
At some point, every data team hits the same wall. Something breaks downstream, an investigation starts, and an hour later, the root cause turns out to be a null value in a column nobody was watching.
According to McKinsey, data processing and cleanup can consume more than half of an analytics team's time, and around 30% of total enterprise time goes to non-value-added tasks caused by poor data quality. For most organizations, that's not a tooling problem or a talent problem. It's a systems problem. Data quality gets managed reactively, after things break, rather than enforced proactively as a standard part of how data moves through the stack.
The problem itself is rarely the hard part. The hard part is that it was entirely preventable.
This guide is about building that system. We'll work through it in three parts. First, the fundamentals: what data quality actually means, how it differs from observability, and the six dimensions teams use to measure it. Next, the obstacles and the frameworks built to handle them: the challenges teams hit when managing quality at scale, and the established frameworks, from DAMA to ISO 8000 to Six Sigma, that give those efforts structure. Finally, putting it into practice: the tools data teams rely on in 2026, a step-by-step roadmap from profiling your data to automating checks in production, and the business case for investing in quality before it becomes a crisis.
Whether you're an engineer trying to make pipelines more reliable or a data leader building the case for investment, this is a practical starting point.
Key Takeaways |
|---|
|
What Is Data Quality?
Data quality measures how well a dataset meets the expectations of the systems and decisions that depend on it. High-quality data supports confident decisions and reliable pipelines. Low-quality data produces unreliable reports, failed pipelines, and flawed model outputs.
The standard isn't absolute. Fitness for purpose is the only real measure and the standard does not have to be absolute. Data that's good enough for customer segmentation may be entirely inadequate for financial reporting.
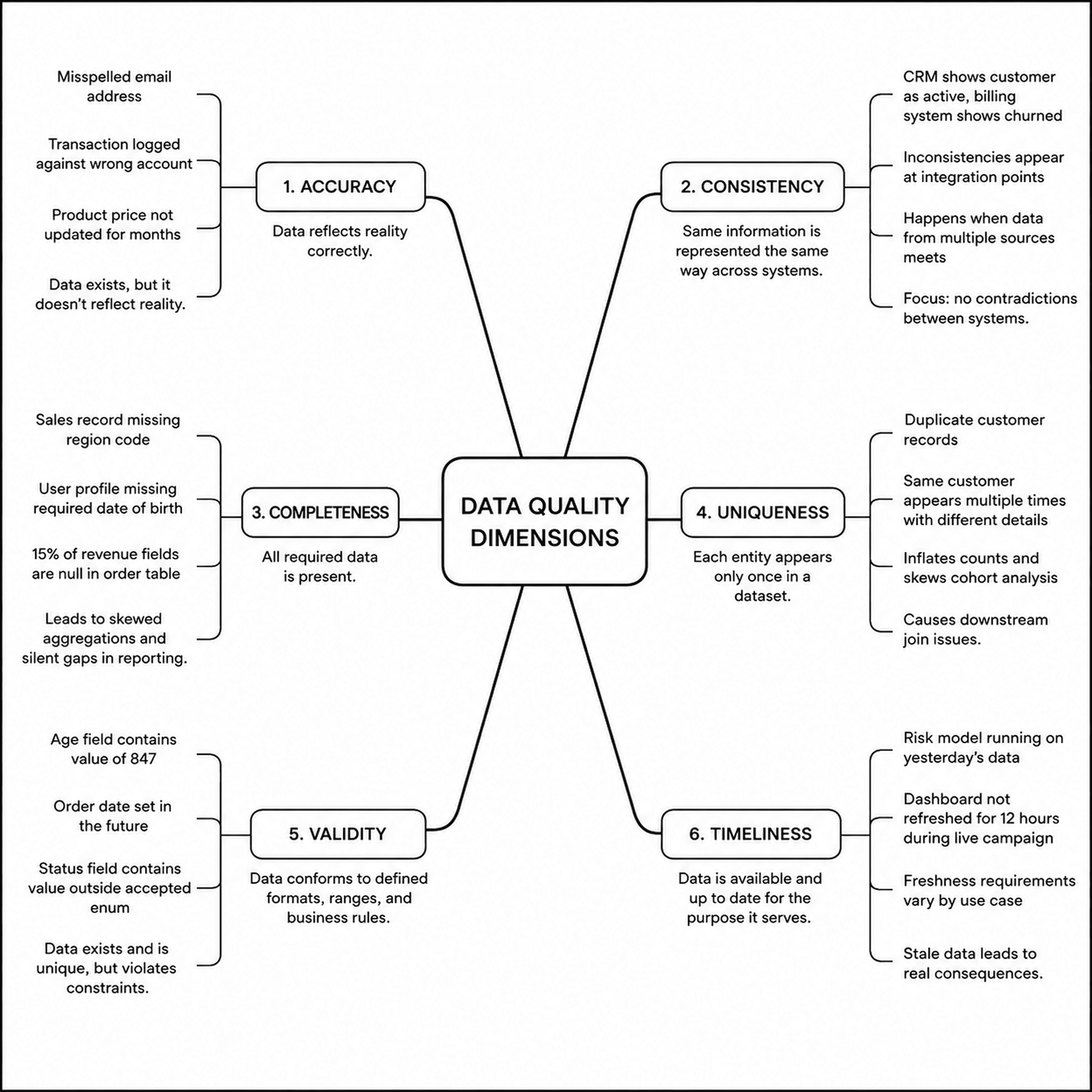
The 6 Dimensions of Data Quality
Data quality is a composite of (usually) six dimensions, each capturing a different way data can fail. Knowing which dimension is failing tells you where to look and what to fix.
Accuracy
A customer record with a misspelled email address, a transaction logged against the wrong account, or a product price that hasn't been updated in six months are all accuracy failures. The data exists, it just doesn't reflect reality.
Consistency
Consistent data means the same information is represented the same way across systems. If your CRM shows a customer as active while your billing system has them marked as churned, you have a consistency problem. Inconsistencies typically surface at integration points, where data from multiple sources meets for the first time.
Completeness
