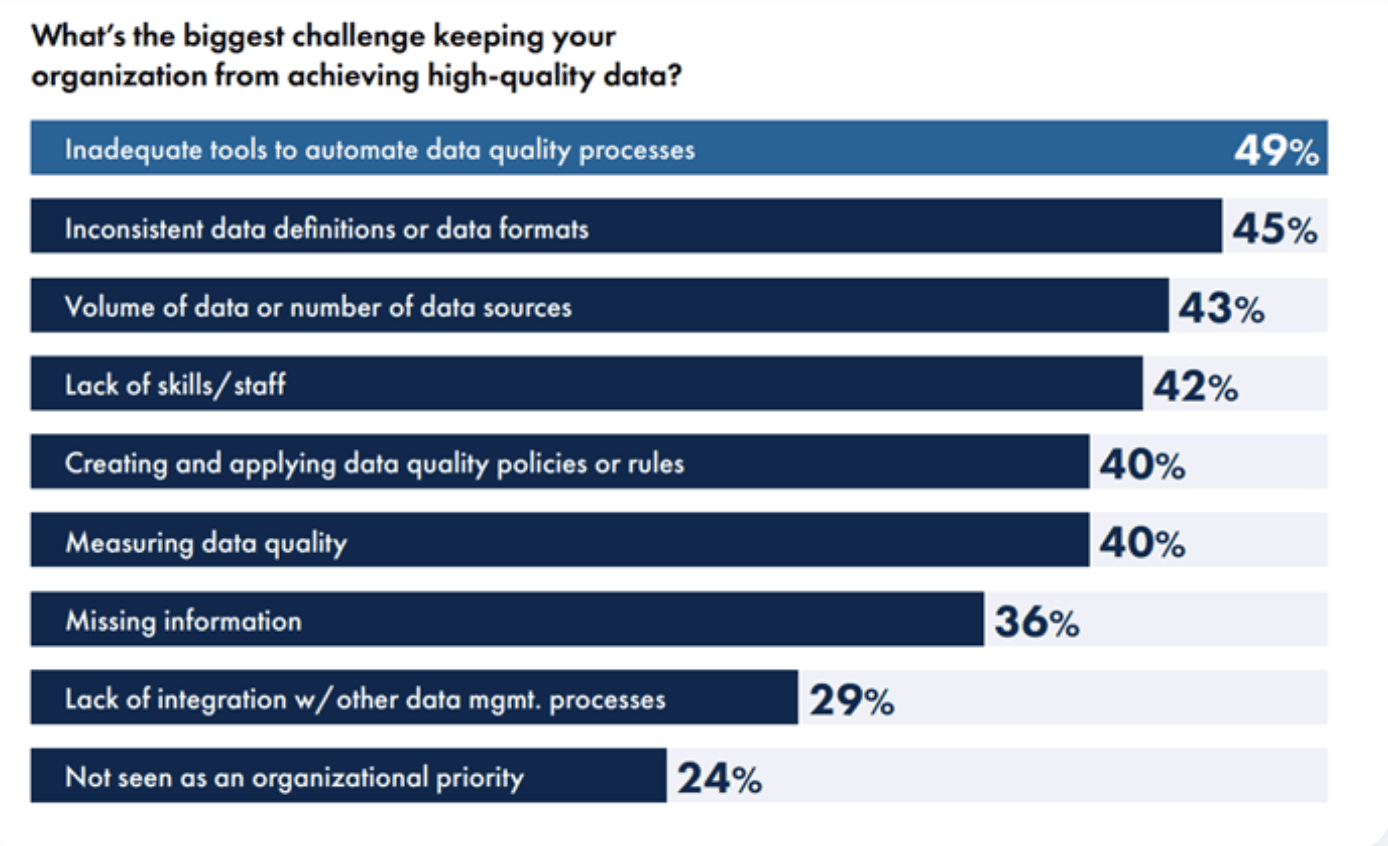
The people who understand the data best — governance leads, analysts, domain experts — still can’t define what “good data” means without filing a ticket and waiting for an engineer to write the check. The checks aren’t getting written fast enough because the interface excludes most of the people who know what to check.
This isn’t a tooling gap. It’s a syntax gap. YAML is the right foundation for data quality checks — not because it’s fashionable, but because it determines who gets to participate.
