
Financial institutions have long been working under the principles of BCBS 239, aiming to strengthen risk data aggregation and reporting. However, with the release of the ECB’s RDARR Guide in May 2024, the expectations around data quality have shifted from high-level principles to concrete operational requirements.
This shift is not subtle. It fundamentally changes how banks must approach data quality, governance, and accountability. What was once interpreted flexibly is now being enforced with clarity, structure, and measurable expectations.
In this blog, we explore what that shift means in practice, how organizations are responding to the new requirements, and what role modern data quality platforms can play in accelerating compliance.
Why Data Errors Hit Harder in Finance
Banks, insurers, lenders, investors, and creditors need to run on accurate, complete, timely data. When that data issues slips, regulatory reports go out wrong, loan decisions misfire, fraud detection lags, risk numbers drift from reality. Each of those compounds into reputational and customer-trust hits that are hard to come back from.
This is why data quality in finance is a regulatory requirement. BCBS 239 (the Basel Committee's risk data aggregation and reporting standard) directs banks to strengthen both how they aggregate and report risk data.
The European Central Bank named remediating risk data aggregation and reporting (RDARR) gaps one of its top supervisory priorities for 2025–2027, and supervisors are committed to "full use of the supervisory escalation toolkit, including sanctions" for banks that miss the deadline.
Manual data checks are slow, error-prone, and don't survive contact with real transaction volume. At thousands of events per second across core banking, trading, and payments, there's no human scale that covers it.
Automated, continuous data monitoring and cleansing enforce the accuracy, completeness, and timeliness that BCBS 239 requires. Together they stop bad data before it reaches the report or the model. They surface issues proactively, so the steward or owner sees the problem before the business does.
From BCBS 239 Principle to ECB Operational Expectation
Under BCBS 239, financial institutions were already required to implement robust data quality controls. However, the regulation left room for interpretation, particularly around scope, ownership, and execution. The RDARR Guide removes much of that ambiguity.
End-to-end data quality control coverage
Data quality checks are no longer limited to downstream reporting layers. Instead, they must span the entire data lifecycle — from front-office systems and operational data sources through to final risk reports. This includes internal accounting data, external data inputs, and even data used in model development.
For many institutions, this has led to a substantial increase in both the volume and granularity of data that must be monitored. It has also forced a “shift-left” approach, where data quality controls are applied earlier in the data pipeline rather than only at reporting stages.
Formal business ownership and issue management
While BCBS 239 emphasized governance, it did not explicitly require structured mechanisms like issue registers or clearly defined ownership models. RDARR changes that. Data quality issues must now be logged, tracked, and resolved through formal processes, with clear accountability assigned to data owners.
This introduces a new level of operational complexity. Organizations must involve more stakeholders across business and technical functions, define escalation paths, and ensure that data quality is actively managed — not just monitored.
Executive-level reporting on data quality itself
