Fraud Detection ML Scores
Fraud Detection ML Scores
Assurez une cohérence irréprochable entre tous vos produits de données
Assurez une cohérence irréprochable entre tous vos produits de données
Ensure fraud scoring data is fresh, complete, and reliable before it is used for real-time fraud decisions, case management, model monitoring, and downstream analytics.

Fabiana Ferraz
Rédacteur technique chez Soda
Data contract description
This data contract enforces schema stability, a strict 1-hour freshness SLA on scored_at, and required identifiers and model metadata to ensure trustworthy fraud scoring outputs. It blocks future-dated scores, validates fraud_score within the [0, 1] range, prevents duplicate scores per transaction_id and model_id, and enforces alignment between fraud_score thresholds and prediction_label values. It also applies controlled formats for UUIDs, semantic versions, and SHA-256 feature hashes to support traceability across model versions.
fraud_scores_data_contract.yaml
datasetvariables: FRESHNESS_HOURS: default: 1 checks: - schema: allow_extra_columns: false allow_other_column_order: false - row_count: threshold: must_be_greater_than: 0 - freshness: column: scored_at threshold: unit: hour must_be_less_than_or_equal: ${var.FRESHNESS_HOURS} - failed_rows: name: "scored_at must not be in the future" qualifier: scored_at_not_future expression: scored_at > ${soda.NOW} - failed_rows: name: "fraud_score must be between 0 and 1" qualifier: score_range expression: fraud_score < 0.0 OR fraud_score > 1.0 - failed_rows: name: "No duplicate scores per transaction per model" qualifier: dup_txn_model query: | SELECT transaction_id, model_id FROM datasource.db.schema.fraud_scores GROUP BY transaction_id, model_id HAVING COUNT(*) > 1 threshold: must_be: 0 - failed_rows: name: "prediction_label must align with fraud_score threshold" qualifier: label_score_alignment expression: > (prediction_label = 'FRAUD' AND fraud_score < 0.5) OR (prediction_label = 'LEGIT' AND fraud_score > 0.9)
columns: - name: transaction_id data_type: string checks: - missing: name: No missing values - invalid: name: "transaction_id must be a UUID" valid_format: name: UUID regex: "^[0-9a-fA-F]{8}-[0-9a-fA-F]{4}-[0-9a-fA-F]{4}-[0-9a-fA-F]{4}-[0-9a-fA-F]{12}$" - name: model_id data_type: string checks: - missing: name: No missing values - invalid: name: "model_id length guardrail" valid_min_length: 1 valid_max_length: 64 - name: model_version data_type: string checks: - missing: name: No missing values - invalid: name: "Semantic version format (e.g. 1.2.3)" valid_format: name: semver regex: "^\\d+\\.\\d+\\.\\d+$" - name: fraud_score data_type: decimal checks: - missing: name: No missing values - invalid: name: "Score must be between 0 and 1" valid_min: 0.0 valid_max: 1.0 - name: prediction_label data_type: string checks: - missing: name: No missing values - invalid: name: "Allowed prediction labels" valid_values: - LEGIT - SUSPICIOUS - FRAUD - name: scored_at data_type: timestamp checks: - missing: name: No missing values - name: feature_hash data_type: string checks: - missing: name: No missing values - invalid: name: "feature_hash must be a valid SHA-256 hex string" valid_format: name: SHA-256 hash regex: "^[a-fA-F0-9]{64}$"
Data contract description
This data contract enforces schema stability, a strict 1-hour freshness SLA on scored_at, and required identifiers and model metadata to ensure trustworthy fraud scoring outputs. It blocks future-dated scores, validates fraud_score within the [0, 1] range, prevents duplicate scores per transaction_id and model_id, and enforces alignment between fraud_score thresholds and prediction_label values. It also applies controlled formats for UUIDs, semantic versions, and SHA-256 feature hashes to support traceability across model versions.