The Conventional Wisdom: Just Use Python
The default assumption in data engineering is that Python is the right language for everything. And for a lot of things, that’s true. Python is expressive, flexible, and every data engineer already knows it.
That logic extends to data quality. Tools built on Python let you write arbitrarily complex validations, chain logic, build custom statistical tests, and plug into any framework. If you can code it, you can check it.
There are good reasons this became the norm. Data quality started as an engineering problem — engineers built the pipelines, so engineers built the tests. Python was already there, so Python became the language of data testing.
The problem is that this approach bakes in an assumption that hasn’t been true for years: that data quality is an engineering-only concern.
Why That’s Wrong
Data quality is everyone’s problem.
The data engineer who built the pipeline doesn’t know that the region_code column switched from ISO-2 to ISO-3 last quarter. The governance lead does. The analyst who noticed that revenue numbers stopped making sense on March 15th has the context the pipeline author lacks.
Those people usually can’t write production Python. But they can read and edit a YAML file.
When your data quality syntax requires programming expertise, you get a bottleneck:
Business users spot the problem. They know the data semantics, they see when numbers look wrong, they understand domain rules that no schema can capture.
They file a ticket or send an email: “Hey, can someone add a check for X?”
It sits in a backlog. The data engineering team has pipeline work, migrations, incident response.
The check either never gets written or arrives weeks later. By that point, the bad data has already caused damage downstream.
This is the same anti-pattern that software engineering eliminated twenty years ago. When only specialists can define tests, testing becomes a bottleneck. The fix wasn’t better specialists. It was better interfaces.
What Actually Works: Declarative Checks as a Shared Language
YAML doesn’t make data quality better because of some inherent property of the format. It works because it shifts the interface for defining quality from imperative code to declarative specifications.
Here’s a null check using a typical Python-first data quality framework:
import dq_framework as dq context = dq.get_context() datasource = context.sources.add_pandas("my_datasource") data_asset = datasource.add_dataframe_asset(name="my_data") batch_request = data_asset.build_batch_request(dataframe=df) validator = context.get_validator(batch_request=batch_request) validator.expect_column_values_to_not_be_null( column="email", mostly=0.95 ) result = validator.validate()
And the same check in YAML (SodaCL):
checks for orders
That’s it. One line. A governance lead can read it. A business analyst can propose a change to it in a pull request. A data engineer can review and merge it in thirty seconds.
This isn’t about YAML being “simpler” in some vague sense. It’s about three specific properties:
Declarative over imperative. YAML checks describe what good data looks like, not how to verify it. row_count > 0 reads like a specification, not a program. That’s the difference between a contract and an implementation.
Version-controlled collaboration. YAML files live in Git. Producers and consumers edit the same file. Changes go through pull requests, not email threads. This is the workflow that transformed software engineering (code review, CI/CD, automated testing) — and it works for data quality too.
Machine-readable by default. YAML slots directly into CI/CD pipelines. No wrapper scripts, no custom runners. A CLI tool parses the file, runs the checks, and returns pass/fail. That’s a circuit breaker you can drop into Airflow, GitHub Actions, or any orchestrator.
(If this sounds like the same argument for Infrastructure as Code, that’s because it is. We already proved that declarative YAML configs beat imperative scripts for managing infrastructure. Data quality is the same pattern.)
Data Contracts: Where YAML Really Shines
Data contracts are formalized agreements between data producers and consumers: what the schema looks like, what quality rules apply, who owns it, and what the SLAs are.
YAML is the dominant format for contract specifications — the Open Data Contract Standard uses it, Soda’s contract engine uses it, dbt uses it. And there’s a reason: contracts are documents that both humans and machines need to read.
A data contract written in Python is code that happens to encode agreements. A data contract written in YAML is the agreement — readable by the governance lead who defined the SLA, the engineer who implements the pipeline, and the CI/CD system that enforces it.