Completeness measures whether all required data is present. A sales record missing a region code, a user profile with no date of birth where one is required, or an order table where 15% of revenue fields are null are all completeness failures. Incomplete data leads to skewed aggregations and silent gaps in reporting.
Uniqueness
Uniqueness ensures that each entity appears only once in a dataset. Duplicate customer records inflate counts, skew cohort analysis, and cause downstream join issues. A single customer appearing three times in a CRM, each with slightly different contact details, is a common and costly uniqueness failure.
Validity
Valid data conforms to defined formats, ranges, and business rules. An age field containing a value of 847, an order date set in the future, or a status field containing a value outside the accepted enum are all validity failures. The data is present and unique, but it violates the constraints the system expects.
Timeliness
Data is timely when it is available and up to date for the purpose it serves. A risk model running on yesterday’s transaction data or a dashboard that has not refreshed in 12 hours during a live campaign both signal a failure in timeliness. Freshness requirements vary by use case, but in time-sensitive contexts, stale data leads to real consequences.
Measuring these dimensions involves defining specific metrics: null percentages, duplicate rates, freshness thresholds, and format conformance scores, then running automated checks consistently across your pipelines.
Common Data Quality Challenges
Data quality challenges come down to a handful of recurring patterns. It's the same handful of blockers repeating across teams, stacks, and quarters. Treat each one as a recurring disease, and you can actually cure it instead of fighting the symptoms forever. Here are the five that come back most.
Data silos create fragmented standards
Data silos are isolated pockets of data that live inside a single team or system and aren't shared or reconciled with the rest of the organization. The reason silos are so damaging is that they don't just divide where your data is stored; they divide what your data means.
When every team and every system maintains its own copy of the truth, each one also develops its own definition of what that truth is. Data quality stops being a single standard that everyone shares and instead becomes something local, defined separately inside each system and enforced nowhere in between.
What makes this so persistent is that the problem reappears every single time data moves from one system to another. Each system looks completely healthy when you examine it on its own, because internally it follows its own rules consistently.
The conflict only becomes visible at the moment two sources meet and their definitions disagree; and in a modern data stack, that moment happens constantly. Every new integration you build becomes one more place for the very same mismatch to surface again.