The RDARR Guide elevates data quality to the management layer. Institutions are now expected to establish dedicated management bodies responsible for data quality oversight. Data Quality Indicators (DQIs) must complement Key Risk Indicators (KRIs), and reporting must include historical trends, enabling leadership to understand how data quality evolves over time.
Challenges Soda Solves
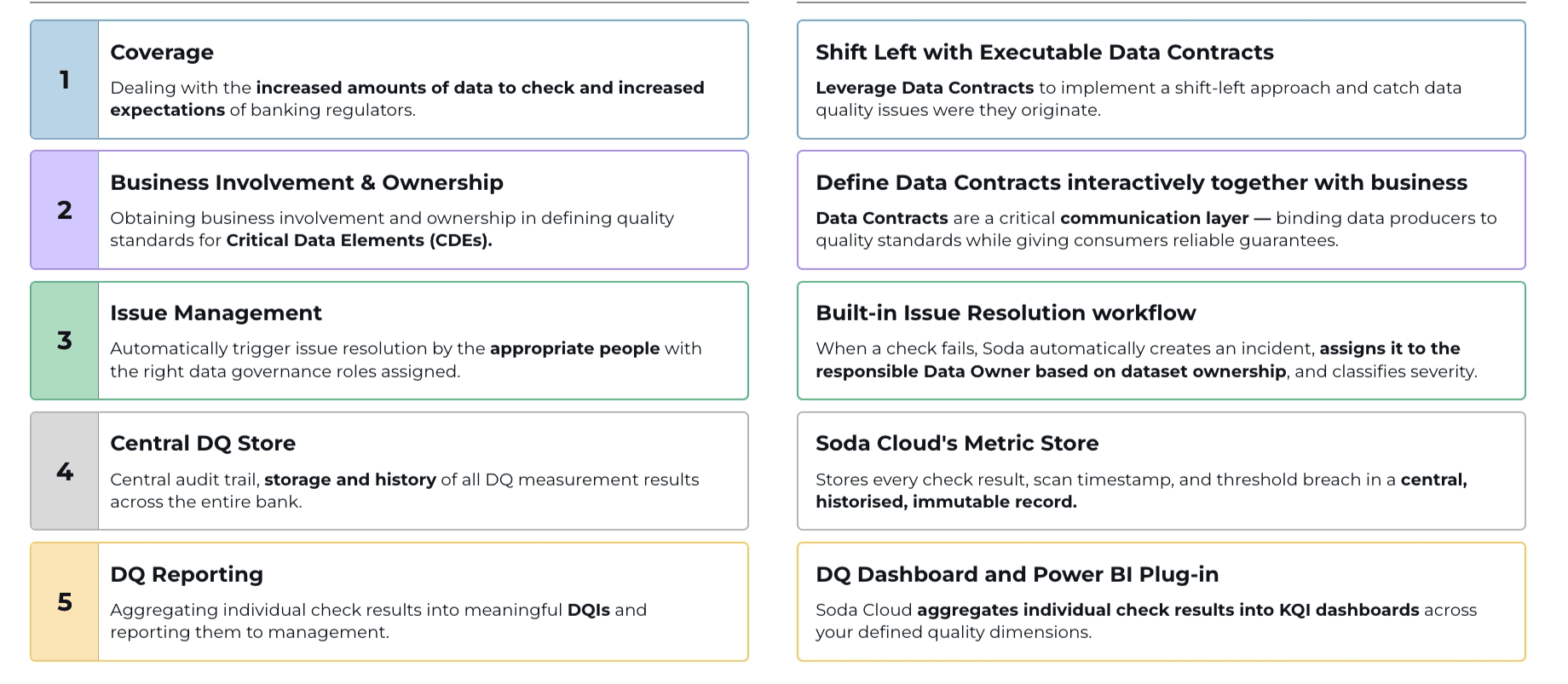
Coverage: Banks must now check more data across more systems, and regulators expect higher standards than before. Soda uses executable data contracts to catch data quality issues at the source, before they reach downstream reports or risk models.
Business Involvement & Ownership: Regulators expect business teams to own data quality standards for Critical Data Elements (CDEs), not just hand them off to IT. Soda gives business and technical users a shared space to define data contracts together. This binds data producers to agreed quality standards and gives consumers reliable guarantees.
Issue Management: When a data quality check fails, the right people need to know immediately. Soda automatically creates an incident, assigns it to the responsible data owner based on dataset ownership, and classifies it by severity. Teams can act without waiting for manual triage.
Central DQ Store: Regulators require a full audit trail of data quality activity across the bank. Soda Cloud's metric store records every check result, scan timestamp, and threshold breach in a central, historized, immutable record that any team can access.
DQ Reporting: Individual check results do not tell leadership much on their own. Soda aggregates them into meaningful Data Quality Indicators (DQIs) and surfaces them through a DQ Dashboard and Power BI integration, so management gets a clear view across all quality dimensions.
Data Observability for scale
Data observability handles what manual rules cannot.
Given the sheer volume of data in modern financial systems, it is no longer practical to define manual rules for every dataset or field. Instead, machine learning models analyze historical patterns and automatically detect anomalies. These could include unexpected changes in row counts, delays in data refresh cycles, or unusual shifts in value distributions.
This approach allows organizations to gain immediate visibility into potential issues without the overhead of manually defining rules. At the same time, human feedback remains critical. Data stewards can validate whether detected anomalies are genuine issues or false positives, allowing the system to continuously improve.
However, observability alone is not sufficient for regulatory compliance. Regulators require explicit, auditable controls. This is where data contracts come into play.
Data contracts for auditability
Data contracts formalize the expectations between data producers and consumers. They define what “good data” looks like by specifying rules around completeness, validity, freshness, and consistency. These contracts can include dataset-level checks, column-level validations, and reconciliation rules that compare data across systems.
What makes this approach particularly powerful is its auditability. Every change to a data contract is tracked, versioned, and reviewable. Business users can propose updates, collaborate with technical teams, and leverage AI-assisted tools to define new checks — all within a controlled and traceable workflow.
Beyond validation, the Soda also supports integrated issue management. When a data quality check fails, it can automatically trigger an incident. These incidents can be assigned, prioritized, and tracked through resolution, often integrating seamlessly with existing tools like Jira or ServiceNow. This ensures that data quality is not only monitored but actively managed.
↗ Soda incident triage flow: detect anomaly, decide if expected, link or create incident, Slack notify, escalate to contracts.