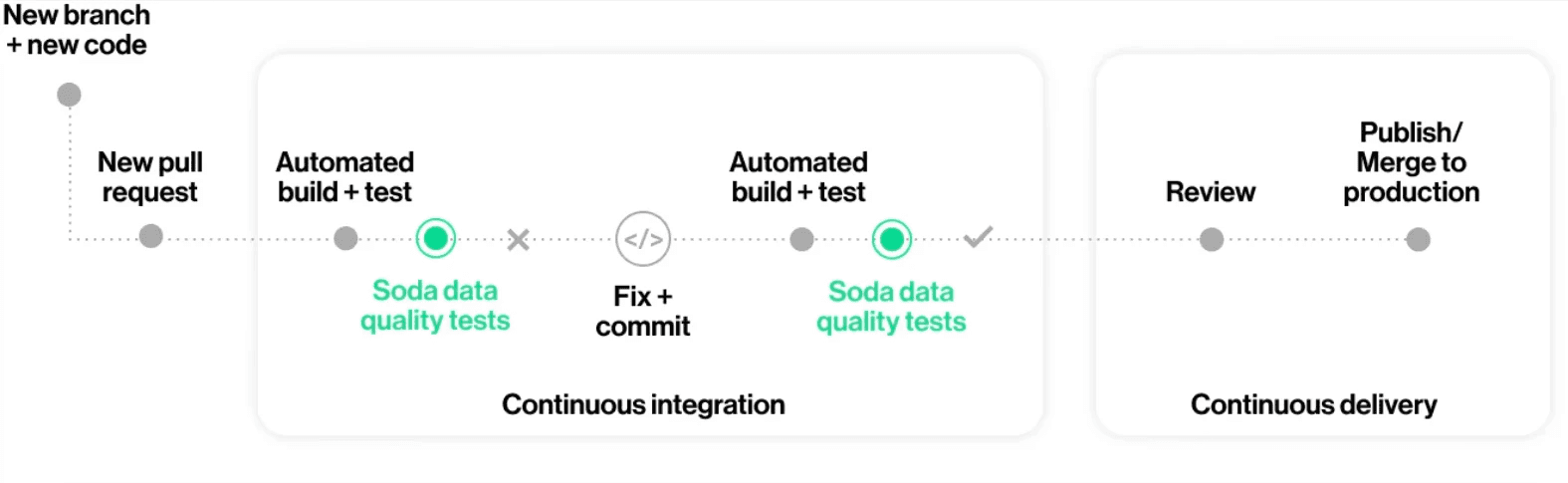
The real power is in the workflow that YAML enables. Instead of data producers and consumers arguing over email about what “valid data” means, they collaborate on a YAML file:
The consumer proposes a contract (or modifies an existing one) via a pull request
The producer reviews it — “We can guarantee
freshness < 1hbut not< 15min“They negotiate in the PR comments, update the YAML, and merge
CI/CD enforces the contract automatically on every pipeline run
That’s governance packaged as engineering. No meetings. No Confluence pages that go stale. The contract is living, versioned, and enforced.
This is exactly how Make, the AI automation platform, shifted data quality left with data contracts in their Airflow pipelines.
When Python Still Makes Sense
I’m not arguing that YAML replaces Python entirely. For about 20% of data quality checks, you genuinely need programmatic logic:
Statistical tests: Distribution comparisons, outlier detection with custom thresholds, seasonality-aware anomaly detection.
Cross-dataset validations: Reconciliation checks that join across sources with complex matching logic.
ML-based quality: Pattern recognition that goes beyond rule-based checks.
For these cases, Python (or SQL) is the right tool. The better approach isn’t YAML or Python. It’s YAML as the primary interface for the 80% of checks that are standard (nulls, schema, freshness, row counts, uniqueness), with Python available for the remaining 20%.
The hybrid model works. Most data quality issues aren’t exotic. They’re a column that went null, a schema that changed without warning, a freshness SLA that was missed. YAML handles all of those without asking anyone to learn a programming language.
How to Start: From Email Threads to Pull Requests
If you’re running data quality checks in Python today, you don’t need to rewrite everything. Start here:
Audit your existing checks (~1 hour). List every quality rule your team enforces, including the informal ones hiding in Slack messages and email threads. Most teams are surprised by how many rules exist outside of code.
Translate the top 20 into YAML (~half a day). Pick the checks that are standard validations: nulls, schema, row counts, freshness, uniqueness. These translate directly to declarative syntax.
Integrate into your pipeline (~2 hours). Drop the YAML checks into your CI/CD workflow. Soda Core, dbt tests, or any YAML-based tool can parse them as quality gates.
Invite your non-engineering stakeholders (~ongoing). This is the step most teams skip. Share the YAML file with your governance lead, your business analyst, your data consumers. Show them how to propose a new check via a pull request. The first time a business user submits a PR that catches a data issue before it hits production, the value of this approach becomes obvious.