You can see this play out in ordinary situations. The finance team might count someone as an "active customer" based on recent payments, while the CRM counts the same person as active based on their last login, so the two systems report different totals for what should be the identical metric. Or your data warehouse might allow null values in a column that the source API treats as strictly required, so records that looked valid upstream quietly turn into gaps downstream.
Manual processes don't scale
A hand-written validation script, an ad hoc SQL check, or a spreadsheet audit captures exactly what your data looked like on the day you built it. That works perfectly well when you have a handful of datasets and a small team that remembers every rule. But the moment your pipelines start to grow, the gap between what your checks cover and what your data actually does begins to widen.
You see the result when something finally breaks where everyone can see it. A team wires in a new source without any validation at all, and weeks later a downstream report shows numbers that are obviously wrong.
Ownership is unclear
Data quality ownership typically falls between engineering and business teams. Engineers own the pipelines but don't always know what "correct" looks like for a given business context. Business teams know what the data should represent but don't have the tools or access to enforce it. The result is that nobody owns it fully. Teams escalate issues instead of preventing them.
Reactive fixes are expensive
Most organizations discover data quality problems after they've already caused damage. By the time an investigation starts, the issue may have been affecting reports or pipelines for days. Fixing the root cause takes longer still. Without a system to prevent recurrence, the same problem surfaces again weeks later.
AI and ML raise the stakes
Poor data quality has always been costly. With AI and ML workloads, the cost compounds. A model trained on inaccurate or incomplete data doesn't just produce one wrong answer; it systematically produces wrong answers at scale.
Data quality issues that were once contained to a single report now propagate through every prediction a model makes. As AI becomes more embedded in operational decisions, the margin for poor data narrows significantly.
Data Quality Frameworks
A data quality framework gives your efforts structure. It defines what good data looks like, how to measure it, and who's responsible for maintaining it. Several established frameworks exist, each with a different emphasis and origin.
IMF Data Quality Assessment Framework (DQAF)
Developed by the International Monetary Fund, the DQAF was originally designed for evaluating statistical data published by governments and central banks. It assesses quality across six dimensions: prerequisites, assurances of integrity, methodological soundness, accuracy and reliability, serviceability, and accessibility. It's most useful for public sector organizations or any context where data is used for policy or regulatory reporting.
DAMA-DMBOK
The Data Management Body of Knowledge, published by DAMA International, is the closest thing the data profession has to a standard reference guide. It covers data governance, data architecture, data quality, and more across 11 knowledge areas. Teams building a formal data management practice from scratch often use DAMA-DMBOK as a foundation for defining roles, processes, and policies.
ISO 8000
ISO 8000 is an international standard focused specifically on data quality and enterprise master data. It defines requirements for exchanging and producing high-quality data, with particular emphasis on portability and accuracy of master data across systems. It's widely adopted by large enterprises and organizations that operate across multiple jurisdictions or regulatory environments.
Six Sigma / DMAIC
Six Sigma applies statistical process control to data quality, targeting fewer than 3.4 defects per million data points. The DMAIC cycle (Define, Measure, Analyze, Improve, Control) gives teams a repeatable methodology for identifying root causes and reducing error rates over time. It works well in data-intensive operational environments where quality can be quantified and tied directly to business outcomes.
Data Quality Maturity Model (DQMM / CMMI)
Maturity models like CMMI define five levels of data quality capability, from Initial (ad hoc, reactive) through Managed, Defined, and Quantitatively Managed, up to Optimizing (continuous, automated improvement). They're useful for organizations that want to benchmark where they currently stand and build a roadmap for improving over time, without overhauling everything at once.
In practice, most organizations don't adopt any single framework wholesale. They borrow the governance principles from DAMA, use ISO 8000 as a compliance reference, and apply DMAIC thinking to specific problem areas. Frameworks provide the vocabulary and structure. Tooling is what makes them operational day to day.
Which Data Quality Tools Are Worth Using in 2026?
The tooling landscape for data quality has matured significantly. Tools now range from lightweight open-source libraries to full platforms covering testing, observability, governance, and remediation. Here's how the categories break down.
Open-source and pipeline-native tools
Python-based validation libraries let teams define rules their data must meet and run them inside existing pipelines via integrations with Airflow, dbt, and Spark. They're a starting point for teams that want code-first validation without a managed platform, though they typically require more engineering effort to maintain and don't extend to observability or cross-pipeline monitoring.