Diagnostics layer for traceability
The Diagnostics Warehouse stores every failed record and validation in the customer's own environment. This enables organizations to drill down from high-level indicators to specific data issues, supporting both internal remediation and regulatory reporting. By tagging checks with regulatory principles or data quality dimensions, institutions can also align their reporting directly with frameworks like BCBS 239.
Together, these capabilities create a system where data quality is continuously monitored, formally governed, and fully traceable—meeting both operational and regulatory needs.
The “Make” versus “Buy” Question
For most financial institutions, the question is not whether to implement data quality capabilities, but how.
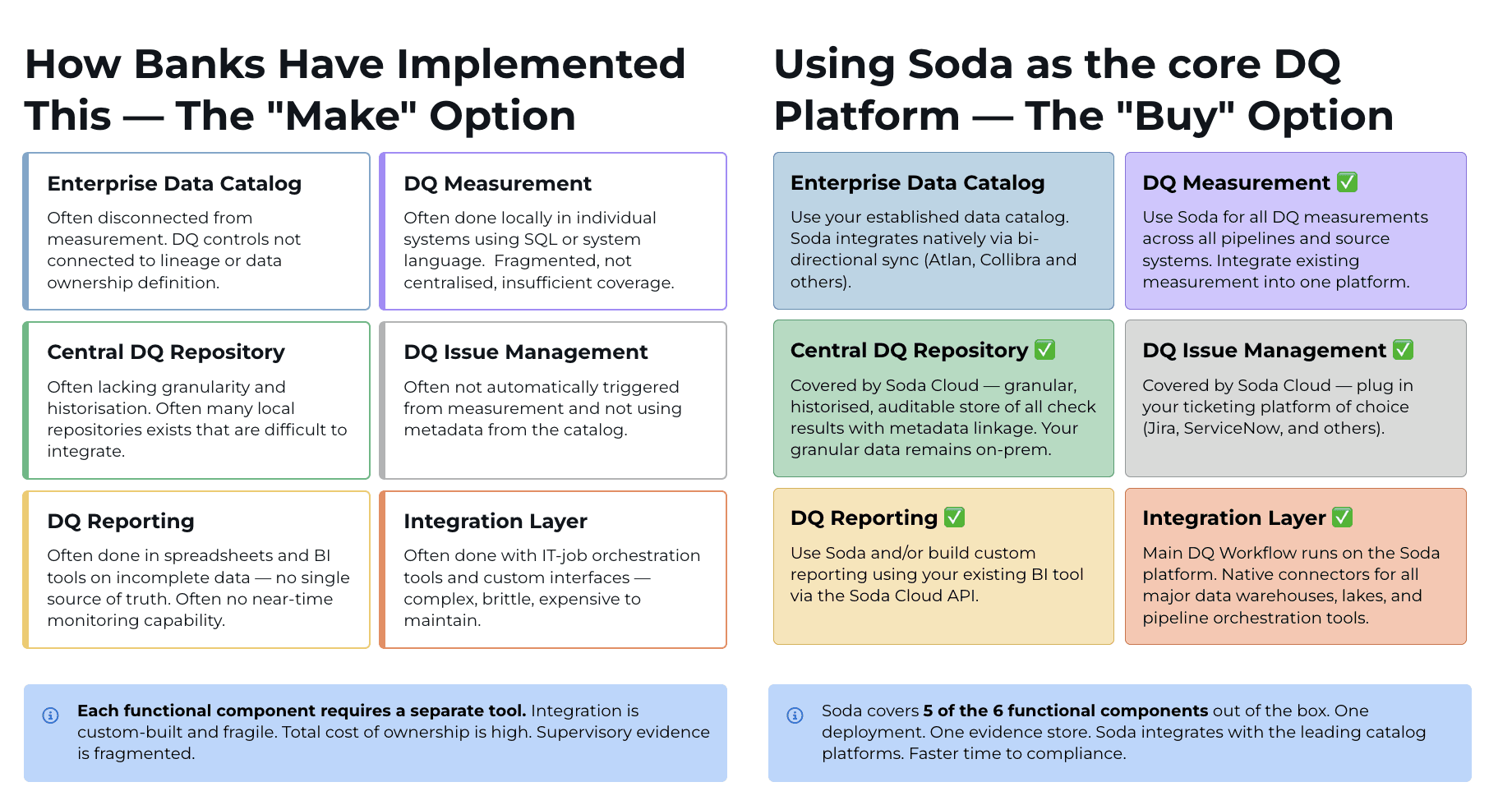
Over the years, many organizations have built their own solutions. These often consist of multiple tools and frameworks stitched together to handle validation, reporting, and issue management. While this approach offers flexibility, it also introduces fragmentation.