The Honest Caveats
YAML has real limitations. It doesn’t support conditional logic, it can’t express complex statistical tests, and deeply nested YAML files become harder to read than the Python they replaced. If your quality checks require significant computation or cross-system orchestration, a declarative config file won’t cut it.
There’s also the “YAML isn’t unique” objection — you could get the same readability from TOML, JSON with comments, or a custom DSL. That’s true in theory. In practice, YAML has the ecosystem: every CI/CD tool parses it, every developer has encountered it, and the major data quality frameworks have already standardized on it. Switching costs matter.
The syntax you choose for data quality isn’t a technical detail. It’s an organizational decision that determines who gets to participate in defining what “good data” means.
Python keeps that power with engineers. YAML distributes it across the organization.
Data quality is too important to be an engineering-only concern. The best syntax is the one that brings everyone to the table.
Check out Soda Contracts Language to see what YAML-based data quality checks look like in practice, or come discuss this in our Slack community.
Frequently Asked Questions
Precisely’s 2025 State of Data Integrity survey (conducted with Drexel University’s LeBow College of Business) found that 77% of organizations rate their data quality as average or worse, and 67% don’t fully trust the data they use for decision-making. When asked why, 49% pointed to the same root cause: inadequate tools to automate data quality processes.
The people who understand the data best — governance leads, analysts, domain experts — still can’t define what “good data” means without filing a ticket and waiting for an engineer to write the check. The checks aren’t getting written fast enough because the interface excludes most of the people who know what to check.
This isn’t a tooling gap. It’s a syntax gap. YAML is the right foundation for data quality checks — not because it’s fashionable, but because it determines who gets to participate.
The Conventional Wisdom: Just Use Python
The default assumption in data engineering is that Python is the right language for everything. And for a lot of things, that’s true. Python is expressive, flexible, and every data engineer already knows it.
That logic extends to data quality. Tools built on Python let you write arbitrarily complex validations, chain logic, build custom statistical tests, and plug into any framework. If you can code it, you can check it.
There are good reasons this became the norm. Data quality started as an engineering problem — engineers built the pipelines, so engineers built the tests. Python was already there, so Python became the language of data testing.
The problem is that this approach bakes in an assumption that hasn’t been true for years: that data quality is an engineering-only concern.
Why That’s Wrong
Data quality is everyone’s problem.
The data engineer who built the pipeline doesn’t know that the region_code column switched from ISO-2 to ISO-3 last quarter. The governance lead does. The analyst who noticed that revenue numbers stopped making sense on March 15th has the context the pipeline author lacks.
Those people usually can’t write production Python. But they can read and edit a YAML file.
When your data quality syntax requires programming expertise, you get a bottleneck:
Business users spot the problem. They know the data semantics, they see when numbers look wrong, they understand domain rules that no schema can capture.
They file a ticket or send an email: “Hey, can someone add a check for X?”
It sits in a backlog. The data engineering team has pipeline work, migrations, incident response.
The check either never gets written or arrives weeks later. By that point, the bad data has already caused damage downstream.
This is the same anti-pattern that software engineering eliminated twenty years ago. When only specialists can define tests, testing becomes a bottleneck. The fix wasn’t better specialists. It was better interfaces.
What Actually Works: Declarative Checks as a Shared Language
YAML doesn’t make data quality better because of some inherent property of the format. It works because it shifts the interface for defining quality from imperative code to declarative specifications.
Here’s a null check using a typical Python-first data quality framework:
import dq_framework as dq context = dq.get_context() datasource = context.sources.add_pandas("my_datasource") data_asset = datasource.add_dataframe_asset(name="my_data") batch_request = data_asset.build_batch_request(dataframe=df) validator = context.get_validator(batch_request=batch_request) validator.expect_column_values_to_not_be_null( column="email", mostly=0.95 ) result = validator.validate()
And the same check in YAML (SodaCL):
checks for orders
That’s it. One line. A governance lead can read it. A business analyst can propose a change to it in a pull request. A data engineer can review and merge it in thirty seconds.
This isn’t about YAML being “simpler” in some vague sense. It’s about three specific properties:
Declarative over imperative. YAML checks describe what good data looks like, not how to verify it. row_count > 0 reads like a specification, not a program. That’s the difference between a contract and an implementation.