Apache Griffin is an open-source data quality solution originally built at eBay. It supports both batch and streaming data and handles accuracy, completeness, timeliness, and uniqueness checks at scale. It's more infrastructure-heavy to set up, making it a better fit for larger engineering teams with existing Hadoop or Spark environments.
dbt tests are built directly into dbt's transformation layer. You can assert that a column has no nulls, that values are unique, or that referential integrity holds between tables. They're easy to adopt if your team is already using dbt, though they cover transformation-layer quality only and don't extend to observability or cross-pipeline monitoring.
Governance and catalog platforms
Governance and catalog platforms like Collibra and Atlan sit at the governance and metadata end of the spectrum. They're strong on data lineage, policy management, and cataloging, and they integrate data quality as one component of a broader governance layer. These platforms tend to be enterprise-grade in both capability and complexity, making them better suited for large organizations with dedicated data governance teams.
Dedicated data quality platforms
Soda focuses specifically on data quality, covering the full cycle from prevention to detection to resolution. With the release of Soda 4.0, the platform brings together data testing, observability, and AI in a single unified environment.
Engineers work through Soda Core, an open-source data contracts engine with 50+ built-in check types and a clean YAML syntax. They define contracts in code, version them in Git, and run them inside their existing orchestration workflows. Soda supports Airflow, Dagster, Prefect, and dbt Cloud natively, along with data platforms including Snowflake, BigQuery, and Databricks.
Business users work through Soda Cloud, where non-technical stakeholders can co-author data contracts through a collaborative UI, review quality expectations in plain English using Contracts Copilot, and track data health without writing a single line of code.
On the observability side, Soda's anomaly detection engine is built in-house and continuously adapts to your data's historical patterns. It covers metrics at the table, metadata, and record level, and incorporates user feedback to reduce false positives over time. According to Soda's own benchmarking, it shows a 70% improvement in detecting anomalous data quality metrics compared to Facebook Prophet across diverse datasets.
Building Your Data Quality Management Roadmap
A data quality management program is only as strong as the process behind it. Here's how to build one that holds up as your stack grows.
1. Profile and assess your data
Before setting standards, understand what you're working with. Data profiling gives you a baseline: null rates, value distributions, duplicate counts, schema structures, and anomalies across your datasets. Most teams are surprised by what they find. Tables they assumed were clean turn out to have 20% null rates in critical columns. Foreign key relationships they relied on have integrity gaps.
Soda's automated profiling scans your datasets on onboarding and surfaces these issues immediately, without requiring manual setup or custom scripts.
2. Define standards and rules
Once you know the state of your data, define what good looks like. For each dataset, set measurable thresholds tied to the dimensions that matter for its use case: acceptable null percentage, freshness requirements, allowed value ranges, uniqueness constraints. These should map to real business outcomes, not abstract technical targets.
Soda formalizes these standards as data contracts, defined as YAML documents that capture schema expectations, column-level rules, and dataset-level checks in a format that both engineers and business users can read and contribute to.
3. Implement governance and ownership
Quality standards only hold if someone is accountable for them. Assign dataset owners. Define roles clearly: engineers own pipeline reliability and contract enforcement, data stewards own domain-level standards, business users own the definition of what the data should represent.
Soda Cloud supports this with role-based collaboration, allowing teams to co-author contracts, assign ownership per dataset, and route alerts to the right person when a check fails.
4. Automate monitoring
Manual checks don't scale. Once you've defined standards, embed them into your pipelines so validation runs automatically at every stage: ingestion, transformation, and before data reaches production. Pair contract-based testing with continuous observability to cover both known failure modes and unexpected anomalies.
Soda integrates directly with Airflow, Dagster, Prefect, and dbt, so quality checks run as part of your existing orchestration workflows. No separate process to maintain.
5. Remediate and improve
When a check fails, the response process matters as much as the detection. Good data quality management means having a clear path from alert to resolution: identify the root cause, isolate the affected data, notify the right stakeholders, and fix the issue upstream so it doesn't recur.