fraud_scores_data_contract.yaml
datasetvariables: FRESHNESS_HOURS: default: 1 checks: - schema: allow_extra_columns: false allow_other_column_order: false - row_count: threshold: must_be_greater_than: 0 - freshness: column: scored_at threshold: unit: hour must_be_less_than_or_equal: ${var.FRESHNESS_HOURS} - failed_rows: name: "scored_at must not be in the future" qualifier: scored_at_not_future expression: scored_at > ${soda.NOW} - failed_rows: name: "fraud_score must be between 0 and 1" qualifier: score_range expression: fraud_score < 0.0 OR fraud_score > 1.0 - failed_rows: name: "No duplicate scores per transaction per model" qualifier: dup_txn_model query: | SELECT transaction_id, model_id FROM datasource.db.schema.fraud_scores GROUP BY transaction_id, model_id HAVING COUNT(*) > 1 threshold: must_be: 0 - failed_rows: name: "prediction_label must align with fraud_score threshold" qualifier: label_score_alignment expression: > (prediction_label = 'FRAUD' AND fraud_score < 0.5) OR (prediction_label = 'LEGIT' AND fraud_score > 0.9)
columns: - name: transaction_id data_type: string checks: - missing: name: No missing values - invalid: name: "transaction_id must be a UUID" valid_format: name: UUID regex: "^[0-9a-fA-F]{8}-[0-9a-fA-F]{4}-[0-9a-fA-F]{4}-[0-9a-fA-F]{4}-[0-9a-fA-F]{12}$" - name: model_id data_type: string checks: - missing: name: No missing values - invalid: name: "model_id length guardrail" valid_min_length: 1 valid_max_length: 64 - name: model_version data_type: string checks: - missing: name: No missing values - invalid: name: "Semantic version format (e.g. 1.2.3)" valid_format: name: semver regex: "^\\d+\\.\\d+\\.\\d+$" - name: fraud_score data_type: decimal checks: - missing: name: No missing values - invalid: name: "Score must be between 0 and 1" valid_min: 0.0 valid_max: 1.0 - name: prediction_label data_type: string checks: - missing: name: No missing values - invalid: name: "Allowed prediction labels" valid_values: - LEGIT - SUSPICIOUS - FRAUD - name: scored_at data_type: timestamp checks: - missing: name: No missing values - name: feature_hash data_type: string checks: - missing: name: No missing values - invalid: name: "feature_hash must be a valid SHA-256 hex string" valid_format: name: SHA-256 hash regex: "^[a-fA-F0-9]{64}$"
Data contract description
This data contract enforces schema stability, a strict 1-hour freshness SLA on scored_at, and required identifiers and model metadata to ensure trustworthy fraud scoring outputs. It blocks future-dated scores, validates fraud_score within the [0, 1] range, prevents duplicate scores per transaction_id and model_id, and enforces alignment between fraud_score thresholds and prediction_label values. It also applies controlled formats for UUIDs, semantic versions, and SHA-256 feature hashes to support traceability across model versions.
fraud_scores_data_contract.yaml
datasetvariables: FRESHNESS_HOURS: default: 1 checks: - schema: allow_extra_columns: false allow_other_column_order: false - row_count: threshold: must_be_greater_than: 0 - freshness: column: scored_at threshold: unit: hour must_be_less_than_or_equal: ${var.FRESHNESS_HOURS} - failed_rows: name: "scored_at must not be in the future" qualifier: scored_at_not_future expression: scored_at > ${soda.NOW} - failed_rows: name: "fraud_score must be between 0 and 1" qualifier: score_range expression: fraud_score < 0.0 OR fraud_score > 1.0 - failed_rows: name: "No duplicate scores per transaction per model" qualifier: dup_txn_model query: | SELECT transaction_id, model_id FROM datasource.db.schema.fraud_scores GROUP BY transaction_id, model_id HAVING COUNT(*) > 1 threshold: must_be: 0 - failed_rows: name: "prediction_label must align with fraud_score threshold" qualifier: label_score_alignment expression: > (prediction_label = 'FRAUD' AND fraud_score < 0.5) OR (prediction_label = 'LEGIT' AND fraud_score > 0.9)
columns: - name: transaction_id data_type: string checks: - missing: name: No missing values - invalid: name: "transaction_id must be a UUID" valid_format: name: UUID regex: "^[0-9a-fA-F]{8}-[0-9a-fA-F]{4}-[0-9a-fA-F]{4}-[0-9a-fA-F]{4}-[0-9a-fA-F]{12}$" - name: model_id data_type: string checks: - missing: name: No missing values - invalid: name: "model_id length guardrail" valid_min_length: 1 valid_max_length: 64 - name: model_version data_type: string checks: - missing: name: No missing values - invalid: name: "Semantic version format (e.g. 1.2.3)" valid_format: name: semver regex: "^\\d+\\.\\d+\\.\\d+$" - name: fraud_score data_type: decimal checks: - missing: name: No missing values - invalid: name: "Score must be between 0 and 1" valid_min: 0.0 valid_max: 1.0 - name: prediction_label data_type: string checks: - missing: name: No missing values - invalid: name: "Allowed prediction labels" valid_values: - LEGIT - SUSPICIOUS - FRAUD - name: scored_at data_type: timestamp checks: - missing: name: No missing values - name: feature_hash data_type: string checks: - missing: name: No missing values - invalid: name: "feature_hash must be a valid SHA-256 hex string" valid_format: name: SHA-256 hash regex: "^[a-fA-F0-9]{64}$"
How to Enforce Data Contracts with Soda
Embed data quality through data contracts at any point in your pipeline.
Embed data quality through data contracts at any point in your pipeline.