Version-controlled collaboration. YAML files live in Git. Producers and consumers edit the same file. Changes go through pull requests, not email threads. This is the workflow that transformed software engineering (code review, CI/CD, automated testing) — and it works for data quality too.
Machine-readable by default. YAML slots directly into CI/CD pipelines. No wrapper scripts, no custom runners. A CLI tool parses the file, runs the checks, and returns pass/fail. That’s a circuit breaker you can drop into Airflow, GitHub Actions, or any orchestrator.
(If this sounds like the same argument for Infrastructure as Code, that’s because it is. We already proved that declarative YAML configs beat imperative scripts for managing infrastructure. Data quality is the same pattern.)
Data Contracts: Where YAML Really Shines
Data contracts are formalized agreements between data producers and consumers: what the schema looks like, what quality rules apply, who owns it, and what the SLAs are.
YAML is the dominant format for contract specifications — the Open Data Contract Standard uses it, Soda’s contract engine uses it, dbt uses it. And there’s a reason: contracts are documents that both humans and machines need to read.
A data contract written in Python is code that happens to encode agreements. A data contract written in YAML is the agreement — readable by the governance lead who defined the SLA, the engineer who implements the pipeline, and the CI/CD system that enforces it.
The real power is in the workflow that YAML enables. Instead of data producers and consumers arguing over email about what “valid data” means, they collaborate on a YAML file:
The consumer proposes a contract (or modifies an existing one) via a pull request
The producer reviews it — “We can guarantee
freshness < 1hbut not< 15min“They negotiate in the PR comments, update the YAML, and merge
CI/CD enforces the contract automatically on every pipeline run
That’s governance packaged as engineering. No meetings. No Confluence pages that go stale. The contract is living, versioned, and enforced.
This is exactly how Make, the AI automation platform, shifted data quality left with data contracts in their Airflow pipelines.
When Python Still Makes Sense
I’m not arguing that YAML replaces Python entirely. For about 20% of data quality checks, you genuinely need programmatic logic:
Statistical tests: Distribution comparisons, outlier detection with custom thresholds, seasonality-aware anomaly detection.
Cross-dataset validations: Reconciliation checks that join across sources with complex matching logic.
ML-based quality: Pattern recognition that goes beyond rule-based checks.
For these cases, Python (or SQL) is the right tool. The better approach isn’t YAML or Python. It’s YAML as the primary interface for the 80% of checks that are standard (nulls, schema, freshness, row counts, uniqueness), with Python available for the remaining 20%.
The hybrid model works. Most data quality issues aren’t exotic. They’re a column that went null, a schema that changed without warning, a freshness SLA that was missed. YAML handles all of those without asking anyone to learn a programming language.
How to Start: From Email Threads to Pull Requests
If you’re running data quality checks in Python today, you don’t need to rewrite everything. Start here:
Audit your existing checks (~1 hour). List every quality rule your team enforces, including the informal ones hiding in Slack messages and email threads. Most teams are surprised by how many rules exist outside of code.
Translate the top 20 into YAML (~half a day). Pick the checks that are standard validations: nulls, schema, row counts, freshness, uniqueness. These translate directly to declarative syntax.
Integrate into your pipeline (~2 hours). Drop the YAML checks into your CI/CD workflow. Soda Core, dbt tests, or any YAML-based tool can parse them as quality gates.
Invite your non-engineering stakeholders (~ongoing). This is the step most teams skip. Share the YAML file with your governance lead, your business analyst, your data consumers. Show them how to propose a new check via a pull request. The first time a business user submits a PR that catches a data issue before it hits production, the value of this approach becomes obvious.
The Honest Caveats
YAML has real limitations. It doesn’t support conditional logic, it can’t express complex statistical tests, and deeply nested YAML files become harder to read than the Python they replaced. If your quality checks require significant computation or cross-system orchestration, a declarative config file won’t cut it.
There’s also the “YAML isn’t unique” objection — you could get the same readability from TOML, JSON with comments, or a custom DSL. That’s true in theory. In practice, YAML has the ecosystem: every CI/CD tool parses it, every developer has encountered it, and the major data quality frameworks have already standardized on it. Switching costs matter.
The syntax you choose for data quality isn’t a technical detail. It’s an organizational decision that determines who gets to participate in defining what “good data” means.
Python keeps that power with engineers. YAML distributes it across the organization.