In practice, internally built solutions tend to suffer from inconsistent rule definitions, limited coverage, and disconnected workflows. Data quality checks may exist in isolation, issue management may rely on external systems, and reporting often requires significant manual effort. As regulatory expectations evolve, these fragmented architectures become increasingly difficult to maintain and scale.
Learn how Group 1001 solved the growing complexity of data quality in a multi-tool environment and integrated Soda to their modern data stack to streamline data quality management.
A complete data quality framework requires some capabilities working as one system:
a data catalog to inventory critical data elements
measurement and monitoring to detect issues continuously
a centralized repository of checks with version control
issue management workflows integrated with ticketing systems
integrated reporting that maps to regulatory frameworks
orchestration across the data stack
Building and maintaining all of these components internally is both complex and resource-intensive. This is where platform-based approaches offer a clear advantage. Solutions like Soda provide many of these capabilities out of the box, enabling organizations to centralize their data quality efforts, standardize processes, and reduce time to compliance.
That said, the decision is rarely a simple binary choice. Most institutions already have parts of the ecosystem in place, such as data catalogs or BI tools. The real challenge lies in integrating these components into a cohesive framework that meets regulatory expectations.
Ultimately, the “make versus buy” question is less about ownership and more about effectiveness. The goal is to move from fragmented, manual processes to an integrated, scalable system that can adapt to evolving requirements.
Key Takeaways
The transition from BCBS 239 principles to RADAR-driven operational expectations marks a turning point for data quality in financial services.
The bar has moved. Institutions are no longer judged solely on whether they have controls in place, but on how effectively those controls are implemented, governed, and reported.
End-to-end coverage is the new baseline. Data quality must now be end-to-end, business-owned, and continuously managed. The combination of observability, data contracts, and integrated workflows offers a practical path forward. It allows institutions to scale their data quality efforts, meet regulatory requirements, and build a foundation for future initiatives, including AI and advanced analytics.
Business ownership is mandatory. Issues must be logged, tracked, and resolved through formal processes with named owners; data quality reporting reaches the executive layer.
Achieving this requires more than incremental improvements. It demands a shift in how organizations think about data quality, from a technical function to a strategic capability.
The challenge is significant, but so is the opportunity. Organizations that get this right will not only achieve compliance, they will gain a stronger, more reliable data foundation for the future.
For a deeper look at how Soda operationalizes BCBS 239 and the RDARR Guide, see the BCBS 239 compliance use case and request a demo.
Watch the Webinar: 23Finance + Soda
In this webinar, we explore how 23Finance can implement a practical, scalable approach to compliant data quality management using Soda. Learn how to move from policy-level requirements to operational data quality controls that support compliance.
Frequently Asked Questions
How is a data anomaly defined?
An anomaly is any value that falls outside the expected range learned from historical data. For example, if values are between 20–30, anything outside that range is flagged. Human feedback can refine detection by correcting false positives or adding exceptions.
How do anomaly checks work for categorical data?
Anomaly detection typically relies on time-series data so values can be compared across periods (e.g., today vs yesterday). For categorical data without timestamps, anomaly detection becomes rule-based rather than historical comparison.
How much historical data is required to train anomaly detection models? Can it be customized?
At least 5 prior data points (iterations) are needed for the model to converge. More historical data improves accuracy. Customization depends on implementation, but increasing history generally leads to better results.
Are data quality (DQ) checks only implemented through contracts?
It depends on the Soda version: - In v3: Checks can exist without contracts - In v4: Checks are always linked to contracts You can still control execution by running only a subset of checks within a contract.
Does Soda move data into its platform to run checks?
No. Soda uses a push-down approach, meaning: - Data stays in your database or warehouse - Checks are executed directly within your data environment
Can you define complex data quality checks (e.g., using Python)?
Yes, but complexity depends on the underlying data source. Most checks translate into SQL queries (adapted to systems like Snowflake, Databricks, BigQuery, etc.). Additionally, LLM-based checks are available for certain use cases (e.g., validating email formats), though they are non-deterministic compared to SQL rules.
When should you use anomaly detection instead of rule-based checks?
Generally: - Use rule-based checks when conditions are clearly defined - Use anomaly detection when patterns are dynamic or unknown and need to be learned from data
Can Soda connect to SAP S/4HANA?
Yes. SAP HANA Cloud support is currently in private preview.
Does Soda support unstructured data or document databases?
Yes. As long as the data can be loaded into a dataframe (e.g., using Pandas), data quality checks and contracts can be applied.