# pip install soda-{data source} for other data sources
# pip install soda-{data source} for other data sources
pip install soda-postgres
pip install soda-postgres
# verify the contract locally against a data source
# verify the contract locally against a data source
soda contract verify -c contract.yml -ds ds_config.yml
soda contract verify -c contract.yml -ds ds_config.yml
# publish and schedule the contract with Soda Cloud
# publish and schedule the contract with Soda Cloud
soda contract publish -c contract.yml -sc sc_config.yml
soda contract publish -c contract.yml -sc sc_config.yml
Check out the CLI documentation to learn more.
Check out the CLI documentation to learn more.
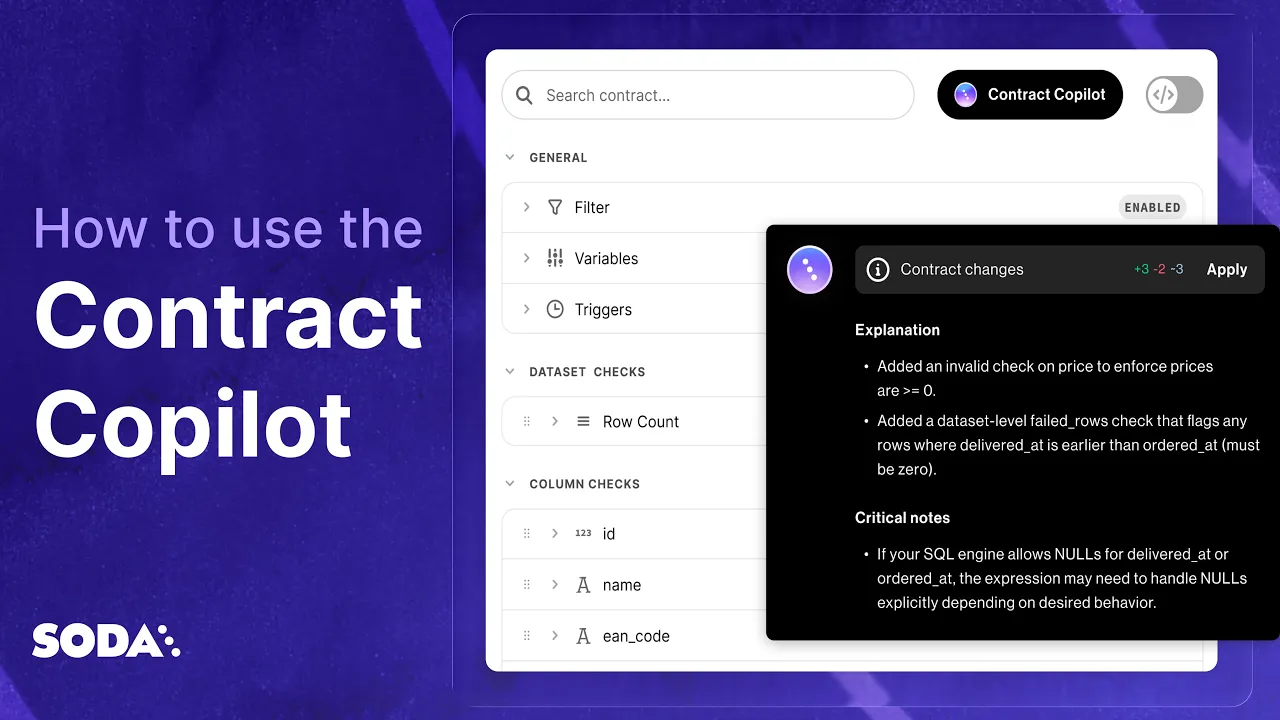
How to Automatically Create Data Contracts.
In one Click.
Automatically write and publish data contracts using Soda's AI-powered data contract copilot.
Qualité des données IA basée sur la recherche
Nos recherches ont été publiées dans des revues et conférences de renom, telles que NeurIPs, JAIR et ACML. Les mêmes lieux qui ont fait progresser les fondations de GPT et de l'IA moderne.
Explore more data contract templates
One new data contract template every day, across industries and use cases









4,4 sur 5
Commencez à faire confiance à vos données. Aujourd'hui.
Trouvez, comprenez et corrigez tout problème de qualité des données en quelques secondes.
Du niveau de la table au niveau des enregistrements.
Adopté par
Product








4,4 sur 5
Commencez à faire confiance à vos données. Aujourd'hui.
Trouvez, comprenez et corrigez tout problème de qualité des données en quelques secondes.
Du niveau de la table au niveau des enregistrements.
Adopté par
Product
Solutions
4,4 sur 5
Commencez à faire confiance à vos données. Aujourd'hui.
Trouvez, comprenez et corrigez tout problème de qualité des données en quelques secondes.
Du niveau de la table au niveau des enregistrements.
Adopté par
Product
Solutions
Company