Data quality is too important to be an engineering-only concern. The best syntax is the one that brings everyone to the table.
Check out Soda Contracts Language to see what YAML-based data quality checks look like in practice, or come discuss this in our Slack community.
Frequently Asked Questions
Precisely’s 2025 State of Data Integrity survey (conducted with Drexel University’s LeBow College of Business) found that 77% of organizations rate their data quality as average or worse, and 67% don’t fully trust the data they use for decision-making. When asked why, 49% pointed to the same root cause: inadequate tools to automate data quality processes.
The people who understand the data best — governance leads, analysts, domain experts — still can’t define what “good data” means without filing a ticket and waiting for an engineer to write the check. The checks aren’t getting written fast enough because the interface excludes most of the people who know what to check.
This isn’t a tooling gap. It’s a syntax gap. YAML is the right foundation for data quality checks — not because it’s fashionable, but because it determines who gets to participate.
The Conventional Wisdom: Just Use Python
The default assumption in data engineering is that Python is the right language for everything. And for a lot of things, that’s true. Python is expressive, flexible, and every data engineer already knows it.
That logic extends to data quality. Tools built on Python let you write arbitrarily complex validations, chain logic, build custom statistical tests, and plug into any framework. If you can code it, you can check it.
There are good reasons this became the norm. Data quality started as an engineering problem — engineers built the pipelines, so engineers built the tests. Python was already there, so Python became the language of data testing.
The problem is that this approach bakes in an assumption that hasn’t been true for years: that data quality is an engineering-only concern.
Why That’s Wrong
Data quality is everyone’s problem.
The data engineer who built the pipeline doesn’t know that the region_code column switched from ISO-2 to ISO-3 last quarter. The governance lead does. The analyst who noticed that revenue numbers stopped making sense on March 15th has the context the pipeline author lacks.
Those people usually can’t write production Python. But they can read and edit a YAML file.
When your data quality syntax requires programming expertise, you get a bottleneck:
Business users spot the problem. They know the data semantics, they see when numbers look wrong, they understand domain rules that no schema can capture.
They file a ticket or send an email: “Hey, can someone add a check for X?”
It sits in a backlog. The data engineering team has pipeline work, migrations, incident response.
The check either never gets written or arrives weeks later. By that point, the bad data has already caused damage downstream.
This is the same anti-pattern that software engineering eliminated twenty years ago. When only specialists can define tests, testing becomes a bottleneck. The fix wasn’t better specialists. It was better interfaces.
What Actually Works: Declarative Checks as a Shared Language
YAML doesn’t make data quality better because of some inherent property of the format. It works because it shifts the interface for defining quality from imperative code to declarative specifications.
Here’s a null check using a typical Python-first data quality framework:
import dq_framework as dq context = dq.get_context() datasource = context.sources.add_pandas("my_datasource") data_asset = datasource.add_dataframe_asset(name="my_data") batch_request = data_asset.build_batch_request(dataframe=df) validator = context.get_validator(batch_request=batch_request) validator.expect_column_values_to_not_be_null( column="email", mostly=0.95 ) result = validator.validate()
And the same check in YAML (SodaCL):
checks for orders
That’s it. One line. A governance lead can read it. A business analyst can propose a change to it in a pull request. A data engineer can review and merge it in thirty seconds.
This isn’t about YAML being “simpler” in some vague sense. It’s about three specific properties:
Declarative over imperative. YAML checks describe what good data looks like, not how to verify it. row_count > 0 reads like a specification, not a program. That’s the difference between a contract and an implementation.
Version-controlled collaboration. YAML files live in Git. Producers and consumers edit the same file. Changes go through pull requests, not email threads. This is the workflow that transformed software engineering (code review, CI/CD, automated testing) — and it works for data quality too.
Machine-readable by default. YAML slots directly into CI/CD pipelines. No wrapper scripts, no custom runners. A CLI tool parses the file, runs the checks, and returns pass/fail. That’s a circuit breaker you can drop into Airflow, GitHub Actions, or any orchestrator.
(If this sounds like the same argument for Infrastructure as Code, that’s because it is. We already proved that declarative YAML configs beat imperative scripts for managing infrastructure. Data quality is the same pattern.)
Data Contracts: Where YAML Really Shines
Data contracts are formalized agreements between data producers and consumers: what the schema looks like, what quality rules apply, who owns it, and what the SLAs are.