Soda connects to Slack, Jira, PagerDuty, and ServiceNow out of the box, routing incidents into the workflows your team already uses. Every failed check links back to the contract that defined the expectation, so root-cause investigation starts with context rather than guesswork.
6. Build a data-first culture
Tools and processes only go so far. Sustained data quality requires that everyone who produces or consumes data treats it as a shared responsibility. That means involving business stakeholders in defining quality expectations, not just notifying them when something breaks. It means making quality metrics visible to the whole organization, not just the data team.
The organizations that get this right, treat data contracts not as a technical artifact but as an agreement between teams about what the data should reliably deliver.
The ROI of Data Quality
Investing in data quality is easier to justify when the cost of ignoring it is visible. Most of the time, it isn't, until something breaks badly enough to get noticed.
The operational cost. Data processing and cleanup often take up a significant share of an analytics team’s time. Across the wider organization, poor data quality also drives a large amount of work that does not create direct value. That translates into engineering effort spent investigating issues instead of building, and analyst time spent validating numbers instead of generating insights.
The financial cost. Bad data in operational systems has direct financial consequences. Duplicate records in billing systems cause incorrect charges. Inaccurate inventory data leads to over-ordering or stockouts. Incomplete customer data reduces marketing effectiveness. An IBM Institute for Business Value report puts numbers to what most data teams already sense: over a quarter of organizations estimate they lose more than $5 million annually to poor data quality, with 7% reporting losses above $25 million. These aren't edge cases. They're recurring costs spread across teams and systems, often invisible until they surface in a quarterly review or a failed audit.
The AI cost. As organizations embed AI and ML into more decisions, data quality becomes a multiplier in both directions. A model trained on clean, well-validated data produces reliable outputs at scale. A model trained on inconsistent or incomplete data produces unreliable outputs at the same scale, amplifying every flaw across every prediction it makes. The higher the stakes of the model, the higher the cost of poor inputs.
The strategic case. Organizations that trust their data move faster. They spend less time in meetings debating whether numbers are correct and more time acting on them. Data quality isn't just a technical concern. It's what determines whether data-driven decisions are actually driven by data, or by whoever argues most convincingly in the room.
The investment in a structured data quality management program pays back through reduced incident response time, faster analytics delivery, lower compliance risk, and more reliable AI outputs. The tools, frameworks, and processes covered in this guide are the practical path to getting there.
Where to Go From Here
None of these steps requires a perfect setup from day one. They require a system that improves over time.
Start by understanding what your data actually looks like today.
Define clear standards based on the dimensions that matter for each use case.
Assign ownership, automate enforcement, and build a process for responding when things go wrong.
As AI becomes more embedded in business decisions, organizations that invest in data quality now build a compounding advantage. Reliable data produces reliable models, which produce decisions people actually trust.
If you're ready to move from reactive fixes to proactive quality management, Soda is built to support that transition. It brings together data testing, observability, and AI-powered automation in a single platform, connecting the engineers who build pipelines and the business teams who depend on them.
Start for free or book a demo to see how Soda works across your stack.
Frequently Asked Questions
What is data quality management?
Data quality management is the ongoing practice of defining, measuring, monitoring, and improving the quality of data across an organization. It includes profiling data to establish baselines, setting standards through data contracts, assigning ownership, automating validation, and building remediation processes when checks fail.
What is the difference between data quality and data governance?
Data quality focuses on the condition of the data itself — whether it is accurate, complete, and reliable. Data governance defines the policies, roles, and processes for managing data as an organizational asset. Governance sets the rules; quality measures whether the data meets them. Both are needed, and they reinforce each other.
How do you measure data quality?
You measure data quality by defining metrics tied to each dimension: null rates for completeness, duplicate counts for uniqueness, freshness thresholds for timeliness, format validation for validity, and cross-system comparisons for consistency. These metrics are then automated as checks that run continuously inside your data pipelines.
How do data contracts improve data quality?
Data contracts are versioned agreements that define what a dataset should look like — its schema, column-level rules, and freshness requirements. By codifying expectations as YAML and enforcing them automatically in CI/CD pipelines and orchestration workflows, contracts shift quality enforcement upstream, catching issues before they reach production rather than after.