YAML is the dominant format for contract specifications — the Open Data Contract Standard uses it, Soda’s contract engine uses it, dbt uses it. And there’s a reason: contracts are documents that both humans and machines need to read.
A data contract written in Python is code that happens to encode agreements. A data contract written in YAML is the agreement — readable by the governance lead who defined the SLA, the engineer who implements the pipeline, and the CI/CD system that enforces it.
The real power is in the workflow that YAML enables. Instead of data producers and consumers arguing over email about what “valid data” means, they collaborate on a YAML file:
The consumer proposes a contract (or modifies an existing one) via a pull request
The producer reviews it — “We can guarantee
freshness < 1hbut not< 15min“They negotiate in the PR comments, update the YAML, and merge
CI/CD enforces the contract automatically on every pipeline run
That’s governance packaged as engineering. No meetings. No Confluence pages that go stale. The contract is living, versioned, and enforced.
This is exactly how Make, the AI automation platform, shifted data quality left with data contracts in their Airflow pipelines.
When Python Still Makes Sense
I’m not arguing that YAML replaces Python entirely. For about 20% of data quality checks, you genuinely need programmatic logic:
Statistical tests: Distribution comparisons, outlier detection with custom thresholds, seasonality-aware anomaly detection.
Cross-dataset validations: Reconciliation checks that join across sources with complex matching logic.
ML-based quality: Pattern recognition that goes beyond rule-based checks.
For these cases, Python (or SQL) is the right tool. The better approach isn’t YAML or Python. It’s YAML as the primary interface for the 80% of checks that are standard (nulls, schema, freshness, row counts, uniqueness), with Python available for the remaining 20%.
The hybrid model works. Most data quality issues aren’t exotic. They’re a column that went null, a schema that changed without warning, a freshness SLA that was missed. YAML handles all of those without asking anyone to learn a programming language.
How to Start: From Email Threads to Pull Requests
If you’re running data quality checks in Python today, you don’t need to rewrite everything. Start here:
Audit your existing checks (~1 hour). List every quality rule your team enforces, including the informal ones hiding in Slack messages and email threads. Most teams are surprised by how many rules exist outside of code.
Translate the top 20 into YAML (~half a day). Pick the checks that are standard validations: nulls, schema, row counts, freshness, uniqueness. These translate directly to declarative syntax.
Integrate into your pipeline (~2 hours). Drop the YAML checks into your CI/CD workflow. Soda Core, dbt tests, or any YAML-based tool can parse them as quality gates.
Invite your non-engineering stakeholders (~ongoing). This is the step most teams skip. Share the YAML file with your governance lead, your business analyst, your data consumers. Show them how to propose a new check via a pull request. The first time a business user submits a PR that catches a data issue before it hits production, the value of this approach becomes obvious.
The Honest Caveats
YAML has real limitations. It doesn’t support conditional logic, it can’t express complex statistical tests, and deeply nested YAML files become harder to read than the Python they replaced. If your quality checks require significant computation or cross-system orchestration, a declarative config file won’t cut it.
There’s also the “YAML isn’t unique” objection — you could get the same readability from TOML, JSON with comments, or a custom DSL. That’s true in theory. In practice, YAML has the ecosystem: every CI/CD tool parses it, every developer has encountered it, and the major data quality frameworks have already standardized on it. Switching costs matter.
The syntax you choose for data quality isn’t a technical detail. It’s an organizational decision that determines who gets to participate in defining what “good data” means.
Python keeps that power with engineers. YAML distributes it across the organization.
Data quality is too important to be an engineering-only concern. The best syntax is the one that brings everyone to the table.
Check out Soda Contracts Language to see what YAML-based data quality checks look like in practice, or come discuss this in our Slack community.
Frequently Asked Questions
Don't Python-first tools handle data quality better than YAML tools?
Python-first data quality frameworks offer deep flexibility—hundreds of built-in validations, custom logic, and programmatic profiling. But "better" depends on who's writing the checks. If your entire team is Python-fluent, those tools work fine. If you want governance leads, analysts, and business stakeholders to participate in defining quality (and you should), YAML lowers the barrier dramatically.
What if my team already invested in Python-based data quality?
You don't have to throw it away. Start by moving the standard checks (nulls, schema, freshness) to YAML and keep Python for the complex ones. Most teams find that 80% of their checks translate cleanly, and the remaining 20% are the ones that genuinely need programmatic logic.
Isn't YAML just a configuration language, not a real testing framework?
YAML is the syntax, not the framework. Behind every YAML check is an engine that parses the declaration and executes the validation. Soda, dbt tests, and Google Cloud's Dataplex all use YAML as the interface while running SQL or Python under the hood. The declarative surface is the point — it's what makes the checks readable and collaborative.
Trusted by the world’s leading enterprises
Real stories from companies using Soda to keep their data reliable, accurate, and ready for action.
At the end of the day, we don’t want to be in there managing the checks, updating the checks, adding the checks. We just want to go and observe what’s happening, and that’s what Soda is enabling right now.

Sid Srivastava
Director of Data Governance, Quality and MLOps
Investing in data quality is key for cross-functional teams to make accurate, complete decisions with fewer risks and greater returns, using initiatives such as product thinking, data governance, and self-service platforms.

Mario Konschake
Director of Product-Data Platform
Soda has integrated seamlessly into our technology stack and given us the confidence to find, analyze, implement, and resolve data issues through a simple self-serve capability.

Sutaraj Dutta
Data Engineering Manager
Our goal was to deliver high-quality datasets in near real-time, ensuring dashboards reflect live data as it flows in. But beyond solving technical challenges, we wanted to spark a cultural shift - empowering the entire organization to make decisions grounded in accurate, timely data.

Gu Xie
Head of Data Engineering
4,4 sur 5
Commencez à faire confiance à vos données. Aujourd'hui.
Trouvez, comprenez et corrigez tout problème de qualité des données en quelques secondes.
Du niveau de la table au niveau des enregistrements.
Adopté par
Product








Trusted by the world’s leading enterprises
Real stories from companies using Soda to keep their data reliable, accurate, and ready for action.
At the end of the day, we don’t want to be in there managing the checks, updating the checks, adding the checks. We just want to go and observe what’s happening, and that’s what Soda is enabling right now.
Sid Srivastava
Director of Data Governance, Quality and MLOps
Investing in data quality is key for cross-functional teams to make accurate, complete decisions with fewer risks and greater returns, using initiatives such as product thinking, data governance, and self-service platforms.
Mario Konschake
Director of Product-Data Platform
Soda has integrated seamlessly into our technology stack and given us the confidence to find, analyze, implement, and resolve data issues through a simple self-serve capability.
Sutaraj Dutta
Data Engineering Manager
Our goal was to deliver high-quality datasets in near real-time, ensuring dashboards reflect live data as it flows in. But beyond solving technical challenges, we wanted to spark a cultural shift - empowering the entire organization to make decisions grounded in accurate, timely data.
Gu Xie
Head of Data Engineering
4,4 sur 5
Commencez à faire confiance à vos données. Aujourd'hui.
Trouvez, comprenez et corrigez tout problème de qualité des données en quelques secondes.
Du niveau de la table au niveau des enregistrements.
Adopté par
Product
Solutions
Trusted by the world’s leading enterprises
Real stories from companies using Soda to keep their data reliable, accurate, and ready for action.
At the end of the day, we don’t want to be in there managing the checks, updating the checks, adding the checks. We just want to go and observe what’s happening, and that’s what Soda is enabling right now.
Sid Srivastava
Director of Data Governance, Quality and MLOps
Investing in data quality is key for cross-functional teams to make accurate, complete decisions with fewer risks and greater returns, using initiatives such as product thinking, data governance, and self-service platforms.
Mario Konschake
Director of Product-Data Platform
Soda has integrated seamlessly into our technology stack and given us the confidence to find, analyze, implement, and resolve data issues through a simple self-serve capability.
Sutaraj Dutta
Data Engineering Manager
Our goal was to deliver high-quality datasets in near real-time, ensuring dashboards reflect live data as it flows in. But beyond solving technical challenges, we wanted to spark a cultural shift - empowering the entire organization to make decisions grounded in accurate, timely data.
Gu Xie
Head of Data Engineering
4,4 sur 5
Commencez à faire confiance à vos données. Aujourd'hui.
Trouvez, comprenez et corrigez tout problème de qualité des données en quelques secondes.
Du niveau de la table au niveau des enregistrements.
Adopté par
Product
Solutions
Company